An 81-million-word multi-genre corpus of Arabic books
Andreas Hallberg

TL;DR
This paper introduces a large Arabic corpus of 81 million words from books across multiple genres, available for linguistic research and language model training.
Contribution
The paper presents a new, freely available multi-genre Arabic corpus with extensive metadata for linguistic and NLP research.
Findings
The corpus includes 1,745 books in various genres, totaling 81.5 million words.
Metadata such as author, genre, and publication dates were collected for each book.
The corpus is suitable for studying linguistic variation and training language models.
Abstract
This article describes The Arabic E-Book Corpus, a freely available Arabic corpus consisting of 1,745 books (81,5 million words) published by the Hindawi Foundation between 2008 and 2024. The books are of various genres, including fiction and non-fiction, children's literature, plays, and poetry. Most of the texts are editions of works originally published in the 20th century, but the corpus also includes editions of older historical works. Books were retrieved in epub format and converted to plain text and html. Only books published under unrestricted licenses are included. Extensive metadata (were collected from colophons and the publisher's website title, author, genre, publication date, original publication date, original language, etc.). The corpus was originally collected in order to investigate variation in the use of vowel diacritics across genres, but it is also suitable for…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
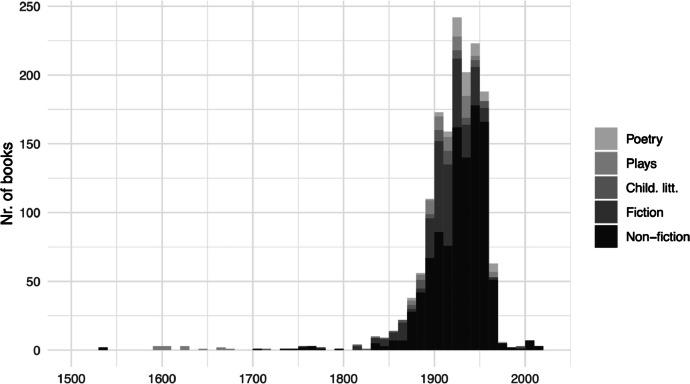 Figure 1
Figure 1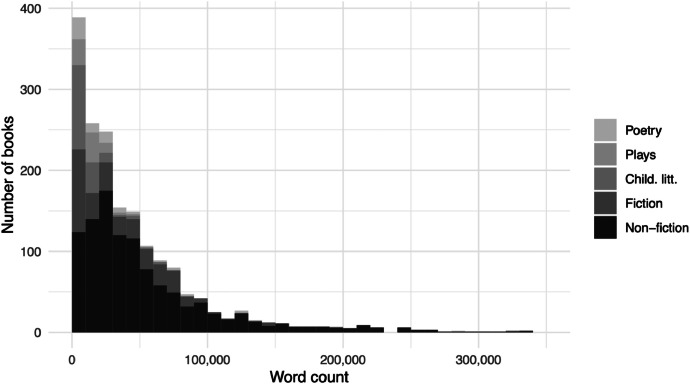 Figure 2
Figure 2Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsNatural Language Processing Techniques · Topic Modeling · Text Readability and Simplification
Specifications TableSubjectLinguistics, Literature, Applied Machine LearningSpecific subject areaArabic corpus linguistic, especially as relating to genre.Type of dataText, Raw.Data collectionBooks were downloaded in epub format and converted to html and plain text. Only books published under free licenses were included. Metadata for each book were extracted from the books and their associated web pages*.*Data source locationSwedish National Data ServiceData accessibilityRepository name: The Arabic E-Book Corpus [1]Data identification number: https://doi.org/10.5878/7rbhgy93Direct URL to data: https://snd.se/sv/catalogue/dataset/2024-145/1#Related research articleA. Hallberg, Principles of variation in the use of diacritics (taškı̄l) in Arabic books, Language Sciences. 93 (2022) 1–15. https://doi.org/10.1016/j.langsci.2022.101482/
Value of the Data
1
- •This corpus is useful for linguistic investigations in Arabic, including in lexicon [2], orthography [3], diacritization [[4], [5], [6]], stylistics, especially as related to genre [7]; as well as for various fields in natural language processing, for example as free-licensed data for the development of large language models [8].
- •In addition to collecting and formatting data for computational analysis, metadata was extracted and collected through a combination of automatic and manual methods, allowing for comparison of texts according to genre, date of publication, date of original publication, translated vs. untranslated works, etc.
- •The corpus is available in two versions: plain text and html. The plain-text version is appropriate for most types of linguistic investigation. The html version includes markup of textual elements (foreign words, poetry, Quranic quotes, etc.), allowing for investigations that target these elements specifically.
Background
2
A previous version of this corpus was originally collected to investigate variation in the use of vowel diacritics across genres [5]. That study required a corpus of digital contemporary book-length texts of various genres. The version of the corpus investigated in that paper included texts with restricted licenses, meaning that the corpus could not be widely shared. In the version presented here, only works published under free licenses are included, allowing for the corpus to be freely accessible to researchers.
To the best of my knowledge, The Arabic E-Book Corpus is the only freely licensed Arabic corpus of contemporary book length publications. Other freely available Standard Arabic corpora are either collections of books primarily of traditional and historical Islamic literature [[9], [10], [11]] or of news articles [12,13]. The first is unsuitable for investigations in Modern Standard Arabic, and the latter is restricted to a single genre. See [14] for an overview.
For a similar dataset with the complete set of books by the same publisher (Hindawi), including works with non-free silences, see [15]. That dataset is twice the size of The Arabic E-Book Corpus, but with the rights to the additional books held by the original publisher, the author, or the author's estate. In addition, the current dataset is enriched with metadata lacking in [15].
Data Description
3
Contents and coverage
3.1
The corpus consists of 1, 745 books published between 2008 and 2024 by the Hindawi Foundation as free e-books, to a total of 81, 5 million words. Of these, 491 books are works translated to Arabic from other languages, primarily from English and French (see Table 1). As shown in Fig. 1, most of the books are editions of works originally published in the early and mid-20th century, but the corpus also includes historical material.1Table 1Translated works by original language.Table 1. English372French80Russian13German12Turkish4Farsi3Italian2Greek2Urdu1Norwegian1Japanese1Total**491Fig. 1. Original publication date. Thirteen books originally published between 724 and 1500 are excluded in the graph.Fig. 1
The length of works vary considerably, with children's literature, plays, and poetry being overrepresented in shorter books up to 30, 000 words. This is illustrated in Fig. 2.Fig. 2. Word counts. Two books longer than 400, 000 words are excluded in the figure.Fig. 2
One of the main benefits of this corpus is the representation of genres. Each book was labeled by category by the publisher from a list of 25 labels. Table 2 shows the representation of these genres in the corpus. Researchers may wish to combine these categories in various ways, depending on the research question.Table 2. Counts and proportions of categories. Some books are assigned more than one category and are then listed more than once in the table. The sums of columns are therefore larger than the corpus totals.Table 2. CategoryWords (millions)% of tot.Nr. of bookshistory24.930.9326literature18.623.1340novels9.511.8178biographies7.08.6124literary.criticism6.58.193science6.58.0175philosophy5.46.799detective.fiction4.85.9169travel.literature3.64.455social.sciences3.84.765poetry3.54.489psychology1.01.319politics1.82.335science.fiction1.11.381plays1.31.688children.stories1.92.4167environmental.sciences0.40.53technology0.50.63geography0.50.67economics0.40.510arts0.70.919linguistics0.80.922health<0.1<0.11
File organization
3.2
The files in the repository are organized as follows:
- corpus-txt/
- 13028368.txt
- 13035305.txt
- 13050381.txt
- [...]
- corpus-html/
- 13028368.html
- 13035305.html
- 13050381.html
- [...]
- metadata.tsv
- README.md
- README.md.pdf
Each book is identified with a unique eight-digit number assigned by the publisher. This number is used for file names for text files, as shown above. All files are in utf8 encoding.
The corpus is provided in two versions: html and unformatted plain text. These are found in the directories corpus-html and corpus-txt respectively. The plain-text version is suitable for most purposes.
The html-version may be of use for investigations requiring isolation of specific text elements. These files retain the markup from the xhtml files embedded in the original epub bundles. In addition to standard html markup for headers, paragraphs, italics, etc., the markup includes custom class elements (e.g., "<span class="quran"> ... </span>") . Some of these classes that may be of interest for researchers are:
- •quran: Quotes from the Quran.
- •dialogue: Dialogue in plays.
- •forignphrase and foreignphrase wordasword: Non-Arabic script embedded in Arabic script.
- •poetry_container: Poetry.
For example, searching for the quran tag in the corpus yields 10, 687 quotes from the Quran that can be extracted and analyzed in isolation.
The typeset, human readable versions of the books can be accessed from the URL http://www.hindawi.org/books/ followed by the eight-digit book number, or directly downloaded in various formats from the same URL and book number followed by ".pdf", ".epub", or ".kfx".
Metadata
3.3
Metadata for books in the corpus are provided in tab-separated format in the file metadata.tsv. This data file contains data for the following 24 variables:
(* = Only applicable to translated works. Empty string in non-translated works.)
- •booknr: An eight-digit unique number assigned by the publisher, used in the corresponding file name.
- •category: Category (genre) as assigned by the publisher. 213 books in the corpus have two or three labels, in which case these are given as a comma separated list. The category labels are listed in Table 2.
- •category.main: Similar to category, but for books with two or three category labels, the second and third are omitted, leaving only the first and primary category label.
- •title: The Arabic title of the book.
- •origtitle*: The title of the original work.
- •author: The author in Arabic script.
- •origauthor*: The author in the original language.
- •pubdate: Publication date of this edition (yyyy-mm-dd).
- •origpubdate: Date of the original publication (yyyy).
- •origpubdate.full: Similar to origpubdate, but for some books specified as
- -yyyy-yyyy (date range). Represented in orgpubdate by the first year in the rage.
- -unkn: Publication date stated in the work to be unknown. Represented in orgpubdate by "NA".
- -mult: Stated in the work to be originally published on multiple (unspecified) dates. Represented in orgpubdate by "NA".
- •translation: Specifies whether the book is a translation from another language (TRUE/FALSE).
- •transdate*: Translation date, provided for re-publications of existing translations (yyyy).
- •origlang.ar: Arabic name of original language (e.g., "").
- •origlang: English name of original language (e.g., "Arabic").
- •wc: Word count.
Experimental Design, Materials and Methods
4
The data was collected and prepared as follows:
- 1)All 3, 485 books available as of April 4, 2024, were downloaded from the Hindawi website (http://www.hindawi.org) in epub format.
- 2)The ebup files were convert to html with Pandoc (http://www.pandoc.org). The resulting html files were then amended as follows:
- a.The <style>-tag specifying scss styling was removed.
- b.The files were indented for readability.
- c.The initial DOCTYPE declaration was replaced with the following (here broken into three lines for display) in order to be displayable in standard browsers:
- <!DOCTYPE html PUBLIC ``-//W3C//DTD XHTML 1.0
- Transitional//EN''
- “http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd”>
- 3)License information was extracted from the colophon in the html files and manually checked. Books published under non-free licenses were removed, including books where copyright is held by the author, the author's estate, or the publisher of the original publication. The remaining 1,745 books are either in the public domain or are published under CC BY 4.0 (https://creativecommons.org/licenses/by/4.0/).
- 4)Metadata (see above) were extracted from colophons in the corpus files and from the webpage for each book on the publisher's website. These data were extracted through an iterative process whereby a string was searched for to locate the relevant information. Books with no hit were identified and checked for a relevant string, which was then searched for in remaining relevant books, and so on, until all data for all books was located and extracted.For example, data on the original language of translated works were extracted by finding the string (`This book was originally published in [the language]') in the colophons. This identified the original language for most of the translated works. For translated works where this string was not found, an alternative formulation giving this information was identified, which was then used to search in the remaining translated works, and so on, until the original language of all translated works was identified.
- 5)The html files were converted to plain text with Pandoc after removing (a) colophons (the contents of the <div class=“copyright”> tag) and (b) repetitions of the title from the cover, half title, and title page.
Limitations
All texts in the corpus are from one single publisher.
Ethics Statement
The current work does not involve human subjects, animal experiments, or any data collected from social media platforms. The paper complies with the ethical requirements for publication in Data in Brief.
Credit Author Statement
Hallberg is the sole author of this paper.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1A. Hallberg, The Arabic e-book corpus, (2024). 10.5878/7rbh-gy 93. · doi ↗
- 2Buckwalter T.Parkinson D.B.A frequency dictionary of arabic: core vocabulary for learners 2011 Routledge London
- 3Parkinson D.B.Orthographic variation in Modern Standard Arabic: the case of the hamza Perspect. Arabic Linguistics 1990269295
- 4Azmi A.M.Almajed R.S.A survey of automatic Arabic diacritization techniques Nat. Lang. Eng.21201547749510.1017/S 1351324913000284 · doi ↗
- 5Hallberg A.Principles of variation in the use of diacritics (taškı̄l) in Arabic books Lang. Sci.93202211510.1016/j.langsci.2022.101482 · doi ↗
- 6Hallberg A.Variation in the use of diacritics in modern typeset Standard Arabic: a theoretical and descriptive framework Arabica 69202227931710.1163/15700585-12341640 · doi ↗
- 7Biber D.Conrad S.Register, genre, and style Second edition 2019 Cambridge University Press Cambridge, UK
- 8Ali A.R.Siddiqui M.A.Algunaibet R.Ali H.R.A large and diverse Arabic corpus for language modeling Procedia Comput. Sci.2252023122110.1016/j.procs.2023.09.086 · doi ↗