Simultaneous Speech and Eating Behavior Recognition Using Data Augmentation and Two-Stage Fine-Tuning
Toshihiro Tsukagoshi, Masafumi Nishida, Masafumi Nishimura

TL;DR
This paper introduces a new method to recognize both speech and eating behaviors at the same time, using data augmentation and two-stage fine-tuning to improve accuracy in health monitoring.
Contribution
The novel approach combines synthetic data augmentation with two-stage fine-tuning for simultaneous speech and eating behavior recognition.
Findings
The method achieves an F1 score of 0.918 for chewing detection and 0.926 for swallowing detection.
Speech recognition accuracy is maintained while improving eating behavior detection performance.
Abstract
Speaking and eating are essential components of health management. To enable the daily monitoring of these behaviors, systems capable of simultaneously recognizing speech and eating behaviors are required. However, due to the distinct acoustic and contextual characteristics of these two domains, achieving high-precision integrated recognition remains underexplored. In this study, we propose a method that combines data augmentation through synthetic data creation with a two-stage fine-tuning approach tailored to the complexity of domain adaptation. By concatenating speech and eating sounds of varying lengths and sequences, we generated training data that mimic real-world environments where speech and eating behaviors co-exist. Additionally, efficient model adaptation was achieved through two-stage fine-tuning of the self-supervised learning model. The experimental evaluations demonstrate…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
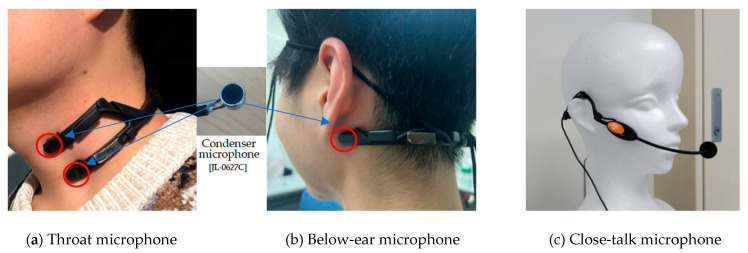 Figure 1
Figure 1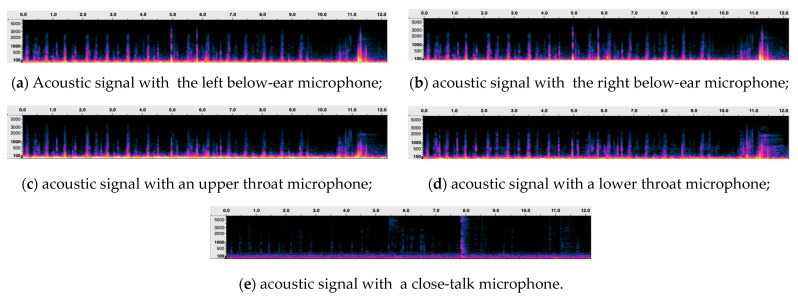 Figure 2
Figure 2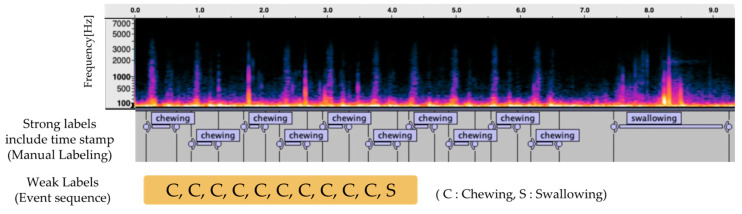 Figure 3
Figure 3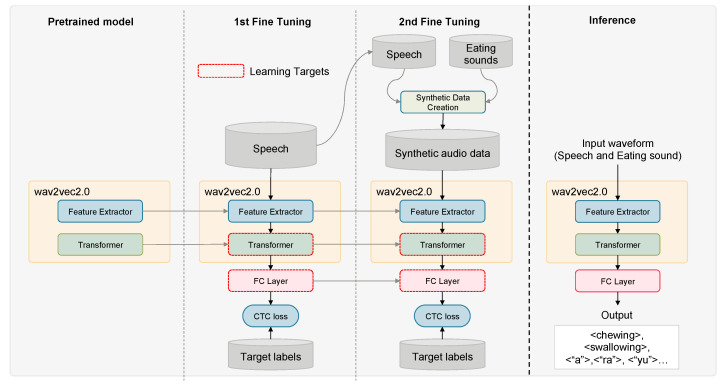 Figure 4
Figure 4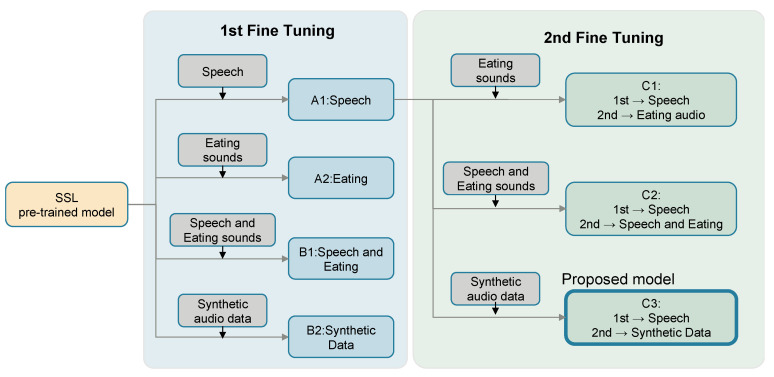 Figure 5
Figure 5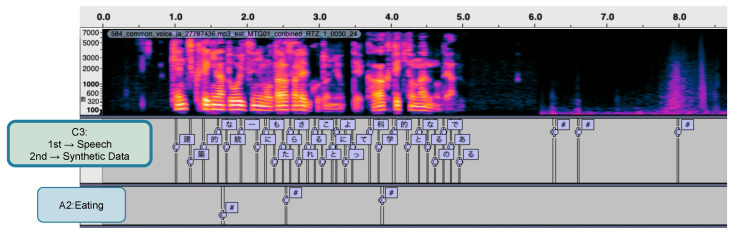 Figure 6
Figure 6Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsVoice and Speech Disorders · Speech Recognition and Synthesis