HYFF-CB: Hybrid Feature Fusion Visual Model for Cargo Boxes
Juedong Li, Kaifan Yang, Cheng Qiu, Lubin Wang, Yujia Cai, Hailan Wei, Qiang Yu, Peng Huang

TL;DR
This paper introduces HYFF-CB, a new visual model that improves box detection accuracy in trucks for automatic loading and unloading systems.
Contribution
HYFF-CB introduces a hybrid feature fusion model with location attention, fusion-enhanced pyramid, and weighted loss for better box detection.
Findings
HYFF-CB outperforms existing models in detection rate for cargo boxes in complex truck environments.
The model accurately detects box stacking locations and quantities in real time.
It meets the practical requirements of automatic loading and unloading systems with high adaptability.
Abstract
In automatic loading and unloading systems, it is crucial to accurately detect the locations of boxes inside trucks in real time. However, the existing methods for box detection have multiple shortcomings, and can hardly meet the strict requirements of actual production. When the truck environment is complex, the currently common models based on convolutional neural networks show certain limitations in the practical application of box detection. For example, these models fail to effectively handle the size inconsistency and occlusion of boxes, resulting in a decrease in detection accuracy. These problems seriously restrict the performance and reliability of automatic loading and unloading systems, making it impossible to achieve ideal detection accuracy, speed, and adaptability. Therefore, there is an urgent need for a new and more effective box detection method. To this end, this paper…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
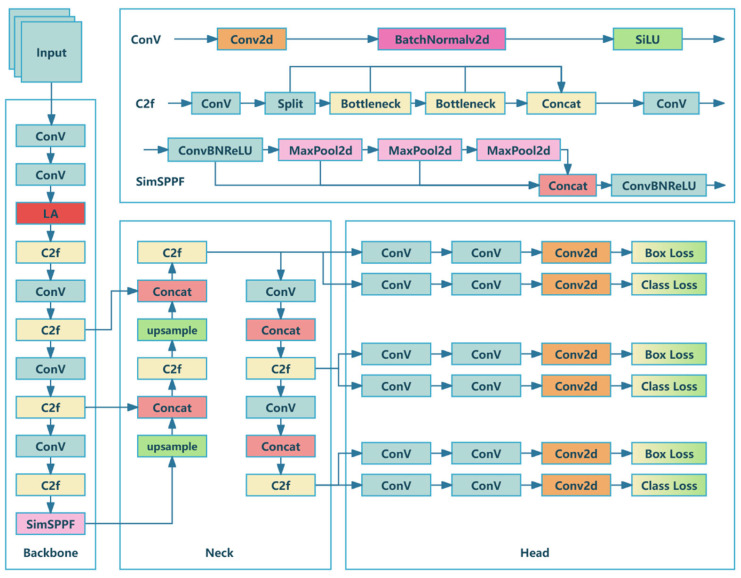 Figure 1
Figure 1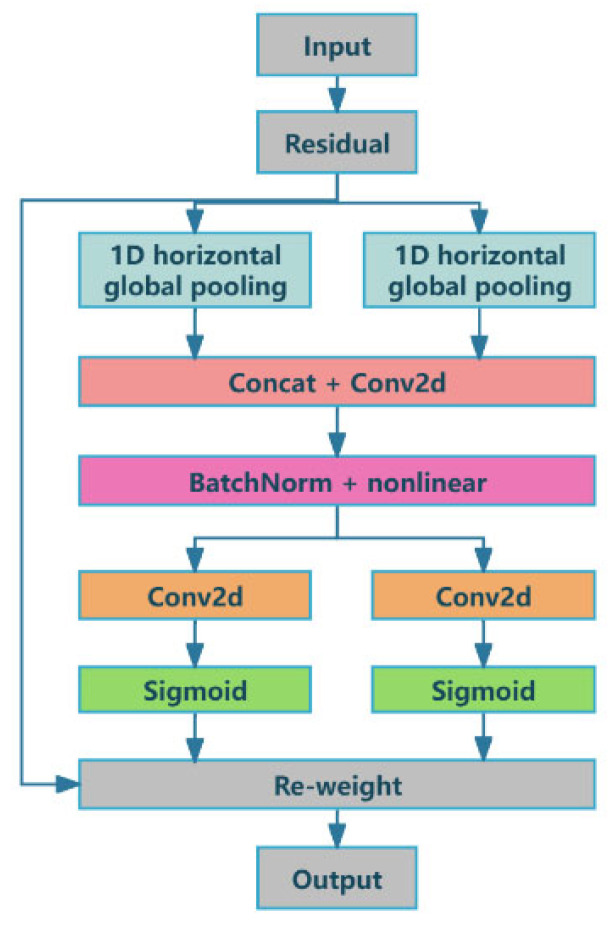 Figure 2
Figure 2 Figure 3
Figure 3 Figure 4
Figure 4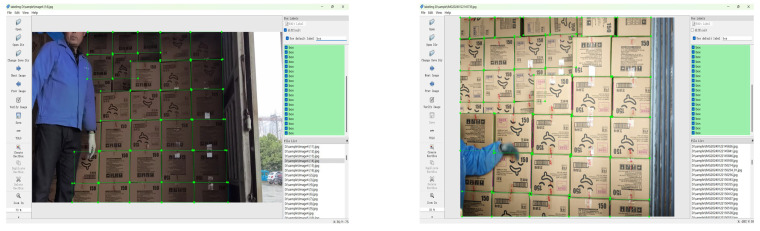 Figure 5
Figure 5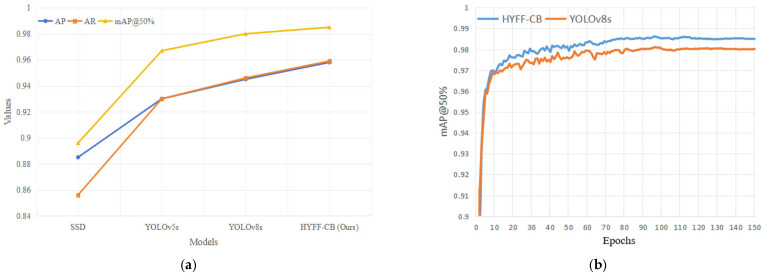 Figure 6
Figure 6 Figure 7
Figure 7- —Guilin Major Special Project
- —Guangxi Science and Technology Base and Talent Special Project
- —Guangxi Key Research and Development Plan
- —Guangxi Key Research and Development Program
- —Scientific Research Project of Guilin Institute of Information Technology
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsVehicle License Plate Recognition · Industrial Vision Systems and Defect Detection · Advanced Neural Network Applications
1. Introduction
In the context of the digital era, the development of Internet technology has significantly promoted the vigorous development of e-commerce, which, in turn, has given rise to the need for the transformation of logistics management into intelligent and efficient logistics. All aspects of the logistics industry, including the receipt, storage, and distribution of goods, require accurate and real-time management based on cost control [1,2]. As key nodes in the logistics process, loading and unloading have a direct impact on the goods turnover rate and warehousing efficiency [3,4,5]. Traditional loading and unloading processes, relying on manual operations, have limitations in efficiency and cost. With the growth of business volume, manual operations are characterized by high cost and increased error rates, affecting the overall logistics efficiency. Therefore, automatic loading and unloading systems have emerged. These systems can automatically complete loading and unloading tasks, including automatically identifying goods, calculating optimal loading solutions, and using automated equipment such as robotic arms for loading and unloading. However, existing automatic systems still face challenges when handling non-standardized goods [6,7].
In the field of modern logistics, the application of image processing and machine vision technologies is becoming increasingly widespread [8,9,10,11]. These technologies optimize the warehouse management process by providing accurate identification and classification of goods. The machine vision system, simulating human vision, captures images with cameras and uses algorithms for image analysis and processing to achieve automatic identification, localization, or classification of goods. The application of this technology has significantly improved the automation level of loading and unloading, reduced dependence on manual operations, and improved operating efficiency and accuracy [12,13,14]. Compared with traditional manual loading and unloading, automatic loading and unloading detection algorithms based on machine vision can achieve all-weather operations and reduce labor intensity and human errors, thereby ensuring the continuity and stability of logistics operations. However, existing cargo box detection methods still have certain limitations in practical applications. For example, when facing situations such as inconsistent cargo box sizes, occlusion, light changes, and complex backgrounds, the detection performance drops significantly. This severely restricts the efficiency and reliability of the automatic loading and unloading system [15,16,17].
In recent years, the successful applications of deep learning algorithms (such as SSD, YOLO, etc.) in the fields of object detection and image recognition have provided powerful technical support for logistics automation systems. By combining convolutional neural networks (CNNs) and feature pyramid networks (FPNs), these algorithms can achieve accurate detection of multi-scale objects, thereby improving the efficiency and reliability of automated loading and unloading systems. In the application of object detection, the YOLO (You Only Look Once) series of algorithms has attracted much attention [18,19,20,21]. The YOLOv8 algorithm, by introducing an improved feature pyramid structure and a dynamic anchor assignment mechanism, has not only improved the detection accuracy of the model, but also significantly enhanced its adaptability to multi-scale objects and complex environments [22,23]. However, when facing the special requirements of cargo box detection in an automatic loading and unloading system, the YOLOv8 algorithm has certain limitations. For example, in terms of the accurate positioning of cargo boxes and the detection of their quantity, YOLOv8 still has room for improvement when dealing with complex occlusions and diverse size distributions.
In order to fill the many gaps existing in the above-mentioned systems or algorithms, solve the problems of cargo box positioning and grasping during loading and unloading, improve logistics efficiency, and reduce warehousing costs, this paper proposes a new cargo box detection model, called HYFF-CB (Hybrid Feature Fusion Visual Model for Cargo Boxes). This model combines key technologies, such as a positioning attention mechanism, a fusion-enhanced pyramid structure, and a synergistic weighted loss system, so as to give full play to the advantages of YOLOv8 in object detection, while making up for its deficiencies in special application scenarios.
2. Research Status
2.1. Automatic Loading and Unloading Technology
In the digital transformation process of the manufacturing and logistics industries, automatic loading and unloading technology is the key to achieving full-process automation. However, this technology is currently stagnated at the early stage of development, due to technical challenges, the diversity of market demands, and insufficient logistics standardization. Against the backdrop of negative population growth in a large number of countries, manual loading and unloading is labor-intensive, enterprises face recruitment difficulties and rising labor costs, and logistics services have a significant impact on online shopping satisfaction [24,25,26]. Therefore, automatic loading and unloading technology has become a point of that weakness in the industry that urgently needs to be overcome. In addition, it has witnessed a surging market demand and has broad application prospects. Its potential market size has reached hundreds of billions to trillions [27,28].
A variety of automation solutions have emerged in the logistics field [29,30]. Among different types of cargo packaging, boxed goods account for about 46% of the automatic loading system market, with the largest demand [29,30]. However, problems such as the diversity of truck models, inconsistent sizes of unloading bins, and irregular stacking inside the truck cause high technical difficulties, which are the focus of this study.
In automatic loading and unloading technology, the truck scanning system is crucial. This system obtains the localization and spatial parameters inside trucks through technologies such as machine vision or LiDAR (Laser Radar), and transmits these parameters to the intelligent loading control system through specified communication protocols. Industrial three-dimensional (3D) cameras and LiDAR have gradually become the standard configurations of automatic loading and unloading systems. When loading and unloading goods of different shapes and sizes in a mixed manner, the existing systems fail to automatically adjust the loading and unloading strategy according to real-time conditions, which may result in low space utilization or inefficient loading and unloading.
2.2. CNN-Based Object Detection Algorithm
In recent years, object detection technology, driven by CNNs (convolutional neural networks), has shown excellent performance in image pattern recognition and classification tasks [31,32,33,34]. Object detection technology mainly uses two-stage and single-stage approaches, among which single-stage approaches are favored for their rapidity and efficiency. M Ju et al. constructed a CNN-based object detector, ISTDet (Infrared Small Target DETection), for infrared small-object detection [35].
Among single-stage object detectors, the SSD (Single Shot MultiBox) detector utilizes CNN’s multi-scale feature maps and predefined bounding boxes to detect objects of different scales [36]. YOLO models have been applied in various fields, such as transportation, biometrics, medical care, and agriculture [37,38,39,40,41,42,43,44,45,46,47,48]. They are also widely used in the object detection of drones and robots [49,50]. JEON-SEONG et al. integrated the generative adversarial network (GAN) and YOLOv5 into an end-to-end structure, and used image enhancement to solve the problem of insufficient lighting inside freight trucks. Their experimental results showed that the image detection for boxes inside freight trucks achieved an accuracy of 91.3% and a recall rate of 82% under poor lighting conditions [51]. Xiang et al. applied YOLOv8 to the automatic docking system for LNG loading arms [52]. Although YOLO models have shown broad application potential in various fields, object detection technology is still in its infancy and lacks mature solutions for loading and unloading scenarios, particularly when dealing with tasks such as box detection in complex environments.
To address this challenge, this study proposes a vision algorithm called HYFF-CB. In order to achieve a reasonable trade-off between computing resources and costs, based on YOLOv8, this algorithm integrates key technologies, such as an LA (localization attention) mechanism, a FEP (fusion-enhanced pyramid) structure, and a SW-Loss (synergistic weighted loss) system. It aims to improve the accuracy and robustness of detection of boxes and other cargo inside trucks. The HYFF-CB algorithm can effectively deal with actual loading and unloading scenarios, such as the diversity of truck models, inconsistent sizes of unloading bins, irregular stacking inside the truck, and complex lighting and weather conditions, thereby meeting the real-time and accuracy requirements of automatic loading and unloading systems for cargo detection. Through these technological innovations, the HYFF-CB algorithm is expected to promote the application of object detection technology in the loading and unloading field and provide new solutions for logistics automation.
3. Methods
By investigating the images of boxes in loading and unloading scenarios, we found various problems concerning the boxes inside trucks, such as relatively small and non-uniform sizes, large quantities, severe occlusion with each other, irregular stacking inside the truck, and many types of SKUs (stock-keeping units). These problems result in poor detection performance and low accuracy of the model. Therefore, to balance the real-time and accuracy requirements of cargo loading and unloading, based on YOLOv8, HYFF-CB incorporates LA into the backbone and adopts SimSPPF [53], with a more simplified structure and faster inference speed, to meet the real-time requirements of the cargo box detection task. In the head, an FEP structure is adopted to fuse the features of objects at different scales. Finally, a SW-Loss system is incorporated to adapt to complex practical scenarios. Through experiments and practical tests, the HYFF-CB can effectively solve the above-mentioned problems and achieve a balance between speed and accuracy. The framework structure of HYFF-CB is shown in Figure 1.
3.1. LA Mechanism
In actual box storage and transportation scenarios, boxes are stacked in complex and diverse ways. They may have different angles, layers, and arrangements. Existing channel attention mechanisms, such as the SE (Squeeze-and-Excitation) module, can improve model performance to some extent. However, they often ignore important location information required to generate spatially selective attention maps while compressing global spatial information. Although spatial attention mechanisms (e.g., GeNet and GcNet) focus on spatial information, their ability to capture global information is relatively weak.
In box detection, however, location information and global information are equally crucial. When boxes are stacked densely, it is impossible to accurately distinguish the boundary locations of each box based solely on location information. If spatial location features are not fully considered, the box locations may be inaccurately detected, or multiple boxes may be misidentified as one. In addition, box detection based solely on local spatial information may cause the model to ignore distant or partially occluded boxes, thereby affecting the completeness and accuracy of detection.
Since existing attention mechanisms cannot deal with the overall planning of location information and global information, the HYFF-CB model introduces an LA mechanism. As shown in Figure 2, the LA mechanism divides the attention process into two one-dimensional (1D) feature encoding processes to collect features along dual spatial dimensions. By capturing spatial information, the LA mechanism improves the precise localization of the regions of interest (boxes) and enables a better understanding of the spatial relationship between different regions in the input image. This allows the model to better distinguish the individual characteristics of each box in the case of complex box stacking, instead of misidentifying a pile of boxes as a whole or missing some of them.
With an innovative dual 1D feature encoding strategy, the LA mechanism significantly improves the performance of cargo detection and effectively overcomes the shortcomings of traditional attention mechanisms. By independently encoding features along two spatial dimensions, the LA mechanism is able to construct an attention map with precise localization awareness, thereby enhancing the model’s ability to represent the objects without increasing any computational burden. During the feature encoding process, the resulting feature map is encoded into an attention map with direction awareness and location awareness, thereby enhancing the ability to represent the objects of interest (boxes) and cleverly avoiding a large amount of computational overhead. The receptive field of the model is increased as well.
This paper assumes that the original feature map is , where denotes the height, denotes the width, and denotes the number of channels. It is encoded along horizontal and vertical dimensions.
First, feature aggregation is performed on each channel in the horizontal direction. The encoding function in the horizontal direction is set as , and then the horizontal feature is obtained. Similarly, feature aggregation is performed on each channel in the vertical direction, to obtain the vertical feature . The outputs of the pooling in two spatial dimensions are concatenated and go through a convolutional layer, as shown in Equation (1):
where denotes the concatenation operation along a spatial dimension; is a nonlinear activation function; and is the reduction rate that controls the block size.
Then, is decomposed into independent tensors. As shown in Equations (2) and (3), two other convolution transforms, i.e., and , are used to transform and , respectively, into the tensors that are consistent with the number of channels in the input .
The number of channels is usually decreased using an appropriate reduction rate to reduce the complexity of the model overhead. After a convolution, the attention weight data are calculated using .
Finally, the input features are multiplied by the weights to generate an LA map that highlights the most informative regions in the input. This attention mechanism effectively captures the spatial relationships between different regions of the input, allowing the network to focus on the most relevant features. Then, the outputs of Equation (4), i.e., and , are expanded and used as attention weights.
At the feature encoding stage, the LA mechanism is designed with a process for encoding feature maps, to generate attention maps that are aware of directions and locations. This process not only enhances the representation of target objects, but also effectively avoids the loss of location information caused by global pooling operations. By decomposing the channel attention into two parallel 1D features, the LA mechanism successfully integrates spatial localization information into the generated channel attention feature vector.
In vision tasks, the capturing of the spatial structure requires preserving the location information of features. Convolution kernels with sizes and are obtained along the horizontal and vertical directions of the input feature map, respectively. These two convolution kernels can be understood as two-dimensional arrays, where and represent the sizes of the kernels along the horizontal and vertical directions, respectively. During the convolution operation, the kernels slide along the two directions of the input feature map and extract features along the two axes to generate the output feature map. Specifically, in the case of input , the two spatial ranges of the pooling kernels and are used to encode the horizontal localization and vertical localization of each channel, respectively. The output of channel can be expressed by Equations (5) and (6):
where and represent the output of channel c at height h and at width w, respectively. This function mapping aggregates features in two spatial directions to form a pair of direction-aware feature mappings. This method improves the precise localization of regions of interest by capturing spatial information. By incorporating such direction-aware feature mappings, the network can better understand the spatial relationships between different regions of the input, thereby improving the performance on vision tasks.
This series of technological innovations enables the LA mechanism to significantly improve the model’s ability to pay attention to spatial features, thus accurately improving object localization accuracy and more accurately capturing spatial dependencies. Ultimately, these improvements enable the LA mechanism to achieve excellent box detection performance in complex real-world scenarios.
3.2. FEP
In actual scenarios, the box size may vary. For example, there are both large container boxes and small turnover boxes in a warehouse scene. The fused feature map allows the model to accurately detect the boxes at different scales, reducing missed detection or false detection caused by size differences. Therefore, the HYFF-CB model uses an FEP structure at its bottleneck layer, which enables the network to better integrate the features of objects of different scales, thereby improving the detection performance of boxes of different scales.
This paper assumes the low-level feature map to be and the size to be (where represents the height, represents the width, and represents the number of channels). After an upsampling operation, the FEP obtains , and the size becomes , as shown in Equation (7):
where represents the location of the feature map after upsampling, represents the localization of the original feature map, is the interpolation kernel function, and is the upsampling factor.
This paper assumes that the high-level feature map is and the size is . After a downsampling operation, is obtained, and the size becomes , as shown in Equation (8):
where represents the localization of the feature map after downsampling, is the localization within the pooling window, and represents the channel dimension.
The upsampled low-level feature map and the downsampled high-level feature map are fused into the feature map , as shown in Equation (9):
Since the fused features contain rich semantic and localization information, the model can more accurately determine the locations and categories of boxes during detection. This fusion method also enhances the robustness of the model, allowing it to better cope with various complex scene changes, such as lighting changes and partial occlusion of boxes. For example, even if a box is partially occluded by other objects, the model can still use the fused features to infer the category of the occluded part based on semantic information, and determine the boundaries of the unoccluded part based on localization information, thereby achieving higher accuracy in box detection.
3.3. SW-Loss System
During the loss calculation process, an SW-Loss system is created to address various problems in box detection, and is used to replace the original loss function, aiming to effectively deal with the main contradictions in box detection.
In complex scenes, such as dense box stacking, partial box occlusion, and lighting changes, it is difficult to accurately detect boxes by relying solely on classification or regression. Classification can better identify boxes based on the location and shape information provided by regression, whereas regression can provide more accurate localization and size estimation based on the target objects identified by classification. This mutually complementary relationship enables the model to more comprehensively understand the box information in the image, thereby completing the box detection task more accurately.
Therefore, the SW-Loss system consists of two parts: classification and regression. The classification part uses BCE (binary cross-entropy), and the regression part uses DFL (distribution focal loss) [36] and the CloU loss function, as shown in Equation (10):
where , , and are the weight coefficients of BCE loss, DFL loss, and CloU loss, respectively.
BCE is used for classification tasks, as shown in Equation (11):
where is the true label, is the probability of the positive class in model prediction, and is the total number of samples. In box detection, BCE helps the model to distinguish the boxes from the background. In particular, when the contrast between the box and the background is not high, or the box is partially blocked, BCE improves the model’s ability to identify boxes by focusing on the classification accuracy of each pixel.
DFL is used for regressing the bounding boxes. Its core idea is to model the location of a bounding box as a probability distribution, rather than a fixed value. DFL is given by Equation (12):
where and are the discretized locations of the bounding box, and and are the probabilities of the corresponding locations. DFL is designed for difficult-to-classify samples in object detection. Its core idea is to reduce the weights of easy-to-classify samples and increase the weights of difficult-to-classify samples. It encourages the model to pay more attention to those difficult-to-detect boxes (e.g., boxes that are similar to the background, have blurred boundaries, or are partially occluded), thereby improving the model’s detection accuracy for these boxes.
CloU considers the penalty terms for the inconsistency between the prediction box and ground truth box in intersection over union (IoU), distance between centroids, and aspect ratio, as shown in Equation (13):
where is the distance between the centroids of the prediction box and ground truth box, is the diagonal length of the minimum bounding rectangle, is a correction factor used to consider the difference in aspect ratio between the prediction box and ground truth box, and is a balance factor. In box detection, the shapes and sizes of boxes may vary depending on the cargo loaded. The CloU loss function uses these additional penalty terms to enable the model to more accurately predict the locations and sizes of boxes.
4. Experimental Results
4.1. Dataset
We collected a high-resolution image dataset specifically for box detection. The dataset consists of 9534 images; the dataset was randomly split into a training set (7627 images), a validation set (953 images), and a test set (954 images). The images were taken at Milaotou Warehouse and Vinda Paper Warehouse. Each image had 10 to 100 target boxes.
Data collection covered a variety of onsite application scenarios, including the following:
- Images from various shooting angles, including images of boxes with varying degrees of blur and occlusion;
- Various lighting conditions, including natural light, artificial light, forward light, and backlight;
- Various weather conditions, such as sunny, cloudy, and rainy days;
- Various locations, including warehouses, trucks, and outdoor scenes.
The statistical results of the dataset’s quantities according to shooting locations are shown in Table 1.
The dataset from the warehouse is the largest. The illumination in the warehouse is relatively uniform, resulting in the lowest detection difficulty. The illumination in the dataset of trucks is also relatively even, yet there is frequent occurrence of occlusion by porters. The outdoor dataset is relatively small, and pictures with extreme lighting conditions, such as backlighting and low illuminance, are likely to appear, which makes the detection more difficult.
We ensured that the dataset could cover various practical application scenarios of boxes. Changes in these conditions brought greater challenges to box detection in images, as shown in Figure 3.
The boxes involved in the dataset could face challenges such as stacking, rotation, and tilt. Other objects or shadows in the images could cause the boxes to be partially obscured. To enhance the generalization ability of the model, we included the images under more challenging scenarios, such as reflected light interference, high-contrast backgrounds, and extreme lighting conditions, into the dataset. Each of these factors made it more difficult to identify the box edges, as shown in Figure 4. The in-depth analysis and simulation results for these complex scenarios show that the object detection model can yield higher detection accuracy and robustness amid diversity and uncertainty.
All datasets were manually labeled using LabelImg. The labeled images are shown in Figure 5.
4.2. Experimental Process and Evaluation Indicators
This dataset contains 9534 images, and the data samples are divided in a ratio of 8:1:1. To determine the optimal hyperparameter configuration, a sensitivity analysis method was adopted, and the model performance was evaluated by changing the basic learning rate, optimizer, weight decay, and other parameters one by one. The equipment and some of the hyperparameters used in the experiments are listed in Table 2.
The SW-Loss system includes two parts, namely, classification and regression. To balance these two factors, we first set the classification score of a candidate sample to be , the regression score to be , and the weights to be and for SW-Loss in the selection of samples. Then, the comprehensive score was . After calculating the comprehensive score for all candidate samples, we selected the top samples with higher comprehensive scores as positive samples , and regarded the remaining samples as negative samples (i.e., the negative sample set ).
Usually, the AP (average precision), AR (average recall), and mAP (mean average precision) are used to evaluate the matching degree of the model to the dataset. They are given by Equation (14):
where denotes the correctly recognized target, denotes the object that is not the target but is recognized as the target, and denotes the unrecognized target. Precision is the proportion of samples that are actually positive among the samples that are predicted to be positive. The recall rate is the proportion of samples that are correctly predicted to be positive among all positive samples. In this study, the IoU value between the prediction box and the ground truth box was greater than 0.5, implying that the predicted object was a real target. A higher recall rate indicates that the model can better identify real targets and miss fewer targets.
4.3. Ablation Experiment
The ablation experiment applied the principle of control variables to control a part of the network in the model, to help provide a better understanding of the network function. Therefore, in this study, each module was added one by one to verify the impact of the improved modules on the model. The experimental results are shown in Table 3. Two modules were added one by one to the original model and compared with the original model. When adding attention modules, the commonly used attention modules SE (Squeeze-and-Excitation) and CBAM (Convolutional Block Attention Module) were selected for comparison with LA to verify the impact of the improved module on the model performance.
As observed from Table 3, the introduction of each individual improvement led to a certain degree of performance enhancement.
The attention modules were added to the YOLOv8s basic model. Three different attention mechanisms, SE, CBAM, and LA, were added. After adding LA, the performance of the model improved the most. The relative improvements in AP, AR, and mAP@50% were 0.74%, 0.74%, and 0.31%, respectively. This indicates that LA can enhance the model’s ability to focus on spatial features. Compared with other attention modules, LA has a stronger ability to detect boxes.
After adding the FEP module, the relative improvements in AP and AR were 0.53% and 0.63%, respectively, which shows that the FEP module can improve the model’s detection performance for boxes of different scales. After adding the SW-Loss module, the relative improvements in AP and AR were 0.21% and 0.21%, respectively. After adding the FEP and SW-Loss modules, compared with the basic model, the relative improvements in AP, AR, and mAP were 0.63%, 0.74%, and 0.2%, respectively.
After adding the FEP, SW-Loss, and LA modules, compared with the basic model, the relative improvements in AP, AR, and mAP were 1.37%, 1.37%, and 0.51%, respectively. The floating point operations per second (FLOPs) only increased by 0.5 GFLOPs/s compared with the basic model, an increase of 1.7%, indicating little impact on the detection speed.
In conclusion, these improvement measures can comprehensively enhance the model’s learning and generalization abilities in complex loading and unloading scenarios.
4.4. Comparative Experiment
We selected SSD, YOLOv5s, YOLOv8s, and HYFF-CB for model performance comparison. The same training parameters were used to verify the effectiveness of the model proposed in this paper. The results are shown in Table 4 and Figure 6. Figure 6a is a curve graph comparing the performance of each model, which contrasts AP, AR, and mAP@50%. Figure 6b displays the performance comparison between the YOLOv8s and HYFF-CB models after 150 epochs. The abscissa represents the number of training rounds, the ordinate represents mAP@50%, and the display range is limited to 0.9–1.
It can be seen from the table above that the mAP of our HYFF-CB model was 0.5% higher than the original YOLOv8s model under basically the same computing amount. Compared with the classic YOLOv5s model, the mAP of our model increased by 1.8%. Therefore, the improved model in this paper can meet the box detection needs of automatic loading and unloading systems.
4.5. Validation of Actual Effect
To verify the actual effectiveness of the HYFF-CB model, images of various scenarios were collected using an industrial camera. Tests were carried out on these scenarios. A total of 663 test samples were selected, and the detection results of the HYFF-CB model were verified manually. The detection results of each cargo box were checked one by one, and the real precision rate and recall rate were counted. The results are shown in Table 5 and Figure 7.
Here, TP represents the number of correctly detected cargo boxes, FP represents the number of objects that are not cargo boxes but are detected as cargo boxes, FN represents the number of missed detected cargo boxes, RP (real precision) is the real precision rate, counted manually, and RR (real recall) is the real recall rate, counted manually. The real precision rate reached 99.9%, and the real recall rate reached 99.8%, indicating that the precision rate and recall rate of the HYFF-CB model can already adapt to various scenarios in practical applications.
The test scenarios included natural light in trucks, supplementary lighting in trucks, backlit scenarios, small-sized cargo box targets, occlusion, irregular stacking, light reflection interference, low illuminance, etc. The test results show that the model can accurately predict the location of each box, and always maintains high reliability.
5. Conclusions
In the process of the automation development of the manufacturing and logistics industries, the accurate and efficient implementation of automatic loading and unloading technology is of great significance. This paper focuses on this issue. By using an industrial camera to collect carriage images in real time, and innovatively integrating the LA attention module into the classic YOLOv8 model, accurate detection of cargo boxes in the carriage was carried out. This model could not only clearly identify the stacking positions of the cargo boxes, but also accurately count their quantities.
After a large number of rigorous tests and in-depth comparative analysis of the detection effects of various different models, it was found that the HYFF-CB model proposed in this paper exhibits excellent performance, and its detection rate is significantly higher than that of other models. The detection performance and practical effects of this model meet or even exceed the expected requirements, and the model is fully capable of perfectly adapting to various complex application scenarios involved in automatic loading and unloading, strongly promoting the progress of automatic loading and unloading technology from theory to practical application.
Although the HYFF-CB model proposed in this paper successfully meets the basic requirements of practical applications in terms of detection accuracy and recall rate, in order to further enhance the practicality and commercial value of this technology in the field of automatic loading and unloading, especially to better match the refined operations of robotic arms, we have clearly planned the next research direction. In the follow-up, we will focus on deeply integrating and matching the HYFF-CB model with the depth information of the cargo boxes scanned by LiDAR. By accurately extracting and efficiently transmitting the spatial position information of the cargo boxes to the robotic arm, a high degree of automation and intelligence of the entire loading and unloading process can be achieved, thus accelerating the achievement of commercial standards for automatic loading and unloading, and injecting new vitality into the development of the industry.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Oliver R.K. Webber M.D. Supply-Chain Management: Logistics Catches up with Strategy The Roots of Logistics Klaus P. Müller S. Springer Berlin/Heidelberg, Germany 201218319410.1007/978-3-642-27922-5_15 · doi ↗
- 2Ferreira B. Reis J. A Systematic Literature Review on the Application of Automation in Logistics Logistics 202378010.3390/logistics 7040080 · doi ↗
- 3Kirchheim A. Burwinkel M. Echelmeyer W. Automatic Unloading of Heavy Sacks from Containers Proceedings of the 2008 IEEE International Conference on Automation and Logistics Qingdao, China 1–3 September 2008 IEEE Piscataway, NJ, USA 200894695110.1109/ICAL.2008.4636286 · doi ↗
- 4Lei W. Market Analysis of Intelligent Loading and Unloading Vehicle Robots Logist. Mater. Handl.2023289093
- 5Jiang H. Development of Automatic Loading and Unloading Vehicle Technology from an Industrial Perspective Logist. Mater. Handl.202328116117
- 6Roy D. de Koster R. Stochastic Modeling of Unloading and Loading Operations at a Container Terminal Using Automated Lifting Vehicles Eur. J. Oper. Res.201826689591010.1016/j.ejor.2017.10.031 · doi ↗
- 7Mi C. Huang Y. Fu C. Zhang Z. Postolache O. Vision-Based Measurement: Actualities and Developing Trends in Automated Container Terminals IEEE Instrum. Meas. Mag.202124657610.1109/MIM.2021.9448257 · doi ↗
- 8Yan R. Tian X. Wang S. Peng C. Development of Computer Vision Informed Container Crane Operator Alarm Methods Transp. A: Transp. Sci.202420214586210.1080/23249935.2022.2145862 · doi ↗