Nat-UV DB: A Natural Products Database Underlying of Veracruz-Mexico
Edgar López-López, Ana Margarita Hernández-Segura, Carlos Lara-Cuellar, Carolina Barrientos-Salcedo, Carlos M. Cerda-García-Rojas, José L. Medina-Franco, Kathia Maria Honorio, David J Newman, Virginia Flores-Morales

TL;DR
Nat-UV DB is a new natural products database from Mexico's coastal zone, offering diverse compounds for drug discovery and other industries.
Contribution
Nat-UV DB is the first natural products database from a Mexican coastal zone, introducing 52 novel scaffolds.
Findings
Nat-UV DB contains 227 compounds with 112 scaffolds, 52 of which are new to natural product databases.
The compounds show higher structural diversity than approved drugs but lower than other natural product databases.
The database complements global natural product resources by representing biodiversity-rich regions.
Abstract
Natural products databases are well-structured data sources that offer new molecular development opportunities in drug discovery, agrochemistry, food, cosmetics, and several other research disciplines or chemical industries. The crescent world’s interest in the development of these databases is related to the exploration of chemical diversity in geographical regions with rich biodiversity. In this work, we introduce and discuss Nat-UV DB, the first natural products database from a coastal zone of Mexico. We discuss its construction, curation, and chemoinformatic characterization of their content, and chemical space coverage compared with other compound databases, like approved drugs, and other Mexican (BIOFACQUIM and UNIIQUIM databases) and the Latin American natural products database (LaNAPDB). Nat-UV DB comprises 227 compounds that contain 112 scaffolds, of which 52 are not present…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
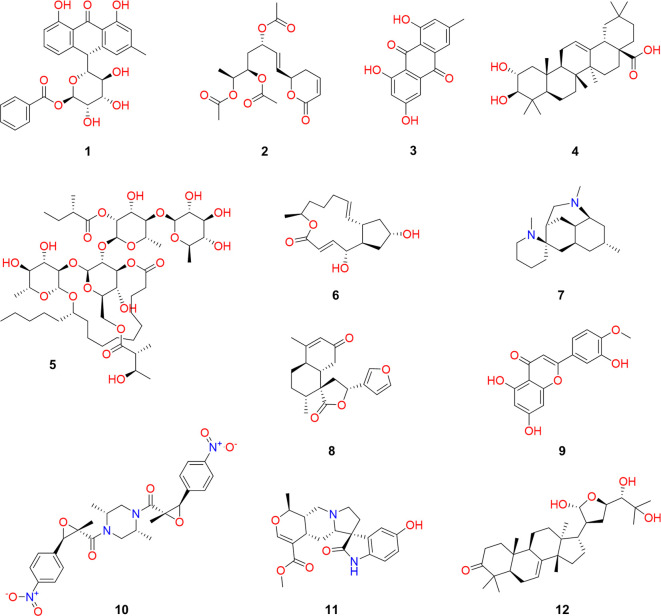 Figure 1
Figure 1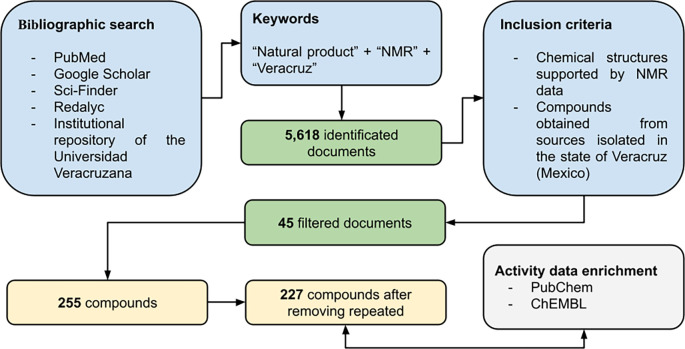 Figure 2
Figure 2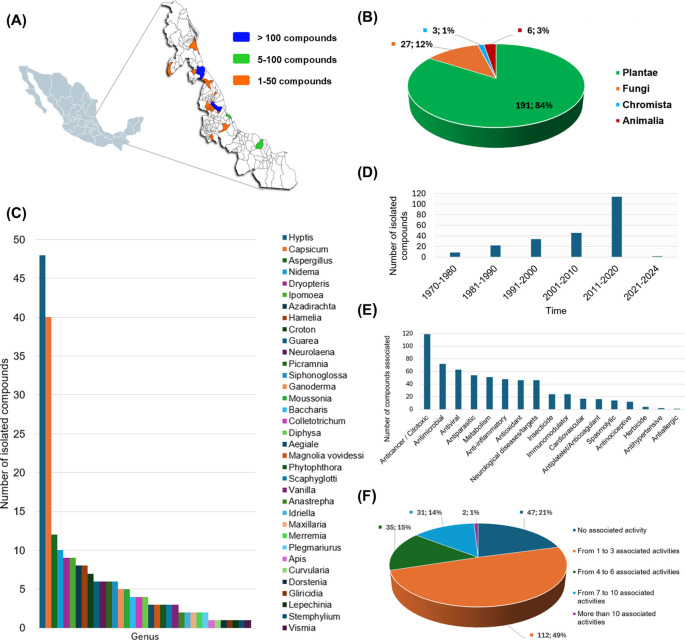 Figure 3
Figure 3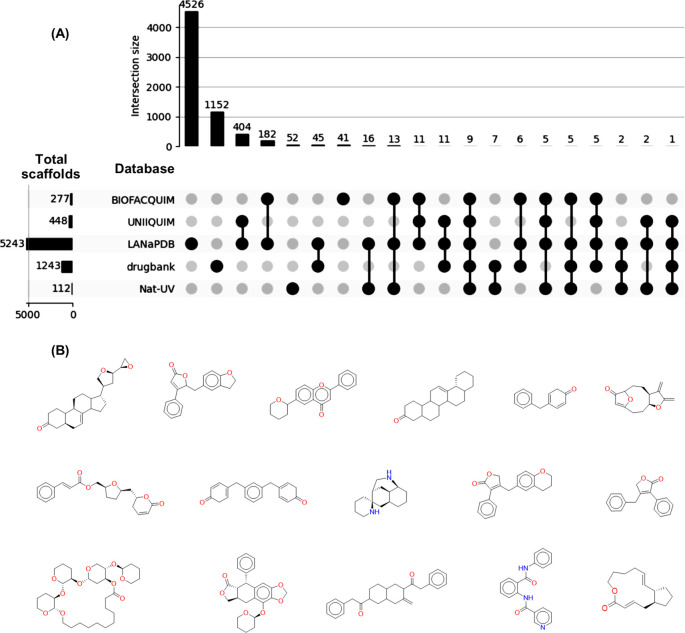 Figure 4
Figure 4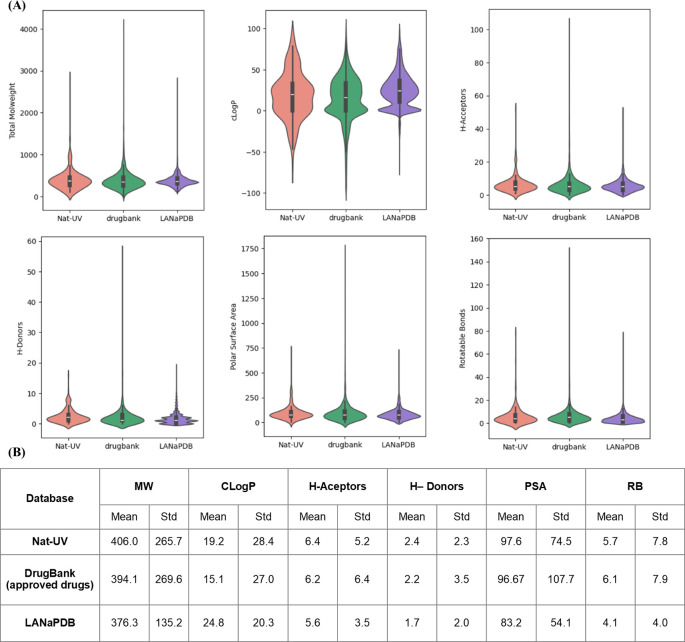 Figure 5
Figure 5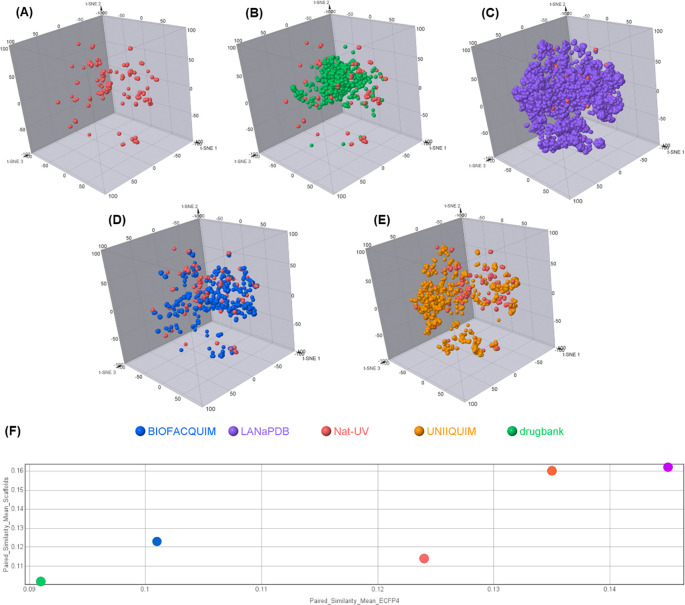 Figure 6
Figure 6| Database | Description | Size
| Reference |
|---|---|---|---|
| Approved drugs (DrugBank v. 2024.0) | Drugs approved for clinical use | 2,144
|
|
| LANaPDB 2.0 | Latinoamerican natural products database with chemicals from Brazil, Colombia, Costa Rica, El Salvador, Mexico, Panama, and Peru | 13,579 |
|
| BIOFACQUIM | Natural products from, Mexico | 531 |
|
| UNIIQUIM | Natural products from, Mexico | 855 |
|
| Nat-UV DB | Natural products from the state of Veracruz (Mexico) | 227 | - |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsComputational Drug Discovery Methods · Microbial Metabolism and Applications · Microbial Natural Products and Biosynthesis
Introduction
Mexico is one of the most biodiverse countries in the world, which has a large list of endemic organisms. ^ 1, 2 ^ At the same time, the state of Veracruz, Mexico, is a coastal region next to the Gulf of Mexico, which has a large diversity in its geographic landscapes and weather, conditions, which have contributed to the increase in biodiversity, and is considered one of the most biodiverse states in the country. ^ 3 ^ It has been reported that the state of Veracruz houses 34% of the total species in Mexico, which highlights the importance of the systematic study of their chemical diversity. ^ 4 ^
Natural products have demonstrated their key role in developing new drugs, materials, nutraceuticals, pesticides, and insecticides, which justify their study. ^ 5, 6 ^ Nowadays it is possible to establish structure-properties relationships using bioinformatics and chemoinformatics methodologies. ^ 7 ^ To achieve this goal, it is necessary to condense, organize, and curate the databases. Recent efforts in Latin America have been developed on the construction of natural products databases that have contributed to the understanding of Latin American traditional medicine, and to accelerate the rational use of natural products in this geographical region. ^ 8 ^ Particularly in Mexico, there are two compound databases ^ 9, 10 ^ that are mainly focused on the natural products identified in the central zone of Mexico. However, there are no reports of databases from the most biodiverse regions in this country.
Figure 1 illustrates representative chemical structures that have been obtained from natural resources collected in the state of Veracruz, which are distinguished by their structural diversity, ^ 11– 21 ^ and their great applicability domain in medicine ( e.g. to develop antimicrobial and anticancer drugs), cosmetology ( e.g. to develop skincare molecules), nutrition ( e.g. to develop nutraceuticals), agriculture ( e.g. to develop biopesticides and insecticides), and many other applications. ^ 22– 25 ^
Representative natural products of the state of Veracruz, Mexico.
In the present scientific context, it is possible to establish highly efficient virtual screening protocols using chemoinformatics methods, natural product databases have covered a worldly interest in the past 20 years. ^ 26, 27 ^ Multiple commercial and open-access natural product databases are available as valuable resources for molecular design. It is expected that databases will continue to grow in number and type. For example, focusing their creation on the organization of data and information on natural products based on their reported biological activity, chemical characterization method, geolocation, natural source, commercial availability, etc. ^ 27 ^ Web applications like COCONUT 2.0 (the COlleCtion of Open NatUral producTs) is an an excellent resource freely available at https://coconut.naturalproducts.net/ to unify and standardize multiple natural product databases, ^ 28 ^ which facilitates the systematic filtering of multipurpose data useful for chemoinformatic and natural products research.
The main objective of this work is to introduce Nat-UV DB, a database of natural products isolated and characterized in the state of Veracruz, Mexico. We also discuss a systematic analysis using chemoinformatics methods, identifying endemic natural products, and studying their chemical diversity.
Methods
Database construction and curation
The database of natural products from the state of Veracruz was assembled from a literature search. For the construction of the first version of NAT-UV DB, PubMed, Google Scholar, Sci-Finder, Redalyc, and the institutional repository of the Universidad Veracruzana (Mexico) databases were searched using the keywords “natural product”, “NMR”, and “Veracruz.” We collected information from research articles, and bachelor, master, and doctorate theses from universities and research centers. To complement the data mining, two additional criteria were used for the final selection of the literature used to construct the database. The first filter was that the elucidation of the reported chemical structures has been supported by nuclear magnetic resonance (NMR). The second one was that the compounds identified were obtained from a natural source from any region in the state of Veracruz (Mexico). The search was generated by publication year from 1970 to June of 2024. We want to emphasize that this is the first version of Nat-UV DB; future versions will have natural products from more years, and more research repositories, to assemble a database representative of the entire biodiversity of the state of Veracruz. For each collected molecule, their isomeric SMILES strings ^ 29 ^ were generated with ChemBioDraw Ultra V.13, maintaining the stereochemistry reported in the primary literature. ^ 30 ^ With the module’Wash’, from the molecular operating environment (MOE) program, version 2024, ^ 31 ^ the database was curated, maintaining without changes the stereochemistry reported of each molecule. This was done to normalize and collect the most relevant information from the molecules. The data curation involved the elimination of salts, the adjustment of the protonation states, and the elimination of the duplicated molecules. The default settings of the ‘Wash’ module were used. The information collected for each identified compound is organized according to the natural origin of its place of collection, like kingdom, genera, species, and geographical collection. Finally, the list of curated compounds was manually cross-referenced to PubChem ^ 32 ^ and ChEMBL v.34 ^ 33 ^ databases, which enabled the annotation of databases with the bioactivities that have been associated with each chemical structure ( Figure 2). For those compounds reported in theses, and which were evaluated in a biological test, the biological activity was also included in the database.
Workflow used to construct the Nat-UV database.
Reference data sets
In order to characterize the chemical diversity of Nat-UV DB and to explore its chemical space coverage, approved drugs ^ 34 ^ and the Latin American natural products compound database (LaNAPDB) ^ 35 ^ were used to compare their chemical structures and properties. The structure files used in this work were taken from open repositories of previously published analyses of natural products databases. ^ 36 ^ The structures of the reference compounds were curated using the same procedure described to prepare Nat-UV DB. Table 1 summarizes Nat-UV DB and the reference databases and the number of compounds. Of note, the reference collections included data sets of natural products, including two from Mexico.
Druglikness profiling
The curated Nat-UV DB database was characterized by calculating six physicochemical properties of pharmaceutical interest, namely: molecular weight (MW), octanol/water partition coefficient (ClogP), topological surface area (TPSA), number of rotatable bonds (RB), number of H-bond donor atoms (HBD), and number of H-bond acceptor atoms (HBA). The statistical analysis was done with the program DataWarrior v.06, ^ 38 ^ by calculating the mean, median, and standard deviation of the calculated properties. Based on these statistics Nat-UV DB was further compared with other databases (LANAPDB, BIOFACQUIM, UNIIQUIM, and approved drugs from DrugBank) ( Table 1). The systematic comparison was generated using the Python programming language. The code is freely available at https://github.com/EdgL2/Nat-UV-DB.
Scaffold content analysis of Nat-UV
DB
The most frequent and unique molecular scaffolds of Nat-UV DB and reference databases ( Table 1) were computed using the scaffold definition of Bemis and Murcko. ^ 39 ^ This analysis was done using Python, the code of which is freely available at https://github.com/EdgL2/Nat-UV-DB.
Visualization of the chemical space
In order to generate a visual representation of the chemical space of Nat-UV DB, the fingerprint ECFP4 (1024 bits) was calculated for each compound ^ 40 ^ and the visualization was done using t-distributed stochastic neighbor embedding (t-SNE). ^ 41 ^ The selection of this visualization method was based on recent studies that support its utility for the systematic study of small and large datasets in terms of neighborhood preservation and visualization capabilities. ^ 42 ^ The ECFP4 fingerprint and the t-SNE coordinates were calculated in KNIME software. The optimization parameters we used in t-SNE were dimensions (3), iterations (10,000), theta (0.3), perplexity (30.0), and number of threats (8), using 28 as the seed number. The interactive visualization was implemented using DataWarrior software, version 06. ^ 43 ^ The KNIME workflow and data generated are freely available in the Software availability section.
Chemical diversity analysis
To compare the chemical diversity of Nat-UV DB with the reference data sets, we employed the consensus diversity (CD) plot which is a simple two-dimensional graph that helps to visualize and compare the diversity of several compound data sets considering multiple representations such as chemical scaffolds, and fingerprint-based diversity. ^ 44 ^ In this study, the CD plot was generated using the median paired similarity (ECFP4-1024 bits)/Tanimoto; x-axis) and the median paired scaffold similarity (Bemis-Murck representations using ECFP4-1014 bits/Tanimoto; y-axis). ^ 44 ^ Both are established and are representative metrics of the scaffold and fingerprint-based diversity. ^ 45 ^ Subsets of the compounds were retrieved from control data sets ( Table 1). The workflow implemented in KNIME software is available in the Software availability section.
Results and discussion
In this section, we present the results of the construction of the Nat-UV database followed by a descriptive analysis of the contained data, and the chemoinformatic characterization in terms of physicochemical properties, scaffold content, chemical space coverage, and consensus chemical diversity.
Nat-UV database
As described in the Methods section, the scientific papers and thesis that complied with the inclusion criteria were selected. Each of the 45 scientific documents selected (1 Doctorate thesis degree; 8 Master thesis degrees; 36 research articles) was analyzed individually to extract manually the chemical structures of each identified natural product. The Nat-UV DB contains information that allows identifying the bibliography precedence of the data. For example: compound name, reference, digital object identifier (DOI), and publication year. Also, it contains data related to the natural source precedence of the data. For example: kingdom, genus, species, and geographical location of the collection of the natural source. Additionally, we added cross-referenced IDs with other databases (e.g. PubChem and ChEMBL). Finally, we manually cross-referenced each compound with their reported bioactivity contained in ChEMBL v. 34.
The current version of Nat-UV DB has 227 compounds collected from different geographical zones of Veracruz ( Figure 3A), mainly isolated by different kinds of gender plants ( Figure 3B). For example, the gender Hyptis, Capsicum, Nidema, Dryopteris, Ipomoea, Azadirachta, Hamelia, Croton, and Guarea are examples of the most frequently studied. Other species from other kingdoms also stand out as Aspergillus, Ganoderma, Colletotrichum, and Aegiale ( Figure 3C). Figure 1D illustrates the distribution of compounds per year reported since 1970 to date. Finally, 79% of the compounds contained in this database have been associated with almost one bioactivity report ( Figure 2E, D) which highlights compounds with anticancer and antimicrobial (antibacterial or antifungal) activities.
Descriptive analysis of the Nat-UV DB.(A) Geographical collection of natural resources studied in this work, and the number of compounds obtained by each region; (B) Quantification of compounds contained in this database by genus; (C) Quantification of compounds contained in this database by specie precedence; (D) Number of isolated compounds by decades; (E) Associated bioactivity for the compounds contained in this database; and (F) Multi-activity landscape of compounds contained in this database.
Molecular scaffolds
From the total number of compounds contained in Nat-UV DB (227 compounds), 112 scaffolds were identified, of which 52 (52/112; 46%) are unique. Namely, Nat-UV DB contains scaffolds (52) that have not been reported previously in other Latin American datasets, and that are not present in the scaffolds collection of approved drugs ( Figure 4A). The most representative unique scaffolds of Nat-UV DB are shown in Figure 4B, highlighting the presence of derivatives of limonoids, butyrolactones, flavones, pentacyclic triterpenes, etc. The full list of unique scaffolds is available in the Data availability section.
Unique scaffold content in Nat-UV DB.(A) Shared scaffolds of Nat-UV DB and reference datasets for natural products (LANaPDB, BIOFACQUIM, and UNIIQUIM) and approved drugs (Drugbank); (B) Representative unique scaffolds contained in Nat-UV DB.
There are previous reports of two Mexican natural products databases ( Table 1), but the BIOFACQUIM database is the unique one associated with collected geographical data. Interestingly, 74 compounds contained in this dataset were collected in the state of Veracruz (Mexico). This explains that 32 (32/112; 28%) scaffolds are shared in both databases ( Figure 4A). Also, 17 (17/112; 15%) scaffolds are shared between Nat-UV DB and UNIIQUIM, while 53 (53/112; 47%) scaffolds are shared between Nat-UV DB and the LaNaPDB. Finally, 24 (24/112; 21%) scaffolds were shared between Nat-UV DB and the approved drugs collection. In other words, Nat-UV DB contains some natural product scaffolds (60/112; 54%) that have been identified previously in Mexico and other Latin American countries or have been used as a drug.
Molecular properties
Figure 5 shows a violin plot of the distribution of the six drug-likeness properties calculated for Nat-UV DB. The distribution of the same properties for the two references used in this work was included in comparing the violin plots. ( Table 1). Intrinsic molecular properties like size, flexibility, and polarity are described by explicit molecular properties like weight (MW), coefficient of octanol/water partition (C LogP), number of H-acceptor and H-donors bonds, polar surface area (PSA), and number of rotatable bonds (RB) ( Figure 5A). Summary statistics are presented at the bottom of the violin plots ( Figure 5B).
Violin plots for the drug-likeness physicochemical properties of Nat-UV DB and reference data sets.(A) The boxes inside of violins enclose data with values within the first and third quartile; (B) Summary statistics are included below each l plot. MW: molecular weight; C logP: octanol/water partition coefficient; H-bond acceptors: number of H-bond acceptor atoms; H-Donors: number of H-bond donor atoms; PSA: polar surface area; RB: number of rotatable bonds.
According to Figure 5 the size (MW, HA, and HB), flexibility (RB), and permeability (PSA) profiling of Nat-UV are comparable with the control datasets. However, the polarity (C LogP) of the compounds contained in Nat-UV DB, LANaPDB, BIOFACQUIM, and UNIIQUIM is higher than the approved drugs, however, the Nat-UV DB exhibited a shorter distribution than each natural products databases. This finding agrees with previous reports indicating that natural products are slightly more hydrophobic than drugs approved for clinical use. ^ 36 ^
Chemical space and diversity analysis
Figure 6 shows a visual representation of the chemical space of Nat-UV DB based on ECFP4 fingerprint using t-SNE. Figure 6(B-E) compares Nat-UV DB with other natural products databases (i.e. LANaPDB, BIOFACQUIM, and UNIIQUIM) and approved drugs. Interestingly, Nat-UV DB shares part of its chemical space with the approved drugs dataset, but Nat-UV DB compounds are more distributed in the three dimensions of the plot, which suggests that have a higher structural diversity than the approved drug dataset. However, LANaPDB (the largest dataset analyzed in this study) has an apparently higher structural diversity than the other studied datasets. To quantify the diversity of each dataset, the calculation of structural diversity and scaffold diversity were done ( Figure 6F). To quantify the diversity of each dataset, we calculated the mean of the paired similarity of the structures (x-axis) and scaffolds (y-axis) based on the similarity of each pair of compounds in the dataset using ECFP4 fingerprint and Tanimoto coefficient, where the higher values confirm a higher structural or scaffold diversity of the dataset. These results showed that Nat-UV DB has a higher structural and scaffold diversity than the approved drugs. However, it has low structural and scaffold diversity in contrast with UNIIQUIM and LANaPDB. Finally, Nat-UV DB shows a higher structural diversity than BIOFACQUIM, but a lower scaffold diversity than this one.
Visual representation of the chemical space coverage of Nat-UV DB and reference datasets based on ECFP4 and t-SNE as a visualization method.(A) Nat-UV DB; (B) Nat-UV DB and Drugbank (approved drugs); (C) Nat-UV DB and LANaPDB; (D) Nat-UV DB and BIOFACQUIM; (E) Nat-UV DB and UNIIQUIM; and (F) Consensus diversity plot of Nat-UV DB and the four reference datasets.
Conclusions
Nat-UV DB is a compound database of natural products from the state of Veracruz in Mexico, which is a coastal zone reported with a large biodiversity. The open-access database contains 227 compounds reported from 1970 to June 2024, which is available at https://github.com/EdgL2/Nat-UV-DB. The compound database contains information of bibliographic resources for each compound, information about the collected species that come from, and cross-referenced bioactivity data. The chemoinformatic characterization and analysis of the coverage and diversity of Nat-UV DB in the chemical space suggest broad coverage, overlapping with regions in the approved drugs chemical space. The analysis also indicated that there are unique compounds in Nat-UV DB concerning other Mexican and Latin American natural products databases. The main perspectives of this work are to use Nat-UV DB to identify active compounds using virtual screening methods and continue to augment the size of Nat-UV DB from the new natural products that would be identified in the state of Veracruz, Mexico.
Ethics and consent
Ethical approval and consent were not required.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Dávila-Aranda P Lira-Saade R Valdés-Reyna J : Endemic species of grasses in Mexico: a phytogeographic approach. Biodivers. Conserv. 2004;13:1101–1121. 10.1023/B:BIOC.0000018147.54695.b 3 · doi ↗
- 2Mapes C Basurto F : Biodiversity and edible plants of Mexico. Lira R Casas A Blancas J , editors. Ethnobotany of Mexico. Ethnobiology. New York, NY: Springer;2016. 10.1007/978-1-4614-6669-7_5 · doi ↗
- 3Peterson AT Egbert SL Sánchez-Cordero V : Geographic analysis of conservation priority: endemic birds and mammals in Veracruz, Mexico. Biol. Conserv. 2000;93:85–94. 10.1016/S 0006-3207(99)00074-9 · doi ↗
- 4SEMARNAT: Informe de la situación del medio ambiente en México. 2015. Accessed 15 November 2024. Reference Source
- 5Chopra B Dhingra AK : Natural products: A lead for drug discovery and development. Phytother. Res. 2021;35:4660–4702. 10.1002/ptr.7099 33847440 · doi ↗ · pubmed ↗
- 6Zhang X Jiang M Niu N : Natural-product-derived carbon dots: From natural products to functional materials. Chem Sus Chem. 2017;11:11–24. 10.1002/cssc.201701847 29072348 · doi ↗ · pubmed ↗
- 7López-López E Medina-Franco JL : Toward structure-multiple activity relationships (SMA Rts) using computational approaches: A polypharmacological perspective. Drug Discov. Today. 2024;29:104046. 10.1016/j.drudis.2024.104046 38810721 · doi ↗ · pubmed ↗
- 8Gómez-García A Medina-Franco JL : Progress and impact of Latin American natural product databases. Biomolecules. 2022;12:1202. 10.3390/biom 12091202 36139041 PMC 9496143 · doi ↗ · pubmed ↗