What you see is not what you get: Observed scale score comparisons misestimate true group differences
Bjarne Schmalbach, Ileana Schmalbach, Jochen Hardt

TL;DR
This paper shows that using observed scores to compare groups can lead to incorrect estimates of true differences, emphasizing the need for latent variable approaches in social sciences.
Contribution
The study demonstrates that observed sum scores misestimate true group differences by up to 25%, highlighting the limitations of traditional methods.
Findings
Cohen’s d values based on observed variance misestimate true group differences in 33 out of 70 cases.
The average misestimation is 25.0% or 0.048 standard deviations.
Scale reliability (McDonald’s ω) does not predict the effect size discrepancy.
Abstract
Social sciences of all kinds are interested in latent variables, their measurement, and how they differ between groups. The present study argues the importance of analyzing mean differences between groups using the latent variable approach. Using an open-access repository of widely applied personality questionnaires (N = 999,033), we evaluate the extent to which the commonly used observed sum score is susceptible to measurement error. Our findings show that Cohen’s d values based on the observed variance significantly misestimate the true group difference (based on just the factor score variance) in 33 of the 70 studied cases, and by an average of 25.0% (or 0.048 standard deviations). There was no meaningful relationship between the effect size discrepancy and scale reliability as measured by McDonald’s ω. We discuss the implications of these results and outline concrete steps that…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
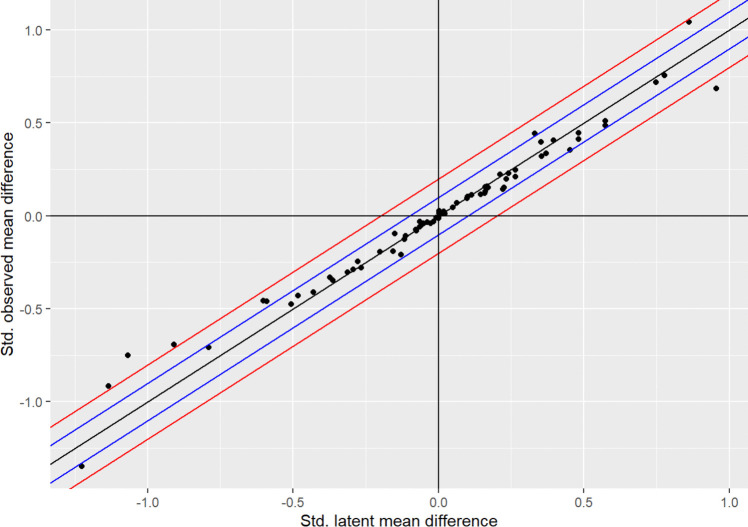 Figure 1
Figure 1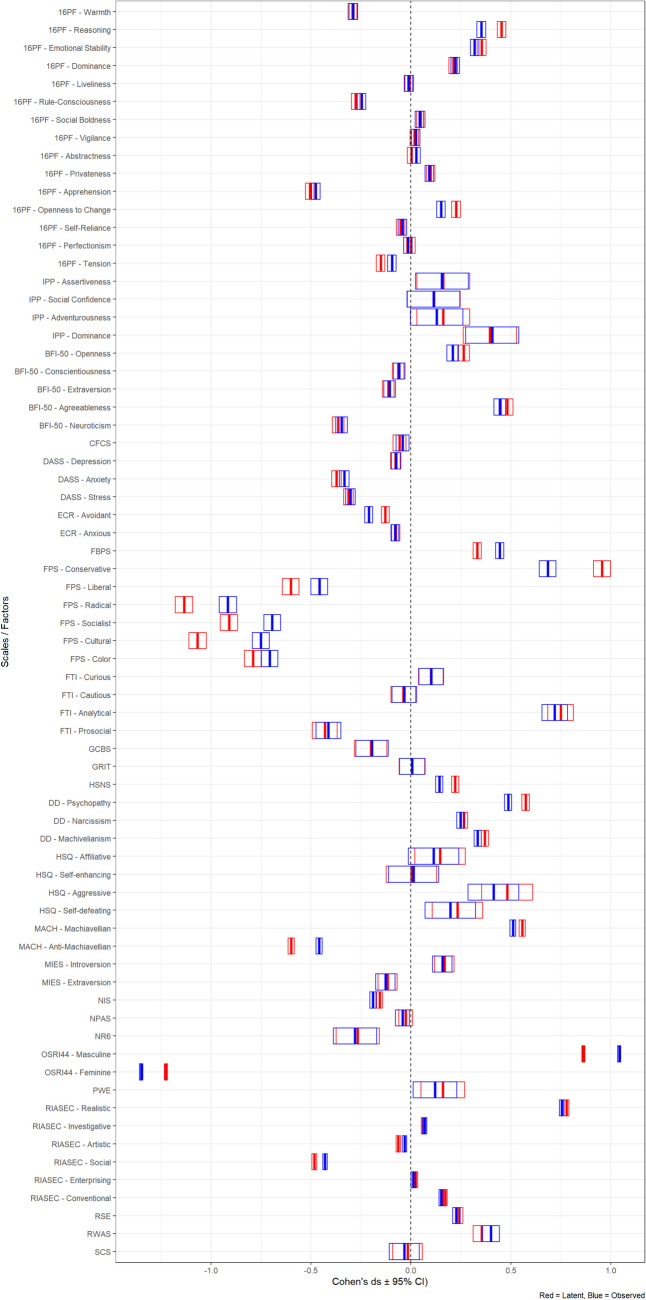 Figure 2
Figure 2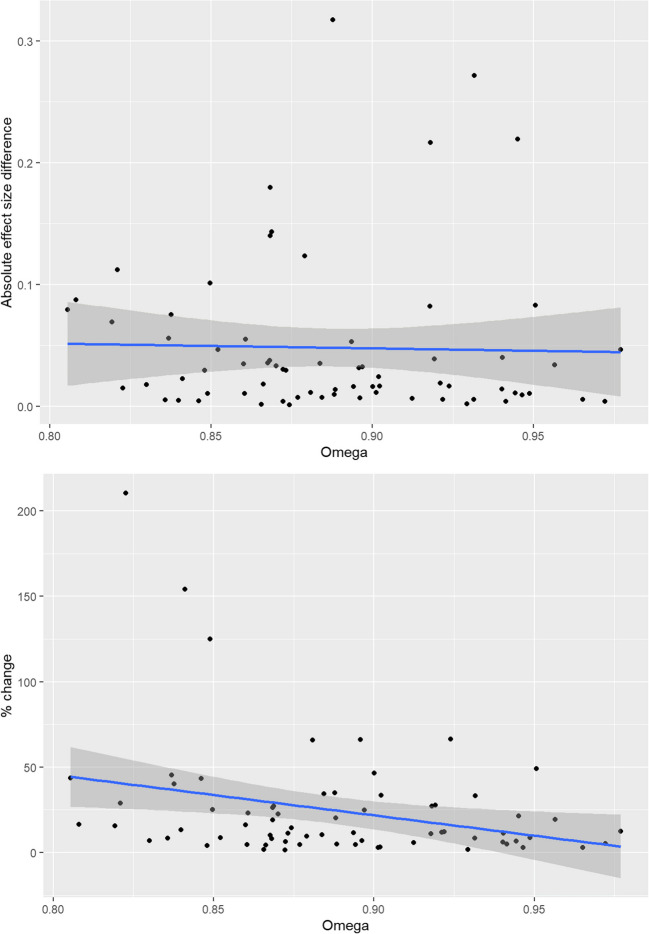 Figure 3
Figure 3- —Universitätsmedizin der Johannes Gutenberg-Universität Mainz (8974)
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsPersonality Traits and Psychology · Social and Intergroup Psychology · Cultural Differences and Values
Introduction
Item-based questionnaires are the backbone of many basic and applied research strands dealing with latent constructs, i.e., such concepts that cannot be directly observed or measured. Social and personality research in particular is known to rely heavily on self-report measures that ask for participants’ subjective evaluations of any given topic (Paulhus & Vazire, 2007). These individual evaluations are subsequently aggregated into a scale score and interpreted as an approximation of the latent construct in question. As such, these measures are absolutely indispensable for a vast array of social sciences (Flake et al., 2017). By and large, researchers simply take the sum or the mean of the observed item scores and use this score to conduct any further analyses. An article by McNeish and Wolf (2020)—along with the entertaining exchange it spawned (McNeish, 2023; Widaman & Revelle, 2023a, 2023b)—broadly discusses shortcomings (and potential advantages) to this approach versus a latent variable approach, which excises measurement error and focuses on the true score (see also Edelsbrunner, 2022; McNeish, 2022). A more recent exchange by Sijtsma et al. (2024) and McNeish (2024) goes into further detail and provides insightful perspectives on many highly relevant issues regarding the topic at hand. It is evident that a comprehensive treatise of the topic is far beyond the scope of this singular contribution. Nonetheless, we aim to elucidate one important aspect of this topic: mean comparisons.
As per classical test theory (CTT; DeVellis, 2006), an individual’s observed test score X always comprises parts of true score τ and measurement error ε:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$X=\tau +\varepsilon$$\end{document}and equally with regard to its variance:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\sigma }_{X}^{2}={\sigma }_{\tau }^{2}+{{\sigma }^{2}}_{\varepsilon }$$\end{document}It follows that the variance of the observed score will be greater than or equal to the variance of the true score. As a result, all calculations that are based on the observed scale score’s variance will carry a bias inversely proportional to the instrument’s reliability. This includes all calculations that incorporate measures of dispersion, such as the most common parametric statistical procedures (e.g., t-test, linear regression, and ANOVA). Because of its simplicity, we will use the standardized mean difference known as Cohen’s d to further illustrate this point (Cohen, 1992):
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$d=\frac{{\mu }_{1}-{\mu }_{2}}{\sigma }$$\end{document}It is evident that the pure mean difference is not affected by any changes in variance. However, any reduction (or increase) in the denominator in (3) will lead to an increase (or reduction) in the resultant effect size d. When bearing in mind the range of reliability parameters that are commonly deemed acceptable, this implies marked differences between the observed d and the true d that one would find with a perfect measurement. The example data in Table 1 demonstrates how, even given a constant mean difference (Δμ = 1) and constant true score variance (σ^2^τ = 1), the introduction of increasing proportions of error variance leads to a misestimation of d.Table 1. Reliability and standardized mean differencesReliabilityError varianceObserved varianceObserved* d*10110.900.111.110.950.800.251.250.890.700.431.430.840.600.671.670.770.50120.71In this example, the mean difference and the true score variance were set to 1 for ease of interpretation. This results in a true d of 1.
As mentioned above, the measurement error component of the variance inflates the denominator in the estimation of Cohen’s d. The question now is what exactly this inflation signifies and whether or not it can be deemed acceptable. Per CTT, measurement error is uncorrelated to the construct of interest, and thus it seems obvious that it should be excluded from consideration (i.e., by the modeling of item-specific error terms in factor analysis). Conversely, Widaman and Revelle (2023a, 2023b) argue that the use of sum scores (and thus the inclusion of measurement error) leads to better comparability and replicability across studies. In their reasoning, that is because—in contrast to the sum score—the latent score is obtained by applying “different weightings”, i.e., the factor loadings, across studies. In our view, this statement confuses the source of differences between studies. They make it seem like the true score portion of the observed score may vary across studies. and the error portion is there to balance this out and make the sum score comparable. However, this is inaccurate. and they do not supply arguments to substantiate this claim. If we accept that the true score represents a concrete and stable construct of interest, while the error term is conceptually unrelated, random noise, then it should be evident that it is actually the error term that first introduces the lack of comparability across studies. The “differing weightings” are simply a result of differing errors (see Table 1 for an illustration of this point). Yet, importantly, if we accept that the substantial construct remains unchanged between studies, then the pattern of unstandardized loadings will also remain unchanged. But of course this construct stability should not be presumed without proper invariance testing.
The present investigation aims to examine the extent to which social sciences are affected by this issue by empirically estimating the differences between observed and latent score group differences. This is to be accomplished by analyzing a large number of openly available data sets and comparing observed and latent versions of the standardized mean difference between males and females. This comparison was chosen for the sake of feasibility, as it is the most widely available grouping variable. We expect that the latent d will differ significantly from the observed d. In addition, we expect the magnitude of this difference to be correlated with the respective scale’s reliability estimate: specifically, lower reliability should be associated with higher differences between ds.
Method
Data and participants
The data sets for the present investigation were acquired at the Open-Source Psychometrics Project (2019d) and are summarized in Table 2. We selected all questionnaires which had an ordinal response scale and only those data sets that fulfilled the conservative requirement of having at least 20 respondents per indicator. For the sake of simplicity, we included only complete observations. In total, 999,033 observations were used in the analysis.Table 2. Overview of all questionnaires and samples under analysisQuestionnaireFull nameCreatorComplete N16PFCattell's 16 Personality Factors TestCattell and Mead (2008)35,027AS + SC + AD + DOIPIP Assertiveness, Social confidence, Adventurousness, and Dominance scalesGolberg et al. (2006)896BFI-50Big Five Personality TestGoldberg (1992)19,592CFCSConsideration of Future Consequences ScaleStrathman et al. (1994)14,598DASSDepression Anxiety Stress ScalesLovibond and Lovibond (1995)39,156ECRExperiences in Close Relationships ScaleBrennan et al. (1998)46,006FBPSFirstborn Personality ScaleOpen-Source Psychometrics Project (2019a)38,383FPSFeminist Perspectives ScaleHenley et al. (1998)11,089FTIFisher Temperament InventoryFisher et al. (2010)4845GCBSGeneric Conspiracist Beliefs ScaleBrotherton et al. (2013)2359GRITDuckworth's Grit ScaleDuckworth et al. (2007)4165HSNSHypersensitive Narcissism ScaleHendin and Cheek (1997)50,730DDThe Dirty DozenJonason and Webster (2010)50,730HSQHumor Styles QuestionnaireMartin et. al. (2003)980MACH-IVMachiavellianism TestChristie and Geis (1970)72,534MIESMultidimensional Introversion–Extraversion ScalesOpen-Source Psychometrics Project (2019b)6893NISNonverbal Immediacy ScaleRichmond et al. (2003)130,028NPASNerdy Personality Attributes ScaleFinister et al. (2021)14,185NR6Nature Relatedness ScaleNisbet and Zelenski (2013)1447OSRI44Open Sex Role InventoryOpen-Source Psychometrics Project (2019c)264,578PWEProtestant Work Ethic ScaleMcHoskey (1994)1301RIASECHolland Code Test(Holland, 1957, 1997)134,440RSERosenberg Self-Esteem ScaleRosenberg (1965)45,602RWASRight-wing Authoritarianism ScaleAltemeyer (1981)9469SCSSexual Compulsivity ScaleKalichman and Rompa (1995)3215
Statistical analyses
All analyses were conducted using R and the packages lavaan and metafor (Rosseel, 2012; Viechtbauer, 2010). For the observed scale scores, we calculated the means/sums according to the instructions of the respective questionnaires and compared them between female and male participants using Cohen’s d. In our analyses, this observed standardized mean difference is called dY. Analogously for the latent variable model, we first assigned items to their respective factors and fitted a multigroup confirmatory factor analysis model using robust diagonally weighted least squares estimation (WLSMV in lavaan). To enable an adequate comparison, we first constrained item thresholds, factor loadings, and item intercepts to be identical between groups (Meredith, 1993; Wu & Estabrook, 2016). It bears mentioning that this assumption is implicit in the traditional sum score approach, and thus we have to presume the same in the latent variable model in order to allow for an apples-to-apples comparison. Finally, we calculated the standardized difference between groups by directly examining the difference between latent variable means and then dividing it by the pooled standard deviation of the latent variable. This metric is called dτ. We then calculated the discrepancy between the two effect size estimates, Δd, in both absolute terms and a signed version that retains the direction of the discrepancy. To then evaluate the difference between the two Cohen’s d values, we first calculated their respective variance using the formula provided by Choi and Lam (2017):
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${{\sigma }^{2}}_{d}=\frac{{n}_{1}+{n}_{2}}{{n}_{1}\times {n}_{2}}+ \frac{{d}^{2}}{{2(n}_{1}+{n}_{2})}$$\end{document}Based on the pooled standard deviations, we then calculated a z score to run a one-tailed significance test. In addition, we report the 95% confidence interval around the difference between the Cohen’s ds, which again uses the standard deviation of d based on (4). Finally, we examined the association between McDonald’s ω for each respective scale and the magnitude of the difference between the observed and latent d.
Results
The focus of the analysis at hand was to test whether the calculation of standardized mean differences would yield significantly different results when applying a SEM framework to test the latent score difference versus simply comparing the observed scale scores. In total, we examined 71 scales. One scale (the Sensitivity subscale of Cattell’s 16PF) exhibited negative error variances and was thus omitted from the analyses. Model fit results can be found in the Supplemental Material. We summarize the findings of interest for the present study for the remaining 70 scales in Table 3. In addition, we provide a graphical representation of the results in Figs. 1 and 2. In Fig. 1, it is fairly obvious that latent and observed scores are strongly correlated but not identical, R^2^ = 0.970. There are some deviations from the central diagonal, which represents the expected value for cases where observed and latent mean differences are equal, but most remain within the area marked off by blue lines—representing discrepancies of less than 10% of a standard deviation. Figure 2 shows the individual comparisons in detail and includes 95% confidence intervals.Table 3. Observed and latent effect size estimates and comparisonsInstrumentSubscale \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${d}_{\tau }$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${d}_{Y}$$\end{document} ΔdSigned Δd**% changeSigned % changep95% CI, lower limit95% CI, upper limitω**16PFWarmth–0.292–0.2880.0040.0041.41.40.3530.026–0.0350.872Reasoning0.4540.3530.1010.10125.125.1 < 0.0010.1320.0700.850Emotional stability0.3540.3190.0350.03510.410.4 < 0.0010.0660.0050.884Dominance0.2120.2220.010–0.0104.7–4.70.1740.020–0.0410.860Liveliness–0.008–0.0120.004–0.00443.4–43.40.3490.035–0.0260.846Rule-consciousness–0.276–0.2470.0300.03011.311.30.0030.001–0.0600.873Social boldness0.0490.0440.0060.00612120.3050.036–0.0250.922Vigilance0.0180.0250.007–0.00734.2–34.20.2550.023–0.0370.884Abstractness0.0030.0260.023–0.023154.1–154.10.0190.008–0.0530.841Privateness0.0990.0920.0070.007770.2710.037–0.0240.896Apprehension–0.506–0.4760.0300.0306.26.20.0030–0.0610.872Openness to change0.2260.1510.0750.0754040 < 0.0010.1060.0450.838Self-reliance–0.051–0.0420.0090.00920.320.30.1940.021–0.0400.888Perfectionism0–0.0140.0150.015210.4210.40.0880.045–0.0150.823Tension–0.151–0.0950.0560.05645.445.4 < 0.001–0.026–0.0860.837IPPAssertiveness0.1620.1550.0070.0074.54.50.4580.194–0.1790.877Social confidence0.1150.1130.0020.0021.81.80.4880.188–0.1840.929Adventurousness0.1620.1290.0330.03322.622.60.3120.219–0.1530.870Dominance0.3960.4070.011–0.0112.82.80.4340.177–0.1990.901BFI-50Openness0.2640.2090.0550.05523.223.2 < 0.0010.0960.0140.861Conscientiousness–0.063–0.0580.0050.0058.38.30.3650.036–0.0460.836Extraversion–0.113–0.1070.0060.0065.75.70.3360.034–0.0470.912Agreeableness0.4820.4440.0370.0378.18.10.0060.079–0.0040.868Neuroticism–0.363–0.3470.0160.0164.54.50.1400.025–0.0570.894CFCS–0.057–0.0410.0160.01633.433.40.1610.030–0.0630.902DASSDepression–0.077–0.0730.0040.0045.35.30.3720.030–0.0380.972Anxiety–0.372–0.3330.0400.04011.311.3 < 0.001–0.006–0.0740.940Stress–0.312–0.3030.0090.0092.92.90.2300.025–0.0430.947ECRAvoidant–0.128–0.2110.083–0.08349–49 < 0.0010.1110.0550.894Anxious–0.076–0.0800.004–0.0045–50.3490.032–0.0240.941FBPS0.3320.4440.112–0.11228.9–28.9 < 0.001–0.083–0.1410.821FPSConservative0.9560.6840.2720.27233.133.1 < 0.0010.3320.2110.932Liberal–0.601–0.4580.1430.14327.127.1 < 0.001–0.084–0.2030.869Radical–1.135–0.9160.2190.21921.421.4 < 0.001–0.158–0.2810.945Socialist–0.910–0.6940.2170.2172727 < 0.001–0.156–0.2770.918Cultural–1.068–0.7510.3170.31734.934.9 < 0.001–0.257–0.3780.888Color–0.789–0.7070.0820.0821111 < 0.001–0.022–0.1420.918FTICurious0.1000.1010.002–0.0021.6–1.60.4790.086–0.0890.866Cautious–0.038–0.0340.0050.00513.313.30.4400.083–0.0920.840Analytical0.7490.7200.0290.029440.1810.119–0.0600.848Prosocial–0.431–0.4130.0180.0184.34.30.2830.070–0.1060.866GCBS–0.200–0.1950.0050.0052.82.80.4470.109–0.1200.965GRIT0.0060.0070.001–0.00114.5–14.50.4880.089–0.0910.874HSNS0.2210.1420.0790.07943.743.7 < 0.0010.1050.0540.806DDPsychopathy0.5740.4870.0870.08716.516.5 < 0.0010.1130.0610.808Narcissism0.2650.2480.0180.0186.96.90.0280.043–0.0080.830Machivelianism0.3700.3340.0360.03610.110.1 < 0.0010.0610.0100.868HSQAffiliative0.1460.1140.0320.03224.824.80.3080.210–0.1460.897Self-enhancing0.0030.0140.011–0.011124.9–124.90.4350.167–0.1880.849Aggressive0.4820.4130.0690.06915.515.50.1430.249–0.1110.819Self-defeating0.2330.1980.0350.03516.216.20.2940.213–0.1440.860MACHMachiavellian0.5740.5100.0630.0638.78.7 < 0.0010.0840.0420.856Anti-Machiavellian–0.590–0.4590.130.13026.426.4 < 0.001–0.109–0.1510.866MIESIntroversion0.1680.1570.0110.0116.66.60.3330.079–0.0580.944Extraversion–0.117–0.1270.010–0.0108.6–8.60.3350.079–0.0580.949NIS–0.157–0.1900.034–0.03419.4–19.4 < 0.0010.0550.0120.957NPAS–0.026–0.0420.016–0.01646.5–46.50.1840.065–0.0330.900NR6–0.266–0.2800.014–0.0145–50.4030.167–0.1390.889OSRI44Masculine0.8631.0420.180–0.18018.9–18.9 < 0.001–0.168–0.1910.868Feminine–1.226–1.3490.123–0.1239.6–9.6 < 0.0010.1350.1110.879PWE0.1590.1210.0390.03927.627.60.2440.193–0.1150.919RIASECRealistic0.7780.7540.0240.0243.23.2 < 0.0010.0410.0080.902Investigative0.0630.0680.005–0.0058.38.30.1720.011–0.0210.931Artistic–0.063–0.0320.0310.03166.2–66.2 < 0.001–0.015–0.0470.896Social–0.483–0.4300.0530.05311.6–11.6 < 0.001–0.037–0.0690.894Enterprising0.0230.0120.0110.01165.865.80.0240.027–0.0050.881Conventional0.1710.1520.0190.01911.811.8 < 0.0010.0350.0030.921RSE0.2420.2270.0140.0146.16.10.0710.041–0.0130.940RWAS0.3540.3960.042–0.04212.3–12.30.0270.018–0.1020.977SCS–0.017–0.0330.017–0.01766.4–66.40.3310.122–0.0890.924dτ = standardized latent mean difference, dY = standardized observed mean difference, Δd = absolute difference of dτ and dY, % change** = relative difference of dτ and dY. See Table 2 for the questionnaires and meanings of the abbreviations.Fig. 1. Latent mean differences versus observed mean differences. Note. Blue lines represent an interval of ± 0.1 SD; red lines represent an interval of ± 0.2 SDFig. 2. Latent and observed mean differences including 95% confidence interval
Out of the 70 scales that remained in the analyses, 33 (47.1%) yielded significant differences between observed and latent d. There were 10 cases that exceeded a Δd of 0.100 and four cases with Δd > 0.200. The average absolute difference between ds was 0.048 (Md = 0.024), but had a large range of values from 0 to 0.32. The average relative change was 25.0% (Md = 12.0%). It should however also be mentioned that not all discrepancies were “in favor” of the latent mean difference. Twenty out of the 70 comparisons had, in absolute terms, larger observed mean differences than latent ones. Thus, when taking into account the direction of the difference, the mean difference between ds was 0.028 (Md = 0.015), ranging from –0.18 to 0.32. The average relative change was 5.9% (Md = 7.0%).
In order to allow for a summary assessment of the individual findings, we also conducted a meta-analysis on both the absolute and signed effect size differences. Regarding the absolute differences, the effect overall was considered significant, dest = 0.050 [0.035, 0.066], p < 0.001. We found significant heterogeneity between the scales under consideration, Q(69) = 1144.55, p < 0.001, I^2^ = 93.98%, τ = 0.060. The results for the signed differences were similar: dest = 0.028 [0.009, 0.046], p = 0.004. We again found significant heterogeneity between the scales under consideration, Q(69) = 2237.69, p < 0.001, I^2^ = 96.01%, τ = 0.074. In particular, the τ parameter—which represents the standard deviation of the estimated effect size—is useful for estimating the distribution of expected effect size discrepancies, because it is in the same metric as the effect size estimate itself. That is, based on these estimates, only about 1% of cases should exceed a Δd of 0.200. Yet, between 5 and 16% (depending on whether one refers to absolute or signed discrepancies) of cases would exceed a Δd of 0.100.
Relation between reliability and magnitude of observed-latent effect size difference mismatch
We calculated two correlations for the associations between scale reliability as measured by ω and the magnitude of the deviation between observed and latent d, once in absolute terms and once for the relative (see Fig. 3.1 and 3.2). Regarding the absolute discrepancy, there was a negligible association with ω, r(68) = –0.026 [–0.259, 0.210], p = 0.833. With regard to the percentage change, however, the association with ω was significant, r(68) = –0.290 [–0.492, –0.059], p = 0.015. This means that the higher a given scale’s internal consistency, the smaller the disconnect between observed and latent mean group differences—in relative terms. However, it should be noted that the relationship for the relative change parameter appears to be driven by a small number of extreme data points. Accordingly, when redoing the analysis using Spearman rank correlation, it is smaller and nonsignificant, ρ(68) = –0.227 [–0.467, 0.012], p = 0.059.Fig. 33.1 The relationship between absolute mean difference discrepancy and internal consistency as measured by ω.** 3.2** The relationship between percent change mean difference discrepancy and internal consistency as measured by ω
Discussion
The present study sought to investigate two different scale scoring methods, that is, scoring by summing/averaging (observed score) versus the more elaborate latent variable approach (latent score). Specifically, we were interested in quantifying the extent to which the two do in fact differ and whether it is practically relevant and necessary to differentiate between the two in most research questions, or whether they arrive at the same conclusion anyways. As Widaman and Revelle (2023b) aptly put it, the “proof is in the pudding, not in a priori declaration by fiat.” Our findings based on the analysis of an extensive personality research database show that simple group comparison results can vary significantly based on the employed scale scoring method. It should be noted that the samples we considered in the present investigation were generally large, and thus significant results are easily achieved even with small effect sizes. Further, it bears mentioning that the average difference between Cohen’s d estimates was indeed small. However, it should not be neglected in relative terms. Moreover, there was substantial variation across scales with regard to the extent of this bias. Since a lower reliability equals a larger proportion of error variance, with the removal of the same we expected a larger impact on the standardized mean difference. We were, however, unable to show this in the present study. This may be due to the generally high level of scale reliability (average ω was 0.89, the lowest was still 0.81). Thus, future research should consider tackling this question again since it can be shown quite easily analytically that low reliability scales will have higher discrepancies between observed and latent mean differences.
Our findings line up well with the potential issues with sum scoring raised by McNeish and Wolf (2020) in their initial contribution on the topic. In particular, they pointed out that inappropriate use of the sum scoring method puts into question a scale’s reliability and validity. McNeish and Wolf chiefly emphasize the impact on individual scoring (as opposed to the group-level means, which we considered in this study). While Widaman and Revelle (2023a) correctly point out that the models under study exhibited unacceptable fit, this does in our view not fully alleviate the issues of discrepancies between observed scores and factor-based scores (or in our case, latent variable means). Instead, it serves to emphasize that given high measurement quality and good model fit, the simple sum score can typically be expected to adequately approximate factor scores (or latent variable means) obtained in confirmatory factor analysis. Finally, McNeish (2023) shows in various simulations that even given near-1 correlations of observed and latent scores, the utilization of sum scores can lead to inappropriate score classifications as well as decreased reliability. In the present study, we similarly found very high correlations between observed and latent mean differences across scales. Nonetheless, about half of the presented scales deviated significantly between observed and latent mean group comparisons. The significant association of the reliability estimate with the mean difference discrepancy is of particular interest.
In practical terms, the present research does not suggest that any and all mean comparisons on scales definitely need to be carried out using a latent variable approach. Both the observed mean difference and the latent mean difference may have their place and time in various research questions. If only one thing were to be taken away from this research, it is the need for reliable measures, as these minimize the impact of measurement error on group comparisons. Nonetheless, given the imperfection of all measurements of latent constructs, studies should strongly consider employing factor analysis if possible within the confines of their respective research question and design. Counter-arguments against using factor analysis could be small sample size and potential issues with model specification. However, especially in such cases where strong intergroup differences are expected, it becomes paramount to reliably estimate them, since the bias will—in absolute terms—be stronger here. As a rule of thumb, we suggest that any scales with reliability estimates of 0.80 or lower should strongly consider using a latent variable approach, since in such cases the bias in the standardized mean difference is expected to exceed 10%.
Limitations and future research
In the present study, we found some unexpected results where the magnitude of the observed mean difference actually exceeded the latent mean difference. This result is surprising, because the excision of error variance should generally lead to a reduction in the denominator portion of the standardized mean difference and thus an increase in effect size magnitude (e.g., ECR, FBPS, and OSRI). It should however be noted that scale reliability is not the only factor affecting the denominator variance and, as a result, the evaluation of standardized mean differences. Future research should consider investigating these exceptions and what caused them.
In particular, the CTT assumption of uncorrelated errors, which is essential for traditional latent variable models in SEM, bears mentioning. This assumption may be violated in some cases, as evidenced by significant clusters of correlated error terms in one’s item subsets. In the authors’ view, this would indicate that portions of (at least partially) construct-related variance have been constrained to the error terms despite them being construct-related to some extent. Thus, the factor analytical approach for testing mean differences may in fact be too liberal in such cases.
Furthermore, in many cases, measurement invariance (or rather a lack thereof) and its conceptual twin, differential item and test function, play an important role in explaining group differences in scale usage and interpretation. In terms of the mean structure, however, lack of scalar invariance does not per se change the obtained latent variable means. It does, however, call into question the validity of inferences made with regard to score-level group differences. It should however be emphasized that the same is true for observed score comparisons. The present investigation disregards this issue in order to focus exclusively on the role of reliability (or measurement error) in conducting group comparisons.
Finally, there are some phenomena that are not directly related to the construct of interest but can still systematically affect the measurement process, such as social desirability and acquiescence (Podsakoff et al., 2003). There is a plethora of research on how these can affect estimates of differences and associations and as many ways to remedy these issues. Thus, we will omit a detailed discussion of the topic at this point.
Conclusion
In sum, the present investigation demonstrated that one can expect significant differences between the results of latent and observed mean comparisons, but generally the magnitude of the effect size is rather small with few exceptions. We discussed factors that impact the magnitude of this bias as well as practical implications. We want to emphasize the importance of carefully selecting reliable and standardized scales, as well as choosing appropriate scale scoring methods, in order obtain correct and comparable study results.
Supplementary Information
Below is the link to the electronic supplementary material.Supplementary file1 (DOCX 26 KB)
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Altemeyer, B. (1981). Right-wing authoritarianism. Univ. of Manitoba Press.
- 2Brennan, K. A., Clark, C. L., & Shaver, P. R. (1998). “ Self-report measurement of adult attachment: An integrative overview ” . In Attachment theory and close relationships , Edited by: Simpson , J. A. and Rholes , W. S. 46–76 . New York : Guilford .
- 3Finister, C., Pollet, T. V., & Neave, N. (2021). An exploratory factor analysis of the Nerdy Personality Attributes Scale in a sample of self-identified nerds/geeks. The Social Science Journal, 1–9.
- 4Holland, J. L. (1997). Making vocational choices: A theory of vocational personalities and work environments. Psychological Assessment Resources.
- 5Lovibond, S. H., & Lovibond, P. F. (1995). Depression anxiety stress scales. Psychological Assessment.
- 6Mc Neish, D. (2023). Psychometric properties of sum scores and factor scores differ even when their correlation is 0.98: A response to Widaman and Revelle. Behavior Research Methods, 55(8), 4269–4290.10.3758/s 13428-022-02016-x 36394821 · doi ↗ · pubmed ↗
- 7Mc Neish, D. (2024). Practical Implications of Sum Scores Being Psychometrics’ Greatest Accomplishment. Psychometrika, 1–22.10.1007/s 11336-024-09988-z 39031300 · doi ↗ · pubmed ↗
- 8Open-Source Psychometrics Project (2019 a). Development of the Firstborn Personality Scale. Retrieved from https://openpsychometrics.org/tests/birthorder/development/