Exploring Coronavirus Disease 2019 Risk Factors: A Text Network Analysis Approach
Min-Ah Kang, Soo-Kyoung Lee

TL;DR
This study uses text network analysis to identify and understand risk factors for severe COVID-19, revealing key themes and how research focus evolved over time.
Contribution
The study introduces text network analysis as a novel method to synthesize and visualize complex relationships among COVID-19 risk factors.
Findings
Five thematic clusters were identified: biomedical, occupational, demographic, behavioral, and complication-related factors.
Research focus shifted from acute complications in early 2020 to long COVID and vaccine efficacy by mid-2021.
The study highlights the dynamic nature of pandemic research and the need for adaptive public health strategies.
Abstract
Background/Objectives: The coronavirus disease 2019 (COVID-19) pandemic has significantly affected global health, economies, and societies, necessitating a deeper understanding of the factors influencing its spread and severity. Methods: This study employed text network analysis to examine relationships among various risk factors associated with severe COVID-19. Analyzing a dataset of published studies from January 2020 to December 2021, this study identifies key determinants, including age, hypertension, and pre-existing health conditions, while uncovering their interconnections. Results: The analysis reveals five thematic clusters: biomedical, occupational, demographic, behavioral, and complication-related factors. Temporal trend analysis reveals distinct shifts in research focus over time. In early 2020, studies primarily addressed immediate clinical characteristics and acute…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
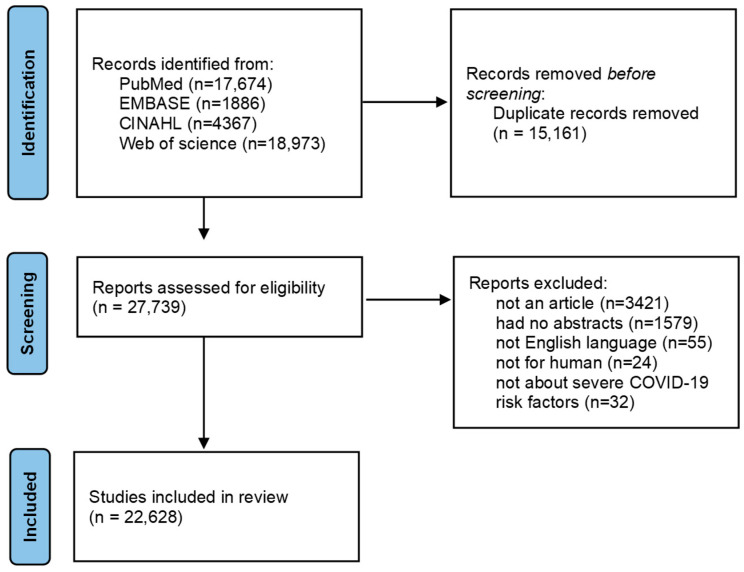 Figure 1
Figure 1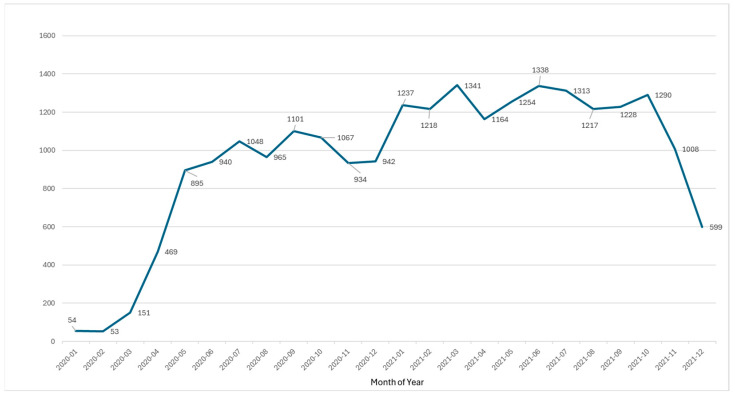 Figure 2
Figure 2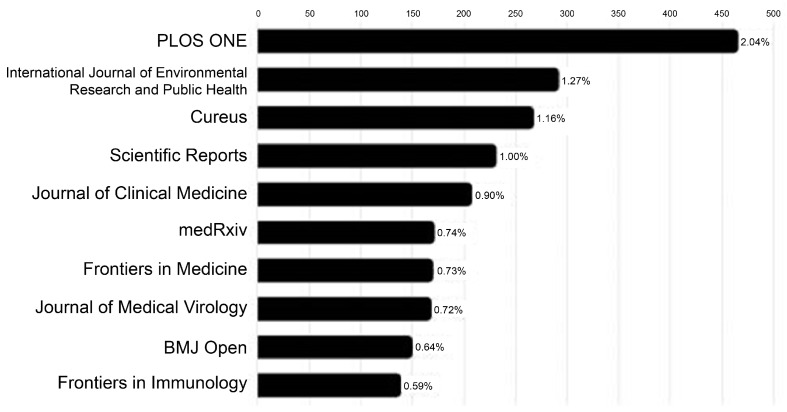 Figure 3
Figure 3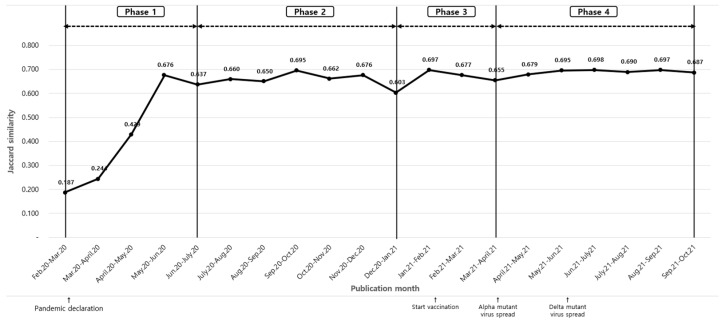 Figure 4
Figure 4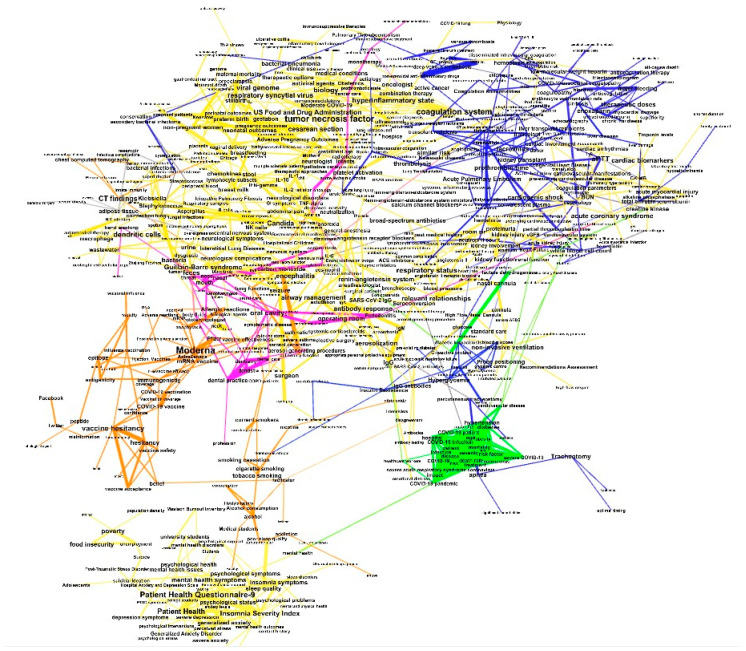 Figure 5
Figure 5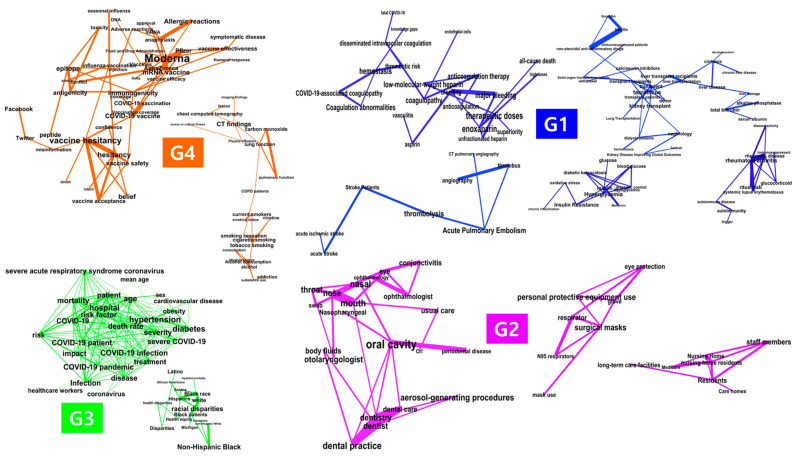 Figure 6
Figure 6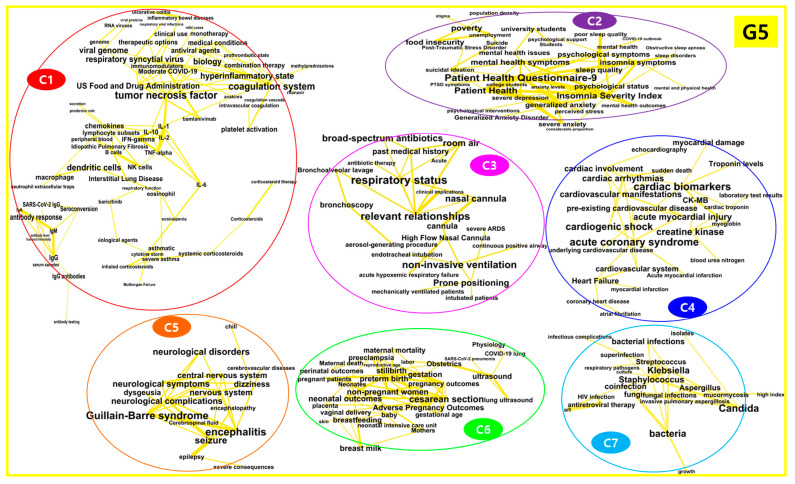 Figure 7
Figure 7- —National Research Foundation of Korea (NRF)
- —Korea government (MSIT)
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsCOVID-19 Clinical Research Studies · Computational Drug Discovery Methods · Misinformation and Its Impacts
1. Introduction
The coronavirus disease 2019 (COVID-19) pandemic has significantly impacted global health systems, economies, and societies. While the acute phase of the pandemic has passed, COVID-19 continues to pose significant health challenges, including the emergence of new variants, long-term complications (long COVID), and mental health effects [1,2]. These ongoing concerns underscore the necessity of continued research on risk factors associated with COVID-19 severity and outcomes. As of December 2021, the long-term effects of COVID-19 and its impact on various populations remain insufficiently understood, necessitating further investigation.
COVID-19′s high transmissibility and variable severity have driven extensive research into its biological, environmental, and social determinants. Early studies highlighted age, comorbidities, and socioeconomic status as key risk factors [2]. However, while these studies provided valuable insights, they often relied on traditional epidemiological models that struggled to capture the evolving and interconnected nature of these risks. Additionally, prior studies often examined risk factors in isolation, lacking a holistic perspective on how different factors interact within the broader research landscape.
The evolving characteristics of COVID-19 have revealed significant disparities in outcomes based on demographic features such as age, sex, race, and socioeconomic status. Studies have shown that older adults and individuals with pre-existing conditions face higher risks of severe illness, while marginalized communities experience disproportionate effects due to limited healthcare access and economic constraints [3]. Variations in health policies, preventive measures, and vaccine distribution add to the complexity of global responses [4]. Addressing these challenges requires advanced analytical approaches that synthesize vast amounts of data to reveal underlying patterns across diverse datasets.
To address these challenges, researchers increasingly turn to computational and data-driven approaches [5]. Advances in data analytics and computational modeling have enabled new approaches, particularly text network analysis, which has emerged as an effective method for identifying patterns and associations within textual data. Unlike traditional epidemiological studies that rely on structured datasets, text network analysis systematically explores unstructured textual information. This methodology is particularly well-suited for addressing the research gap in understanding the relationships among various COVID-19 risk factors, as it enables the detection of hidden connections and emerging trends within vast literature [6].
TNA differs from other computational methods, such as machine learning and natural language processing (NLP), in several ways. Machine learning techniques typically require labeled datasets for supervised training or employ unsupervised clustering algorithms to categorize data, often necessitating large-scale training datasets. NLP, on the other hand, is focused on processing and extracting meaning from text but may lack the ability to systematically map relationships between key concepts over time. In contrast, TNA constructs networks of semantic relationships between key terms, allowing researchers to visualize knowledge structures, detect thematic shifts, and track the evolution of scientific discourse [7].
Traditional epidemiological models primarily rely on structured datasets and predefined variables, which may limit their ability to capture complex interconnections and dynamic research trends. In contrast, TNA enables the systematic exploration of unstructured textual data, allowing researchers to uncover emerging themes, detect hidden relationships, and track the evolution of scientific discourse over time. Unlike static epidemiological models, TNA can continuously adapt to new research developments and identify unexpected associations between risk factors [8].
A key advantage of TNA is its ability to integrate diverse information sources, including academic literature, social media, and public health reports, to uncover meaningful relationships and emerging trends [9]. For example, during the early stages of the pandemic, social media served as a critical channel for disseminating public health information yet also contributed to the spread of misinformation. TNA enables researchers to systematically analyze and contextualize such data, distinguishing between reliable findings and misleading narratives [10].
Previous studies have often examined COVID-19 risk factors in isolation, lacking a holistic perspective on how different determinants interact within the broader research landscape. Additionally, many studies struggled to capture dynamic research shifts, as they relied on static datasets. By employing TNA, this study provides a comprehensive, data-driven synthesis of risk factor interactions over time, bridging these gaps and offering new insights into the evolving research landscape.
Recognizing the importance of understanding COVID-19 risk factors and their interconnections, this study employs text network analysis to investigate relationships among various disease-associated determinants. Specifically, the study aims (1) to identify key keywords in studies related to risk factors for severe COVID-19, (2) to analyze the relationships among keywords and classify subgroups based on network clusters, and (3) to examine the temporal research trends in studies related to severe COVID-19 risk factors.
Through this approach, this study seeks to provide a comprehensive and data-driven synthesis of risk factor interactions over time. By leveraging text network analysis, this research aims to bridge gaps in existing knowledge, offering insights that can inform public health strategies, policy decisions, and pandemic preparedness efforts.
2. Materials and Methods
This quantitative content analysis used text network analysis to extract key keywords related to severe COVID-19 risk factors, classify network-based subgroups, and identify research trends over time.
2.1. Search Strategy
Keywords for data collection were designed using a combination of natural language and MeSH (Medical Subject Heading) terms. Keywords included ‘COVID-19’, ‘SARS-CoV-2’, ‘2019-nCoV’, ‘risk’, ‘risk factor’, ‘severe’, ‘critical’, ‘severity’, ‘intensive care unit’, ‘respiratory failure’, and ‘fatal’ (Table A1). A literature search was conducted across four major academic databases: PubMed, Scopus, Web of Science, and EMBASE, to ensure comprehensive coverage of peer-reviewed studies. Boolean operators (“AND” and “OR”) were applied to construct the search queries. Specifically, “OR” was used to combine synonyms and related terms (e.g., “COVID-19” OR “SARS-CoV-2” OR “2019-nCoV”), while “AND” was used to refine searches by including key concepts (e.g., “COVID-19” AND “risk factor” AND “severe”). The final search queries were tailored to the syntax of each database. The search was limited to articles published in English and indexed in peer-reviewed journals, with a publication period from January 2020 to December 2021. To ensure transparency, a PRISMA flow diagram (Figure 1) was included to illustrate the article selection process.
2.2. Inclusion and Exclusion Criteria
A total of 42,900 articles were retrieved from the databases. After removing 15,161 duplicates, 27,739 articles were screened based on their titles and abstracts. Inclusion criteria were as follows: (1) articles published between January 2020 and December 2021; (2) studies on COVID-19 risk factors related to disease severity and transmission; (3) peer-reviewed publications in English; and (4) articles providing relevant epidemiological or clinical data. Exclusion criteria were as follows: (1) non-peer-reviewed papers, preprints, and opinions; (2) articles without abstracts or full-text availability; (3) studies involving non-human subjects (e.g., mice, cats, dogs, gorillas); and (4) research focusing on unrelated topics such as MERS or information security. Two independent reviewers, a researcher and a nursing professor, screened the articles and ultimately selected 22,628 articles for data analysis.
2.3. Data Extraction and Analysis
Data extraction focused on keyword identification, cleaning, statistical validation, and visualization. The following steps were performed:
-
(1)Keyword Extraction and Cleaning
-
Keywords were extracted from the titles, abstracts, and keywords of the selected articles using Python 3.9, Natural Language Toolkit (NLTK) 3.6.7, and Text Rank algorithm.
-
Standardization was applied to account for variations in capitalization, pluralization, abbreviations, and special characters.
-
Synonyms were consolidated into single representative terms, ensuring consistency across the dataset.
-
(2)Keyword Analysis and Visualization
-
Key keywords were analyzed using term frequency analysis and Term Frequency-Inverse Document Frequency (TF-IDF) with Python’s Sklearn module (Scikit-learn 0.24.2).
-
Results were visualized using Gephi 0.9.2, a widely used open-source tool for network analysis.
-
(3)Clustering and Network Classification
-
Clusters were identified using modularity-based algorithms and PageRank centrality measures in Gephi.
-
Nodes with low similarity were filtered to improve clustering accuracy.
-
The Jaccard similarity coefficient threshold was set at 0.065 to exclude weak associations. The threshold (0.065) was determined based on both heuristic analysis and empirical validation. Following prior research [11], network visualization was used to assess optimal threshold selection. Additionally, multiple threshold values (0.05, 0.06, 0.07) were tested to balance network density and meaningful keyword relationships. The threshold of 0.065 was selected as it minimized noise while retaining key associations.
-
(4)Temporal Trend Analysis
-
Temporal trends were analyzed by computing monthly similarity indices based on frequency matrices and Jaccard coefficients.
-
Cut-off points were determined by identifying peaks and troughs in similarity trends using statistical methods, including moving averages and Z-scores, to ensure objective detection.
-
Four distinct time intervals were identified, highlighting emerging keywords in each period.
This methodology provides a systematic approach to understanding the evolving landscape of severe COVID-19 risk factors, ensuring a data-driven framework for public health insights and policymaking.
3. Results
3.1. Characteristics of Severe COVID-19 Risk Factor Studies and Key Keywords
The collected studies on severe COVID-19 risk factors included articles published in international and domestic journals between January 2020 and December 2021. A total of 22,628 studies were analyzed. Monthly publication trends showed a rapid increase, starting with 54 studies in January 2020 and peaking at 895 in May 2020. Approximately 1000 studies were published monthly until October 2021, after which the number decreased (Figure 2).
The surge in early 2020 likely reflects the global research response to COVID-19. The peak in May 2020 may correspond to the initial wave of studies focusing on early risk-factor identification and pandemic mitigation strategies. After October 2021, the decline in publications likely resulted from a research shift toward vaccine efficacy, long COVID, and post-pandemic recovery efforts. Figure 2 illustrates these trends, highlighting the evolving research priorities over time in response to global health events and policy changes.
The retrieved studies were published in 5410 journals, with the top 15–20 journals accounting for approximately 9.8% of all articles (Figure 3). The top 10 journals included PLOS ONE (2.04%), International Journal of Environmental Research and Public Health (1.27%), Cureus (1.16%), Scientific Reports (1.00%), and Journal of Clinical Medicine (0.90%).
Table 1 presents keyword frequency and PageRank centrality values. Frequently appearing keywords included ‘age’ (3224 times), ‘treatment’ (2934), ‘diabetes’ (1504), ‘hypertension’ (1230), and ‘obesity’ (1045). PageRank centrality identified influential keywords such as ‘non-invasive ventilation’, ‘IgG’, ‘hyperglycemia’, ‘hypertension’, and ‘diabetes.’ Keywords with both high frequency and centrality included ‘hypertension’, ‘diabetes’, and ‘age. A detailed list of keywords is provided in Table A2.
3.2. Network Analysis of Keywords
To examine structural trends in studies on severe COVID-19 risk factors, a text network analysis was conducted to visualize the knowledge structure. Using a PageRank algorithm analysis, 1492 keywords were identified. Applying a Jaccard similarity coefficient ≥0.065, the dataset was filtered to 346 nodes and 672 links, removing keywords with low frequency or weak connectivity. The final selected keywords represent core risk factors for severe COVID-19. Figure A1 presents a spring map visualization of the network.
A total of 21 clusters were identified and categorized into five major thematic groups: (1) biomedical, (2) occupational and environmental, (3) demographic, (4) health behavior, and (5) complication factors (Figure A2).
These clusters reflect key aspects of severe COVID-19 risk factors. For example, the biomedical cluster includes terms such as “cytokine storm” and “coagulopathy”, which are closely associated with severe disease progression. The demographic cluster highlights age-related risks, particularly among elderly populations. Similarly, the occupational and environmental cluster encompasses COVID-19 exposure risks in work environments.
While this cluster includes terms such as mouth and dentists, these are strongly linked to occupational hazards in healthcare settings. Studies have consistently identified dentists and other frontline workers as high-risk groups due to their frequent exposure to aerosol-generating procedures (AGPs). This underscores the importance of infection control measures and personal protective equipment (PPE) usage in these work environments.
As shown in Figure A3, Group 5 (complication factors) was further divided into seven subcategories based on complications affecting organ systems (e.g., cardiovascular, respiratory, and immune responses). The keywords for each group are summarized in Table 2, illustrating that the major risk factors for severe COVID-19 are multifaceted and interrelated. The clustering results provide a structured overview of the interconnections between various risk factors, offering insights into how different domains contribute to severe COVID-19 outcomes. These findings highlight the multifaceted nature of COVID-19 risk and the necessity for interdisciplinary approaches in pandemic research.
3.3. Temporal Trends of Severe COVID-19 Risk Factor Studies
Temporal trends were analyzed using frequency matrices and Jaccard similarity coefficients to identify keyword usage changes over time. Keywords were examined monthly for 24 months and segmented into four phases. Phase 1 (February–June 2020) included keywords appearing ≥10 times with ≥100 total occurrences. Phase 2 (July–December 2020) included keywords with ≥10 occurrences and ≥50 total frequency. Phase 3 (January–March 2021) identified emerging keywords with ≥5 occurrences. Phase 4 (April–September 2021) highlighted keywords appearing ≥10 times with ≥20 total frequency (Figure 4).
Table 3 shows keyword frequencies by phase, including terms such as ‘obesity’, ‘social distancing’, ‘dyspnea’, ‘psychological well-being’, ‘long COVID’, and ‘mRNA vaccine’. Detailed frequencies are in Table A3.
4. Discussion
4.1. Principal Findings
The rapid spread of COVID-19 in early 2020 led to an exponential rise in research on transmission, mortality, and risk factors. Identifying contributors to severe COVID-19 became a global priority, informing public health interventions and guiding future research. This study employed text network analysis to examine key concepts and structural relationships in studies published between January 2020 and December 2021, providing insights into the evolving knowledge landscape.
Our findings identified ‘age’ as the most frequently mentioned keyword, aligning with prior studies indicating that older adults are more vulnerable due to weakened immune function and chronic inflammation [12]. ‘Hypertension’ emerged as a central keyword with both high frequency and PageRank centrality, confirming its role as a predictor of severe outcomes [13]. These findings highlight the need for targeted interventions for high-risk groups, particularly older adults and patients with pre-existing conditions. Additionally, recent research suggests that metabolic risk factors, such as obesity, diabetes, and metabolic syndrome, present a greater risk for severe complications than individual diseases alone [14]. This underscores the importance of a multidimensional approach to addressing complex risk factors. Some studies suggest that metabolic factors act as independent risk factors for severe COVID-19, while others indicate that their impact is mediated through hypertension and systemic inflammation [15]. This suggests the need for further research using causal modeling techniques to disentangle these interrelated pathways.
‘Non-invasive ventilation (NIV)’ exhibited high PageRank centrality despite lower frequency, indicating strong connections to other risk factors. However, many studies analyzing NIV use were conducted in hospital settings, which could introduce selection bias. The frequency of NIV use in severe COVID-19 cases may reflect institutional protocols rather than universal best practices [16]. Further investigation is needed to determine the optimal use of NIV across different patient populations and healthcare settings.
4.2. Network and Cluster Analysis
Network analysis identified five primary thematic clusters: biomedical, occupational, demographic, behavioral, and complication-related factors. The biomedical cluster featured terms such as ‘coagulopathy’, ‘hyperglycemia’, and ‘rheumatoid arthritis’, reinforcing the significance of underlying medical conditions. Consistent with previous research, coagulopathy was associated with increased mortality risk, highlighting the need for close monitoring of coagulation markers [17].
Occupational and environmental clusters focused on healthcare workers and long-term care facilities, underscoring occupational risks related to aerosol-generating procedures and inadequate protective equipment [18]. These findings support enhanced workplace protections for healthcare workers and vulnerable populations.
The demographic cluster emphasized ‘age’, ‘obesity’, and ‘race’, reflecting disparities in COVID-19 outcomes. Higher infection and mortality rates among Black and Hispanic populations have been widely documented, but the underlying causes of these disparities are complex [19]. Such disparities may arise from a combination of biological factors, socioeconomic conditions, and healthcare accessibility issues. Understanding the root causes of these disparities is crucial for developing equitable public health interventions. To effectively reduce racial and ethnic health disparities, a multi-faceted approach is required, which includes the following: Reducing socioeconomic inequalities through policies aimed at improving financial security, employment opportunities, and housing conditions. Enhancing healthcare access by addressing systemic inequities in insurance coverage and expanding medical services in underserved communities. Eliminating cultural and linguistic barriers to ensure equitable communication of health information and medical guidance. By implementing these strategies, public health initiatives can more effectively mitigate COVID-19 disparities and promote long-term health equity.
Behavioral clusters included ‘vaccine hesitancy’ and ‘alcohol consumption’, underscoring modifiable risk factors. Vaccine hesitancy remains a major barrier to herd immunity and outbreak control [19,20,21], necessitating public health campaigns to improve vaccine acceptance. Additionally, lifestyle factors such as smoking and alcohol consumption compromise immune function, increasing the risk of severe COVID-19. Smokers are 2–14 times more likely to develop severe cases than non-smokers, reinforcing the need for smoking cessation and alcohol reduction programs [22,23,24,25].
4.3. Inter-Cluster Relationships
This study highlights the interconnected nature of different clusters. Biomedical factors such as hypertension and obesity were closely linked to behavioral risk factors, including diet and physical inactivity. Similarly, occupational exposure correlated with demographic factors, as older adults and minority groups were more likely to work in high-risk frontline positions. Understanding these inter-cluster relationships is crucial for designing holistic public health strategies that address multiple interacting risk factors rather than isolated variables.
This study underscores the importance of a comprehensive approach to mitigating severe COVID-19 outcomes. By leveraging text network analysis, this study identified key research themes and their interconnections, offering valuable insights for future public health interventions and policymaking. Unlike traditional epidemiological models that analyze individual risk factors separately, our findings highlight the need for interdisciplinary approaches that integrate biomedical, social, and behavioral determinants to effectively mitigate severe COVID-19 outcomes.
4.4. Temporal Trends
Temporal analysis divided research trends into four phases:
Phase 1 (February–June 2020): Focused on early pandemic responses, including social distancing and transmission pathways [26].
Phase 2 (July–December 2020): As the pandemic progressed, research priorities shifted toward understanding population-specific vulnerabilities, including racial and socioeconomic disparities in infection rates and disease severity. During this period, the prolonged impact of lockdowns and healthcare system strain also contributed to increased interest in mental health challenges associated with pandemic stressors [27].
Phase 3 (January–March 2021): With the emergence of long-term effects of COVID-19, studies began to explore long COVID symptoms, post-viral syndromes, and their sociodemographic correlations [28].
Phase 4 (April–September 2021): Research efforts were increasingly directed toward vaccine development, public vaccination strategies, and the impact of emerging viral variants [29].
This progression reflects the evolving nature of research priorities in response to pandemic challenges, transitioning from immediate containment strategies to long-term health consequences and public health preparedness.
4.5. Strengths and Limitations
A key strength of this study is the use of advanced text network analysis, enabling a comprehensive evaluation of large-scale textual data. This approach provided insights into both established and emerging trends, supporting data-driven decision-making.
However, several limitations should be acknowledged. This study relied exclusively on English-language publications, introducing selection bias and limiting generalizability. The exclusion of non-peer-reviewed studies may have resulted in publication bias, omitting relevant but unpublished findings. Additionally, text network analysis has inherent limitations, including potential keyword bias, as term selection influences network structure. Temporal bias may also exist due to publication delays, potentially underrepresenting emerging risk factors. Furthermore, this study primarily utilized keyword frequency analysis and network-based methods, which identify associations between risk factors and severe COVID-19 outcomes but do not establish causal relationships. While the network analysis provides valuable insights into relational structures and co-occurrence patterns, it does not infer causality or determine the direct impact of specific risk factors. As a result, the findings should be interpreted as indicative of correlations rather than definitive causal links. To enhance the robustness of future research, additional statistical validation techniques (e.g., regression analysis, time-series modeling) and epidemiological modeling approaches (e.g., cohort studies, causal inference models, structural equation modeling) should be incorporated. These methods would help differentiate associative relationships from causal mechanisms, providing stronger empirical evidence for risk factor significance.
4.6. Implications and Future Directions
Findings from this study emphasize the need for interdisciplinary approaches to COVID-19 risk factors. While this study highlights key research themes, it is essential to translate these insights into clear and actionable public health strategies to improve pandemic preparedness.
Although COVID-19 is no longer a newly emerging crisis, its long-term effects—including post-infection complications, evolving variants, and pandemic-induced health disparities—continue to impact healthcare systems worldwide. The need to manage long COVID, chronic disease exacerbation, and the integration of pandemic lessons into future outbreak preparedness underscores the relevance of continued research in this field.
One of the critical aspects of pandemic response is ensuring that high-risk populations receive targeted interventions. Older adults, individuals with hypertension, and those with metabolic syndrome are particularly vulnerable to severe outcomes, necessitating tailored preventive measures and medical management strategies. In addition, efforts to expand healthcare access are crucial in mitigating disparities faced by vulnerable demographic groups who often experience systemic barriers to medical care.
Guidance on the appropriate use of non-invasive ventilation (NIV) is another area that requires refinement. Evidence-based guidelines should be established to ensure that NIV is utilized effectively, minimizing unnecessary intubations while optimizing respiratory support. Similarly, the psychological effects of lockdowns, economic distress, and post-infection trauma must be addressed through stronger mental health support systems integrated into pandemic response efforts.
Vaccine acceptance remains a major challenge in public health. Targeted communication strategies that address misinformation and vaccine hesitancy are essential in ensuring widespread immunization coverage. Effective campaigns should focus on culturally appropriate messaging and trust-building within communities.
Beyond these immediate public health measures, future research should incorporate statistical and epidemiological methodologies to strengthen the validity of findings derived from text network analysis. The application of regression models, time-series analysis, and epidemiological modeling—such as cohort studies, causal inference models, and structural equation modeling—would enhance causal inference and improve the robustness of risk factor identification.
As pandemics continue to evolve, integrating diverse analytical approaches will be crucial in shaping effective public health strategies. This study provides a comprehensive analytical framework that can be adapted for future infectious disease outbreaks, reinforcing data-driven decision-making in global health policy.
5. Conclusions
This study demonstrates the utility of the text network analysis in mapping knowledge structures and identifying trends in severe COVID-19 risk factors. The insights gained can inform targeted public health interventions, support data-driven policy development, and enhance pandemic preparedness. Specifically, our findings can help policymakers develop risk stratification models to identify high-risk populations, optimize vaccine distribution strategies, and improve early warning systems for emerging infectious diseases. Furthermore, the application of the text network analysis extends beyond COVID-19, offering a scalable approach for analyzing epidemiological data in future outbreaks. By leveraging such data-driven methodologies, decision-makers can implement more effective and proactive health strategies.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1World Health Organization Coronavirus Disease (COVID-19) Pandemic 2020 Available online: https://www.who.int/emergencies/diseases/novel-coronavirus-2019(accessed on 12 February 2022)
- 2Centers for Disease Control and Prevention COVID-19 Overview and Infection Prevention and Control Priorities in Non-U.S. Healthcare Settings.Available online: https://archive.cdc.gov/www_cdc_gov/coronavirus/2019-ncov/hcp/non-us-settings/overview/index.html(accessed on 12 February 2022)
- 3Dong E. Du H. Gardner L. An interactive web-based dashboard to track COVID-19 in real time Lancet Infect. Dis.20202053353410.1016/S 1473-3099(20)30120-132087114 PMC 7159018 · doi ↗ · pubmed ↗
- 4Zhou F. Yu T. Du R. Fan G. Liu Y. Liu Z. Xiang J. Wang Y. Song B. Gu X. Clinical course and risk factors for mortality of adult inpatients with COVID-19 in Wuhan, China: A retrospective cohort study Lancet 20203951054106210.1016/S 0140-6736(20)30566-332171076 PMC 7270627 · doi ↗ · pubmed ↗
- 5Wang C. Horby P.W. Hayden F.G. Gao G.F. A novel coronavirus outbreak of global health concern Lancet 202039547047310.1016/S 0140-6736(20)30185-931986257 PMC 7135038 · doi ↗ · pubmed ↗
- 6Eysenbach G. How to fight an infodemic: The four pillars of infodemic management J. Med. Internet Res.202022 e 2182010.2196/2182032589589 PMC 7332253 · doi ↗ · pubmed ↗
- 7Lodhwal V. Choudhary G. Survey Paper: Automatic Title Generation for Text with RNN and Pre-trained Transformer Language Model Int. J. Res. Appl. Sci. Eng. Technol.2023112117212410.22214/ijraset.2023.49713 · doi ↗
- 8Dritsas E. Trigka M. Exploring the intersection of machine learning and big data: A survey Mach. Learn. Knowl. Extr.202571310.3390/make 7010013 · doi ↗