Maximizing the accuracy of genetic variance estimation and using a novel generalized effective sample size to improve simulations
Javier Fernández-González, Julio Isidro y Sánchez

TL;DR
This paper introduces a more accurate method for estimating genetic variance and a new effective sample size to improve genetic simulations for breeding programs.
Contribution
A novel PEV-based variance estimation and generalized effective sample size for more accurate and flexible genetic simulations.
Findings
PEV-based additive variance estimation significantly reduces root mean square errors compared to traditional methods.
The generalized effective sample size improves simulation accuracy by accounting for sampling variation.
The method supports complex interactions like genotype by environment effects in breeding program simulations.
Abstract
We developed an improved variance estimation that incorporates prediction error variance as a correction factor, alongside a novel generalized effective sample size to enhance simulations. This approach enables precise control of variance components, accommodating for more flexible and accurate simulations. Phenotypic variation in field trials results from genetic and environmental factors, and understanding this variation is critical for breeding program simulations. Additive genetic variance, a key component, is often estimated using linear mixed models (LMM), but can be biased due to improper scaling of the genomic relationship matrix. Here, we show that this bias can be minimized by incorporating prediction error variance (PEV) as a correction factor. Our results demonstrate that the PEV-based estimation of additive variance significantly improves accuracy, with root mean square…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
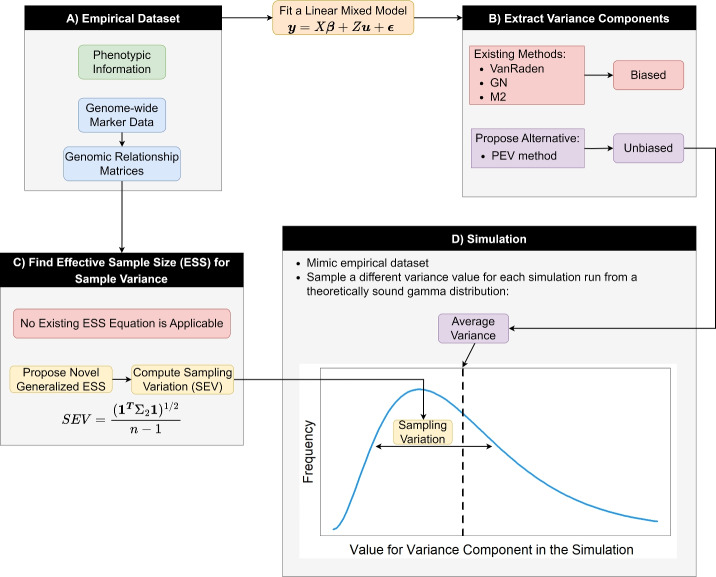 Figure 1
Figure 1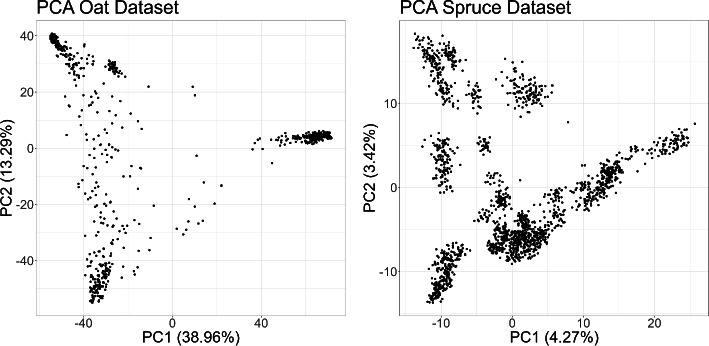 Figure 2
Figure 2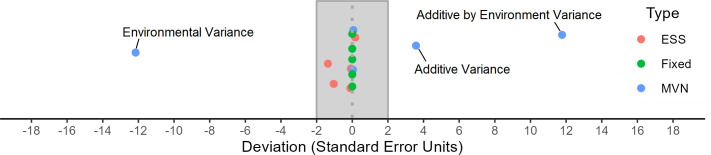 Figure 3
Figure 3- —Ministerio de Ciencia, Innovación y Universidades
- —http://dx.doi.org/10.13039/501100011033Agencia Estatal de Investigación
- —http://dx.doi.org/10.13039/501100008530European Regional Development Fund
- —Universidad Politécnica de Madrid
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsGenetic and phenotypic traits in livestock · Genetic Mapping and Diversity in Plants and Animals · Genetics and Plant Breeding
Introduction
Phenotypic variation in field trials arises from numerous components, including additive and non-additive genetic effects, environmental effects, spatial variation within the field, and measurement errors. Partitioning of the variance involves fitting a model to the data and extracting the variance values from it. There are several available options, including linear mixed models (LMM), which are based on restricted maximum likelihood (REML); Haseman-Elston regression, based on least squares, and bayesian models, based on Gibbs sampling. Each of these methods has several advantages and disadvantages, but all of them may present bias in the estimation of variance components under certain circumstances as discussed in depth in Chen (2014, 2016), de Los Campos et al. (2015). In this work, we will focus on LMM due to their combination of computational efficiency, flexibility for including non-additive effects, good performance (Kerin and Marchini 2020) and widespread application (Hallauer et al. 2010; Coutiño-Estrada and Vidal-Martínez 2006; Carvalho et al. 2017; Yue et al. 2022; Coelho et al. 2021). The bias in the estimation can come from two main sources (de Los Campos et al. 2015): firstly, overly simplistic model assumptions that do not match the reality can bias the variance estimates. This is outside the scope of this work. Secondly, extracting a value for the variance components from a given model is not straightforward and can cause substantial additional bias. In this work, we aim to prove this issue, as well as proposing a solution, which will remove one of the main sources of bias for variance estimates from LMM.
Minimizing bias in the estimation of variance components is crucial in breeding, as they are required for the computation of heritability and the study of the genetic control of complex traits. They are also essential for estimating response to selection using the breeder’s equation (Lush 1943). The additive genetic variance \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\big (\sigma ^2_a\big )$$\end{document} is of special relevance as the only heritable genetic effect (Falconer and Mackay 1983) and we will focus on it for the sake of simplicity. However, our arguments apply to any other variance component as well.
Typically, in a LMM, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\sigma ^2_a$$\end{document} is extracted from a random effect \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\varvec{a}} \sim \text {MVN}({\varvec{0}}, G\sigma ^2_{a^*})$$\end{document} , where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\varvec{a}}$$\end{document} is a vector of true breeding values, G is an additive genomic relationship matrix, often calculated with the VanRaden (2008) formulation, and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\sigma ^2_{a^*}$$\end{document} is a scaling factor estimated by REML. It is often incorrectly assumed that \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\sigma ^2_a = \sigma ^2_{a^*}$$\end{document} , using \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\sigma ^2_{a^*}$$\end{document} as the estimate for the additive variance component. This is true only if the G matrix is scaled to unit variance, meaning the overall variability encompassed within the multivariate covariance matrix G equals one. The scaling performed in the standard G matrix (VanRaden 2008) attempts to achieve this, but it relies on several, unrealistic assumptions outlined in Appendix 1. This results in the VanRaden matrix being improperly scaled for variance component estimation, making \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\sigma ^2_{a^*}$$\end{document} non-representative of the overall additive variance, i.e., \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\sigma ^2_{a^*} \ne \sigma ^2_a$$\end{document} (Forni et al. 2011; Lehermeier et al. 2017; Feldmann et al. 2022). \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\sigma ^2_{a^*}$$\end{document} is simply a scaling factor that does not have a useful biological interpretation. It is important to note that the genomic best linear unbiased predictors (BLUPs) estimated by the model are unaffected by the scaling of the G matrix; they depend only on its structure (Feldmann et al. 2022). Therefore, we are not arguing against the use of the VanRaden relationship matrix, but rather showcasing that it is not suitable for the estimation of variance components through REML.
Other attempts at scaling the G matrix to unit variance include normalizing it to have average diagonal values equal to one (Forni et al. 2011; Vitezica et al. 2017), i.e., \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\text {GN} = \frac{G}{tr(G)/n}$$\end{document} , where GN stands for normalized genomic relationship matrix, tr() refers to the trace of a matrix and n is the number of genotypes. However, as we exemplify in Supplementary File 1, it presents some bias. Similarly, Feldmann et al. (2022) described a relationship matrix based on average semivariance: \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$K_{\text {ASV}} = \frac{G}{\text {tr}(G)/(n-1)}$$\end{document} . This is conceptually different to GN, but numerically the differences are negligible.
Alternatively, Lehermeier et al. (2017) proposed the M2 method, which can estimate \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\sigma ^2_a$$\end{document} independently of the scaling of G matrix. This method allows to extract the actual additive variance from the marker effects and the covariance matrix between marker positions. However, they failed to account for the shrinkage of the estimated marker effects, causing a consistent underestimation of additive variance (proof available in Appendix 2). Thus, the first objective of this work is to propose a methodology able to extract additive variance from a given LMM without bias and compare it to existing methodologies.
Among the many applications of accurate variance components, we will further explore their use in simulations. Since genomics became commonplace in plant breeding, simulations have served as a test-bed for new methodologies. The seminal work for genomic selection (Meuwissen et al. 2001) relied heavily on simulations, and numerous other studies have also incorporated them (Jannink 2010; Wimmer et al. 2013; Endelman et al. 2014; Bernardo 2014; Hickey et al. 2014; Heslot et al. 2015; Neyhart et al. 2017; Technow et al. 2012; Faux et al. 2016; Jighly et al. 2019) due to their flexibility, speed and negligible cost compared to performing empirical experiments. However, simulations are only useful if they faithfully replicate the genetic control of the traits of interest; otherwise, any conclusion drawn from them will probably not hold in actual breeding programs. Therefore, it is important to first estimate variance components from empirical field trials and then use them as the target variances for the simulation (Ould Estaghvirou et al. 2013). Thus, minimizing bias in the estimation of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\sigma ^2_a$$\end{document} and other variance components is critical to enable improved simulations.
Once the variance components are estimated, it is possible to start the simulation process that mimics the empirical trait (Daetwyler et al. 2013; Sun et al. 2011; Faux et al. 2016; Yuan et al. 2012). Several key criteria must be met. These include i) ensuring stable marker effects across generations, ii) adjusting marker effects to match an assumed trait architecture, iii) maintaining coherence among different genetic factors, iv) ensuring the variance of the simulated effects matches the target variance, and v) accounting for the standard error of the sample variance (SEV).
The SEV is often neglected but it is crucial for ensuring the accuracy and reliability of the simulation results. For instance, we can assume that the average variance of the location effect for the trait of interest \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\sigma ^2_{L}$$\end{document} is known. Nevertheless, in real field trials, the value of the location variance varies across different years. Therefore, forcing all years to have a location variance equal to \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\sigma ^2_{L}$$\end{document} would not be realistic. To address this issue, different years can have different values of the location variance, with the average across years being equal to \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\sigma ^2_{L}$$\end{document} . This creates the problem of controlling how much the location variance should vary across years, which can be done through the SEV.
It is often of interest to assume correlated locations, making the effective sample size (ESS) different from the number of locations and altering the SEV value. A similar problem arises in most terms of the simulation, such as genetic effects in which the genotypes are correlated. Therefore, a generalized ESS is needed for controlling the SEV. To our knowledge, none of the available equations for calculating ESS or SEV applies to a generalized multivariate normal distribution, limiting their application in this context (Bayley and Hammersley 1946; Vallejos and Osorio 2014; Berger et al. 2014; Lin et al. 2007; Morita et al. 2008; Cogley 1999; Bretherton et al. 1999; Thiébaux and Zwiers 1984; Afyouni et al. 2019; Chelton 1983). Thus, the second objective of this work is to find a generalized ESS for SEV calculation.
In summary, the objectives of this work are to 1) find an improved method for estimating variance components from a LMM robust to the improper scaling of the G matrix, 2) develop a method to calculate the generalized ESS and SEV for any multivariate normal distribution and 3) build a simulation strategy that combines both advancements to meet all the quality criteria outlined previously and match reality as closely as possible.
Materials and methods
In Fig. 1 we have summarized the main modules of this paper, showcasing how they interact to enable more realistic simulations.Fig. 1. Overview of the study structure. Using an empirical dataset, we estimated genetic and non-genetic variance components, which were used as the baseline for simulation variance components. A novel equation for the standard error of the variance (SEV) was applied to control sampling variation across simulation runs. Detailed descriptions of all methods and equations are provided in the following sections
Materials
In this section, we will explain the two empirical datasets we used in this work (Fig. 1A). We chose a highly homozygous oat dataset and a highly heterozygous spruce dataset. This allowed us to test the methodologies across varying degrees of heterozygosity, which significantly impacts variance estimation (Feldmann et al. 2022). Both datasets include several traits, ensuring consideration of varied trait architectures.
The oat dataset (Canales et al. 2021a) comprises 699 lines genotyped with 17,288 SNP markers after quality control and phenotyped in a randomized complete block design (RCBD) across three environments with three blocks each. All lines were almost completely homozygous and exhibited a strong population structure. The inbred nature of the lines ensures that they are not in Hardy–Weinberg equilibrium (HWE). Among the environments, two corresponded to different locations within the same year, and one to a different year. The latter was discarded to avoid the large variation across-year. Four traits were included in this study, yield, biomass, height, and heading days.
The spruce dataset (Beaulieu et al. 2014) contained 1722 lines with adjusted phenotypes summarizing the performance across two environments for three traits: diameter at breast height, density, and height. The lines were genotyped with 6930 SNP markers after quality control. In contrast to the oat dataset, population structure was weak, and 27.6% of the marker positions were heterozygous. We applied a corrected \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\chi ^2$$\end{document} test at each marker position to assess deviations from HWE (Graffelman 2010). Out of 6930 loci, 4480 were in HWE with a p value above 0.01, while 2450 showed significant deviations, exceeding the expected type I errors rate ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$6930/100 = 69.3$$\end{document} ). Thus, although the population is not fully in HWE, it remains close. It is important to note that this approach provides a broad assessment of whether a population is in Hardy–Weinberg equilibrium (HWE); however, it does not identify specific loci deviating from HWE due to the absence of a multiple-test correction. For example, applying a Bonferroni correction reveals that only 909 markers significantly diverge from HWE.
To further investigate the population structure, we conducted a principal component analysis on the double-centered (Gauch Jr et al. 2019) marker matrix of both datasets. Figure 2 displays individuals based on their first two principal components (PCs). In oat, these PCs account for over 50% of the variance, indicating strong population structure. In spruce, although some clusters are visually apparent, the first two principal components explain less than 10% of the variance, suggesting weak population structure and small genetic distances between clusters.Fig. 2. Genotypes are plotted based on their first two principal components (PC1, PC2) derived from the double-centered marker matrix for both datasets. The percentage of variance explained is shown in brackets next to each principal component
Methods for variance component estimation
We used several methods to estimate additive variance (Fig. 1, B) and evaluated their accuracy. We tested variance estimation using the classical VanRaden (2008) relationship matrix, the GN matrix (the only unbiased estimator in Feldmann et al. (2022)), and the M2 method from Lehermeier et al. (2017), which was also shown to be unbiased in its original paper. However, as explained in the introduction, we believe that none of these methods reliably produce unbiased estimates. Therefore, we propose a new methodology based on prediction error variance (PEV) to address this issue.
VanRaden method
Let M be a matrix of marker scores, with n individuals in rows, p marker positions in columns and values within the matrix counting the number of copies of the minor allele in each position. Then, Z is the matrix obtained by column-centering M. This allows to compute the VanRaden (2008) matrix for diploid species as:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} G = \frac{ZZ^T}{2 \sum _{j=1}^p p_j(1-p_j)} \end{aligned}$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$p_j$$\end{document} is the minor allele frequency for marker j. The variance component estimation is done by fitting a mixed model to the data with a random effect for the additive values: \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\varvec{a}} \sim \text {MVN}({\varvec{0}}, G\sigma ^2_{a^*})$$\end{document} . \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\sigma ^2_{a^*}$$\end{document} will be used as the value for the variance component, i.e., it will be assumed that \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\sigma ^2_{a^*} = \text {var}({\varvec{a}}) = \sigma ^2_a$$\end{document} .
The derivation of Eq. (1) and an explanation of why it relies on unrealistic assumptions are available in Appendix 1.
Normalized genomic relationship (GN) method
A normalized relationship matrix GN is obtained as in Forni et al. (2011):
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \text {GN} = \frac{G}{\text {tr}(G)/n} \end{aligned}$$\end{document}The trace of a matrix is the sum of its eigenvalues (Jonsson 1982). Thus, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\text {tr}(G)/n$$\end{document} is the average of the eigenvalues of the G covariance matrix and is a common way to extract the overall variance from a covariance matrix. However, as the off-diagonals are completely disregarded, this method is biased (see Supplementary File 1). An extreme example would involve all instances in the GN matrix having a variance of 1 and correlations of 1. This would cause all genotypes to have the same additive values and therefore \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\sigma ^2_a = \text {var}({\varvec{a}})$$\end{document} would be equal to zero even if \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\text {tr}(\text {GN})/n = 1$$\end{document} .
The variance component estimation is done by fitting a mixed model to the data in which \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\varvec{a}} \sim \text {MVN}({\varvec{0}}, \text {GN}\sigma ^2_{a^*})$$\end{document} and using \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\sigma ^2_{a^*}$$\end{document} as the estimate for the additive variance.
M2 method
Instead of directly relying on REML in a mixed model, additive variance can be alternatively estimated from the marker effects as described by Lehermeier et al. (2017):
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \sigma ^2_a = \text {var}({\varvec{a}}) = \varvec{\beta }^T \Sigma _M \varvec{\beta } \end{aligned}$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\beta$$\end{document} is a vector of additive marker effects and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\Sigma _M$$\end{document} is the covariance matrix between markers. This method directly accounts for linkage disequilibrium to address the limitations of VanRaden and GN methods. However, in Appendix 2 we argue that the M2 method is also unsuitable because it calculates the variance of the shrunk BLUPs rather than the actual population variance of the true breeding values. Furthermore, for large numbers of markers, computing \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\Sigma _M$$\end{document} can become unfeasible.
Prediction error variance (PEV) method
We propose this methodology to correct for the shrinkage in the M2 method, thereby eliminating the source of the bias. Furthermore, we will use an alternative implementation based on the genomic estimated breeding values (GEBVs) rather than on marker effects, massively reducing the computational burden. According to Henderson (1975), it is known that:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \text {cov}\begin{pmatrix} {\varvec{a}} \\ \varvec{{\hat{a}}} \end{pmatrix} = \begin{pmatrix} G\sigma ^2_{a^*} & G\sigma ^2_{a^*} - \text {PEV} \\ G\sigma ^2_{a^*} - \text {PEV} & G\sigma ^2_{a^*} - \text {PEV} \end{pmatrix} \end{aligned}$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{{\hat{a}}}$$\end{document} is a vector of estimated additive genotypic values (i.e., they are shrunk BLUPs) and PEV is the matrix of prediction error variance-covariance. \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\text {cov}(\cdot )$$\end{document} denotes the variance-covariance matrix of a random vector. Although \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\text {var}(\cdot )$$\end{document} is commonly used for this purpose, in our work, we reserve \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\text {var}(\cdot )$$\end{document} to indicate the sample variance of a vector, which is a scalar rather than a matrix. From this, we can express \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\text {cov}({\varvec{a}})$$\end{document} as a function of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\text {cov}(\varvec{{\hat{a}}})$$\end{document} and PEV:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \text {cov}(\varvec{{\hat{a}}}) = G\sigma ^2_{a^*} - \text {PEV};\\ \text {cov}(\varvec{{\hat{a}}}) = \text {cov}({\varvec{a}}) - \text {PEV};\\ \text {cov}({\varvec{a}}) = \text {cov}(\varvec{{\hat{a}}}) + \text {PEV}; \end{aligned}$$\end{document}Therefore, the scalar \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\sigma ^2_a = \text {var}({\varvec{a}})$$\end{document} can be expressed as:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \small \sigma ^2_a = \text {var}({\varvec{a}}) = \text {var}(\varvec{{\hat{a}}}) + \frac{\text {tr}(\text {PEV})}{n} = \frac{\sum _{i=1}^n ({\hat{a}}_i - \bar{a})^2}{n} + \frac{\text {tr}(\text {PEV})}{n} = \frac{\sum _{i=1}^n {\hat{a}}_i^2}{n} + \frac{\text {tr}(\text {PEV})}{n} \end{aligned}$$\end{document}The value of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\sigma ^2_a$$\end{document} is calculated from the variance of the shrunk BLUPs in \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{{\hat{a}}}$$\end{document} and the average PEV is added to compensate for the shrinkage. Please note that in the denominator of the sample variance of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{{\hat{a}}}$$\end{document} we have used n instead of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$n-1$$\end{document} because the BLUPs are always mean-centered, which means that their population mean is known to be zero ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\bar{a} = 0$$\end{document} ) and there is no need to expend a degree of freedom estimating it.
This method still requires extracting a scalar that summarizes the overall variance from the multivariate PEV matrix as the mean of its trace, which will incur in some bias as explained previously and exemplified in Supplementary file 1. However, we argue that the error incurred when calculating the average PEV is smaller than that caused by the scaling of GN. The reason is that the variances in PEV are always smaller or equal to those in \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\text {GN}\sigma ^2_{a^*}$$\end{document} . As a result, if a similar relative error occurs when extracting the overall variance from PEV and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\text {GN}\sigma ^2_{a^*}$$\end{document} , a smaller absolute error will be incurred for the PEV matrix, minimizing bias. Furthermore, the PEV method accounts for linkage disequilibrium and marker effects, which are implicitly included in the vector of BLUPs, whereas the REML estimate of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\sigma ^2_{a^*}$$\end{document} does not. It is also important to note that the PEV method relies on the REML estimate of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\sigma ^2_{a^*}$$\end{document} and other variance components to construct the mixed model equations (Henderson 1975) necessary for computing the BLUPs and PEV matrix. Therefore, rather than an alternative to REML, the PEV method serves as a correction to REML estimates to incorporate linkage disequilibrium and the distribution of marker effects.
Validation pipeline for variance estimation
To find which estimation method is better, we tested them in several models for both the oat and the spruce dataset. To that end, we applied a validation methodology similar to the one in Lehermeier et al. (2017). The following two-stage model was be used:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} {\varvec{y}} = X_{L} {\varvec{L}} + X_{Block} \varvec{Block} + X_g{\varvec{g}} + \varvec{\epsilon } \end{aligned}$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\varvec{y}}$$\end{document} is a vector of phenotypes, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\varvec{L}}$$\end{document} is a vector of fixed location effects, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{Block}$$\end{document} is a vector of fixed block effects nested within location, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\varvec{g}}$$\end{document} is a vector fixed genotypic effects and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{\epsilon } \sim \text {MVN}({\varvec{0}}, R)$$\end{document} is a vector of independent, identically distributed (i.i.d.) residuals within each location with heterogeneous variance across locations. \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$X_{L}$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$X_{Block}$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$X_g$$\end{document} are the design matrices of their corresponding effects. The \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\varvec{L}}$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{Block}$$\end{document} effects were set as fixed because they did not present enough levels for a good variance component estimation by REML. Next, the genotypic best linear unbiased estimators ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{{\hat{g}}}$$\end{document} ) were used as the response variable for a stage 2 model that partitions them into additive effects and residuals:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \varvec{{\hat{g}}} = {\varvec{a}} + \varvec{\epsilon } \end{aligned}$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\varvec{a}} \sim \text {MVN}({\varvec{0}}, K\sigma ^2_{a^*})$$\end{document} is a vector of additive genotypic values and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{\epsilon } \sim \text {MVN}({\varvec{0}}, I\sigma ^2_\epsilon )$$\end{document} is a vector of residuals. K can be the G or GN matrix as needed for each variance estimation method.
One important note about the notation we will use going forward: asterisks will be included in the subindex of the variance components (e.g., \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\sigma ^2_{a^*}$$\end{document} ) when they are just a scaling factor for a covariance structure without unit variance (such as G). The asterisk is used to indicate that the REML estimate is a non-interpretable value different from the actual variance component. Please note that for i.i.d. terms (e.g., \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\sigma ^2_\epsilon$$\end{document} ), the covariance matrix is the identity (scaled to unit variance) and in these cases, the asterisk is not included as the REML estimates are the actual variance component.
From the model assumption that the residuals are independent from the other model effects, we can state that, within the stage 2 model:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} & \text {var}(\varvec{{\hat{g}}}) = \text {var}({\varvec{a}} + \varvec{\epsilon }) = \text {var}({\varvec{a}}) + \text {var}(\varvec{\epsilon });\\ & \sigma ^2_a = \text {var}({\varvec{a}}) = \text {var}(\varvec{{\hat{g}}}) - \text {var}(\varvec{\epsilon }) = \frac{\sum _{i=1}^n ({\hat{g}}_i - \bar{{\hat{g}}})^2}{n-1} - \sigma ^2_\epsilon \end{aligned}$$\end{document}This method of calculating \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\sigma ^2_a$$\end{document} is unbiased, as it involves subtracting the sample variance (an unbiased estimator) of the response variable and the REML estimation (an unbiased estimator) of the residual variance. This is only possible because there is a single random effect in the model. Thus, this methodology is useful for validation purposes in this simple model, but its applicability is limited outside this context. We can compare the VanRaden, GN, M2, and PEV methods for estimating \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\sigma ^2_a$$\end{document} against the unbiased estimation of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\sigma ^2_a = \frac{\sum _{i=1}^n ({\hat{g}}_i - \bar{{\hat{g}}})^2}{n-1} - \sigma ^2_\epsilon$$\end{document} , allowing us to identify the estimator with the lowest bias. Furthermore, in Appendix 5, we have also evaluated the bias of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\sigma ^2_a$$\end{document} estimated in the framework of the natural and orthogonal interactions (NOIA) model (Vitezica et al. 2017).
It is important to clarify that, in this context, bias strictly refers to the error incurred when extracting the additive variance component from a given model. Bias resulting from an unsuitable model, such as one based on unrealistic assumptions, is beyond the scope of this work.
To study the effect of the experimental design, we also performed this analysis in an unbalanced subset of the oat dataset. We randomly discarded 75% of the observations in each location, yielding a highly unbalanced dataset. Then, we estimated the variance components using this unbalanced dataset and performed 20 repetitions to account for the influence of the random selection of observations. We compared the average variance values across repetitions for the different estimation methodologies.
Generalized effective sample size
Here, we will introduce the equations we propose for computing sampling variation for Fig. 1C. It is well known that the standard errors in the estimation of sample mean (SEM) and sample variance (SEV) are heavily influenced by sample size. When the available data are comprised of n i.i.d. observations sampled from a normal distribution of variance \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\sigma ^2$$\end{document} , the standard errors can be calculated as follows:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{array}{*{20}l} {{\text{SEM}} = \frac{\sigma }{{n^{{1/2}} }}} \hfill \\ {{\text{SEV}} = \frac{{2^{{1/2}} \sigma ^{2} }}{{(n - 1)^{{1/2}} }}} \hfill \\ \end{array} {\text{ }}$$\end{document}However, correlated data often carry less information than i.i.d. samples, i.e., their effective sample size (ESS) is usually lower than the census count. For instance, the information carried by n observations that are perfectly correlated is equal to an ESS of one, as all observations after the first one are redundant. A lot of research is available in the literature for the ESS, but it mostly focuses on the sample mean and in autoregressive processes, linear models, and Bayesian statistics (Vallejos and Osorio 2014; Berger et al. 2014; Lin et al. 2007; Morita et al. 2008; Cogley 1999; Bretherton et al. 1999; Thiébaux and Zwiers 1984; Afyouni et al. 2019; Chelton 1983). Thus, as far as we are concerned, a generalized way of calculating ESS for sample variance is not available in the literature. Bayley and Hammersley (1946) show how it can be calculated in an autoregressive process, and our work could be seen as a generalization of it for any multivariate normal distribution. We have described how SEM, SEV and their associated effective sample sizes ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\text {ESS}_\mu$$\end{document} for the mean and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\text {ESS}_{\sigma ^2}$$\end{document} for the variance) can be calculated even in the presence of heteroscedasticity, heterogeneous correlations, and nonuniform means. For the sake of brevity, here we will just show the final equations, but a detailed mathematical derivation of them is available in Appendix 3. For any \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\varvec{X}} = \{X_1, X_2,\ldots , X_n\} \sim \text {MVN}(\varvec{\mu }, \Sigma )$$\end{document} :
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{array}{*{20}l} {{\text{SEM}} = \left( {\frac{{\overline{{\sigma ^{2} }} }}{{{\text{ESS}}_{\mu } }}} \right)^{{1/2}} = \frac{{({\mathbf{1}}^{\user2{T}} \Sigma {\mathbf{1}})^{{1/2}} }}{n}} \hfill \\ {{\text{SEV}} = \frac{{2^{{1/2}} \overline{{\sigma ^{2} }} }}{{({\text{ESS}}_{{\sigma ^{2} }} - 1)^{{1/2}} }} = \frac{{({\mathbf{1}}^{\user2{T}} \Sigma _{2} {\mathbf{1}})^{{1/2}} }}{{n - 1}}} \hfill \\ {\overline{{\sigma ^{2} }} = \frac{{tr(\Sigma )}}{n}} \hfill \\ {\Sigma _{2} [i,j] = 2(\Sigma _{1} [i,j])^{2} + 4\Sigma _{1} [i,j](\mu _{i} - \bar{\mu })(\mu _{j} - \bar{\mu })} \hfill \\ {\Sigma _{1} [i,j] = \Sigma [i,j] + {\text{SEM}}^{2} - \frac{{\Sigma [i,1:n]{\mathbf{1}}}}{n} - \frac{{\Sigma [j,1:n]{\mathbf{1}}}}{n}} \hfill \\ {{\text{ESS}}_{\mu } = \frac{{tr(\Sigma )}}{{{\mathbf{1}}^{\user2{T}} \Sigma {\mathbf{1}}}}n} \hfill \\ {{\text{ESS}}_{{\sigma ^{2} }} = \frac{{2(\overline{{\sigma ^{2} }} )^{2} (n - 1)^{2} }}{{{\mathbf{1}}^{\user2{T}} \Sigma _{2} {\mathbf{1}}}} + 1} \hfill \\ \end{array}$$\end{document}It is important to clarify that, in Eq. (7), \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\Sigma$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\Sigma _1$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\Sigma _2$$\end{document} refer to different matrices. \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\Sigma _1$$\end{document} is derived from \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\Sigma$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\Sigma _2$$\end{document} is derived from \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\Sigma _1$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{\mu }$$\end{document} . To validate the proposed methods, we tested them across various scenarios, incorporating autoregressive covariance structures and additive and dominance relationship matrices with different means. We compared the SEM and SEV calculated as proposed in Eq. (7) with: i) the standard error of the mean and variance estimated under the assumption of i.i.d. observations with homogeneous means (Eq. 6) and ii) empirical standard errors, calculated as the standard deviation of the sample mean and sample variance estimated from \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$10^5$$\end{document} samples drawn from the corresponding multivariate normal distributions.
Simulation strategies
We compared the two most common simulation strategies to our proposed methodology, which is based on the PEV variance component estimation and the usage of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\text {ESS}_{\sigma ^2}$$\end{document} to introduce sampling variance as outlined in Fig. 1D. First, we fitted a model to the oat dataset for yield to extract the variance components used as targets for the simulation:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} {\varvec{y}} = X_{L} {\varvec{L}} + X_{Block} \varvec{Block} + Z_a{\varvec{a}} + Z_{aL}{{\varvec{a}}}{{\varvec{L}}} + \varvec{\epsilon } \end{aligned}$$\end{document}Where all effects are the same as in Eq. (5) where applicable, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\varvec{a}} \sim \text {MVN}({\varvec{0}}, G\sigma ^2_{a^*})$$\end{document} is a vector of additive genotypic values and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${{\varvec{a}}}{{\varvec{L}}}$$\end{document} is a vector of additive by location interaction with the following covariance structure:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} {{\varvec{a}}}{{\varvec{L}}} \sim \text {MVN}({\varvec{0}}, \begin{pmatrix} \sigma ^2_{aL1^*} & 0 \\ 0 & \sigma ^2_{aL2^*} \end{pmatrix}\otimes G) \end{aligned}$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\otimes$$\end{document} refers to the Kronecker product. We assumed the different locations were independent to reduce the number of parameters the model needed to estimate and to facilitate the estimation of the overall variance component from the interaction terms. \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{\epsilon }$$\end{document} represents the vector of residuals with heterogeneous variance across locations:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \varvec{\epsilon } \sim \text {MVN}\left({\varvec{0}}, \begin{pmatrix} \sigma ^2_{\epsilon L1} & 0 \\ 0 & \sigma ^2_{\epsilon L2} \end{pmatrix}\otimes I\right) \end{aligned}$$\end{document}The design matrices for their corresponding effects are \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$X_L$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$X_{Block}$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$Z_a$$\end{document} , and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$Z_{aL}$$\end{document} . Non-additive effects such as dominance and epistasis were excluded for the sake of simplicity. We estimated all variance components of random effects using REML and by the PEV method. For interaction effects and residuals with heterogeneous variances across locations, the overall variance was calculated as the average of the variance of the two locations (a weighted mean was unnecessary due to the balanced experimental design). The variance of the fixed location effect was calculated as \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\text {var}({\varvec{L}}) = \text {var}(X_{L} \hat{{\varvec{L}}})$$\end{document} , where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\hat{{\varvec{L}}}$$\end{document} is the vector of best linear unbiased estimators. The variance of the block effect was calculated similarly within each location and the average across locations was taken as the overall variance.
For all simulations, we randomly selected a subset of 50 genotypes and used their empirical genotypic information. We simulated field trials consisting of 5 locations with 3 blocks each, arranged in RCBD. We assumed that the locations had a compound symmetry covariance structure, with homogeneous variance and a common correlation of 0.3. These positive correlations reflect a similarity between locations, which is typical in breeding programs targeting specific environmental profiles. All effects in Eq. (8) were simulated, and the phenotype was calculated as the sum of all of them. We performed 500 repetitions for each simulation type.
MVN simulation: not marker-based
All effects were sampled from their corresponding normal distributions, which is the reason why we will refer to this approach as the multivariate normal (MVN) one:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{array}{*{20}l} {\user2{L}\sim {\text{MVN}}\left( {{\mathbf{0}},K_{e} \sigma _{{L^{*} }}^{2} } \right)} \hfill \\ {\user2{Block}\sim N\left( {0,\sigma _{{Block}}^{2} } \right)} \hfill \\ {\user2{a}\sim {\text{MVN}}\left( {{\mathbf{0}},G\sigma _{{a^{*} }}^{2} } \right)} \hfill \\ {\user2{aL}\sim {\text{MVN}}\left( {{\mathbf{0}},K_{e} \otimes G\sigma _{{aL^{*} }}^{2} } \right)} \hfill \\ {\varepsilon \sim N\left( {0,\sigma _{\varepsilon }^{2} } \right)} \hfill \\ \end{array}$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$K_e$$\end{document} is the covariance structure assumed for the locations (common variance with unit value and correlations of 0.3). The values for all variance components were the REML estimates from the model in Eq. (8). The PEV estimate of the variances was not used because it does not compensate for the inadequate scaling of the G matrix, while the REML estimate does.
Fixed simulation: marker-based, fixed variance components
In this methodology, all effects were initially simulated at the marker level with arbitrary variance. In the second step, the effects were scaled to match the target variance exactly. For this reason, we will refer to this simulation as the ‘Fixed’ approach going forward. The target variance values were obtained using the PEV method of variance estimation as explained in Sect. 2.4.
Additive effects were based on 2500 randomly selected markers that acted as quantitative trait loci (QTL). It is important to note that, since we were simulating a single field trial, there is no drawback in setting the markers to be the actual QTL. However, for simulations spanning several generations, it would be important to instead treat the QTL as positions in linkage disequilibrium with the markers, which would allow to consider the variation in linkage disequilibrium patterns across generations due to recombination during meiosis (Daetwyler et al. 2013; Sun et al. 2011; Faux et al. 2016; Yuan et al. 2012).
Non-scaled additive marker effects ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{\beta ^*}$$\end{document} ) for the 2500 QTL were sampled from a gamma distribution with shape = 0.4, scale = 1.66. These parameters are commonly used in the literature, such as in Meuwissen et al. (2001) and Technow et al. (2012). To avoid the minor allele always having a positive effect, we randomly multiplied the additive marker effects by 1 or \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$-1$$\end{document} with equal probability. Non-scaled additive values ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{a^*}$$\end{document} ) were obtained as \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{a^*} = M\varvec{\beta ^*}$$\end{document} , where M refers to the matrix of numeric marker scores. Next, we scaled \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{a^*}$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{\beta ^*}$$\end{document} to the desired target variance, which can easily be done by dividing them by their standard deviation and multiplying by the target standard deviation:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} & \varvec{\beta } = \varvec{\beta ^*}\frac{\sigma _a}{sd(\varvec{a^*})}\\ & {\varvec{a}} = M\varvec{\beta } \end{aligned}$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{\beta }$$\end{document} are the scaled marker effects and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\sigma _a$$\end{document} is the PEV estimate for the standard deviation of the additive effect. \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\varvec{a}}$$\end{document} contains the scaled additive values, i.e., \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$sd({\varvec{a}}) = \sigma _a$$\end{document} .
For the simulation of the additive by location interaction, the aim was to obtain a matrix AxL with genotypes in the rows and locations in the columns, where the elements correspond to the additive by location interaction values. The first step was defining a matrix \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$M_a$$\end{document} with dimensions corresponding to n individuals in the rows and p QTL in the columns. This matrix contains the marker scores in M multiplied by their corresponding marker effects in \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{\beta }$$\end{document} , i.e.,:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} M_a = M \begin{pmatrix} \beta _1 & 0 & \dots & 0 \\ 0 & \beta _2 & & 0 \\ \vdots & & \ddots & \vdots \\ 0 & 0 & \dots & \beta _p \end{pmatrix} \end{aligned}$$\end{document}Next, 100 environmental covariates for each location were sampled from \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\text {MVN}({\varvec{0}}, K_e)$$\end{document} and the results were stored in a matrix ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$L_{\text {cov}}$$\end{document} ) with the environmental covariates in the rows and the locations in the columns. A matrix \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$B_{aL}$$\end{document} with dimensions \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$p \times t$$\end{document} (number of QTL times number of environmental covariates) was created and its elements were sampled from a standard normal distribution. \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$B_{aL}$$\end{document} contains the intensity of interaction between additive effects and environmental covariates. The non-scaled additive by location interaction matrix \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$AxL^*$$\end{document} was obtained by multiplying each marker effect in \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$M_a$$\end{document} by each environmental covariate in \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$L_{\text {cov}}$$\end{document} and their interaction intensity in \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$B_{aL}$$\end{document} and adding up the corresponding values for each genotype-location combination. In matrix notation:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} AxL^* = M_a B_{aL} L_{\text {cov}} \end{aligned}$$\end{document}Subsequently, the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$AxL^*$$\end{document} was double-centered to remove any main effects and leave only the interaction terms. Finally, the double-centered matrix ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$AxL^*_c$$\end{document} ) was scaled to the target variance as:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} AxL = AxL_c^* \frac{\sigma _{aL}}{sd(AxL_c^*)} \end{aligned}$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$sd(AxL_c^*)$$\end{document} refers to computing the standard deviation of all elements in the matrix and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$sd(AxL) = \sigma _{aL}$$\end{document} .
The non-scaled location main effects \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{L^*}$$\end{document} were calculated as the sum of the column means of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$AxL^*$$\end{document} . Then, the scaled effects \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\varvec{L}}$$\end{document} were calculated as:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} {\varvec{L}} = \varvec{L^*} \frac{\sigma _{L}}{sd(\varvec{L^*})} \end{aligned}$$\end{document}Finally, within each location, the non-scaled block effects \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{Block^*}$$\end{document} and residuals \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{\epsilon ^*}$$\end{document} were sampled from a standard normal distribution and scaled to the target variance to obtain:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} & \varvec{Block} = \varvec{Block^*}\frac{\sigma _{Block}}{sd(\varvec{Block^*})}\\ & \varvec{\epsilon } = \varvec{\epsilon ^*}\frac{\sigma _{\epsilon }}{sd(\varvec{\epsilon ^*})} \end{aligned}$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{Block}$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{\epsilon }$$\end{document} are the scaled block and residual values.
ESS simulation: marker-based, variable variance components
This simulation was performed similarly to the previous one, except for the step for scaling the effects to the target variance. In the previous case, scaling was done by dividing all values by their standard deviation and multiplying by the target standard deviation estimated from the empirical data. Conversely, in this scenario, a variable scaling factor was used to account for sampling variance. This approach uses the fact that sample variance follows a gamma distribution with a mean equal to the population variance and a standard deviation equal to SEV. As many effects are not i.i.d., calculating SEV requires considering its \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\text {ESS}_{\sigma ^2}$$\end{document} . For this reason, we will refer to this simulation as the ‘ESS’ approach going forward.
For the additive effects, the population variance is the desired target variance \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\sigma ^2_a$$\end{document} (estimated through the PEV method) and, as shown in Eq. (7), the standard deviation SEV can be calculated from \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\Sigma = \text {GN}\sigma ^2_a$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{\mu } = {\varvec{0}}$$\end{document} and n equal to the number of genotypes. Please note that the GN matrix is used in the calculation of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\Sigma$$\end{document} because having a diagonal with unit average ensures that, in Eq. (7), \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\bar{\sigma ^2} = \frac{\text {tr}(\Sigma )}{n} = \frac{\text {tr}(\text {GN})}{n}\sigma ^2_a = \sigma ^2_a$$\end{document} . After computing SEV, we can sample a variance value \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$s^2_a$$\end{document} from a gamma distribution of mean \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\sigma ^2_a$$\end{document} and variance \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\text {SEV}^2$$\end{document} , i.e., \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$s^2_a \sim \Gamma (\mu = \sigma ^2_a, \sigma ^2 = \text {SEV}^2)$$\end{document} . For ease of use, it is possible to find the scale ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\theta$$\end{document} ) and shape (k) parameters of the gamma distribution from its mean and variance as follows: \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\theta = \frac{\sigma ^2}{\mu } = \frac{\text {SEV}^2}{\sigma ^2_a}$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$k = \frac{\mu ^2}{\sigma ^2} = \frac{\sigma ^4_a}{\text {SEV}^2}$$\end{document} . Finally, the square root of the sampled \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$s^2_a$$\end{document} can be used as a variable scaling factor when scaling the marker effects:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \varvec{\beta } = \varvec{\beta ^*} \frac{s_a}{sd(\varvec{a^*})}; s^2_a \sim \Gamma \left( \theta = \frac{\text {SEV}^2}{\sigma ^2_a}, k = \frac{\sigma ^4_a}{\text {SEV}^2}\right) \end{aligned}$$\end{document}In summary, as \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$s^2_a$$\end{document} is a random sample, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\text {var}({\varvec{a}}) = \text {var}(M\varvec{\beta }) = s^2_a$$\end{document} will have a different value in each simulation run, but they will be centered around the target \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\sigma ^2_a$$\end{document} , following a theoretically sound distribution with standard deviation equal to SEV.
The same can be done for all the other effects, with \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\Sigma$$\end{document} for the calculation of SEV being the assumed covariance matrices for each effect (see Eq. 9) and n is the number of rows or columns in \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\Sigma$$\end{document} . For the i.i.d. block and residual effects, SEV can be calculated as in Eq. (6). For a more detailed overview, we provide the code to perform this simulation in Supplementary File 2.
Validation pipeline for the simulation strategies
The three simulation strategies (MVN, Fixed, and ESS) were repeated 500 times using the variance components extracted from the oat dataset in Eq. (8) as the target. The average variance of each effect across iterations for each simulation type was computed. The theoretical distribution of this average is known (see Appendix 4), allowing us to check if the average variance across iterations falls within a 95% confidence interval of the expected value. This helps to determine if the variances obtained by the simulations significantly differ from the desired target value, indicating potential bias in the simulation. Additionally, we checked if the dispersion of the variance values across iterations matches the expected distribution to validate the inclusion of sampling variance in the simulations.
In summary, we evaluated the simulation strategies based on their ability to be unbiased and accurately include sampling variation.
Results
Comparison of methods for variance component estimation
The results in Table 1 confirm that the VanRaden, GN and M2 methods are biased, while the PEV methodology was mostly unbiased, exhibiting the lowest error by far. In the oat dataset with a balanced experimental design, the root mean square error (RMSE) for variance values with respect to the unbiased estimation was 0.00316, 0.340, 0.473, and 0.132 for the PEV, VanRaden, GN, and M2 methods, respectively. A similar but less extreme pattern was present in the spruce dataset, with RMSE values of 0.00254, 0.0511, 0.0483, and 0.460 for PEV, VanRaden, GN, and M2. When unbalance was introduced in the oat dataset, the error for VanRaden, GN, and M2 methods increased substantially, but it remained extremely low for PEV. The RMSE values were 0.00441, 0.581, 1.80, and 0.333 for PEV, VanRaden, GN, and M2, respectively. In summary, the largest relative error for the PEV methodology across all traits and scenarios is 0.5%. Conversely, other methods presented much larger errors, with the largest one being a 200% error for the GN methodology in the unbalanced dataset for the biomass trait.
The genomic relationship matrices used previously assumed HWE, which was not realistic, particularly for the oat dataset. To assess the impact of this, we repeated the analyses using the genomic relationship matrix from the NOIA model (Vitezica et al. 2017), which does not assume HWE (See Appendix 5, Table 4). This resulted in a RMSE of 0.404, 1.63 and 0.0476 for the balanced oat, unbalanced oat, and spruce datasets, respectively, when using REML estimates of additive variance. With PEV estimates, RMSE was significantly lower, ranging from 0.0113 to 0.00280.
All values above apply for the estimation of the additive variance, but we also tested the PEV method for the estimation of genotypic variance when the model had an i.i.d. genotypic random effect, i.e., \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\varvec{g}} \sim \text {MVN}({\varvec{0}}, I\sigma ^2_g)$$\end{document} . The results for this analysis are available in Appendix 6, Table 5, and they show that the PEV method had negligible differences with the unbiased estimate for balanced designs (RMSE \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\approx 10^{-4}$$\end{document} ), but it presented a small error for the unbalanced dataset, with relative errors ranging between 0.1% and 7% depending on the trait (RMSE \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$= 0.00458$$\end{document} ).Table 1. Comparison of the variance component estimation between the different methods in the oat and spruce datasetsDatasetExperimental designTrait \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\sigma ^2_{\text {Unbiased}}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\sigma ^2_{\text {PEV}}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\sigma ^2_{\text {VanRaden}}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\sigma ^2_{\text {GN}}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\sigma ^2_{M2}$$\end{document} OatBalancedYield1.0001.0040.5540.9830.897OatBalancedBiomass1.0000.9980.7521.3330.781OatBalancedHeight1.0001.0041.0641.8850.901OatBalancedHeading days1.0001.0000.5570.9870.964OatUnbalancedYield1.0000.9971.5422.7290.692OatUnbalancedBiomass1.0000.9951.6963.0050.498OatUnbalancedHeight1.0000.9951.5992.8330.715OatUnbalancedHeading days1.0000.9971.4632.5900.874SpruceBalancedDiameter1.0001.0001.0001.0060.467SpruceBalancedHeight1.0000.9960.9430.9470.542SpruceBalancedDensity1.0001.0000.9330.9350.623For the unbalanced datasets, the average variance across 20 repetitions of randomly dropping observations from the full dataset are presented. The column for \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\sigma ^2_{\text {Unbiased}}$$\end{document} displays the difference between the variance of the response variable and residual variance. \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\sigma ^2_{\text {VanRaden}}$$\end{document} contains the REML estimation of the variances when using G as covariance structure of the additive effects, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\sigma ^2_{\text {GN}}$$\end{document} estimates variance using GN as covariance structure of the additive effects, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\sigma ^2_{M2}$$\end{document} estimates variance using M2 method and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\sigma ^2_{\text {PEV}}$$\end{document} estimates the variance component with the PEV method. For ease of interpretation, the variance estimates in each row have been standardized in such a way that the value of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\sigma ^2_{\text {Unbiased}}$$\end{document} is equal to one
Validation of the proposed effective sample size for mean and variance
The results in Table 2 show the results of the SEM and SEV estimates for several normally distributed random variables. We compared the SEM and SEV wrongly assuming i.i.d. random variables ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\text {SEM}_{iid}$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\text {SEV}_{iid}$$\end{document} , computed as in Eq. 6), using the generalized SEM and SEV described in Eq. (7) ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\text {SEM}_{g}$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\text {SEV}_{g}$$\end{document} ) and empirically ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\text {SEM}_{e}$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\text {SEV}_{e}$$\end{document} ). The latter were calculated as the standard deviation of the sample mean and sample variance estimated across \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$10^5$$\end{document} samples from the corresponding multivariate normal distributions. The data and code that generate the results in Table 2 are available in Supplementary Files 3 and 4.
Most of the scenarios tested (first seven rows in Table 2) are based on an autoregressive process of order one with different values of autocorrelation ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\rho$$\end{document} ). The vector of means was sampled from a standard normal distribution to ensure that our methods are effective for heterogeneous means, i.e., \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\varvec{X}} \sim \text {MVN}(\varvec{\mu _{N(0,1)}}, \Sigma _{\text {AR}1(\rho )})$$\end{document} , where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{\mu _{N(0,1)}} \sim N(0,1)$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\Sigma _{\text {AR}1(\rho )}$$\end{document} is the correlation matrix of the autoregressive process. It is important to note that using the correlation matrix as a variance-covariance matrix is not problematic because correlation and covariance are equivalent when all variables have a variance equal to one.
Two non-autoregressive scenarios were tested to ensure the robustness of our equations for ESS under non-autoregressive covariance structures: \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\varvec{X}} \sim \text {MVN}({\varvec{0}}, G)$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\varvec{X}} \sim \text {MVN}({\varvec{0}}, Gd)$$\end{document} , where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\varvec{0}}$$\end{document} represents a vector of zero means, G is the additive genomic relationship matrix (VanRaden 2008) and Gd is the dominance genomic relationship matrix (Vitezica et al. 2013). Both matrices exhibit heteroscedasticity with heterogeneous correlation and were derived from genome-wide molecular markers in the oat dataset.
The results in Table 2 confirm that the values of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\text {SEM}_{iid}$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\text {SEV}_{iid}$$\end{document} do not match reality for correlated observations. In contrast, the theoretical values for \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\text {SEM}_{g}$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\text {SEV}_{g}$$\end{document} match the empirical ones ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\text {SEM}_{e}$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\text {SEV}_{e}$$\end{document} ) in all scenarios. The minor discrepancies observed are caused by the empirical values being estimated with a large, yet finite, sample size, i.e., the true SEM and SEV values are \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\text {SEM}_{g}$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\text {SEV}_{g}$$\end{document} ; while \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\text {SEM}_{e}$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\text {SEV}_{e}$$\end{document} are only empirical estimates with very low error.Table 2. Theoretical and empirical values of the standard error of the mean (SEM) and the sample variance (SEV) are presented from correlated samples \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\mu }$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\Sigma$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\text {SEM}_{iid}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\text {SEM}_{g}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\text {SEM}_{e}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\text {SEV}_{iid}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\text {SEV}_{g}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\text {SEV}_{e}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{\mu } \sim N(0,1)$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\text {AR}1(\rho = -1)$$\end{document} 0.1000.0000.0000.1421.4341.432 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{\mu } \sim N(0,1)$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\text {AR}1(\rho = -0.9)$$\end{document} 0.1000.0240.0240.1420.4850.487 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{\mu } \sim N(0,1)$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\text {AR}1(\rho = -0.1)$$\end{document} 0.1000.0910.0910.1420.2650.266 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{\mu } \sim N(0,1)$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\text {AR}1(\rho = 0)$$\end{document} 0.1000.1000.1000.1420.2490.249 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{\mu } \sim N(0,1)$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\text {AR}1(\rho = 0.1)$$\end{document} 0.1000.1100.1100.1420.2440.245 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{\mu } \sim N(0,1)$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\text {AR}1(\rho = 0.9)$$\end{document} 0.1000.4150.4150.1420.3910.391 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{\mu } \sim N(0,1)$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\text {AR}1(\rho = 1)$$\end{document} 0.1001.0000.9970.1420.0000.000 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{\mu } = {\varvec{0}}$$\end{document} G0.038000.0540.6330.634 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{\mu } = {\varvec{0}}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$G_d$$\end{document} 0.0380.7100.7090.0540.1770.176The initial seven rows detail autoregressive processes of order one with varying autocorrelation ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\rho$$\end{document} ) levels and nonzero means derived from a standard normal distribution. The last two rows correspond to two genomic relationship matrices, an additive matrix (G) and a dominance matrix ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$G_d$$\end{document} ), both characterized by zero means. \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\text {SEM}_{iid}$$\end{document} denotes the SEM assuming i.i.d. observations; \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\text {SEM}_{g}$$\end{document} represents the generalized SEM outlined in this work; \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\text {SEM}_{e}$$\end{document} is the empirical SEM; \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\text {SEV}_{iid}$$\end{document} indicates the SEV assuming i.i.d. and observations with homogeneous means; \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\text {SEV}_{g}$$\end{document} describes the generalized SEV introduced in this work; \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\text {SEV}_{e}$$\end{document} is the empirical SEV
Ability of the different simulation approaches to control variance components
In a simulation, the actual variance of simulated terms should not significantly differ from the assumed population variance. To assess this, Fig. 3 shows the average deviation of simulated variances from the assumed population variance across 500 repetitions. A deviation of zero indicates that the simulated variance matches the target population variance exactly. Deviations within the gray rectangle in Fig. 3 suggest that, while the simulated variances differ slightly from the assumed population variance, they are not significantly different, which is expected for a random sample. Deviations outside this range indicate that the simulated variances are significantly different from the population variance, leading to biased simulations. More details on the construction of the confidence interval are provided in Appendix 4.
The MVN simulation presented a strong dispersion, with the environmental, additive and additive by environment variances being significantly different from the desired target variance. Conversely, the fixed simulation always had exactly the desired value for the variance, i.e., it was unbiased but neglected sampling variance. Finally, the ESS simulation presented some dispersion (it accounted for sampling variance), but all values were within the 95% confidence interval, indicating that the simulated values were not significantly different from the desired target (i.e., the simulation was unbiased).Fig. 3. Deviation of the average variance of the simulated effects from the assumed population variance across the 500 simulation repetitions expressed in units of standard error of the mean. The points correspond to the different variance components for the three simulation strategies (in different colors). If the simulation variances are unbiased and distributed as expected in theory, they would be centered around zero and with deviations between – 2 and 2 (highlighted with a gray rectangle) with a probability of approximately 0.95. All outliers outside this range are labeled and they belong to the simulation strategy of sampling from multivariate normal distributions. More details about how we calculated the standard error and built the confidence interval are available in Appendix 4
Discussion
Comparison of methods for variance component estimation
To estimate \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\sigma ^2_{a}$$\end{document} from field trials, the first step is fitting a model, commonly a LMM. This allows to partition phenotypic variance into its underlying components, such as \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\sigma ^2_{a}$$\end{document} . However, if the model is based on unrealistic assumptions, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\sigma ^2_{a}$$\end{document} may not accurately reflect the additive variance in the population, resulting in bias. This issue is discussed extensively by Chen (2014), Chen (2016), de Los Campos et al. (2015), but falls outside the scope of this work. Moreover, extracting \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\sigma ^2_a$$\end{document} from a given LMM is complex and can introduce further bias. In this work, we demonstrate that existing methods show substantial bias for complex traits and propose a PEV-based approach that minimizes it.
The REML estimation of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\sigma ^2_{a^*}$$\end{document} when the G or GN matrices are assumed as covariance structures is unbiased in the sense that it scales the G or GN matrices to the most likely covariance matrix for the random effect. However, as shown in Table 1, interpreting \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\sigma ^2_{a^*}$$\end{document} as the variance component of the additive effect would be erroneous because neither G nor GN have unit variance. This contrasts with the results of Feldmann et al. (2022), in which GN performed very well. In that study, GN was tested in both simulations and empirical datasets. In the latter, they simply tested several methods for variance estimation, but they did not provide an unbiased estimate of the additive variance as a baseline for comparison. Therefore, their analyses in empirical datasets did not determine how accurate the GN method is.
Conversely, in the simulated data, they compared the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\sigma ^2_{a^*}$$\end{document} variance estimated with GN to the true additive variance ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\sigma ^2_{a}$$\end{document} ), and GN was unbiased. However, not many details about the simulation were provided in Feldmann et al. (2022). For instance, we can speculate that, when they simulated the marker scores, they may have not explicitly included correlations between them (i.e., linkage disequilibrium), which, as shown by Lehermeier et al. (2017), have a massive impact on the ability of the relationship matrix to be correctly scaled.
In contrast, in our work, we prove that the GN method is biased in two ways. Firstly, in Supplementary File 1, we demonstrate that the scaling factor used to generate GN (the average of the diagonal values in G) does not reliably capture the overall variation in G and therefore is unable to scale GN to unit variance. As a result, the GN method of variance estimation cannot be unbiased. Secondly, we tested the GN method in empirical datasets with varying levels of heterozygosity, population structure, balance in the experimental design, and trait architectures. In all circumstances, GN was biased, especially under low heterozygosity, unbalanced experimental designs and absence of HWE.
To further support this claim, we repeated the analysis with the additive genomic relationship matrix from the NOIA model (Vitezica et al. 2017). This matrix is similar to GN (it is scaled to have an average value for its main diagonal equal to one) but has the advantage of not requiring the assumption of HWE for the calculation of its covariance structure. The results from Table 4 in Appendix 5 show that the REML estimates when using this matrix were very similar to the error-prone GN.
The M2 method (Lehermeier et al. 2017) is extremely interesting because it bypasses the problem of scaling the G matrix. Equation (3) shows that additive variance is the sum of the variances of the marker scores plus twice their covariances, scaled by their corresponding marker effects. That way, strong linkage disequilibrium between two markers (positive covariance) increases the additive variance only if these two markers have substantial marker effects. This reflects that the distribution of marker effects along the genome conditions how much impact the linkage disequilibrium has on the additive variance. Therefore, as seen in Lehermeier et al. (2017), a good G matrix scaling needs to consider the linkage disequilibrium, which appears to be possible only if the distribution of marker effects along the genome is known. As a result, it seems to us that finding an unbiased scaling for the G matrix a priori is impossible, i.e., we cannot properly scale G before fitting the model and finding the marker effects. This is further supported by the fact that, in Table 1, the variance estimates for a given relationship matrix presented different errors for different traits, which means that a good scaling of the G matrix would need to be trait-specific. As a result, the REML estimates of the additive variance component cannot be unbiased regardless of which genomic relationship matrix is used as a covariance structure, explaining the poor performance of the VanRaden and GN methods.
While the M2 method accounts for linkage disequilibrium, it simply represents the variance of the additive BLUPs, as proven in Appendix 2. Due to the shrinkage of the BLUPs, their variance is smaller than the true population variance that we aim to estimate, resulting in a biased estimation. In Lehermeier et al. (2017), a dataset with high replication (4 replicates) and very high heritability (around 0.9), minimized the effect of shrinkage. This explains why the M2 method performed well for them but consistently underestimated additive variance in this work.
To solve this problem, we described the PEV method, which can be viewed as the M2 method with an added correction factor to compensate for shrinkage. Furthermore, the M2 method requires the computationally intensive covariance matrix between markers. Conversely, the PEV method is instead based on the genotypic additive values, which are much more computationally efficient, and carry equivalent information to the marker effects as shown in Appendix 7. Thus, the PEV method can still implicitly capture the effect of the linkage disequilibrium. As shown in Table 1, this allows the PEV method to present negligible bias when estimating the additive variance, making it by far the most accurate method we have encountered. This can significantly improve the accuracy of the study of the genetic control of traits, calculation of heritability, retrieval of target variances for simulations, and more.
Implications of the proposed generalized effective sample size
As highlighted in Table 2, the generalized SEM and SEV described in this work perfectly match empirical values and are robust to different covariance structures and vectors of means. The equation for SEM is equivalent to the one described in Griffith (2008), but here we show that it holds for any multivariate normal distribution. Conversely, the equation for SEV was not previously described and it supposes a generalization of the equation in Bayley and Hammersley (1946) from an autoregressive process to any multivariate normal distribution, which is essential for its application in quantitative genetics.
Furthermore, SEM, SEV, and their associated ESS have some interesting properties that broaden their potential applications. \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\text {ESS}_\mu$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\text {ESS}_{\sigma ^2}$$\end{document} are insensitive to the multiplication of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\Sigma$$\end{document} by a scalar if the vector of means is zero (which is always true for random effects). For instance, this results in the value of ESS being the same for \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\Sigma = G$$\end{document} or \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\Sigma = G\sigma ^2_{a^*}$$\end{document} , making ESS an interesting tool for characterizing a population even if the value of their variance component is unknown.
Furthermore, both SEM and SEV (and their associated ESS) are sensitive to the degree of replication of the experiment, i.e., the SEM or SEV calculated with \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\Sigma$$\end{document} can differ from that computed from \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$Z\Sigma Z^T$$\end{document} , where Z is the design matrix of the experiment.
This sensitivity suggests potential applications for optimizing the training set in genomic selection. Coincidentally, as seen in Eq. (7), \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\text {SEM}^2 = \frac{{\varvec{1}}^T \Sigma {\varvec{1}}}{n^2}$$\end{document} , which is the average of all elements in \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\Sigma$$\end{document} and is exactly equivalent to the Avg_GRM_self optimization criterion described in Fernández-González et al. (2023), aimed at maximizing training set diversity.
This makes sense, as minimizing SEM ensures that the average of all BLUPs is consistently close to zero, which is the value of the population mean. This requires a balance of genotypes with above-average and below-average performance, resulting in maximum diversity. Therefore, there are potential unexplored applications of SEM and SEV as criteria for optimizing the degree of replication, the training set composition (Isidro y Sánchez and Akdemir 2021), maximizing variability in genomic mating (Akdemir and Sánchez 2016; Woolliams and Thompson 1994; Kinghorn 1999), etc.
Comparison of the different simulation strategies
In this work, we have tested marker-based simulations (Fixed and ESS) and a non-marker-based simulation (MVN). The latter does not require knowledge of the actual values of the variance components, relying instead on REML-estimated scaling factors, such as \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\sigma ^2_{a^*} \ne \text {var}({\varvec{a}})$$\end{document} . Conversely, the marker-based strategies need the actual values of the variance components, such as \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\sigma ^2_{a} = \text {var}({\varvec{a}})$$\end{document} . As discussed earlier, these values can only be reliably estimated within a reasonable error margin using the PEV methodology described in this work. The MVN simulation has numerous drawbacks, whereas the Fixed and ESS ones are recommended, highlighting the importance of the accurate estimation of variance component estimation through the PEV methodology.
To justify our argument against the MVN simulation, we will review the list of ideal requirements for a simulation outlined in the introduction. We will also use this to compare the ESS with the Fixed strategies.
For simplicity, this work focuses on simulating field trials within a single year. However, for across-year and across-generations simulations, it is important to calculate marker effects that remain consistent across generations. Both marker-based simulations (Fixed and ESS) can do this, but the MVN one can only do it partially. It is possible to obtain additive marker effects from additive values as \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{\beta } = M'(MM')^{-1}{\varvec{a}}$$\end{document} (Henderson (1977), see Appendix 7 for more details). However, to our knowledge, it is not possible to do the same for the interaction effects, which would limit the MVN simulation across generations.
Furthermore, extracting the marker effects from the additive values in the MVN approach does not provide any control over the desired distribution of the marker effects (i.e., trait architecture), while both Fixed and ESS simulations can control from which distribution the markers are sampled. Moreover, the MVN approach would independently sample additive and interaction effects such as epistasis, which is not realistic because the magnitude of the epistasis between two QTL is likely to be affected by the size of their additive values. In other words, the different effects are not coherent in the MVN simulation. This issue can be resolved in the Fixed and ESS simulations by calculating interaction effects as the product of additive effects weighted by an interaction intensity.
Regarding the control of the variance components, as shown in Fig. 3, environmental, additive and additive by environment were significantly different from the target variance in the MVN simulation. The inclusion of the G matrix and the covariance between the environments in the simulation makes the control of variance components challenging in the MVN simulation, as the nonzero covariances distort the overall variation in unpredictable ways. The ESS and Fixed simulations solve this by scaling the effects to the desired target after they are sampled.
Another similar problem of the MVN simulation is its inability to ensure that the AxL matrix of genotype by location interactions is double-centered, which would add undesired variation to the additive and location main effects. This is not a problem for the ESS and Fixed simulations, which can adjust the genotype by environment variance after double-centering it.
Finally, both MVN and ESS simulations can consider sampling variance, but the Fixed approach does not. This is the only difference between the ESS and Fixed simulations, but in our opinion, it makes ESS the preferable choice. Including sampling variance allows for heterogeneous spatial and residual variances across locations, heterogeneous location variance across years, etc. All of these occur routinely in empirical field trials. Therefore, including them in simulations is essential for matching reality as much as possible. Furthermore, even when simulating a single field trial within a single year, fixing all variance components to always be exactly equal to the target is not ideal. The genetic variance components estimated from empirical data are not the true values; they are simply our best estimate. Allowing the variance components to fluctuate in different repetitions according to SEV, results in a comprehensive exploration of different combinations of likely variance values centered around the desired target with a theoretically sound distribution.
Furthermore, the ESS simulation is very flexible. While this work used it to simulate some complex interaction terms, it is also suitable for other effects not showcased in this work for simplicity. Examples include dominance with or without heterosis, epistasis, autoregressive spatial trends within each field, interaction between non-additive genetic effects and the location, and even effects not usually considered, such as genotypic by spatial interactions within a field.
In summary, both the Fixed and ESS methodologies offer significant advantages over the MVN simulation, while ESS is superior to the Fixed method in its ability to consider sampling variance. The main challenge in the Fixed and ESS simulations was finding a good estimation for the target variance components from empirical data. This can be done with minimal error with the PEV methodology described in this work, which allows simulations to very closely mimic empirical field trials. This can be invaluable for testing novel methodologies and exploring different breeding schemes under realistic circumstances at a minimal cost.
Conclusions
This work highlights the limitations in current methodologies for extracting variance components from a LMM fitted on empirical data and proposes a PEV-based alternative to minimize bias. This approach can significantly improve the accuracy of important metrics such as heritability and response from selection, aiding decision-making in breeding programs. Although this study focuses primarily on additive variance for simplicity, the PEV method is applicable to estimating the variance component of any random effect in a LMM.
Accurate estimation of variance components is crucial to ensure that the target variance in simulation studies closely matches the empirical datasets they aim to replicate. Additionally, to improve simulation accuracy, it is important to account for the sampling variance of variance components across simulation runs. To address this, we have introduced a generalized ESS for the sample variance in any multivariate normal distribution, accommodating heteroscedasticity, correlations, and heterogeneous means. This approach ensures that the variance of simulation terms matches their theoretical distribution across repetitions. Consequently, our simulation can reflect the varying variance components observed across generations in empirical breeding programs.
Supplementary Information
Below is the link to the electronic supplementary material.Supplementary File 1: Small R script showcasing the difficulty of summarizing in a single scalar the overall variability of a multivariate normal distribution (r 2 KB)Supplementary File 2: It contains the code needed to run the ESS simulation (r 21 KB)Supplementary File 3: It contains the code used to validate the proposed generalized SEM and SEV. This code was used to generate the results in Table 2 (r 10 KB)Supplementary File 4: Additive (G) and dominance ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$G_d$$\end{document} ) relationship matrices computed from the oat dataset (Canales et al. 2021b). These matrices are used as an input for the code in Supplementary File 3 (rdata 7176 KB)
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Canales FJ, Montilla-Bascón G, Bekele WA, Howarth CJ, Langdon T, Rispail N, Tinker NA, Prats E (2021 a) Population genomics of mediterranean oat (A. sativa) reveals high genetic diversity and three loci for heading date. Theor Appl Genet 10.1007/s 00122-021-03805-2PMC 826355033770189 · doi ↗ · pubmed ↗
- 2Canales FJ, Montilla-Bascón G, Bekele WA, Howarth C, Langdon T, Rispail N, Tinker N, Prats E (2021 b) Data set from: population genomics of mediterranean oat (A. sativa) reveals high genetic diversity and three loci for heading date. Dryad, Dataset 10.1007/s 00122-021-03805-2PMC 826355033770189 · doi ↗ · pubmed ↗
- 3Faux A-M, Gorjanc G, Gaynor RC, Battagin M, Edwards SM, Wilson DL, Hearne SJ, Gonen S, Hickey JM (2016) Alphasim: software for breeding program simulation. Plant Genom 9(3):plantgenome 2016–0210.3835/plantgenome 2016.02.001327902803 · doi ↗ · pubmed ↗
- 4Feldmann MJ, Piepho H-P, Knapp SJ (2022) Average semivariance directly yields accurate estimates of the genomic variance in complex trait analyses. G 3 12(6):jkac 08010.1093/g 3journal/jkac 080PMC 915715235442424 · doi ↗ · pubmed ↗
- 5Fernández-González J, Akdemir D, Isidro y Sánchez, J (2023) A comparison of methods for training population optimization in genomic selection. Theor Appl Genet 136(3):3010.1007/s 00122-023-04265-6PMC 999858036892603 · doi ↗ · pubmed ↗
- 6Henderson CR (1975) Best linear unbiased estimation and prediction under a selection model. Biometrics 423–4471174616 · pubmed ↗
- 7Isidro y Sánchez J, Akdemir D (2021) Training set optimization for sparse phenotyping in genomic selection: a conceptual overview. Front Plant Sci 188910.3389/fpls.2021.715910 PMC 847549534589099 · doi ↗ · pubmed ↗
- 8Neyhart JL, Tiede T, Lorenz AJ, Smith KP (2017) Evaluating methods of updating training data in long-term genomewide selection. G 3: Genes, Genom, Genet, 7(5):1499–151010.1534/g 3.117.040550 PMC 542750528315831 · doi ↗ · pubmed ↗