Centralized Hierarchical Coded Caching Scheme for Two-Layer Network
Kun Zhao, Jinyu Wang, Minquan Cheng

TL;DR
This paper introduces a new caching strategy for two-layer networks that reduces coding delays by efficiently using cache memory at both mirrors and users.
Contribution
A novel centralized hierarchical coded caching scheme using PDAs for two-layer networks with heterogeneous user distributions.
Findings
The proposed scheme treats mirrors and users as unified cache nodes to optimize memory usage.
Numerical results show reduced coding delays compared to existing hierarchical caching methods.
The scheme is extended to handle heterogeneous networks with varying numbers of users per mirror.
Abstract
This paper considers a two-layer hierarchical network, where a server containing N files is connected to K1 mirrors and each mirror is connected to K2 users. Each mirror and each user has a cache memory of size M1 and M2 files, respectively. The server can only broadcast to the mirrors, and each mirror can only broadcast to its connected users. For such a network, we propose a novel coded caching scheme based on two known placement delivery arrays (PDAs). To fully utilize the cache memory of both the mirrors and users, we first treat the mirrors and users as cache nodes of the same type; i.e., the cache memory of each mirror is regarded as an additional part of the connected users’ cache, then the server broadcasts messages to all mirrors according to a K1K2-user PDA in the first layer. In the second layer, each mirror first cancels useless file packets (if any) in the received useful…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
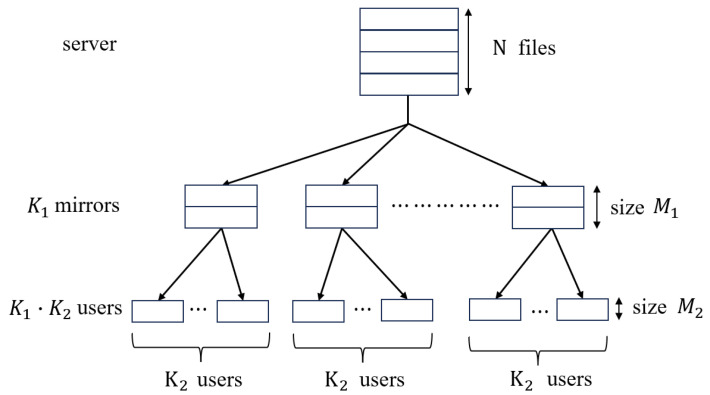 Figure 1
Figure 1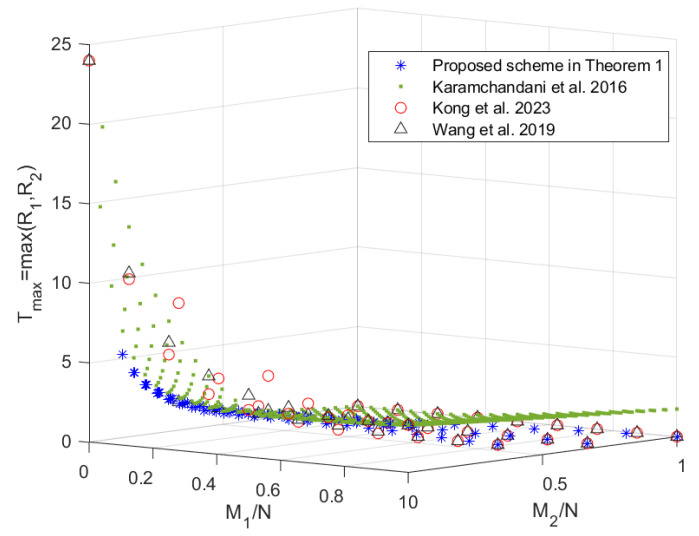 Figure 2
Figure 2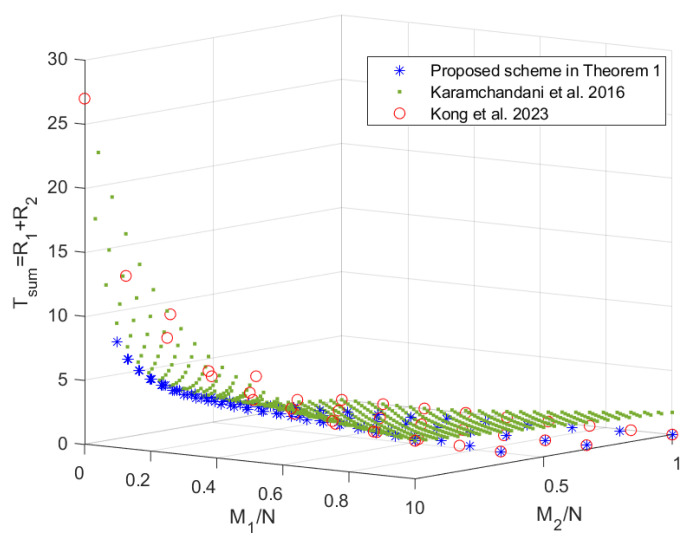 Figure 3
Figure 3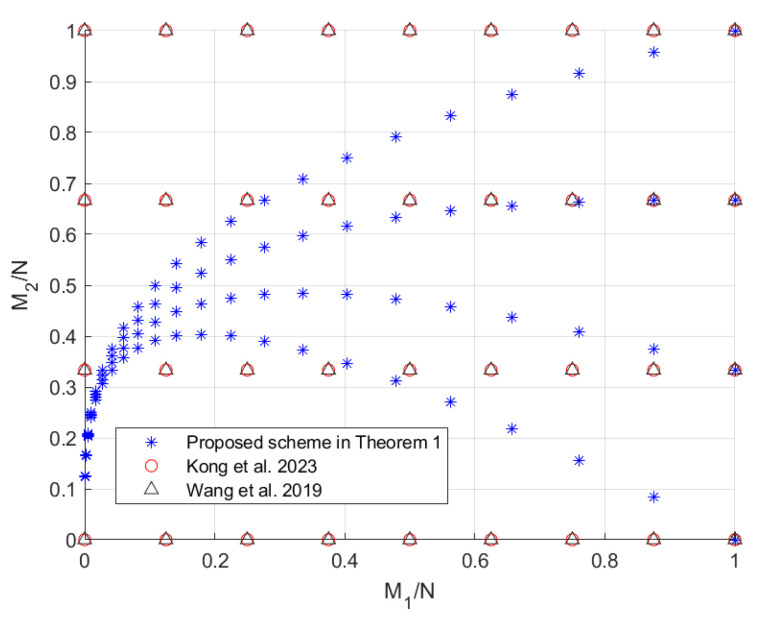 Figure 4
Figure 4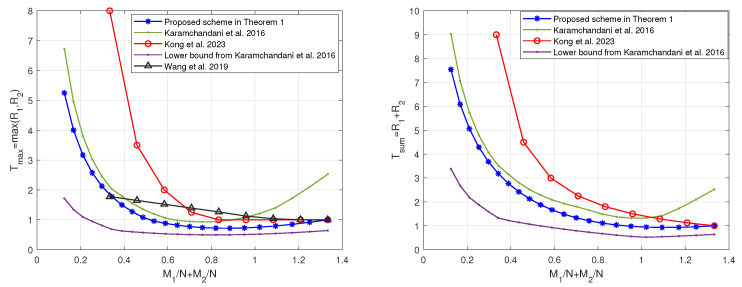 Figure 5
Figure 5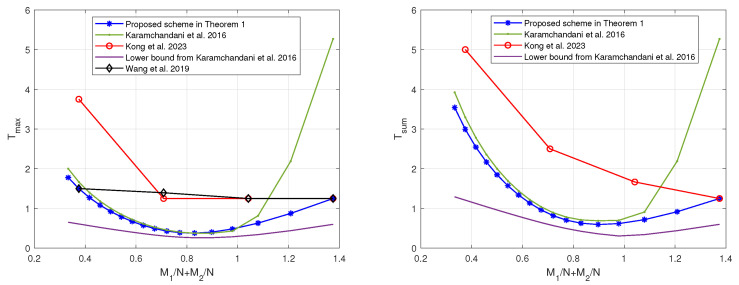 Figure 6
Figure 6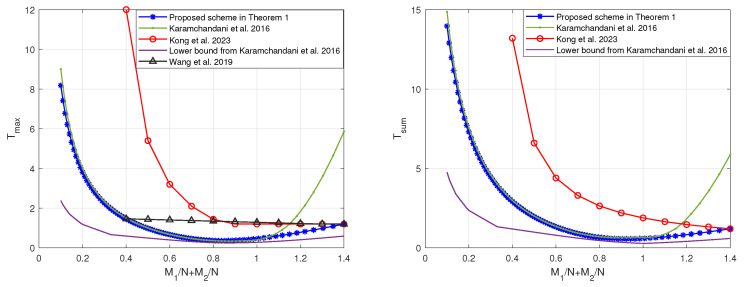 Figure 7
Figure 7- —Guangxi Natural Science Foundation
- —National Natural Science Foundation of China
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsCaching and Content Delivery · Cooperative Communication and Network Coding · Opportunistic and Delay-Tolerant Networks
1. Introduction
With the development of the Internet, video and social media traffic occupy the main part of the network, leading to serious congestion. Due to the unbalanced distribution of network traffic over time, caching technology has been proposed to alleviate network congestion. In [1], Maddah-Ali and Niesen (MN) proposed a coded caching scheme (referred to as the MN scheme) for the caching system: a server containing N files is connected to K users through an error-free shared link, and each user has an isolated cache of size M files. A coded caching scheme operates in two phases. In the placement phase, each file is divided into F packets, some of which are stored in each user’s cache according to a certain strategy. The quantity F is referred to as the subpacketization. In the delivery phase, network coding techniques are utilized to combine the packets requested by multiple users into multicast messages for transmission, such that each user can rebuild their desired file. The worst-case normalized transmission amount in the delivery phase is referred to as the transmission load R. Coded caching realizes multicast transmission for multiple users with different demands, which can effectively reduce the transmission load compared to uncoded caching. The MN scheme is optimal under uncoded placement when [2,3,4], and is order optimal within a factor of 2 with respect to the information-theoretic lower bound [5]. However, the subpacketization of the MN scheme increases exponentially with the number of users. In order to reduce the subpacketization, Shanmugam et al. [6] proposed a grouping method, which divides the users into several groups and applies the MN scheme to each group. Yan et al. [7] proposed a combinatorial structure called a placement delivery array (PDA) to represent coded caching schemes. The MN scheme can be represented by a special class of PDA, which is referred to as the MN PDA. Based on the concept of PDA, several coded caching schemes were proposed in [7,8,9,10,11,12]. Other combinatorial structures, including linear block codes [13], special -free hypergraphs [14], Ruzsa-Szeméredi graphs [15], projective geometry [16], combinatorial designs [17], and rainbow structures [18], have also been utilized in the design of coded caching schemes.
1.1. Two-Layer Hierarchical Network Model and Related Works
In practical applications, most caching systems consist of multiple layers. This paper considers the ( ) two-layer hierarchical network proposed in [19], as shown in Figure 1. There is a single server connected to mirrors through an error-free broadcast link. Likewise, each mirror is connected to users, so there are users in total. The server contains N equal-size files denoted by . Each mirror and each user have a cache memory of size and files, respectively. The j-th user attached to the i-th mirror is denoted by user (i, j), where , .
The network operates in two phases:
- Placement Phase: Each file is split into F packets with equal size, i.e., ; then, the mirrors and users cache some packets of each file. Denote the content cached by the i-th mirror and user by and , respectively. In this phase, the server has no knowledge of the users’ future requests.
- Delivery Phase: Each user randomly requests a file from the server, assuming that user requests the file , the request is denoted by . The server broadcasts coded messages of total size files to all mirrors, and each mirror broadcasts coded messages of total size files to all its attached users, such that each user can rebuild their desired file. is referred to as the transmission load from the server to the mirrors, and is called the transmission load from each mirror to its attached users.
Notice that a parallel transmission may exist between the server and mirrors due to the orthogonal links between the two layers. Thus, in a two-layer hierarchical network, if the server and all mirrors concurrently send symbols through all transmission slots, then the corresponding coding delay is
If there exists a mirror which starts transmission after the server finishes its transmission, the coding delay is
The goal is to design coded caching schemes with the coding delay or as small as possible.
For the two-layer hierarchical network, Nikhil Karamchandani et al., in [19], divided each file in the server into an fraction and fraction, and divided each user cache memory into a fraction and fraction. By applying the decentralized MN scheme to the two parts of the files separately, the achieved transmission loads are as follows:
where
It was shown that and are simultaneously approximately minimized when and , where
When and , Wang et al. [20] proposed a centralized coded caching scheme that leverages idle transmission time resources by constructing concurrent transmissions between the two layers, achieving the following maximum coding delay:
where
and . It was shown that is approximately optimal when and , where
Zhang et al. [21] improved the scheme in [19] by jointly designing the data placement and delivery in two layers, effectively avoiding the transmission of any content already stored by the users. On this basis, Kong et al. [22] defined a combinatorial structure called a hierarchical placement delivery array (HPDA) to design hierarchical coded caching schemes, and proposed a transformation from two PDAs to an HPDA. When the two PDAs are chosen from the MN PDA, the resulting scheme is shown in Lemma 1, which aligns with the centralized scheme in [23], and achieves a smaller and the same compared to the scheme in [21]. Based on the definition of HPDA, Rashid Ummer et al. [24] designed two hierarchical coded caching schemes via t-designs. In addition, Pandey et al. [25] considered a hierarchical coded caching problem with coded placement. A wireless scenario was considered in [26,27], where each mirror connects to users via a wireless channel.
Lemma 1([22]). When and , there exists a hierarchical coded caching scheme with transmission loads , where .
1.2. Contribution and Organization
In this paper, we consider the ( ) two-layer hierarchical network proposed in [19]. Most existing schemes focus on creating as many multicast opportunities as possible among users connected to the same mirror, thus reducing the load from the mirror to its connected users (i.e., ), without fully leveraging the mirror and user caches to create multicast opportunities among all users. We aim to design a coded caching scheme for a two-layer hierarchical network to further reduce the coding delays and . To this end, we first treat the mirrors and users as cache nodes of the same type, i.e., the cache memory of each mirror is regarded as an additional part of its connected users’ cache, then the server broadcasts messages to all mirrors according to a -user MN PDA in the first layer. In the second layer, each mirror first cancels the useless packets (if any) in the received useful messages and forwards them to its connected users, such that each user can decode the requested packets not cached by the mirror, then broadcasts coded subpackets to its connected users according to a -user MN PDA, such that each user can decode the requested packets cached by the mirror. The proposed scheme is extended to a heterogeneous two-layer hierarchical network, where the number of users connected to each mirror is different. Performance analysis showed that both the achieved coding delays and of the proposed scheme are lower than those of existing schemes.
The rest of this paper is organized as follows: Section 2 introduces the definition of PDA and related results. Section 3 shows the main results of this paper. Section 4 presents an illustrative example. Performance analysis is provided in Section 5, and Section 6 concludes this paper.
Notations:
- For any integers a and b with , we define and .
- For any positive integers c, we define .
- For two integers , if , is the binomial coefficient defined as , and we let if or or .
- For any array , represents the element in the i-th row and j-th column of , where and .
To improve readability, we add Table 1 to summarize frequently used symbols.
2. Placement Delivery Array
This section reviews the definition of PDA and the relationship between a PDA and a coded caching scheme.
Definition 1([7]). For any positive integers K, F, Z, S, an array with alphabet is called a placement delivery array (PDA) if it satisfies the following conditions:
- C1. The symbol “∗” appears Z times in each column;
- C2. Each integer occurs at least once in the array;
- C3. For any two distinct entries and , if , then and .
If each integer occurs exactly g times in a PDA, the PDA is called a g-regular PDA or g-PDA.
In a PDA, the symbol “∗” in the j-th row and k-th column indicates that the k-th user stores the j-th packet of all files in the placement phase. The integer in the j-th row and k-th column indicates that the k-th user does not store the j-th packet of all files. The requested packets represented by the same integer in the PDA are sent to the users after the xoring operation in the delivery phase. Condition C1 implies that the memory ratio of each user is . Condition C3 ensures that each user can decode its requested packet, since it has cached all the other packets in the received coded message. Condition C2 implies that the number of coded messages broadcast by the server is exactly S, each of size file, so the transmission load is .
Lemma 2([7]). Given a PDA, there exists a coded caching scheme with user memory ratio , subpacketization F and transmission load .
When , the MN PDA corresponding to the MN scheme is defined as follows: for any and for any with ,
where is an injection from to . For example, when and , the MN PDA is as follows:
Lemma 3([7]). For any positive integers K and t with , the MN PDA is a - PDA.
3. Main Results
In this section, we propose a coded caching scheme for a two-layer hierarchical network using two MN PDAs. The first MN PDA is for all the users, which fully utilizes the cache memory of all mirrors and users to create multicast opportunities among all users. The second MN PDA is for each group of users connected to the same mirror, which fully utilizes user caches to create multicast opportunities within each group. The main result is as follows:
Theorem 1. In the two-layer hierarchical network, let , for any , , there exists a coded caching scheme with
Proof. For any and , there is a - MN PDA and a - MN PDA , where , , , , , . The PDA is divided into subarrays, i.e., , where contains columns for each . The hierarchical coded caching scheme in Theorem 1 is generated based on the PDA and as follows:
- Placement Phase: Each file is split into F packets, i.e., . The j-th packet of each file is cached by the -th mirror if each element of the j-th row in the subarray is “∗”, i.e.,
Since the number of rows in each consisting entirely of “∗”s is , the memory ratio of each mirror is
The cached content of user consists of two parts, i.e.,
where is not cached by the -th mirror and is a subset of the content cached by the -th mirror. Specifically, the j-th packet of each file is cached by user if it is not cached by the -th mirror and the element at the j-th row and -th column of the subarray is “∗”, i.e.,
Each packet cached by the -th mirror is further divided into subpackets, i.e., for any , we have . The subpacket is cached by user if the corresponding packet is cached by the -th mirror and the element at the h-th row and -th column of is “∗”, i.e.,
Hence, the memory ratio of each user is
- Delivery Phase: Each user requests a file from the server, assuming that user requests the file . The transmission from the server to the mirrors is according to the PDA . Specifically, for any integer , the server sends
to the mirrors. Therefore, the transmission load from the server to the mirrors is
The transmission from each mirror to the attached users consists of two parts. First, each mirror cancels useless packets (if any) in the received useful messages using the cached content, then forwards them to the attached users. The number of messages forwarded by each mirror is . Second, each mirror transmits its cached contents to its attached users according to the PDA . Specifically, for any packet index j satisfying that the j-th packet of each file is cached by the -th mirror, i.e., where , for any integer , the -th mirror sends
to all its attached users. Hence, the transmission load from each mirror to its attached users is
By using the messages forwarded by the -th mirror, user can recover each requested packet not cached by the -th mirror, since is a PDA. By using the messages in (8), user can recover each requested packet cached by the -th mirror, since is also a PDA. Hence, each user can recover its desired file. □
The scheme in Theorem 1 can be extended to a heterogeneous scenario where the number of users connected to each mirror may vary. Precisely, there is a central server containing N files connected to A mirrors. For any , there are users connected to the i-th mirror. For any , the j-th user connected to the i-th mirror (denoted by user ) has a cache memory of size files and the i-th mirror has a cache memory of size files. This scenario is called a heterogeneous two-layer hierarchical network.
For the heterogeneous two-layer hierarchical network, we choose a MN PDA , where , , , , and . is divided into A subarrays, i.e., , where contains columns. For any , we choose an MN PDA where , , and .
In the placement phase, each file is split into F packets, i.e., . The f-th packet of each file is cached by the i-th mirror if the f-th row of the subarray consists entirely of “∗”s. Then, the memory ratio of the i-th mirror is
The cached content of user includes two parts. The first part is completely non-cached by the i-th mirror. That is, the f-th packet of each file is cached by user if it is not cached by the i-th mirror and . The second part is a subset of the content cached by the i-th mirror. That is, each packet cached by the i-th mirror is further divided into subpackets, i.e., , and the h-th subpacket of is stored by user if . Therefore, the total memory ratio of user is
In the delivery phase, the server broadcasts S coded messages to the mirrors according to the PDA , thus the transmission load from the server to the mirrors is
For any , the i-th mirror first cancels useless packets (if any) in the received useful messages by using cached content and forwards them to the attached users. The number of messages forwarded by the i-th mirror is . Then, the i-th mirror broadcasts coded subpackets to the attached users according to . Hence, the total transmission load from the i-th mirror to its connected users is
Since and are all PDAs, each user can decode its desired file. The following result is obtained:
Theorem 2. For the heterogeneous two-layer hierarchical network, there exists a coded caching scheme with the memory ratio of the i-th mirror
the memory ratio of the j-th user connected to the i-th mirror
the transmission load from the server to the mirrors
and the transmission load from the i-th mirror to the attached users
where , , , and .
Note that when , and , the scheme in Theorem 2 reduces to the scheme in Theorem 1.
4. An Illustrative Example for Theorem 1
For the ( ) two-layer hierarchical network where , we have . By choosing , the MN PDA is shown in (9), where , , and . is divided equally into subarrays, each with columns, i.e., .
By choosing , the MN PDA is shown in (10), where , , and .
The placement and delivery phases of the hierarchical coded caching scheme are generated by the PDA in (9) and in (10), as follows:
- Placement Phase: Each file is split into packets, i.e., . The j-th packet of each file is cached by the -th mirror if each element of the j-th row in the subarray is “∗”. From (3) and (9), the cached content of each mirror is as follows:
thus, the memory ratio of each mirror is .The cached content of user consists of two parts, i.e., , where the first part is not cached by the -th mirror, and the second part is a subset of the content cached by the -th mirror. From (5) and (10), the first part of the cached content of each user is as follows:
Each packet cached by the -th mirror is further divided into subpackets, i.e., for any , we have . From (6), (10) and (11), the second part of the cached content of each user is as follows:
Hence, the memory ratio of each user is .
- Delivery Phase: Each user requests a file from the server, assuming the request vector is
i.e., user request respectively. The transmission from the server to the mirrors is according to the PDA in (9). Specifically, the server sends
to the mirrors from (7) and (9). Therefore, the transmission load from the server to the mirrors is .The transmission from each mirror to the attached users consists of two parts. First, each mirror cancels useless packets (if any) in the received useful messages by using the cached content, then forwards them to the attached users. Specifically, the first mirror cancels in to obtain , cancels in to obtain , then forwards to user and . The second mirror cancels in to obtain , cancels in to obtain , then forwards to user and . Second, each mirror transmits coded subpackets to the attached users according to the PDA in (10). Specifically, the first mirror sends
to its attached users, and the second mirror sends
to its attached users from (8), (10) and (11). Thus, the transmission load from each mirror to its attached users is .
After receiving the messages from the connected mirror, each user can recover their desired file. For example, let us consider user who requests the file . First, it can decode from , since it caches . It can decode from , since it caches . It can decode from , since it caches and . Second, it can obtain subpacket from , since it caches where , thus obtaining the packet . The remaining packets and are cached by user . Thus, user can recover the desired file . The decodability for other users is similar.
5. Performance Analysis
In this section, we compare the scheme in Theorem 1 with the schemes in [19,20,22], since the scheme in [24] does not provide an exact expression for and the scheme in [22] (which is consistent with the centralized scheme in [23]) outperforms the scheme in [21]. When , the tradeoffs of the coding delays with the memory ratios of each mirror and user, i.e., and , are shown in Figure 2 and Figure 3, respectively. Note that the scheme in [20] only focuses on the maximum coding delay . The scheme in [19] is applicable to arbitrary memory ratios, while the scheme proposed in Theorem 1 and the schemes in [20,22] are applicable to specific memory ratios, which are shown in Figure 4. It can be seen from Figure 2 and Figure 3 that the scheme in Theorem 1 achieves lower coding delays and than the schemes in [19,20,22]. To see this more clearly, we restrict the scheme in [19] to the memory ratio points applicable to the scheme in Theorem 1, and the obtained tradeoffs of the coding delays and with the sum of memory ratios are shown in Figure 5. It can be seen that under the same sum of memory ratios, both the coding delays and of the scheme in Theorem 1 are lower than those of the schemes in [19,20,22]. Moreover, when the sum of memory ratios is relatively large or small, the two coding delays of the scheme in Theorem 1 are significantly reduced compared to the scheme in [19]. This is primarily due to the fact that, in the first layer of communication, we have fully leveraged the caches of both the mirrors and the users to create as many multicast opportunities as possible among all users; in the second layer of communication, we once again make full use of the users’ caches to maximize multicast opportunities within each group of users connected to the same mirror.
Similarly, when or , by restricting the scheme in [19] to the memory ratio points that are compatible with the scheme in Theorem 1, the tradeoffs of the coding delays and with the sum of memory ratios are as shown in Figure 6 and Figure 7, respectively. In can be seen that, regardless of the relative sizes of and , our proposed scheme is capable of achieving reduced coding delays across a majority of memory ratio points.
6. Conclusions
In this paper, we proposed a novel coded caching scheme for the two-layer hierarchical network by utilizing two MN PDAs. The first MN PDA is for all users, which fully utilizes the cache memory of all mirrors and users to create as many multicast opportunities as possible. The second MN PDA is for a group of users connected to the same mirror, which fully utilizes the user’s cache to create multicast opportunities within the group. Moreover, the proposed scheme was extended to a heterogeneous two-layer hierarchical network. Numerical comparisons showed that the proposed scheme achieved lower coding delays and than existing schemes in [19,20,22] at most memory ratio points.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Maddah-Ali M.A. Niesen U. Fundamental Limits of Caching IEEE Trans. Inf. Theory 2014602856286710.1109/TIT.2014.2306938 · doi ↗
- 2Wan K. Tuninetti D. Piantanida P. On the optimality of uncoded cache placement Proceedings of the 2016 IEEE Information Theory Workshop (ITW)Cambridge, UK 11–14 September 201616116510.1109/ITW.2016.7606816 · doi ↗
- 3Wan K. Tuninetti D. Piantanida P. An Index Coding Approach to Caching with Uncoded Cache Placement IEEE Trans. Inf. Theory 2020661318133210.1109/TIT.2020.2967753 · doi ↗
- 4Yu Q. Maddah-Ali M.A. Avestimehr A.S. The Exact Rate-Memory Tradeoff for Caching with Uncoded Prefetching IEEE Trans. Inf. Theory 2018641281129610.1109/TIT.2017.2785237 · doi ↗
- 5Yu Q. Maddah-Ali M.A. Avestimehr A.S. Characterizing the Rate-Memory Tradeoff in Cache Networks Within a Factor of 2IEEE Trans. Inf. Theory 20196564766310.1109/TIT.2018.2870566 · doi ↗
- 6Shanmugam K. Ji M. Tulino A.M. Llorca J. Dimakis A.G. Finite-Length Analysis of Caching-Aided Coded Multicasting IEEE Trans. Inf. Theory 2016625524553710.1109/TIT.2016.2599110 · doi ↗
- 7Yan Q. Cheng M. Tang X. Chen Q. On the Placement Delivery Array Design for Centralized Coded Caching Scheme IEEE Trans. Inf. Theory 2017635821583310.1109/TIT.2017.2725272 · doi ↗
- 8Yan Q. Tang X. Chen Q. Cheng M. Placement Delivery Array Design Through Strong Edge Coloring of Bipartite Graphs IEEE Commun. Lett.20182223623910.1109/LCOMM.2017.2765629 · doi ↗