Content-based image retrieval assists radiologists in diagnosing eye and orbital mass lesions in MRI
Josef Lorenz Rumberger, Winna Lim, Benjamin Wildfeuer, Elisa Birgit Sodemann, Augustin Lecler, Simon Stemplinger, Ahi Sema Issever, Ali Sepahdari, Sönke Langner, Dagmar Kainmueller, Bernd Hamm, Katharina Erb-Eigner

TL;DR
A machine learning-based image retrieval tool helps radiologists diagnose eye and orbital issues more accurately and quickly using MRI scans.
Contribution
A CBIR tool combined with a curated MRI database improves diagnostic accuracy and reduces reading time for eye and orbital mass lesions.
Findings
CBIR tool alone increased diagnostic accuracy from 55.88% to 70.59%.
CBIR with status quo tools increased accuracy to 83.33%.
CBIR alone reduced reading time by 98 seconds per case.
Abstract
Diagnosing eye and orbit pathologies through radiological imaging presents considerable challenges due to their low prevalence, the extensive range of possible conditions, and their variable presentations, necessitating substantial domain-specific expertise. This study evaluates whether a ML-based content-based image retrieval (CBIR) tool, combined with a curated database of orbital MRI cases with verified diagnoses, can enhance diagnostic accuracy and reduce reading time for radiologists diagnosing eye and orbital pathologies. It explores whether this tool alone, or in combination with status quo reference tools (e.g. Radiopaedia.org, StatDx) provides these benefits. In a multi-reader, multi-case study involving 36 radiologists and 48 retrospective orbital MRI cases, participants diagnosed eight cases: four using status quo reference tools and four with the addition of the CBIR tool.…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
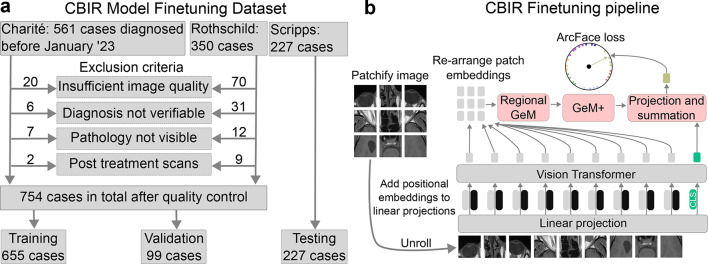 Figure 1
Figure 1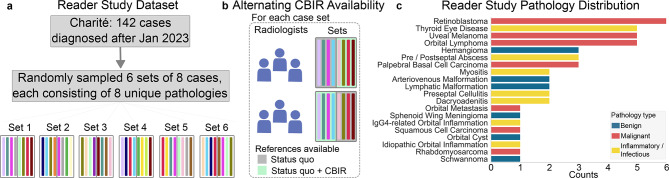 Figure 2
Figure 2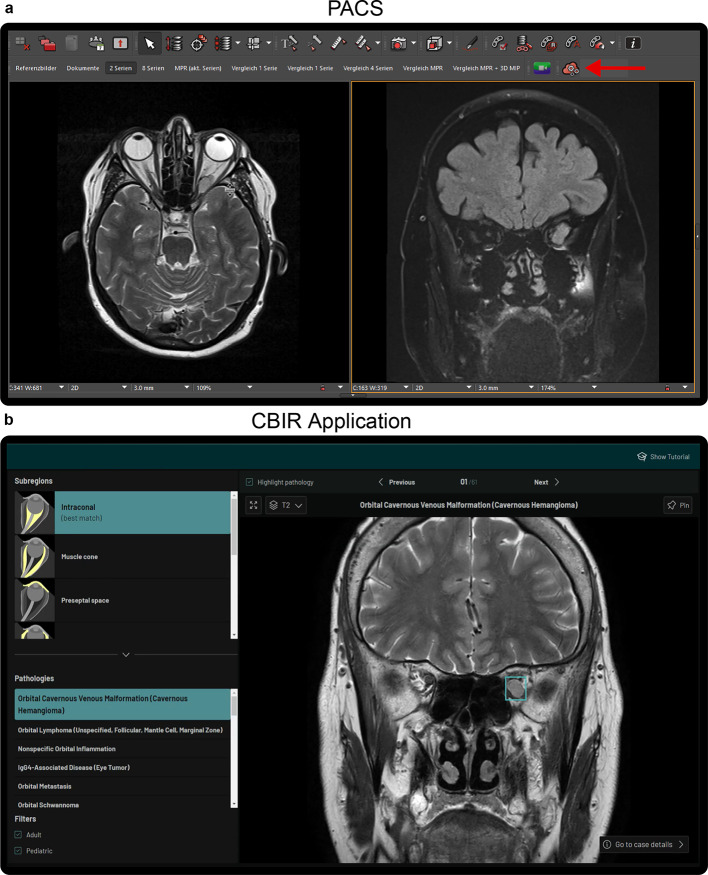 Figure 3
Figure 3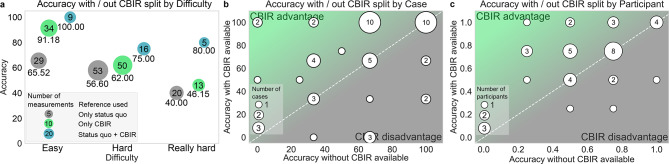 Figure 4
Figure 4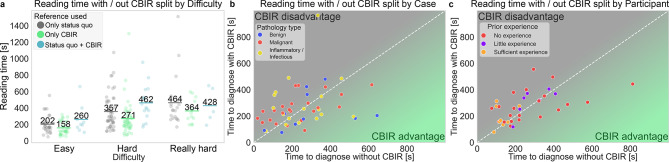 Figure 5
Figure 5- —Charité - Universitätsmedizin Berlin (3093)
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsRadiology practices and education · Radiomics and Machine Learning in Medical Imaging · Artificial Intelligence in Healthcare and Education
Introduction
Inaccurate diagnoses in medical imaging reports are a burden to the patient and the healthcare system^1^. Reading MRI scans of patients with eye and orbit diseases poses a particular diagnostic challenge due to the rarity of these lesions. Most radiologists lack profound experience reading these cases or they may find it difficult to recall imaging features from past cases. Radiologists specialized in the eye and orbit area are also rare, thus these cases are often read by general radiologists or neuroradiologists, increasing the probability for diagnostic inaccuracies. Additionally, the high number of distinctive tissue types in the orbit enables a variety of orbital pathologies, increasing the number of possible differential diagnoses to consider.
Although large, multi-center studies describing the diagnostic accuracy of eye and orbital lesions are lacking, it has been reported for lacrimal gland lesions that the degree of correspondence between image-based diagnosis and histopathologic diagnosis is only moderate (Cohen’s kappa = 0.451, p < 0.001)^2^. Other studies found that diagnostic errors occur at an average rate of 3–4%, with a 32% retrospective error rate for interpretation of abnormal studies^3^. These challenges may delay diagnosis and treatment or expose patients to potentially unnecessary biopsies and treatments, which can cause harm and be costly^1^.
Content-based image retrieval (CBIR) methods retrieve similar images from a database based on a query image, by comparing visual features like color, texture, and shape, rather than metadata or text^4^. In the context of Radiology, CBIR systems allow radiologists to retrieve relevant cases from a curated database with clinical or histopathological validation, based on visual similarity with supplied patient query images. Given the cases and their associated diagnoses retrieved by the CBIR system, radiologists may be able to give better informed and more accurate diagnoses. Previous studies on CBIR showed increases in diagnostic accuracy, particularly for diagnosing interstitial lung diseases on CT scans^5–8^. However, these studies often did not compare CBIR with status quo reference tools (e.g. StatDx, radiopaedia.org, etc.)^7,8^, and involved a small number of participants, albeit many cases per participants. Notably absent is research on CBIR’s effectiveness in challenging MRI diagnoses and other organ systems where retrieval of reference cases can be crucial and time consuming.
Thus, our study seeks to close this gap by evaluating whether a CBIR system can improve diagnostic accuracy and reading time for diagnosing challenging eye and orbital pathologies. We developed an ML-based CBIR tool and conducted a retrospective study involving 36 radiologists and 48 orbital MRI cases to assess its effectiveness across a wide range of experience levels and orbital pathologies.
Methods
Ethics statement
This retrospective study was approved by the institutional review board of Charité University Medicine under ethics application code EA121422. The study was conducted in strict accordance with relevant guidelines and regulations. Written consent was obtained from radiologists participating in the study, informed consent from patients was waived due to the retrospective character of the study. All data were completely anonymized before inclusion.
Orbital pathologies datasets
For developing the CBIR machine learning (ML) model and the database, we collected anonymized data from patients with eye and orbit pathologies who were diagnosed between 2012 and 2022 at Charité University Medicine, Hôpital Fondation Rothschild, and Scripps Hospital La Jolla (Fig. 1a). The inclusion criteria required clinical or histopathological confirmation of the diagnosis verified through multidisciplinary clinical assessments, visible lesions on the respective MRI scans, scans performed prior to any therapeutic treatment, and sufficient image quality. For the ML model development, 3D regions of interest (ROIs) were annotated as bounding boxes around each lesion by three expert radiologists in a consecutive non-blinded manner. For annotation and review of the dataset we build tailormade data annotation software (based on Ruby-on-rails and the OHIF DICOM viewer). The following routinely acquired MRI sequences were annotated: T1-weighted spin echo sequences before and after intravenous contrast agent administration, T2-weighted sequences with and without fat suppression, and Fluid-Attenuated Inversion Recovery sequences. Sequences were acquired with a range of different scanners: Siemens (Skyra, Aera, Avanto, Magnetom Amira, Vida), Philips (Ingenia, Intera, Symphony), Toshiba (Titan) and GE (Optima, Signa). Field strength varied between 1.5 T and 3 T depending on the scanner. Data from Charité University Medicine and Hôpital Fondation Rothschild was split into training and validation cases, with the validation dataset being constructed by taking 10% of cases of each pathology to ensure a representative sample. The Scripps dataset was used as an external test dataset.Fig. 1. Dataset composition and finetuning. (a) for the CBIR model we gathered data from 3 sources and excluded cases based on a range of quality control measures. (b), we used the training dataset to finetune a vision transformer with class token (CLS), Regional Generalized Mean (GeM) Pooling and GeM pooling with manual hyperparameter tuning (GeM +) for image retrieval, by optimizing the ArcFace loss.
For the reader study, data with similar characteristics, but diagnosed after January 2023 were collected at Charité University Medicine. The dataset included 142 cases, spanning 28 pathologies which were a subset of the pathologies present in the training dataset. Six sets of eight cases were randomly sampled for the reader study, such that each set consisted of cases with eight distinct pathologies without repetition (Fig. 2a,b). This sampling procedure resulted in 48 cases spanning 20 different pathologies, with the pathology distribution shown in Fig. 2c. The 48 sampled patients had an average age of 43 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pm$$\end{document} 24 years and 48% were female.Fig. 2. Reader study dataset composition. (a) for the reader study we only used cases from Charité University Medicine, diagnosed after the cases in the finetuning dataset. (b) cases were sampled such that each case set contained 8 distinct diagnoses, and the sets were read by 6 radiologists with alternating CBIR availability. c, the randomly sampled 48 cases span 20 distinct diagnoses of different types.
Content-based image retrieval tool
The CBIR tool is seamlessly integrated into the PACS viewer and accessible to eligible radiologists with one click on a dedicated button in the PACS (Fig. 3a). To use the CBIR tool, users navigate to a sequence slice where the pathology is clearly visible, then click on the button which opens the web application that shows a range of pathologies, sorted by image similarity (Fig. 3b). The user interface enables exploration of several cases across 77 verified eye and orbit pathologies in seven anatomical subregions (preseptal space, globe, optic nerve, intraconal, extra ocular muscles, extraconal, lacrimal gland, subperiosteal space and bony orbit). The CBIR algorithm employs an ML model that compares the uploaded radiology sequence slice with those in the database, ranking them by similarity. The algorithm is based on the DinoV2 self-supervised learning framework^9,10^, whose pre-trained checkpoint was further trained on publicly available radiology datasets^11^ (see Suppl. S3 for details). A head comprising Regional Generalized Mean (Regional GeM) Pooling and GeM + Pooling^12^ was added to extract features from the patch embeddings, which were then combined with CLS token features into a single embedding vector. The model was finetuned on the ArcFace image-retrieval objective^13^ using the CBIR fine-tuning dataset (Fig. 1b). More details on the data pre-processing steps and the model performance are presented in Suppl. S2-S4 and Suppl. Figure 1. The ML model was developed using PyTorch (version 2.3.0) and Python (version 3.10).Fig. 3PACS integrated CBIR application. (a) the PACS viewer environment, with the button starting the CBIR tool highlighted with a red arrow. (b) the CBIR web application with the search results for the slice shown on the right in (a). The pathology is highlighted with a cyan box in (b).
Study population
The study was conducted in March and April 2024 at Charité University Medicine. Eligible for the study were radiologists with experience in reading MRI exams. 36 radiologists were randomly recruited for the study, who covered a representative cross section of the department (Table 1a), working in a range of medical roles (Table 1b), having varying job tenure (Table 1c). Prior experience in reading orbital MRI cases was low (Table 1d), with 28 of 36 participants having either no or only little prior experience.Table 1. Study participant demographics.DemographicShare of participantsa | SexFemale41.67 (15/36)b | Medical roleResident44.44 (16/36)Board-certified27.78 (10/36)Senior27.78 (10/36)c | Tenure0–5 years44.44 (16/36)6–10 years27.78 (10/36)11–15 years11.11 (4/36) > 15 years16.67 (6/36)d | Prior exp. in orbital MRINo exp19.44 (7/36)Little exp58.33 (21/36)Sufficient exp22.22 (8/36)Relative number of participants stratified by sex (a), medical role (b), tenure (c) and prior experience in reading orbital MRIs (d). Fractions of total number of participants in parentheses.
Reader evaluation
In total 36 participants each diagnosed a set of eight cases only based on the MRI scans (Fig. 2a), four with and four without the CBIR tool available. Other status quo reference tools like radiopaedia.org, StatDx or Google were available throughout the study. Half of the participants had the CBIR tool available for the first four cases, whereas the other half for the last four cases. Each individual case was read by six randomly selected participants with alternating availability of the CBIR tool (Fig. 2b). Before the participants read cases with the CBIR tool, they went through a short tutorial and were allowed to test the tool by diagnosing a case with a pathology not present in the reader study dataset. In addition, they were allowed to ask questions of the experimenter regarding the CBIR tool. Cases were read on radiology workstations within a standard PACS environment. After each case, the participants were asked to give their diagnosis in free-text form, rate the perceived difficulty, provide their confidence level in the diagnosis, and the reference tools that they used. Confidence levels and difficulty ratings were assessed using a 4-point Likert scale, designed as a forced-choice format without a neutral option to encourage definitive responses. For confidence, participants responded to the statement ‘You are confident that your diagnosis is correct.’ with one of the following options: ‘Strongly agree,’ ‘Somewhat agree,’ ‘Somewhat disagree,’ or ‘Strongly disagree.’ For difficulty ratings, they answered the question ‘How would you assess the difficulty level of this case?’ with one of the following choices: ‘Very difficult,’ ‘Difficult,’ ‘Easy,’ or ‘Very easy.’ A person instructing the participants and taking time measurements was in the room during the session. After the measurements were completed, an eye and orbit radiology specialist with over 15 years of expertise with access to additional clinical information on each case, assessed the diagnoses given by the participants in a fully blinded manner. The evaluation was based on the criterion that the diagnosis was sufficiently correct to ensure the accurate administration of downstream treatment, meaning only clinically significant errors were counted as being incorrect (more details in Suppl. S1). This assessment considers that the classification of orbital lesions can vary among centers and countries, thus diagnostic accuracy should not be judged merely on technical correctness, but on its clinical impact on patient management and outcomes.
Statistical analysis
Prior to commencement of the study, a power analysis was conducted to determine the number of participants required to detect significant effects (defined as p < 0.05) for the endpoints. We reviewed effect sizes from comparable studies and calculated that a sample size of 36 participants and 48 cases, resulting in 288 measurements in total, would allow us to detect effects down to an effect size of Cohen’s D 0.6 at 80% statistical power (more details in Suppl. S7 and Suppl. Figure 2)^14^.
Instead of analyzing if the availability of the CBIR tool had an effect on accuracy and reading times, we focused on the actual reference tools that the participants used for each case, which we measured during the study for each participant and case individually. Therefore, we split reference tool usage into four categories: no reference used, only status quo (only SQ) used, only CBIR used, or both status quo and CBIR used (SQ + CBIR). However, the ‘no reference used’ category was not further analyzed in direct comparison to cases where reference tools were used, as participants refrained from using references only when they immediately and confidently recognized the diagnosis. This introduces a strong selection effect, rendering direct comparisons with tool-assisted observations inappropriate (see Suppl. S6 and Suppl. Table 3 for details). We analyzed the effect of the CBIR tool on diagnostic accuracy using a logistic mixed effects model, treating individual participants and cases as random effects, and including reference usage, medical roles, tenure, and interaction terms as fixed effects. For analyzing the effect of the CBIR tool on reading times, we employed a linear mixed effects model with the same random and fixed effects. Reading times were log-transformed, to meet the distributional assumption of the model. We excluded fixed effects via a backwards elimination process based on the Akaike information criterion^15,16^. The residuals of the mixed effects models were examined to check if all assumptions were met in accordance with the approach published by Singer et al.^17^. Reported P values are based on two-sided Student’s t tests for generalized mixed effects models. Statistical analysis and data visualization were performed using R (version 4.3.3) and Python (version 3.10).
Results
Participants spent on average (± standard deviation) 01 h:03 m:57 s \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pm$$\end{document} 35 m:31 s in total on the tutorial, reading the cases and providing the measurements. When not accounting for the reference tools that the participants actually used but only for the ones that were available in the respective study phase, reading times stayed approximately constant (no CBIR 260 s, CBIR 257 s p = 0.09, N = 288), while during the CBIR phase participants used reference tools more often (no CBIR 70.14%, CBIR 92.36%) and had a significantly higher diagnostic accuracy (no CBIR 63.19%, CBIR 73.61% p = 0.049, N = 288) (Table 2a). In addition, having the CBIR tool available slightly increased confidence in the diagnoses (Table 2b). No trend is visible on the perceived difficulty of the cases over the study phases (Table 2c). Without the CBIR tool available, most participants used radiopaedia.org and Google for finding reference cases, whereas with the CBIR tool available, participants used considerably fewer other reference resources (Table 2d). Participants often used only the CBIR tool when it was available and only used additional status quo reference tools in 20.83% of the cases (Table 2e). In the following sections, the impact on the diagnostic accuracy and reading times of using only status quo (only SQ) reference tools, only the CBIR reference tool (only CBIR), and using both in conjunction (SQ + CBIR) are analyzed.Table 2. Summary statistics split by treatment phase.CharacteristicsNo CBIRCBIRa | GeneralReading time [s]260 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pm$$\end{document} 228257 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pm$$\end{document} 193Reading time with reference tool [s]336 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pm$$\end{document} 230272 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pm$$\end{document} 193Reference tool use70.14 (101/144)92.36 (133/144)Accurate diagnoses63.19 (91/144)73.61 (106/144)b | ConfidenceReally low confidence9.03 (13/144)4.17 (6/144)Low confidence17.36 (25/144)18.06 (26/144)Sufficient confidence61.81 (89/144)63.19 (91/144)High confidence11.81 (17/144)14.58 (21/144)c | DifficultyReally easy0.00 (0/144)0.00 (0/144)Easy37.50 (54/144)35.42 (51/144)Hard47.22 (68/144)48.61 (70/144)Really hard14.58 (21/144)12.50 (18/144)Not stated0.07 (1/144)3.47 (5/144)d | Reference tools used by participantsCBIR tool0.00 (0/144)91.67 (132/144)Radiopaedia59.72 (86/144)18.06 (26/144)Google38.19 (55/144)10.42 (15/144)StatDx9.03 (13/144)1.39 (2/144)Pubmed6.94 (10/144)0.00 (0/144)Others2.08 (3/144)0.69 (1/144)e | Reference categoriesNo reference used29.86 (43/144)7.64 (11/144)Only SQ70.14 (101/144)0.69 (1/144)Only CBIR0.00 (0/144)70.83 (102/144)SQ + CBIR0.00 (0/144)20.83 (30/144)Unless otherwise stated, data is presented as percentages relative to the total number of measurements. Fractions of total number of measurements in parenthesis. Participants were allowed to use multiple reference tools, so the relative numbers in d add up to more than 100%
Impact of CBIR usage on diagnostic accuracy
Diagnostic accuracy significantly improved overall from 55.88% with status quo reference tools only, to 70.59% when using the CBIR tool only (odds ratio = 2.07, p = 0.03) and to 83.33% when using the CBIR tool in conjunction with status quo tools (odds ratio = 3.65, p = 0.02, Suppl. Table 1), which constitutes a 26.32% and a 49.12% relative improvement over the status quo (Table 3f).Table 3. Diagnostic accuracy with/out CBIR.CharacteristicsOnly SQOnly CBIRP valueSQ + CBIRP valuea | DifficultyEasy65.52 (19/29)91.18 (31/34)0.02100.00 (9/9)0.99Hard56.60 (30/53)62.00 (31/50)0.4775.00 (12/16)0.23Really hard40.00 (8/20)46.15 (6/13)0.8680.00 (4/5)0.13b | Pathology typeInfl. & Infect55.56 (20/36)77.78 (28/36)0.05581.82 (9/11)0.11Benign43.48 (10/23)44.44 (8/18)0.9383.33 (5/6)0.12Malignant62.79 (27/43)75.00 (36/48)0.2284.62 (11/13)0.23c | Medical roleResident62.26 (33/53)79.49 (31/39)0.0980.95 (17/21)0.11Board-certified59.09 (13/22)53.13 (17/32)0.6275.00 (3/4)0.62Senior40.74 (11/27)77.42 (24/31)0.01100.00 (5/5)0.99d | Prior experienceNo exp52.00 (13/25)77.27 (17/22)0.10100.00 (6/6)0.11Little exp57.38 (35/61)69.81 (37/53)0.1579.17 (19/24)0.058Sufficient exp56.25 (9/16)66.67 (18/27)0.79-e | Tenure0–5 years62.26 (33/53)79.49 (31/39)0.1080.95 (17/21)0.116–10 years41.67 (10/24)61.76 (21/34)0.15100.00 (4/4)0.9011–15 years55.56 (5/9)50.00 (6/12)0.64- > 15 years56.25 (9/16)82.35 (14/17)0.1680.00 (4/5)0.44f | OverallAll55.88 (57/102)70.59 (72/102)0.0383.33 (25/30)0.02Statistics of diagnostic accuracy in percent are shown for measurements where only status quo reference tools were used (Only SQ), where only the CBIR tool was used (Only CBIR) and where both were used (SQ + CBIR). Total numbers as fractions in parentheses. P values indicate significant differences to reference level ‘Only status quo’ and were calculated using logistic mixed effects models with individual readers and patients as random effects. All models were estimated with the full dataset, consisting of 288 measurements in total.
At the case level, accuracy increased on average with CBIR usage in 21 cases, stayed constant for 18 cases and decreased for 9 cases (Fig. 4b cases above, on and below the isoline). For three cases, diagnostic accuracy declined considerably with the CBIR tool available (from 66.66% without CBIR to 0% with CBIR), which we discuss in more detail in Suppl. S5. Accuracy declined with increased perceived difficulty independent of reference tool use, but using the CBIR tool retained a higher accuracy across increasing difficulty levels (Fig. 4a, Table 3a, Suppl. Figure 3a,b). Most cases within a pathology were consistently rated with similar difficulty ratings by study participants across experience levels (Suppl. Figure 3b,c), with the highest difficulty ratings given to arteriovenous malformations, orbital cysts, metastases and schwannomas. Difficulty ratings were relatively consistent across study participants of different prior experience levels (Suppl. Figure 3b). We found an increase in diagnostic accuracy from 65.52% with status quo tools only, to 91.18% with the CBIR tool only, a 39% relative increase (p = 0.02) for ‘easy’ cases. For ‘hard’ and ‘really hard’ cases, we found similar positive trends (Table 3b). Stratified by pathology type, the highest increase in accuracy was observed for inflammatory and infectious diseases (only SQ 55.56%, only CBIR 77.78% p = 0.055, SQ + CBIR 81.82% p = 0.11), albeit not significant.Fig. 4. Diagnostic Accuracy. (a), diagnostic accuracy averaged over individual cases that readers perceived as easy, hard or really hard. (b,c), diagnostic accuracy with CBIR available (Y-axis) and without CBIR available (X-axis) averaged over individual cases (b) and over individual study participants (c). Dots above the white isoline indicate higher accuracy with the CBIR tool than without and vice versa. Dot-size indicates the number of measurements (a), of cases (b) and participants (c).
At the participant level, diagnostic accuracy increased on average for 15 study participants, stayed constant for 16 and decreased for 5 (cf. Figure 4c, participants above, on and below the isoline). Accuracy of participating senior radiologists improved with the CBIR tool (only SQ 40.74%, only CBIR 77.42% p = 0.01), whereas accuracy of resident and board-certified radiologists showed positive but insignificant trends (Table 3c). Diagnostic accuracy improved the most for participants with no experience (only SQ 52%, only CBIR 77.27% p = 0.10, SQ + CBIR 100% p = 0.11) and those with little experience (only SQ 57.38%, only CBIR 69.81% p = 0.15, SQ + CBIR 79.17% p = 0.058), albeit not significantly (Table 3d). Accuracy showed a positive trend for all tenure levels, except for the 11–15 years tenure level where it showed a slightly decreasing trend (only SQ 55.56%, only CBIR 50% p = 0.64, Table 3e).
Impact of CBIR usage on reading time
Reading time decreased by 29% when using only the CBIR tool compared to only status quo tools (only SQ 334 s, only CBIR 236 s p < 0.001). In contrast, reading time increased by 19% when using CBIR in conjunction with status quo tools (only SQ 334 s, SQ + CBIR 396 s p < 0.001, Table 4f and Suppl. Table 2).Table 4. Reading time with / without CBIR.CharacteristicsOnly SQOnly CBIRP valueSQ + CBIRP valuea | DifficultyEasy202 ± 113158 ± 780.14260 ± 1730.01Hard357 ± 206271 ± 1980.002462 ± 2120.03Really hard464 ± 317364 ± 1440.41428 ± 2150.94b | Pathology typeInfl. & Infect338 ± 201226 ± 1120.005389 ± 2420.10Benign363 ± 240335 ± 3040.40476 ± 2780.34Malignant314 ± 250207 ± 126 < 0.001365 ± 1630.045c | Medical roleResident417 ± 278276 ± 232 < 0.001441 ± 2230.046Board-certified208 ± 96228 ± 1360.34205 ± 640.79Senior273 ± 112195 ± 900.08360 ± 1880.58d | Prior experienceNo exp313 ± 160288 ± 1810.75393 ± 1400.19Little exp377 ± 263236 ± 186 < 0.001397 ± 2320.054Sufficient exp204 ± 113194 ± 1220.50-e | Tenure0–5 years417 ± 278276 ± 232 < 0.001441 ± 2230.0496–10 years237 ± 104210 ± 1260.58408 ± 1790.2911–15 years187 ± 89250 ± 1330.32- > 15 years286 ± 114188 ± 740.17198 ± 570.73f | OverallAll334 ± 230236 ± 172 < 0.001396 ± 215 < 0.001*Statistics of reading time averages ± standard deviations in seconds are shown for measurements where only status quo reference tools were used (Only SQ), where only the CBIR tool was used (Only CBIR) and where both were used (SQ + CBIR). P values indicate significant differences to reference level ‘Only status quo’ and were calculated using linear mixed effects models with individual readers and patients as random effects. All models were estimated with the full dataset, consisting of 288 measurements in total.
At the case level, reading time decreased when using only the CBIR tool and increased when using it together with SQ tools, for hard cases (only SQ 357 s, only CBIR 271 s p = 0.002, SQ + CBIR 462 s p = 0.03, Fig. 5a, Table 4a). In addition, we found evidence for a similar effect for malignant lesions (only SQ 314 s, only CBIR 207 s p < 0.001, SQ + CBIR 365 s p = 0.045) and a decrease in reading times for inflammatory and infectious lesions when using only the CBIR tool (only SQ 338 s, only CBIR 226 s p = 0.005, Fig. 5b, Table 4b).Fig. 5. Reading time. (a), reading time split by perceived difficulty and use of the CBIR tool with averages overlayed. (b,c), reading time with CBIR available (Y-axis) and without CBIR available (X-axis) split by cases (b) and study participants (c). Dots below the white isoline indicate a lower reading time with the CBIR tool than without and vice versa, dots on the isoline.
At the participant level, resident radiologists benefited the most from the CBIR tool (only SQ 417 s, only CBIR 276 s p < 0.001, Table 4c). In addition, the decrease in reading time was the strongest for participants with little experience (only SQ 377 s, only CBIR 236 s p < 0.001, Fig. 5c, Table 4d). Reading times among participants of different tenure levels decreased the most for the 0–5 years of tenure group, with a relative decrease of 31% (only SQ 417 s, only CBIR 276 s p < 0.001), while they showed an increase when both CBIR and SQ tools were used together (only SQ 417 s, SQ + CBIR 444 s p = 0.049, Table 4e).
Discussion
Our results indicate a significant positive impact on diagnostic accuracy with high effect sizes when using the CBIR tool for characterizing various orbital lesions. Furthermore, we found evidence for a decrease in reading times when using only the CBIR tool, but an increase in reading time when using CBIR in conjunction with status quo tools.
Our measured diagnostic accuracy of 55.88% with status quo reference tools is comparable to other studies that assessed accuracy for orbital lesions^2,18^. However, our measured status quo accuracy is considerably higher than status quo measurements of most studies that analyzed the effect of CBIR on interstitial lung disease diagnostics in chest CT. There, the reported diagnostic accuracies range between 35%^7^ and 46.1%^5^, except for Pogarell et al.^8^ who reported 30% for novice and 60.7% for resident readers. The positive effect of the CBIR tool on diagnostic accuracy is comparable to the effects reported in Choe et al.^5^ (without CBIR 46.1%, with CBIR 60.9%), but more moderate than the ones reported in other studies^7,8^. In general, the measured diagnostic accuracy in our and other studies might underestimate the true diagnostic accuracy in the clinic, as only limited patient history and no laboratory data, nor reports from other sub-specialties were available to the participants.
The effect of CBIR on reading time is mixed in the literature. Haubold et al. find an increase in reading time by 22% (p < 0.001) which moderates to 7% after readers become more familiar with the software^7^, whereas Röhrich et al. find a decrease by 31.3% (p < 0.001)^6^. In our study we found a significant 29% decrease in reading times when using only the CBIR tool, and a significant 19% increase when SQ + CBIR tools were used for diagnosing eye and orbit mass lesions. Other studies did not analyze whether the CBIR tool was used in conjunction with other tools, thus the two opposing effects could be conflated. However, our study may have overestimated reading times with the CBIR tool, since participants only read four cases having the CBIR tool available, thus they only had limited time to get used to the software and reading times might be lower under routine conditions.
In other studies, participants were required to read 54^6^ or more cases in total^5,7,8^, which allows readers to become more familiar with the software but severely limits the total number of study participants that could be included to 8^5,6^ or less^7,8^. In our study, the low number of cases per participant allowed us to include 36 participants with considerable differences in experience and tenure, which better accounts for the heterogenous effects that AI assistance can have on radiologists^19^. In addition, this and other studies^5,6^ compared CBIR usage with status quo reference tools, whereas others compared CBIR assistance to no assistance at all^7,8^, which may lead to different interpretations of the impact of CBIR tools on outcome variables.
This study has two main limitations. While we included a diverse range of cases and participants, the small sample size still limits the generalizability of our findings. Further studies will expand to a larger and more geographically diverse participant and case pool, ideally involving participants from multiple medical centers, which would provide more robust data and would allow for more granular sub-group analyses. Another concern is the potential for the CBIR tool to negatively influence radiologists by retrieving confusing or irrelevant cases, which was not evaluated. Given that 5 of 36 participants and 9 of 48 cases had lower diagnostic accuracy with the CBIR tool available than without, it is crucial to assess if there exist underlying systematic factors, either radiologist-specific or case-specific, that may lead to this disparate impact. Prior AI research suggests that radiologists’ decisions can be influenced by AI errors and that this effect is more severe for inexperienced radiologists^20^. A similar effect could occur with CBIR if retrieved cases are misinterpreted as strong diagnostic evidence. In contrast, our results suggest that inexperienced radiologists gain the most and have the highest diagnostic accuracy across experience levels when having the CBIR tool available (Table 3d, Suppl. Figure 3a). In addition, we do not find a clear relationship between model retrieval performance scores for individual pathologies and diagnostic accuracy of study participants (Suppl. Figure 3d). Future work should examine how CBIR influences diagnostic reasoning and whether retrieval-based recommendations affect radiologists differently depending on experience levels and retrieval quality. Furthermore, mitigation strategies to reduce the risk of over-reliance of radiologists on CBIR outputs should be assessed. Potential approaches include integrating uncertainty or confidence scores alongside retrieved images to help users gauge retrieval reliability, providing guidelines on how to critically interpret CBIR results, and implementing feature importance heatmaps overlaid on query images to highlight key regions driving similarity scores^21^.
In conclusion, adopting CBIR in routine diagnostic workflows for eye and orbital mass lesions could have a substantial positive impact on radiological decision making and thus patient outcomes. However, more work is needed to assess the benefits of CBIR tools in other organ systems and imaging modalities. We plan to continue developing and refining the CBIR tool, expanding it to other organ systems and testing it in future studies.
Electronic supplementary material
Below is the link to the electronic supplementary material.
Supplementary Material 1
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Oquab, M. et al. Dinov 2: Learning robust visual features without supervision. Preprint at ar Xiv:2304.07193 (2023).
- 2Darcet, T., Oquab, M., Mairal, J. & Bojanowski, P. Vision transformers need registers. ar Xiv:2309.16588 (2023).
- 3Wu, C., Zhang, X., Zhang, Y., Wang, Y. & Xie, W. Towards generalist foundation model for radiology. Preprint at ar Xiv:2308.02463 (2023).
- 4Shao, S. et al. Global features are all you need for image retrieval and reranking. in Proceedings of the IEEE/CVF International Conference on Computer Vision 11036–11046 (2023).
- 5Deng, J., Guo, J., Xue, N. & Zafeiriou, S. Arcface: Additive angular margin loss for deep face recognition. in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition 4690–4699 (2019).
- 6Yu, F. et al. Heterogeneity and predictors of the effects of AI assistance on radiologists. Nat. Med. 1–13 (2024).10.1038/s 41591-024-02850-w PMC 1095747838504016 · doi ↗ · pubmed ↗