Genome sequence of Bacillus sp. strain BAU-SS-2023, isolated from nasal swab of cattle in Bangladesh
Md. Abdur Rahman, Jahangir Alam, Farah Zereen, Md. Golzar Hossain, Sukumar Saha

TL;DR
This paper presents the genome sequence of a Bacillus strain isolated from cattle nasal swabs in Bangladesh.
Contribution
The novel contribution is the complete genome sequencing of a newly isolated Bacillus strain from Bangladeshi cattle.
Findings
The genome is 9,162,285 bp with 32.4% G+C content.
It contains 9,145 coding sequences, 6 rRNAs, 73 tRNAs, and 9 noncoding RNAs.
Abstract
We report the genome sequence of the Bacillus sp. strain BAU-SS-2023, isolated from nasal swabs of cattle in Bangladesh. The strain was isolated using brain heart infusion (BHI) broth and blood agar media. The genome was 9,162,285 bp, 32.4% G+C content, 9,145 coding sequences, 6 rRNAs, 73 tRNAs, and 9 noncoding RNAs.
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
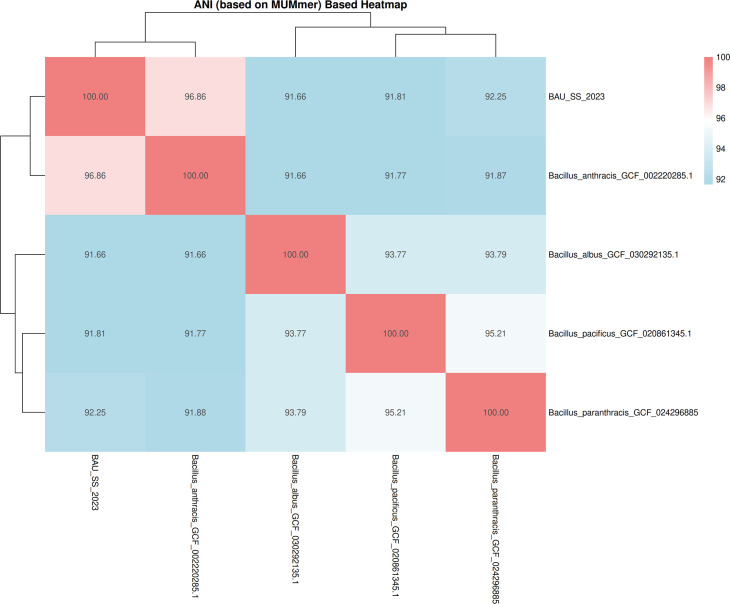 Fig 1
Fig 1- —World Bank Group (WBG)
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsMicrobial infections and disease research · Bacteriophages and microbial interactions · Genomics and Phylogenetic Studies
ANNOUNCEMENT
Bacillus species are Gram-positive, spore-forming, rod-shaped, motile bacteria that can survive in various environmental settings (1). Bacillus sp. BAU-SS-2023 strain was identified through colony characteristics and draft genome sequence itself along with Pasteurella multocida serotype B2 from nasal swab samples of clinically suspected hemorrhagic septicemia showing signs of fever, restlessness, nasal discharge, and progressive respiratory distress of nine crossbred dairy cattle at Trishal (90.0242560°E, 24.2235986°N), Mymensingh, Bangladesh. The nasal swab samples were separately inoculated into brain heart infusion (BHI) broth (2) and kept under constant shaking at 180 rpm for 48 hours at 37°C in a shaking incubator. Then, the enriched samples were inoculated separately into bovine blood agar media and incubated overnight at 37°C (3). Small, round, white, opaque, glistening, and non-hemolytic colony characteristics resembling Bacillus spp. were observed on blood agar from three different samples. Among them, a single colony of BAU-SS-2023 strain was selected, picked, and purified three times by repeated streaking onto bovine blood agar. Then, a single colony from that blood agar was inoculated into BHI broth. Genomic DNA was extracted from the same culture broth at sterile conditions using the Monarch Genomic DNA Purification Kit (New England Biolabs Inc.) and was sequenced on the Illumina MiSeq platform, with a maximum read length of 2 × 300 bp. First, genomic DNA was fragmented into 400–550 bp pieces using the M220 Focused-ultrasonicator (Covaris Ltd., Brighton, UK), and the Nextera XT DNA Library LT kit (Illumina, San Diego, CA, USA) was used to construct the DNA sequencing library. With a sequence depth of 50× coverage, the Illumina sequencing yielded 626,056 paired-end reads in total.
The raw sequence data underwent quality control using the FastQC (version 0.11.9) tool. Following this, adapter sequence trimming was performed with the fastp (version 0.23.2) (4). With the paired-end reads in hand, we employed Unicycler (version 0.4.8) tools which use SPADES for genome assembly (5). This resulted in a genome 9,162,285 bp long consisting of 85 contigs with N50 length 210,837 and GC content 32.4%. Post-assembly, genome annotation was carried out using the NCBI prokaryotic annotation pipeline PGAP (6), which predicted 9,233 genes, including 9,145 CDSs (coding sequences), 88 RNAs, 6 rRNAs, 73 tRNAs, and 9 noncoding RNAs (ncRNAs).
The contigs of the assembled genome were subjected to screening for virulence properties in the Virulence Factor Database-VFDB (7). The antibiotic resistance database was used to find plausible gene candidates linked to antimicrobial resistance (8, 9) and found three antibiotic resistance genes such as VanR-M_1, VanZ-F_1, and vat (E)_10 (10). This screening was performed using Abricate (version 0.5), with parameter cutoffs of 90% coverage and 95% nucleotide identity (11). Average nucleotide identity was calculated with JSpeciesWS and visualized on a clustered heatmap (12), in which about 91.66%–96.86% nucleotide identity was found with different Bacillus spp. (Fig. 1). Default parameters were used for all software.
Heatmap of Bacillus spp. Average nucleotide identity (ANI) was calculated using JSpeciesWS Online Service (https://jspecies.ribohost.com/) using ANIm (MUMmer-based method). Here, above cutoff (>95%) and below cutoff (<95%) nucleotide similarity is the indication of similar species.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Nicholson WL, Munakata N, Horneck G, Melosh HJ, Setlow P. 2000. Resistance of Bacillus endospores to extreme terrestrial and extraterrestrial environments. Microbiol Mol Biol Rev 64:548–572. doi:10.1128/MMBR.64.3.548-572.200010974126 PMC 99004 · doi ↗ · pubmed ↗
- 2Brain Heart Infusion Broth. 2017. Brain heart infusion broth liquid medium for the cultivation of various fastidious organisms and detection of staphylococci.
- 3Lu Z, Guo W, Liu C. 2018. Isolation, identification and characterization of novel Bacillus subtilis. J Vet Med Sci 80:427–433. doi:10.1292/jvms.16-057229367516 PMC 5880821 · doi ↗ · pubmed ↗
- 4Chen S, Zhou Y, Chen Y, Gu J. 2018. Fastp: an ultra-fast all-in-one FASTQ preprocessor. Bioinformatics 34:i 884–i 890. doi:10.1093/bioinformatics/bty 56030423086 PMC 6129281 · doi ↗ · pubmed ↗
- 5Wick RR, Judd LM, Gorrie CL, Holt KE. 2017. Unicycler: resolving bacterial genome assemblies from short and long sequencing reads. PLOS Comput Biol 13:e 1005595. doi:10.1371/journal.pcbi.100559528594827 PMC 5481147 · doi ↗ · pubmed ↗
- 6Tatusova T, Di Cuccio M, Badretdin A, Chetvernin V, Nawrocki EP, Zaslavsky L, Lomsadze A, Pruitt KD, Borodovsky M, Ostell J. 2016. NCBI prokaryotic genome annotation pipeline. Nucleic Acids Res 44:6614–6624. doi:10.1093/nar/gkw 56927342282 PMC 5001611 · doi ↗ · pubmed ↗
- 7Chen L, Zheng D, Liu B, Yang J, Jin Q. 2016. VFDB 2016: hierarchical and refined dataset for big data analysis--10 years on. Nucleic Acids Res 44:D 694–D 697. doi:10.1093/nar/gkv 123926578559 PMC 4702877 · doi ↗ · pubmed ↗
- 8Jia B, Raphenya AR, Alcock B, Waglechner N, Guo P, Tsang KK, Lago BA, Dave BM, Pereira S, Sharma AN, Doshi S, Courtot M, Lo R, Williams LE, Frye JG, Elsayegh T, Sardar D, Westman EL, Pawlowski AC, Johnson TA, Brinkman FSL, Wright GD, Mc Arthur AG. 2017. CARD 2017: expansion and model-centric curation of the comprehensive antibiotic resistance database. Nucleic Acids Res 45:D 566–D 573. doi:10.1093/nar/gkw 100427789705 PMC 5210516 · doi ↗ · pubmed ↗