Estimation and model selection for finite mixtures of Tukey’s g- &-h distributions
Tingting Zhan, Misung Yi, Amy R. Peck, Hallgeir Rui, Inna Chervoneva

TL;DR
This paper introduces a flexible statistical model for analyzing protein expression levels in tissues, using a mixture of Tukey’s g- &-h distributions to handle complex data patterns.
Contribution
The novel contribution is a quantile-based estimation method and a stepwise model selection algorithm for finite mixtures of Tukey’s g- &-h distributions.
Findings
The proposed QLMD estimator effectively fits Tukey’s g- &-h mixtures with both Gaussian and non-Gaussian components.
The method outperforms skew-normal and skew-t mixtures in modeling real protein expression data.
Parameter estimates from the model are useful predictors of progression-free survival in breast cancer.
Abstract
A finite mixture of distributions is a popular statistical model, which is especially meaningful when the population of interest may include distinct subpopulations. This work is motivated by analysis of protein expression levels quantified using immunofluorescence immunohistochemistry assays of human tissues. The distributions of cellular protein expression levels in a tissue often exhibit multimodality, skewness and heavy tails, but there is a substantial variability between distributions in different tissues from different subjects, while some of these mixture distributions include components consistent with the assumption of a normal distribution. To accommodate such diversity, we propose a mixture of 4-parameter Tukey’s g- &-h distributions for fitting finite mixtures with both Gaussian and non-Gaussian components. Tukey’s g- &-h distribution is a flexible model that allows…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
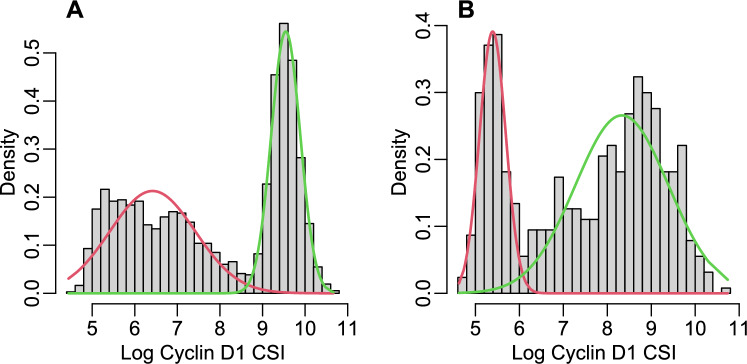 Figure 1
Figure 1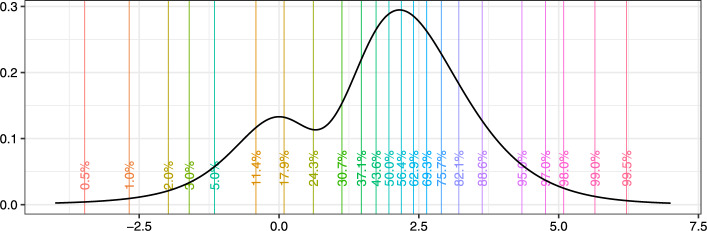 Figure 2
Figure 2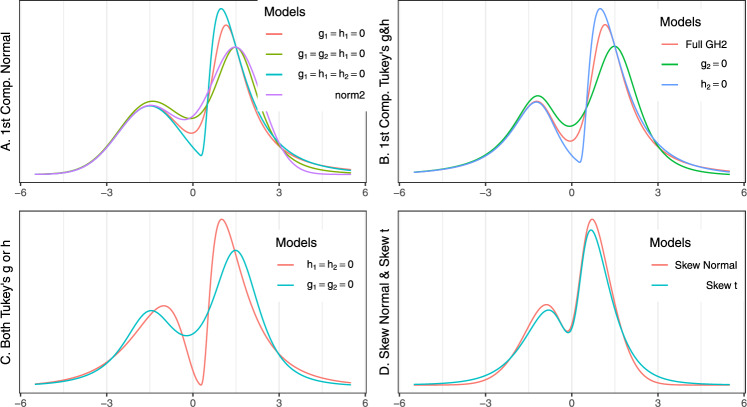 Figure 3
Figure 3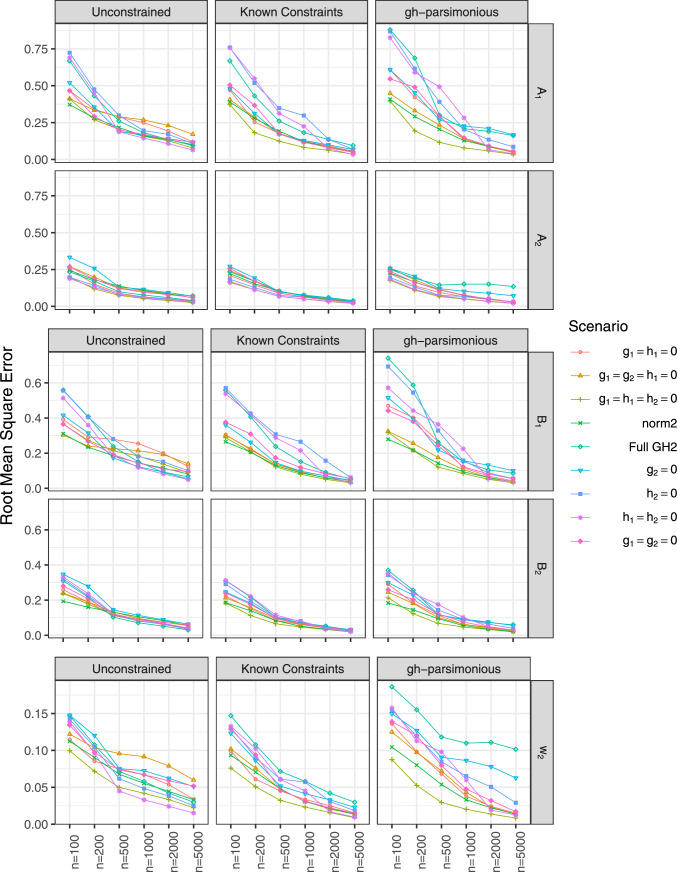 Figure 4
Figure 4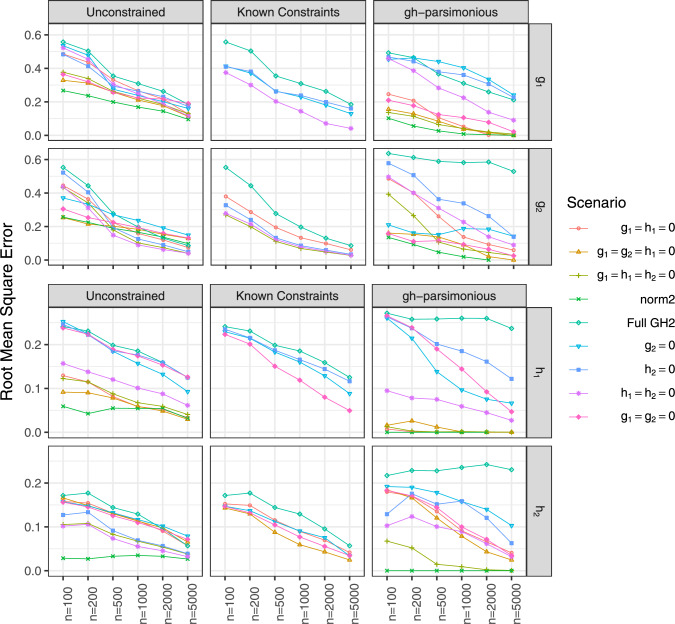 Figure 5
Figure 5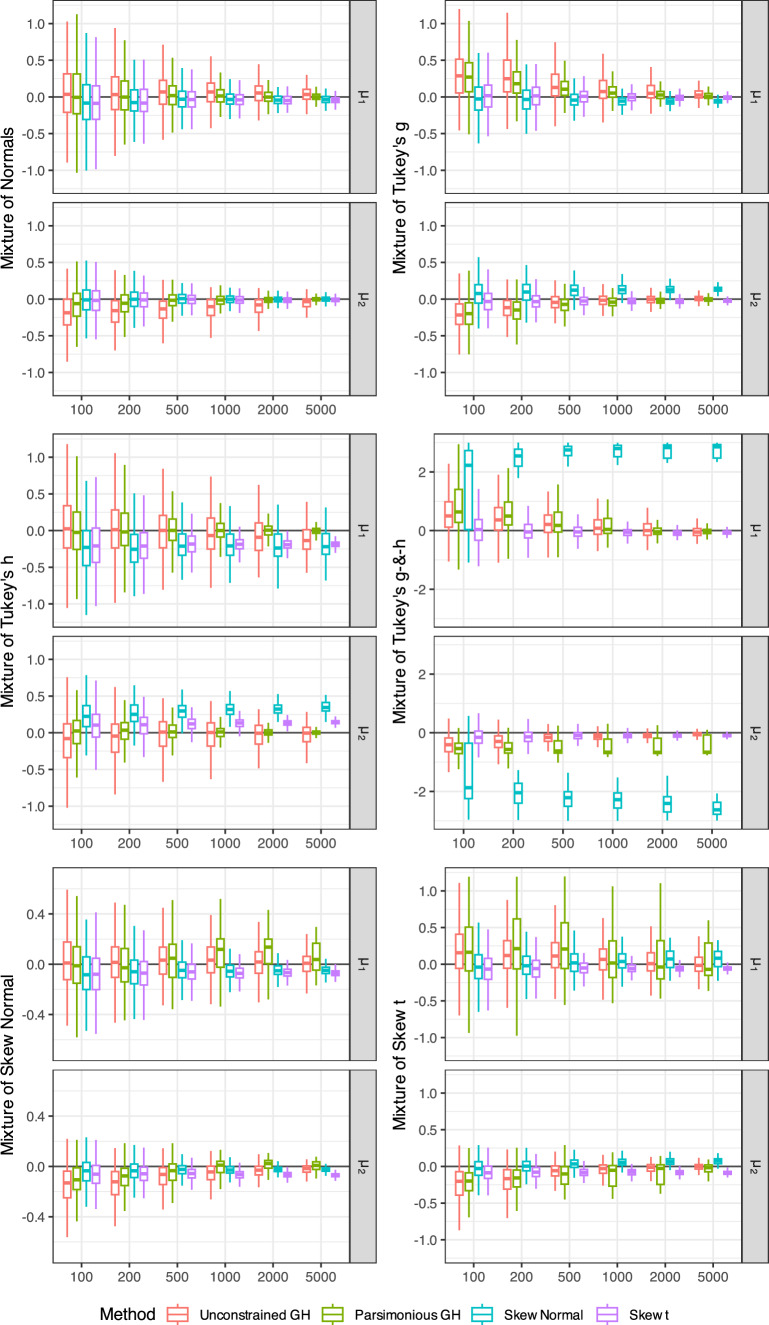 Figure 6
Figure 6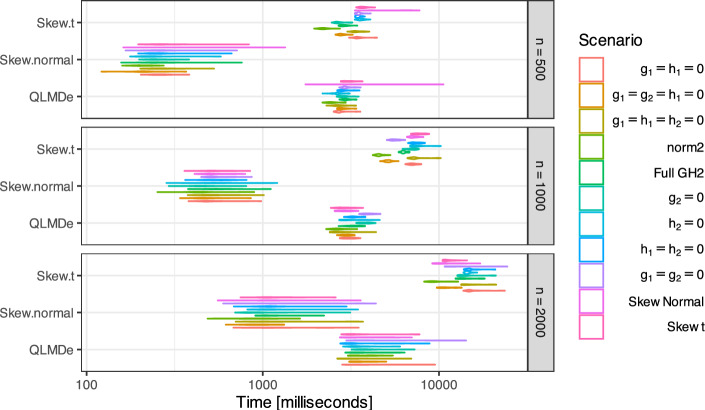 Figure 7
Figure 7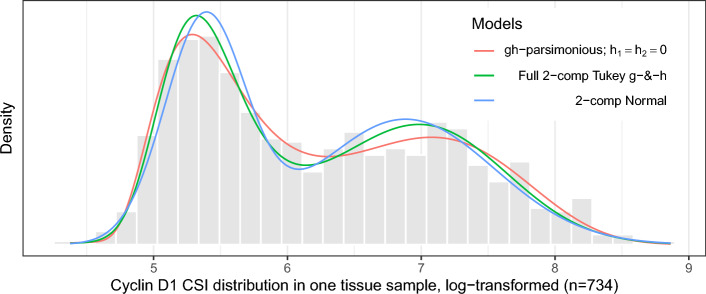 Figure 8
Figure 8- —http://dx.doi.org/10.13039/100000002National Institutes of Health
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsBayesian Methods and Mixture Models · Statistical Methods and Inference · Statistical Methods and Bayesian Inference
Introduction
Finite mixtures are popular distribution models with a continuously expanding range of applications. Data exhibiting multimodality are quite common in biomedical sciences, and finite mixtures are especially useful for modeling distinct subpopulations with some overlap and clustering (Titterington et al. 1985; McLachlan and Basford 1988; Everitt and Hand 1981; McLachlan et al. 2019). The finite mixture of Gaussian/normal components most commonly used to identify heterogeneous subpopulations as components of the mixture (Reynolds 2009; Geoffrey 2000, 2014; Benaglia et al. 2009), including the application to assignment of cell identity from single-cell multiplexed imaging and proteomic data (Geuenich et al. 2021).
However, the distributions of mixture components may be skewed and have heavy tails in many applications, especially biomedical. For instance, such distributions are often observed for the data generated by quantification of cellular signal intensity (CSI) of protein expression in the immunofluorescence immunohistochemistry (IF-IHC) images. Figure 1 shows histograms of CSI distributions of Cyclin D1 protein quantified using IF-IHC technology in a tissue microarray (TMA) cores of breast cancer patients. For many other proteins heterogeneously expressed in tumor tissue, the distributions of CSI levels are often bimodal and heavily skewed like the ones shown in Fig. 1. It is biologically meaningful to assume that such CSI distributions are mixtures of a lower component representing the background noise and an upper component(s) representing the actual signal, but normal distribution is not appropriate in many cases. For example, see the first component in Fig. 1A and for the second component in Fig. 1B.Fig. 1. Examples of fitting 2-component normal mixtures to Cyclin D1 Log CSI expression levels with poor fit of the normal distribution in the first component A or in the second component B
In this work, we develop a finite mixture of Tukey’s g- &-h distributions to accommodate components with variable degrees of skewness and kurtosis. The normal distribution family can be expanded to include heavy tailed and skewed distributions within the g- &-h distributional family introduced by Tukey (Tukey 1977). This family represents a rich class of common univariate distributions with different levels of skewness and elongation. Tukey’s g- &-h distributions can approximate a wide variety of commonly used distributional shapes, such as normal, lognormal, Weibull, exponential and many other distributions that do not have finite first four moments, such as the Cauchy distribution (Martinez and Iglewicz 1984). Mixtures of two Tukey’s g-distributions, a subclass of Tukey’s g- &-h distributions, were recently proposed for econometric applications (Vitiello 2008; Jiménez and Arunachalam 2016), but Tukey’s g- &-h mixtures that include h-parameter have not been considered in the literature before. Since Tukey’s g- &-h family includes subclasses of normal distributions, g-distributions, and h-distributions, using Tukey’s g- &-h mixtures allows different components to have different number of parameters. That is one component may have a normal distribution, while the other may have Tukey’s g- &-h distribution with 4 parameters.
The likelihood of a single Tukey’s g- &-h distribution and Tukey’s g- &-h mixture do not have a closed analytical form, and the maximum likelihood estimation is not feasible. Therefore, we propose a Quantile Least Mahalanobis Distance (QLMD) estimator of Tukey’s g- &-h mixture parameters. This QLMD estimator minimizes the Mahalanobis distance between selected empirical sample quantiles and corresponding model-based quantiles. The QLMD estimator may be viewed as an indirect estimator and its consistency and asymptotic normality follows from the general theory of indirect estimation (Gourieroux et al. 1993; Gouriéroux et al. 1996). This estimator generalizes the quantile based least squares (QLS) estimator (Xu et al. 2014) by accommodating a mixture rather than a single Tukey’s g- &-h distribution and incorporating the covariance matrix of sample quantiles in the objective function. The QLMD estimator can be made robust to extreme outliers if the quantiles selected as ancillary parameters exclude the extreme tail probabilities, similar to the QLS estimator (Xu et al. 2014).
To facilitate selection of a parsimonious Tukey’s g- &-h mixture model, we developed an algorithm which combines forward selection of g- &-h parameters for a given number of components and forward selection of the number of components to maximize a penalized likelihood. All methods developed were implemented in the R (R Core Team 2022) package QuantileGH, available at https://CRAN.R-project.org/package=QuantileGH.
Previously proposed finite mixtures of continuous non-Gaussian parametric distributions include mixtures of t-distributions (Peel and McLachlan 2000), skew-normal distributions (Lin et al. 2007; Basso et al. 2010), multivariate skew t-distributions (Lin 2010; Lee and McLachlan 2014), skew elliptical distributions, including the scale mixtures of the skew-normal distribution (Branco and Dey 2001; Genton 2004; Prates et al. 2013), Gamma distributions (Wiper 2001; Young et al. 2019), and generalized hyperbolic distributions (Browne and McNicholas 2015). Finite scale mixtures of skew-normal distributions have been also used to model random errors in the context of robust mixture regression (Zeller et al. 2016).
The scale mixtures of skew-t distributions have the same number of parameters as the proposed full/unconstrained Tukey’s g- &-h mixture model, and both models incorporate parameters for skewness and kurtosis. The main advantage of our model is flexibility with respect to combining components with different complexity and required number of parameters. That is, a parsimonious Tukey’s g- &-h mixture model may include components with normal distribution combined with Tukey’s g-distribution or h-distribution or g- &-h distribution. This allows adaptive complexity of the model potentially improving interpretability.
A simulation study was conducted to (i) evaluate the finite sample performance of the QLMD estimator with and without model selection for estimating parameters of 2-component Tukey’s g- &-h mixture models and (ii) compare fitted 2-component mixtures with Tukey’s g- &-h, skew-normal, and skew-t components. The simulation results indicate that Tukey g- &-h mixtures provide more accurate estimates of component means that are more robust to mis-specification of the component distribution.
We then applied Tukey’s g- &-h mixture to modeling distributions of cell-level Cyclin D1 protein expression in breast cancer tissues. Full or reduced 2-component mixtures as well as the models with the optimal number of components were estimated for distribution of Cyclin D1 expression in cells from each tissue. The fitted models were used to estimate the location parameter of the upper end component, which was evaluated as predictor of progression free survival (PFS) in breast cancer patients. The best prognostic value was achieved using the parsimonious Tukey’s g- &-h mixture. This highlights the advantage of the proposed parsimonious Tukey’s g- &-h mixture model that allows optimizing the complexity of the components in the mixture. We have also compared the goodness of fit for optimal Tukey’s g- &-h, skew-normal, skew-t, and normal mixtures applied to Cyclin D1 expression in each tissue. The optimal Tukey’s g- &-h mixtures had similar goodness of fit, but smaller number of parameters for the majority of breast cancer tissues, as compared to alternative optimal non-Gaussian mixtures.
Finite mixtures of Tukey’s g- &-h distributions
Tukey’s g- &-h distributions
Tukey’s g- &-h random variable \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$T_{(A,B,g,h)}$$\end{document} (Tukey 1977) is defined through a monotone transformation of the standard normal variable Z (Hoaglin 1985),
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned}&T_{(A,B,g,h)}\\&\quad ={\left\{ \begin{array}{ll} A + B\cdot G(Z)\cdot Z & g\ne 0,\ g\text {-distribution} \\ A + B\cdot H(Z)\cdot Z & h>0,\ h\text {-distribution} \\ A + B\cdot G(Z)\cdot H(Z)\cdot Z & g\ne 0,h>0,\ gh\text {-distribution} \\ \end{array}\right. } \end{aligned}$$\end{document}where A is the location and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$B>0$$\end{document} is the scale parameter. The skewness is introduced by \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$G(z)=(e^{gz}-1)/gz$$\end{document} with \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$G_0(z)=\lim _{g\rightarrow 0} G_{g \ne 0}(z)=1$$\end{document} . The kurtosis is introduced by \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$H(z)=e^{hz^2/2}$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$h\ge 0$$\end{document} . When \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$g=0$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$h=0$$\end{document} then \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$T_{(A,B,g,h)} = A + BZ$$\end{document} follows a normal distribution \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$N(A, B^2)$$\end{document} .
The quantile function of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$T_{(A,B,g,h)}$$\end{document} is
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} t_{(A, B, g, h)}(p)={\left\{ \begin{array}{ll} A+B z_p G(z_p) & g\ne 0 \\ A+B z_p H(z_p) & h>0 \\ A+B z_p G(z_p) H(z_p) & g\ne 0,\ h>0 \end{array}\right. } \end{aligned}$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$z_p$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$0<p<1$$\end{document} , is the p-th quantile of the standard normal distribution. The distribution function \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$F_{(A,B,g,h)}(t)=\text {Pr}(T_{(A, B, g, h)} \le t)=\text {Pr}(Z \le \zeta _{(A, B, g, h)}(t))$$\end{document} , where
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned}&\zeta _{(A, B, g, h)}(t) \nonumber \\&\quad = {\left\{ \begin{array}{ll} g^{-1}\ln \big (gB^{-1}(t-A)+1\big ), & g\ne 0 \\ z:\ z H(z) = B^{-1}(t-A), & h>0 \\ z:\ z G(z) H(z) = B^{-1}(t-A), & g\ne 0,\ h>0 \end{array}\right. } \end{aligned}$$\end{document}The distribution function \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$F_{(A,B,g,h)}(t)$$\end{document} , as well as the inverse Tukey transformation \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\zeta _{(A, B, g, h)}(t)$$\end{document} , do not have a closed analytical form when \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$h>0$$\end{document} , but their numerical values could be found by using a root-finding algorithm (Brent 1971). The density function \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$f_{(A,B,g,h)}(t)$$\end{document} has a closed analytical form in terms of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\zeta _{(A, B, g, h)}$$\end{document} ,
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} f_{(A,B,g,h)}(t) = \dfrac{e^{-z^2/2}}{\sqrt{2\pi }\cdot \partial t_{(A, B, g, h)}(z)/\partial z}\Bigg |_{z=\zeta _{(A, B, g, h)}(t)} \end{aligned}$$\end{document}where
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned}&\dfrac{\partial t_{(A, B, g, h)}}{\partial z}\\&\quad = {\left\{ \begin{array}{ll} Be^{gz}, & g\ne 0\\ Be^{hz^2/2}(1+hz^2), & h>0 \\ Be^{hz^2/2}\left( e^{gz}+g^{-1}hz(e^{gz}-1)\right) , & g\ne 0,\ h>0 \end{array}\right. } \end{aligned}$$\end{document}Finite mixture of Tukey’s g- &-h distributions
Consider the random variable \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{T}_\phi $$\end{document} of a K-component Tukey’s g- &-h mixture distribution,
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \text {Pr}\left( \textbf{T}_\phi< t\right) = \sum ^K_{k=1} w_k\text {Pr}\left( T_{A_k,B_k,g_k,h_k}<t\right) \end{aligned}$$\end{document}The 5K-dimensional parameter vector \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\phi = \{A_k, B_k, g_k, h_k, w_k: k = 1,\cdots ,K\}$$\end{document} is a subject to constraint \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\sum _k w_k = 1$$\end{document} , the ordered location constraint \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$A_1< A_2< \cdots < A_K$$\end{document} , and the component-wise constraints \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$B_k>0$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$h_k\ge 0$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$k = 1,\cdots ,K$$\end{document} . To avoid non-identifiability due to empty or equal components and relabeling the components, we reparammeterize model (3) using \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{\theta }$$\end{document} in the unconstrained parameter space \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{R}^{5K - 1}$$\end{document} ,
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \varvec{\theta }=&(A_1,d_2,\cdots ,d_k,\ \ b_1,\cdots , b_k,\ \ g_1,\cdots ,g_k,\nonumber \\ &\qquad \eta _1,\cdots ,\eta _k,\ \ \pi _2,\cdots ,\pi _K)^t \end{aligned}$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$d_k = \log (A_k - A_{k-1})$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pi _k = \ln w_k - \ln w_1$$\end{document} for \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$k = 2,\cdots ,K$$\end{document} ; and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$b_k = \log B_k$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\eta _k = \log h_k$$\end{document} for \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$k = 1,\cdots ,K$$\end{document} . The use of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$A_1$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$d_k$$\end{document} instead of all \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$A_k$$\end{document} , and multinomial logits \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pi _k$$\end{document} instead of component weights \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$w_k$$\end{document} , guarantees formal identifiability of (3) (Frühwirth-Schnatter 1981) by ensuring that (3) is a mixture of K distinct (with different and ordered means) and nonempty components. The proof of generic identifiability (Teicher 1963) of a finite mixture of Tukey’s g- &-h distributions is given in Appendix A.
The unconstrained parameterization (4) does not allow \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$h_k=0$$\end{document} , which will be addressed later in Sect. 3.1. In further developments, let \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{T}_\theta $$\end{document} be the finite Tukey’s g- &-h mixture with unconstrained parameters \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{\theta }$$\end{document} .
Quantile least Mahalanobis distance (QLMD) estimator for finite Tukey’s g- &-h mixture
Given a random sample \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$X=(x_1, \cdots , x_n)^t$$\end{document} , the quantile least Mahalanobis distance (QLMD) estimator \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\hat{\varvec{\theta }}_{\text {QLMD}}$$\end{document} minimizes the Mahalanobis distance between the sample quantiles \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{t} = (t_{p_1}, \cdots , t_{p_l})^t$$\end{document} and the true quantiles \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{t}_{\varvec{\theta }} = (t_{\varvec{\theta },p_1}, \cdots , t_{\varvec{\theta },p_l})^t$$\end{document} , for l pre-specified probabilities \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$0<p_1<\cdots<p_l<1$$\end{document} ,
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \hat{\varvec{\theta }}_\text {QLMD} = \arg \min _{\varvec{\theta }} \left( \textbf{t} - \textbf{t}_{\varvec{\theta }}\right) ^t \hat{\textbf{V}}^{-1}_\textbf{t}\left( \textbf{t} - \textbf{t}_{\varvec{\theta }}\right) \end{aligned}$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\hat{\textbf{V}}_{\textbf{t}}$$\end{document} is a nonparametricly estimated covariance matrix of sample quantiles (Mosteller 1946) with the ij-th element
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \left[ \hat{\textbf{V}}_\textbf{t}\right] _{ij} = \dfrac{\min \{p_i,p_j\}\ (1-\max \{p_i,p_j\})}{\hat{f}(t_{p_i}) \hat{f}(t_{p_j})}, \quad i,j = 1,\cdots , l \end{aligned}$$\end{document}and kernel density estimator \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\hat{f}$$\end{document} . Under the assumptions listed in Appendix B, the indirect estimation theory (Gourieroux et al. 1993; Gouriéroux et al. 1996) implies that \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\hat{\varvec{\theta }}_{\text {QLMD}}$$\end{document} is \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\sqrt{n}$$\end{document} -consistent for estimating the true parameter \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{\theta }_0$$\end{document} and, as \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$n\rightarrow \infty $$\end{document} ,
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned}&\sqrt{n}\left( \hat{\varvec{\theta }}_{\text {QLMD}} - \varvec{\theta }_0\right) \nonumber \\&\qquad {\mathop {\rightarrow }\limits ^{D}} \text {N}\left( \textbf{0}, \left( \textbf{J}_{\textbf{t}_{\varvec{\theta }_0}}^t\textbf{J}_{\textbf{t}_{\varvec{\theta }_0}}\right) ^{-1}\textbf{J}_{\textbf{t}_{\varvec{\theta }_0}}^t \textbf{V}_{\textbf{t}_{\varvec{\theta }_0}} \textbf{J}_{\textbf{t}_{\varvec{\theta }_0}}\left( \textbf{J}_{\textbf{t}_{\varvec{\theta }_0}}^t\textbf{J}_{\textbf{t}_{\varvec{\theta }_0}}\right) ^{-1}\right) \end{aligned}$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{J}_{\textbf{t}_{\varvec{\theta }_0}}$$\end{document} is the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$l \times (5K-1)$$\end{document} Jacobian matrix with the ij-th partial derivative
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \left[ \textbf{J}_{\textbf{t}_{\varvec{\theta }_0}}\right] _{ij} = \dfrac{\partial t_{\varvec{\theta },p_i}}{\partial \theta _j}\Bigg |_{\varvec{\theta } = \varvec{\theta }_0}\qquad i = 1,\cdots ,l \ \text {and}\ j = 1,\cdots ,5K-1 \end{aligned}$$\end{document}and matrix \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{V}_{\mathbf {t_{\varvec{\theta }_0}}}$$\end{document} is the asymptotic covariance matrix of sample quantiles of Tukey’s g- &-h mixture with the true parameter vector \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{\theta }_0$$\end{document} . Matrix \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{V}_{\mathbf {t_{\varvec{\theta }_0}}}$$\end{document} , additional assumptions needed for consistency and asymptotic normality of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\hat{\varvec{\theta }}_{\text {QLMD}}$$\end{document} , and sketch of the proof are given in Appendix B. The approximate asymptotic covariance matrix of the original parameter \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\phi $$\end{document} can be obtained from the asymptotic covariance (6) of the unconstrained parameter \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{\theta }$$\end{document} in (4) using the delta method, see detail in Appendix B.
Implementation of QLMD estimator
The number of quantiles l for QLMD estimation has to be at least as large as the number of parameters in the mixture to satisfy the assumptions listed in Appendix B. Quantiles corresponding to equidistant probabilities may be considered a natural choice, but our numeric studies suggest that inclusion of additional quantiles at the tails improves the accuracy of g and h parameter estimation. For mixtures with 2–3 components, we recommend using fifteen (15) equidistant probabilities between .05 and .95, and denser probabilities in each tail of the distribution, .005, .01, .02, .03, .97, .98, .99, .995. Figure 2 illusttrates this selection of percentages on a two-component Tukey’s g- &-h mixtures with parameters \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$(A_1,A_2)=(0,2.5)$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$B_1=B_2=1$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$(g_1,g_2)=(0,.3)$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$(h_1,h_2)=(.2,0)$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$(w_1,w_2)=(.33,.67)$$\end{document} .Fig. 2. Selection of p
Since QLMD estimator is potentially sensitive to the initial parameter values, we propose to use two different approaches for computing the starting values and then select the starting values that provide a better fit for the data.
The first approach is to use the normal mixture estimates (R package mixtools, Benaglia et al. (2009)) as starting values for means, standard deviations and mixing proportions and let \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$g=h=0$$\end{document} for all components.
For the second approach, we first apply k-means clustering (Cuesta-Albertos et al. 1997) to trimmed data with \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$5\%$$\end{document} of the observations being trimmed. Then the Mahalanobis distance from each trimmed observation to each of the K clusters is computed. Each trimmed observation is assigned to the closest cluster in terms of Mahalanobis distance. This approach of trimmed k-means clustering with re-assignment, is superior to the k-means clustering (Hartigan and Wong 1979), which could identify the long tails due to heavy skewedness and/or kurtosis as standalone cluster(s). The relative proportions of the resulting re-assigned clusters are used as initial estimates of the mixing parameters w’s. The cluster-wise Tukey’s g- &-h parameter estimates are computed using a slightly modified letter-value based estimates of Hoaglin (1985) (see details in Appendix C). We use letter-value based estimates based on lower half-spread (LHS) to estimate the distribution parameters of the cluster with the smallest location parameter, upper half-spread (UHS) for the cluster with the largest location parameter, and full-spread for the rest of the clusters.
In the simulation studies, we observed that the second approach yields better starting values for Tukey’s g- &-h mixtures with non-trivial g and/or h parameters, while the first approach may yield better starting values in cases when many g and/or h parameters are zero. Therefore, we obtain both types of initial estimates and choose the one with greater numerically approximated likelihood as the starting values. The QLMD of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{\theta }$$\end{document} in (4) is then obtained using Nelder-Mead minimization (Nelder and Mead 1965).
Parsimonious model selection
We developed two forward selection algorithms to find a parsimonious K-component Tukey’s mixture with some or all \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$g_k=0$$\end{document} and/or \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$h_k=0$$\end{document} , and to find an optimal number of components no greater than a user-specified \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$K_\text {max}$$\end{document} .
K-component gh-parsimonious mixture
Let \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{\rho }= (g_1,\cdots ,g_K,h_1,\cdots ,h_K)^t$$\end{document} be a sub-vector of g- &-h parameters of a K-component Tukey’s g- &-h mixture distribution. We call the mixture gh-constrained if \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$g_k=0$$\end{document} or \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$h_k=0$$\end{document} , for at least one \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$k=1,\cdots ,K$$\end{document} . If \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$g_k=h_k=0$$\end{document} for all \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$k=1,\cdots ,K$$\end{document} , i.e., \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{\rho }={\textbf {0}}$$\end{document} , the mixture reduces to a normal mixture.
The forward stepwise selection starts with a K-component normal mixture and adds a non-zero g or h parameter only if this increases the penalized log-likelihood \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\text {PL}(\theta )$$\end{document} with the same penalty as in Akaike (AIC, Akaike 1974) or Bayesian information criterion (BIC, Schwarz 1978),
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \text {PLa}(\theta )&= \ln \mathcal {L}(\theta ) - r&\text {AIC-like} \\ \text {PLb}(\theta )&= \ln \mathcal {L}(\theta ) - r\ln (n)/2&\text {BIC-like} \end{aligned}$$\end{document}where r is the number of parameters and n is the sample size. The likelihood \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathcal {L}(\theta )$$\end{document} has a closed form in terms of numerical solution to equation (2).
The algorithm proceeds as following:
- Compute QLMD estimate \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\hat{\varvec{\theta }} ^0$$\end{document} with all \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$g_k=h_k=0$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$k=1,\cdots ,K$$\end{document} , i.e. a normal mixture estimate.
- For each index \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$m=1,\cdots ,2K$$\end{document} of parameter sub-vector \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{\rho }$$\end{document} , compute QLMD estimate \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\hat{\varvec{\theta }} ^0_{+m}$$\end{document} for a gh-constrained mixture with \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{\rho } ^0_{+m} = (0,\cdots ,0,\rho _m,0,\cdots ,0)^t$$\end{document} . Here, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{\rho } ^0_{+m}$$\end{document} can be a g or h parameter.
- If \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\text {PL}(\hat{\varvec{\theta }} ^0) > \text {PL}(\hat{\varvec{\theta }} ^0_{+m})$$\end{document} , for all \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$m = 1,\cdots ,2K$$\end{document} , then the normal mixture \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\hat{\varvec{\theta }} ^0$$\end{document} is gh-parsimonious and the algorithm is completed.Otherwise, let \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$b = \arg \max _{m}\text {PL}(\hat{\varvec{\theta }} ^0_{+m})$$\end{document} , denote \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\hat{\varvec{\theta }} ^\text {new}=\hat{\varvec{\theta }} ^0_{+b}$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{\rho }^\text {new} = \varvec{\rho } ^0_{+b}$$\end{document} , and proceed to the next step.
- Let \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\hat{\varvec{\theta }} ^c=\hat{\varvec{\theta }} ^\text {new}$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{\rho }^c= \varvec{\rho }^\text {new}$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$M^c$$\end{document} be the set of indexes of zeros in \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{\rho }^c$$\end{document} . If \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$M^c$$\end{document} is empty, then \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\hat{\varvec{\theta }} ^c$$\end{document} is gh-parsimonious and the algorithm is completed. Otherwise, for each \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$m \in M^c$$\end{document} , compute QLMD estimate \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\hat{\varvec{\theta }} ^c_{+m}$$\end{document} with \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{\rho } ^c_{+m} =\varvec{\rho }^c+(0,\cdots ,0,\rho _{m},0,\cdots ,0)^t$$\end{document} .
- If \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\text {PL}(\hat{\varvec{\theta }} ^c) > \text {PL}(\hat{\varvec{\theta }} ^c_{+m})$$\end{document} for all \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$m \in M^c$$\end{document} , then \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\hat{\varvec{\theta }} ^c$$\end{document} is gh-parsimonious and the algorithm is completed.Otherwise, let \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$b = \arg \max _{m}\text {PL}(\hat{\varvec{\theta }} ^c_{+m})$$\end{document} and denote \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\hat{\varvec{\theta }} ^\text {new}=\hat{\varvec{\theta }} ^c_{+b}$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{\rho }^\text {new} = \varvec{\rho } ^c_{+b}$$\end{document} and return to Step 4. The resulting K-component gh-parsimonious mixture can be either a full Tukey’s g- &-h mixture, a gh-constrained mixture, or simply a normal mixture.
Optimal number of components
We select a gh-parsimonious mixture with the number of components ranging from \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$K=1$$\end{document} to a user-specified \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$K_\text {max}$$\end{document} , in case of no a priori knowledge or preference for K. The forward selection algorithm proceeds as following:
- Let \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$K^c=1$$\end{document} .
- Let \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\hat{\varvec{\theta }}_{K^c}$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\hat{\varvec{\theta }}_{K^c+1}$$\end{document} be the QLMD estimates of gh-parsimonious mixtures described in Sect. 3.1, with \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$K^c$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$K^c+1$$\end{document} components, respectively.
- If \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\text {PL}(\hat{\varvec{\theta }}_{K^c}) \ge \text {PL}(\hat{\varvec{\theta }}_{K^c+1})$$\end{document} , then \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\hat{\varvec{\theta }}_{K^c}$$\end{document} is optimal and the selection is completed.
- If \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\text {PL}(\hat{\varvec{\theta }}_{K^c}) < \text {PL}(\hat{\varvec{\theta }}_{K^c+1})$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$K^c+1 < K_\text {max}$$\end{document} , then let \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$K^\text {new} = K^c + 1$$\end{document} and repeat Step 2 with \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$K^c=K^\text {new}$$\end{document} .
- If \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\text {PL}(\hat{\varvec{\theta }}_{K^c}) < \text {PL}(\hat{\varvec{\theta }}_{K^c+1})$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$K^c+1 = K_\text {max}$$\end{document} , then \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\hat{\varvec{\theta }}_{K^c+1}$$\end{document} , or \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\hat{\varvec{\theta }}_{K_\text {max}}$$\end{document} is optimal within the user-specified range of K and the selection is completed.
Simulation studies
Design
Random samples were generated from nine 2-component Tukey’s g- &-h mixtures (Table 1) with shared parameters \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$(A_1,A_2) = (-1.5,1.5)$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$(B_1,B_2)=(1.1,.9)$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$(w_1,w_2)=(.4,.6)$$\end{document} and skew-normal and skew-t (Basso et al. 2010) mixtures with parameters \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$(\xi _1,\xi _2) = (-.3,.3)$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$(\omega _1,\omega _2) = (1.1,.9)$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$(\alpha _1,\alpha _2) = c(-2, 3)$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\nu _1=\nu _2=5$$\end{document} . Figure 3 shows the density curves of all simulation scenarios. Five hundred (500) data sets were simulated for each simulation scenario with sample sizes \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$n=100$$\end{document} , 200, 500, 1000, 2000 and 5000.Table 1. Simulated: Tukey’s g- &-h mixturesScenario \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$g_1$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$g_2$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$h_1$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$h_2$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$g_{1}=h_{1}=0$$\end{document} 00.700.2 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$g_{1}=g_{2}=h_{1}=0$$\end{document} 0000.2 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$g_{1}=h_{1}=h_{2}=0$$\end{document} 00.7002-comp. Normal0000Full 2-comp. Tukey g- &-h \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$-$$\end{document} 0.50.70.30.2 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$g_{2}=0$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$-$$\end{document} 0.500.30.2 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$h_{2}=0$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$-$$\end{document} 0.50.70.30 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$h_{1}=h_{2}=0$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$-$$\end{document} 0.50.700 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$g_{1}=g_{2}=0$$\end{document} 000.30.2
Fig. 3. Simulated: Mixtures of Tukey’s g- &-h, skew normal and skew t
The following mixture models were fitted,
- Unconstrained, estimating (i) \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$(\hat{\xi }_1,\hat{\xi }_2,\hat{\omega }_1,\hat{\omega }_2,\hat{\alpha }_1,\hat{\alpha }_2,\hat{w}_2)$$\end{document} of skew-normal mixture model via function smsn.mix of R package mixsmsn (Prates et al. 2013) with option family = "Skew.normal"; (ii) \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$(\hat{\xi }_1,\hat{\xi }_2,\hat{\omega }_1,\hat{\omega }_2,\hat{\alpha }_1,\hat{\alpha }_2,\hat{\nu }_1,\hat{w}_2)$$\end{document} of skew-t mixture model via function smsn.mix with option family = "Skew.t"; (iii) \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$(\hat{A}_1, \hat{A}_2, \hat{B}_1, \hat{B}_2, \hat{g}_1, \hat{g}_2, \hat{h}_1, \hat{h}_2, \hat{w}_2)$$\end{document} for Tukey’s g- &-h mixture model using the QLMD estimator.
- Known-Constraint, estimating non-zero parameters listed in Table 1 using QLMD estimator and assuming that true constraints are known (for Tukey’s g- &-h mixture model only);
- gh**-parsimonious** Tukey’s gh-parsimonious mixture model described in Sect. 3.1.
Performance of QLMD estimator
Figure 4 presents the root mean squared errors (RMSEs) of location and scale parameters and mixing proportions estimates for Tukey’s g- &-h mixtures with all three estimation approaches. For applications, these parameters are usually of practical interest and can be compared to parameters of fitted normal mixtures. For all estimation approaches, all RMSEs decrease as the sample size increases, and RMSEs are the lowest when correctly specified model is estimated (“Known Constraint" approach). The unconstrained and gh-parsimonious fitted models yield similar RMSE for location and scale parameters of the components. Meanwhile, for mixing proportions, gh-parsimonious approach resulted in higher RMSE as compared to unconstrained Tukey’s g- &-h mixtures across all sample sizes. The highest RMSE of mixing proportions with gh-parsimonious approach correspond to the simulated mixtures with 3 or 4 non-zero g and h parameters. These simulated mixtures are either the full unconstrained models or the models closest in complexity to the full mixture. Also notable, the RMSE of location and scale parameter estimates was higher for the first as compared to the second component due to the larger proportion of observations generated from the second component.
The RMSE for g and h parameters estimates are shown in Figs. 5. For g and h parameters equal to zero in the true simulated model, the estimates are not computed using “Known Constraint" approach. For g and h parameters, the RMSE also reduces as the sample size increase, but the rate of decrease is slower as compared to RMSE of location and scale parameters and mixing proportions. The “Known Constraint" approach performs the best estimating g and h parameters, while gh-parsimonious models yield highest RMSE for simulated mixtures with 3 or 4 non-zero g and h parameters.
Comparison with skew-normal and skew-t mixtures
Figure 6 shows the bias of estimating the means of the fitted mixtures of skew-normal, skew-t, and Tukey’s g- &-h distributions. The data were simulated using the mixtures of normal, skew-normal, skew-t, and Tukey’s g- &-h distributions, as specified in y-axis labels in Fig. 6. The component means of Tukey’s g- &-h, skew-normal, and skew-t distributions were derived from the corresponding moments in Appendix D.Fig. 4RMSE of the location parameter estimates ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$A_1$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$A_2$$\end{document} ), scale parameter estimates ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$B_1$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$B_2$$\end{document} ), and mixing proportion estimates ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$w_2$$\end{document} )Fig. 5. Simulation results, RMSE of the estimates of skewness g and kurtosis hFig. 6. Bias in estimated component means ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mu _{1}$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mu _{2}$$\end{document} ) in simulated the mixtures of normal, skew-normal, skew-t, and Tukey’s g- &-h distributions
As expected, the smallest bias was observed for the fitted models that were correctly specified. For the simulated mixtures of normal, none of the fitted models was correctly specified, but mixtures of skew-normal, skew-t, and parsimonious mixture of Tukey’s g- &-h distributions performed well approximating normal mixtures when sample size was sufficiently large. Notably, full mixtures of Tukey’s g- &-h distributions yielded smaller mean bias than mixtures of skew-t distributions when the true model was the mixture of skew-normal distributions. Similarly, full mixtures of Tukey’s g- &-h distributions yielded smaller mean bias than mixtures of skew-normal distributions when the true model was the mixture of skew-t distributions. Thus, unconstrained and/or parsimonious Tukey’s g- &-h mixtures may be expected to provide more robust estimates of the component means if the model is misspecified. Meanwhile, there were no notable differences between estimations methods in terms of goodness of fit as measured by the Cramér-von Mises distance between fitted and empirical distribution (results not shown).
Figure 7 compares the running time of function QuantileGH::QLMDe vs. function mixsmsn::smsn. mix (with options family = "Skew.normal" or family = "Skew.t"), with the help of R packages microbenchmark (Mersmann 2023) and parallel. One random sample was generated at each sample size of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$n=500$$\end{document} , 1000, 2000 and from each scenario in Fig. 3. Fourty (40) evaluations of each R function were performed using R 4.3.1 on a Mac mini with Apple M1 chip.
The running time for computing unconstrained QLMD estimator was around 5 s for \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$n=500$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$n=1000$$\end{document} , but increased to 5–8 s for \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$n=2000$$\end{document} . The time cost of skew-normal estimator was always lower than for the unconstrained QLMD estimator. Meanwhile is time cost of skew-t estimator was either similar (for \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$n=500$$\end{document} ) or higher (for \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$n=1000$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$n=2000$$\end{document} ) as compared to the time cost of QLMD estimator. Note that the number of parameters in Tukey’s g- &-h mixtures estimated using QLMD estimator is the same as the number of parameters in skew-t mixtures and larger than the number of parameters in skew-normal mixtures.Fig. 7. Time cost of QuantileGH::QLMDe vs. mixsmsn::smsn.mix (with options family = "Skew.normal"+ or family = "Skew.t"), based on one random sample generated at \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$n=500$$\end{document} , 1000, 2000 from each scenario in Fig. 3 and 40 evaluations
Application
Breast cancer data
We used the Tukey’s g- &-h mixture model to analyze Cyclin D1 expression levels in cancer cells of treatment-naive breast cancer patients. Cyclin D1 is a protein that belongs to the cyclin family. Cyclins function as regulators of cyclin-dependent kinase. Cyclin D1 over-expression is associated with poor prognosis in estrogen receptor-positive (ER+) breast cancer (Stendahl et al. 2004; Lundberg et al. 2019).
The study population included 690 ER+ patients that had outcome data available, did not have distant metastases at the time of surgery, and had Cyclin D1 CSI expression levels for at least 100 cancer cells in the TMA core IF-IHC image. The progression-free survival (PFS) was defined as the time from diagnosis to the evidence of local, regional or distant recurrence or death from the disease. The additional covariates available included age, race (white vs. non-white), ER status, HER2 status, histologic grade, stage, node status, tumor size ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$<2$$\end{document} cm, 2cm-5cm, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$>5$$\end{document} cm), and indicator variables for chemotherapy, radiation therapy, and hormone therapy. Patients were classified as “non-compliant" with hormone treatment if it was recommended but patients did not receive this treatment. Ninety three (93) progression events were observed in this study population, with a median follow-up of 89 months (range: 2–238 months).
Modeling Cyclin D1 distributions as g- &-h mixtures
The log-transformed Cyclin D1 expression levels in cancer cells, from each patient tissue core, were modeled using three versions of the 2-component Tukey’s g- &-h mixture,
- unconstrained with all possible 9 parameters;
- gh-parsimonious as described in Sect. 3.1
- optimal gh-parsimonious with \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$K_\text {max}=3$$\end{document} , as described in Sect. 3.2 The 2-component mixtures were used because for IF-IHC technology, it is plausible to assume that the CSI distribution is a mixture of a lower component representing the background noise and an upper component representing the actual signal. Mixtures with up to 3 components were considered to allow a possibility that the actual signal distribution is not unimodal.
Figure 8 shows an example of the resulting fitted mixtures along with the fitted 2-component normal mixture and kernel density estimator. The estimate of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$A_2$$\end{document} in fitted normal mixture is potentially downward biased as compared to \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$A_2$$\end{document} estimate in fitted Tukey’s g- &-h mixture.Fig. 8. Example of Tukey’s g- &-h and normal mixtures fitted to one sample tissue
In order to capture the signal in the subpopulations of cells with highest Cyclin D1 expression, we defined \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$A_\text {max}=\text {max}(A_1,A_2,A_3)$$\end{document} , if fitted distribution is a 3-component Tukey’s g- &-h mixture, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$A_\text {max}=\text {max}(A_1,A_2)$$\end{document} , if fitted distribution is a 2-component Tukey’s g- &-h mixture, and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$A_\text {max}=A_1$$\end{document} , if fitted distribution is a 1-component Tukey’s g- &-h mixture. The estimated patient-specific Cyclin D1 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$A_\text {max}$$\end{document} values were then evaluated as dichotomized predictor of PFS using a Cox proportional hazard model with bootstrap-based optimism correction procedure (Harrell et al. 1996; Steyerberg 2009). For multivariable Cox model, multiple imputations were used for missing values in clinicopathologic covariates for some patients (0.6% to 10% for all covariates). Forty (40) imputed datasets were created using the Multivariate Imputation by Chained Equations (MICE) algorithm with Fully Conditional Specification (van Stef and Groothuis-Oudshoorn 2011). The bootstrap-based optimism correction was applied to each imputed data set. Then results for all imputed data sets were averaged using the Rubin’s rule (Rubin 2004).
The following steps were performed for the bootstrap optimism correction. First, 200 bootstrap samples were drawn with replacement from each imputed data set with all patients. In each bootstrap sample, the survival tree model (R package rpart) was used to establish an objective data-driven optimal cutpoint for dichotomizing \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$A_\text {max}$$\end{document} . The cutpoint from the current bootstrap sample was used to compute the log hazard ratio for the univariate or multivariate Cox model in the current bootstrap sample (“Bootstrap performance") and in the main sample (“Test performance"). The optimism in hazard ratio estimation was computed as the difference between log hazard ratio for “Bootstrap performance" and for “Test performance". The optimism estimate was computed as the median optimism over 200 bootstrap samples. The cutpoint for dichotomizing \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$A_\text {max}$$\end{document} was also established in each imputed data set and its “apparent performance" was computed as the log hazard ratio for dichotomized \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$A_\text {max}$$\end{document} in the corresponding Cox model. Finally, the optimism-corrected performance estimates were computed by subtracting the optimism estimates from the “apparent performance" estimates (Steyerberg 2009).Table 2. Bias-adjusted hazard ratios (HR) with 95% confidence limits for dichotomized \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$A_\text {max}$$\end{document} as a predictor of PFS in univariate Cox modelsModel for CSI distributionsHR95%LCL95%UCLPUnconstrained 2-comp Tukey’s g- &-h mixture1.410.892.220.146gh-parsimonious 2-comp Tukey’s g- &-h mixture1.741.022.990.047Optimal gh-parsimonious Tukey’s g- &-h mixture1.781.182.690.008
Table 2 shows the bias-adjusted results from the univariate Cox models with dichotomized \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$A_\text {max}$$\end{document} as a predictor. Noticeably, the hazards ratio for dichotomized \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$A_\text {max}$$\end{document} is the highest based on fitted gh-parsimonious Tukey’s g- &-h mixture with the optimal number of components and the lowest and non-significant for \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$A_\text {max}=A_2$$\end{document} in full Tukey’s g- &-h mixture. The \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$A_\text {max}=A_2$$\end{document} in gh-parsimonious 2-comp Tukey’s g- &-h mixture produced slightly lower hazards ratio as compared to the parsimonious Tukey’s g- &-h mixture. Furthermore, in bias-adjusted multivariate Cox models, only dichotomized \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$A_\text {max}$$\end{document} from the optimal gh-parsimonious Tukey’s g- &-h mixture yielded significant predictor of PFS (hazards ratio 1.68, 95%CI: 1.09 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$-$$\end{document} 2.59, p=0.020). The effect of Cyclin D1 in multivariate Cox models is reduced as compared to the univariate Cox models due to association between Cyclin D1 over-expression and known risk factors such as larger tumor size and higher histologic grade (He et al. 2014).
Discussion
We developed statistical methods and software tools (R package QuantileGH) for modeling complex and possibly multi-modal distributions as finite Tukey’s g- &-h mixture. This approach allows accommodating mixtures that include components with variable degree of skewness and/or kurtosis. Our simulations assume 2-component mixtures to facilitate computations, but our methodology and R package allow fitting more than 2 components. We used 3-component mixtures for our application, but we have not evaluated the functionality of our package for fitting Tukey’s g- &-h mixture with four or more components because the number of parameters becomes excessive (up to 19 for four components). Also, it is not clear whether such mixtures of four or more components have interpretational advantages over the standard kernel density estimation.
We have developed a model selection algorithm that allows reducing the number of parameters in the mixture if the data does not support the need of all four Tukey’s g- &-h parameters for each component. Our simulation results indicate similar performance of full and parsimonious 2-component Tukey’s g- &-h mixture in terms of RMSE and mean bias, but the reduced model is usually desired for interpretation and higher efficiency. When applied to Cyclin D1 expression data, our model selection of parsimonious Tukey’s g- &-h mixture for each subject data provided improved results in the population analysis.
In this work, we considered univariate Tukey’s g- &-h mixtures, but multivariate extensions may be of interests for modeling multidimensional grossly non-Gaussian distributions. Multivariate finite mixtures have been previously considered, for example, with components modeled as multivariate skew-normal distributions (Cabral et al. 2012) or multivariate skew-t distributions (Frühwirth-Schnatter and Pyne 2010). As a fully flexible alternative, one can also consider finite mixtures of unspecified multivariate densities as components and estimate the mixture using kernel density estimators (Benaglia et al. 2009). A multivariate version of Tukey’s g- &-h distribution was developed by Field and Genton (2006) and can be used to define a finite mixture of multivariate Tukey’s g- &-h distributions.
In conclusion, the proposed finite mixture of Tukey’s g- &-h distributions model provides a new flexible statistical framework for accommodating multimodal distributions with variably skewed and heavy-tailed components often originating in biomedical applications, but our model could be also useful for econometrics applications.
Supplementary material
R-package for QLMD routine: R (R Core Team 2022) package QuantileGH, available at https://CRAN.R-project.org/package=QuantileGH, contains code to perform the QLMD estimation in the article.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Benaglia, T., Chauveau, D., Hunter, D.R., Young, D.: mixtools: an R package for analyzing finite mixture models. J. Stat. Softw. 32(6), 1–29 (2009). 10.18637/jss.v 032.i 06 · doi ↗
- 2Harrell, JR., Frank, E., Lee, Kerry L., Mark, Daniel B.: Multivariable prognostic models: Issues in developing models, evaluating assumptions and adequacy, and measuring and reducing errors. Statistics in Medicine 15(4), 361–387 (1996). 10.1002/(SICI)1097-0258(19960229)15:4361::AID-SIM 1683.0.CO;2-410.1002/(SICI)1097-0258(19960229)15:4<361::AID-SIM 168>3.0.CO;2-48668867 · doi ↗ · pubmed ↗
- 3Mersmann, O.: microbenchmark: Accurate Timing Functions. (2023). R package version 1.4.10. https://CRAN.R-project.org/package=microbenchmark
- 4R Core Team: R: a Language and Environment for Statistical Computing. R Foundation for Statistical Computing, Vienna, Austria (2022). R Foundation for Statistical Computing. https://www.R-project.org/
- 5Xu, X., Iglewicz, B., Chervoneva, I.: Robust estimation of the parameters of -and- distributions, with applications to outlier detection. Comput. Stat. Data Anal. 75, 66–80 (2014). 10.1016/j.csda.2014.01.00310.1016/j.csda.2014.01.003PMC 396171824665144 · doi ↗ · pubmed ↗