Singing to speech conversion with generative flow
Jiawen Huang, Emmanouil Benetos

TL;DR
This paper introduces a system to convert singing into speech, preserving phonetic information while reducing musical elements like pitch and rhythm.
Contribution
The paper presents the first deep learning-based system for singing to speech conversion using generative flow.
Findings
The proposed model outperforms signal processing baselines in naturalness.
It achieves higher phonetic similarity compared to a transcribe-and-synthesize baseline.
Singing-to-speech conversion is shown to be effective for augmenting low-resource lyrics transcription.
Abstract
This paper introduces singing to speech conversion (S2S), a cross-domain voice conversion task, and presents the first deep learning-based S2S system. S2S aims to transform singing into speech while retaining the phonetic information, reducing variations in pitch, rhythm, and timbre. Inspired by the Glow-TTS architecture, the proposed model is built using generative flow, with an adjusted alignment module between the latent features. We adapt the original monotonic alignment search (MAS) to the S2S scenario and utilize a duration predictor to deal with the duration differences between the two modalities. Subjective evaluations show that the proposed model outperforms signal processing baselines in naturalness and outperforms a transcribe-and-synthesize baseline in phonetic similarity to the original singing. We further demonstrate that singing-to-speech could be an effective…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
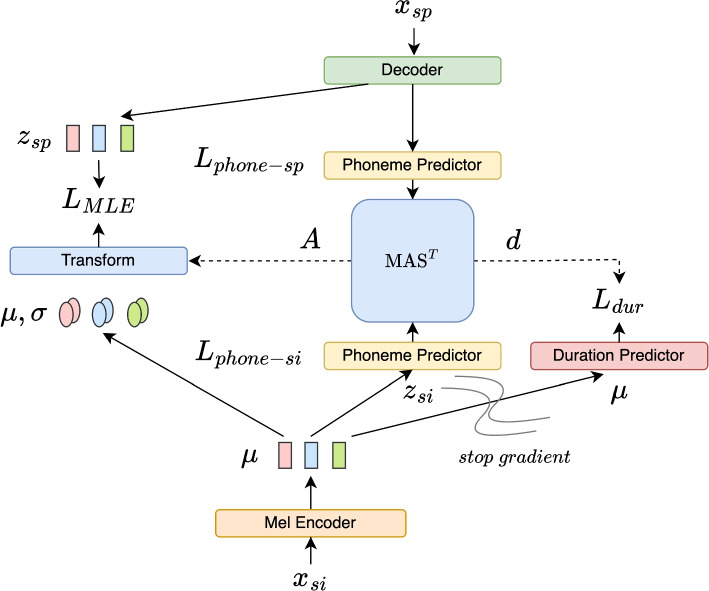 Figure 1
Figure 1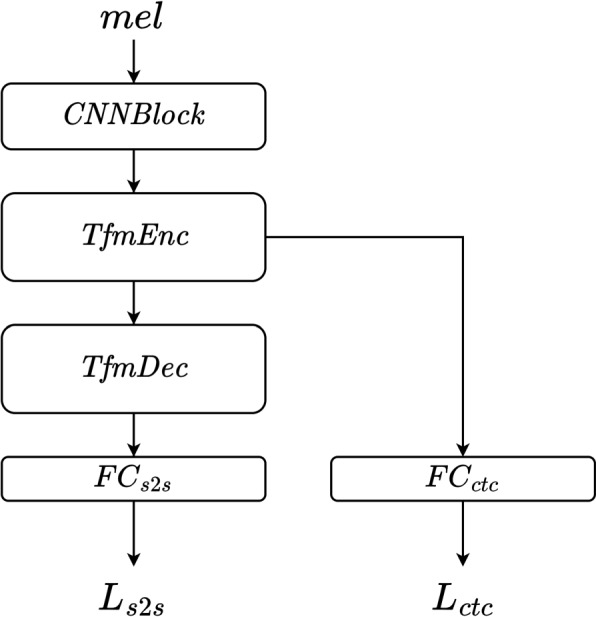 Figure 2
Figure 2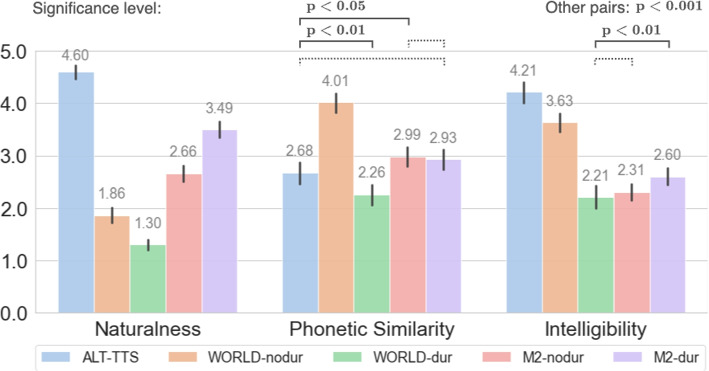 Figure 3
Figure 3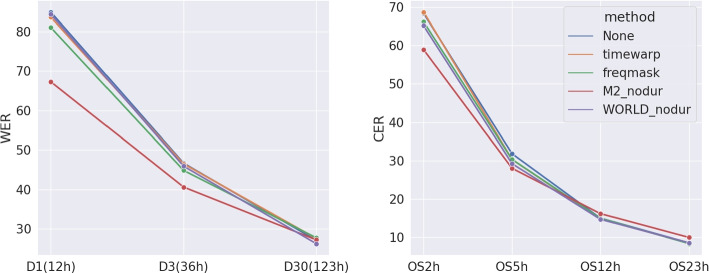 Figure 4
Figure 4- —http://dx.doi.org/10.13039/100014013UK Research and Innovation
- —RAEng/Leverhulme Trust
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsSpeech Recognition and Synthesis · Speech and Audio Processing · Music and Audio Processing
Introduction
Research on singing analysis and manipulation using deep learning has attracted a lot of attention in recent years, including lyrics transcription and singing voice conversion. Compared to speech, singing analysis and manipulation tends to be more challenging, with pitch, duration and timbre typically varying more over time [1]. This characteristic requires greater model capacity and larger datasets for data-driven approaches.
In this work, we propose singing to speech conversion (S2S) as a novel task, which aims to reduce the variations in pitch, rhythm, and timbre in singing to create a signal that sounds like speech. The primary aim is to reduce the above variations while retaining phonetic information, rather than generating intelligible and natural speech. This distinction ensures that the converted signal retains essential phonetic information, making it potentially valuable for downstream tasks, such as being the input prompt for singing voice conversion.
As shown in [2], acoustic modeling for singing is more difficult due to these variations. Thus, S2S could potentially improve the training process for lyrics transcription by providing more uniformly structured data. In addition to its potential for analysis tasks, S2S could support singing manipulation as well. By converting singing to a normalized and interpretable format, an S2S-converted signal can serve as input for various manipulation tasks, such as singing identity conversion, pitch correction, and singing technique/style conversion. Furthermore, S2S could enhance the listening experience of individuals with hearing loss, particularly those with cochlear implants (CI). CI users perceive frequencies at a poor resolution, which may limit their enjoyment of music [3]. The pitch of a singing voice becomes more stable after S2S conversion, potentially making it easier for CI users to perceive it, leading to increased intelligibility.
Despite their natural affinity, singing and speech differ significantly in their acoustic properties. In addition to the pitch and rhythm introduced by melody, dynamics and pronunciations could be different as well [4, 5]. A previous computational pronunciation analysis study found severe confusion between the plosives “D” and “T”, and in approximants with vowels, when predicting phonemes in singing with a phoneme recognition model [4]. It is also common for singers to modify vowels or omit consonants for fluency in singing. These pronunciation differences affect the intelligibility of singing (i.e., words pronounced as they are in singing may be less understandable when read) but contribute to the expressiveness. We argue that the phonetic information is crucial to a singing performance, and essential to analysis and non-phonetic manipulation tasks. Therefore we focus on reducing the variations in singing attributes, while retaining the phonetic information, rather than generating high-quality, intelligible spoken lyrics.
Nowadays, automatic lyrics transcription (ALT) systems are able to achieve decent performance on monophonic singing, with a word error rate of around 10% [6] for English. Additionally, text-to-speech (TTS) systems can generate high-quality speech recordings [7]. While combining these two systems may appear to be a straightforward solution for singing-to-speech conversion, it comes with several limitations. First, this approach would result in a loss of expressiveness, as it compresses all phonetic information into text through the transcription bottleneck. Secondly, temporal information is also lost through the bottleneck, and alignment is not available between the singing and the converted signal. Thirdly, the effectiveness depends upon the quality of ALT and TTS systems, which might not be available for low-resource languages.
The contribution of this work is summarized as follows:
- (I)We propose a new singing conversion task, called Singing-to-Speech, which aims at reducing variations in pitch, duration, and timbre, to create a signal that sounds like speech while retaining phonetic information.
- (II)We propose the first deep learning-based S2S system, leveraging generative flow for its invertibility [8]. This enables us to perform cross-domain alignment and impose constraints on the alignment path. We tackle the challenge of drastic timing differences by adapting the monotonic alignment search algorithm to the S2S scenario.
- (III)Objective and subjective evaluations show that the proposed model outperforms a signal processing-based baseline in terms of naturalness, and a transcribe-then-synthesize baseline in terms of phonetic similarity to the original singing.
- (IV)We demonstrate that S2S could be an effective data augmentation method for low-resource ALT. The rest of the paper is organized as follows: related work is presented in Section 2. The proposed S2S model is introduced in Section 3. In Section 4, we demonstrate the application of the S2S model as a data augmentation method for ALT. Experimental details are provided in Section 5. Objective and subjective results for the proposed S2S model, and the data augmentation ALT results, are discussed in Section 6. Finally, conclusions are drawn in Section 7.
Related work
In-domain voice conversion
Voice conversion (VC) in the context of speech or singing usually refers to changing the identity of the speaker or singer while maintaining the linguistic content. Various methods have been explored in the field of speech conversion, including using a pre-trained Automatic Speech Recognition (ASR) model to extract speaker-invariant linguistic features (text [9, 10] or phonemes [11, 12]), followed by speech synthesis for the target speaker. Others employ autoencoders to disentangle speaker and linguistic information during reconstruction using an autoencoder [13, 14]. GAN-based (generative adversarial network) models [15, 16] have been applied to alter the speaker identity while retaining the content with the help of discriminators. Singing voice conversion (SVC) research generally follows that of speech conversion: GAN-based models (ROSVC [17], FastSVC [18]) and disentanglement-based methods (VQVAE and its variants [19, 20]) have also been explored. Recent advancements have also explored the use of diffusion models and normalizing flows for SVC, demonstrating their potential to achieve high-quality conversion results [21, 22].
Other aspects beyond speaker or singer identity can also be manipulated, including pitch [23–25], singing techniques [26], and prosody [27, 28].
Cross-domain voice conversion
It is worth noting that, although some of the above conversion pipelines involve alignment or time warping (either implicitly or explicitly), the warping does not introduce drastic changes because the conversion stays within the singing or the speech domain. In [29], the authors show that with dynamic time warping (DTW), the cross-domain (between singing and speech) alignment error is much higher than speech alignment error (between speech and speech), due to the large differences in rhythm and timing between speech and singing. It is also generally acknowledged that substantial local tempo differences are challenging for time warping methods.
As a cross-domain conversion task, S2S has a lot in common with the task in the opposite direction, i.e., speech-to-singing conversion, where speech is converted to singing given a pitch contour or a reference singing. Both tasks face challenges such as limited amounts of paired training data (singing and speech recordings with the same linguistic content) and obtaining a temporal alignment between paired singing and speech. Earlier signal processing approaches [29–31] compute the alignment between speech and singing (or/and text) using DTW or its variants. Recent studies [32, 33] have shown a growing interest in deep learning approaches without explicit synchronization input. These approaches aim to learn a mapping from speech to singing, or vice versa, without requiring explicit alignment between the two modalities.
Flow-based generative models
A flow-based generative model [34] transforms a simple tractable probability distribution, such as a standard normal distribution, to the data distribution, through a series of invertible transformations. The resulting transformation can be applied in both directions. As a consequence, it is possible to generate new samples from the data distribution and compute the exact likelihood of existing data.
The generative process can be defined as
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} z \sim \pi (z) \end{aligned}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} x = f(z) \end{aligned}$$\end{document}where z is a latent variable, x is a data sample, and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pi$$\end{document} is a tractable density, such as a multivariate Gaussian: \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pi (z) = \mathcal {N}(z;\mu ,\sigma ^{2})$$\end{document} . The function f consists of L invertible functions:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} f=f_1 \circ f_2 \circ ...\circ f_L \end{aligned}$$\end{document}The exact log-likelihood of data x can be calculated as follows:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \log p(x) & = \log \pi (z) + \log \left| \det \frac{\partial f^{-1}(x)}{\partial x} \right| \nonumber \\ & = \log \pi (z) + \sum ^{L}_{i=1} \log \left| \det \varvec{\mathcal {J}}(f^{-1}_i(x)) \right| \end{aligned}$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\det \varvec{\mathcal {J}}(f^{-1}_i(x))$$\end{document} is the Jacobian determinant of the function \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$f^{-1}_i$$\end{document} . Flow-based models choose functions \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$f_i$$\end{document} whose Jacobian is a triangular matrix, such that the log-determinant calculation is straightforward and efficient.
For audio generation tasks, flow-based generative models have attracted considerable interest due to their exact likelihood computation, invertibility, and efficiency [35]. Corresponding methods have been successfully used for TTS [36, 37], singing synthesis [38, 39] and voice conversion [11, 39].
Duration prediction
Duration prediction [36, 40, 41] was proposed to address robustness issues in neural TTS models, such as word skipping, repeating and attention collapse [7]. A duration predictor either predicts the length of the whole output sequence or the length of corresponding frames in the output for each input token. While the former is used to prevent the network from generating unusually long output, the latter replaces the attention module during inference to avoid attention collapse. By removing the attention modules, misalignment caused by length mismatch between text and speech is alleviated. In Glow-TTS, duration is explicitly predicted for every input token, from which an alignment path can be generated. This exploits the inherent monotonic nature, where each input token corresponds to multiple output frames. A similar correspondence exists between speech and singing with the same linguistic content, where speech is often much shorter than singing. Given this context, we propose adopting the duration prediction from Glow-TTS, as it proves effective in handling cross-domain length mismatches.
Proposed method
Our model is based on the Glow-TTS architecture [36], which in its original form aligns input text and output spectrograms using monotonic alignment search (MAS) [36] based on latent features. To adapt it to the S2S task, we need to change various core components. First, we modify the MAS algorithm to address the issue of temporal alignment between the singing and speech audio. Next, unlike TTS, S2S takes singing Mel-spectrograms as input and produces speech-like Mel-spectrograms. Thus, the proposed model consists of a Mel Encoder \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$f_{enc}$$\end{document} , a flow-based decoder \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$f_{dec}$$\end{document} , a duration predictor \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$f_{dur}$$\end{document} , and a phoneme predictor \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$f_{phone}$$\end{document} . We define \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$x_{si}$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$x_{sp}$$\end{document} to be a pair of singing and speech Mel-spectrograms which share the linguistic content. Let \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$T_{si}$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$T_{sp}$$\end{document} denote the lengths of the singing and speech Mel-spectrogram. Given the true data distribution \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$(x_{si}, x_{sp}) \sim p^{*}(x_{si}, x_{sp})$$\end{document} , the goal is to model \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$x_{sp} \sim p^{*}(x_{sp}|x_{si})$$\end{document} (Fig. 1).Fig. 1. Diagram of the proposed S2S model
Training
The Mel encoder \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$f_{enc}$$\end{document} maps the singing Mel-spectrogram \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$x_{si}$$\end{document} into the statistics of a latent space Z. To this end, we sample \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$z_{si}$$\end{document} from \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathcal {N}(\mu ,\sigma )$$\end{document} with a noise level \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\epsilon$$\end{document} as follows. The phoneme predictor \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$f_{phone}$$\end{document} is applied to \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$z_{si}$$\end{document} to produce a phoneme posteriorgram \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$Q_{si}$$\end{document} :
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \mu & = f_{enc}(x_{si}), \; \sigma = 1 \end{aligned}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} z_{si} & = \mu + \epsilon \sigma \end{aligned}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} Q_{si} & = f_{phone}(z_{si}) \end{aligned}$$\end{document}During training, an inverse pass of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$f_{dec}$$\end{document} maps the speech Mel-spectrogram \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$x_{sp}$$\end{document} to the same latent space Z, and the same phoneme predictor is applied to produce a speech phoneme posteriorgram \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$Q_{sp}$$\end{document} :
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} z_{sp} & = f^{-1}_{dec}(x_{sp})\end{aligned}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} Q_{sp} & = f_{phone}(z_{sp}) \end{aligned}$$\end{document}Let \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$S_{phone}$$\end{document} be the phoneme sequence of the linguistic content. \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$f_{phone}$$\end{document} is trained with a CTC Loss [42] as follows:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} L_{phone-si} & = CTC(Q_{si}, S_{phone})\end{aligned}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} L_{phone-sp} & = CTC(Q_{sp}, S_{phone}) \end{aligned}$$\end{document}According to Eq. 4, we can calculate the log-likelihood:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \log p(x_{sp}|x_{si}) = \log \pi (z|x_{si}) + \log \left| \det \frac{\partial f^{-1}(x_{sp})}{\partial x_{sp}} \right| \end{aligned}$$\end{document}Given that \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$z_{si}$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$z_{sp}$$\end{document} differ in length, an alignment A is required in some form to relate them. In Glow-TTS, the phoneme alignment is trained in the latent space Z with MAS. In the original MAS algorithm for TTS, it searches for the most probable monotonic alignment between the latent features computed from speech and the statistical prior distribution derived from text. Essentially, it finds a monotonic alignment path between the two, using DTW with directional constraints to ensure monotonicity. In TTS, due to the property that one input phoneme would always produce 1 or more frames, MAS does not allow multiple input tokens to be aligned with one output frame. In other words, the alignment only allows expanding the length for every token in the sequence. However, in the S2S scenario, this assumption no longer holds. Our preliminary study on the NUS-48E dataset [43] shows that around 80% of the phoneme counts are shortened in speech compared to singing. Therefore, we apply the restriction to the other direction, that we only allow shortening every input sequence. This led us to implement a variant of the MAS algorithm called MAS \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$^{T}$$\end{document} . In practice, this is implemented by simply swapping the direction restriction to ensure monotonicity in the opposite direction (shortening instead of expansion).
In [11], the authors present a voice conversion model based on Glow-TTS and mention that MAS leads to challenging training dynamics. They avoid the problem by using pre-trained explicit phoneme durations and therefore no alignment is required. In internal tests, we also found alignments in Z-space failing to produce reasonable alignment paths. For that reason, we compute the alignment between the singing and speech phoneme posteriorgrams \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$Q_{si}$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$Q_{sp}$$\end{document} using MAS \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$^{T}$$\end{document} :
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} A = \text {MAS}^{T}(Q_{si}, Q_{sp}). \end{aligned}$$\end{document}Here, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$A(i) = j$$\end{document} encodes that the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$i^{th}$$\end{document} frame of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$Q_{si}$$\end{document} is aligned to the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$j^{th}$$\end{document} frame of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$Q_{sp}$$\end{document} . From A we define \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$d_j$$\end{document} as the inverse of the number of singing frames being aligned to the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$j^{th}$$\end{document} frame of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$Q_{sp}$$\end{document} . This is used as the duration prediction target and the mean squared error (MSE) loss \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$L_{dur}$$\end{document} is defined as follows:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} d_j & = \frac{1}{\sum _{j=1}^{T_{si}} 1_{A(i)=j}}, j=1,...,T_{sp} \end{aligned}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} L_{dur} & = MSE(f_{dur}(\mu ), d) \end{aligned}$$\end{document}We can describe the prior distribution as follows:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \log P(z_{sp}|x_{si}; \theta , A) = \sum ^{T_{sp}}_{j=1} log N\left( z_{sp,j}; \frac{1}{d_j}\sum _{A(i)=j}^{T_{si}}\mu _i, \sigma \right) \end{aligned}$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\theta$$\end{document} indicates the network parameters. The inner summation means that, when multiple singing frames are aligned with one speech frame, an average is computed among the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mu$$\end{document} values. The objective is given by:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \min _{\theta } L_{MLE}(\theta ) = \min _{\theta } -\log P(z_{sp}|x_{si}; \theta , A) \end{aligned}$$\end{document}The final loss consists of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$L_{MLE}$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$L_{dur}$$\end{document} , which share the same weight \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\omega$$\end{document} , while \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$L_{phone-si}$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$L_{phone-sp}$$\end{document} are included without additional weighting:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} L = \omega (L_{MLE} + L_{dur}) + L_{phone-si} + L_{phone-sp} \end{aligned}$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\omega$$\end{document} is a tunable parameter.
Inference
During inference, we follow the same process to calculate \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$z_{si}$$\end{document} (Eq. 5-6). Duration is predicted by the duration predictor:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} d = f_{dur}(\mu +\epsilon \sigma ) \end{aligned}$$\end{document}The mapping A can be inferred by accumulating d until the sum is greater than a threshold h. The \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$z_{sp}$$\end{document} is sampled from the isotropic multivariate Gaussian distribution with the aligned mean values:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} z_{sp,j} \sim \pi (z_{sp,j}) & = \mathcal {N} \left( z_{sp,j}; \frac{1}{d_j}\sum _{A(i)=j}^{T_{si}}\mu _i, \sigma \right) \end{aligned}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} x_{sp} & = f_{dec}(z_{sp}) \end{aligned}$$\end{document}Architecture
The input \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$x_{si}$$\end{document} is an 80-bin Mel-spectrogram, computed at 16 kHz sampling rate, with a FFT size of 1024 and a hop size of 256, from 80 to 7600 Hz. This setting is adopted to be compatible with a pretrained Parallel Wave GAN 1, which is used for speedy Mel-to-audio conversion. The Mel-spectrograms are normalized with the global mean and standard deviation.
Mel encoder
The first part of the Mel Encoder has 5 blocks of Conv1D layers with group normalization. The convolutional layers have 512 channels, with a kernel size of 5 and a stride of 1. Each group has 16 channels, resulting in 32 groups for normalization. The 5 Conv1D blocks are followed by another 3 Conv1D blocks, which alter the channel number from 512 to 128, 32, and 80, which is the embedding dimension and the hidden dimension for alignment. The second part uses the same architecture as Glow-TTS’s text encoder, except that the text embedding layer is removed. The output \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mu$$\end{document} (and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$z_{si}$$\end{document} ) is then passed to the MAS \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$^{T}$$\end{document} module, duration predictor, and phoneme predictor.
Phoneme predictor
The phoneme predictor contains 1 linear layer, 3 bidirectional LSTM layers, and 1 linear layer to map the dimension to the number of phonemes in the end. Log-softmax is applied before it is used for alignment and connectionist temporal classification (CTC) loss [42] computation.
Duration predictor
The duration predictor consists of 2 multi-head attention layers, accompanied by Conv1D layers and LayerNorms. Note that this is more complicated than the linear projection in Glow-TTS, because it needs to learn from the context to decide the shortening rate. Stop gradient is applied to avoid affecting other objectives.
Flow-based decoder
The flow-decoder is a stack of 12 blocks, each consisting of an activation normalization layer, invertible \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$1\times 1$$\end{document} convolution layer, and affine coupling layer [34].
S2S for data augmentation
Automatic lyrics trimited publicly available training data, ALT suffers from insufficient data, especially for non-English languages, as English dominates most of those datasets.
As one potential applicanscription (ALT) [44] for singing voice is the equivalent task to ASR for speech. Due to the lation, we propose S2S as a data augmentation method for ALT, which focus on low-resource settings. It has the following strengths: (1) unlike traditional augmentation methods for audio such as speed perturbation and SpecAugment [45], S2S is content-aware. Therefore, it can reduce the variations in irrelevant aspects, and let ALT focus on the phonetic information. (2) S2S does not require access to external audio and metadata. (3) S2S can be applied to unseen languages, making it suitable for low-resource language scenarios. Since languages often share numerous phonemes, an S2S model can generalize to other languages by leveraging its knowledge of phoneme mapping.
In Section 5.5, we investigate the efficacy of S2S models as data augmentation methods across varying amounts of training data and different languages.
Experiments
Datasets
The experiments are conducted on the DAMP Sing! 300 ✕ 30 ✕ 2 dataset [46, 47] (DSing), which contains singing recordings with lyrics annotations collected from the Smule karaoke platform across 30 countries. In each country, 300 songs are included, each performed by one female and one male singer. We use the split configuration in [47]. There are in total 81,092 (from the DSing30 split), 482, and 480 utterances from train, development, and test splits with lyrics annotations. Because the alignment depends on the phoneme posteriorgram, it works only after the phoneme predictor is trained to a certain level. To achieve faster and more stable training, we decide to use samples that are less than 5 s and longer than 3 s. After filtering, 20,985 utterances are left for training. The lyrics are first converted to a phoneme sequence via a grapheme to phoneme tool 2.
For every singing utterance, a speech audio is generated by Tacotron2 3 [48]. This allows us to create paired training data. All of the audio files are resampled or generated at 16 kHz sampling rate.
For evaluation, we use both the test split from DSing and NHSS [49]. NHSS is a speech and singing parallel database with 2791 pairs of utterances, each has a singing and a spoken version. Although there is no direct comparison between the proposed S2S and the spoken utterances in NHSS due to our S2S task definition, the spoken utterances can serve as a source of natural prosody (intonation and rhythm) for our baselines.
Baselines
The first baseline is the straightforward approach to S2S, which is to transcribe the lyrics and then synthesize using TTS. We choose the lyrics transcription model from [6]. The TTS model is Tacotron2 [48]. This baseline is referred to as ALT-TTS.
We build two more baselines with the WORLD synthesizer [50], one with duration adjustment and the other without. WORLD is a vocoder which parameterizes speech into pitch contour ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$F_0$$\end{document} ), harmonic spectral envelope (SP), and aperiodic spectral envelope (AP). It is commonly used for pitch manipulation on voices by editing the pitch contour and resynthesizing the signal [24, 25]. For baselines, we align the singing with its speech reference, and replace the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$F_0$$\end{document} of singing with that of the aligned reference speech. In this way, we approximate the intonation and the duration (rhythm) in the reference. We use different reference speech signals on DSing and NHSS. For DSing, the synthesized speech by ALT-TTS is used as a reference for intonation and duration adjustment. On NHSS, we use spoken utterances as the reference.
The steps to create the baseline with duration adjustment (WORLD-dur) are as follows: First, a standard DTW is applied between the MFCC features of singing and the synthesized speech, similar to the temporal alignment method adopted in [29]. Secondly, with the synchronization information, time-stretching is applied to the singing using rubberband 4. Next, the F0 contours are extracted by WORLD from the stretched singing ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$F0^{align}_{si}$$\end{document} ) and the speech ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$F0_{sp}$$\end{document} ). A linear interpolation on \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$F0_{sp}$$\end{document} is applied to compensate the voiced/unvoiced frame mismatch due to imperfect alignment, so that the voiced/unvoiced information is the same as \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$F0^{align}_{si}$$\end{document} for each frame. Finally, we re-synthesize the signal using the interpolated \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$F0_{sp}$$\end{document} , the stretched singing SP, and the stretched singing AP. Similar to WORLD-dur, if the time-stretching is applied to the synthesized speech, the output would have no duration adjustment. This is denoted as WORLD-nodur.
SVC models are not considered as baselines since most of them are not capable of duration manipulation, making them invalid as S2S systems for comparison.
Training and inference
We use the ADAM optimizer, at the learning rate of 0.0001. Parameter \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\omega$$\end{document} is set to 10. The model is first trained for 223 epochs at a noise level \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\epsilon$$\end{document} of 0, and finetuned at a noise level of 0.3 for another 60 epochs. The models before and after finetuning are referred to as *M1 *and M2.
During inference, the duration is predicted by the duration predictor. Additionally, it is possible to manually adjust the duration by entering duration rates. When all values are set to 1, the duration adjustment is disabled, and the rhythm information in the input is preserved. To demonstrate the impact of duration adjustment on the converted audio, we compare two models: one with duration adjustment, denoted as M-dur*, and one without duration adjustment, denoted as M-nodur*.
Evaluation
Objective evaluation
To evaluate the audio quality and intelligibility of the S2S systems, we adopt two objective metrics: MOSNet [51] and SRMR (speech-to-reverberation modulation energy ratio) [52, 53]. MOSNet is a deep learning-based metric that predicts a mean opinion score (MOS) estimation for voice conversion tasks. SRMR, on the other hand, is a non-intrusive speech intelligibility metric that measures the ability to comprehend speech in a noisy environment. SRMR-CI is a variant of SRMR designed for CI (cochlear implant) users, and we use it to measure the intelligibility for people with hearing loss. It is worth noting that MOSNet and SRMR may not be the most suitable metrics for evaluating the intelligibility of S2S output, because the noise distribution in our setting is heterogeneous to those from a denoising or enhancement system. Nonetheless, we believe that the combination of MOSNet and SRMR provides some useful insights into the naturalness and intelligibility. Besides, we report the word error rate (WER) and character error rate (CER) from a pretrained ASR model 5 and a pretrained ALT model [6].
Subjective evaluation
Our pilot subjective study shows that the model after fine-tuning (M2) generates perceptually better audio than the model without fine-tuning (M1). Due to the limited resources for a subjective test, M1 is excluded from the subjective study.
We conducted an online survey to evaluate the performance of S2S conversion methods, in which we compared five different methods: ALT-TTS, WORLD-nodur, WORLD-dur, M2-nodur, and M2-dur. We randomly selected one utterance between 3 to 5 s from each of the 8 singers (four female and four male) out of 10 in the NHSS dataset, and applied the five methods to each of these utterances. Participants in the survey were asked to rate the naturalness, phonetic similarity to the singing reference, and intelligibility to recognize the given reference lyrics on a Likert scale ranging from 1 to 5. The survey was held on Qualtrics 6.
In the context of this study, phonetic similarity refers to the extent of acoustic resemblance between two linguistic elements in terms of their pronunciations. However, it is important to note that a universally accepted definition does not exist, as pointed out in [54]. In our online survey, we define the phonetic similarity from a practical viewpoint, assessing the degree to which the given audio sample sounds like the reference in terms of pronunciation.
From our internal tests, we found that the rating of phonetic similarity can be easily influenced by audio quality and intelligibility. We observed that some participants disregarded the pronunciation and consistently chose the sample with the best quality or the most intelligible linguistic content. To reduce such biases in the analysis, we introduced two screening questions. Participants were asked to select the TTS-generated samples that demonstrated the highest phonetic similarity to a singing reference, where we modified the input phoneme prompt for TTS to mimic the singing pronunciation. Responses that did not pass the screening would be excluded from the analysis.
S2S for data augmentation
We propose S2S to be an effective augmentation method under low-resource settings. To approximate the low-resource condition and to study how the effectiveness varies over the training data size, different training subsets from the same datasets are used.
Data splits
For English ALT, the three splits of DSing (DSing1, DSing3, and DSing30) are adopted. Additionally, we utilize OpenSinger [55], a Chinese singing voice dataset, to conduct parallel experiments on a language unseen during training, reflecting the model’s generalization ability. We form the test set by leaving out four singers (2 males and 2 females) out of the total 76, and another 4 singers are reserved for the validation set. We randomly sample subsets, resulting in four training sets: OS2h, OS5h, OS12h, and OS23h (named according to their total durations).
S2S Methods for comparison
Among the proposed S2S models, M2-nodur is selected for yielding the best ALT WER. S2S models (M2-nodur and WORLD-nodur) are compared against time warping and frequency masking from SpecAugment [45], as well as no augmentation. ALT-TTS is not included due to its dependencies on descent ALT and TTS models, which assume a high-resource setting.
Architecture
Experiments are conducted using the same transformer ALT model and training pipeline implemented with the speechbrain [56] toolkit. The ALT model is a hybrid CTC/attention [57] transformer. Figure 2 illustrates the model architecture. The input is an 80-bin Mel-spectrogram, consistent with the proposed models. It is passed through a convolutional block and a transformer encoder. The encoder’s output is directed to two branches: one for CTC loss [42], and the other for sequence-to-sequence (seq2seq) loss. The CTC branch comprises a single fully connected layer, generating a CTC loss \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$L_{ctc}$$\end{document} . The seq2seq branch consists of one transformer decoder and another fully connected layer. The seq2seq branch produces a cross-entropy loss \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$L_{s2s}$$\end{document} and performs inference autoregressively. The final loss is a weighted sum of the two:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} L = \alpha L_{ctc} + (1-\alpha ) L_{s2s} \end{aligned}$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\alpha$$\end{document} is the weighting parameter.Fig. 2. Architecture of the ALT model. It consists of a convolutional block CNNBlock, a transformer encoder TfmEnc, a transformer decoder TfmDec, and two fully connected layers FCctc, FCs2s
We follow the default setting in a speechbrain recipe 7 and make adaptations. The input \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$x_{si}$$\end{document} is an 80-bin Mel-spectrogram, computed at a 16-kHz sampling rate, with an FFT size of 1024 and a hop size of 256, ranging from 80 to 7600 Hz. This configuration is consistent with that of the pretrained Parallel Wave GAN model 8 and the proposed S2S model output. The convolutional block comprises 3 CNN blocks, each with 64 channels. The initial two layers have a kernel size of 5 and a stride of 2, while the last layer has both the kernel and stride set to 1. The transformer encoder consists of 12 layers, and the transformer decoder consists of 6 layers. Each encoder layer consists of a multi-head attention and a positional-wise feed-forward layer. Each decoder layer shares the same structure except that the attention layer is causal. The dimensions are configured as follows: attention dimension is set to 512, and the dimensional size of the positional-wise feed-forward layer is 2048. The number of heads is set to 8, and the loss weighting parameter \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\alpha$$\end{document} is set to 0.3 according to [58].
Training
All experiments on DSing datasets are trained for 100 epochs, and all experiments on OpenSinger datasets are trained for 300 epochs (except for OS2h is 600 epochs). The numbers are adjusted according to the convergence condition.
For both languages, we use pretrained tokenizers from huggingface hubs 9. Both tokenizers produce 5000 tokens (subwords) in total.
SpecAugment methods are applied at runtime, with the time-warping parameter set to 5, and the number of frequency masks set to 2, each with a width of 15. Augmented Mel-spectrograms using S2S methods are incorporated at training time, with each singing Mel-spectrogram having a 50% probability of being replaced by its S2S-converted counterpart.
We use the ADAM optimizer [59] and employ the Noam learning rate scheduler [60], with the initial learning rate set to 0.001. The number of warm-up steps is set to 25000. The final model is derived by averaging the best 5 validated end-of-epoch checkpoints.
For validation and testing, we apply beam search on the transformer decoder to determine the best autoregressive prediction. The beam size is set to 10 during validation and 66 during testing. No language model is involved, and we report WER for English and CER for Chinese results.
Results and discussion
Objective results
Table 1 shows the objective evaluation results on S2S methods and their reference audio on DSing 10. It can be observed that the MOSNet and SRMR are degraded after conversion with WORLD models, while M1 and M2 models show improvements in SRMR. This suggests that the signal processing approach introduces artifacts, while the proposed models unintentionally achieve some level of denoising and dereverberation due to the clean training target. Table 1. Objective evaluation on the DSing test setDuration adjustmentReferencenodurdurMethodSingALT-TTSWORLDM1M2WORLDM1M2MOSNet \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\uparrow$$\end{document} 3.012.861.992.892.842.422.962.94SRMR \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\uparrow$$\end{document} 12.2114.511.8515.5513.735.5619.8615.85SRMR-CI \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\uparrow$$\end{document} 7.409.085.089.558.184.2011.628.93ASR WER/CER \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\downarrow$$\end{document} 0.54/0.310.31/0.180.66/0.401.00/0.660.97/0.630.85/0.620.88/0.640.84/0.58ALT WER/CER \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\downarrow$$\end{document} 0.13/0.070.22/0.150.23/0.150.73/0.510.61/0.400.72/0.530.71/0.530.62/0.45Sing indicates the original singing voice
Comparing to M2, the M1 model yields superior MOSNet and SRMR results, but inferior WERs/CERs. This can be attributed to the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\epsilon = 0.3$$\end{document} finetuning process, which encourages a sparser distribution of the centres of the multivariate Gaussian. This encourages the encoder to be more confident about the phoneme information, and leads to clearer pronunciation. Other \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\epsilon$$\end{document} values (0.1, 1.0) have been explored and we chose \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\epsilon =0.3$$\end{document} empirically.
All methods show an increase in WER/CER after conversion, and these results are not satisfactory. This is not surprising, partly because the ASR/ALT models are not accustomed to speech-like signals being uttered in singing pronunciations. Moreover, proposed models have limited information about semantics, hence when they encounter ambiguous phonemes in singing such as ‘D’ or ‘T’, or noisy recordings, they cannot rely on a language model, but convert it as they are. As a result, some utterances may be challenging to detect by an ASR model but still make sense to a human listener.
The ASR and ALT error rates are heavily degraded for WORLD when applying the duration adjustment, while the opposite can be observed for M1. Relatively small degradation of ALT error rates can be observed for M2. This suggests that the proposed models are more effective at addressing substantial rhythm conversion.
Subjective results
We recruited 23 subjects who were Master’s or PhD students in Computer Science and Engineering or interdisciplinary fields involving AI. Among them, many had experience in music processing. Table 2 summarizes the participants’ self-reported gender, age, and singing experience. Figure 3 shows the MOS results of all methods and aspects, and the pair-wise Wilcoxon signed-rank test significance levels. Table 2. Demographic information and singing experience of participants, including gender, age, and amount of singing experienceGender Man11 Woman6Age Group 18–253 25–3513 35–451Singing experience Not trained / do not sing6 Little training but enjoy singing9 Trained for years2
Fig. 3. Comparison of different methods in subjective evaluation. All values are Mean Opinion Score (MOS). All pair-wise significance level is \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$p<0.001$$\end{document} except for those indicates above the plot. A dotted line means no significance
ALT-TTS achieves the highest score in naturalness, due to the advance of TTS technology. Our proposed M2 models outperform WORLD methods, probably because the neural network approach introduces fewer artefacts than the signal processing approach. The WORLD method performs worse with duration adjustment, while M2 performs better. This trend is consistent with the objective evaluation and is also observed in the intelligibility scores, suggesting that M2 is better at handling rhythm conversion. It is possible that alignment with time-stretching fails to produce natural and clean signals, which can negatively impact intelligibility. On the other hand, the duration predictor in M2 produces a more natural speech rhythm which is easier for human perception and contributes to a higher level of intelligibility.
WORLD-nodur achieves the highest score in phonetic similarity, probably because this is the method with the least manipulation (only in pitch) therefore the pronunciation is well-preserved. ALT-TTS is rated slightly lower than M2 models. This suggests that, despite the high accuracy of the ALT model, the ALT-TTS method may sacrifice some pronunciation details in favour of preserving linguistic content. In contrast, the M2 models retain pronunciation details better, but at the cost of a degradation in intelligibility.
S2S for data augmentation results
Figure 4 displays the ALT results when training on different sizes of subsets with different augmentation methods. M2-nodur shows a clear advantage over the others under low-resource settings for both languages. As the training data increases, it performs slightly worse than the others, likely due to the error propagated from M2. It is noteworthy that M2-nodur proves effective on OS2h and OS5h, even though Chinese samples were unseen during training. Additionally, the test set involves a tonal language (Chinese), while the training data (English) is non-tonal.Fig. 4S2S for data augmentation results on different training sets. On the left: WERs on the DAMP test set, with numbers in parentheses indicating the duration of the subsets. The numbers in the parentheses indicate the duration of the subsets. On the right: CERs on the OpenSinger test set
Conclusion
This work introduces the singing-to-speech conversion task and presents the first deep learning-based S2S system. By leveraging existing TTS models and technology to generate synthetic data for training and adapting the Glow-TTS model to S2S, we achieve a better balance of naturalness and phonetic similarity than the baseline models. Additionally, we demonstrate the new S2S task can benefit ALT through data augmentation, and the proposed model exhibits the ability to generalize to unseen languages. Moreover, S2S has potential as an input for various manipulation tasks and could serve to anonymize singing voices before uploading them to a voice editing service. The proposed MAS \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$^{T}$$\end{document} may offer a solution to bridge timing differences between singing and speech. These potential advantages will be investigated in future studies.
Currently, the model is trained with \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\text {MAS}^{T}$$\end{document} under the assumption that all frames in singing are shortened in speech. It can sometimes lead to problematic conversion for consonants. Furthermore, glottal fricatives (“H”) are often skipped probably due to their resemblance to inhaling. To carry more accurate phonetic information, we plan to incorporate language models that leverage semantic information and make more informed decisions. On the other hand, we plan to enhance the audio quality of the converted samples by further narrowing the performance gap between M2 and ALT-TTS. This could involve refining the synthesis process to generate more life-like voice.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1A.M. Kruspe, in Proceedings of the 17th International Society for Music Information Retrieval Conference, ISMIR 2016, New York City, United States, August 7-11, 2016. Bootstrapping a system for phoneme recognition and keyword spotting in unaccompanied singing (ISMIR, 2016), pp. 358–364
- 2A.M. Kruspe, in Proceedings of the 15th International Society for Music Information Retrieval Conference, ISMIR 2014, Taipei, Taiwan, October 27-31, 2014. Keyword spotting in a-capella singing (ISMR, 2014), pp. 271–276
- 3E. Demirel, S. Ahlbäck, S. Dixon, in 29th European Signal Processing Conference, EUSIPCO 2021, Dublin, Ireland, August 23-27, 2021. Computational pronunciation analysis in sung utterances (IEEE, 2021), pp. 186–190
- 4C. Gupta, H. Li, Y. Wang, in 19th Annual Conference of the International Speech Communication Association, Interspeech 2018, Hyderabad, India, September 2-6, 2018. Automatic pronunciation evaluation of singing (ISCA, 2018), pp. 1507–1511
- 5L. Ou, X. Gu, Y. Wang, in Proceedings of the 23rd International Society for Music Information Retrieval Conference, ISMIR 2022 Bengaluru, India December 4-8, 2022. Towards transfer learning of wav 2vec 2.0 for automatic lyric transcription (ISMIR, 2022), pp. 891–899
- 6L. Dinh, D. Krueger, Y. Bengio, in 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, May 7-9, 2015, Workshop Track Proceedings. NICE: non-linear independent components estimation (2015)
- 7J.X. Zhang, L.J. Liu, Y.N. Chen, Y.J. Hu, Y. Jiang, Z.H. Ling, L.R. Dai, in Joint Workshop for the Blizzard Challenge and Voice Conversion Challenge, Shanghai, China, October 30, 2020. Voice conversion by cascading automatic speech recognition and text-to-speech synthesis with prosody transfer (ISCA, 2020), pp. 121–125
- 8S.W. Park, D. Kim, M. Joe, in 21st Annual Conference of the International Speech Communication Association, Interspeech 2020, Virtual Event, Shanghai, China, October 25-29, 2020. Cotatron: Transcription-guided speech encoder for any-to-many voice conversion without parallel data (ISCA, 2020), pp. 4696–4700