Workload of Queueing Systems with Autocorrelated Service Times
Andrzej Chydzinski

TL;DR
This paper analyzes queueing systems where service times are autocorrelated, deriving new formulas for workload-related metrics and showing that average workload can be unexpectedly large.
Contribution
New formulas for workload probability density, tail, average, and entropy in autocorrelated service time queueing systems are derived.
Findings
The average workload can exceed several times the product of average queue size and average service time.
Formulas for workload metrics are derived for both time-dependent and steady-state cases.
Numerical examples illustrate the behavior of the derived workload formulas.
Abstract
The queuing model with autocorrelated service times is studied with respect to workload, i.e., the time needed to serve all the customers in the queue. Specifically, new formulas for the probability density of workload, its tail, the average value, and entropy are derived and illustrated using numerical examples. Both time-dependent and steady-state cases are covered. It is also demonstrated that the average workload may reach surprisingly large values, exceeding several times the product of the average queue size and the average service time.
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
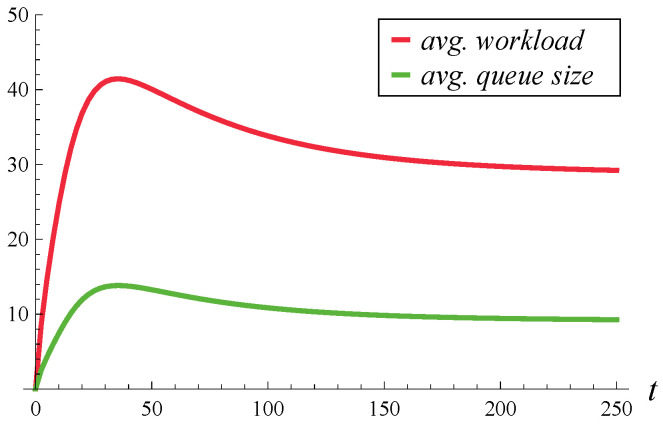 Figure 1
Figure 1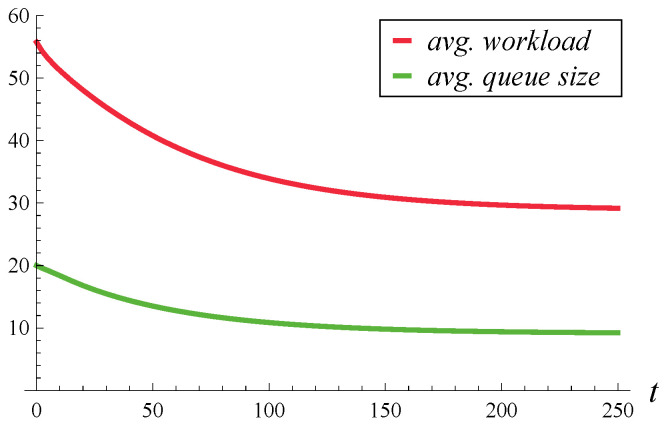 Figure 2
Figure 2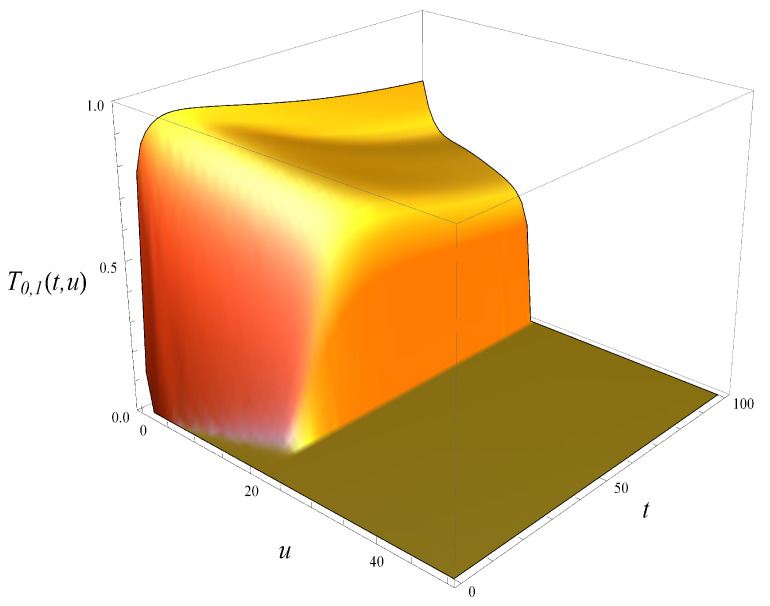 Figure 3
Figure 3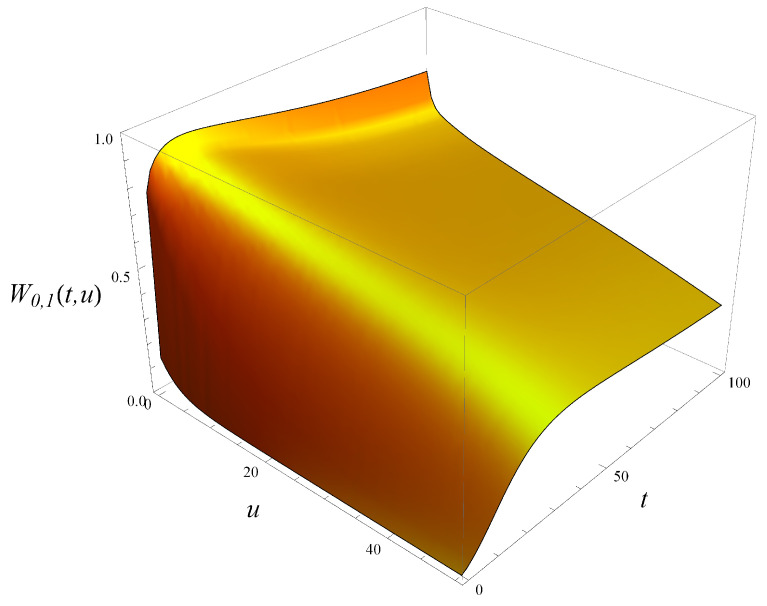 Figure 4
Figure 4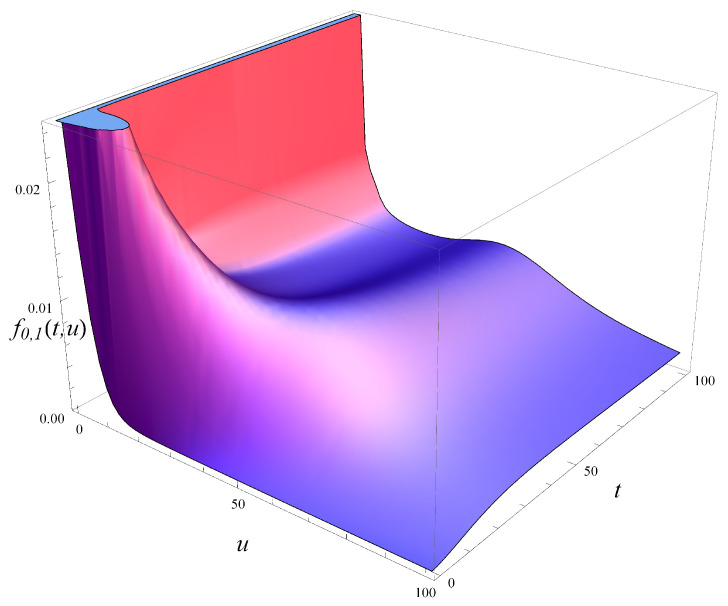 Figure 5
Figure 5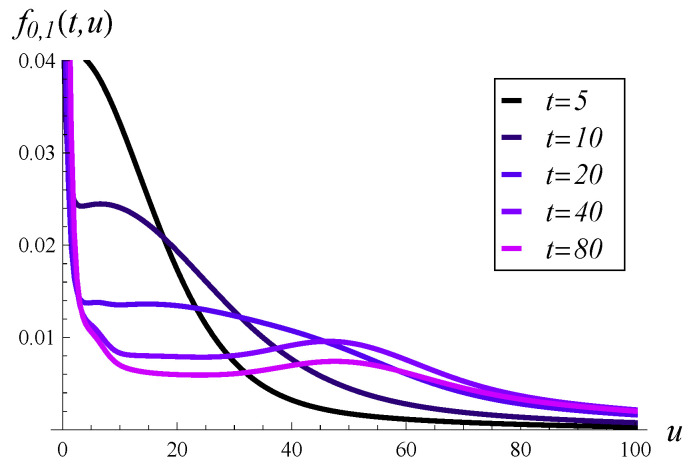 Figure 6
Figure 6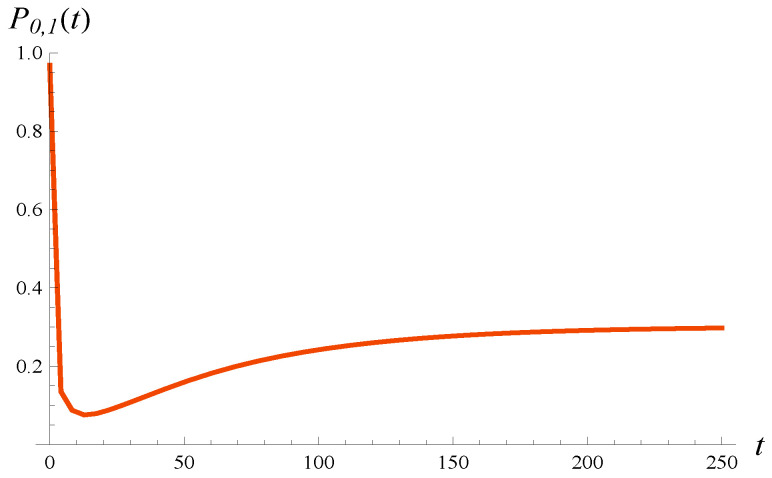 Figure 7
Figure 7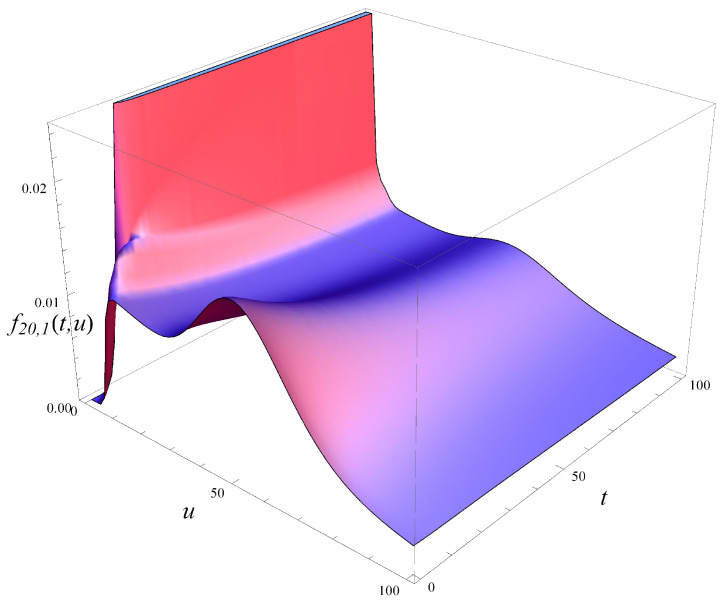 Figure 8
Figure 8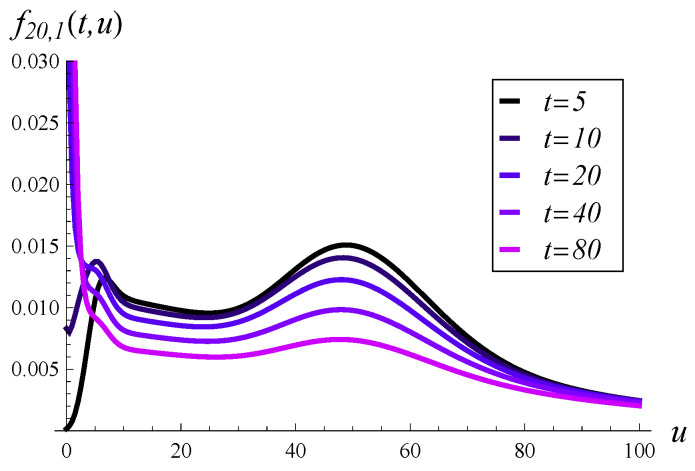 Figure 9
Figure 9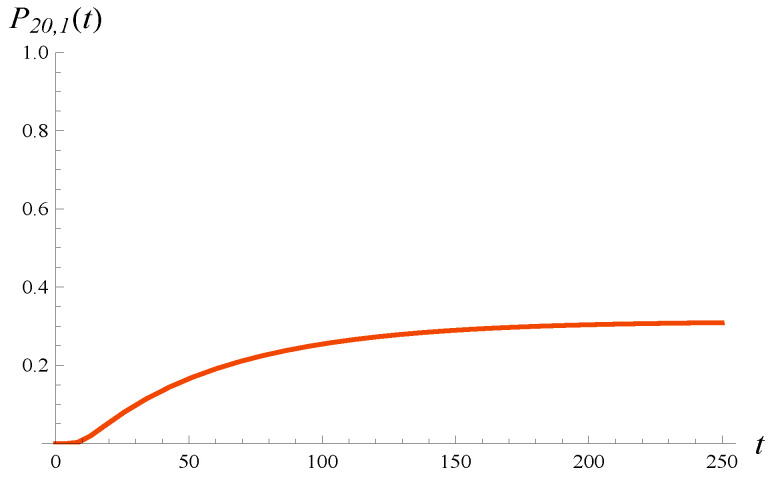 Figure 10
Figure 10Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsAdvanced Queuing Theory Analysis · Simulation Techniques and Applications · Healthcare Operations and Scheduling Optimization
1. Introduction
In every queueing theory textbook, the study of the performance of a system begins with the queue size—its distribution and average value are usually derived first. The reason for this is perhaps that, in most real-life queueing systems, the queue size is the easiest aspect to observe and interpret.
Another important characteristic of queueing systems is workload, understood as the total time required to serve all the customers in the queue, i.e., the time needed to empty the system completely through the service process, assuming new arrivals are suspended.
In simple queueing systems, without autocorrelation in arrival or service processes, and with small variances of interarrival and service times, workload is roughly proportional to the queue size. Specifically, if the queue size is X and the average service time is , the workload is approximately . In the M/M/1 queueing system, workload is exactly equal to .
However, when the service times are autocorrelated, such intuitive calculations of workload can be completely inaccurate. As will be seen, workload can also be equal to rather than . In other words, knowledge of the queue size provides no information about the system workload when the service times are autocorrelated.
Because of that, in this paper, we will derive several formulas characterizing workload in the queueing model with autocorrelated service times. Specifically, formulas will be derived for the tail of the workload distribution, the probability density of workload, its entropy, and the average value. These formulas will encompass both time-dependent and steady-state workloads. The considered queueing model is universal in the meaning that the interarrival time distribution is general, whereas service times are modeled by the Markovian service process. This feature allows for an alignment of the autocorrelation function of the model with an empirical autocorrelation function. Finally, in addition to presenting new theorems and formulas, numerical examples will be provided to illustrate various workload-related characteristics and compare them with the average queue size.
There are several convincing reasons to study models with autocorrelated service times. For example, human-operated queueing systems may exhibit autocorrelation of service times caused by the operator’s tiredness, resulting in longer service times, or due to his/her learning process, which shortens the service times. Another reason for service autocorrelation in such systems could be the similarity of customers arriving at the queue. For instance, customers calling a call center about the same problem may require similar attendance times. In telecommunications, consecutive packet sizes can be correlated, leading to autocorrelated transmission times. In computing, autocorrelated task execution can result from resource sharing. Specifically, when a service is under heavy load caused by external tasks, it can decelerate the service in the queue of interest, leading to long, autocorrelated service times.
In short, the principal contributions of this study are as follows:
- –a theorem on the tail of the distribution of workload at arbitrary time;
- –a theorem on the probability density of workload at arbitrary time;
- –a theorem on the average workload at arbitrary time;
- –numeric examples of these characteristics, including a demonstration of counterintuitive values of workload when paired with the queue size.
The following organization applies to the rest of the article. In Section 2, the related work is reviewed, whereas in Section 3, the queueing model in question is formally defined. Section 4 is devoted to the derivation of the workload distribution. Its main results are Theorems 1 and 2, concerning the tail and the probability density of workload, respectively. In addition to that, the entropy of workload is obtained, basing on Theorems 1 and 2. In Section 5, the average workload is derived, with the final result of this section presented in Theorem 3. In Section 6, numeric examples are provided. These include sample calculations of the probability density, distribution tail, entropy, and average workload. Section 7 concludes the study with a few final remarks.
2. Related Work
To the author’s recognition, all the main results of this study, i.e., Theorems 1–3 and numerical examples, are new.
The vast majority of previous work on systems with Markovian service processes has focused solely on steady-state calculations.
Specifically, in [1], the queue size distribution in a model with a finite buffer is derived. In [2], the decay rates of large queue sizes in infinite-buffer models are investigated. In [3], the queue size and response time distributions are obtained for a model with a finite buffer and group service process. In [4], the performance of systems with finite and infinite buffers is evaluated using the queue size distribution along with the response time distribution. In [5], multiple servers with Markovian service processes are introduced. For such a model, the queue size distribution is obtained and accompanied by the idle and partly-idle period calculations, i.e., periods when every server is idle or when some servers are idle, respectively. In [6], the limit of the customer blocking probability, as the buffer size approaches infinity, is studied.
Study [7] is devoted to a differently defined service process. Namely, after an idle period, the service process returns to a fixed phase. Thus, in this model, the autocorrelation of service times isolated by an idle period is broken. Typically, in Markovian service processes, it is assumed that the correlation of service times is preserved through the idle period, i.e., the service phase remains the same as it was just before the idle period. However, both approaches may be useful in practice.
In [8], the queue with group arrivals and a finite buffer is investigated under two possible acceptance rules. The first assumes that, when the buffer is nearly full, part of the arriving group of customers can be accepted, filling the buffer completely, while the remainder is blocked. The second rule blocks the entire group in such cases. Several performance characteristics are derived for both variants, i.e., the queue size and waiting time distributions, and the blocking probability for the first, the last, and an arbitrary customer in an arriving group.
In [9], the model with group services and an infinite buffer is investigated with respect to the queue size distribution at arrival and arbitrary times. Additionally, the response time is calculated. In [10], roots of the characteristic equation are used to derive the queue size distribution for a model with single services and an infinite buffer. In [11], the response time and the autocorrelation of inter-departure times are studied in the infinite buffer model.
Two articles [12,13] focus on models with group arrivals and infinite buffers. One [12] examines the queue size along with idle and busy periods, while the other [13] investigates the distribution of waiting times.
The model with group arrivals is studied again in [14], but under a finite-buffer assumption. For this model, the average waiting time of a random customer, as well as the first and last customers in a group, is obtained. Additionally, the probability of blocking an arbitrary customer and the probability of blocking k or more consecutive customers during a busy period are derived. In [15], the model with group services and a finite buffer is revisited, aiming to optimize a profit function that combines all key performance characteristics, e.g., average queue size, waiting time, blocking probability, and others.
Article [16] compares two models with Markovian service processes regarding their queue sizes. In the first model, the service phase remains constant during idle periods, whereas in the second, it changes according to a Markov chain. In both models, group service is assumed.
The only published study involving the time-dependent analysis of a model with a Markovian service process [17] is devoted solely to the queue size. As will be seen, knowledge of the queue size provides no insight into workload when service times are autocorrelated.
Lastly, it is worth noting that the references discussed above focus on models with general interarrival distributions, as is the case here. Other studies with Markovian service processes are based either on specific interarrival distributions (e.g., Poisson, MAP, BMAP) or on discrete queueing systems with discrete-time Markovian service, e.g., [18,19,20,21,22,23,24,25,26,27].
3. Model
The model of interest is the model of a queueing system with a single server. Specifically, the next customer arrives to the queue after time is distributed according to , where is some distribution function on , not further specified, with the average value: ,
and the Laplace–Stieltjes transform,
All interarrival intervals are mutually independent.
The queue of customers is formed following the arrival order and served from the head.
Service times of customers are mutually dependent and follow the Markovian service process [4]. Namely, there is an underlying random process , called the service phase at time t. may assume M values, . To fully parameterize , we need two matrices of size , , and , such that is negative on the diagonal and nonnegative off the diagonal, and is nonnegative, while is a transition-rate matrix, with every row summing to 0.
The evolution of produces various service times of different customers, in the interdependent manner, as follows. When the number of customers in the system at some t is non-zero and , then, immediately after t, at , the service phase may jump to j with probability , and the ongoing service of a customer is continued, or the phase may jump to j with probability , and the present service is completed, so the customer is departed from the system.
If the number of customers in the system becomes zero after a departure, then the evolution of the service phase is terminated for the whole idle period. Upon a new customer arrival after that period, starts evolving again according to the rule given in the previous paragraph, beginning with the same phase it had just before the idle period. (Note that from this definition it follows that is not a Markov process).
The system volume is finite and equal to B customers, including the one being served. If, at the time of a new arrival, there are B customers in the system, the new customer is blocked. Specifically, he/she leaves unserved the system and never arrives again.
It is easy to check that the average service time is
where e denotes the column vector of 1’s, whereas denotes the stationary vector of transition-rate matrix .
The correlation of two arbitrary service times can be computed in the same way as in the case of Markovian arrival processes (see, e.g., [28,29]). Specifically, we have
where is the k-th service time, is the service time which follows after other completed services, is the stationary vector for transition-rate matrix , is the identity matrix, and
In the derivations of the next section, a vital role will be undertaken by two characteristics of the service process, and . The former, , is defined as the probability that l customers are served in period , and the service phase is k at the end of the l-th service time, assuming and . The latter, , is defined as the probability that l customers are served in , and the service phase is k at time x, assuming and . It will subsequently be shown how these two characteristics can be calculated.
By , we will represent the queue size at t, including the customer under service, if applicable. We also adopt the convention that every time the phrase “queue size” is used, it means “including the customer under service, if any”.
Lastly, it is presumed that the first arrival time has distribution , i.e., the arrival process is not shifted at the time origin.
4. Workload Distribution and Entropy
Let denote workload at time t, i.e., the time needed to empty the system completely by the service process, assuming there were no new arrivals after t. Obviously, is a random variate, so it has to be characterized by the probability distribution. For technical reasons, it is easier to start with calculations of the tail of the distribution of , namely,
Having the tail, we can procure the distribution function of the workload:
We start with constructing integral equations for . Firstly, for an initially empty system, , and any , we have
This system is obtained by conditioning upon the time of arrival of the first customer, x. Indeed, when no customer is present, the service phase remains the same, i.e., j. When the first customers arrives, the service begins with this phase and a queue size of 1. Thus, the new tail of the workload distribution at time is .
Secondly, for an initially full system, , and any , we get
The first integral of (9) handles the condition of zero services completed in . Under such a condition, the tail of the workload distribution at time is because the customer arriving at x is blocked. The second integral of (9) handles the condition of l services completed in , where . Under such a condition, the size of the queue is reduced by time x, but not to zero. The new tail of the workload distribution at is because the customer arriving at x is allowed to the queue. The third integral of (9) handles the condition of B services completed in , which makes the system empty by x. Thus, counting the new customer arriving at x, the new tail of the workload distribution at is . The last component of (9) handles the condition of no new arrivals by t. Specifically, to have a non-zero tail of the workload distribution at t under this condition, the system must not become empty by t, which happens with the following probability:
Furthermore, under such condition, we have
which completes the explanation of (9).
For a partially occupied system, , and any , we obtain
Equation (12) can be explained in the same way as (9), with the exception that (12) has no analog of the first part of (9). This is because, in the case of , no customer can be blocked by the first arrival time, x.
Denoting
we can restate Equation (8) as
while (9) can be restated as
and (12) as
Employing the vector
and matrices
to (17), (18), and (19) yields
respectively, with
Before presenting the solution of system (23)–(25), it ought to be underlined that all the coefficient matrices in (23)–(25) can be calculated numerically. Specifically, , , and can be computed using the uniformization algorithm [30,31], whereas can be obtained using the formulas proven in [17], namely,
with
We can now move to finding the solutions of (23)–(25). Specifically, applying the lemma of [32], p. 200, we realize that the solution of (25) is
where vector is unknown, but independent of m, whereas
and 0 represents the square zero matrix. Inserting into (32) yields
Then, using (32) together with (33) and (36), we have
with
What is left to find is the unknown occurring in (37). After that, (37) will be fully solved. Fortunately, can be found by utilizing (37) with and leveraging (24) in addition to that. The final results can be gathered as follows.
Theorem 1. The transform of the tail of the workload distribution in the model with a Markovian service process is
where
while , , , , and are given in (15), (35), (26), (38), and (29), respectively.
Now we can proceed to calculations of the density of workload . By definition, we have
(As we can see, this definition is restricted to . The distribution of workload for will be discussed below).
Denote
and
We have obviously
Therefore, we have to compute the derivative of (39)–(41) with respect to u. In fact, variable u occurs in (39)–(41) only in and , defined in (26). In order to differentiate (26), we can use the well-known formulas
which give
The latter formula, accompanied with (39)–(41), delivers the final result.
Theorem 2. The transform of the probability density of the workload in the model with a Markovian service process is
where is given in (49).
Now we can proceed to the derivation of the entropy of the workload. To accomplish that, we have to observe first that density is defective; i.e., in general, it does not integrate to 1 with respect to u. This comes from the fact that if the queue is empty, which has a non-zero probability, then the workload is zero. Thus, the distribution of workload has an atom at . The size of this atom, , is the following:
In this way, the distribution of workload is in fact a mixture of a discrete distribution, which assumes only a value of 0, and a continues distribution, having probability density . The two-point mixing distribution is the following: .
Denote by the entropy of workload at time t given , while denotes the entropy of its discrete part, denotes the entropy of its continues part, and denotes the entropy of the mixing distribution. Adopting this notation yields
(see, e.g., Formula (7) in [33]). Furthermore, we have
and
Lastly, combining (54) with (55)–(57) and (53), we arrive at the final formula for the entropy of the workload:
where can be obtained from Theorem 1, while can be obtained from Theorem 2.
Indeed, Theorems 1 and 2 can be used to calculate numerically and for a specific t, as well as in the steady state, for . To calculate the steady-state values, and , we have to calculate numerically the limits of and , respectively, directly from Theorems 1 and 2. This follows from the well-known FVT theorem. To compute these characteristics at a specific t, we have to employ a numeric inversion formula for the transform [34].
5. Average Value
Define
For an initially empty system, , and any , we have
which can be rationalized in the same manner as (8). For an initially full system, , and any , we obtain
This equation differs from (9) only in the last term, which handles the condition of no new arrivals by t, which happens with probability . Under such a condition, the average workload at t equals . Analogously, for a partially occupied system, we obtain
System (60)–(62) has the same layout as (8), (9), and (12), except for free terms. Due to that, it can be solved correspondingly, with obvious modifications. Using the notation
the final solution has the following form.
Theorem 3. The transform of the average workload in the model with a Markovian service process is
where
6. Examples
In the numeric examples, the following parameter matrices of the Markovian service process are utilized:
For these matrices, the average service time is while the 1-lag autocorrelation is
The interearrival time has a hyperexponential distribution, with parameters (2, 0.4) and (0.75, 0.25), which gives the average interarrival time . Therefore, the system is fully loaded, with . Finally, the system capacity is 20 customers.
In Figure 1 and Figure 2, the evolution of the average workload and queue size over time is depicted. The average workloads were obtained from Theorem 3 proven here, while the average queue sizes were obtained from Theorem 2 of [17]. Figure 1 differs from Figure 2 by the initial system occupancy, which is 0 in Figure 1 and 20 in Figure 2. In both figures, the steady-state average queue size (i.e., the limit on the right-hand side) is 9.121, while the steady-state average workload is 28.834.
These numbers, and Figure 1 and Figure 2 in general, are quite surprising. Given that the average service time is 1, one might expect that the average queue sizes and average workloads should be close to each other, rather than differ by more than three times. Such a difference emphasizes the need for calculating the workload separately, as the queue sizes computed using the formulas of [17] provide no knowledge of workload.
The following explanation for such a large discrepancy between the average queue size and average workload can be proposed: In the Markovian service process, some service phases slow down the service process below the average, while others speed it up above the average. Moreover, when the autocorrelation is positive, as here, once the service is in a slow phase, it has a tendency to stay in this slow phase for a period of time, increasing the chances of a few long service times in a row. In addition to that, an arbitrarily chosen time t is more likely to be in a long service interval than in a short service interval. To put it differently, it is more likely to be in a slow service phase than in a fast service phase.
Therefore, an arbitrarily chosen t is not only more likely to be in a slow service phase, i.e., within a longer-than-average current service time, but also it is likely that a few subsequent services will also be long. This makes the tail of the workload quite heavy, much heavier than the tail of the queue size, which explains the discrepancy between the queue size and workload in Figure 1 and Figure 2.
To illustrate this further, in Figure 3 and Figure 4, both tails are depicted, i.e., the tail of queue size distribution defined as
and the tail of workload distribution defined in (6). As seen, the tail of workload in Figure 4 decreases much more slowly with u than the tail of the queue size, and this is true for every t.
Finally, the difference between the queue size and workload can also be observed from the information theory perspective. Namely, the entropy of the queue size distribution in the steady state equals to 2.11 nats. (This was calculated from Theorem 1 of [17]). On the other hand, the entropy of the workload distribution in the steady state is 3.63 nats, which was computed by means of Formula (58), with the help of Theorems 1 and 2. As seen, the entropy of the workload is much higher than the entropy of the queue size.
In Figure 5, the probability density of workload over time is depicted for an initially empty system. Five vertical slices of Figure 5, taken at different moments in time, are depicted in Figure 6. As seen in these figures, the probability mass is initially concentrated near , but it quickly spreads out as time passes. For a low t of just 20, there is already a significant portion of the probability mass beyond .
Note that the steady state has not yet been reached in Figure 5. As indicated in Figure 1, the steady state is reached at around .
As discussed in Section 5, the densities of workload presented in Figure 5 and Figure 6 are defective; i.e., they do not integrate to 1. The missing probability is , which is the probability of zero workload at time t. This probability is depicted in Figure 7. Its steady-state value is 0.312. It is interesting that the evolution of is not monotonic—it clearly has a minimum shortly after the system is activated.
In Figure 8, the probability density of workload is depicted over time, now for an initially full system. Five vertical slices of Figure 8, taken at different moments in time, are shown in Figure 9. As seen in these figures, the density function can assume a complicated shape, with multiple extrema. For a small t, there is no probability mass near , as the system occupancy is non-zero with a probability close to 1. However, this changes quickly with time.
Finally, in Figure 10, the probability that the workload is zero, which is the missing probability mass in the defective density of workload, is depicted over time. Now the evolution of is monotonic. It obviously converges to the same steady-state value as in Figure 7, i.e., 0.312.
7. Conclusions
We studied the queueing model with autocorrelated service times with respect to workload. The study was motivated by real queueing systems, in which such autocorrelation is quite common. The model we studied was universal in the meaning that the interarrival time distribution was general, while the service times were modeled by the Markovian service process, which allowed aligning the autocorrelation function of the model with an empirical autocorrelation function.
New formulas for the probability density of workload, its tail, entropy, and the average value were derived and illustrated through numeric examples, covering both time-dependent and steady-state workload of the system.
Among other findings, it was demonstrated that, in the model in question, workload can assume surprisingly large values, exceeding several times the product of the queue size and the average service time. This observation highlights the need to calculate workload as a separate characteristic. The queue size alone provides no insight into workload, as one might naively assume.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Bocharov P.P. Stationary distribution of a finite queue with recurrent flow and Markovian service Autom. Remote Control.199696678(In Russian)
- 2Alfa A.S. Xue J. Ye Q. Perturbation theory for the asymptotic decay rates in the queues with Markovian arrival process and/or Markovian service process Queueing Syst.20003628730110.1023/A:1011032718715 · doi ↗
- 3Chaplygin V.V. The mass-service G/BMSP/1/r Inf. Process.2003397108(In Russian)
- 4Bocharov P.P. D’Apice C. Pechinkin A.V. Salerno S. The stationary characteristics of the G/MSP/1/r queueing system Autom. Remote Control.20036428830110.1023/A:1022219232282 · doi ↗
- 5Albores-Velasco F.J. Tajonar-Sanabria F.S. Analysis of the GI/MSP/c/r queueing system Inf. Process.200444657
- 6Kim J. Kim B. Asymptotic analysis for loss probability of queues with finite GI/M/1 type structure Queueing Syst.200757475510.1007/s 11134-007-9045-6 · doi ↗
- 7Gupta U.C. Banik A.D. Complete analysis of finite and infinite buffer GI/MSP/1 queue—A computational approach Oper. Res. Lett.20073527328010.1016/j.orl.2006.02.003 · doi ↗
- 8Banik A.D. Gupta U.C. Analyzing the finite buffer batch arrival queue under Markovian service process: GIX/MSP/1/N Top 20071514616010.1007/s 11750-007-0007-2 · doi ↗