Anatomy guided modality fusion for cancer segmentation in PET CT volumes and images
Ibtihaj Ahmad, Sadia Jabbar Anwar, Bagh Hussain, Atiq ur Rehman, Amine Bermak

TL;DR
This paper introduces a new method for combining CT and PET scans to better identify cancer areas, improving diagnosis and treatment planning.
Contribution
The novel intermediate fusion approach with learnable normalization and anatomical guidance improves cancer segmentation in PET CT.
Findings
The proposed method achieves a dice score of 0.8184 for cancer segmentation.
The model reduces computational load with fewer filters while maintaining high accuracy.
The HD95 score of 2.31 demonstrates improved spatial precision in tumor delineation.
Abstract
Segmentation in computed tomography (CT) provides detailed anatomical information, while positron emission tomography (PET) provide the metabolic activity of cancer. Existing segmentation models in CT and PET either rely on early fusion, which struggles to effectively capture independent features from each modality, or late fusion, which is computationally expensive and fails to leverage the complementary nature of the two modalities. This research addresses the gap by proposing an intermediate fusion approach that optimally balances the strengths of both modalities. Our method leverages anatomical features to guide the fusion process while preserving spatial representation quality. We achieve this through the separate encoding of anatomical and metabolic features followed by an attentive fusion decoder. Unlike traditional fixed normalization techniques, we introduce novel “zero layers”…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
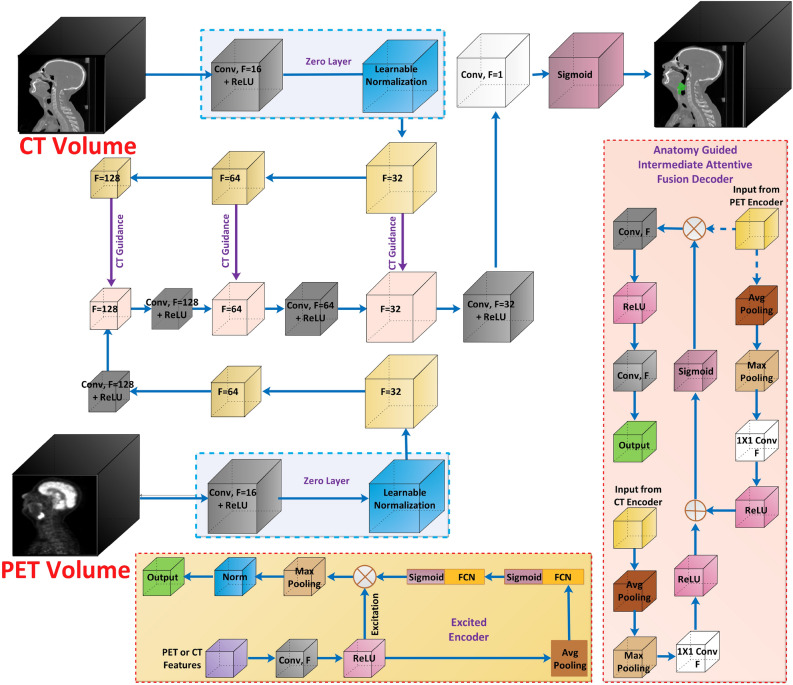 Figure 1
Figure 1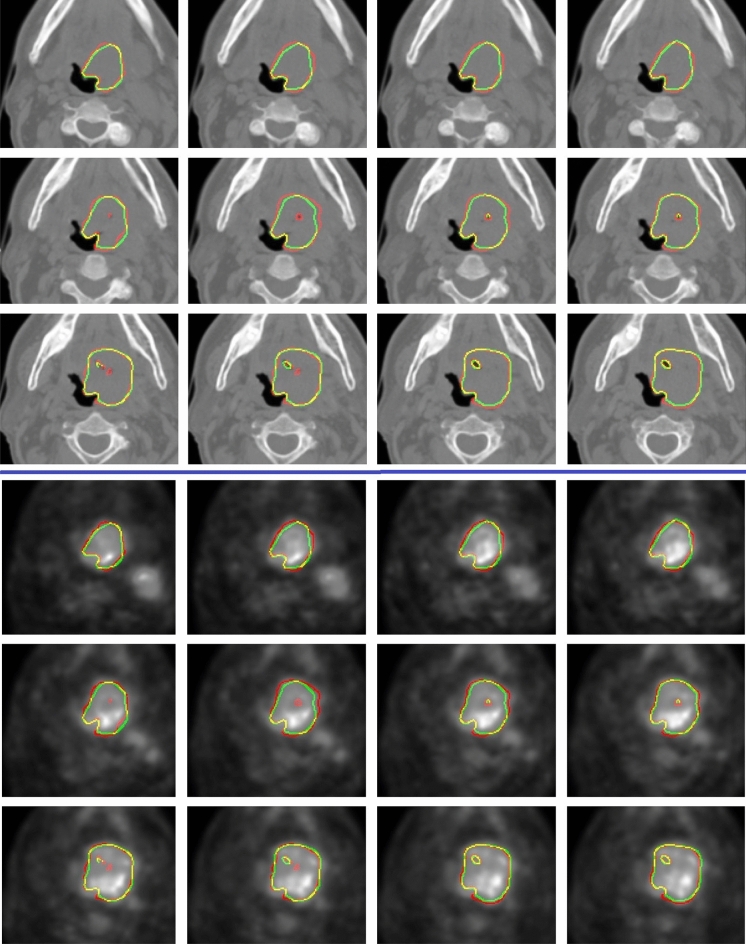 Figure 2
Figure 2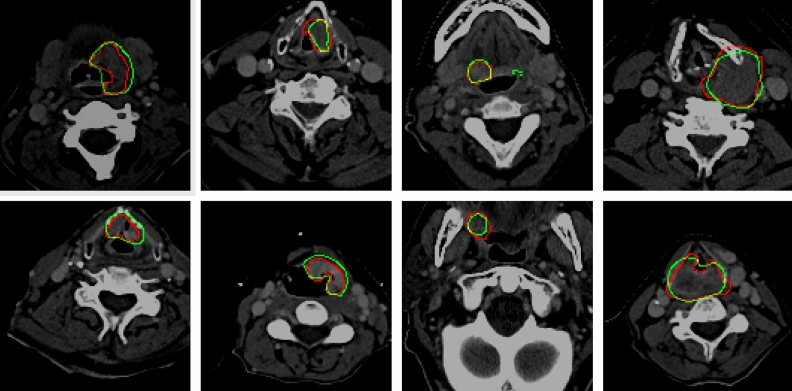 Figure 3
Figure 3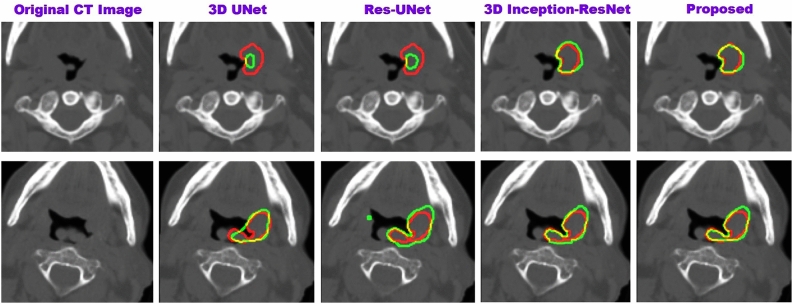 Figure 4
Figure 4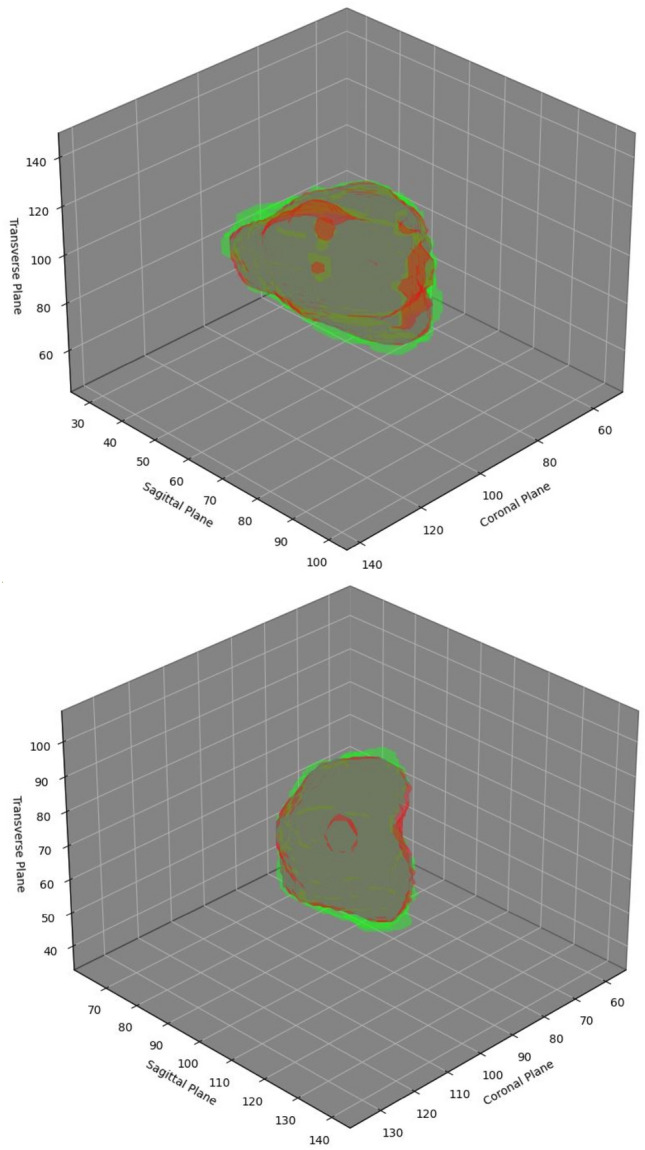 Figure 5
Figure 5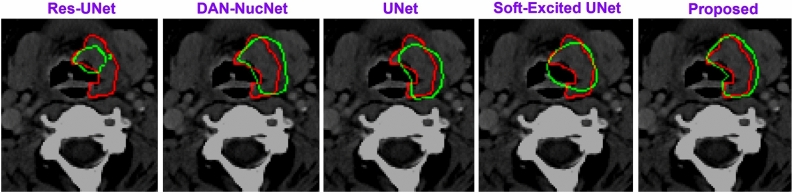 Figure 6
Figure 6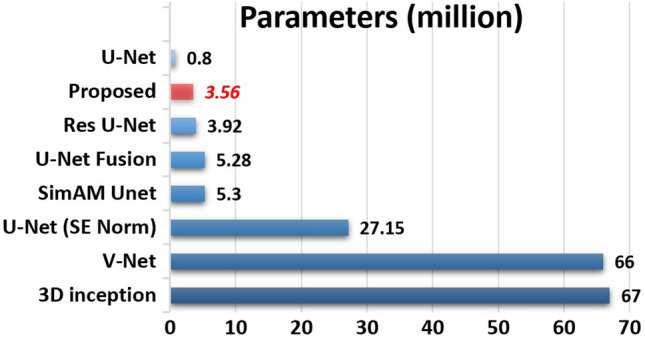 Figure 7
Figure 7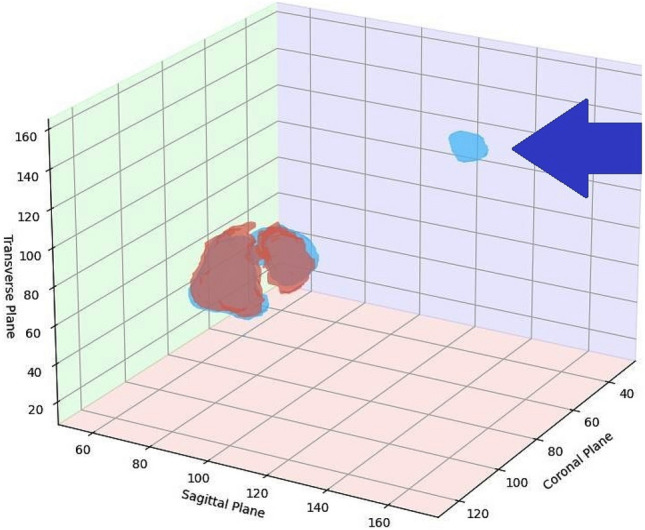 Figure 8
Figure 8- —Qatar Research Development and Innovation Council
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsMedical Imaging Techniques and Applications · Radiomics and Machine Learning in Medical Imaging · Advanced X-ray and CT Imaging
Introduction
PET offers metabolic information that helps to identify and assess malignancies such as tumors. In PET scans, the tumor typically exhibits a higher standardized uptake value. Therefore, PET scans are crucial for clinical diagnosis and radiotherapy treatment. However, PET lacks anatomical information and has low resolution. CT on the other hand, offers a high-resolution view of anatomical structures. However, CT does not reveal much about malignancies. In conjunction, the oncologists use PET to examine lesions and CT to find the anatomical context. Combining these modalities improves the segmentation performance^1^. Given that PET-CT modalities are in the form of volumes, automated analysis with computer assistance is still difficult because of the redundant data in these enormous volumes.
Early Computer-Aided Diagnosis (CAD) systems used individual 2D PET or CT slices to train deep-learning segmentation models. However, because they do not take 3D information into account, they produce low-quality segmentation^2^. These segmentations can not be used for critical procedures, such as radiotherapy. 2.5D methods were introduced to use 3D information at a lower computational cost^3^. However, 2.5D methods still use part of the 3D volumes, resulting in lower-quality segmentation. With the development of powerful Graphical Processing Units, more accurate 3D approaches have become possible. These methods produce better segmentation at the expense of more resources. These methods use PET or CT separately or combine them to produce better results^4,5^. The effective techniques for combining these modalities are based on early or late fusion^6,7^. However, these methods cannot independently learn complementary features of CT and PET modalities. Furthermore, PET and CT images are less correlated at the volume level and should not be fused as channels^1^. On the other hand, late fusion techniques utilize more resources and cannot use shallow inter-modality features.
We resolve these issues via anatomy guided intermediate attentive fusion mechanism. We excite the encoders with individual modalities through the squeeze and excite method to improve the quality of spatial representation. We then fuse PET features with CT features guided by anatomical attention. We demonstrate that our approach reduces the number of filters required, making the model lightweight. We also add a “zero layer,” which has a learnable normalization layer. Furthermore, we train and evaluate the model with volumes and images (2D slices). The following are the major contributions of this work:
- We extract features from each modality separately via excited encoders to improve the spatial representations and then fuse only useful features intermediately through a guided attentive fusion mechanism.
- We propose zero layers, which use learnable normalization. The learnable normalization produces significant improvements compared to the fixed normalization used by the state-of-the-art.
- Compared to the state-of-the-art, our model is less complex in terms of training parameters. Furthermore, unlike the state-of-the-art models, the suggested model applies to volumes and slices.
Related work
The development of deep learning models significantly improved automatic computer-assisted diagnosis. The earliest deep learning techniques outperformed the conventional image segmentation methods^8–10^. These techniques have more generalization capability yet possess huge improvement gaps. The performance gaps are improved with the UNet style encode-decode structures^11–15^. These techniques works well for images, however for applications like radiotherapy planning, 2D segmentation they are unreliable because it is susceptible to discontinuity in 3D space^2^. Powerful Graphical Processing Units made the development of 3D models possible which with higher computational costs, can capture 3D features^2,16^. Early 3D models utilized single-modality encoder-decoder architecture.^17^ proposed the first encoder-decoder style model to segment tumors in CT images.^18^ used a 3D UNet with deformable convolution blocks. Other variants of UNet are proposed to improve the segmentations^19–21^. In contrast to encoder-decoder style methods,^22^ suggested a 3D FCN generate a probability map from the modality and segment the tumor from its surrounding soft tissues.^23^ suggested a multi-resolution network to integrate features from different image resolutions and feature levels via residual connections.^24^ integrated 2D dense connection CNN with 3D VNet. These techniques only use one modality, which yields unsatisfactory segmentation and is inadequate for applications involving complicated medical procedures, e.g., radiation therapy^25^.
PET and CT modalities are fused to achieve superior segmentation performance^20,26^. These methods are classified as late fusion and early fusion. Late fusion, such as the one proposed by^7^ and^27^, generally employs distinct CT and PET models combined at the decision level. Late fusion models require a lot of resources^6^. In contrast, early fusion methods fuse CT and PET at the modality level^28^. Early fusion-based methods, such as^29^ and^30^, use attention mechanisms to exploit the advantages of spatial attention. The early fusion method based on 3D-Inception ResNet employs modified Inception units as encoders, while ResNet units as decoders^31^. Early fusion-based methods are often less resource-hungry and outperform late fusion techniques in segmentation performance^6^. However, early fusion-based methods have drawbacks, i.e., they lack the ability to learn the complementary features among each modality^7^. Furthermore, CT and PET modalities are less correlated at the volume level^1^. Intermediate fusion strategies combine the benefits of both methods while overcoming their drawbacks^32–34^. These methods have demonstrated improved performance for segmenting 2D medical images. However, they rely on massive intermediate connections. 3D volumes, such as PET and CT, drastically increase the required intermediate connections due to the depth of these modalities. By reducing the massive number of features caused by the depth of modalities via some mechanism, the intermediate fusion can become less resource-hungry while producing improved results. According to recent literature, the fusion via attention mechanism is more effective than other methods^35^. Fusion via the attentive mechanism is now being used in other image processing applications^36,37^. These techniques have outperformed other intermediate fusion techniques in terms of performance. However, designing fusion via the attentive mechanism is challenging in the case of PET and CT^38,39^. Since both modalities are in the form of huge 3D volumes, designing complex intermediate fusion mechanisms may increase the computational burden. Another important factor that can highly affect the segmentation in PET and CT is the normalization^40,41^. PET scans produce images where pixel intensities represent tracer uptake, often expressed as Standardized Uptake Values (SUVs). These values can vary significantly depending on the patient body weight, injected dose, and scanner calibration. Similarly, with a defined range, CT scans measure tissue density in Hounsfield Units (HU). These values might be consistent across scans but differ substantially from PET values. Both of these modalities need to be normalized. Existing methods rely on fixed normalization, which might not accurately normalize if the scans are from different sources. These fixed methods might include standard slipping, z-score normalization, sine wave, etc.^19,20,42,43^. To solve the above mentioned problems, this work aims to design an intermediate fusion mechanism that includes learnable normalization and may require fewer resources.Fig. 1. The figure illustrates our architecture along with the excited encoder and anatomy guided intermediate fusion decoder..
Proposed architecture
The proposed architecture uses learnable normalization layers for each modality to learn the normalization for each input modality. The architecture uses parallel squeeze and excited (SE) encoders for PET and CT features. These encoders extract relevant features from each modality separately. The encoders are followed by an anatomy-guided intermediate fusion mechanism (Fig. 1) via the specially designed decoders. Finally, it outputs the semantic segmentation mask of the cancer. The major components of the architecture are explained in detail as follows:
Zero layers
The model has two inputs for each modality (V) which is independently passed through a “zero layer”. The learnable normalization layer at this stage plays a significant role in performance improvement since the normalization of CT and PET is essential due to the variations caused by capturing environment and equipment. Although we perform normalization at the pre-processing stage (refer “Datasets” for details), this secondary normalization adds to the performance improvement. The improvement caused by this additional normalization is verified in the ablation study (refer “Ablation studies”).
The model takes PET and CT volumes as inputs, denoted as \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$M_{\text {PET}}$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$M_{\text {CT}}$$\end{document} , respectively. Each volume passes through the Zero Layer. The zero layers consist of convolution (Conv) with the kernel (k) and filters (F), followed by ReLU ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\rho$$\end{document} ) and normalization (N) layers, respectively. The normalization is learnable via gamma ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\lambda _{PET/CT}$$\end{document} ), beta ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\delta _{PET/CT}$$\end{document} ) parameters, and a learnable constant \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\epsilon$$\end{document} .
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} P_{\text {PET}}= & \rho \left( Conv^F_{k,k}(M_{\text {PET}})\right) \\ P_{\text {CT}}= & \rho \left( Conv^F_{k,k}(M_{\text {CT}})\right) \end{aligned}$$\end{document}The normalized outputs for PET and CT are given by:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} & Norm (\text {PET}) = \lambda _{\text {PET}} \cdot \left( \frac{P_{\text {PET}} - \mu (P_{\text {PET}})}{\sqrt{\sigma ^2(P_{\text {PET}}) + \epsilon }}\right) + \delta _{\text {PET}} \\ & Norm (\text {CT}) = \lambda _{\text {CT}} \cdot \left( \frac{P_{\text {CT}} - \mu (P_{\text {CT}})}{\sqrt{\sigma ^2(P_{\text {CT}}) + \epsilon }}\right) + \delta _{\text {CT}} \end{aligned}$$\end{document}Squeeze and excited encoders
PET and CT carry complementary information but differ significantly in the kinds of features they emphasize. The squeeze-and-excite mechanism allows the model to adaptively emphasize the most important features from each modality. By learning weighting, the model can decide how much importance to give to each feature map based on the specific modality, thus improving the overall feature representation.
The normalized outputs from zero layers are processed through their respective encoders, which consist of convolution layers (Each stage of encoder have different number of filters, i.e. \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$F=[128, 64, 32, 16]$$\end{document} ) and ReLU activations ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\rho$$\end{document} ).
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} Enc_{\text {PET}}= & \rho \left( Conv^{F}_{3,3}(Norm_{\text {PET}})\right) \\ Enc_{\text {CT}}= & \rho \left( Conv^{F}_{3,3}(Norm_{\text {CT}})\right) \end{aligned}$$\end{document}Then the global features \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$g$$\end{document} are extracted via average pooling is:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} g_{\text {PET}}= & Pool_{\text {GAP}}(Enc_{\text {PET}}) \\ g_{\text {CT}}= & Pool_{\text {GAP}}(Enc_{\text {CT}}) \end{aligned}$$\end{document}The excitation is calculated by passing \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$g$$\end{document} through fully connected layers with ReLU and sigmoid activations ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\sigma$$\end{document} ):
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} Exc_{\text {PET}}= & \sigma (FCN(\rho (FCN(g_{\text {PET}})))) \\ Exc_{\text {CT}}= & \sigma (FCN(\rho (FCN(g_{\text {CT}})))) \end{aligned}$$\end{document}The final excited features are computed by modulating the fused feature map \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$f_{\text {fused}}$$\end{document} with the excitation via channel-wise multiplication:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} f_{\text {PET}}= & Enc_{\text {PET}} \otimes Exc_{\text {PET}} \\ f_{\text {CT}}= & Enc_{\text {CT}} \otimes Exc_{\text {CT}} \end{aligned}$$\end{document}The excited features are passed through a final set of max pooling and normalization layers to yield the final output:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} PET_{\text {excited}}= & Norm(Pool_{\text {MP}}(f_{\text {PET}}) \\ CT_{\text {excited}}= & Norm(Pool_{\text {MP}}(f_{\text {CT}}))) \end{aligned}$$\end{document}Anatomy-guided intermediate fusion
The extracted features from PET and CT are fused in the intermediate fusion block. The features are first pooled using average pooling and max pooling, then processed through convolution layers to reduce dimensions. The pooled features ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$PET^{\text {pf}}$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$CT^{\text {pf}}$$\end{document} ) are represented as:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} PET^{\text {pf}}= & Conv^F_{1,1}(Pool_{\text {MP}}(Pool_{\text {AP}}(PET_{\text {excited}}))) \\ CT^{\text {pf}}= & Conv^F_{1,1}(Pool_{\text {MP}}(Pool_{\text {AP}}(CT_{\text {excited}}))) \end{aligned}$$\end{document}Fusion is performed by element-wise addition and ReLU activation, followed by a convolution layer:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} f_{\text {fused}} = \sigma \left( PET^{\text {pf}} \oplus CT^{\text {pf}})\right) \end{aligned}$$\end{document}Now the anatomy guidance is provided by element-wise multiplying the fused features with the excited CT features from the encoder.
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} CT_{guidance} = CT_{\text {excited}} * f_{\text {fused}} \end{aligned}$$\end{document}The fused feature map is processed by sigmoid activation ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\sigma$$\end{document} ) and a 1x1 convolution to get the intermediate fusion decoder output:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} Dec\_out = Norm \left( \sigma \left( Conv^F_{1,1}(CT_{guidance}) \right) \right) \end{aligned}$$\end{document}Datasets
Data selection for training PET-CT segmentation models is difficult since most available datasets are limited to a few samples, usually in tens. Training with such data leads to over-fitting, which is a serious concern since the reported results may not be reliable^7^. Furthermore, the data is usually collected from a single equipment or collection center. Since PET-CT may have huge variations caused by varying equipment, the dataset from a single source may be unreliable. Due to these reasons, we select the dataset based on strict guidelines to avoid these problems and report reliable results. We select the dataset having the following features. First, it must be standardized and huge in size. Second, it must have different collection sources. Third, it must have manual PET-CT delineations. Based on these guidelines, the two datasets, HEad and neCK TumOR segmentation challenge (HECKTOR)^43^, and The Cancer Imaging Archive (TCIA)^44–46^ are selected. HECKTOR contains 224 samples obtained from five different sources. TCIA dataset consists of 137 samples from different sources.
Since the dataset is obtained from various sources, we apply normalization to both modalities. The CT volumes are clipped at Hounsfield Units between \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$[ -1024,1024 ]$$\end{document} . The volume is then mapped between the range \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$[-1, 1]$$\end{document} . PET volume is normalized using Z-score, i.e. \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$z = (x ^{\breve{\,}} \mu )/\sigma$$\end{document} , where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mu$$\end{document} is mean, and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\sigma$$\end{document} is standard deviation. These techniques are proven to be a standard for PET-CT normalization^19,20,43^. Apart from the normalization, we have applied augmentation techniques, including horizontal and vertical flipping and rotation, since it contributes towards performance improvement^47^.
Experiment and results
Implementation environment
The suggested architecture is implemented using Keras, a python library. Nvidia RTX 2060 12G GPU, accelerated by CUDA 9.0, is used to train, test, and evaluate the architecture. The batch size is set to one while the learning rate is set to 0.005, which is reduced if the model stops learning for ten consecutive epochs. Adam optimizer is used to minimize the loss function.
Performance evaluation
The performance of our 3D model is evaluated using the 3D dice similarity coefficient (DSC) and 95% Hausdorff Distance ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\hbox {HD}^{95}$$\end{document} ). 3D DSC measures the volume overlap between computer-assisted segmentation and segmentation performed by an expert.
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} DSC \left( x,y \right) = 2\times \frac{\left| x \right| \bigcap \left| y \right| }{\left| x \right| +\left| y \right| } \end{aligned}$$\end{document}\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\hbox {HD}^{95}$$\end{document} measures the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$95^{th}$$\end{document} percentile of the distances between boundaries drawn by experts and computers.
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} HD^{95}\left( x,y \right) =P^{95}\left[ \underset{\text {i}\in \text {x} \text { j}\in \text {y}}{\text {sup inf }} E_{d}(i,j), \underset{\text {j}\in \text {y} \text { i}\in \text {x}}{\text {sup inf }} E_{d}(i,j) \right] \end{aligned}$$\end{document}where x, and y are ground truth and predicted tumor volumes. \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$E_{d}$$\end{document} is the euclidean distance between i, and j. sup, and inf are supremum, and infimum. \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$P^{95}$$\end{document} is the 95th percentile. Apart from DSC and ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\hbox {HD}^{95}$$\end{document} ), we have used precision and recall as supporting evaluation metrics. We employ 2D DSC, Precision, and Recall to evaluate the performance of 2D architecture. These metrics are commonly used for performance evaluation^48,49^.
Results
We follow the same strategy as the state-of-the-art to report and compare our results for the HECKTOR dataset. We use data from one data center as the test data and train our model on the rest. Table 1 shows each data center’s results, in terms of median, average, and random split. It is to be noted that the “fold” in the table refers to the data on which the model is tested. Furthermore, the deviation reported in the table refers to the maximum deviation in the folds and is not to be confused with the standard deviation. Similarly, the median refers to the median among all the data folds. Apart from the leave-one-center strategy, the data is randomly split into the test (20%) and training (80%) datasets, and the model is evaluated. It is observed that the random split produces slightly reduced performance compared to the leave one-center-split strategy. In the case of the TCIA dataset, we split the dataset randomly and report the results since the dataset does not mention the collection centers.The performance of the proposed model is also compared to the state-of-the-art models. The proposed model is compared to the generic modules (3D UNet^17^, Res UNet^50^, VNet^51^) as well as models designed specifically for PET-CT fusion (refer to Tables 2 and 3). Our model generates improved volumetric segmentation, represented by DSC, and improved delineated boundaries, represented by \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\hbox {HD}^{95}$$\end{document} score.Table 1. The table presents the outcomes obtained using the leave one-center-alone of the HECKTOR dataset. The average of the 5-fold cross-validation is shown in the second last row. The last row shows the results obtained random data split strategy.Data CenterDSC \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\hbox {HD}^{95}$$\end{document} PrecisionRecallFold 1 (CHGJ)0.84272.820.85000.6368Fold 2 (CHUS)0.80032.000.76860.5892Fold 3 (CHMR)0.79872.430.75780.5922Fold 4 (CHUM)0.80822.000.81610.5800Fold 5 (CHUP)0.84212.300.83090.6466Fold average0.81842.310.80460.6079Median ± deviation0.8207±0.02202.41±0.410.8039 ±0.04610.6133±0.0333Random split0.8102 ±0.01253.02 ±0.130.84765±0.03430.5695±0.0532Table 2The table compares the suggested 3D model to state-of-the-art 3D models using the HECKTOR dataset.MethodsDSC \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\hbox {HD}^{95}$$\end{document} PrecRec3D UNet (CT)^17^0.495819.840.56740.23223D UNet (PET)0.654713.90.69320.37493D UNet (PET-CT)0.71297.380.73540.4442VNet^51^0.6398–0.71200.3511CCUT-Net^29^0.70444.260.72390.4353Skip-scSE^52^0.75414.950.79910.4871UNet (SE Norm)^28^0.76883.790.82240.5023SimAM UNet^30^0.78843.150.86020.5440Res UNet^50^0.76802.980.72980.56183D-Inception-ResNet^31^0.79402.800.79500.5618Proposed0.81842.310.80460.6079Significant values are in bold.
The results obtained from the TCIA dataset are compared with the state-of-the-art in Table 3. Additionally, the 2D architecture are compared to the relevant state-of-the-art 2D models in Table 4. In Table 4, each state-of-the-art 2D model is evaluated on CT and PET individually, and then, by using early fusion. Figurative examples of segmentation generated by the 3D and 2D models are shown in Figs. 2, 3 and 5, respectively. While the 2D and 3D figurative comparison of the suggested model with the top-performing state-of-the-art models are shown in Figs. 4 and 6, respectively.Table 3. The table compares the suggested 3D model to the state-of-the-art 3D models using TCIA dataset.MethodsDSC \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\hbox {HD}^{95}$$\end{document} PrecRec3D UNet (CT)^17^0.299811.260.27400.12993D UNet (PET)0.47515.670.41540.24923D UNet (PET-CT)0.65443.850.77500.3543Skip-scSE^52^0.77824.310.82170.5199Res UNet^50^0.75433.350.81420.4819UNet (SE Norm)^28^0.77902.930.83590.5158Proposed****0.83373.160.9027****0.5916Significant values are in bold.Table 4. The table compares the suggested 2D model to the recent state-of-the-art 2D models using the TCIA dataset.MethodsDSCPrecRecDIST (CT)^14^0.40030.41270.1795DIST (PET)0.50450.46240.2655DIST (PET-CT)0.54690.46970.3139DAN-NucNet (CT)^35^0.40060.40010.1822DAN-NucNet (PET)0.44290.42190.2145DAN-NucNet (PET-CT)0.53630.47810.2970ResUNet (CT)^50^0.40450.39120.1875ResUNet (PET)0.48170.45890.2424ResUNet (PET-CT)0.57220.47660.3457SE UNet (CT)^28^0.39900.40220.1805SE UNet (PET)0.50190.46270.2625SE UNet (PET-CT)0.58050.52250.3359UNet (CT)^11^0.39100.37150.1805UNet (PET)0.49730.43280.2678UNet (PET-CT)0.61440.54990.3714Proposed0.64270.61540.3847Significant values are in bold.
Fig. 2. The figure depicts examples of consecutive slices from a 3D CT and PET volume, respectively, in HECKTOR dataset (CHUM center, volume 6, slice 32nd onwards.). The original tumor boundary is highlighted in red, while the predicted boundary is highlighted in green. The intersection of the original and predicted boundaries is shown in yellow. Fig. 3. Slices from different patients in the TCIA dataset are displayed in each row of the figure. The manually drawn tumor boundary, the boundary predicted by our suggested 2D model, and the boundary overlap are represented by a different color: red, green, and yellow, respectively. Fig. 4. The figure shows the comparison of the proposed 3D model with the state-of-the-art methods. The manually delineated tumor boundary, the predicted boundary by our 3D model, and the boundary overlap are shown in red, green, and yellow, respectively. Fig. 5. The figure shows two examples of the actual cancer (green), the segmented cancer (red), and their overlap (gray) in 3D. The axis of the figures are marked by the slice number from a 3D volume. Fig. 6. The figure shows the comparison of the proposed 2D model with some of the state-of-the-art methods. The manually delineated tumor boundary, the predicted boundary by our 2D model, and the boundary overlap are shown in red, green, and yellow, respectively.
Discussion
This section discuss various aspects of the suggested architecture in detail.
Complexity analysis
Multi-modality volumetric segmentation requires enormous computational and memory resources. Therefore the complexity analysis of the 3D models is crucial. We have compared the suggested model with the state-of-the-art models (refer to Fig. 7).Fig. 7. The figure compares the complexity of the suggested model to existing models in terms of trainable parameters.
The number of parameters utilized by the models are obtained using Keras’s model “summary” method. The suggested model has fewer parameters than the state-of-the-art, including VNet, 3D-Inception ResNet, and variants of UNet. The primary reason for such a low number of parameters is that the proposed model is less deep than the state-of-the-art. The state-of-the-art models are usually six to eight layers deep, which makes them extremely resource hungry. The intelligently designed decoders and encoders reduce the requirement of having more deep layers. The parameters are also reduced by the fusion of the selected features from each modality instead of fusing the whole modality.
Ablation studies
The ablation studies in this section confirm our hypotheses about the model’s functionality. In the first study, we add individual elements and evaluate the model at each stage. We first train and test the model with only one modality, where we do not use our modality fusion mechanism. Then, we train and test the model using only a simple fusion of PET and CT. In the next stage, we fuse the PET and CT with our attentive fusion decoder. Then, we train and test the model by adding the zero layers. It is to be noted that in all the above stages, we do not use SE encoders; instead, we use encoders without SE. Finally, we train and test the model by adding the SE encoders. The results of the model at each stage is reported in Table 5. We observe that each addition to the model improves the performance significantly. The primary performance improvement is contributed by anatomy-guided intermediate fusion. The addition of zero layers and excited encoders to our model contributes further toward improved segmentation. The improvement in the DSC represents slight significant improvement in the segmentation quality. However the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$HD^{95}$$\end{document} shows a huge improvement representing the higher quality boundary delineation of the tumor.Table 5. The table summarizes the ablation study performed using the HECKTOR dataset to determine each additional effect of the model’s sections.AblationDSC \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\hbox {HD}^{95}$$\end{document} CT0.442414.9PET0.59898.18PET-CT0.73926.60PET-CT attentive fusion0.81043.42PET-CT with zero layer0.81193.20PET-CT attentive fusion with SE encoder0.8184****2.31Significant values are in bold.
We also conducted experiments to investigate how much the data pre-processing contributes toward performance improvement. We first trained and tested our model with unprocessed data, then with normalized data (PET z-score normalization and CT clipping), and eventually with both normalization and augmentation. Table 6 summarizes the results of this ablation study. Normalization and augmentation, as expected, significantly improve segmentation.Table 6. The table presents the findings of the ablation study based on data pre-processing.AblationDSC \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\hbox {HD}^{95}$$\end{document} Without normalization0.68728.30Normalization0.79982.44Normalization \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$+$$\end{document} augmentation0.8184****2.31Significant values are in bold.
The proposed architecture guides tumor segmentation in PET volume using CT attention (anatomy awareness). In contrast to PET attention (functional awareness), this approach produces improved performance. The PET guided segmentation approach have been used in the past, however due to the lack of the spatial representations in the PET volumes/images, the segmentation quality remains low. To demonstrate this, we train and compare a model in which PET attention guides tumor segmentation to the proposed model (refer Table 7). This ablation study confirms that CT attention yields superior segmentation performance.Table 7. The table depicts the ablation study, in which we individually fed both modalities to the attention block and compared their performance.AblationDSC \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\hbox {HD}^{95}$$\end{document} PET guided segmentation0.79613.60CT guided segmentation0.8184****2.31Significant values are in bold.
Limitations
During detailed studies, we observed that our model shows slightly improved performance for metastasis compared to the state-of-the-art. The network may still not be able to segment metastasis occasionally (Fig. 8).Figure 8. The figure shows distant metastasis in a volume that is not segmented by the proposed model..
The problem of miss segmentation is not related to the suggested model. It remains a major concern for the state-of-the-art models as well. While extending our framework to metastasis segmentation is an interesting direction, it falls outside the scope of this study. Future work may incorporate transfer learning, distilled learning, or other techniques to adapt the model for metastasis-related tasks. Another limitation of the model is that it may not be able to segment the early stage cancer that is near or lower to the critical mass. This can be improved by increasing the depth or resolution of the PET and CT slices. However increasing the resolution may also cause a huge increase the required computational resources.
Conclusion
Cancer segmentation in PET-CT is critical for computer-assisted treatment, and radiotherapy planning. Existing models rely primarily on the fusion of PET-CT modalities at the decision level (late fusion) or the modality level (early fusion). Both of these techniques have disadvantages that limit segmentation performance. These methods cannot independently learn complementary features of CT and PET modalities. Furthermore, they utilize more resources and cannot use shallow inter-modality features. In this work, we employ novel zero layers, integrate excitation into our encoders that separately extract features from each modality, and fuse these modalities via anatomy-guided attentive intermediate fusion. We design the encoders by energizing them with spatial features from each modality, thus improving the spatial representations within the modalities. In addition, we introduce a zero layer that learns normalization compared to the state-of-the-art, which uses fixed normalizations. We demonstrate that our approach addresses the issues caused by early and late fusion. We show that the suggested architecture is less deep and, thus, more lightweight than existing models. We demonstrate the superiority of the suggested model through extensive results and ablation studies. Compared to the state-of-the-art, we achieved the highest DSC of 0.8184 and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\hbox {HD}^{95}$$\end{document} score of 2.31. Future research could focus on improving performance for distant metastasis. Furthermore, the model could be extended to include other modalities.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Zhao, H., Shi, J., Qi, X., Wang, X. & Jia, J. Pyramid scene parsing network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2881–2890. 10.48550/ar Xiv.1612.01105 (2017).
- 2He, K., Zhang, X., Ren, S. & Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 770–778 (2016).
- 3Zhou, Z., Siddiquee, M. M. R., Tajbakhsh, N. & Liang, J. U Net++: A nested U-Net architecture for medical image segmentation. In Deep learning in medical image analysis and multimodal learning for clinical decision support: 4th international workshop, DLMIA 2018, and 8th international workshop, ML-CDS 2018, held in conjunction with MICCAI 2018, Granada, Spain, September 20, 2018, proceedings 4, pp. 3–11. Springer International Publishing. 10.1007/978-3-030-00889-5_1 (2018).10.1007/978-3-030-00889 · doi ↗ · pubmed ↗
- 4Dubost, F. et al. GP-Unet: Lesion detection from weak labels with a 3D regression network. In International Conference on Medical Image Computing and Computer-Assisted Intervention, pp. 214–221. Cham: Springer International Publishing. 10.1007/978-3-319-66179-7_25 (2017).
- 5Zhang, Y., Liao, Q., Ding, L. & Zhang, J. Bridging 2D and 3D segmentation networks for computation efficient volumetric medical image segmentation: An empirical study of 2.5D solutions. 10.48550/ARXIV.2010.06163 (2020).10.1016/j.compmedimag.2022.10208835780703 · doi ↗ · pubmed ↗
- 6Ahmad, I., Xia, Y., Cui, H. & Islam, Z. U. DAN-Nuc Net: A dual attention based framework for nuclei segmentation in cancer histology images under wild clinical conditions. Expert Syst. Appl.213(Part A), 118945. 10.1016/j.eswa.2022.118945 (2023).
- 7Xiao, N. et al. PET and CT image fusion of lung cancer with siamese pyramid fusion network. Front. Med.9. 10.3389/fmed.2022.792390 (2022).10.3389/fmed.2022.792390 PMC 901003435433720 · doi ↗ · pubmed ↗
- 8Ren, J., Li, M. & Korreman, S. Sine wave normalization for deep learning-based tumor segmentation in CT/PET imaging. ar Xiv: 2409.13410. 10.48550/ar Xiv.2409.13410 (2024).