A graph-theoretic framework for integrating mobility data into mathematical epidemic models
Razvan G. Romanescu

TL;DR
This paper introduces a new method to improve epidemic models by integrating mobility data, allowing better tracking of disease spread based on real-world movement patterns.
Contribution
The paper proposes a novel framework that links epidemic transmission rates to mobility data, enhancing model accuracy for multi-wave outbreaks.
Findings
The model successfully adapts transmission rates to population mobility patterns.
Using Google Community Mobility Reports improves the fit of epidemic models to real-world data.
The approach is demonstrated effectively on the first four waves of the COVID-19 pandemic.
Abstract
Advances in modeling the spread of infectious diseases have allowed modellers to relax the homogeneous mixing assumption of traditional compartmental models. The recently introduced synthetic network model, which is an SIRS type model based on a non-linear transmission rate, effectively decouples the underlying population network structure from the epidemiological parameters of disease, and has been shown to produce superior fits to multi-wave epidemics. However, inference from case counts alone is generally problematic due to the partial unidentifiability between probability of person to person transmission and the average number of contacts per individual. An alternate source of data that can inform the network alone has the potential to improve overall modeling results. Aggregate cell phone mobility data, which record daily numbers of visits to points of interest, provide a proxy for…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
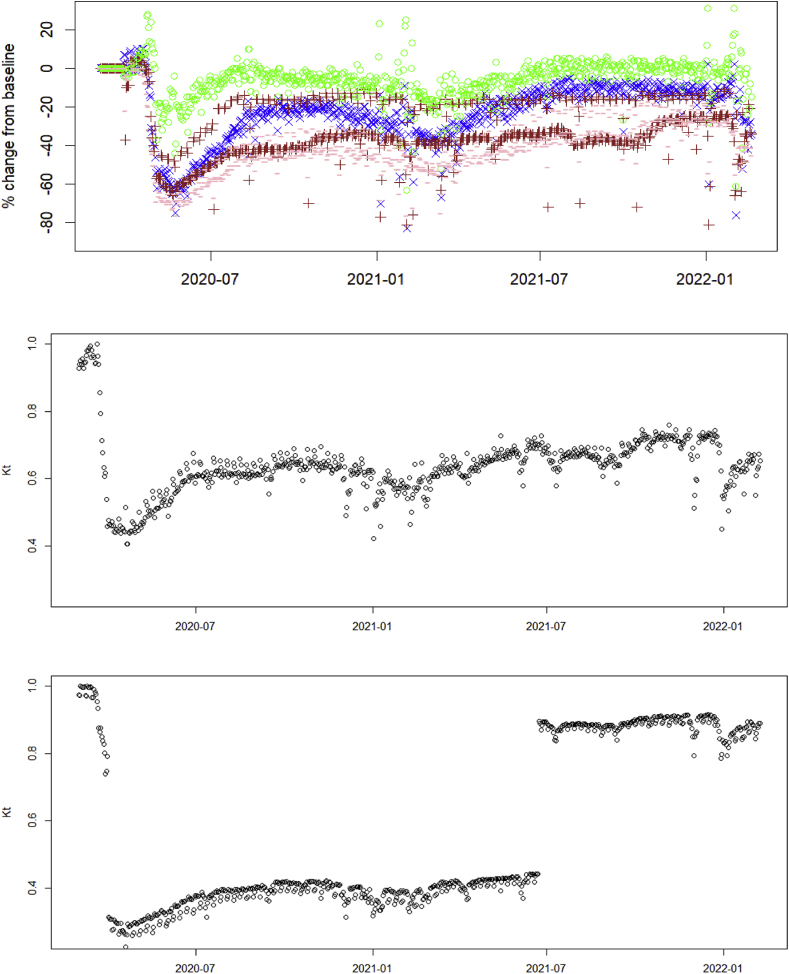 Figure 1
Figure 1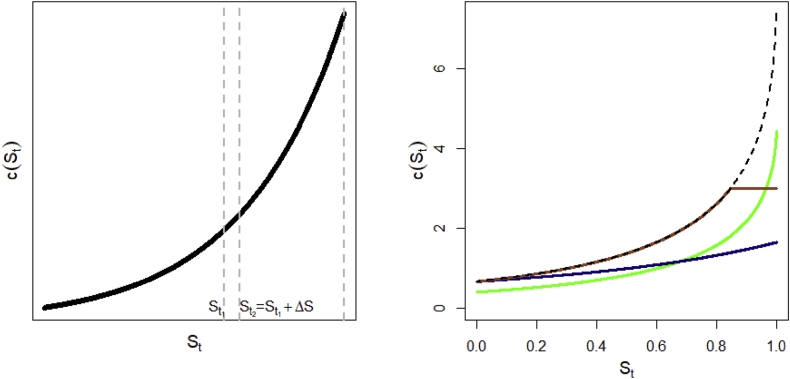 Figure 2
Figure 2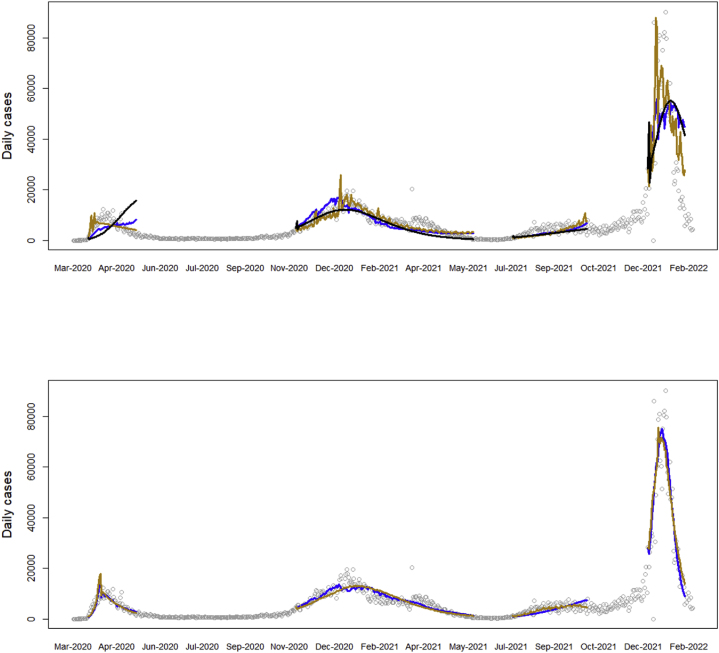 Figure 3
Figure 3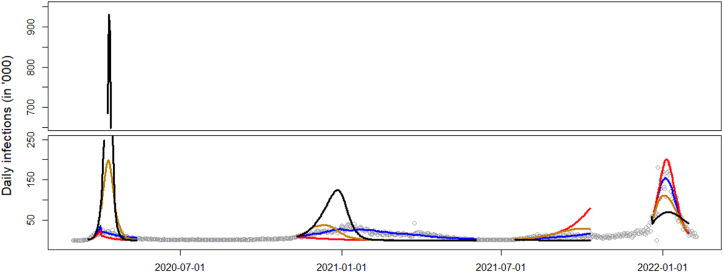 Figure 4
Figure 4Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsComplex Network Analysis Techniques · Human Mobility and Location-Based Analysis · COVID-19 epidemiological studies
Introduction
1
Mathematical infectious disease models typically produce one curve that describes the trajectory of an epidemic, based on a set of parameters. The model is fit to observed cases of infection, producing a best fitting curve, which is assumed to describe the overall epidemic progression in the past and (near) future. In reality, parameters governing transmission change, as individuals adapt to real or perceived risks of the circulating pathogen. Public health agencies introduce restrictions on mobility and access, aiming precisely to change relevant transmission parameters and contain the infection. As a result, datasets of observed infection counts are a realization of models changing in real time. One solution is to fit piecewise models according to known restrictions. This model building approach amounts to adding parameters and relying on the data to infer the best fitting values for different time segments of the epidemic (Romanescu et al., 2023; Wu et al., 2021). The shortcoming of this approach is that it relies on a single source of data, i.e., case counts, to infer changes in both the epidemic, as well as the social network processes. This can lead to confounding and identifiability problems, as changes in either process can lead to the same predicted case counts. For example, both a less infectious strain of the pathogen, or fewer social contacts will result in fewer observed cases of disease. It would be very desirable to have different types of data in addition to case counts, which can be used to identify one of these processes in isolation.
Recently, cell phone mobility data has emerged as a promising source of information to infer the contact network underlying disease transmission. The utility and far-reaching implications of using cell data to study human mobility on a large scale has been noted a decade ago in Becker et al. (2013), who used this data to describe the daily commute and travel patterns of the metropolitan populations of Los Angeles, San Francisco, and New York. A review of the different types of data that can be generated from mobile phones is given in Grantz et al. (2020). It becomes necessary to distinguish between granular versus aggregate mobility data sources. The focus of this paper will be the latter, although it is worth mentioning how highly granular data has been used in epidemic modeling. During the COVID-19 pandemic, spatial cell phone locations have been used to inform movement of individuals between points of interest and census block groups, in a bipartite graph with weighted edges (Chang et al., 2021). In general, dealing with the vast amounts of data available from granular sources is challenging and requires some form of aggregation or dimension reduction before this data becomes interpretable in a modeling setting. For instance, Levin et al. (2021) uses machine learning techniques to reduce mobility data to a small number of dimensions, which are then used to identify mobility patterns, subpopulations and correlations with COVID-19 cases.
Once the data has been compacted into a (multivariate) time series format, either by oneself or a data provider, the problem of integration into classical compartmental models of infectious disease becomes feasible. Google Community Mobility Reports (GMR) provide a single time series of changes in aggregate mobility volume for one location type (Aktay et al., 2020). There have been a few attempts in the literature so far to assimilate this data, often using mobility to explain changes in the efective reproduction number ( ). For instance, Li et al. (2021) have used the different component time series of the GMR in a multivariate log-linear regression to predict changes in at UK local authorities. Sulyok and Walker (2020) have used the GMR data within generalised additive models to explain case incidence. A more mechanistic approach was taken by Vanni et al. (2021) who derive based on a chemical representation of infectious diseases, as two types of molecules colliding in a solution; importantly, the contact rate increases linearly with movement speed of individuals, and this is informed by GMR. The approach we take in this paper similarly models in terms of the GMR data, with the crucial difference that we link both the transmission rate in the epidemic model, as well as the total volume of connections given by GMR, to the underlying network architecture of individuals. The mechanism is that reductions in mobility make the network more sparse, which affects the transmission rate in a (possibly) nonlinear fashion. A related problem to data integration is how mathematical models handle changes in transmission rates, with the most common approach being a proportional shift (see e.g., Anderson et al., 2020). Our approach is flexible in this regard, and we can accommodate common and custom changes to the transmission rate, which can be used to evaluate different reduction policies.
In the rest of the paper, we first review an SIRS epidemiological model based on a non-linear transmission function, in Section 2. We then derive the graph-theoretic link between the transmission function, which can also be interpreted as the average contacts of the infectious set, and mobility data, which acts as a proxy for the total number of edges in the population network. The two sources of data – namely case counts and aggregate mobility, – then inform an augmented epidemic model whose transmission rate changes in response to mobility volumes, depending on which individuals are impacted more by mobility restrictions. We fit this model to COVID-19 data from New York in Section 3 to illustrate how including GMR data helps inference. We conclude with a discussion and recommendations for future research and data collection in Section 4.
Methods
2
Epidemiological model
2.1
The epidemic model we use follows the synthetic network model, a discretized ODE-type model of transmission in the susceptible-infected-removed-susceptible (SIRS) setting. This model has been introduced elsewhere (Romanescu et al., 2023), and is summarized in this section. The distinguishing feature of this framework is that it models daily incidence ( ), as opposed to prevalence ( ), via the effective reproduction number ( ). Let be the probability mass function of the time (in days) between a primary and secondary infection, i.e., the generation interval. Then we can estimate incidence at time as (Abbott et al., 2020; Nishiura & Chowell, 2009)
where is the maximum range of the generation interval. can be decomposed, as per standard theory, into , where is the person to person probability of transmission given that a contact exists; is the fraction of all nodes that are still susceptible; and is the average number of contacts of infectious individuals at time , less one (the previous infector is excluded). The model additionally assumes that where is a decreasing function in the SIR case, meaning that the average contact rate of currently active infectors is a one-to-one function of . This relationship emerges in a number of population structures, for instance in well-mixed networks (as discussed in the next subsection); or in non-network models of randomly-mixing individuals with heterogeneous susceptibility (Novozhilov, 2008). The assumption of a well-mixed population (not to be confused with a homogeneous population) is important, so this model may not work well in a structured population, such as loosely-connected clusters (as may be the case in a rural setting, for instance). Thus, is computed as:
This is used to sequentially compute from Equation (1), then update the susceptible fraction as
where is the total population size and is the underreporting rate, defined as the fraction of reported cases to actual infections.
An essential advantage of factorization (2) is that it not only separates the effect of the pathogen ( ) from the effect of the transmission network, but also decouples potential infectious contacts into an epidemic state variable ( ), and a component that only reflects network architecture (function ). This will be important for the rest of this paper because we can model changes in the social network due to factors exogenous to disease spread, via shifts in curve .
Among the choices for contact rate function given in Romanescu et al. (2023), we select , a model adapted from Granich et al. (2009), where , , and are parameters estimable from data. This was shown in our previous work to outperform the mass action model (in which ) by a wide margin in terms of quality of fit to data. Note that and are only identifiable as a product and not individually, and we will denote the estimable function by . For clarity of exposition, we will be using the tilde notation throughout the paper to indicate the estimable version of a variable or function.
In the SIRS case, the dynamics of transmission can be approximated (Romanescu et al., 2023) via an adjusted . Assume that a fraction of infected individuals lose their immunity to the pathogen at the beginning of each new wave. Let and represent the overall fraction at the beginning of the current epidemic wave, and at the end of the previous wave, respectively, such that . We use the following weighted contact rate in each subsequent wave of the epidemic:
where the weights and sum to . Note that and need to be reset at the beginning of each new wave. The effective reproductive number is then computed as , and is updated in the same way as in the SIR case. Using a weighted contact rate is motivated by the fact that newly susceptible individuals (moving from R → S) tend to have more contacts compared to those left susceptible at the end of the previous wave, as they have gotten infected before. The choice of weights reflects the fact that the overall degree distribution of susceptibles at the start of a new wave is a mixture of distributions between the degree of those left at the end of the previous wave, and the original degree distribution (in the fully susceptible population), with weights equal to and , respectively.
Finally, each wave beyond the first is allowed a different person-to-person transmissibility via the relative change parameters , to reflect changing infectiousness in the pathogen strains. Thus, transmissibilities in each wave are etc.
Modeling the reduction in social connectivity as a result of public health orders
2.2
Link between total contacts in the population and the contact rate function c(t)
2.2.1
In the epidemic model described above, it is possible to recover the total number of contacts in the population from the contact rate function of the infectious set. Assume a disease with that progresses in discrete, non-overlapping generations in the SIR framework, and that all infectious individuals recover at the end of their generation. Formally, let the population be represented by a fixed, connected graph with edge set and vertex set , with cardinalities and . Let be the set of infectious vertices (individuals) at time (or generation) , and be the set of all edges touching individuals in . We denote the susceptible set at time to be . The numbers of elements in the random sets , and are random variables , and , respectively. According to the definition in the previous subsection, , assuming that individuals in are not themselves sharing common edges. We further assume, as above, that there exists a function such that . In other words, that depends only on cumulative infections up to time , and not on the pathways of infection; formally, that is independent of . Such a function has been shown to describe the mean-field behavior of diffusion processes over first order networks, i.e. networks characterized by degree distribution alone, with no higher order structure (Newman, 2002; Romanescu & Deardon, 2017; Volz, 2008). The relationship also seems to hold empirically in networks with second order structure, or joint distribution of degrees of connected individuals, as illustrated in simulation studies (Romanescu, 2024), though this has not been formally proved yet.
Thus, we have, by definition, that , for , where is the last time that an infection is recorded. Adding all these equations side by side, we get
where we used the notation (in the rest of the paper except for this section, will continue to denote the fraction of susceptibles, as their full number will not be needed again).
As this is a connected graph, a probability of per-edge infection necessarily implies that all individuals in the population will become infected by time . Thus, we have , , and also . A few interesting observations can be made about equation (5). On the right hand side, we get a constant, which depends only on the shape of function on the interval . For the sum on the left-hand side, notice that every edge in the graph is counted in exactly two consecutive sets, as per our setup: once when the first end of the edge gets infected, and once at the next time point, when infection passes through the edge to the other end. Thus, the left-hand side is also constant, as . Finally, notice that neither end of Equation (5) depends on the choice of initial infections set , although the terms in the middle (such as ) are random variables.
It will be more convenient for the future to speak in terms of the average degree ( ) of the graph instead of the total number of edges. This represents the mean number of contacts (degree) of a random individual in the population, and obeys the identity ; thus, we can write . Substituting in (5), we conclude that
Notice that this formula is a feature of the network, and does not depend on the values of the epidemiologic parameters. Equation (6) is important because we can estimate from non-epidemic sources (such as mobility data), and infer how the contact rate changes as a direct result of observed changes in the transmission network. While traditional epidemic models relying on infection data alone cannot easily separate from the transmissibility , which confounds it, equation (6) provides a way to tease out the magnitude of independently of .
Modeling changes over time in the shape of the contact rate function
2.2.2
As our investigation focuses on changes in contact volumes over time, we need to model ways in which the contact rate changes on a daily basis. Firstly, quantities and should be viewed as time-dependent, because they change in real-time as the network changes (we use , and, by abuse of notation, to refer to the current state of the non-epidemiologic network on day ). Secondly, equation (6) relates to the area under , at each point in time; but we also need to postulate how the shape of is allowed to change with . Indeed, reducing the contact rate is a crucial objective of public health policy and comes in the form of social restrictions, such as lockdowns and capacity limits. Being able to correctly model is thus paramount for evaluating the effectiveness of control measures. As discussed in the introduction, there are a few approaches in the literature on how , or the transmission rate, might change, although by far the most common is via multiplication by a factor. This approach is used in modeling, often by default, because epidemic data alone does not usually permit one to distinguish between a drop in transmissibility of the pathogen, and a restriction on individual contacts; thus, there is rarely a basis for a more complex form. However, working specifically with network models, we have shown that a “tapered” approach might make more sense when there is heterogeneity in contacts (Romanescu et al., 2023). This consists of adding an exponential tail to the probability mass function of individual contacts. More exactly, if we let and denote the fractions of individuals in the original population with and contacts ( ), then, under restrictions, the new fractions and satisfy , where controls the severity of restrictions on the network. This assumption can be shown to imply the tapered scenario in Table 1, under a first order network model. This scenario can be argued to be more realistic than a scale reduction, at least in certain situations. Finally, scenario 3 consists of capping average connections at a certain level. While this is not necessarily a realistic representation of past containment efforts, we would expect it to be the most effective among the three scenarios, if it could be implemented. In each scenario in Table 1, the time-dependent variable quantifies the strength of restriction on the original (unrestricted) network. Fig. 1 graphically illustrates the shift in for each scenario. While this is by no means an exhaustive list, it does capture a range of possibilities, each having different implications for the total burden of disease, as will be illustrated in the data application.Table 1. Scenarios of reduction in contact rate function.Table 1. ScenarioChange relative to unconstrained Individual level impact1. Scaled down Individuals “equally” impacted, i.e., everyone loses the same percentage of connections2. Tapered Highly connected individuals disproportionately restricted compared to least connected3. Top off Individuals affected tend to have connections above a certain level.Fig. 1(Left) Contact rate of the infectious set during an epidemic, as a function of the remaining susceptible fraction. The area of a slice under curve between and gives the average number of contacts (less 1) of typical infected individuals between epidemic ages and (Right) Changes in the original curve (dashed line) according to the scenario: downscaled (green), tapered (blue), top off (sepia).Fig. 1
Pre-processing Google Community Mobility Reports data
2.3
The Google Community Mobility Reports (GMR) were published between February 2020 and October 2022 and report the change in cell phone traffic volume at different categories of locations, including: work, retail and recreation, parks, public transit, and residential. Changes are reported as percentages compared to a reference baseline defined as the median volume for that day of the week, over a period of 5 weeks between Jan 3–Feb 6, 2020 (Google LLC). Numbers are aggregated to preserve confidentiality, and no absolute values are given.
We pre-process the Community Mobility Reports to infer the average number of hours spent in various location categories, accounting for differences between weekdays and weekends. From the American Time Use Survey (ATUS) we estimate the daily time spent in each mobility category (Table A1 in the Appendix). A similar approach was taken in Gutiérrez-Jara et al. (2022), who produce detailed simulations to show how changes to daily patterns of activity might affect epidemic spread. Since the GMR data are given as percentage changes relative to the same day of the week during Feb 2020–March 2020, we multiply the relative fraction by the number of hours spent in each category from ATUS to obtain the estimated actual hours spent in the activity. We do this separately for weekends and weekdays. In the end, for each category apart from residences and parks, i.e., for retail & recreation, grocery & pharmacy, transit stations, and workplaces, we now have a time series of hours spent at that location on each day, which we jointly denote as vector , for each day .
Joint inference from epidemic and mobility data
2.4
General setup in the SIR case
2.4.1
In what follows, we will let the Mobility Reports inform restriction level on each day. To calibrate we equate the number of total contacts lost (as the difference in area under the curves and ) with the reduction in cell phone traffic volume.
Assume that individuals establish epidemiologically relevant contacts at rates per hour spent in each category, and constant rate contacts at home. Thus, if contacts were established uniformly and individuals were homogeneous, the average number of contacts formed on day is , where we assume that contacts at home are independent of time spent. A similar regression approach was taken in García-Cremades et al. (2021), who have also pointed out the non-linearity and multicollinearity present in the data, which violate the assumption of the regression model. To alleviate the multicollinearity issue, we de-trend each variable by first computing the trend as the 7 day moving average of the sum of ‘s in the four categories noted above, then subtracting a scaled trend from each variable as
for , such that each is de-trended and centered. We write the average number of contacts now as , where and we allow an extra parameter for trend in .
Non-linearity in translating between cell phone traffic and number of infectious contacts formed should not be surprising. Just as the epidemiologic model is non-linear, it is possible, even likely, that equal, incremental changes in overall mobility volume may not result in equal increments of contacts gained. For example, we may postulate that a reduction in cell phone traffic from 100 to 95% is driven by individuals who willingly choose to reduce their mobility in response to a circulating pathogen (perhaps because they are more proactive, or risk-averse), whereas a reduction in volume from 55 to 50% is more likely driven by individuals who take a “wait and see” approach, or who were constrained by law. If the number of contacts formed correlates with behavioral pattern, then the relationship will be non-linear. To accommodate this, we define the mobility metric as , where is the standard logistic curve. During fitting, will act as a baseline level that determines where the points fall on the logistic curve, i.e., whether the relationship is concave or convex; as such, will not be interpretable as number of contacts formed at home.
By identifying in Equation (6), we can write:
or, using the estimable function ,
where and . Note how blends in naturally with other unknowns, and will not require separate estimation. We further denoted the right hand side by , which will be the estimable mobility metric, in the absence of information on . Parameters and will be chosen as a function of curve parameters in order to ensure that Equation (7) is solvable for at each time point , as detailed under ‘Model implementation details’ in the Appendix. The parameters will be estimated as part of the model fit.
Fitting the full model proceeds in two steps. In the first, integral equation (7) is solved for as a function of the other model parameters and of vector , for a specific reduction scenario in Table 1. The solution gives the amount of reduction in contact rate consistent with the observed mobility for day . In the second step, all free model parameters are estimated via maximum likelihood, as detailed in the Appendix.
Solution for scale down scenario
2.4.2
In this case, and Equation (7) becomes . We first solve for as . Then, under restrictions, the epidemiologic model (2) becomes
Solution for tapered scenario
2.4.3
In this case we have (see Appendix for derivation). Equation (7) thus becomes
This requires a numerical solution for , though the integral can be expressed via special functions for our choice of , hence simplifying the calculation (see Appendix for details). Denoting the solution of (9), the restricted epidemiologic model becomes .
Solution for top off scenario
2.4.4
Here, is the level of the susceptible fraction from which the contact rate tops off. Equation (7) leads to
Solving (10) numerically for , the effective reproductive number becomes .
Inference in the SIRS case
2.4.5
In the SIRS case, Equation (7) does not change, as it is independent of infection or reinfection status. So the solution for each time is the same as in the SIR case. However, under reinfection, changes during subsequent waves according to formula (4). Thus, when computing as a function of and , we will be using the weighted which accounts for reinfections. Note, in particular, in Equation (8), the middle term uses as in the SIR case (as this is part of ), but the SIRS version in the last term.
Results
3
We illustrate this framework on the time series of COVID-19 cases from New York State, over the period March 2020–February 2022, which is comprised of four visible waves. The dataset, including the exact definition of waves, is described elsewhere (Romanescu et al., 2023). This population was chosen because our previous research found evidence of heterogeneity in contacts, specifically a power law degree distribution (Romanescu & Deardon, 2017), which makes the contact rate very different from a flat curve. Being a highly urban area, this satisfies the assumption of a well-mixed population, which is required for this type of epidemic model. Other features that makes this dataset a good example include the fact that all four waves of COVID-19 are well-represented (compared to some other cities where the first wave is absent), and there is an extensive subway system, leading us to expect that the Traffic category in GMR will be more prominent in transmission, compared to cities with a less developed public transit infrastructure.
Data obtained from Google Community Mobility Reports for the corresponding period is preprocessed as described in Methods. Other epidemiological parameters (including the underreporting rate ) are taken from Romanescu et al. (2023) and references therein. We further consider an offset vector giving the delay, for each day, between GMR and COVID reported cases, which is computed as: . Here, incubation periods are specific for each strain (Wu et al., 2022): for wildtype 6.65 days, for alpha variant 5.00 days, for delta 4.41 and for omicron 3.42 days. Reporting delay of COVID cases is estimated to be 3.3 days during the summer of 2020 (Harris, 2022), while mobility data is assumed to have a delay of 2 days (Aktay et al., 2020).
Model fit to the NY dataset
3.1
We first fit the assumed curve without any restrictions to the entire dataset – this fit does not use the mobility data. We then fit the model including the GMR data, for each of the first two reduction scenarios in Table 1. Fig. 2 shows the fitted curves, and parameter estimates are given in Table 2.Fig. 2. Fit of the curve model to the NY case data under different reduction scenarios: (upper) no reduction (black), downscaled (blue), tapered (gold). (Lower) downscaled (blue), and tapered scenarios (gold), allowing for an extra parameter ( ) in .Fig. 2. Table 2Parameter estimates of the fits and negative log likelihood values for each assumed reduction scenario.Table 2. ParametersNo reductionScaled downTaperedScaled down (incl. )Tapered (incl. ) 20 (−)20 (−)20 (−)3.09 (0.35)19.99 (0.65) 3.21 (0.06)2.38 (0.13)3.04 (0.04)300 (−)3.58 (0.01) 0.035 (0.004)0.026 (0.006)0.650 (0.191)4.527 (0.111)0.179 (0.005)loss of immunity rate 0.057 (0.018)0.087 (0.030)0 (−)0.435 (0.028)1.00 (0.012)relative variant transmissibility for waves 2+ ( ) 1.11 (0.04)0.90 (0.03)1.02 (0.01)0.98 (0.06)1.30 (0.02) 1.35 (0.06)0.98 (0.06)1.11 (0.03)0.52 (0.02)0.40 (0.01) 1.77 (0.10)1.33 (0.10)1.41 (0.02)0.75 (0.03)0.65 (0.01)activity contact rates –−10.0 (−)−10.0 (−)0.15 (1.18)−10.0 (−) –0.27 (0.06)1.44 (0.08)0.20 (0.08)0.02 (0.002) –−0.02 (0.31)5.73 (0.57)0.46 (0.46)−0.37 (−) –0.06 (0.07)2.88 (0.32)0.11 (0.13)−0.14 (−) –−0.22 (0.56)3.92 (0.18)0.02 (0.71)1.29 (−) –4.80 (4.00)0.71 (0.25)−5.83 (5.37)−0.01 (0.03) –––1.64 (0.72)1.15 (0.02)Variance parameter ( )8821.30 (711.62)5885.91 (469.99)3947.20 (300.18)2178.65 (162.68)2189.57 (161.52) 4124.74083.34010.73894.53895.6# of parameters814141515AIC8265.48194.68049.47819.07821.2
Notice from the likelihood and AIC values in Table 2 that including the GMR data leads to a significant improvement in fit. In particular, the trend component is highly significant across the different model setups. Still, the quality of fits is not entirely satisfactory, as waves 1 and 3 are only partially fitted, and the peak of wave 4 is underestimated. From our previous work on this data, we have obtained superior fits by introducing different reduction parameters to fit different levels of public health restrictions over the time periods they were known to be in effect. Ideally, the severity of public health restrictions on mobility should be reflected in a reduction in GMR aggregate indices over the duration of those restrictions. We can test the sensitivity of GMR as a proxy of epidemiologically-relevant mobility by allowing for a single, parallel drop in mobility index during the times of public health restrictions (2020-Mar-22 to 2021-Jun-14). We model this drop by parameter such that . We adjust the start and end dates of restriction measures to reflect a delay of , which is the time it would take to begin seeing an effect in infection counts. Thus, estimates any extra effects from public health orders not captured by the Google data. These are likely changes in behavior other than isolation (e.g., social distancing in public places).
We fit the model including using the same two reduction scenarios. Fig. 2 shows a much improved fit to observed case data with the additional shift. This is confirmed quantitatively by the AIC values. For better illustration we have plotted the implied values of restriction level in the downscaled scenario, which can be interpreted as the fraction of current mobility compared to pre-pandemic times (Fig. A1 in the Appendix). Notice that even though the GMR data generally shows lower activity during public health restrictions, it fails to capture the full extent of the reduction in epidemiological contacts, as implied by the highly significant effect of . The change in level under the tapered scenario is qualitatively similar (results not shown). One explanation of why the mobility metric may not be epidemiologically sensitive enough might be that categories defined by Google are too broad, and are not stratified by infection potential. For instance, the Retail and Recreation category includes bars and restaurants, where individuals stay in close contact for extended periods and engage in casual conversation, as well as large retail stores (e.g., Walmart), which typically do not offer nearly the same opportunity to transmit infection. Public health orders specifically targeted venues in the former category with closures, while allowing those in the latter to stay open (for good reason). It is entirely conceivable that individuals changed their behavior in response to such restrictions by going shopping more instead of going to restaurants. This change is likely to significantly impact case numbers, however may not have much effect on the GMR, which counts visits to both types of venues the same.
Categories comparison
3.2
Next, we wish to better understand how changes in activity levels for various categories affect epidemic spread. Firstly, based on our model formulation, the components of are interpretable as the effect of an extra hour spent in that category on the average number of connections formed on that day. However, care should be taken in interpretation due to the non-linearity of , as adding time increments to a category will not result in equal increments in contacts formed. This means that such inferences are only accurate around the best fit point in the parameter space. Looking at the estimates in Table 2, there is no consistency between the different model fits, and, in every case but one, the estimates are not significant, most likely due to multicollinearity among the GMR time series. For the best fitting model in Table 2, a test of versus not all are equal, is not significant, meaning that, at least under scenario 1, the trend term captures the full effect of the mobility data (recall that represents the total time spent in any of the activity categories mentioned). For the fit under scenario 2 without , surprisingly, all activities show statistically significant parameters. These results are appealing because they are in line with what we may expect intuitively: for instance, more contacts are formed spending time in entertainment and retail versus work; as well, spending time in transit results in more contacts than doing grocery shopping. These results to some degree corroborate the findings of Li et al. (2021), who conclude that increased visits to retail and recreation, and workplaces increase substantially more than visits to grocery and pharmacy, while spending more time at home or in parks decreases . Arguably, the latter may simply be a result of having less time to spend in the contact-generating activities. They also find that increased volumes in transit stations result in even higher increases in , but only in major cities, which is in line with our results.
Pursuing this line of inquiry further, we can estimate the impact of each category on the total epidemic burden. To assess this, we increase each component category of by (or 30 minutes) at all time steps, and compute the extra number of infections compared to the original fit. From Table 3 we see that the most time-efficient activities in terms of generating infections are retail and recreation (a.k.a. entertainment), followed by transit stations and work. It is important to use caution, however, when interpreting these results, as the same parameters are not supported by the better fitting model including . Thus, the significant relationships observed above may be due to overfitting, and hence the results in Table 3 should be viewed as exploratory.Table 3. Sensitivity analysis of total infections generated by an extra 30 min spent in each category. Original fit is under the tapered scenario in Table 2, which has 10,168,410 infections.Table 3. Parallel upward shift inTotal infections infections% changeTrend10,758,758590,3485.8Entertainment12,781,4422,613,03225.7Work11,419,8101,251,40012.3Transit11,997,7241,829,31418.0Grocery10,453,118284,7082.8
Comparison between reduction scenarios
3.3
An interesting observation from the best fitting models under scenarios 1 and 2 is that we get essentially the same quality of fit from very different model settings. One could easily (and incorrectly) conclude that there is no difference between the reduction scenarios. In order to compare the effectiveness of the different reduction scenarios for curve at stopping epidemic spread, we need to keep both the epidemic model, as well as the mobility level , fixed, and project what the infection curve would look like, if we only changed the reduction mechanism. In other words, we use the same overall daily loss of contacts regardless of scenario, and solve for the corresponding levels under each scenario separately. Then we compute and compare the curves starting from the same epidemiological parameters, but using the time series that was calculated under each of the three scenarios. The fixed parameter values are based on the scaled down scenario including (this had the best fit in Table 2), with the difference that we exclude the four category ’s, as they are not significant. The projected curves for each scenario are shown in Fig. 3, along with a curve for no reduction. As can be seen, all scenarios manage to curb the pandemic, which would otherwise peak at an extreme level during the first wave. However, the epidemic trajectories are quite different for each. To get a sense of their stopping power, in Table 4 we cumulate infections across all waves. We do the same starting from the tapered fit, as it is qualitatively similar, but implies a very different epidemiological model (in particular, a large fitted results in more reinfections and overall higher infected counts). In both assumed models, scenario 3 results in the highest reduction in cases. This is not surprising, as targeting the most connected individuals removes the most edges from the underlying network.Fig. 3. Daily projected number of infections under the three scenarios, matched for daily contact volumes: downscaled (blue), tapered (gold), top off (red). For reference, the infection curve if no precautions were taken (i.e., no change in mobility from baseline) is given in black.Fig. 3. Table 4Projected infections under each reduction scenario, starting from a common epidemiological model and assuming the same overall mobility volumes.Table 4. Assumed modelInfections without change in mobilityInfections assuming mobility effects in scenario 1Infections assuming mobility effects in scenario 2Infections assuming mobility effects in scenario 3Scaled down fit15,841,33910,003,99410,828,3678,754,721Tapered fit25,656,80918,503,50910,097,9845,861,201
Discussion
4
This paper presented a framework for integrating aggregate cell phone mobility data into a model of infectious disease spread. The most important contribution to the field is identifying the relationship between total contacts, or edges, in the population network, and the contact rate in the epidemiologic transmission model. Estimating the former from aggregate cell phone volume in the population allows us to infer how the latter fluctuates in response to changing public behavior and policies. The paper also demonstrated how different scenarios for reduction in average number of connections could have a profound impact on reducing the total burden of disease. The potential of this research is quite enticing; for instance, it allows public health practitioners to answer questions such as “if we were to mandate working from home for two days a week, what would the impact be on spread?” With a well-calibrated model, this can be predicted by simply reducing by and predicting the new epidemic trajectory with all other variables kept at current levels. The ability to estimate how the contact rate curve changes in response to policy can be invaluable in designing future interventions.
The availability of cell phone data, which can inform aggregate network statistics, is welcome in infectious disease modeling. However, there is room for growth in both the quality of this data and in how it is modeled. Starting with the data itself, the Google Community Mobility Reports were introduced as another one of the Google suite of products with the general aim of providing “insights into changes in mobility patterns” (Aktay et al., 2020). There is no indication that this was intended to be used by epidemiologists, so we can assume that infectious disease modeling was not the intended application. However, a mobility metric based on cell phone data is certainly a much needed tool for modellers in epidemiology, as this paper and others (e.g., Chang et al., 2021) have shown. A couple of recommendations for any future iterations of GMR to make them more useful as research tools are as follows: 1) keep a single baseline, as opposed to changing the baseline according to the day of the week. Not having an explicit baseline for each day introduces unnecessary variability in the dataset (in the present paper, we made the assumption that all weekdays are alike, as are Saturday and Sunday). 2) Refine the categories to be more relevant to the spread of infection; in particular, points of interest that were specifically targeted by public health orders, such as dining and entertainment venues, should be reported separately from other retail and recreation categories. 3) An important limitation of this data is that it does not give absolute magnitudes of cell phone traffic, but only relative volumes. This is a barrier that prevents the complete identification of the network effect from the pathogen transmissibility effect.
In addition to improvements in quality of the input data, future efforts will need to focus on how to model and interpret mobility data. Unless working with very granular spatial data, which requires large, intractable models, aggregate mobility data will necessarily collapse different behavioural categories of individuals into single metrics. As a result, having insight into such patterns at the individual and population levels will be necessary to make the best use of this data. For example, there are two noticeable patterns in the implied restriction level in Fig. 4: 1) a general drop compared to pre-pandemic levels of more than 20%, from which the population does not recover; and 2) three lows corresponding roughly to the three largest COVID-19 waves. There are a couple of insights here: first, that there is likely a risk-averse segment of the population whose activity does not bounce back, even after official restrictions have been lifted. Second, given that the data strongly favors a large reduction in during the mandated orders, as shown by our fits including , we would speculate that these three visible dips had a greater impact than can be captured on a linear or logistic scale. Perhaps two behaviorally different segments of the population – one segment that takes drastic measures to isolate even when the risk is low, and another one that responds only when the risk is high, or when forced to –, should be modeled separately. In any case, more research is needed to understand how individual compliance or risk aversion can be used to inform infectious disease models.
Declaration of competing interest
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
Fig. 4(top) Percentage daily changes in mobility from Google for categories: retail and recreation (x), workplaces (+), grocery & pharmacy (o), and transit stations (−). Restriction level implied by the fitted model under the downscaled scenario: (middle) excluding in the fit; (lower) including .Fig. 4
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Abbott S.Hellewell J.Thompson R.N.Sherratt K.Gibbs H.P.Bosse N.I.…Funk S.Estimating the time-varying reproduction number of SARS-Co V-2 using national and subnational case counts Wellcome Open Research 51122020112
- 2Aktay A.Bavadekar S.Cossoul G.Davis J.Desfontaines D.Fabrikant A.Gabrilovich E.Gadepalli K.Gipson B.Guevara M.Kamath C.Kansal M.Lange A.Mandayam C.Oplinger A.Pluntke C.Roessler T.Schlosberg A.Shekel T.…Wilson R.J.Google COVID-19 community mobility reports: Anonymization process description (version 1.1)(ar Xiv:2004.04145). ar Xiv 2020 http://arxiv.org/abs/2004.04145
- 3Anderson S.C.Edwards A.M.Yerlanov M.Mulberry N.Stockdale J.E.Iyaniwura S.A.Falcao R.C.Otterstatter M.C.Irvine M.A.Janjua N.Z.Coombs D.Colijn C.Quantifying the impact of COVID-19 control measures using a Bayesian model of physical distancing P Lo S Computational Biology 16122020 e 100827410.1371/journal.pcbi.1008274 PMC 773816133270633 · doi ↗ · pubmed ↗
- 4American time use survey (ATUS)https://www.bls.gov/tus/#data
- 5Becker R.Cáceres R.Hanson K.Isaacman S.Loh J.M.Martonosi M.Rowland J.Urbanek S.Varshavsky A.Volinsky C.Human mobility characterization from cellular network data Communications of the ACM 5612013748210.1145/2398356.2398375 · doi ↗
- 6Chang S.Pierson E.Koh P.W.Gerardin J.Redbird B.Grusky D.Leskovec J.Mobility network models of COVID-19 explain inequities and inform reopening Nature 58978402021828710.1038/s 41586-020-2923-333171481 · doi ↗ · pubmed ↗
- 7García-Cremades S.Morales-García J.Hernández-Sanjaime R.Martínez-España R.Bueno-Crespo A.Hernández-Orallo E.…Cecilia J.M.Improving prediction of COVID-19 evolution by fusing epidemiological and mobility data Scientific Reports 1112021151733431245510.1038/s 41598-021-94696-2PMC 8313557 · doi ↗ · pubmed ↗
- 8Google LLC Google COVID-19 Community Mobility Reports Accessed: 22 November 2022 https://www.google.com/covid 19/mobility/