Exploring multi-granularity balance strategy for class incremental learning via three-way granular computing
Yan Xian, Hong Yu, Ye Wang, Guoyin Wang

TL;DR
This paper introduces a new method for class incremental learning that balances old and new data to reduce forgetting and improve performance.
Contribution
A novel multi-granularity balance strategy (MGBCIL) is proposed to address class imbalance in incremental learning.
Findings
MGBCIL improves average accuracy by up to 9.59% on CIFAR-10 with limited stored exemplars.
The method reduces the forgetting rate by up to 25.45% in incremental learning scenarios.
Strategies are applied at batch, task, and decision levels to balance new and old class samples.
Abstract
Class incremental learning (CIL) is a specific scenario in incremental learning. It aims to continuously learn new classes from the data stream, which suffers from the challenge of catastrophic forgetting. Inspired by the human hippocampus, the CIL method for replaying episodic memory offers a promising solution. However, the limited buffer budget restricts the number of old class samples that can be stored, resulting in an imbalance between new and old class samples during each incremental learning stage. This imbalance adversely affects the mitigation of catastrophic forgetting. Therefore, we propose a novel CIL method based on multi-granularity balance strategy (MGBCIL), which is inspired by the three-way granular computing in human problem-solving. In order to mitigate the adverse effects of imbalances on catastrophic forgetting at fine-, medium-, and coarse-grained levels during…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
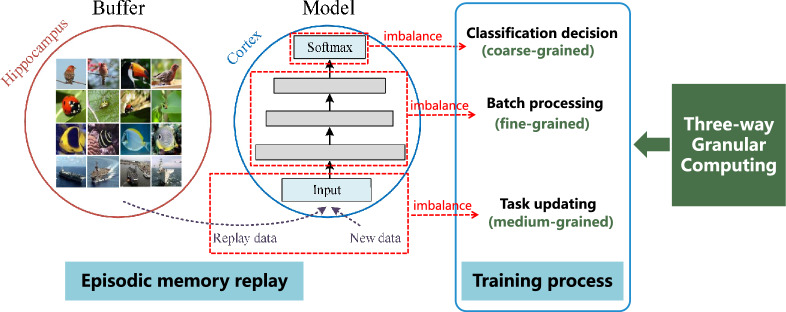 Figure 1
Figure 1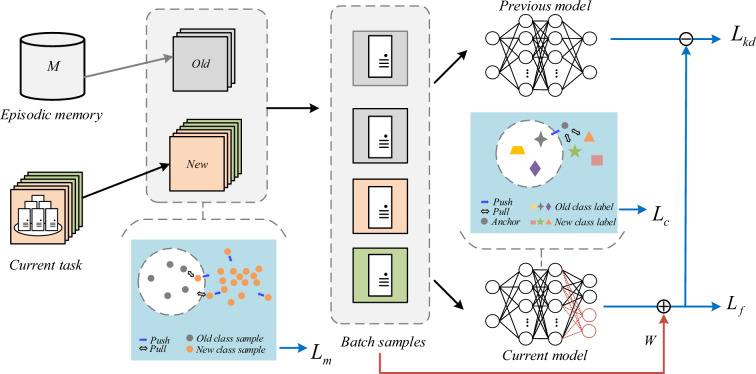 Figure 2
Figure 2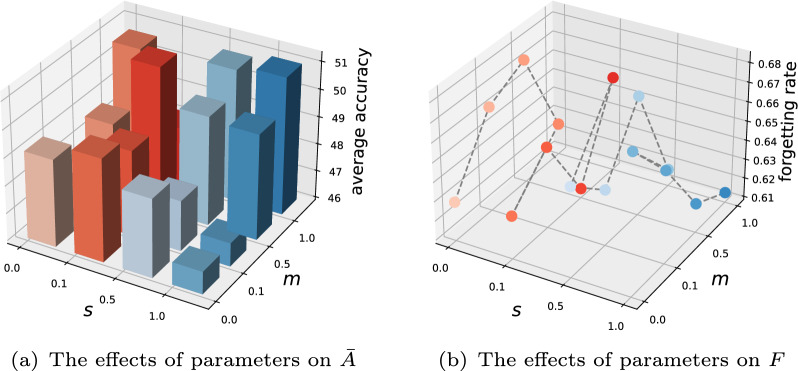 Figure 3
Figure 3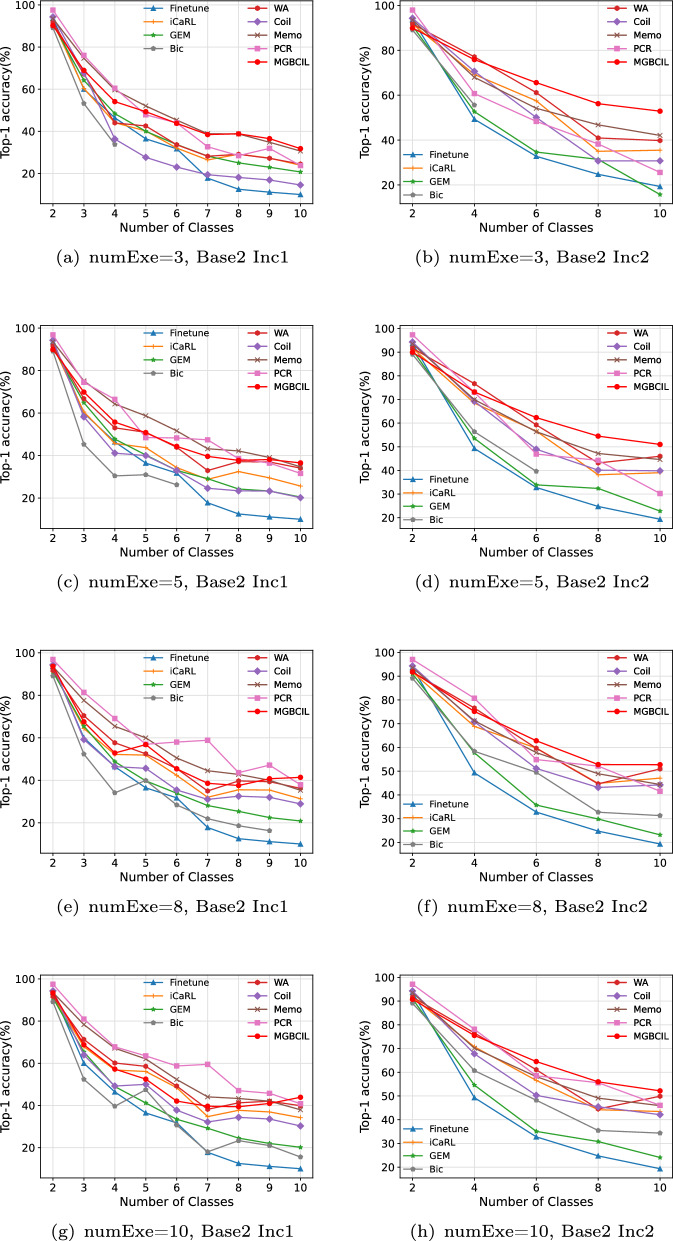 Figure 4
Figure 4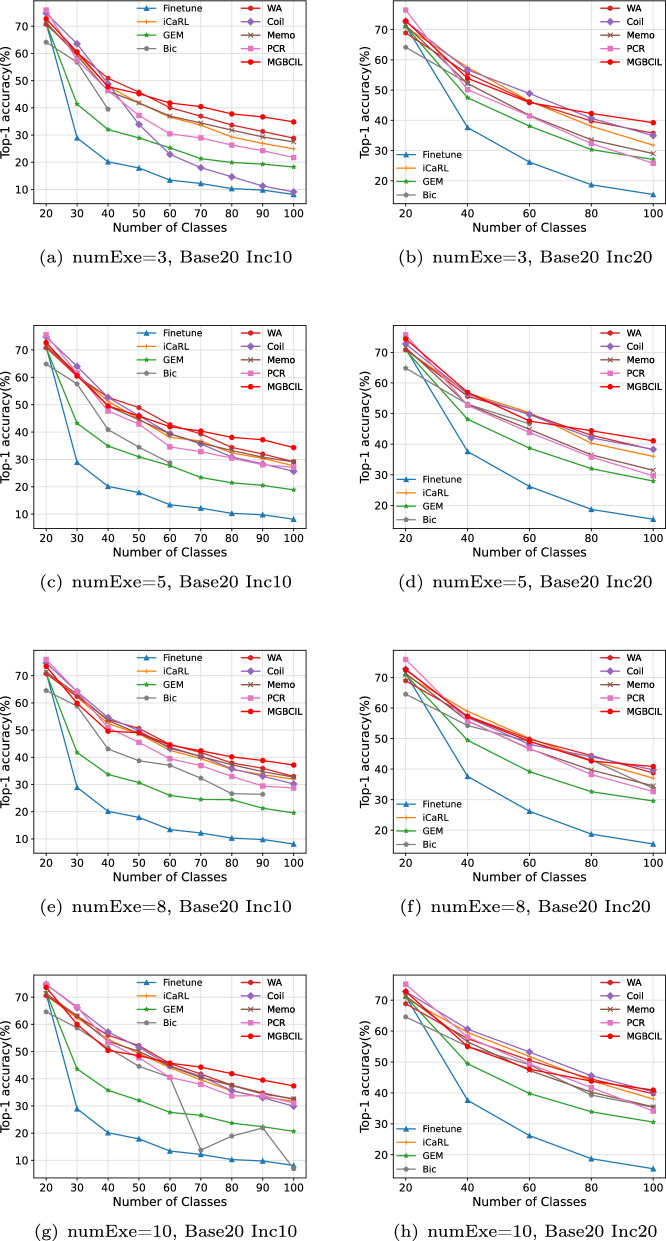 Figure 5
Figure 5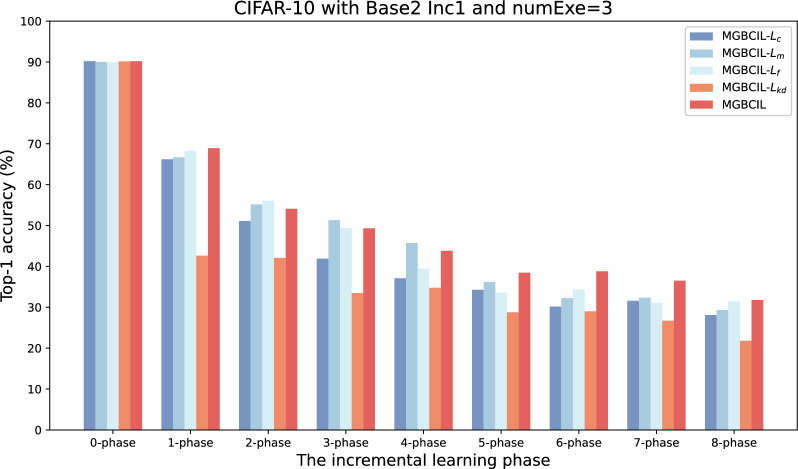 Figure 6
Figure 6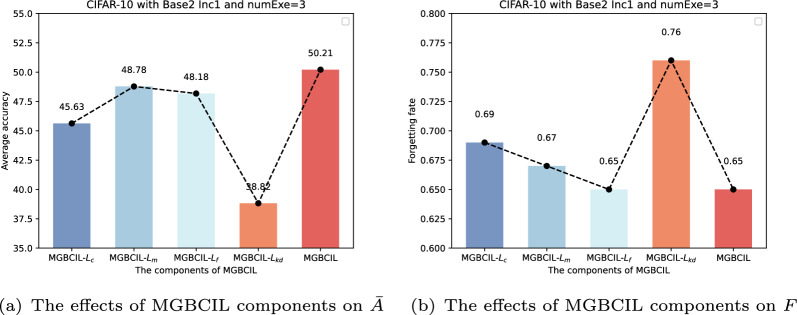 Figure 7
Figure 7- —Doctoral Innovation Talent Program of Chongqing University of Posts and Telecommunications
- —https://doi.org/10.13039/501100001809National Natural Science Foundation of China
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsDomain Adaptation and Few-Shot Learning · Machine Learning and ELM · Multimodal Machine Learning Applications
Introduction
The incremental learning [1–4] is also known as continual learning or lifelong learning, which means updating the model in a series of data stream. It is widely used in the fields of semantic segmentation [5], natural language processing [6], and object detection [7], etc. There are three primary scenarios in incremental learning: task incremental learning (TIL), domain incremental learning (DIL), and class incremental learning (CIL). In this paper, we focus on the CIL scenario without task identities, where the model learns from a data stream of new classes and can classify all observed classes at any time.
The CIL method is known to suffer from catastrophic forgetting, where the model struggles to recognize old classes after learning new ones, leading to poor generalization [8]. This phenomenon contrasts with the ability of humans to learn incrementally without forgetting old knowledge. The biological basis of human incremental learning ability is mainly derived from the neural replay mechanism of the hippocampus, which consolidates the memory storage in the neocortex by activating stored episodic memories [9, 10]. Inspired by the function of the hippocampus, the CIL methods based on episodic memory replay store a limited set of representative samples from old classes and replay them when learning new classes, thereby enhancing the memory of the old class [11]. In addition, methods based on non-episodic memory replay primarily integrate prior knowledge by using regularization terms [12] or dynamic expansion of network architectures [13], thus preserving old class knowledge to some extent. The researches has shown that episodic memory replay-based methods achieve superior performance than another [14, 15], as the replay of prior experiences is considered essential for stabilizing new memories [9].Fig. 1. Schematic diagram of multi-granularity imbalance of episodic memory replay methods in the training process
To mitigate catastrophic forgetting, some episodic memory replay-based learning methods have been proposed. These methods stored representative exemplars from old classes as episodic memory [16–19]. Meanwhile, episodic memory replay can be naturally combined with knowledge distillation (KD) to incorporate previous knowledge from old model [11, 18, 20, 21]. However, although knowledge distillation can reduce forgetting to a certain degree, they still face challenges related to the imbalance of training samples between new and old classes. As illustrated in Fig. 1, episodic memory replay-based methods [22] are constrained by a limited buffer budget during incremental learning stages, allowing only a small number of old class exemplars to be stored. Consequently, the training process encounters a large number of samples from new classes compared to the relatively few old ones from old classes, resulting in an imbalance between new and old class samples. The class-specific weights are adversely affected by the imbalance, which produces a notable bias towards the new classes and ultimately leads to the forgetting of old classes.
The aforementioned issue of imbalance persists across different stages of the incremental training process, including batch processing, task updating, and classification decision. Specifically, the batch processing focuses on samples, the task updating combines both new and old class samples along with their labels, and the classification decision categorizes the labels. These three stages display a hierarchical structure at the data level, which is closely related to the hierarchical nature of human cognition. Zadeh [23] identified three basic concepts of human cognition: granulation, organization, and causation. Among them, the granular cognition mechanism is inspired by the human ability to granulate and reason with information. Yao [24] proposed the granular computing based on this mechanism, decomposing whole systems into multiple components and processing information through different granularity levels. The granular computing is conceptualized as a general theory for problem-solving, including two types of operators: one type deals with the transition from fine-grained to coarse-grained levels, and the other type handles the shift from coarse-grained to fine-grained levels. In the method of granular computing [25], three-way decision is an important method and has been widely used. Its basic concept is thinking in threes, which deals with a whole through three distinct but related parts [26, 27]. This corresponds to granular computing in threes, i.e., three-way granular computing [28]. In the last few years, we have witnessed the rapid development of three-way granular computing in multivariate time series forecasting [29], multi-view clustering [30], and multi-label classification [31]. Therefore, inspired by three-way granular computing, we map the batch processing, task updating, and classification decision stages of the incremental training process to three different granularity levels. The batch processing is at the fine-grained level as it handles the sample carefully, the task updating is at the medium-grained level by integrating samples and labels from both new and old classes, and the classification decision is regarded as the coarse-grained level because it categorizes labels for the entire task.
These methods are designed to solve the imbalance problem of class incremental learning [32–36]. They only address the imbalance between new and old class samples at the classification decision or task updating of training process, but they tend to ignore the imbalance that also exists at the batch processing. Therefore, we propose a novel CIL method based on multi-granularity balance strategy (MGBCIL), which is inspired by the three-way granular computing for human problem-solving. MGBCIL combines three granularities of the training process to mitigate the forgetting caused by the imbalance. Meanwhile, knowledge distillation is introduced to retain the knowledge of old classes and further mitigate forgetting. Specifically, at the fine-grained level of batch processing, we define a weighted cross-entropy loss with a smoothing factor to assign different weights to old and new classes’ samples, rather than the traditional cross-entropy loss that treats the loss calculation of each sample equally. In addition, during the medium-grained level of task updating and coarse-grained level of classification decision, we introduce the contrastive learning with different anchor settings to promote the local and global separation of new and old classes respectively.
To verify the effectiveness of the proposed MGBCIL method, we conduct extensive experiments on CIFAR-10 and CIFAR-100 datasets, showing superior performance compared to other methods. In particular, when the number of exemplars is 3 on CIFAR-10 with Base2 Inc2 setting, the average accuracy improves by up to 9.59% and the forgetting rate reduces by up to 25.45%. In conclusion, our main contributions are summarized as follows:
- A novel CIL method is proposed to achieve balance among the three granular levels within the training process, which is inspired by the three-way granular computing for human problem-solving.
- As far as we know, it is the first time that the weighted cross-entropy loss is designed to rebalance the samples of new and old classes in batch processing.
- We introduce contrastive learning with different anchor settings during the task updating and the classification decision, thereby promoting the local and global separation of new and old classes. This paper is an extended version of an earlier conference paper [37]. We conduct a deeper analysis of the causes and processes of imbalance in incremental training, as shown in Fig. 1. Additionally, we expand all evaluations to multiple incremental settings and add new comparison methods to strengthen the experimental analysis. A notable finding is that MGBCIL performs better when there is a high degree of imbalance between the new and old class samples.
Related work
The well-known problem of catastrophic forgetting is addressed in numerous CIL methods, which can be coarsely categorized into two main learning paradigms: non-episodic memory replay-based and episodic memory replay-based. In the first learning paradigm, these can be further subdivided into regularization-based and network architecture-based.
Regularization-based Methods
The methods constraint the loss function related to the current classes, preventing the overwriting of previous knowledge with new information. MAS [38] adopted online and unsupervised strategies to gather importance measures, relying on the sensitivity of prediction results to parameter changes, thus effectively protect critical knowledge related to previous task will not be covered. PODNet [12] employed a spatial distillation loss to maintain representations within the model. By penalizing feature changes of input samples across old and new feature spaces, the parameter adjustment is indirectly affected. The method preserves the knowledge of old classes and mitigates forgetting during incremental learning. The significance of every parameter is approximated online via SI [39] based on its contribution to the total loss variation and the extent of its updates throughout the training process. Nevertheless, the regularization-based methods’ performance tend to be lower than that of the episodic memory replay-based methods [40].
Network architecture-based methods
The methods extend models designed for previous classes to incorporate current classes by maintaining varying degrees of parameter isolation between the previous and current components. This isolation is typically achieved by adding new branches [41], [13] or splitting existing connections [42]. \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$H^2$$\end{document} [43] explicitly optimizes a binary mask in a fixed network design, allocating specific neurones or parameters for each task while freezing masked areas for previous tasks. However, CPG [44] allow the network to dynamically expand when the network architecture’s capacity is not sufficient to effectively learn a new task. These methods are commonly applied in TIL scenarios with provided task identifiers. However, the parameter size increases with the number of seen tasks, posing challenges in CIL scenarios without task identifiers compared to episodic memory replay-based methods. In these scenarios, the methods either fail or perform poorly [40].
Episodic memory replay-based methods
The methods mitigate catastrophic forgetting by flexibly transferring a limited set of exemplars from old classes, simulating the function of the hippocampus of the human brain to replay the episodic memory. The Coil [18], DER [17], and Foster [19] adopted a herd selection strategy, selecting representative exemplars of old classes based on distance histograms and storing them in episodic memory. GEM [16] stored the last m samples of representative exemplars from each task as episodic memory. ER [45] proposed reservoir sampling to manage exemplars within a fixed buffer budget, assuming that data streams follow an independently and identically distributed pattern. DRI [46] trained a generative model to supplement old training samples with generated data. Meanwhile, episodic memory replay can be naturally combined with knowledge distillation. Co2L [20] introduced the constrastive loss and preservation mechanism for robust representations against catastrophic forgetting. iCaRL [11] decoupled the learning of the classifier and feature representation, where the classifier was implemented using exemplars from the episodic memory and feature representation was derived through knowledge distillation [47]. To mitigate data imbalance with limite old training samples, Bic [32] introduced a bias correction method that used a linear model to adjust the distribution of output logits. IL2M [33] suggested a dual-memory approach that adjusted prediction scores by storing both statistical data and exemplars from old classes. LUCIR [34] used cosine normalization and hard negative mining to align features orientations between old and new models. FSCIL [48] showed that knowledge could be effectively retained by learning the topology of the manifold feature space, even when the manifold exhibits non-uniform and heterogeneous properties. SS-IL [35] employed separated softmax in the last layer and task-wise KD to reduce the impact of imbalance. Memo [49] identified that the shallow layers of a model exhibited greater generality, while the deeper layers were more task-specific. Consequently, it decoupled the intermediate backbone by proposing a modular design. PCR [36] proposed replacing anchor contrastive samples with corresponding proxies, which achieved a complementary balance between proxy-based and contrastive replay, thereby effectively mitigating challenges caused by class imbalance.
The replay-based methods usually address the imbalance between new and old class samples at medium- or coarse-grained levels, primarily focusing on classification decision or task updating during the training process. However, it is common to ignore the imbalance that occurres at the fine-grained level of the training process, such batch processing. To address this problem, we propose a multi-granularity balance strategy for the CIL method that includes three granularities to comprehensively mitigate imbalances across different stages of the training process.
The proposed method
In this section, we provide a detailed introduction to the proposed MGBCIL method and the overall framework of MGBCIL is illustrated in Fig. 2. To mitigate the classification bias caused by the imbalance between old and new class samples, we design the multi-granularity balance strategy inspired by the three-way granular computing. Specifically, the training process is divided into fine-, medium-, and coarse-grained stages for batch processing, task updating, and classification decision respectively. \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$L_{f}$$\end{document} represents the proposed weighted cross-entropy loss, ensuring all classes are fully learned at fine-grained stage. \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$L_{m}$$\end{document} treats the current task samples as anchors and others as negative samples, promoting local separation between old and new classes at medium-grained stage. Meanwhile, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$L_{c}$$\end{document} sets the old classes as anchors and new classes as negative samples, encouraging global separation between new and old classes at coarse-grained stage. The multi-granularity balance strategy helps mitigate the adverse impact of imbalances on the resolution of catastrophic forgetting. Additionally, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$L_{kd}$$\end{document} is used to distill knowledge from old to new models, further preventing forgetting.Fig. 2. Overview of the proposed MGBCIL frameworkTable 1Summary on important notationsNotationsMeanings \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$C_{i}$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$D_{i}$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$N_{C_{i}}$$\end{document} , NThe class, the datasets for class \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$C_{i}$$\end{document} , the number of samples for class \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$C_{i}$$\end{document} , the total number of samples in the current task \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$C_{old}$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$C_{new}$$\end{document} , k, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\delta$$\end{document} The set of old class, the set of new class, the number of old class, the number of new class \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$M_{old}$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$M_{new}$$\end{document} The episodic memory of old classes, episodic memory after cumulative updating \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{x}$$\end{document} , y, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$N_b$$\end{document} The sample in batch processing, the ground truth label of sample, the number of samples in batch processing \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$L_{f}$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$L_{m}$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$L_{c}$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$L_{kd}$$\end{document} Fined-grained loss, medium-grained loss, coarse-grained loss, knowledge distillation loss \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\text {NWs}(C_{i})$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{W}$$\end{document} The smoothed and normalized weight of class \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$C_{i}$$\end{document} , the weight vector of the current class \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\text {Enc}(\theta )$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\text {Proj}(\phi )$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\text {H}(\cdot )$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\text {Aug}(\cdot )$$\end{document} Encoder, projection function, augmentation function, label embeddingsThe smoothing parameter of fined-grained lossmMargin of separation between old and new classes in coarse-grained losses
Notation and preliminary
The notation table is included in Table 1, and we shall explain its precise meaning when first used. Assuming that n classes are needed for incremental learning, a random sequence of classes \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$C_{i}\in \left\{ C_{1}, C_{2}, \cdots , C_{n}\right\}$$\end{document} is created. The dataset for class \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$C_{i}$$\end{document} is denoted as \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$D_{i}=\left\{ \left( \varvec{x}_{1}^{(i)}, y_{1}^{(i)}\right) ,\left( \varvec{x}_{2}^{(i)}, y_{2}^{(i)}\right) , \cdots ,\left( \varvec{x}_{N_{C_{i}}}^{(i)}, y_{N_{C_{i}}}^{(i)}\right) \right\}$$\end{document} , where each class \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$C_{i}$$\end{document} includes \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$N_{C_{i}}$$\end{document} samples. We use the Base \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\Theta$$\end{document} Inc \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\delta$$\end{document} incremental setup, where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\Theta$$\end{document} classes are introduced for the initial training phase (0-phase), and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\delta$$\end{document} classes are added in each subsequent phase. Formally, we suppose the model is trained on old classes \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$C_{old}=\left\{ C_{1}, C_{2}, \cdots , C_{k}\right\}$$\end{document} , retaining the episodic memory \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$M_{old}$$\end{document} of these classes. There are \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$k+\delta$$\end{document} classes with a total number of samples \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$N=N_k+N_\delta$$\end{document} in current task. We aim to train a classifier based on the new classes \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$C_{new}=\left\{ C_{k+1}, \cdots , C_{k+\delta }\right\} (k+\delta \le n)$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$M_{old}$$\end{document} , and then evaluate its classification performance across all observed classes \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\left\{ C_{1}, C_{2}, \cdots , C_{k+\delta }\right\}$$\end{document} , updating the accumulated episodic memory \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$M_{new}$$\end{document} .
Multi-garularity balance strategy
The fine-grained of batch processing
In batch processing at a fine-grained level, the cross-entropy loss is commonly utilized to train the multi-class classifiers for each sample \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{x}$$\end{document} :
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$L_f=-\sum _{i=1}^{\vert k+\delta \vert } y_{i} \log p_{i}$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$y_i$$\end{document} denotes the ground-truth label of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{x}$$\end{document} , and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$p_i$$\end{document} is the probability derived from the softmax of the corresponding class.
However, we find that there is a significant sample imbalance between old and new classes during each fine-grained batch training. The traditional cross-entropy loss treats each sample equally, ignoring this imbalance. Thus, we propose a weighted cross-entropy loss to solve the imbalance by assigning different weights to samples from different classes, ensuring that all classes are fully learned within the batch processing. The total occurrence times \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\operatorname {Tol}(C_{i})$$\end{document} and frequency \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\operatorname {Freq}(C_{i})$$\end{document} of class \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$C_{i}$$\end{document} are calculated as:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \operatorname {Tol}\left( C_{i}\right) =\sum _{j=1}^{N_b} I_{\left\{ \varvec{x}_{j} \mid y_{j}=C_{i}\right\} }\left( \varvec{x}_{j}\right) , i \in \{1,2, \ldots , k+\delta \}, \end{aligned}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \operatorname {Freq}(C_{i})=\frac{\operatorname {Tol}(C_{i})}{N_b}, \end{aligned}$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{x}$$\end{document} represents the sample in batch processing, y indicates its corresponding label, and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$N_b$$\end{document} is the number of samples in batch processing. The indicator function I returns a value of 1 if \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$y_{j}=C_{i}$$\end{document} for sample \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{x}_{j}$$\end{document} , and 0 otherwise. Subsequently, the weighted value for each class \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$C_{i}$$\end{document} is calculated as:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \text{ Wc } (C_{i})=\frac{1}{\operatorname {Freq}(C_{i})}. \end{aligned}$$\end{document}To mitigate the impact of extremely low or high frequencies, a smoothing parameter s within the range of [0, 1] is introduced. When \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$s=0$$\end{document} , the weight is directly assigned as the reciprocal of the actual class frequency. When \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$s>0$$\end{document} , a smoothing term is added to the frequency value to prevent the influence of extreme frequencies. Due to the addition of s, the denominator does not become excessively small when \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\operatorname {Freq}(C_{i})$$\end{document} is low, nor does it fluctuate significantly when \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\operatorname {Freq}(C_{i})$$\end{document} is high. This has the effect of smoothing the weights and avoiding extreme situations.
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \begin{aligned} \text{ Ws } (C_{i})&=\frac{1}{\operatorname {Freq}(C_{i})+s}\\&= \text{ Wc } (C_{i})(\frac{1}{1+ \text{ Wc } (C_{i})\cdot s}). \end{aligned} \end{aligned}$$\end{document}To ensure that the weights are distributed in a reasonable range, the class weights \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\text {Ws}(C_{i})$$\end{document} in Eq.(5) is normalized to ensure that maximum weight is 1:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \text {NWs}(C_{i}) = \frac{\text {Ws}(C_{i})}{\max (\text {Ws}(C_{i}))}, i\in \{1,2,\ldots ,k+\delta \}, \end{aligned}$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\max (\text {Ws}(C_{i}))$$\end{document} is the max value of class weights in this batch, so that the vector of weight is represented as follow:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \varvec{W} =\left\{ \text {NWs}(C_{i}) \mid i \in \{1, 2, \ldots , k+\delta \}\right\} . \end{aligned}$$\end{document}The weighted cross-entropy loss of the fine-grained is defined by Eq.(8), which can pay more attention to a few classes by giving a higher weight to these classes during batch training, reducing the impact of sample imbalance on the anti-forgetting performance of the model. The strategy allows the model to adapt its focus adaptively based on data distribution, learning more distinguishable features from a limited number of samples effectively.
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$L_{f}=-{\varvec{W}}\sum _{i=1}^{\vert k+\delta \vert } y_{i} \log p_{i}.$$\end{document}The medium-grained of task updating
During the medium-grained of task updating, an imbalance persists between new and old class samples across the current and previous tasks. Therefore, we introduce the asymmetric supervised constrastive learning to promote the local separation of new and old classes [20]. In this setup, samples from the current task are used as anchors, while the samples from previous task stored in the episodic memory buffer are treated as negative samples.
In batch processing, there are \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$N=N_k+N_\delta$$\end{document} samplels and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$k+\delta$$\end{document} classes of the current task. The data augmentation function \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\operatorname {Aug}(\cdot )$$\end{document} applies a random transformation, resulting in \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$a \ne b \Leftrightarrow \operatorname {Aug}_{a}(\cdot ) \ne \operatorname {Aug}_{b}(\cdot )$$\end{document} . The index set for the samples of the current task is designated as \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$2N=\operatorname {Aug}_{a}(N) \cup \operatorname {Aug}_{b}(N)$$\end{document} . Each sample \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{x}$$\end{document} within 2N is mapped to an embedding vector \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{r}=\operatorname {Enc}\left( \varvec{x};\theta \right)$$\end{document} through the encoder \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\operatorname {Enc}(\theta )$$\end{document} , and then transformed into a projection vector \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{z}=\operatorname {Proj}\left( \varvec{r}; \varphi \right)$$\end{document} using the projection function \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\operatorname {Proj}(\varphi )$$\end{document} . The asymmetric supervised constrastive loss of the medium-grained is defined as:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \begin{aligned} L_{m}=\sum _{i \in S} \frac{-1}{\left| \mathfrak {p}_{i}\right| } \sum _{j \in \mathfrak {p}_{i}} \log \left( \frac{\exp \left( \varvec{z}_{i} \cdot \varvec{z}_{j} / \tau \right) }{\sum _{t \ne i} \exp \left( \varvec{z}_{i} \cdot \varvec{z}_{t} / \tau \right) }\right) ,\\ \end{aligned} \end{aligned}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \mathfrak {p}_i =\{q \mid i\ne j \wedge y_i=y_j,\ j\in \{1,2,\ldots ,2N\}\}, \end{aligned}$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\tau$$\end{document} represents a temperature hyper-parameter, and the index set of the current task samples in the batch is signified as \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$S \subset \{1, 2, \ldots , 2N\}$$\end{document} . The index set \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathfrak {p}_i$$\end{document} corresponds to the positive samples related to the anchor.
The coarse-grained of classification decision
In the classification decision stage, there is a class imbalance between the new and old classes. In order to avoid the confusion that may be caused by class imbalance, we promote their global separation through a margin ranking loss [34]. The strategy focuses on the overall distribution and relationship of classes, and considers the global separation between the new and old classes at the coarse-grained level.
In particular, we attempt to separate all new classes from the ground-truth label of old classes by the margin m. The sample \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{x}$$\end{document} of old classes in \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$N_k$$\end{document} is regarded as the anchor from the memory buffer. The ground-truth label embeddings of the old classes are used as positive, and the Top-L new classes with the highest response to \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{x}$$\end{document} are taken as hard negative samples, using their ground-truth label embeddings as negative. It is defined as:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} L_{c}=\sum _{l=1}^{L} \max \left( 0, -\langle \operatorname {H}(\varvec{x}), \operatorname {Enc}\left( \varvec{x};\theta \right) \rangle +\left\langle \operatorname {H}^{l}(\varvec{x}), \operatorname {Enc}\left( \varvec{x};\theta \right) \right\rangle +m\right) , \end{aligned}$$\end{document}where m is the margin threshold, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\operatorname {Enc}\left( \varvec{x};\theta \right)$$\end{document} is the feature encoding of sample \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{x}$$\end{document} extracted by the current model, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\operatorname {H}(\varvec{x})$$\end{document} is the label embedding of old class sample \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{x}$$\end{document} , and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\operatorname {H}^{l}(\varvec{x})$$\end{document} is the label embedding of the new class that responds to the Top-L of the old class sample \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{x}$$\end{document} , which is chosen as hard negatives.
Update the model
In order to further mitigate catastrophic forgetting, we incorporate a distillation loss Lkd to preserve knowledge from previous classes. By aligning the output distributions of the current model with those of the previous model, the distillation loss ensures that essential information from earlier learning stages is retained. This mechanism effectively reduces the tendency of the model to overwrite old knowledge while accommodating new information, thereby enhancing the overall stability and performance of the incremental learning process. The distillation loss is defined as:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$L_{k d}=-\sum_{i=1}^{k} \tau_{i}\left(p^{*}\right) \log \left(\tau_{i}(p)\right) ,$$\end{document}where the soft label p^*^ for sample x is generated by the previous model trained on the old classes, and the p is generated by the current model trained on the new and old classes. The rescaling function \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\tau _{i}(v)=v_{i}^{1 / \Omega } / \sum _{j} v_{j}^{1 / \Omega }$$\end{document} with \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\Omega =2$$\end{document} is used to increase the weights of smaller values.
The proposed MGBCIL method addresses the effects of imbalance on catastrophic forgetting by integrating fine-grained, medium-grained, and coarse-grained strategies. Additionally, the incorporation of the distillation technology ensures effective retention of old knowledge while accommodating the learning of new class, further mitigating the forgetting. Therefore, we combine the above losses into a comprehensive total loss function, which consists of four terms:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} L=L_{f}+\lambda L_{kd}+L_{m}+ L_{c}, \end{aligned}$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\lambda =\lambda _{\text{ base } } \sqrt{\left| C_{new}\right| /\left| C_{old}\right| }$$\end{document} , and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\lambda _\text{base}$$\end{document} is a fixed constant for each dataset.
Experiment
Preparation
Datasets
We evaluate the proposed model using two widely recognized datasets: CIFAR-10 and CIFAR-100 [50], which contain 10 and 100 classes, respectively. Each dataset comprises a total of 60,000 color images, with a resolution of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$32 \times 32$$\end{document} pixels per image. In the experiments on these datasets, 40,000 images are used for training, while 10,000 images are allocated for validation and another 10,000 are set aside for testing. To analyze the impact of memory constraints on incremental learning, we evaluate the model under four different exemplar storage settings: 3, 5, 8 and 10 exemplars per class.
Comparison method
Eight methods are compared with our method: Finetune [51] updated the model parameters without storing episodic memory. Several CIL methods were utilized the episodic memory replay, such as GEM [16], iCaRL [11], Bic [32], WA [52], Coil [18], Memo [49] and PCR [36]. These methods are described in detail as follows:
- Finetune: The method fine-tuned the model parameters based on new classes without adding any episodic memory from old classes.
- GEM: The method projected the gradient to the closest gradient satisfying the constraints, achieving a balance between learning new classes and retaining old knowledge.
- iCaRL: The method extended knowledge distillation regularization by incorporating exemplar sets to retain previous knowledge. Additionally, it eliminated the fully connected layer and utilized nearest class mean (NCM) for classification during inference.
- Bic: The method addressed the imbalance between new and old classes by introducing a dynamic balancing term. Furthermore, it proposed an additional rectification layer to adjust predictions. This layer was fine-tuned using a separate validation set split from the exemplar set to optimize performance.
- WA: The method improved incremental learning by normalizing classifier weights after each optimization step. Additionally, it employed weight clipping to ensure that the predicted probabilities were proportional to the classifier’s weights.
- Coil: The method introduced a bidirectional distillation framework through co-transport, leveraging the semantic relationships between new and old models to enhance incremental learning.
- Memo: The method proposed decoupling the intermediate backbone and expanding the deeper layers to improve the model’s capacity for task-specific knowledge retention.
- PCR: The method replaced the contrastive samples of anchor points with corresponding proxies, effectively solving the problem of imbalance.
Evaluation metrics
The Top-1 accuracy after the b-th phase is represented as \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$A_{b}$$\end{document} . Several evaluation metrics are selected to measure the performance in the public datasets [53], [2], including average accuracy \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\bar{A}$$\end{document} , last phase accuracy \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$A_{B}$$\end{document} , and forgetting rate F.
- Average accuracy ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\bar{A}=\frac{1}{B} \sum _{b=1}^{B} A_{b}$$\end{document} ): This metric calculates the average accuracy across the initial and all incremental phases under various incremental settings. It provides a holistic view of the method’s performance throughout the entire incremental learning process and helps assess its stability in adapting to new tasks while retaining previously learned knowledge.
- Last phase accuracy (AB): This metric represents the accuracy achieved at the end of the last incremental phase. It is a critical indicator for evaluating the ultimate performance of the model after learning all tasks, reflecting its capacity to retain knowledge from both the initial and incremental phases.
- Forgetting rate ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$F=(A_{B}-A_{0})/{A_{B}}$$\end{document} ): This metric measures the percentage change in accuracy between the initial phase and the last incremental phase. A higher forgetting rate indicates greater loss of knowledge from earlier tasks, while a lower rate suggests better retention. It is particularly useful for assessing the robustness of methods in mitigating catastrophic forgetting during the incremental learning process.
Training process
In the training procedure, we implement the methods using PyTorch on a GeForce RTX 2080 Ti GPU, and some comparison methods based on the PyCIL toolbox [54]. The classes within the datasets are arranged in a fixed random order, and the performance of model is evaluated on all observed classes after each phase. For the CIFAR-10 and CIFAR-100 datasets, the number of exemplars (numExe) are set to \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\left\{ 3, 5, 8, 10 \right\}$$\end{document} . ResNet-18 is adopted as the encoder and backbone network for all methods. For MGBCIL, the projection function is an MLP with a hidden layer activated by ReLU. The initial learning rate is set to 0.01 and reduced by a factor of 10 after 80 and 120 epochs, with training spanning a total of 160 epochs. The hyper-parameters are configured as follows: \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\lambda _\text{base}=5$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\tau =0.07$$\end{document} , while the number of layers L is set to 1 for CIFAR-10 and 2 for CIFAR-100.Fig. 3. Parameter studies of MGBCIL on CIFAR-10 with Base2 Inc1 and numExe=3
Parameter study
To enhance the stability of fine-grained loss, a smoothing parameter s is introduced to prevent extreme frequency impacts. Simultaneously, a margin threshold m is incorporated into coarse-grained loss to enforce a clear separation between new and old classes. This experiment explores the effects of these parameters on the incremental learning performance of MGBCIL. Specifically, we report the average accuracy \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\bar{A}$$\end{document} and forgetting rate F on the CIFAR-10 dataset under the Base2 Inc1 incremental learning setting, where the values of s and m are adjusted within the range of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\left\{ 0.0, 0.1, 0.5, 1.0 \right\}$$\end{document} .
As illustrated in Fig. 3(a) and (b), which depict the average accuracy and forgetting rate, respectively. MGBCIL achieves its optimal performance when \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$s=0.1$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$m=0.5$$\end{document} . These parameter values ensure a balanced trade-off between two objectives: reducing the impact of extreme frequency in the fine-grained loss and maintaining effective separation between new and old classes in the coarse-grained loss. Based on these findings, we adopt \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$s=0.1$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$m=0.5$$\end{document} as the default parameter settings for all subsequent experiments. This parameter selection not only maximizes the overall effectiveness of MGBCIL but also provides validation for the reasonableness of its design.
Comparison with existing work
In this section, we conduct comprehensive experiments to validate the effectiveness of MGBCIL in mitigating catastrophic forgetting and incremental classification. The proposed MGBCIL is compared with other methods on the CIFAR-10 and CIFAR-100 datasets. To further demonstrate the versatility of MGBCIL, we evaluate its performance under different episodic memory buffer budget settings, which is a crucial factor in incremental learning as it directly impacts the model’s ability to retain knowledge from old classes.
The advantage of the proposed MGBCIL method during the incremental learning process is clearly shown in Figs. 4 and 5, which displays the changes in Top-1 accuracy at each incremental phase. Specifically, as depicted in Figs. 4(a)-(e) and 5(a)-(e), the Bic method disrupts the incremental learning process when the numExe is to 8 or less. To ensure a fair comparison, we only evaluate the incremental classification results of the Bic method during the phases when the numExe exceeds 8, as shown in Figs. 4(g)-(h) and 5(g)-(h). The results of these two figures indicate a gradual decrease in classification accuracy for all methods as new classes are learned incrementally, which aligns with the phenomenon of catastrophic forgetting. This progressive decrease in accuracy reflects the difficulty of retaining previously learned knowledge while incorporating new information. Although it is impossible to completely eliminate forgetting in incremental learning, the findings highlight that the effects of forgetting can be mitigated to a certain extent.Fig. 4. Top-1 accuracy variation on CIFAR-10Fig. 5Top-1 accuracy variation on CIFAR-100
As shown in Figs. 4 and 5, when numExe is set variably within the range of 3 to 10, the forgetting phenomenon of MGBCIL is relatively stable without any sudden decreases or increases. Although the proposed MGBCIL method performs slightly inferior to the Coil and PCR methods in the early phase, it is completely superior to other comparison methods in the later phase of the incremental learning, and its performance is optimal on the final phase of incremental learning. In conclusion, these results demonstrate the superior ability of MGBCIL to retain old knowledge, highlighting its effectiveness in mitigating catastrophic forgetting. The findings provide strong evidence of its excellent performance across various incremental settings. This further underscores the importance of strategies such as multi-granularity balance and knowledge distillation in reducing the impact of forgetting.
In addition, we report several key performance metrics, including the average accuracy \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\bar{A}$$\end{document} across all incremental phases, the final phase accuracy \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$A_{B}$$\end{document} , and the percentage increase or decrease of the forgetting rate F. In these evaluations, the symbol \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\uparrow$$\end{document} indicates that larger values are better, while the symbol \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\downarrow$$\end{document} signifies that smaller values are better. For clarity, the best results are highlighted in bold, and the second-best results are shown in underline. As shown in Tables 2, 3, 45, MGBCIL performs better than other methods in the experimental settings of CIFAR-10 with Base2 Inc2, CIFAR-100 with Base20 Inc10, and CIFAR-100 with Base20 Inc20. In particular, the last phase accuracy \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$A_{B}$$\end{document} and forgetting rate F are almost the best perform. For example, when numExe=3 in Table 3, the average accuracy is improved by up to 9.59% and the forgetting rate is reduced by up to 25.45%. These findings confirm the robustness of MGBCIL across various memory settings, further validating its potential for incremental learning tasks.
The multi-granularity balance strategy in MGBCIL shows limited effectiveness under a low degree of imbalance between the old and new class samples. As shown in the experimental results in Table 2 that compared with Memo and PCR methods, the average accuracy of MGBCIL does not achieve optimal performance when using the Base2 Inc1 setting on the CIFAR-10 dataset. This phenomenon can be attributed to the relatively small number of new class samples in the incremental setting of Base2 Inc1, where the initial phase contains two classes and only one new class is added in each subsequent incremental phase. Consequently, during the three stages of the incremental training process (batch processing, task updating, and classification decision), there is a low degree of imbalance between the old class samples replayed from episodic memory and the new class samples introduced in the current task. In such cases, the advantage of the multi-granularity balance strategy has not been fully utilized, which is designed to address the imbalance problem between old and new class samples. As a result, the performance of the MGBCIL method is limited in this specific setting to some extent.Table 2. The average accuracy \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\bar{A} (\uparrow )$$\end{document} , last phase accuracy \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$A_{B} (\uparrow )$$\end{document} , forgetting rate \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$F (\downarrow )$$\end{document} of methods on CIFAR-10 with Base2 Inc1DatasetNumExeIndicatorFinetune [51]iCaRL [11]GEM [16]Bic [32]WA [52]Coil [18]Memo [49]FCR [36]MGBCILCIFAR-103 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\bar{A}$$\end{document} 35.5141.6841.58-43.1135.3352.0349.1850.21 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$A_{B}$$\end{document} 10.0023.9020.71-24.4614.5230.6223.7431.78F0.890.740.77-0.730.850.670.760.655 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\bar{A}$$\end{document} 35.5143.6041.55-49.7139.7855.8254.2851.39 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$A_{B}$$\end{document} 10.0025.6120.47-34.0820.1734.7031.6236.53F0.890.720.78-0.630.790.630.670.598 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\bar{A}$$\end{document} 35.5148.5241.73-51.9645.0356.6261.1152.71 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$A_{B}$$\end{document} 10.0031.3020.83-36.1928.8935.2937.8841.37F0.890.660.77-0.610.690.620.610.5610 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\bar{A}$$\end{document} 35.5151.6041.7537.4554.6847.2857.8662.3953.08 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$A_{B}$$\end{document} 10.0034.2220.1615.5639.8830.2737.9540.8143.87F0.890.630.780.830.570.680.590.580.53Table 3. The average accuracy \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\bar{A} (\uparrow )$$\end{document} , last phase accuracy \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$A_{B} (\uparrow )$$\end{document} , forgetting rate \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$F (\downarrow )$$\end{document} of methods on CIFAR-10 with Base2 Inc2DatasetNumExeIndicatorFinetune [51]iCaRL [11]GEM [16]Bic [32]WA [52]Coil [18]Memo [49]FCR [36]MGBCILCIFAR-103 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\bar{A}$$\end{document} 43.9757.8045.10-62.1555.3060.9254.1868.11 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$A_{B}$$\end{document} 19.3435.4915.75-39.8030.7742.0925.5952.89F0.790.610.83-0.570.670.550.740.415 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\bar{A}$$\end{document} 43.9758.7946.71-63.3558.4962.3258.3666.20 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$A_{B}$$\end{document} 19.3439.0222.81-45.9939.8344.6030.2350.99F0.790.570.75-0.500.580.520.690.438 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\bar{A}$$\end{document} 43.9762.4447.4952.2064.7160.7263.1865.2567.05 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$A_{B}$$\end{document} 19.3447.0723.1931.3050.9444.2144.3941.5552.72F0.790.490.750.650.440.530.530.570.4310 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\bar{A}$$\end{document} 43.9761.3447.1053.5764.7659.9963.3867.0867.79 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$A_{B}$$\end{document} 19.3443.3624.0834.3649.8942.1345.9346.0752.17F0.790.530.740.610.460.550.510.530.43Table 4. The average accuracy \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\bar{A} (\uparrow )$$\end{document} , last phase accuracy \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$A_{B} (\uparrow )$$\end{document} , forgetting rate \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$F (\downarrow )$$\end{document} of methods on CIFAR-100 with Base20 Inc10DatasetNumExeIndicatorFinetune [51]iCaRL [11]GEM [16]Bic [32]WA [52]Coil [18]Memo [49]FCR [36]MGBCILCIFAR-1003 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\bar{A}$$\end{document} 21.3341.2930.82-44.2832.9942.0638.7546.41 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$A_{B}$$\end{document} 8.1224.9218.24-28.839.0927.4721.7434.83F0.890.650.74-0.590.880.620.710.525 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\bar{A}$$\end{document} 21.3343.6832.41-45.6044.1543.9442.346.73 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$A_{B}$$\end{document} 8.1227.6618.87-29.1325.6429.0627.1334.31F0.890.610.73-0.590.660.590.640.538 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\bar{A}$$\end{document} 21.3346.3432.53-47.8947.3347.2744.8948.33 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$A_{B}$$\end{document} 8.1231.9319.54-32.9630.2032.6928.6937.15F0.890.550.72-0.530.600.540.620.4910 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\bar{A}$$\end{document} 21.3346.7833.7135.7048.2248.2147.5646.5849.03 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$A_{B}$$\end{document} 8.1231.7820.656.9132.4629.932.6631.0637.35F0.890.550.710.890.540.600.540.580.49Table 5. The average accuracy \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\bar{A} (\uparrow )$$\end{document} , last phase accuracy \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$A_{B} (\uparrow )$$\end{document} , forgetting rate \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$F (\downarrow )$$\end{document} of methods on CIFAR-100 with Base20 Inc20DatasetNumExeIndicatorFinetune [51]iCaRL [11]GEM [16]Bic [32]WA [52]Coil [18]Memo [49]FCR [36]MGBCILCIFAR-1003 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\bar{A}$$\end{document} 33.8448.8842.81-49.2050.7945.5545.2250.82 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$A_{B}$$\end{document} 15.4731.7827.06-35.7434.9129.0025.8039.21F0.780.550.62-0.480.520.590.660.465 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\bar{A}$$\end{document} 33.8450.8543.51-51.5151.8447.4747.5552.88 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$A_{B}$$\end{document} 15.4736.0227.95-38.2038.3231.4729.6841.09F0.780.490.60-0.460.470.560.610.458 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\bar{A}$$\end{document} 33.8451.9244.3448.9251.8752.3249.6049.8652.47 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$A_{B}$$\end{document} 15.4737.0229.5633.7138.7339.7734.5132.6640.85F0.780.480.580.480.440.450.520.570.4410 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\bar{A}$$\end{document} 33.8452.7844.9748.6952.2354.5150.1851.6952.03 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$A_{B}$$\end{document} 15.4738.0030.5535.3539.7140.3535.4834.1540.90F0.780.460.570.450.420.450.500.550.44
Ablation experiment
The proposed MGBCIL method incorporates four components of loss functions, each designed to address specific challenges in incremental learning: \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$L_{f}$$\end{document} rebalances the samples of new and old classes during batch processing to mitigate fine-grained imbalances. \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$L_{m}$$\end{document} ensures the local separation during task updating, and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$L_{c}$$\end{document} promotes the global separation in classification decisions. \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$L_{kd}$$\end{document} retains knowledge from old classes via distillation. To verify the benefits of each loss function in MGBCIL, we conduct the ablation study on the CIFAR-10 dataset with Base2 Inc1 and numExe=3 using several combinations.
As shown in Fig. 6, the experimental results show that MGBCIL with four loss components significantly outperforms other methods in classification accuracy at most phases of the entire incremental training process, especially from phase 5 to phase 8, where MGBCIL achieves the best results. Meanwhile, we find that MGBCIL has the highest average accuracy and the lowest forgetting rate in Fig. 7. These observations suggest that each loss function plays a crucial role in addressing the impact of the imbalance between new and old class samples, while also effectively mitigating the forgetting of previous knowledge. These findings highlight the necessity of four loss functions in the MGBCIL framework and emphasize their importance in incremental learning.Fig. 6. Top-1 accuracy for different components of MGBCIL in all incremental phases on CIFAR-10 with Base2 Inc1 and numExe=3Fig. 7Average accuracy and forgetting rate for different components of MGBCIL on CIFAR-10 with Base2 Inc1 and numExe=3
Conclusion
In this paper, we propose a novel CIL method to mitigate forgetting caused by imbalance through the multi-granularity balance strategy, which is inspired by the three-way granular computing for human problem-solving. Specifically, we propose a weighted cross-entropy loss for rebalancing batch processing, and introduce the contrastive learning with different anchor settings in the task updating and the classification decision to promote the local and global separation of new and old classes. Additionally, the distillation loss also preserves previous knowledge to further mitigate catastrophic forgetting. According to experimental results, the proposed MGBCIL significantly outperforms the compared methods in various incremental learning settings, including classification accuracy and forgetting rate. These results verify the effectiveness of the MGBCIL in mitigating catastrophic forgetting.
According to the experimental results, MGBCIL does not get the highest average accuracy on the CIFAR-10 dataset with Base2 Inc1 incremental setting. This can be attributed to the fact that the number of new class samples is relatively small in the Base2 Inc1 setting, which reduces the degree of imbalance between new and old class samples and weakens the role of the multi-granularity balancing strategy. In future work, we aim to further explore an optimized multi-granularity balance strategy that can maintain efficient performance even in low degree of imbalance scenarios, or explore other strategies that operate effectively under various imbalance conditions.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Wang G, Xu J (2014) Granular computing with multiple granular layers for brain big data processing. Brain Inf 1:1–1010.1007/s 40708-014-0001-z PMC 488315127747523 · doi ↗ · pubmed ↗
- 2Zenke F, Poole B, Ganguli S ( 2017) Continual learning through synaptic intelligence. In: Proceedings of the 34th International Conference on Machine Learning (ICML), vol. 70, pp. 3987– 3995. PMLR, Sydney, Australia PMC 694450931909397 · pubmed ↗