Information-theoretic evaluation of covariate distributions models
Niklas Hartung, Aleksandra Khatova

TL;DR
This paper evaluates non-Gaussian models for covariate distributions using information theory, showing their advantages over simpler models in life sciences.
Contribution
A new method for constructing confidence intervals for KL divergence using nearest neighbour estimators and subsampling.
Findings
Non-Gaussian models outperformed Gaussian models in KL divergence across various datasets.
KL divergence estimates were robust to missing data and latent variables.
Copula-based models generalized well, while MICE showed overfitting tendencies.
Abstract
Statistical modelling of covariate distributions allows to generate virtual populations or to impute missing values in a covariate dataset. Covariate distributions typically have non-Gaussian margins and show nonlinear correlation structures, which simple descriptions like multivariate Gaussian distributions fail to represent. Prominent non-Gaussian frameworks for covariate distribution modelling are copula-based models and models based on multiple imputation by chained equations (MICE). While both frameworks have already found applications in the life sciences, a systematic investigation of their goodness-of-fit to the theoretical underlying distribution, indicating strengths and weaknesses under different conditions, is still lacking. To bridge this gap, we thoroughly evaluated covariate distribution models in terms of Kullback–Leibler (KL) divergence, a scale-invariant…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
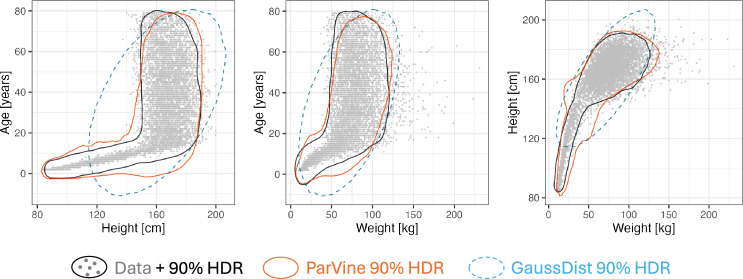 Figure 1
Figure 1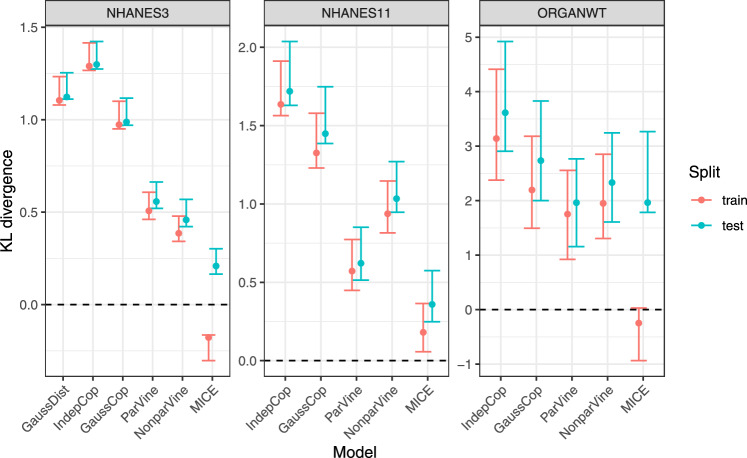 Figure 2
Figure 2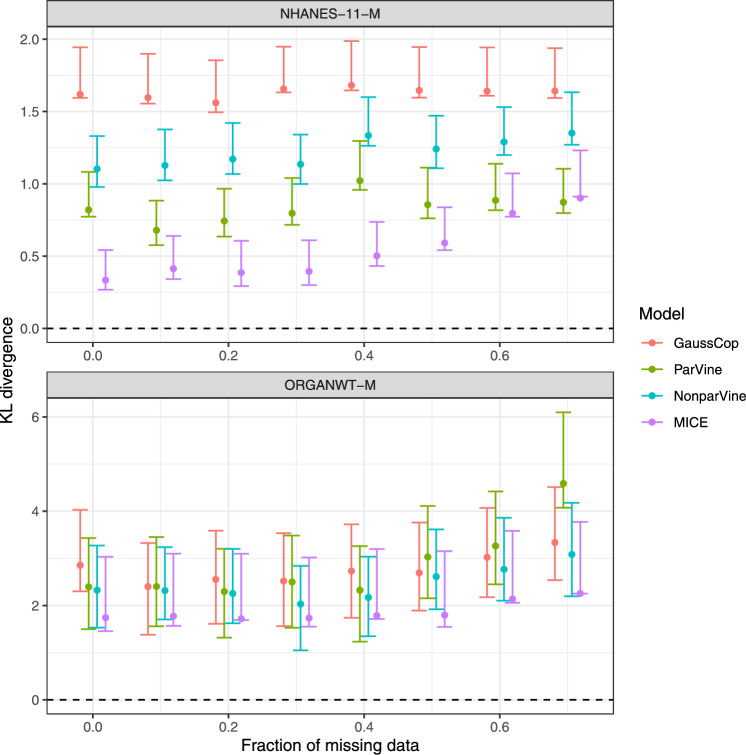 Figure 3
Figure 3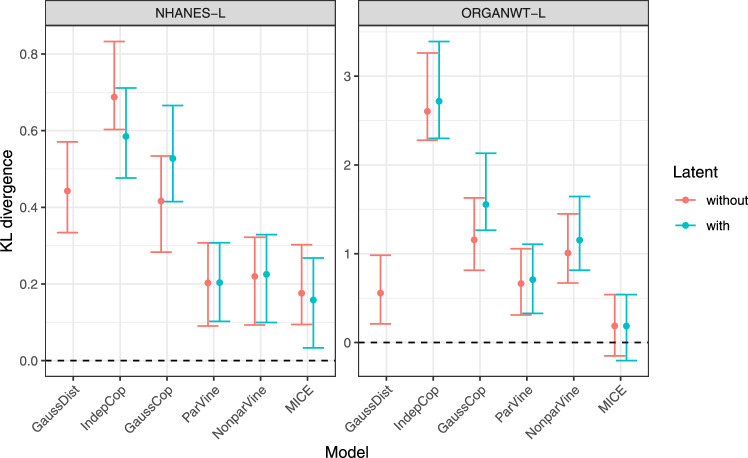 Figure 4
Figure 4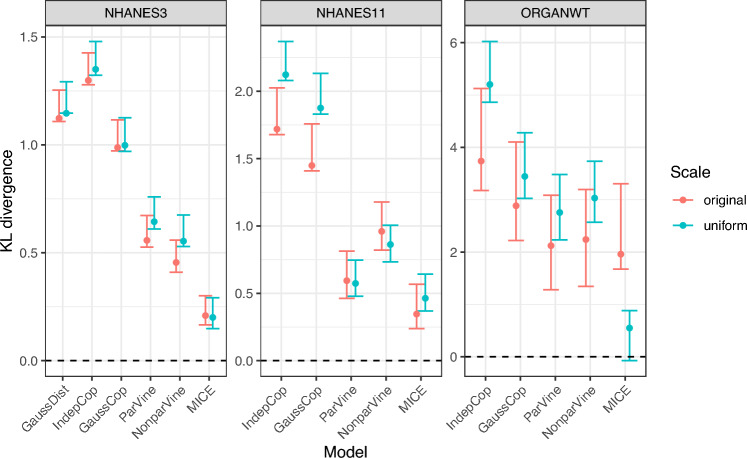 Figure 5
Figure 5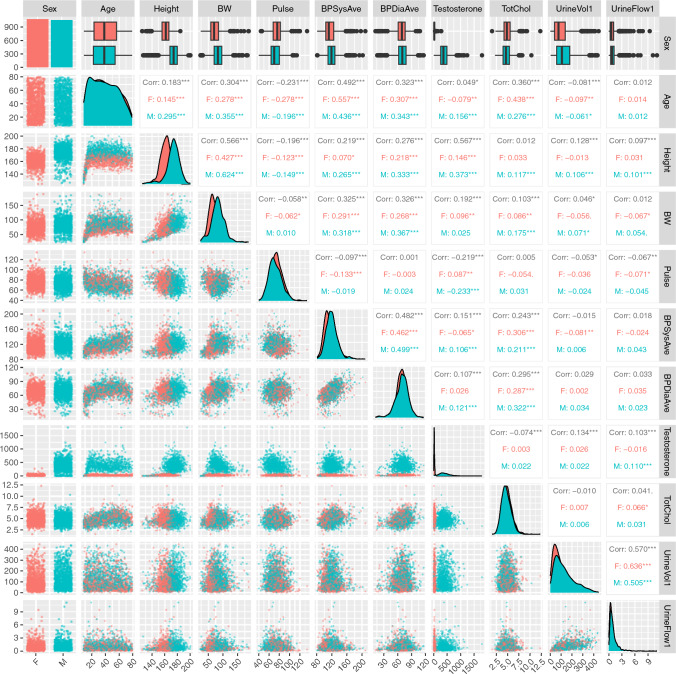 Figure 6
Figure 6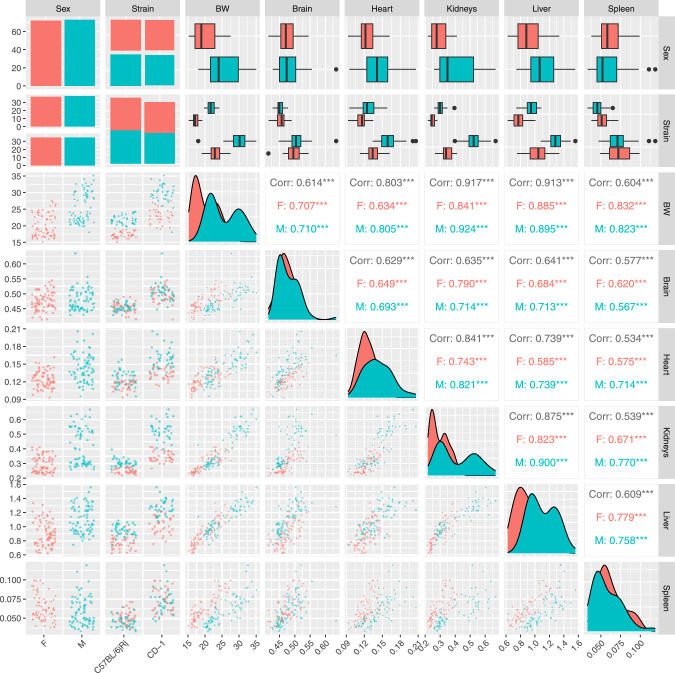 Figure 7
Figure 7- —Universität Potsdam (1031)
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsStatistical Methods and Bayesian Inference · Advanced Statistical Methods and Models · Statistical Distribution Estimation and Applications
Introduction
The impact of covariates on an outcome of interest is of relevance in many modelling exercises. To name a few examples, age, weight, sex as well as biomarkers and genotypic information enter many pharmacokinetic/pharmacodynamic (PK/PD) models [2, 7], and physiologically-based pharmacokinetic (PBPK) models even rely on a large set of organ weights and blood flows [12]. For empirical PK/PD models, a covariate-to-parameter relationship needs to be estimated based on observed data first, which is not necessary for mechanistic PBPK models. Irrespective of the model type, the aim then is to perform simulations evaluating the impact of covariates on outcomes of interest. Often, a set of observed covariates is used for such simulations, but this approach comes with important limitations: (i) Mostly, only summary statistics are shared—other researchers cannot reproduce the results since the information on the correlation structure is lost; (ii) Specific subpopulations may be too sparsely observed for meaningful simulations; (iii) Missing values in a covariate dataset need to be dealt with. In contrast, statistical models for covariate distributions allow to generate virtual populations of arbitrary sizes and can often naturally deal with missing values. Since covariate distributions typically have non-Gaussian margins and show nonlinear correlation structures, simple approaches based on multivariate Gaussian distributions may fail to represent them accurately.
A natural approach to overcome a Gaussian assumption for margins of continuous covariates is to apply a scale transform (e.g., log-transform for intrinsically positive covariates). An effort to include discrete variables into such a lognormal model has been made by [31]. Recently, two non-Gaussian methods, namely Multivariate Imputation by Chained Equations (MICE) and copula-based models, have also been proposed for the simulation of covariate distributions. MICE, an imputation method for missing data [3], has been applied for the simulation of covariate distributions in [29]. Copula modeling, which has a history in financial mathematics, has been introduced to life sciences by [35]. Beyond these data-driven approaches, mechanistic scaling methods have been proposed for some domains like PBPK model parametrization (organ weights/blood flows) [11]. Also, regression models have been developed for some examples, like the distribution of body weight as a function of age and sex [30]. Despite these efforts, multivariate covariate distribution modelling remains the most generally applicable method.
Existing studies have evaluated model performance in terms of univariate or linear measures of association (mean and (co-)variance), which do not discriminate between Gaussian and non-Gaussian models, or by visual inspection [29, 35]. However, a goodness-of-fit metric for the evaluation of covariate distribution models needs to be able to detect any deviation, including non-Gaussian, from the data generating distribution. Kullback–Leibler (KL) divergence fulfils these demands; furthermore it is scale-invariant and can be interpreted well, namely as the information loss when approximating the true population distribution by a surrogate model [14]. Also, typical complicating factors like mixed discrete/continuous data, missing data, latent variables and overfitting have received little attention. We therefore aimed at evaluating goodness-of-fit via KL divergence and in a variety of situations, also covering the above-mentioned issues.
Since in practice, only a sample from the data generating distribution is available, sample-based estimation of KL divergence is required. For high-dimensional continuous data, methods based on nearest neighbour density estimation, combined with a finite sample bias correction, have been found to perform well [21, 33]. However, both the extension to mixed discrete/continuous data as well as uncertainty quantification have not been discussed in the literature. Therefore, a secondary goal of the present work is to extend the available methodology to accommodate mixed data types (a common case in covariate data sets) and to determine confidence intervals for KL divergence estimates (which allows to judge the significance of differences in KL divergence estimates between models/scenarios). An implementation of this approach, combining KL divergence estimators with subsampling-based uncertainty quantification, has recently been distributed as R package kldest [8].
Methods
Datasets
We considered three different datasets that cover both data-rich and -sparse, as a well low- and high-dimensional situations, thereby providing a broad range for the benchmarking covariate distribution models.
- NHANES-3/-11. The US national health and nutrition examination survey (NHANES) contains a collection of demographic, physical, health-related and lifestyle-related variables from a representative sample of the US population [1]. The dataset distributed in R package NHANES contains a resampled version of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$n=$$\end{document} 10,000 individuals from the 2009 to 2012 NHANES survey, to counterbalance oversampling of certain subpopulations [24]. From this dataset, we ignored individuals with age of 80 years or above (for whom exact age is not given) and those with a diastolic blood pressure of 0 (likely a database error). Subsequently, we derived two NHANES analysis datasets by selecting a subset of covariates and removing duplicates and missing values:
- NHANES-3 (data-rich low-dimensional setting). 6230 unique measurements of 3 continuous covariates: age, weight and height.
- NHANES-11 (medium-sparse high-dimensional setting). 2133 unique measurements of 11 covariates, of which 10 are continuous (age, weight, height, heart rate, systolic blood pressure, diastolic blood pressure, testosterone concentrations, total cholesterol, urine volume, urine flow rate) and one is discrete (sex).
- ORGANWT (very sparse high-dimensional setting). A dataset on organ weights of two different mouse strains has been reported by [16]. From this dataset, we selected 6 continuous covariates (body weight and the 5 most relevant organs weights for PBPK modelling [12] that are available in the dataset, namely brain, heart, kidneys, liver, spleen) and 2 discrete variables (sex and strain), totalling 145 measurements of 8 covariates (after removing one animal in which brain weight was missing).
The sizes of the datasets are summarised in Table 1.Table 1. Dimensions of the three datasetsNumber of covariatesNumber of measurementsContinuousDiscreteNHANES-3306230NHANES-111012133ORGANWT62145
General notation and scope
We consider the observed covariates \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{x} = (x^{(1)},...,x^{(n)})$$\end{document} to be an i.i.d. sample from an (unknown) d-dimensional probability distribution with density p and (cumulative) distribution function F. For example, in dataset NHANES-3, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$x^{(i)}=(x^{(i)}_{1},x^{(i)}_{2},x^{(i)}_{3})$$\end{document} is age, weight and height of the i-th observed individual ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$d=3$$\end{document} ). The aim of covariate distribution modelling is to estimate a surrogate model q which approximates p, in order to be able to simulate i.i.d. data \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{y}$$\end{document} from this surrogate model. Alternatively, a method may directly provide such data \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{y}$$\end{document} .
Copula models
Here we give a short introduction to copula modelling for continuous distributions. Since the notation required for a general presentation of theory and estimation (especially for vine copulas) is complex, we refer to [5] for further details. Any multivariate density p can be uniquely decomposed into a product of marginals and their dependency structure (known as Sklar’s theorem),
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} p(x_{1},...,x_{d}) = p_{1}(x_{1})\cdot \ldots \cdot p_{d}(x_{d})\cdot c\big (F_{1}(x_{1}),...,F_{d}(x_{d})\big ), \end{aligned}$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$p_{i}$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$F_{i}$$\end{document} are the i-th marginal density and distribution functions, respectively, and where c is a copula density, supported on the unit cube. This decomposition allows to estimate the marginals and the dependency structure in two separate steps.
First, the marginals are modelled, giving rise to estimated marginal distribution functions \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\hat{F}_{1}, ..., \hat{F}_{d}$$\end{document} . In this step, standard univariate distribution fitting methods can be used. Here, we employed univariate local polynomial kernel density estimators as implemented in R package kde1d [17]. If the margins are regular enough, parametric methods can be used as well.
Next, using the estimated marginals, the covariates are transformed to uniform scale via
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} x \mapsto \hat{u}(x) := \big (\hat{F}_{1}(x_{1}),...,\hat{F}_{d}(x_{d})\big ). \end{aligned}$$\end{document}A copula model can then be estimated on the transformed data \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{u} = \hat{u}(\textbf{x})$$\end{document} . One possible approach consists of using multivariate copula models such as Gaussian copulas. While this approach is conceptually simple, it assumes the same type of dependency across all variables. A more flexible copula modelling approach consists of combining bivariate copula models in a pair copula decomposition of the multivariate copula. These copula models, termed vine copulas, use a graph-theoretical structure (vine) describing the conditional dependency structure of the pair copula decomposition. Modelling with vine copulas is supported by libraries such as rvinecopulib [18], which automatize the selection of both the vine structure and the pair copulas, and allow for efficient simulation.
Multiple imputation by chained equations (MICE)
MICE is, at its origin, a method for imputing missing values in a datasets. Also known as conditional distribution modelling, it aims at predicting a missing value given all other (non-missing) observations. Within MICE, different algorithms are available. We used the defaults in the R implementation in package mice, namely predictive mean matching [15] for continuous variables and logistic regression for categorical variables, for which robust performance has been reported [3]. To use this method for the simulation of covariate distributions, we used the method described in [29]: (i) if missing data are present, a single standard MICE step is used to fill the missing data; (ii) then, all observed covariates are again labeled as missing and drawn in turn according to MICE in order to obtain a sample.
Covariate distribution models
Six different covariate distribution models are considered in this article, which differ in how marginals are modelled, the choice of dependency structure and the use of parametric or nonparametric elements.
- GaussDist. A multivariate Gaussian distribution (with density q) is fitted to the data \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{x}$$\end{document} on original scale. Hence, all marginals are also Gaussian. This method only applies to continuous covariates.
- IndepCop. An independence copula is used for the transformed data \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{u}$$\end{document} . This means that marginals are modelled, but no dependency structure.
- GaussCop. A multivariate Gaussian copula is fitted to the transformed data \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{u}$$\end{document} . This scenario combines GaussDist and IndepCop. It can be considered an optimized version of the “continuous method” by [31], in which the log-transform is replaced by an kernel-based transform.
- ParVine. A vine copula is fitted to the transformed data \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{u}$$\end{document} . For each dependency element within the vine copula structure, the best bivariate copula is selected from a family of parametric copulas.
- NonparVine. A vine copula is fitted to the transformed data \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{u}$$\end{document} . For each dependency element, a nonparametric bivariate copula model is constructed based on a transform kernel approach [19].
- MICE. The MICE method is applied to the entire dataset, as described in [29].
Kullback–Leibler divergence estimation
For ease of notation, we assume here that all considered covariates are continuous. A combined continuous/discrete framework is described in Appendix C. We assume a surrogate model with density q (i.e., a multivariate Gaussian distribution or a copula model) has been estimated from the data \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{x}$$\end{document} . The KL divergence between p and q is then defined as
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} D_\text {KL}(p||q) := \int _{{\mathbb R}^{d}} \log \left( \frac{p(x)}{q(x)}\right) p(x)dx. \end{aligned}$$\end{document}To estimate \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$D_\text {KL}(p||q)$$\end{document} , we used a nearest neighbour density-based method proposed in [33]. In their approach, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$D_\text {KL}(p||q)$$\end{document} is estimated from two samples, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{x}$$\end{document} from p and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{y}$$\end{document} from q. While \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{x}$$\end{document} is already available, a (large) sample \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{y} = (y^{(1)},...,y^{(m)})$$\end{document} is simulated from the surrogate model q. For copula-based models, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{y}$$\end{document} is obtained by transforming a copula sample \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{v}$$\end{document} back to the original scale, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{y} = \hat{u}^{-1}(\textbf{v})$$\end{document} . Working with a second sample \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{y}$$\end{document} rather than directly using the surrogate model density q allowed for the use of a two-sample bias reduction method. Also, it allows a natural comparison to the MICE method, in which a sample \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{y}$$\end{document} is obtained directly without estimating a density first.
The construction of the two-sample bias-reduced nearest-neighbour KL divergence estimator is presented in Appendix A. It is implemented and documented in the R package kldest [8]. A benchmark (for different data dimensions and with uncertainty quantification) demonstrating robust performance of this estimator is presented on the website accompanying the R package kldest [9].
While KL divergence is scale-invariant, KL divergence estimation might differ between data scales. In the main text, all results are shown on the original scale. An investigation of differences between original and uniform scale (where the copula models are fitted) is shown in Fig. 5 (Appendix D).
Uncertainty quantification
Uncertainty quantification of KL divergence estimators has not been addressed in the literature beyond the 1-D discrete case, and in particular, no asymptotic distributions of nearest neighbour-based KL divergence estimators are available. Also, nearest neighbour-based KL divergence estimation cannot deal with samples containing duplicates. This means that standard bootstrapping, which relies on resampling with replacement, cannot be used for uncertainty quantification either. Instead, we opted for using subsampling as described by [22]. A precise definition of the procedure is provided in Appendix B. Briefly, a large number s of subsamples of size \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$b \ll n,m$$\end{document} is drawn without replacement. Subsequently, the distribution of the KL divergence estimator is approximated by the subsample distribution, corrected for differences in sample size. We chose \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$b = n^{2/3}$$\end{document} and large fixed \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$s = 1000$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$m=$$\end{document} 10,000.
Simulation framework
All simulations were performed in R version 4.2.2 [25]. The source code for reproducing the results, including the three datasets, is available on Zenodo [10]. Requiring as input a list of datasets, it is designed to easily generalise to other datasets.
Results
Non-Gaussian methods lead to a considerably better fit
We start by considering dataset NHANES-3. As can be seen in Fig. 1, the three covariates age, weight and height have a non-Gaussian dependency structure, which a parametric vine copula model (ParVine) is able to capture. Importantly, the clear visual improvement in goodness-of-fit of ParVine over GaussDist is not reflected in linear metrics: the mean and (co-)variance of GaussDist coincides with the respective empirical metric in the dataset (e.g., mean age ± SD \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\approx 35.0\pm 21.1$$\end{document} years), while that of ParVine differs somewhat (mean age± SD \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\approx 32.3\pm 21.0$$\end{document} years). In contrast, KL divergence is much lower for ParVine than for GaussDist (see also Table 2), as would be expected from graphics.
Similar non-Gaussian relationships are present in the higher-dimensional datasets NHANES-11 and ORGANWT, see Figs. 6 and 7 (Appendix E). KL divergence estimates for all three datasets are summarized in Table 2. For the large and low-dimensional dataset NHANES-3, MICE performed best, followed by NonparVine and ParVine. In the high-dimensional dataset NHANES-11, MICE still had the best performance, but ParVine was better than NonparVine, showing that the two vine copula-based methods scale quite differently with the dataset dimension. Lastly, in the sparse dataset ORGANWT, ParVine showed better performance than MICE and NonparVine. In all three datasets, the two vine copula-based methods and MICE outperformed the simpler (e.g. Gaussian) approaches.Fig. 1. Scatterplot matrix and 90% highest density regions (HDR), obtained by bivariate kernel density estimation, for dataset NHANES-3 and two fitted covariate distribution models, ParVine and GaussDist
Table 2. Estimated Kullback–Leibler divergence (with 95% CI) for all 6 covariate models and 3 datasetsNHANES-3NHANES-11ORGANWTGaussDist1.12 (1.11–1.25)––IndepCop1.30 (1.27–1.42)1.72 (1.63–2.04)3.62 (2.91–4.92)GaussCop0.99 (0.97–1.12)1.45 (1.39–1.75)2.73 (2.00–3.83)ParVine0.56 (0.52–0.66)0.62 (0.51–0.85) 1.96 (1.16–2.77) NonparVine0.46 (0.42–0.57)1.03 (0.95–1.27)2.33 (1.61–3.24)MICE 0.21 (0.17–0.30)
0.36 (0.25–0.58) 1.96 (1.77–3.27)The lowest KL divergence estimate per dataset is highlighted in bold
MICE, but not copula models, shows overfitting to the data
Due to the flexibility in the shapes that non-Gaussian covariate distribution models can describe, the question naturally arises whether they tend to overfit the data. We investigate this question by splitting the NHANES-3, NHANES-11 and ORGANWT dataset in half at random, fitting models on one half and comparing KL divergence to the fitted (training) vs. the non-fitted (test) data. As shown in Fig. 2, Gaussian and copula-based models have very similar KL divergence estimates on the two data splits. In contrast, the MICE method tends to overfit the data, with much lower KL divergence estimates on the training compared to the test data. To account for this difference in model behaviour, all simulations results shown in this article employ this data split and evaluate KL divergence on the test data only. While Fig. 2 only shows one data split, choosing other splits does not qualitatively change the results. Fig. 2 also illustrates that the estimator can take negative values. In practice, this would be interpreted as 0.Fig. 2. Comparison of KL divergence estimates (with 95% CI) between training and test data, for all considered covariate distribution models and datasets
All models tolerate a moderate degree of missing data
Both the copula framework and MICE can handle missing data, and we investigated the fit to the data for different degrees of missingness. Methods GaussDist and IndepCop were excluded from this analysis since GaussDist would need additional post-processing and IndepCop assumes covariates to be independent, which prohibits useful inference for missing values from the model. Two scenarios were considered:
- NHANES-11-M: datasets with different fractions p of data missing completely at random were simulated. Of note, due to the high dimensionality of this dataset, the fraction of complete observations \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$f_\text {complete} = (1-p)^{11}$$\end{document} quickly decreases with p (e.g., \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$f_\text {complete} < 0.02$$\end{document} for \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$p=0.3$$\end{document} ).
- ORGANWT-M: datasets with complete observations on sex, strain and body weight, but fractions p of missing organ weights are simulated. This corresponds to the common case where some covariates are much easier to measure than others. Subsequently, covariate distribution models were fitted to the incomplete datasets, samples were generated from the estimated covariate distributions and KL divergence estimated to an independent (complete) test dataset. The results of this analysis are depicted in Fig. 3. All investigated methods were able to handle large fractions of missing data, with almost unchanged performance for up to \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$p=0.3$$\end{document} and mostly moderate increases in KL divergence thereafter.Fig. 3. Comparison of KL divergence estimates (with 95% CI) for different fractions of missing data, for copula-based covariate distribution models (excluding IndepVine) and MICE, and two data scenarios
Latent variables do not compromise model performance
The variables included during covariate distribution model development may not all be needed in a given application scenario. Thus, the question naturally arises how fitting a high-dimensional covariate distribution impacts on the fit to a subset of these covariates. To formally address this question, we split a covariate vector x into observed and latent covariates, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$x = (x_{o},x_{l})$$\end{document} , and investigate the KL divergence between the distribution of observed covariates and the joint covariate distribution model, subsequently marginalized over the latent covariates. We considered two scenarios:
- NHANES-L: impact of including all variables in NHANES-11 while only those in NHANES-3 are of interest.
- ORGANWT-L: impact of including body weight, sex and strain as latent variables when the variables of interest are the organ weights. In both scenarios, the inclusion of latent variables only had a minor impact on estimated KL divergence (Fig. 4). Therefore, including additional covariates during development of a covariate model allows to increase its range of applicability without deteriorating model performance.Fig. 4. Impact of latent variables in covariate distribution models on KL divergence estimates (with 95% CI). Since the multivariate Gaussian distribution model (GaussDist) can deal with the observed continuous covariates, but not with the discrete latent variables present in both datasets, the second error bar is missing for model GaussDist
Discussion
In this work, the performance of non-Gaussian covariate distribution models was evaluated systematically by means of KL divergence between the underlying distribution and the estimated covariate distribution model. Non-Gaussian methods showed considerably improved goodness-of-fit over Gaussian ones, and packages are available that greatly facilitate the use of these more advanced methods.
Parametric vine copulas (ParVine) and MICE performed best overall. When deciding between these two approaches, two main points need to be considered. First, MICE generally works better than ParVine in a rich data scenario, while ParVine performs as good as MICE for sparse data. The second aspect concerns data sharing: while parametric model fits can be shared easily (e.g., as a table) without having to disclose original data, MICE always relies on the underlying dataset. Therefore, if a dataset cannot be shared, e.g. for intellectual property reasons, a parametric vine copula model like ParVine still allows for a reproducible analysis and easier adoption by other researchers. The nonparametric vine copula model did not perform as well as one might have expected. While it performed better than ParVine in the low-dimensional and observation-rich dataset NHANES-3, the other nonparametric method, MICE, was even better. Also, increasing dimensionality affected the nonparametric vine copula method much more than the other methods.
All copula-based models and MICE were robust to quite large fractions of missing values and inclusion of latent variables. Therefore, building a high-dimensional and/or sparse dataset for covariate modelling does not invalidate the use of such models on a subset of covariates. Since different PK/PD or PBPK models require different covariates as input and complete observations may be difficult to obtain, this is a desirable feature.
The MICE methodology is quite different to the other (distribution-based) models, which has several implications. First, MICE may produce (generally, a small fraction) of simulated values that are identical to observed sets of covariates since the imputed values are drawn from the set of observed values. In this respect, MICE behaves like a (more refined) bootstrapping procedure. Since nearest neighbour-based KL divergence estimator cannot deal with ties in the data, these were removed from the simulated covariate set. Also, sampling from observed values makes MICE much more prone to overfitting, which needs to be accounted for when comparing different models. Here, this was realized by a training/test data split approach.
KL divergence was chosen as a measure to quantify the information loss in an estimated covariate model compared to the data-generating process. While this measure is frequently used and has good theoretical properties, alternatives do exist. For example, other types of f-divergences, such as Hellinger distance or total variation distance, could be used [26]. An alternative of a different type would be the Wasserstein distance [13], but it is not scale-invariant.
Sample-based KL divergence estimation, including uncertainty quantification and mixed continuous/discrete data, was rendered possible by combining nearest neighbour density estimation with subsampling and a reformulation conditional on the discrete covariates. While this approach extends already existing methods significantly, some caveats do apply. First, the conditional formulation does not scale well with the number of categories and discrete variables. Also, KL divergence estimation by nearest neighbour-based methods cannot deal with ties in the dataset. Such ties could appear at several levels, namely the data itself (which might be resampled for representativity reasons, as the NHANES data), the covariate distribution method (as it may happen in MICE), or resampling-based uncertainty quantification. In this work, all ties were avoided, either by the choice of method (subsampling instead of bootstrapping) or as a post-processing step (for NHANES and MICE). Jittering could be an alternative to this approach, but the jittering strength is another parameter which is expected to have a significant impact. Therefore, this option was not considered in the present work.
While the investigated covariate distribution models cover a broad spectrum of modelling practice, some additional approaches are worth mentioning. First, bootstrapping from the covariate set \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{x}$$\end{document} is often done [32]. Since all samples \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$y^{(i)}$$\end{document} produced this way have an identical counterpart in the dataset \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{x}$$\end{document} , the KL divergence estimator cannot deal with this method – again, jittering would be an option. Although bootstrapping was excluded from our analysis, we did consider MICE, which has many similarities with bootstrapping (and, in addition, can readily deal with missing data). Second, generative machine learning models like diffusion models have been applied with success to the simulation of, e.g., realistic images [4]. In principle, such methods could also be applied to covariate distribution modelling, but since covariate datasets are differently structured (non-spatial) and much more sparse when compared to image data, considerable adjustments would certainly be required for these methods, which were out of scope of this work.
The considered datasets were chosen based on relevancy of the considered covariates. Covariates age, weight, height and sex are among the most commonly used ones in empirical PK models, and are also used as input parameters in physiological scaling methods [11]. The mouse organ weight dataset is of high relevance for PBPK modelling, a context in which a detailed physiology is required. These datasets covered both sparse and rich data scenarios and varying dimensions. Importantly, the training/test data split ensured that the predictive behaviour of covariate distribution models was evaluated, not a mere fit. We expect our results to generalise to other covariate datasets consisting mainly of continuous variables (as is often the case in PK/PD modelling) and with similar context and dimensions as the considered ones. However, since a KL-based evaluation becomes more challenging in the presence of both discrete and continuous covariates, only a limited number of discrete (binary) covariates were considered. Consequently, it is less clear whether the analyses generalise to datasets with many discrete variables or categories.
Furthermore, all covariates were considered static, i.e. time-varying covariates were out of scope. First results on copula modelling for time-varying covariates were given in [35]. Also, the impact of covariate distribution model misspecification on PK/PD or PBPK model predictions was not investigated. While the question is of much relevance and could be investigated in future work, we decided to focus on the covariate distribution model itself, in order to sharpen the focus and not render the presented analysis dependent on another model type (a specific PK/PD or PBPK model). A correctly specified covariate distribution model coupled to a correctly specified PK/PD or PBPK model will then result in predictions accurately reflecting the impact of covariates. In contrast, if the combination of a covariate distribution model type and one specific PK/PD or PBPK model resulted in good predictions for some observable, this would not mean that they are trustworthy when coupling the covariate distribution model to another PK/PD or PBPK model or when predicting other observables.
In summary, our findings demonstrate that non-Gaussian covariate distribution modelling can be successfully applied to realistic life science covariate datasets.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1(2009-2012) Centers for Disease Control and Prevention (CDC). National Center for Health Statistics (NCHS). National Health and Nutrition Examination Survey Questionnaire (or Examination Protocol, or Laboratory Protocol). U.S. Department of Health and Human Services, Centers for Disease Control and Prevention, Hyattsville, MD. https://www.cdc.gov/nchs/nhanes/index.htm
- 2Geyer CJ (2013) 5601 notes: the subsampling bootstrap. https://www.stat.umn.edu/geyer/5601/notes/sub.pdf
- 3Hartung N (2024) kldest: sample-based estimation of Kullback-Leibler divergence, r package version 1.0.0. https://cran.r-project.org/package=kldest
- 4Hartung N (2024) Website for R package kldest. https://niklhart.github.io/kldest/
- 5Hartung N, Khatova A (2024) Supplementary code for article “Information-theoretic evaluation of covariate distributions models”. Zenodo (version 1.0.0). 10.5281/zenodo.1165664310.1007/s 10928-025-09968-5PMC 1195012040148687 · doi ↗ · pubmed ↗
- 6Nagler T, Vatter T (2022) kde 1d: univariate kernel density estimation, r package version 1.0.5. https://CRAN.R-project.org/package=kde 1d
- 7Nagler T, Vatter T (2023) rvinecopulib: high performance algorithms for vine copula modeling, r package version 0.6.3.1.1. https://CRAN.R-project.org/package=rvinecopulib
- 8Noh YK, Sugiyama M, Liu S et al (2014) Bias reduction and metric learning for nearest-neighbor estimation of Kullback-Leibler divergence. In: Kaski S, Corander J (eds) Proceedings of the seventeenth international conference on artificial intelligence and statistics, proceedings of machine learning research, vol 33. PMLR, Reykjavik, Iceland, pp 669–677. https://proceedings.mlr.press/v 33/noh 14.html