A New Frequentist Implementation of the Daniels and Hughes Bivariate Meta‐Analysis Model for Surrogate Endpoint Evaluation
Dan Jackson, Michael Sweeting, Robbie C. M. van Aert, Sylwia Bujkiewicz, Keith R. Abrams, Wolfgang Viechtbauer

TL;DR
This paper introduces a new frequentist method for evaluating surrogate endpoints using a bivariate meta-analysis model, addressing estimation challenges previously only solvable with Bayesian approaches.
Contribution
A novel frequentist implementation of the Daniels and Hughes model with bias-corrected maximum likelihood estimation for variance components.
Findings
A bias-adjusted maximum likelihood estimator is derived for the model's variance component.
Simulation studies show the estimator effectively overcomes frequentist estimation challenges.
The method is demonstrated on two oncology examples, showing practical applicability.
Abstract
Surrogate endpoints are used when the primary outcome is difficult to measure accurately. Determining if a measure is suitable to use as a surrogate endpoint is a challenging task and a variety of meta‐analysis models have been proposed for this purpose. The Daniels and Hughes bivariate model for trial‐level surrogate endpoint evaluation is gaining traction but presents difficulties for frequentist estimation and hitherto only Bayesian solutions have been available. This is because the marginal model is not a conventional linear model and the number of unknown parameters increases at the same rate as the number of studies. This second property raises immediate concerns that the maximum likelihood estimator of the model's unknown variance component may be downwardly biased. We derive maximum likelihood estimating equations to motivate a bias adjusted estimator of this parameter. The bias…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
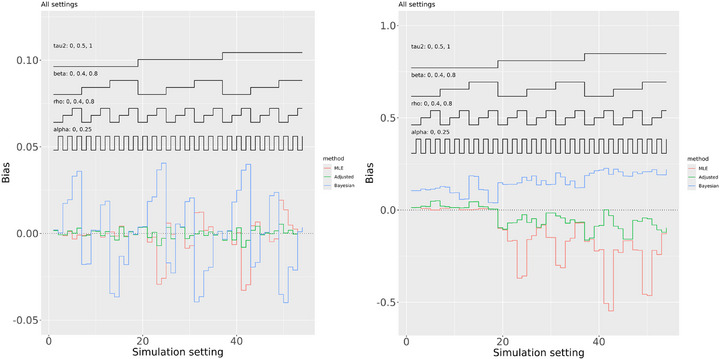 FIGURE 1
FIGURE 1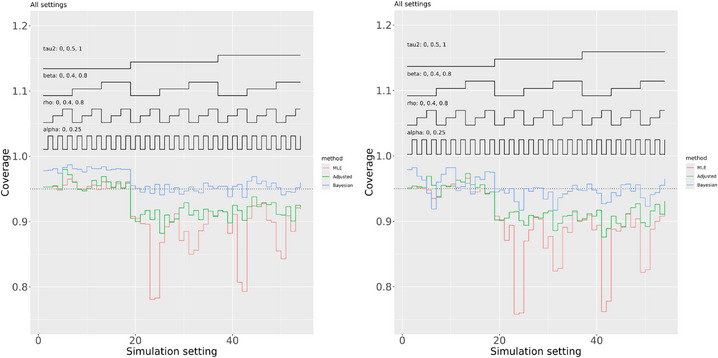 FIGURE 2
FIGURE 2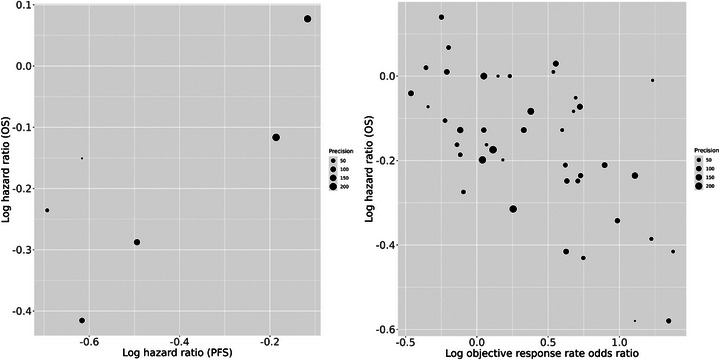 FIGURE 3
FIGURE 3| Estimation method | |||
|---|---|---|---|
| Frequentist (both) | 0.102 (−0.025, 0.229) | 0.776 (0.421, 1.130) | 0 |
| Bayesian (mean, %) | 0.078 (−0.270, 0.401) | 0.678 (−0.132, 1.369) | 0.030 (0.000, 0.204) |
| Bayesian (median, HPD) | 0.081 (−0.274, 0.395) | 0.688 (−0.093, 1.405) | 0.008 (0.000, 0.125) |
| Estimation method | ||||
|---|---|---|---|---|
| Frequentist (unadjusted) | −0.1 | −0.088 (−0.137, −0.039) | −0.216 (−0.306, −0.126) | 0.003 |
| Frequentist (adjusted) | −0.1 | −0.088 (−0.140, −0.036) | −0.214 (−0.308, −0.121) | 0.004 |
| Bayesian (mean, %) | −0.1 | −0.097 (−0.148, −0.044) | −0.189 (−0.277, −0.103) | 0.005 (0.000, 0.014) |
| Bayesian (median, HPD) | −0.1 | −0.097 (−0.147, −0.044) | −0.188 (−0.278, −0.104) | 0.004 (0.000, 0.012) |
| Frequentist (unadjusted) | −0.3 | −0.094 (−0.143, −0.044) | −0.196 (−0.286, −0.107) | 0.004 |
| Frequentist (adjusted) | −0.3 | −0.094 (−0.143, −0.044) | −0.196 (−0.286, −0.107) | 0.005 |
| Bayesian (mean, %) | −0.3 | −0.095 (−0.149, −0.042) | −0.193 (−0.279, −0.102) | 0.006 (0.001, 0.015) |
| Bayesian (median, HPD) | −0.3 | −0.095 (−0.148, −0.041) | −0.193 (−0.279, −0.102) | 0.005 (0.000, 0.013) |
| Frequentist (unadjusted) | −0.5 | −0.100 (−0.150, −0.051) | −0.175 (−0.263, −0.086) | 0.005 |
| Frequentist (adjusted) | −0.5 | −0.100 (−0.150, −0.050) | −0.176 (−0.265, −0.087) | 0.006 |
| Bayesian (mean, %) | −0.5 | −0.093 (−0.143, −0.041) | −0.195 (−0.276, −0.110) | 0.007 (0.001, 0.016) |
| Bayesian (median, HPD) | −0.5 | −0.093 (−0.142, −0.040) | −0.195 (−0.276, −0.110) | 0.006 (0.001, 0.014) |
| Frequentist (unadjusted) | −0.7 | −0.112 (−0.160, −0.064) | −0.142 (−0.230, −0.054) | 0.004 |
| Frequentist (adjusted) | −0.7 | −0.106 (−0.159, −0.052) | −0.157 (−0.249, −0.064) | 0.009 |
| Bayesian (mean, %) | −0.7 | −0.092 (−0.143, −0.042) | −0.194 (−0.277, −0.111) | 0.009 (0.003, 0.018) |
| Bayesian (median, HPD) | −0.7 | −0.092 (−0.142, −0.041) | −0.194 (−0.275, −0.110) | 0.008 (0.002, 0.017) |
| Frequentist (unadjusted) | −0.9 | −0.151 (−0.193, −0.109) | −0.033 (−0.115, 0.048) | 0 |
| Frequentist (adjusted) | −0.9 | −0.110 (−0.169, −0.050) | −0.144 (−0.243, −0.044) | 0.014 |
| Bayesian (mean, %) | −0.9 | −0.091 (−0.141, −0.040) | −0.194 (−0.274, −0.114) | 0.010 (0.004, 0.020) |
| Bayesian (median, HPD) | −0.9 | −0.091 (−0.141, −0.040) | −0.194 (−0.272, −0.112) | 0.010 (0.004, 0.018) |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsStatistical Methods in Clinical Trials · Economic and Environmental Valuation · Meta-analysis and systematic reviews
Introduction
1
Surrogate endpoints are used when the primary endpoint is difficult to measure accurately, for example when little information is accessible or information may only become available in the longer term. A common example in the context of oncology trials is the use of progression‐free survival (PFS) as a surrogate endpoint for overall survival (OS; Belin et al. 2020). Determining if an outcome is suitable to use as a surrogate endpoint is a challenging task in practice, despite the criteria that have been proposed for this purpose (e.g., Baker 2018; Daniels and Hughes 1997; Prentice 1989).
We focus on the situation where evidence from multiple trials is available and a statistical assessment of trial‐level surrogacy is required. A number of approaches have been developed that require individual patient data (IPD; Burzykowski et al. 2001; Burzykowski et al. 2021; Buyse 2000; Dai and Hughes, 2012; Molenberghs et al. 2008). We agree with Li and Meredith (2003) that models using IPD are to be preferred when these data are available because associations between patient outcomes can then be quantified. However, it is typically the case that only aggregate (or summary level) data are available to the analyst and we address this common situation. Meta‐analytic approaches focus on the association between treatment effects and so, in the framework of Taylor and Elston (2009), assess “level one” evidence for surrogacy. In general, other methods will be needed to assess evidence at their second (associations between outcomes) and third (biological plausibility) levels.
Bujkiewicz et al. (2017) provide an accessible overview of methods for meta‐analysis, that can be used to assess if an outcome is a suitable surrogate endpoint, requiring only aggregate level study information. One of these methods is the model proposed by Daniels and Hughes (1997), where a linear regression is assumed for the true effects across studies. Advantages of the Daniels and Hughes (1997) model are that it does not require the estimation of a between‐study correlation parameter, which can be challenging (Burke et al. 2018), and it does not assume that the surrogate treatment effects are exchangeable (Bujkiewicz et al. 2017). However this model is, in some respects, unusual. For example, the marginal model is not a conventional linear model. Furthermore, it uses a separate fixed effect for the candidate surrogate treatment effect from each study, so that the number of unknown parameters increases at the same rate as the number of studies. These two features make the Daniels and Hughes (1997) model difficult to satisfactorily fit in a frequentist framework, where the main challenge relates to estimating its unknown variance component. This is because the presence of a separate fixed effect for each study can result in notable downward bias in maximum likelihood estimates of variance parameters (Jackson, Law, et al. 2018), analogously to the well‐known Neyman and Scott (1948) problem.
Extensions of the Daniels and Hughes (1997) model are possible, for example, where there is more than one potential surrogate (Pozzi et al. 2016) or multiple treatment classes (Papanikos et al. 2020), and we return to this in the discussion. There has therefore been considerable methodological development since Daniels and Hughes (1997) and this model is gaining traction in Health Technology Assessment (HTA). For example, it is described in detail in NICE Technical Support Document 20 (Bujkiewicz, Achana, et al. 2019). We therefore anticipate that the application of the Daniels and Hughes model to increase. Our position is that it is useful to have Bayesian and frequentist estimation methods available to us. Our work fills an important void by providing, to the best of our knowledge, the first frequentist implementation of the Daniels and Hughes model.
The main competitor to the Daniels and Hughes model is the bivariate random‐effects meta‐analysis model (Jackson et al. 2011; Bujkiewicz et al. 2017; Bujkiewicz, Jackson, et al. 2019) that has been extended to the network meta‐analysis setting (Achana et al. 2014; Bujkiewicz, Achana, et al. 2019; Efthimiou et al., 2014; Jackson, Bujkiewicz, et al. 2018). This is a linear model where the number of parameters does not depend on the number of studies, so that this model is more amenable to frequentist methods. However it requires the estimation of the between‐study correlation and assumes that the surrogate treatment effects are exchangeable. Hence, the Daniels and Hughes and bivariate random‐effects meta‐analysis models are diametrically opposites in terms of these advantages and disadvantages. However, both these models acknowledge that the surrogate treatment effects are estimated with uncertainty. A wide variety of estimation methods for the between‐study covariance matrix are available for the bivariate random‐effects meta‐analysis model but they are not immediately applicable to the Daniels and Hughes model. For example, the theory for the restricted maximum likelihood estimator (REML; Jennrich and Schluchter 1986), that helps to correct for the downward bias of maximum likelihood estimates of variance components (Jackson et al. 2011), assumes a linear model. Moment‐based estimators for bivariate random‐effects meta‐analysis (Jackson et al. 2013) have not been developed for the Daniels and Hughes model, and estimators of this type possess no optimality properties. Conventional meta‐regression (Thompson and Sharp 1999) is another competing method (Bujkiewicz et al. 2017) that instead includes the treatment effect on the surrogate endpoint as a covariate.
Daniels and Hughes (1997) propose fitting their model in the Bayesian framework, which circumvents the estimation difficulties encountered when using frequentist methods, but comes at the price of sensitivity to prior distribution specification. In particular, the conventional univariate random‐effects model for meta‐analysis has been found to be sensitive to the prior distribution used for the between‐study variance parameter (Lambert et al. 2005). This can also be anticipated to be the case for the unknown variance component of the Daniels and Hughes model. The aim of this paper is to develop frequentist estimation methods for this model and so avoid concerns related to prior sensitivity. We achieve this by considering maximum likelihood estimation and then using the resulting estimating equations to derive a bias adjusted estimator of the unknown variance component. This estimate can then be used in a bias adjusted frequentist analysis using the Daniels and Hughes (1997) model that addresses the potential bias in the corresponding maximum likelihood estimator.
The rest of the paper is set out as follows. In Section 2, we present the Daniels and Hughes model. In Section 3, we develop maximum likelihood estimating equations and we derive a bias adjusted estimator of the unknown variance component in Section 4. In Section 5, we perform a small‐scale simulation study that provides proof of concept that our adjusted estimator overcomes the problems associated with using maximum likelihood estimation in conjunction with the Daniels and Hughes model. In Section 6, we apply our methodology to two contrasting examples and we conclude with a short discussion.
The Daniels and Hughes Model
2
The Daniels and Hughes (1997) bivariate meta‐analysis model for surrogate endpoint evaluation assumes that each study provides two estimates (with corresponding standard errors and within‐study correlation): the estimated treatment effect on the clinical outcome of interest and the surrogate treatment effect. For example, the estimated treatment effect on the clinical outcome of interest could be an estimated log hazard ratio comparing two treatment groups for OS and the surrogate treatment effect could be the corresponding log hazard ratio for PFS. The overall aim is to determine if the surrogate is viable (see Section 2.4 below).
Let n be the number of studies included in the analysis. For the ith study, let θi and γi, i=1,2,…n, be the true treatment effect on the clinical outcome of interest, and on the surrogate, respectively. Let θ^i and γ^i be the corresponding estimates that are usually available or can be extracted from published papers or reports, and so are aggregate level information available to the analyst.
The Within‐Study Model
2.1
Daniels and Hughes (1997) assume the standard within‐study model for bivariate meta‐analysis (their eq. (1); Jackson et al. 2011), and so assume that
Model (1) describes how the distributions of θ^i and γ^i depend on the true θi and γi. We treat the within‐study covariance matrix in model (1) as fixed and known. Typically the within‐study variances, σi2 and δi2, will be known but the within‐study correlations ρi between θ^i and γ^i are unlikely to be directly reported in aggregate level data. We agree with Riley (2009) that using appropriate values for the within‐study correlations is an important consideration. A variety of approaches are available that produce suitable values of ρi (Bujkiewicz et al. 2013; Bujkiewicz, Achana, et al. 2019; Riley et al. 2008; 2015; Wei and Higgins 2013) and we explore two possibilities in our examples below.
The Between‐Studies Model
2.2
Between studies, Daniels and Hughes (1997) assume that
Model (2) is the between‐studies model because it states the assumptions made about the relationships between the true treatment effects on the two outcomes across trials. Equation (2) is different to the conventional between‐study model for random‐effects bivariate meta‐analysis (Jackson et al. 2011; their eq. (2)) that instead assumes that (θi,γi) follows a bivariate normal distribution. It is therefore model (2) that distinguishes the Daniels and Hughes model from the bivariate random‐effects meta‐analysis model. The parameter τ2 is the (conditional on γi) between‐study variance of θi and is the focus of attention in much of the work that follows. Model (2) follows from the bivariate random‐effects model but does not make the assumption of bivariate normality.
The Marginal Model
2.3
The implied marginal model, from models (1) and (2), is
In the frequentist framework, inferences are usually based on the marginal model. Hence we take model (3) to be the Daniels and Hughes model. The Daniels and Hughes model makes normality assumptions both within (model 1) and between (model 2) studies. Methods for meta‐analysis that make fewer normality assumptions are in general available (Jackson and White 2018) and we return to the possibility of relaxing these assumptions in the discussion. We assume that each pair of (θ^i,γ^i) is independent.
Assessing Surrogacy
2.4
All three parameters α, β, and τ2 in model (3) are useful when determining if the putative surrogate endpoint is suitable as a good predictor of clinical benefit measured by the clinical outcome of interest, which is discussed by Daniels and Hughes (1997). Briefly, α=0, β≠0, and τ2=0 are taken to be indicative of a perfect surrogate relationship. If α=0, then no treatment effect for the surrogate corresponds to no treatment effect for the outcome of clinical interest. If β≠0, then a treatment effect for the surrogate is associated with a treatment effect for this outcome; if the same directional effects indicate treatment benefit for the surrogate and outcome of clinical interest, then β>0 is suggestive of a surrogate relationship. Finally, if τ2=0, then the treatment effect on the final clinical outcome can be predicted perfectly given the effect on the surrogate endpoint. All three parameters in model (2) should be used to assess surrogacy. The γi are usually regarded as nuisance parameters.
Hence α^≈0 and τ^2≈0, estimated with small uncertainty, and a confidence or credible interval for β that does not include zero, indicate that the surrogate is considered suitable. However, the extent to which different departures from this are tolerable when declaring surrogacy is an open question. We return to this issue in the discussion.
Challenges for Frequentist Inference
2.5
As explained in the introduction, model (3) presents two main challenges for frequentist estimation. First, there is a separate parameter γi for each study, so that the number of parameters increases at the same rate as the number of studies. Hence the maximum likelihood estimator of τ2 may be badly downwardly biased (Jackson, Law, et al. 2018). Second, model (3) is a nonlinear model because it contains the term βγi in the linear predictor for θ^i, which is not linear in terms of the model parameters. One implication of this is that the theory of restricted maximum likelihood (REML; Jennrich and Schluchter 1986) does not apply.
Despite concerns about downward bias for the maximum likelihood estimate of τ2, we will begin by deriving maximum likelihood estimating equations for all model parameters. These estimating equations will then be used to motivate a bias adjusted estimator of τ2.
Maximum Likelihood Estimating Equations
3
The likelihood function is the product of densities of the bivariate normal probability density function from model (3), where each study contributes one such term. Maximum likelihood estimating equations can be derived using the properties of the normal distribution.
Estimating Equation for γi
3.1
We use γ^i,MLE, i=1,…n, to denote the model‐based maximum likelihood estimate of γi. Conceptually, γ^i,MLE and γ^i are estimates of the same quantity γi. The difference however is that γ^i,MLE uses information from all studies, assuming the meta‐analysis model (3), whereas γ^i is aggregate level data used in analysis and uses information only from the ith study.
The likelihood function is the product of probability density functions implied by model (3), so that the only terms in this function that contain γi are from the ith study. When differentiating the log‐likelihood function with respect to γi, only the logarithm of the bivariate normal density contribution for the ith study remains. Reparameterizing so that θ^i∗=θ^i−α, model (3) becomes
where C(β,1) is a column vector of length 2 where the first entry is β and the second is one. Noting that only the contribution from the ith study remains when differentiating the log‐likelihood function with respect to γi, γ^i,MLE satisfies the maximum likelihood estimating equation for γi from model (4) where all other parameters are replaced by their maximum likelihood estimates. Model (4) is a weighted linear regression model, so that the standard theory for this type of model can be used to derive the resulting maximum likelihood estimating equation for γi.
Let W^i be the inverse of the covariance matrix in (4) where τ2 is replaced by its maximum likelihood estimate, τ^2. Standard theory for weighted linear regression models results in the estimating equation
where all estimates are maximum likelihood estimates. Estimating Equation (5) could be used as part of an iterative scheme to estimate all parameters, where estimates at the previous step are used on the right‐hand side to produce the maximum likelihood estimate of γi at the current step on the left. Equation (5) is the basis for n estimating equations, because there is one such equation for each γi.
Estimating Equations for α and β
3.2
We factorize the contributions to the likelihood from the ith study resulting from the bivariate normal model (3) as contribution from the marginal density of γ^i∼N(γi,δi2) and the contribution from the conditional density
To simplify notation, let μi(γ^i)=α+βγi+(ρiσi/δi)(γ^i−γi) and vi2=σi2(1−ρi2). Then the conditional distribution of θ^i|γ^i above becomes
Model (6) is a weighted linear regression with an offset. Estimating equations are therefore easily derived, as explained in Appendix A.
Estimating Equation for τ2
3.3
The marginal model γ^i∼N(γi,δi2) does not depend on τ2. Hence, when differentiating the log‐likelihood function with respect to τ2, only terms from the conditional distributions of θ^i|γ^i from model (6) contribute. When omitting terms that do not include τ2, to within a constant the log‐likelihood is
Differentiating Equation (7) with respect to τ2, setting the resulting expression to zero, and replacing all parameters with their maximum likelihood estimates gives the estimating equation
where μ^i(γ^i)=α^+β^γ^i,MLE+(ρiσi/δi)(γ^i−γ^i,MLE). Rearranging Equation (8) quickly provides the estimating equation
Equation (9) is analogous to eq. (3b) from Thompson and Sharp (1999). We truncate τ^2=0 if the estimate from Equation (9) is negative.
We have now derived maximum likelihood estimating Equations ((5), (9), (A2), (A3)), where two of these equations are in Appendix A, for all model parameters. Note that parameter estimates appear on the right‐hand sides of these estimating equations, so that they may be used in iterative scheme to fit the model; they are not closed‐form solutions that can be used to compute the maximum likelihood estimates.
Assumptions Required for Estimating Equation (9) for τ2 to Be Unbiased
3.3.1
Before considering bias correction, it is insightful to understand the conditions under which estimating Equation (9) is unbiased. Suppose that all model parameters, α, β, τ2, and all γi, were known and are used to evaluate the right‐hand side of estimating Equation (9). Then we replace the estimates in Equation (9) with their corresponding true parameter values and this estimating equation becomes
We can evaluate the expectation of (10) as
From the conditional model (6), in Equation (11), we have E[(θ^i−μi(γ^i))2|γ^i]=vi2+τ2, where vi2 and τ2 are both treated as constants. Hence Eτ^2=τ2, so that τ^2 is then unbiased. If we knew the true parameter values, there would of course be no need to estimate τ2, but this does clarify that the form of the estimating Equation (9) is a good starting point.
Bias Adjusted Estimating Equation for τ2
4
The main concern is that the presence of an unknown fixed effect γi for each study may result in downward bias for the maximum likelihood estimate of τ2. We now repeat the analysis in Section 3.3.1 but where we take into account the fact that the estimates γ^i,MLE, rather than the true values γi, are used in the estimating equation for τ2 in Equation (9). However, we will treat α^, β,^ and τ^2 as fixed constants when evaluating the right‐hand side of Equation (9). This is because the main difficulties for the estimation of τ2 are associated with the number of unknown γi increasing at the same rate as the number of studies. This approach deals with the most serious problem in an analytically tractable way.
Our proposed bias adjusted estimate of τ2 is a modified version of the estimating Equation (9) given by
where bi=(β^−ρiσi/δi)w1i; w1i is the first entry of the row vector (C(β^,1)TW^iC(β^,1))−1C(β^,1)TW^i.
The mathematical result required to derive the bias adjusted estimating Equation (12) is derived in Appendix B. We motivate this estimating equation by taking iterated expectations in (12), in the same way as in Section 3.3.1, but now using Equation (B4) from Appendix B to evaluate the inner expectations. This calculation shows that the expected value of τ^adjusted2 in estimating Equation (12) is τ2, so that estimating Equation (12) removes bias in the maximum likelihood estimate of τ2 associated with the need to estimate the γi. We truncate τ^adjusted2=0 if the estimate from Equation (12) is negative.
Evaluating the Bias Correction Terms
4.1
The key quantities are the “bias adjustment terms” bi=(β^−ρiσi/δi)w1i in estimating Equation (12). This is because if all bi=0, then no adjustment to the maximum likelihood estimate τ^2 from Equation (9) is made. We can explicitly compute w1i by computing (C(β^,1)TW^iC(β,1))−1C(β^,1)TW^i and extracting the first entry. This is straightforward because W^i is the inverse of the 2×2 covariance matrix in (4); when computing this inverse using the adjoint method the determinant cancels in the calculation of (C(β^,1)TW^iC(β,1))−1C(β^,1)TW^i, which simplifies the calculation, and we obtain
Hence
Equation (13) shows that 0≤bi<1, so that in Equation (12) we have 1≤(1−bi)−2<∞. Hence positive scaling terms that cannot result in a smaller estimate of τ2 are applied to the squared residuals when using the bias adjusted estimator (12).
If β^=ρiσi/δi, then bi=0 and no adjustment is made for the ith study. From Equation (2), β is the gradient of the between‐study regression of θi on γi. Furthermore, in the within‐study model (1) for the ith study, ρiσi/δi is the gradient associated with γ^i in E(θ^i|γ^i). We will therefore refer to ρiσi/δi and β as the “within‐study gradient,” and “between‐study gradient,” respectively. Conceptually, if the estimated within and between‐study gradients associated with the clinical outcome of interest on the surrogate are identical, no adjustment is made, via the bias adjustment terms bi, when estimating τ2 using maximum likelihood. Furthermore, the adjustment becomes larger as the magnitude of the difference between these two gradients increases. The bias adjustment terms therefore have a clear and intuitive interpretation. Our results indicate that maximum likelihood estimation of τ2 can be expected to perform well when the dependence of the clinical outcome on the surrogate is in this sense similar within and between studies. The bias adjustment terms bi are functions of parameter estimates, so that they may also be conceptualized as estimates, but we refrain from presenting them as b^i because they do not estimate parameters of inferential interest.
Simulation Study
5
We performed a small‐scale simulation study to provide proof of concept that maximum likelihood estimates of τ2 can be badly biased downwards, and further that the corresponding bias adjusted estimator addresses this problem.
Simulation Study Design
5.1
We used n=20 studies throughout, so that the Daniels and Hughes model can be adequately estimated while assuming a plausible sample size. We assumed that the true γi are uniformly distributed from −5 to 5. We assumed that the within‐study variances, σi2=δi2=0.05,0.1,…1.00, are the same and fixed for each simulated data set. For simplicity, we took σi2=δi2 for all studies.
We varied the other four model parameters, using three values of β=0,0.4,0.8 and similarly three different values of ρi=0,0.4,0.8 (where the same ρi was assumed for all studies). From the theory derived in Section 4, maximum likelihood estimation of τ2 should perform well in terms of bias when ρ=β=0, 0.4, or 0.8 because then, in the absence of bias in β^, β^≈ρiσi/δi so that bi≈0. Otherwise the bias adjusted estimator should provide an improvement. We used three different values of τ2=0,0.5,1. If τ2=0, then, because τ^2≥0, the conventional maximum likelihood estimator can only exhibit positive bias. Hence τ2=0 was considered, not because this is necessarily plausible, but because it was of interest to assess the extent that the bias adjusted estimator may exacerbate this. We used two different values of α=0,0.25 but we did not expect this to have much impact on the estimation performance. We therefore examined 3×3×3×2=54 different scenarios. One thousand simulations were used in each setting, so that in total our methods were applied to 54,000 simulated data sets.
Computational Details
5.2
Conventional maximum likelihood estimation was performed numerically where log(τ2), and all other unknown parameters, may take any real value. The resulting log(τ^2) was then exponentiated to provide τ^2>0, where very large negative values of log(τ^2) correspond to τ^2=0. All numerical maximum likelihood estimates were then substituted into the estimating Equations ((5), (9), (A2), (A3)) to confirm that the correct solutions had been found. An advantage of using the estimating equations is that they can be used to remove all doubt that numerical optimizers have correctly converged; there is a separate γi for each study, so the dimension of the optimization problem can be high, and convergence may be difficult to correctly identify in practice.
Standard errors were computed as the inverse of the Hessian matrix, where this matrix was obtained numerically. Computing the standard error of log(τ^2) in this way however presents problems when τ^2=0, because small changes in very large and negative values of log(τ^2) result in negligible differences in the likelihood function. If this occurs, then all partial derivatives with respect to log(τ2) will be calculated to be zero, resulting in a Hessian that is not invertible. To avoid this difficulty, the generalized matrix inverse of the Hessian was used, which is numerically equivalent to constraining τ2=0 in the analysis when τ^2=0. A more computationally intensive alternative is to use methods based on the profile likelihood and we return to this possibility in the discussion. Wald‐type 95% confidence intervals for α and β were computed using their point estimates, standard errors, and normal approximations.
An adjusted analysis was then performed constraining τ2=τ^adjusted2 and performing maximum likelihood estimation for the other model parameters, so that the bias adjusted estimate of τ2 was used instead of the maximum likelihood estimator. Estimating Equations ((5), (A2), (A3)) were used, with this constraint, to confirm that numerical optimizers had correctly converged. Using the estimated between‐study variance as the true value in this way is a common approximation in meta‐analysis (Jackson and White 2018). Although the accuracy of this approximation may be questionable, for example, in situations where the number of studies is small, the greater concern is that a conventional maximum likelihood–based analysis may result in severe downward bias for τ2.
The main outcomes of interest were the biases of the estimates of α,β, and τ2, and the coverage probabilities of the 95% confidence intervals of α and β. Calculating confidence intervals for τ2 is a complex issue even under the univariate random‐effects model for meta‐analysis and we return to this issue in the discussion.
We also compared our frequentist analyses to a more conventional Bayesian analysis. Here “vague,” and independent, prior distributions of γi,α,β∼N(0,1000) were used. In general the prior for τ2 can be expected to be influential (Lambert et al. 2005). Here we followed Bujkiewicz, Achana, et al. (2019) and used the prior τ∼U(0,2), that is, a uniform prior for the between‐study standard deviation. To make the Bayesian results more comparable with our frequentist analyses, we used the same values of ρi in our modeling, instead of using prior distributions for the ρi that may instead be used to allow for the possibility that these values are unknown. Our Bayesian analyses are merely intended to be representative, so that we can compare our frequentist methods to a typical type of Bayesian analysis. Posterior means, and coverage probabilities of 95% percentile–based credible intervals, can then be used to provide comparisons with frequentist biases and coverage probabilities. Posterior distributions of τ2 can be skew and biases were also computed using the posterior median. Burn ins of 1000 Markov chain Monte Carlo iterations were used. A further 10,000 iterations were used to make inferences with a thinning frequency of two.
Results
5.3
The full results are shown in the Supporting Information. No concerns relating to bias when estimating α were encountered in any setting or using any estimation method (see the Supporting Information).
The largest biases when estimating β were produced by the Bayesian analysis, and the adjusted analysis also resulted in noticeably smaller biases than conventional maximum likelihood estimation (Figure 1, left). A closer examination (see the Supporting Information) revealed that all three methods performed more similarly in scenarios where β=ρiσi/δi=ρi. From our analysis in Section 3, we know that this criterion has important implications for the maximum likelihood estimation of τ2. It appears that it may also have implications for Bayesian analyses that also use the likelihood function. We should interpret this finding cautiously, because simulation study results may not generalize to other settings, but the observation that our proposed adjusted frequentist method performed best in terms of bias when estimating β is an important finding.
Bias across all scenarios when estimating β (left) and τ2 (right). Results for the maximum likelihood estimator (MLE) are shown in red, the bias adjusted (Adjusted) estimator are shown in green, and Bayesian (posterior mean) estimators are shown in blue.
The Bayesian analysis consistently resulted in positive bias when estimating τ2 (Figure 1, right). This can be explained by the prior τ∼U(0,2) that gives considerable probability to larger values of τ2 than explored in our simulation study. This bias was reduced by instead using the posterior median of τ2 (see Supporting Information). The standard maximum likelihood analysis resulted in slight positive bias when estimating τ2 when the true value was zero, as expected, and the bias adjusted method slightly increased this (Figure 1, right). However standard likelihood–based estimation resulted in large negative bias when the true τ2>0 and the adjusted method greatly reduced, but did not completely remove, this bias. A closer examination (see the Supporting Information) revealed that the bias adjustment made little difference in the scenarios where β=ρiσi/δi=ρi, for which the downward bias of the maximum likelihood estimate of τ2 was much less severe, as expected. We conclude that the estimation of τ2 is challenging but our adjusted method greatly reduces the problems resulting from using maximum likelihood estimation and avoids concerns related to prior sensitivity in Bayesian analyses.
The results for the coverage probabilities of confidence and credible intervals are shown in Figure 2. The Bayesian analysis generally performed well in terms of the coverage probability of 95% credible intervals for α and β, where these probabilities were close to 0.95 when τ2>0 and overcoverage was observed when τ2=0. The conventional maximum likelihood analysis resulted in severe under coverage when τ2>0, for example, as low as under 0.8. The lowest adjusted analysis coverage probabilities were instead around 0.9, which is a considerable improvement. The overall impression is that the bias adjustment greatly reduces the downward bias of the maximum likelihood estimation of τ2, and so avoids the severe under coverage of the confidence intervals for α and β, but does not entirely eliminate this. When τ2=0, the frequentist methods generally resulted in slight overcoverage for α but this was not evident for β. The two frequentist methods can only result in positive bias for τ2 when this is zero, so that overcoverage for the other parameters might then be anticipated, but fully accommodating the uncertainty in many γi is likely to counteract this intuition. Ad hoc methods for increasing the coverage probability of confidence intervals, for example, by using the t distribution to compute them, might be worth considering but any concrete proposal for this would need to be carefully justified.
Coverage probabilities for α (left) and β (right). Results for the maximum likelihood estimator (MLE) are shown in red, the bias adjusted (Adjusted) estimator are shown in green, and Bayesian (percentile based) estimators are shown in blue.
To summarize, the proposed “bias adjusted method” performs better than conventional maximum likelihood estimation by greatly reducing its main problems. Bayesian estimation performed best in terms of coverage probabilities for α and β but raises concerns about sensitivity to prior distributions. The two frequentist methods, and the adjusted method in particular, performed better in terms of bias when estimating β. No method performed best in all respects but our position is that this simulation study indicates that our proposed bias adjusted method is, at the very least, a viable alternative to more conventional Bayesian estimation of the Daniels and Hughes model.
Examples
6
Example 1: Antiangiogenic Therapies for Metastatic Colorectal Cancer
6.1
The systematic review “Anti‐angiogenic therapies for metastatic colorectal cancer” (Wagner et al. 2009) contains six studies that report hazard ratios for PFS and OS. A scatter plot of these six pairs of estimates (log hazard ratios) are shown in Figure 3 (left). A within‐study correlation of ρi=0.513 is available for one of the studies (Elia et al. 2020) but for the others this is unknown. We will perform an analysis assuming that that the within‐study correlations are similar across studies and so use ρi=0.513 for all studies. Our analyses will explore if PFS is a potential surrogate endpoint for OS at the study level.
Scatter plots for example 1 (left, Section 6.1) and example 2 (right, Section 6.2).
The results are shown in Table 1, where the same Bayesian method described in Section 5 was used for both this and the subsequent example. In addition to presenting posterior means and percentile based credible intervals (mean, %), as in the simulation study in Section 5, we also show posterior medians and highest probability density (HPD)‐based credible intervals. The adjusted and unadjusted frequentist estimates are τ^2=0 so that these two methods give the same results. This is because the six “within‐study gradients,” ρiσi/δi, take values in the interval [0.453,0.623]. These values are are not sufficiently numerically dissimilar to the β^=0.776 for the bias adjustment to instead provide τ^adjusted2>0. Although 95% credible intervals for τ2 are shown in Table 1, the corresponding confidence intervals are omitted because the best way to compute them is left as further work. We return to this issue in the discussion. The Bayesian (mean %) and (median, HPD) results for α and β in Table 1 are similar but the results for τ2 are notably different, and indicate that the posterior distribution of τ2 is skew. This is not surprising because there are just six pairs of estimates contributing to the analysis.
Our frequentist analyses support the results from the Bayesian analysis that PFS may be a suitable surrogate endpoint for OS. In particular, they reinforce the conclusion that τ2 is small, so that the variation in the true treatment effects on OS is explained by the corresponding treatment effects on PFS. Credible intervals for τ2 are wide, however, so this finding should be treated with caution. Both types of the analysis provide α^≈0, which is also supportive of surrogacy. The point estimates of β are also similar but the Bayesian analysis has resulted in much wider interval estimation. In an example such as this, where the number of studies is small, the Bayesian analysis can reasonably claim to better describe model uncertainty. The Bayesian credible intervals for β include zero, whereas the frequentist analyses exclude this.
The overall impression is that more evidence is required because confidence and, in particular, credible intervals are wide, but PFS may be a suitable surrogate endpoint for OS. Our adjusted analysis indicates that concerns relating to the downward bias of the maximum likelihood estimate of τ2 is not an issue for this example.
Example 2: Objective Response Rate and Survival‐Based Endpoints in First‐Line Advanced Non–Small Cell Lung Cancer
6.2
Goring et al. (2022) recently performed a systematic review and meta‐analysis, “Correlations between objective response rate and survival‐based endpoints in first‐line advanced non‐small cell lung Cancer: A systematic review and meta‐analysis,” that includes 42 pairs of estimates. Here we reanalyze the data in their supplementary table A11 to explore whether the objective response rate is a potential surrogate endpoint for OS. A scatter plot of the 42 pairs of estimates (log objective response rate odds ratios and log OS hazard ratios) is shown in Figure 3 (right). The within‐study correlations are unknown but can be expected to be negative, because we assume that increase in response rate implies a reduction in the mortality rate. Hence we will perform a sensitivity analysis where we take ρi=−0.1,−0.3,−0.5,−0.7,−0.9 for all studies. The values ρi=−0.1 and ρi=−0.9 are probably implausibly small and large, respectively, but it is of interest to assess the extent to which inferences are sensitive to the assumed within‐study associations between the treatment effects on the potential surrogate endpoint and the final clinical outcome.
The results are shown in Table 2. The two frequentist methods give similar results for ρi=−0.1,−0.3,−0.5, where the bias adjusted estimates of τ2 are only slightly larger than the maximum likelihood estimates. This is because the “within‐study gradients,” ρiσi/δi, take values in the intervals [−0.073,−0.046], [−0.220,−0.137], and [−0.366,−0.228], for these three values of ρi respectively, that are not dissimilar to the corresponding maximum likelihood estimates of β (Table 2). However for ρi=−0.7,−0.9, the bias adjustment results in a much larger estimate of τ2 and provides results that are in better agreement with the Bayesian analysis. This is especially evident for ρi=−0.9 where the maximum likelihood estimate of τ2 is zero, whereas the corresponding bias adjusted estimate is τ^adjusted2=0.014. The “within‐study gradients,” ρiσi/δi, take values in the intervals [−0.513,−0.319] and [−0.659,−0.410] for ρi=−0.7 and ρi=−0.9, respectively, that are notably different from the corresponding maximum likelihood estimates of β. Our proposed method has therefore had considerable impact for the last two values of ρi in our sensitivity analysis, where we observe better agreement with the Bayesian analysis when using our bias adjusted method. The Bayesian (mean, %) and (median, HPD) results are in much better agreement than the first example, as expected because many more pairs of estimates contribute to the analysis.
The overall impression is that our results support the conclusion from Goring et al. (2022) that objective response rate is associated with OS in this trial level meta‐analysis (β<0). Furthermore, estimates of τ2 are small. Estimates of α are not large but confidence and credible intervals do not include zero, which casts doubt on the use of the objective response rate as a surrogate for OS.
Conclusions
7
We have developed a new frequentist estimation method for fitting the Daniels and Hughes bivariate meta‐analysis model. The proposed estimation method is entirely based on this model but is otherwise fundamentally different to the current Bayesian implementation. Perhaps the main advantage of our approach is avoiding the need to specify prior distributions. Justifying particular priors for unknown variance components is challenging and in general inferences can be expected to be sensitive to this. The existing Bayesian approach, however, also has advantages. For example, it more naturally lends itself to decision analysis. We propose our estimation method as an alternative to, rather than a replacement of, a Bayesian analysis. A by‐product of our work is that we are able to clarify the circumstances where a standard maximum likelihood based analysis is appropriate and so when more conventional frequentist analyses are feasible.
More sophisticated statistical modeling is possible, for example, by allowing more than one type of potential surrogate, multiple treatment classes, and/or considering models that make fewer normality assumptions. For example, alternative within‐study models could be used to better describe binary outcome data and more sophisticated between‐study regression models be used for the studies' true treatment effects. Another important avenue for future research is to investigate the best methods for computing confidence intervals for the between‐study variance, for which profile likelihood based confidence intervals may prove to be a good solution. A wide variety of methods are available for this under the univariate random‐effects model (Veroniki et al. 2016). Extending some or all of these to the Daniels and Hughes model would be valuable. However this can be anticipated to be challenging because of the bias we have found in the corresponding maximum likelihood point estimate. More extensive simulation and empirical studies would also be highly worthwhile. This could include comparing the performance of methods based on different statistical models, for example the random‐effects bivariate meta‐analysis model and meta‐regression.
Three model parameters have been used to make inferences about whether a potential surrogate endpoint is suitable but more guidance concerning how to assess this would be valuable. We have adopted the approach of considering each of these parameters in turn, but the development of alternative statistical procedures, for example, that consider these parameters simultaneously may be worthwhile. For example, Daniels and Hughes (1997) used Bayes factors to test for associations. We have treated the γi as nuisance parameters but study specific effects may also be of interest (van Aert et al. 2021). Other statistical outputs are also often of interest, for example, prediction intervals (van Aert et al. 2021) and I2 statistics (Higgins and Thompson 2002). We leave the best way to compute quantities such as these as another avenue for further work.
To summarize, our work provides a new way to fit the Daniels and Hughes bivariate meta‐analysis model. We have applied our methodology, and a more conventional Bayesian analysis, to two examples. We have also performed a simulation study. Computing codes, in R, for both the examples and the simulation study are provided in the Supporting Information. To the best of our knowledge, our methods provide the first frequentist implementation of the Daniels and Hughes model. This model is gaining traction and so our work fills an important void in the current state of statistical science.
Conflicts of Interest
Sylwia Bujkiewicz is a member of the NICE Decision Support Unit (DSU) and the NICE Guidelines Technical Support Unit (TSU). She has served as a paid consultant, providing methodological advice in relevant area, to NICE, Roche, RTI Health Solutions, and IQVIA and has received payments for educational events from Roche.
Open Research Badges
This article has earned an Open Data badge for making publicly available the digitally‐shareable data necessary to reproduce the reported results. The data is available in the Supporting Information section.
This article has earned an open data badge “Reproducible Research” for making publicly available the code necessary to reproduce the reported results. The results reported in this article could fully be reproduced.
Supporting information
Supporting Information
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Achana, F. , N. Cooper , S. Bujkiewicz , et al. 2014. “Network Meta‐Analysis of Multiple Outcome Measures Accounting for Borrowing of Information Across Outcomes.” BMC Medical Research Methodology 14: 92.25047164 10.1186/1471-2288-14-92PMC 4142066 · doi ↗ · pubmed ↗
- 2Baker, S. 2018. “Five Criteria for Using a Surrogate Endpoint to Predict Treatment Effect Based on Data From Multiple Previous Trials.” Statistics in Medicine 37: 507–518.29164641 10.1002/sim.7561 PMC 5771803 · doi ↗ · pubmed ↗
- 3Belin, L. , A. Tan , Y. De Rycke , and A. Dechartres . 2020. “Progression‐Free Survival as a Surrogate for Overall Survival in Oncology Trials: A Methodological Systematic Review.” British Journal of Cancer 122: 1707–1714.32214230 10.1038/s 41416-020-0805-y PMC 7250908 · doi ↗ · pubmed ↗
- 4Burke, D. , S. Bujkiewicz , and R. Riley . 2018. “Bayesian Bivariate Meta‐Analysis of Correlated Effects: Impact of the Prior Distributions on the Between‐Study Correlation, Borrowing of Strength, and Joint Inferences.” Statistical Methods in Medical Research 27: 428–450.26988929 10.1177/0962280216631361 PMC 5810917 · doi ↗ · pubmed ↗
- 5Burzykowski, T. , M. Buyse , G. Molenberghs , H. Geys , and D. Renard . 2001. “Validation of Surrogate end Points in Multiple Randomized Clinical Trials With Failure Time end Points.” Journal of the Royal Statistical Society, Series C 50: 405–422.
- 6Burzykowski, T. , M. Buyse , G. Molenberghs , A. Alonso , W. Van der Elst , and Z. Sckedy . 2021. “Meta‐Analytic Approach to Evaluation of Surrogate Endpoints.” Handbook of Meta‐Analysis, edited by C. Schmid , T. Stijnen , and I. White . Chapman and Hall, 457–477.
- 7Buyse, M. , G. Molenberghs , T. Burzykowski , D. Renard , and H. Geys . 2000. “The Validation of Surrogate Endpoints in Meta‐Analyses of Randomized Experiments.” Biostatistics 1: 49–67.12933525 10.1093/biostatistics/1.1.49 · doi ↗ · pubmed ↗
- 8Bujkiewicz, S. , J. Thompson , A. Sutton , et al. 2013. “Multivariate Meta‐Analysis of Mixed Outcomes: A Bayesian Approach.” Statistics in Medicine 32: 3926–3943.23630081 10.1002/sim.5831 PMC 4015389 · doi ↗ · pubmed ↗