An online intelligent detection method for slurry density in concept drift data streams based on collaborative computing
Lanhao Wang, Hao Wang, Taojie Wei, Wei Dai, Hongyan Wang

TL;DR
This paper introduces a new method for detecting slurry density in industrial settings that adapts to changing data conditions in real time.
Contribution
A novel online detection method using collaborative computing and adaptive models to handle concept drift in slurry density data streams.
Findings
The proposed method outperforms existing algorithms in density estimation metrics.
Collaborative computing ensures real-time detection and model adaptability in industrial applications.
The method effectively mitigates concept drift by focusing on recent data.
Abstract
In industrial environments, slurry density detection models often suffer from performance degradation due to concept drift. To address this, this article proposes an intelligent detection method tailored for slurry density in concept drift data streams. The method begins by building a model using Gaussian process regression (GPR) combined with regularized stochastic configuration. A sliding window-based online GPR is then applied to update the linear model’s parameters, while a forgetting mechanism enables online recursive updates for the nonlinear model. Network pruning and stochastic configuration techniques dynamically adjust the nonlinear model’s structure. These approaches enhance the mechanistic model’s ability to capture dynamic relationships and reduce the data-driven model’s reliance on outdated data. By focusing on recent data to reflect current operating conditions, the…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
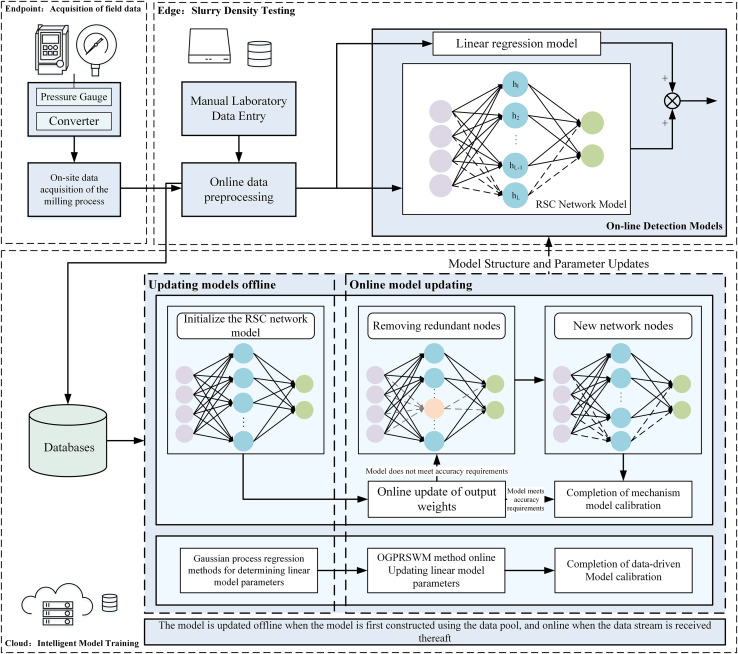 Figure 1
Figure 1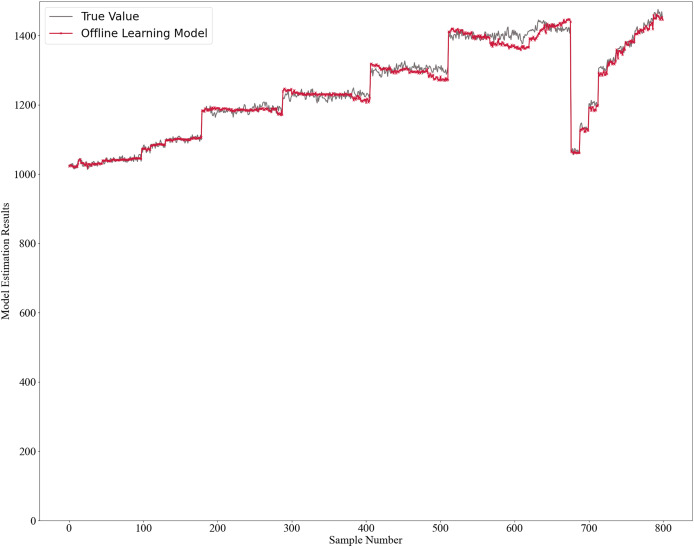 Figure 2
Figure 2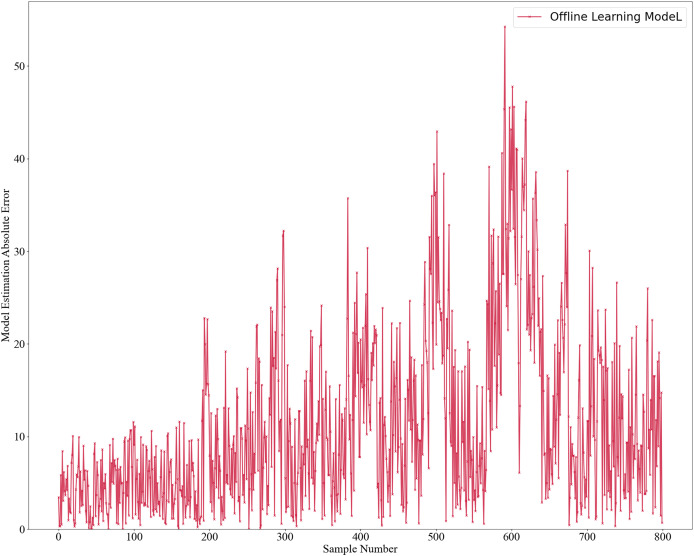 Figure 3
Figure 3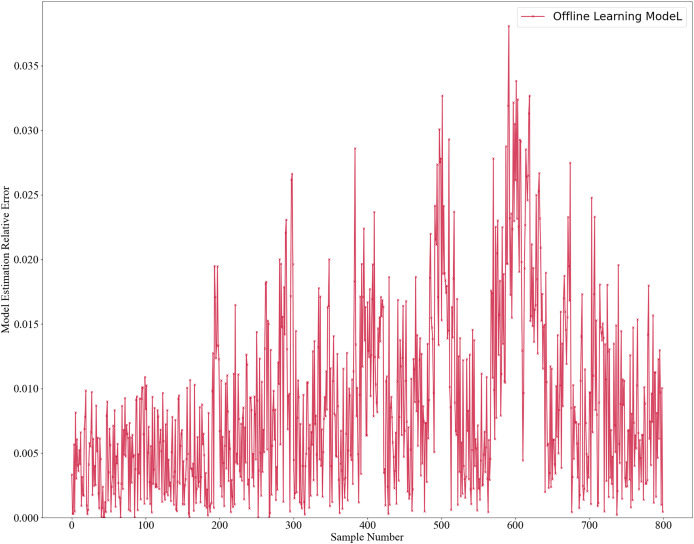 Figure 4
Figure 4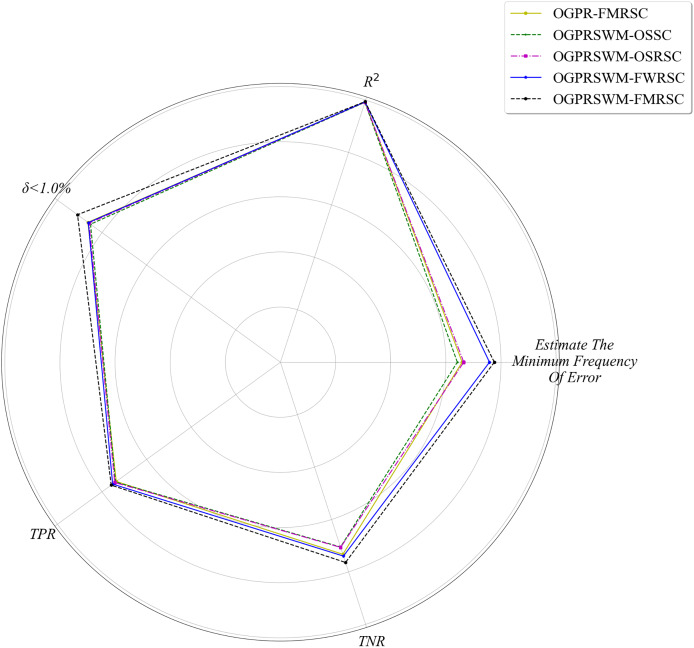 Figure 5
Figure 5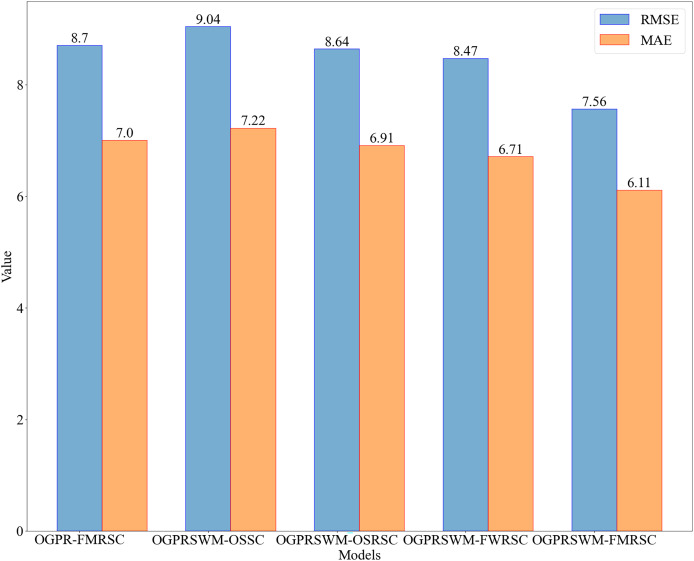 Figure 6
Figure 6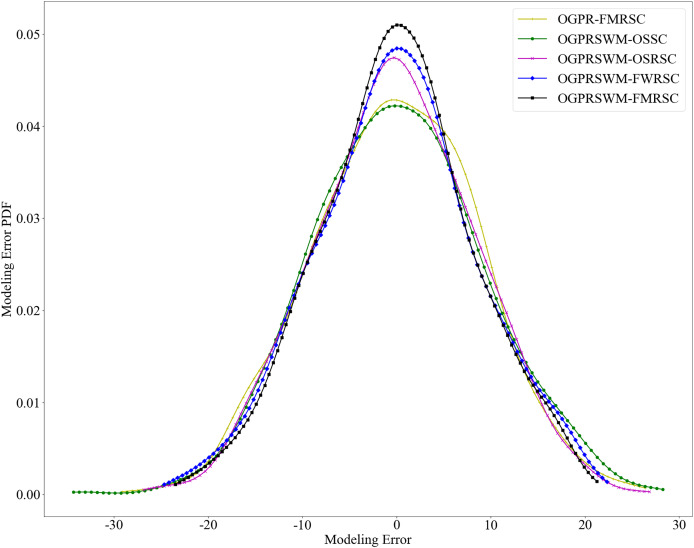 Figure 7
Figure 7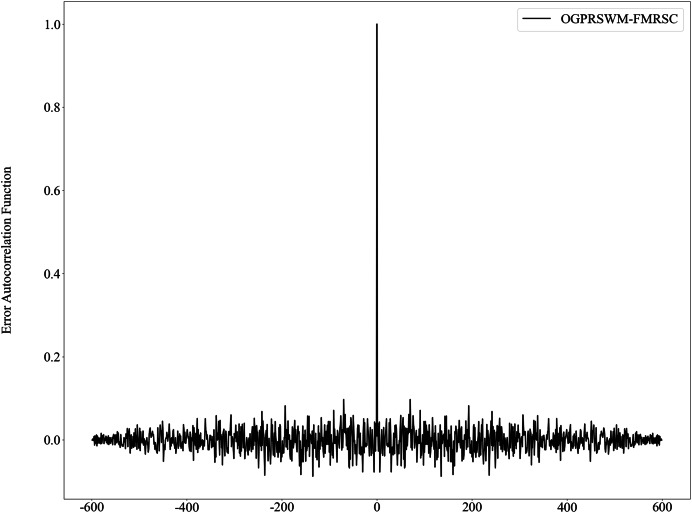 Figure 8
Figure 8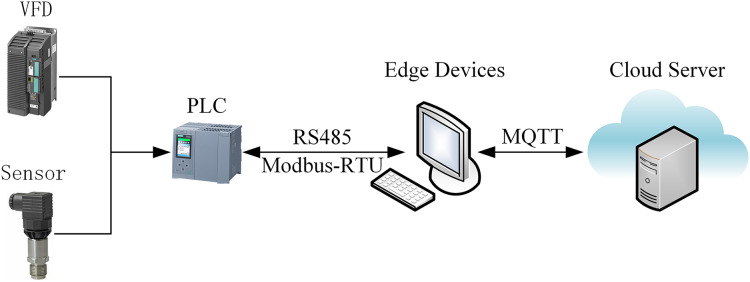 Figure 9
Figure 9 Figure 10
Figure 10 Figure 11
Figure 11 Figure 12
Figure 12- —National Natural Science Foundation of China
- —Fundamental Research Funds for the Central Universities of China
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsData Stream Mining Techniques · Network Security and Intrusion Detection · Anomaly Detection Techniques and Applications
Introduction
The mineral processing workflow comprises several stages, including raw ore transportation, crushing and screening, grinding and classification, beneficiation, and dewatering (Hodouin et al., 2001). Among these, grinding and classification serve as a critical link between crushing and beneficiation, significantly influencing the overall workflow. Key equipment in grinding operations includes ball mills and hydrocyclones, whose performance directly affects grinding efficiency (Mukhitdinov et al., 2024; Bradley, 2013). The hydrocyclone feed density is a vital parameter impacting its overflow particle size. Higher feed density increases slurry viscosity and resistance, resulting in coarser overflow particles and reduced classification efficiency. On the other hand, lower feed density improves classification efficiency but reduces throughput while increasing water and power consumption. Therefore, accurate monitoring and control of hydrocyclone feed density are essential for optimizing grinding and classification efficiency (Reddy et al., 2023).
Slurry density is a key metric in grinding and classification, directly influencing metal recovery rates, concentrate grades, production efficiency, and process stability (Whitworth et al., 2022). Current detection methods primarily rely on manual laboratory techniques and densitometers, with limited exploration of artificial intelligence (AI) applications. The pycnometer method is the most common manual technique, where a pycnometer is filled with slurry, weighed, and its density calculated using a formula. Densitometers, on the other hand, use precise instruments to determine material density based on physical principles. Recently, advances in AI technologies have enabled some innovative approaches for slurry density detection. For example, the combination of Prompt Gamma Neutron Activation Analysis (PGNAA) technology and artificial neural networks (ANN) has been proposed for online detection (Huang et al., 2024). Similarly, an approach based on closed-loop input error and deep learning offers a novel method for real-time slurry concentration prediction (Han et al., 2024).
In mineral processing, operational fluctuations such as variations in feed rate and water addition often lead to concept drift, causing slurry density detection models to degrade in performance (Bayram, Ahmed & Kassler, 2022). To address this issue, researchers have developed methods to enhance model adaptability to changing data distributions. These include selecting training samples that represent recent data distributions (Fan, 2004), employing online learning algorithms to update model parameters continuously, dynamically adjusting model structures for new data features (Yang & Fong, 2015), and applying weighted updates to reduce the influence of outdated data (Sen, 2014; Martínez-Rego et al., 2011). These techniques ensure model accuracy and adaptability in dynamic environments. This study investigates a modeling approach that combines mechanistic and data-driven methods to address the challenges of concept drift and meet the demands for accurate, real-time slurry density detection in mineral processing (Cui et al., 2024). We propose an online intelligent detection method for slurry density in concept drift data streams, leveraging collaborative computing. This approach is not limited to slurry density detection and can be extended to monitor other industrial process variables, enhancing the accuracy of industrial parameter detection and improving production efficiency (Wang et al., 2023).
Process description and characteristics analysis
Grinding and classification are among the most critical stages in mineral processing (Yuan et al., 2020). These stages typically involve a closed grinding circuit comprising ball mills, hydrocyclones, and slurry pumps. The primary grinding circuit includes a ball mill and a spiral classifier, while the secondary circuit consists of a ball mill, hydrocyclone, and pump sump. In the primary circuit, ore is mixed with water and ground in the ball mill, after which the slurry is classified by the spiral classifier. Coarse particles are returned to the ball mill for further grinding, while finer particles proceed to the secondary circuit. In the sump, additional water is added, and the slurry is pumped into the hydrocyclone. The hydrocyclone uses centrifugal force to separate the slurry, discharging coarse particles for further grinding and sending finer particles to subsequent beneficiation processes (Wang & Chai, 2019).
The mechanistic analysis of slurry flow in pipelines focuses on selecting auxiliary variables and building a comprehensive model for slurry density detection (Ma, Wang & Peng, 2024). Resistance losses are categorized based on boundary conditions. For smooth boundaries, frictional resistance arises from boundary-fluid interactions and fluid viscosity. Local resistance losses occur due to sudden boundary changes, such as pipe bends, valves, or cross-sectional variations, which can alter flow paths and velocities, potentially causing vortices. Since slurry density detection is performed in vertical pipelines, local resistance losses are negligible, and only frictional resistance losses are included in calculations (Peet, Sagaut & Charron, 2009).
In an ideal scenario without resistance losses, the pressure difference is given by:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} $$\Delta p = \rho g \Delta H.$$\end{document}In Eq. (1), \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \rho\end{document} is the slurry density, g is gravitational acceleration, and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \Delta H\end{document} is the height difference of the liquid surface. During slurry flow, frictional resistance losses occur, which are described by:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} $${H_f} = \gamma \displaystyle{L \over D}\displaystyle{{{V^2}} \over {2g}}.$$\end{document}In Eq. (2), \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \gamma\end{document} is the frictional resistance coefficient, L is the pipe length, D is the pipe diameter, V is the average flow velocity, and g is gravitational acceleration. In actual industrial processes, the total pressure difference \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \Delta p = \rho g\Delta H - {H_f}\end{document} can be expressed as:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} $$\rho = \displaystyle{{\Delta p + {H_f}} \over {g\Delta H}}.$$\end{document}In industrial production, density measurement commonly relies on pressure differential signals from sensors placed at different heights. However, directly using these signals as inputs for detection models may reduce accuracy (Li et al., 2020). According to Bernoulli’s principle, the total pressure in a fluid remains constant; as flow velocity increases, static pressure decreases. Slurry pressure meters, however, measure only static pressure.
As inlet velocity rises, the dynamic pressure difference between two points also increases. Traditional pressure sensors convert pressure into electrical signals by inducing deformation in a force-sensitive element, which changes resistance in a Wheatstone bridge and generates a potential difference output (Xu et al., 2018). While effective for measuring static pressure differences, this method cannot capture dynamic pressure changes, potentially reducing measurement accuracy if differential signals are used directly in density models. Additionally, system and random errors in pressure measurements necessitate corrections to the high-pressure side absolute pressure \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} {p_H}\end{document} and the low-pressure side absolute pressure \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} {p_L}\end{document} . The pressure difference \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \Delta p(t) = {p_H}(t) - {p_L}(t)\end{document} measured at time t is adjusted as follows:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} $$\Delta p(t) = A{p_H}(t) - B{p_L}(t) + C + {l_1}({p_H}(t),{p_L}(t)).$$\end{document}In Eq. (4), A and B are correction coefficients for high pressure and low pressure, respectively; C is the offset term, and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} {l_1}( \cdot )\end{document} represents unknown nonlinear errors in pressure measurement. The average flow velocity V has a nonlinear relationship with the slurry pump current i and frequency f:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} $$V(t) = {l_2}(f(t),i(t)).$$\end{document}This relationship can be expressed as follows:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} $$\rho (t) = {\rho _0}(t) + \Delta\rho (t).$$\end{document}In Eq. (6),
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} $\eqalign{& {\rho _0}(t) = {k_1}{p_H}(t) + {k_2}{p_L}(t) + {k_3} \cr & \Delta\rho (t) = l\left( {{p_H}(t),{p_L}(t),f(t),i(t)} \right) \cr & {k_1} = \displaystyle{A \over {g\Delta H}},{k_2} = - \displaystyle{B \over {g\Delta H}},{k_3} = \displaystyle{C \over {g\Delta H}}(g\Delta H > 0) \cr & l( \cdot ) = \displaystyle{{{l_1}\left( {{p_H}(t),{p_L}(t)} \right)} \over {g\Delta H}} + \displaystyle{{\gamma Ll_2^2\left( {f(t),i(t)} \right)} \over {2{g^2}D\Delta H}}}$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} l( \cdot )\end{document} includes measurement errors and unknown nonlinear terms in the slurry flow process.
Mechanism and data-driven online intelligent detection method for slurry
Classification and handling methods of concept drift
In industrial environments, slurry density detection models face the challenge of concept drift, which refers to dynamic changes in data distribution or characteristics over time. Concept drift often arises from external factors such as variations in raw material properties, production processes, or equipment aging. To maintain prediction accuracy, detection models must adapt continuously to these evolving conditions.
Concept drift is generally categorized as follows:
- 1)Sudden drift: This involves rapid and significant changes in data features over a short time, often caused by abrupt shifts in raw material properties, equipment failures, or emergency adjustments. Such changes can lead to sudden prediction errors, requiring models to quickly adapt.
- 2)Gradual drift: Gradual drift occurs when data features evolve slowly over time, such as equipment aging or long-term fine-tuning of process parameters. Although these changes may not immediately affect data distribution, model performance will degrade if left unaddressed. Dynamic update mechanisms are commonly used to adapt to these gradual changes.
- 3)Incremental drift: This refers to stable, cumulative changes in data distribution, such as progressive variations in slurry concentration across production batches. While each change is small, the cumulative effect can shift the data distribution, necessitating models capable of incremental learning.
- 4)Recurrent drift: Recurrent drift arises from cyclical factors like periodic equipment cleaning or routine production adjustments. Handling this type of drift requires models to recognize and leverage cyclical patterns to make appropriate adjustments.
In industrial slurry density detection, concept drift is common and often involves multiple drift types coexisting, placing high demands on model robustness and adaptability. In this study, the dataset primarily exhibits sudden and gradual drift. Sudden drift arises from abrupt changes in raw material properties, equipment failures, or emergency operational adjustments, leading to rapid shifts in data features. Gradual drift, in contrast, involves slow changes over time due to equipment aging or minor adjustments in process parameters. To address these drift types, the proposed detection model incorporates a sliding window mechanism and a forgetting mechanism to dynamically update model parameters. For sudden drift, the sliding window mechanism focuses on recent data, discarding outdated information to enable quick adaptation to abrupt changes. The window size is dynamically adjusted to promptly capture new feature distributions during drift events. Recursive formulas are also used to update key parameters online, ensuring the model responds without delays. For gradual drift, the forgetting mechanism reduces the weight of historical data over time, enhancing the model’s sensitivity to current data. By dynamically adjusting the forgetting factor, the model ensures smooth updates for gradual changes while avoiding overreactions to short-term fluctuations. By combining these mechanisms, the proposed model effectively handles diverse types of concept drift in complex industrial environments, significantly improving the accuracy and stability of slurry density detection.
Establishing and calibrating the comprehensive model for slurry density
In dynamic data environments, concept drift occurs when the statistical properties of data change over time, posing challenges for density detection models. This article proposes an intelligent detection algorithm for streaming data, combining a mechanistic model based on Gaussian process regression (GPR) and a data-driven model (Wei et al., 2022) based on a regularized stochastic configuration (RSC) Network for offline learning (Zhang & Wang, 2021). Initially, a subset of the data is selected to establish the initial model. Subsequently, the linear and nonlinear models are updated with streaming data, and the results of both models are combined to obtain the final slurry density detection value (Zhang et al., 2024). As new samples arrive, the linear model parameters are updated online using a recursive formula, yielding a linear model estimate \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} {\hat \rho _0}\end{document} and its variance \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \sigma _{}^2\end{document} . The nonlinear model’s output weights are updated online using the teacher signal \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \Delta\bar{\rho} \left( {\Delta\bar{\rho} = \rho - {{\hat \rho }_0}} \right)\end{document} and the variance of the linear estimate \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \sigma _{}^2\end{document} as labels, without altering the model structure. This provides the nonlinear model’s density estimate \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \Delta\hat \rho\end{document} . If the estimate falls outside the confidence interval \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} [\Delta\bar{ \rho} - 3\sigma ,\Delta\bar{ \rho} + 3\sigma ]\end{document} , the nonlinear model structure is dynamically adjusted to improve generalization performance. Otherwise, the overall model is updated.
Mechanism-based model using online Gaussian process regression
The mechanistic model, representing the linear component, is based on the physical principles of slurry flow in pipelines (Lui, Liu & Xie, 2022). Using Gaussian process regression with a sliding window mechanism (OGPRSWM), the linear model updates its parameters in real-time. This approach reduces the influence of outdated data, improves parameter estimation, and ensures the model remains accurate and up-to-date (Gu, Fei & Sun, 2020).
Initially, GPR is employed to identify the linear component of slurry density (Cao et al., 2023). When input data \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} x{'_a}(k)\end{document} at time \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} t = k\end{document} is provided, the probability distribution of the mechanism model’s output can be obtained as follows:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} $$\eqalign{P\left( {{{\hat y}_a}(k)|x{^\prime_a}(k),X{^\prime_a}(k - 1),{Y_a}(k - 1)} \right) \hfill \cr \;\;= {\rm {\cal N}}\left( {\sigma _n^{ - 2}x{^\prime_a}(k){A^{ - 1}}X{^\prime_a}T(k - 1){Y_a}(k - 1),x{^\prime_a}(k){A^{ - 1}}x{^\prime_a}T(k)} \right).}$$\end{document}In Eq. (7), \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} A = {\Sigma ^{ - 1}} + \sigma _n^{ - 2}X{^\prime_a}T(k - 1)X{^\prime_a}(k - 1)\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} {N_t}\end{document} represents the total number of training samples in the data pool. \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} {X_a}(k - 1)\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} {Y_a}(k - 1)\end{document} denote the input and output data used for training the linear model up to a given time, respectively. \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} {x_a}(k - {i_1})\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} {y_a}(k - {i_1})\end{document} represent the input and output data for training the linear model at a specific time; \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} {\hat \rho _0}(k) = {\hat y_a}(k) = \sigma _n^{ - 2}x{^\prime_a}(k){A^{ - 1}}X{^\prime_a}T(k - 1){Y_a}(k - 1)\end{document} is the estimated result of the linear model, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} {\sigma ^2}(k) = x{^\prime_a}(k){A^{ - 1}}x{^\prime_a}T(k)\end{document} is the variance estimated by the Gaussian process regression.
Subsequently, an online Gaussian process regression with a sliding window mechanism is applied. During the initialization phase, dataset \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} { {X_b}(k - 1),{Y_b}(k - 1)}\end{document} is used to construct the initial linear model, and the posterior distribution of parameters is estimated using \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} {N_0}\end{document} , the number of training samples in the data pool. \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} {X_b}(k + {i_2})\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} {Y_b}(k + {i_2})\end{document} denote the input and output data for training the linear model up to time \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} k + {i_2}\end{document} , while \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} {x_b}(k + {i_2})\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} {y_b}(k + {i_2})\end{document} represent the input and output data at time \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} k + {i_2}\end{document} :
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} $$\eqalign{&P\left( {\hat \theta (k - 1)|{Y_b}(k - 1),X{^\prime_b}(k - 1)} \right) \hfill \cr & \;\;= {\rm {\cal N}}\left( {\displaystyle{1 \over {\sigma _n^2}}\; {A^{ - 1}}(k - 1)X{^\prime_b}T(k - 1){Y_b}(k - 1),{A^{ - 1}}(k - 1)} \right).}$$\end{document}In Eq. (8),
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} $\eqalign{X{^\prime_b}(k - 1) = {[x{^\prime_b}T(k - {N_0}),\ldots,x{^\prime_b}T(k - 2),x{^\prime_b}T(k - 1)]^T} \hfill \cr x{^\prime_b}(k + {i_2}) = [{p_H}(k + {i_2}),{p_L}(k + {i_2}),1] \hfill \cr A(k - 1) = {\Sigma ^{ - 1}} + \sigma _n^{ - 2}X{^\prime_b}T(k - 1)X{^\prime_b}(k - 1).\hfill}$\end{document}After adding new samples and discarding older historical data, dataset \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} { X{'_b}(k - 1),{Y_b}(k - 1)}\end{document} is updated to \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} { X{^{\prime\prime}b}(k),Y_b^{^\prime}(k)}\end{document} , The newly added sample is \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} { x{'b}(k),{y_b}(k)}\end{document} , and the discarded sample is denoted as \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} { X{'{drop}},{Y{drop}}}\end{document} ; Following the update of the data samples, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \sigma _n^{ - 2}\end{document} is updated to \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \sigma _n^{' - 2}\end{document} . The key issue in updating the linear model is to update \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} {A^{ - 1}}(k - 1)\end{document} to \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} {A^{ - 1}}(k)\end{document} , where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} A(k)\end{document} is:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} $$\eqalign{A(k) = {\Sigma ^{ - 1}} + \sigma _n^{^\prime - 2}X^{\prime\prime}_b T(k)X^{\prime\prime}_b(k) \hfill \cr \;\; = {\Sigma ^{ - 1}} + \sigma _n^{^\prime - 2}\sigma _n^2\left( {A(k - 1) - {\Sigma ^{ - 1}}} \right) + \sigma _n^{^\prime - 2}\left( {x{^\prime_b}T(k)x{^\prime_b}(k) - X{^\prime_{drop}}TX{^\prime_{drop}}} \right).}$$\end{document}The computational complexity of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} A(k)\end{document} primarily stems from matrix multiplication, with the original expression having a complexity of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} O(N_w^2 \times 3)\end{document} . Let \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} {N_w}\end{document} represent the sliding window size; the complexity of the recursive computation is \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} O\left( {\left( {N_{drop}^2 + 1} \right) \times 3} \right)\end{document} . Based on \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} N_w^2 ;> !!> N_{drop}^2 + 1\end{document} , the derived recursive formula is used for online updates of the linear model to reduce computational load and improve efficiency. By performing matrix inversion on \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} A(k)\end{document} , the updated parameters are obtained, and the estimated density value and variance for the new incoming data sample \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} x{'_{on,lin}}(k + 1)\end{document} are calculated as follows:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} $$\eqalign{&{{\hat \rho }_b}(k + 1) = \sigma_n^{ - 2}x{^\prime_b}(k + 1){A^{ - 1}}(k)X^{\prime\prime}_b T(k)Y_b^{^\prime}(k) \cr & {\sigma ^2}(k + 1) = x{^\prime_b}(k + 1){A^{ - 1}}(k)x{^\prime_b}T(k + 1).}$$\end{document}Data-driven model based on online regularized stochastic configuration networks
This article presents a novel learning algorithm, the Forgetting Mechanism Regularized Stochastic Configuration (FMRSC) algorithm, to address concept drift and enable online learning for data-driven models based on Regularized Stochastic Configuration (RSC) Networks (Luo et al., 2022). Unlike the Online Sequential Stochastic Configuration (OSSC) algorithm (Chen & Li, 2022), the proposed FMRSC method processes streaming data without requiring the retraining of the entire historical dataset. It achieves this by integrating regularization and forgetting mechanisms into the OSSC algorithm. Additionally, FMRSC dynamically adjusts the model structure using network pruning and stochastic configuration to handle concept drift effectively. This approach leverages recent data, minimizes reliance on outdated information, and enhances processing efficiency and adaptability (Dai, Liu & Wang, 2024).
Online parameter update strategy
The RSC algorithm, used as the data-driven method in this study, is an improved version of the Stochastic Configuration Network (SCN) (Wang & Li, 2017). By incorporating regularization techniques, RSC effectively mitigates overfitting, producing more robust and generalized neural network models.
The output \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} {h_L}\end{document} of the hidden layer node \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} L\end{document} and the supervision mechanism \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} {\xi _{L,q}}\end{document} , q = 1, 2 are defined as follows:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} $${{h_L} = \left[ {{g_L}\left( {\omega _L^T{x_c}(k - 1) + {b_L}} \right),{g_L}\left( {\omega _L^T{x_c}(k - 2) + {b_L}} \right),} \right. \ldots, {\left. {{g_L}\left( {\omega _L^T{x_c}(k - N) + {b_L}} \right)} \right]^T}}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} $${\xi _{L,q}} = \displaystyle{{{{\left( {e_{L - 1,q}^T{h_L}} \right)}^2}} \over \gamma } - \left( {1 - r - {\mu _L}} \right)e_{L - 1,q}^T{e_{L - 1,q}},q = 1,2.$$\end{document}In Eqs. (11) and (12), \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \gamma = {(h_L^T \cdot {h_L} + 1/C)^2}/(h_L^T \cdot {h_L} + 2/C)\end{document} . Given \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} 1 - \varepsilon ;\lt; r ;\lt; 1\end{document} , let \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} {\mu L} = (1 - r)/(L + 1)\end{document} and C be the regularization coefficients. Then, perform \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} {T{\max }}\end{document} stochastic configurations. In each configuration, randomly select the input weights \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} {\omega _L}\end{document} and bias \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} {t_i}\end{document} for the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} L{\rm th}\end{document} hidden layer node within a certain range, and compute \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} {\xi _{L,q}},q = 1,2\end{document} . If \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \min {\xi _{L,1}},{\xi _{L,2}} \ge 0\end{document} is satisfied, store \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} {\omega _L}\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} {t_i}\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} {\xi _{L,q}}\end{document} ; if none of the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} {\xi _{L,q}}\end{document} configurations meet the condition, choose a larger \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} r\end{document} value and reconfigure. After completing the random configurations, select the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} {\omega L}\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} {b_L}\end{document} corresponding to the largest \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \sum\nolimits{q = 1}^2 {{\xi _{L,q}}}\end{document} as the input weights and bias for the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} L{\rm th}\end{document} node.
The estimated value of the data-driven model at time \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} t = k\end{document} is expressed as:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} $$\Delta\hat \rho (k) = \sum\limits_{j = 1}^L {{\beta _j}} {g_j}\left( {\omega _j^T{x_c}(k) + {b_j}} \right).$$\end{document}Next, the parameters are updated online using a forgetting mechanism. Given dataset \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} { {X_d}(k + {N_{str}} - 1),{Y_d}(k + {N_{str}} - 1)}\end{document} , during the initialization phase of the nonlinear model, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} { {X_d}(k - 1),{Y_d}(k - 1)}\end{document} is used to construct the initial nonlinear model. Here, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} {X_d}(k + {i_2})\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} {Y_d}(k + {i_2})\end{document} denote the input and output data for training the nonlinear model up to time \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} k + {i_2}\end{document} , and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} {x_d}(k + {i_2})\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} {y_d}(k + {i_2})\end{document} represent the input and output data at time \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} k + {i_2}\end{document} . If a regularized random configuration network with \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} L\end{document} hidden layer nodes is constructed based on these \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} {N_0}\end{document} sets of training data, the optimization objective for the output layer weights \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} {\beta _{k - 1}}\end{document} is as follows:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} $${\beta _{k - 1}} = \arg \mathop {\min }\limits_{{\beta _{k - 1}}} \left( {{{\left\| {{H_{k - 1}}{\beta _{k - 1}} - {Y_d}(k - 1)} \right\|}^2} + \displaystyle{1 \over C}{{\left\| {{\beta _{k - 1}}} \right\|}^2}} \right).$$\end{document}Let \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} {H_{k - 1}}\end{document} represent the output of the hidden layer nodes of the nonlinear model initialized with training data from Group \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} {N_0}\end{document} . Let \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} C\end{document} denote the regularization term coefficient. The solution can be obtained as follows:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} $${\beta _{k - 1}} = {\left( {{H_{k - 1}}^T{H_{k - 1}} + \displaystyle{E \over C}} \right)^{ - 1}}{H_{k - 1}}^T{Y_d}(k - 1).$$\end{document}When data from Group \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} ({N_0} + 1){\rm th}\end{document} reaches the model, it is necessary to update the weights with the latest data. To mitigate the influence of past data on the model parameter updates, a forgetting mechanism has been introduced. Given the fixed structure of the neural network and the constant weights of the input layer, the optimization objective for obtaining new output layer weights \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} {\beta _k}\end{document} is as follows:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} $${\beta _k} = \arg \mathop {\min }\limits_{{\beta _k}} {\mkern 1mu} \left( {{\theta _k}{{\left\| {{H_{k - 1}}{\beta _k} - {Y_d}(k - 1)} \right\|}^2} + {{\left\| {{h_k}{\beta _k} - {y_d}(k)} \right\|}^2} + \displaystyle{1 \over C}{{\left\| {{\beta _k}} \right\|}^2}} \right).$$\end{document}Let \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} {\theta k}\end{document} represent the forgetting factor, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} {h_k}\end{document} represent the hidden layer node outputs calculated from the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} ({N_0} + 1){\rm th}\end{document} Group dataset, and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} {H_k} = {[H{k - 1}^T,h_k^T]^T}\end{document} be given.
The solution can be obtained as follows:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} $${\beta _k} = {\left( {{H_k}^T\Theta _k^T{\Theta _k}{H_k} + \displaystyle{E \over C}} \right)^{ - 1}}{H_k}^T\Theta _k^T{\Theta _k}{Y_d}(k).$$\end{document}In Eq. (17), \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} {\Theta _k} = {\rm diag}{ \sqrt {{\theta _k}} ,\sqrt {{\theta _k}} ,\ldots,\sqrt {{\theta _k}} ,\sqrt {{\theta _k}} ,1}\end{document} .
Let \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} {P_{k - 1}} = H_{k - 1}^T{H_{k - 1}},\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} {P_k} = \theta k^2H{k - 1}^T{H_{k - 1}} + h_k^T{h_k} = \theta k^2{P{k - 1}} + h_k^T{h_k}\end{document} , then we obtain:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} $$\eqalign{&{\beta _k} = {\left( {{P_k} + \displaystyle{E \over C}} \right)^{ - 1}}\left( {\theta _k^2\left( {{P_{k - 1}} + \displaystyle{E \over C}} \right){\beta _{k - 1}} + h_k^T{y_d}(k)} \right) \cr& = {\beta _{k - 1}} + {\left( {{P_k} + \displaystyle{E \over C}} \right)^{ - 1}}\left( {\displaystyle{{\theta _k^2 - 1} \over C}{\beta _{k - 1}} + h_k^T\left( {{y_d}(k) - {h_k}{\beta _{k - 1}}} \right)} \right).}$$\end{document}From this, we can derive the recursive formula for the output weights that incorporates a forgetting mechanism. Similarly, when the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} ({N_0} + {i_2}){\rm th}\end{document} dataset is fed into the model, we have:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} $${\beta _{k + {i_2}}} = {\left( {H_{k + {i_2}}^T\Theta _{k + {i_2}}^T{\Theta _{k + {i_2}}}{H_{k + {i_2}}} + \displaystyle{E \over C}} \right)^{ - 1}}{H_{k + {i_2}}}^T\Theta _{k + {i_2}}^T{\Theta _{k + {i_2}}}{Y_d}(k + {i_2}).$$\end{document}In Eq. (19), \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} {\Theta {k + {i_2}}} = {\rm diag}{ \sqrt {\prod\limits{s = 0}^{{i_2}} {{\theta {k + s}}} } ,\dots ,\sqrt {\prod\limits{s = 0}^{{i_2}} {{\theta {k + s}}} } ,\sqrt {\prod\limits{s = 1}^{{i_2}} {{\theta {k + s}}} } ,\sqrt {\prod\limits{s = 2}^{{i_2}} {{\theta {k + s}}} } ,\cdots ,\sqrt {\prod\limits{s = i}^{{i_2}} {{\theta _{k + s}}} } ,1}\end{document} .
The recursive formula for \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} {\beta _{k + {i_2}}}\end{document} is:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} $${\beta _{k + {i_2}}} = {\beta _{k + {i_2} - 1}} + {\left( {{P_{k + {i_2}}} + \displaystyle{E \over C}} \right)^{ - 1}}\left( {\displaystyle{{\theta _{k + {i_2}}^2 - 1} \over C}{\beta _{k + {i_2} - 1}} + h_{k + {i_2}}^T\left( {{y_d}(k + {i_2}) - {h_{k + {i_2}}}{\beta _{k + {i_2} - 1}}} \right)} \right)$$\end{document}In Eq. (20), \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} {P_{k + {i_2}}} = \theta {k + {i_2}}^2H{k + {i_2} - 1}^T{H_{k + {i_2} - 1}} + h_{k + {i_2}}^T{h_{k + {i_2}}} = \theta {k + {i_2}}^2{P{k + {i_2} - 1}} + h_{k + {i_2}}^T{h_{k + {i_2}}}\end{document} .
Dynamic adjustment strategy for model structure
Online adjustment of output layer parameters helps the model adapt to new data. However, as operational conditions change and data distributions shift, the neural network may struggle to handle new data characteristics. To address this, a dynamic structural adjustment strategy based on network pruning is proposed. This strategy optimizes the model structure and parameters, enhancing the adaptability of Stochastic Configuration Networks.
Assuming that a regularized stochastic configuration network with L hidden layer nodes has been constructed based on the training data set \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} {N_0}\end{document} , the output of the neural network is given by:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} $$F_{L,0}^T\left( {{X_d}(k - 1)} \right) = \sum\limits_{j = 1}^L {{\beta _{j,0}}} {g_{j,0}}(\omega _{j,0}^TX_d^T(k - 1) + {b_{j,0}}).$$\end{document}In Eq. (21), \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} F_{L,0}^T\left( {{X_d}(k - 1)} \right)\end{document} represents the output of a regularized stochastic configuration network without network structure adjustment, while \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} {\beta {j,0}},{g{j,0}},{\omega {j,0}},{b{j,0}},j\end{document} represents the output weight of the hidden node \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} j\end{document} , the activation function of the hidden node \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} j\end{document} , the input weight of the hidden node \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} j\end{document} , and the bias of the hidden node \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} j\end{document} , respectively. When new data flows into the model and the accuracy remains unsatisfactory after updating the parameters of both the linear and nonlinear models, an adjustment of the structure of the nonlinear model is necessary. The adjustment criterion can be described as follows:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} $$\left\| {F_{L,0}^T\left( {{x_d}(k)} \right) - \Delta\bar \rho (k)} \right\| > 3\sigma (k).$$\end{document}When the difference between the estimated values of the nonlinear model and the nonlinear labels exceeds three standard deviations, the model structure requires a dynamic adjustment. After pruning the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} I{\rm th}\end{document} hidden node, the model output is:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} $$F_{L - 1,1}^{^\prime T}\left( {{x_d}(k)} \right) = \sum\limits_{j = 1}^L {{\beta _{j,0}}} {g_{j,0}}(\omega _{j,0}^Tx_d^T(k) + {b_{j,0}}) - \beta _{I,1}^{^\prime}g_{I,1}^{^\prime}(\omega _{I,1}^{^\prime T}x_d^T(k) + b_{I,1}^{^\prime}).$$\end{document}Thus, the change in network residual can be expressed as:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} $$\Delta{F_I} = \left\| {{Y_d}(k) - F_{L - 1,1}^{'T}\left( {{x_d}(k)} \right)} \right\|.$$\end{document}By comparing the impact of each hidden layer node on the change in model output residuals and sorting them by \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \Delta{F_{(1)}} < \Delta{F_{(2)}} < \cdots < \Delta{F_{(L)}}\end{document} , we select and prune the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} {N_{prun}}\end{document} nodes with the least impact. The value of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} {N_{prun}}\end{document} satisfies \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \Delta{F_{({N_{prun}})}}/\left| {F_{L,0}^T\left( {{x_d}(k)} \right)} \right| < {\sigma p}/L\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \Delta{F{({N_{prun}} + 1)}}/\left| {F_{L,0}^T\left( {{x_d}(k)} \right)} \right| > {\sigma p}/L\end{document} , where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} {\sigma p}\end{document} is the pruning coefficient that determines the number of nodes to be pruned. After pruning, the output of the nonlinear model is represented as \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} F{L - {N{prun}},1}^{'T}\left( {{X_d}(k)} \right)\end{document} , and the current network residual is as follows:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} $$e_{L - {N_{prun}}}^\prime = F_{L - {N_{prun}},1}^{^\prime T}\left( {{X_d}(k)} \right) - {Y_d}(k) = \left[ {e_{L - {N_{prun}},1}^\prime ,e_{L - {N_{prun}},2}^\prime } \right].$$\end{document}Incorporating new nodes based on the supervision mechanism. Subsequently, compute the output weights as follows:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} $${\beta _{k,L - {N_{prun}} + 1}} = {\left( {H^\prime_{k,L - {N_{prun}} + 1}T \cdot H{^\prime_{k,L - {N_{prun}} + 1}} + \displaystyle{E \over C}} \right)^{ - 1}}{H^\prime_{k,L - {N_{prun}} + 1}}T{\Theta _k}{Y_d}(k).$$\end{document}\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} H{^\prime_{k,L - {N_{prun}} + 1}} = [h{^\prime_{k,1}},h{^\prime_{k,2}},\ldots,h{^\prime_{k,L - {N_{prun}} + 1}}]\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} {h_{k,L - {N_{prun}} + 1}}\end{document} denotes the hidden layer output of the nonlinear model at the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} (L - {N_{prun}} + 1){\rm th}\end{document} hidden node trained using dataset \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} {N_0} + 1\end{document} . After incorporating the new nodes, the network output is:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} $$F_{L - {N_{prun}} + 1,1}^T\left( {{X_d}(k)} \right) = \sum\limits_{j = 1}^{L - {N_{prun}} + 1} {{\beta _{j,1}}} {g_{j,1}}(\omega _{j,1}^TX_d^T(k) + {b_{j,1}}).$$\end{document}Next, determine if the network output error meets the predefined error criteria. If the criteria are satisfied, the model construction is complete; otherwise, new hidden layer nodes will be added based on a supervisory mechanism to minimize the output error until the termination condition is met.
Adaptive intelligent detection method for slurry density based on collaborative computing
With the rapid advancement of Internet of Things (IoT) technology, we have entered an era of ubiquitous connectivity. Innovations such as cloud computing, big data, and artificial intelligence are transforming industrial applications through Internet platforms. In this context, edge-cloud collaboration has emerged as a crucial technology. Unlike traditional frameworks, edge computing enhances data processing by performing initial tasks near the data source (e.g., equipment or sensors). Edge devices handle data acquisition and preliminary analysis, while edge control systems conduct initial data processing. This reduces the burden on central cloud servers, improving processing speed and efficiency. By addressing the limitations of traditional edge-cloud collaboration in real-time data processing, this approach enables efficient, real-time analysis and decision-making (Zhou et al., 2021). Edge-cloud collaboration has advanced industrial automation and intelligence, laying a strong foundation for Industry 4.0.
As illustrated in Fig. 1, the proposed online intelligent detection method for slurry density uses an edge-cloud collaborative framework to enhance real-time monitoring and intelligent analysis. Edge devices acquire and preprocess data, ensuring system stability and responsiveness. The edge control system processes data, runs online detection models, and allows operators to monitor key parameters such as slurry pump current, frequency, pressure, and density in real time. Operators can also input manual assay values via an interactive interface for model updates. The edge system’s low latency and real-time capabilities meet the demands of industrial environments. Meanwhile, the cloud platform provides centralized computing power, managing databases and running slurry density detection software. It updates the initial model offline or online and deploys the updated model back to the edge for real-time detection. This architecture leverages the cloud’s robust resources for iterative model optimization and centralized data management.
Collaborative computing-based pulp density intelligent detection system structure diagram.
Experimental analysis
The process data in this study were collected from the grinding and classification stages of an actual mineral processing operation using industrial instruments. High-pressure sensors, low-pressure sensors, motor current, and motor voltage transmitted data via 4-20 mA signals to a Siemens S7-1500 PLC. The PLC used the Modbus-RTU protocol to communicate with edge servers, transferring real-time field data. These data captured various operating conditions, such as changes in raw ore properties, equipment aging, and fluctuations in process parameters. Manual data were obtained through periodic on-site assays, covering slurry densities ranging from 1,000 to 1,500 kg/m^3^. Variations were influenced by operational changes, such as the addition of ore or water. Measurement errors, caused by instrument limitations and environmental factors, were inevitable. To improve model performance, significant outliers were removed by cross-referencing with manual assay results. The cleaned dataset contained 800 samples, split in a 1:3 ratio for initial model training and streaming data. Min-Max Normalization was applied to remove dimensional unit interference and standardize the data for model training. Let \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} X = [{P_H},{P_L},f,I]\end{document} , and the data were processed using Eq. (28):
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} $${X^\prime } = \displaystyle{{X - \min (X)} \over {\max (X) - \min (X)}}.$$\end{document}The dataset exhibited both sudden and gradual concept drift. Sudden drift resulted from abrupt changes, such as ore property variations, equipment failures, or emergency operational adjustments. Gradual drift arose from factors like equipment aging or long-term parameter fine-tuning. During the evaluation phase, the dataset was fed sequentially into the model as a data stream, maintaining the chronological order of collection. After processing each data point, the estimation error was calculated, and the model was updated. RMSE and MAE were computed cumulatively to compare different models’ performance, demonstrating the proposed method’s robustness under various drift scenarios.
The initial model was trained using two offline learning methods: GPR for the mechanistic model and RSC Network for the data-driven model. Once trained, the model is not further updated. The model estimates’ results are shown in Fig. 2, with absolute errors in Fig. 3 and relative errors in Fig. 4. In the first 180 samples, conditions were relatively stable, and the model achieved high accuracy, with most absolute errors under 10 and relative errors below 1%. However, for samples 180–200, significant operational changes led to poor estimates, suggesting the model failed to capture new data distribution features. In the remaining dataset, the model’s performance deteriorated further, highlighting the need for continuous learning to address frequent changes in operational conditions. This degradation reflects a concept drift phenomenon. To mitigate this, we propose an algorithm enabling online updates to adapt quickly to new distributions, ensuring high performance in industrial applications.
Offline learning model estimation results.
Absolute error estimation of offline learning model.
Relative error estimation of offline learning model.
To demonstrate the effectiveness and superiority of the proposed intelligent detection method for concept drift data streams, we compared our method, OGPRSWM-FMRSC, with several other models. The linear model used is the online Gaussian process regression with sliding window mechanism (OGPRSWM), and the nonlinear model is a Regularized Stochastic Configuration Network (RRCN) with a forgetting mechanism. The alternative models evaluated include OGPR-FMRSC, which uses a standard Online Gaussian Process Regression (OGPR) without the sliding window, retaining historical data. The key parameter update formula is shown in Eq. (29), and the nonlinear model is the same as our proposed algorithm.
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} $$\eqalign{&A(k) = {\Sigma ^{ - 1}} + \sigma _n^{^\prime - 2}X{^\prime_b}T(k)X{^\prime_b}(k) \hfill \cr & \;\;= {\Sigma ^{ - 1}} + \sigma _n^{^\prime - 2}\sigma _n^2\left( {A(k - 1) - {\Sigma ^{ - 1}}} \right) + \sigma _n^{^\prime - 2}x{^\prime_b}T(k)x{^\prime_b}(k).}$$\end{document}OGPRSWM-OSSC uses OGPRSWM for the linear model and an Online Sequential Stochastic Configuration Network (OSSC) for the nonlinear model. OGPRSWM-OSRSC utilizes OGPRSWM for the linear model and an Online Sequential Regularized Stochastic Configuration Network (OSRSC) for the nonlinear model. The output weights are updated online as follows:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} $${\beta _k} = {\beta _{k - 1}} + {\left( {{P_k} + \displaystyle{E \over C}} \right)^{ - 1}}h_k^T\left( {{y_d}(k) - {h_k}{\beta _{k - 1}}} \right).$$\end{document}In Eq. (30), \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} {P_k} = H_{k - 1}^T{H_{k - 1}} + h_k^T{h_k} = {P_{k - 1}} + h_k^T{h_k}\end{document} ; OGPRSWM-FWRSC incorporates OGPRSWM for the linear model and updates the output weights of the nonlinear model using the proposed online update method without dynamic structural adjustments. We evaluated the models using metrics such as R^2^, minimum error frequency, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} {{\rm P}_{\delta < 1.0% }}\end{document} , MAE, RMSE, true positive rate (TPR), true negative rate (TNR), and mean relative error (MRE).
Figure 5 compares R^2^, minimum error frequency, TPR, TNR, and A across different models, while Fig. 6 compares RMSE and MAE. Overall, OGPRSWM-FMRSC outperformed the other models in all metrics. Specifically, the sliding window mechanism in OGPRSWM-FMRSC proved effective in handling concept drift, as evidenced by its superior performance compared to OGPR-FMRSC. The comparative performance of OGPRSWM-FMRSC, OGPRSWM-FWRSC, OGPRSWM-OSRSC, and OGPRSWM-OSSC sequentially declined, highlighting the importance of dynamic structure adjustment and the combination of the forgetting mechanism with regularized least squares in enhancing model performance.
Comparison of different models in terms of R2, minimum estimation error frequency, TPR, TNR and Pδ<1.0%.
Comparison of RMSE and MAE among different models.
Table 1 presents the performance evaluation metrics of the five models for slurry density detection. The initial condition of the test dataset is labeled as Condition 1, with subsequent significant density changes due to sample addition labeled as Conditions 2, 3, and 4. Condition 5 begins around sample number 680, reflecting multiple sample additions over a short period. Table 2 shows the MRE of each model under different conditions. OGPRSWM-FMRSC demonstrated superior performance, with the lowest MAE and RMSE of 6.11 and 7.56, respectively. Its R^2^ value reached 99.40%, indicating a high fit between the model’s estimates and actual data. The OGPRSWM-FMRSC model also had 91% of samples with a relative error below 1.0%, and its TPR and TNR were 75.88% and 76.39%, respectively, outperforming the other models.
Table 1: Model evaluation results.
Table 2: Model evaluation for MRE under different operating conditions.
Figure 7 presents the probability density function of estimation errors for the five models. The error distribution for OGPRSWM-FMRSC is centered around zero and exhibits a unimodal peak consistent with Gaussian distribution characteristics, suggesting that the error sequence approximates randomness. Figure 8 presents the autocorrelation function of OGPRSWM-FMRSC’s error, indicating that it approaches white noise levels, with errors primarily attributed to random factors rather than poor model generalization. This suggests that OGPRSWM-FMRSC has superior estimation and generalization capabilities, making it more suitable for dynamic industrial environments and potentially more stable under specific conditions compared to the other models.
Comparison of estimation error PDFs for different models.
Self-correlation function of estimation error for the OGPRSWM-FMRSC model.
Industrial application analysis
In industrial applications, the Siemens S7-1500 PLC interfaces with edge devices via the RS485 bus and Modbus-RTU protocol to collect and transmit real-time field data. Edge devices utilize TIAV16 and Modscan32 software to simulate Modbus communication, enabling remote monitoring and control of field equipment. The edge data is transmitted to the cloud for analysis and storage using a proprietary cloud protocol, as illustrated in Fig. 9. To enable online slurry density detection and provide a intuitive interface, a software application based on Vue, Spring Boot, and Flask frameworks was developed. This software supports data visualization, storage, and query functions. It has been deployed for over 5 months at a beneficiation plant in Shenyang. The interface design and human-machine interaction prioritize efficiency and ease of use, optimizing operational procedures, reducing operational difficulty, and significantly reducing the frequency of operator errors, thereby enhancing operational safety and production efficiency. As shown in Fig. 10, the real-time slurry density detection module displays the slurry density trend calculated by the intelligent detection model alongside scatter points representing manually obtained density values. By hovering the mouse over any data point reveals the specific slurry density value at that point. Figure 11 illustrates a table from the software interface, showing the most recent nine sets of comparison values obtained through random sampling and testing post-system deployment. In these nine sets, the relative error between the estimated slurry density and the actual test results did not exceed 1%. Figure 12 illustrates a bar chart distribution of the slurry density estimation errors over the 5 months of operation, and Table 3 details the corresponding error analysis data. With an acceptable relative error threshold of less than 2%, all months showed a qualification rate above 95%, indicating that the proposed adaptive intelligent detection system based on collaborative computing performed effectively in industrial settings, significantly enhancing production efficiency.
Hardware platform framework.
Pulp density real-time monitoring module demonstration.
Sampling inspection result table.
Bar chart of the pulp density estimation error after more than 5 months of operation.
Table 3: Analysis of the pulp density estimation error after more than 5 months of operation.
Conclusion
This study addresses concept drift in slurry density detection models within industrial environments and proposes an intelligent detection algorithm for concept drift data streams. Operational changes over time often lead to a gradual decline in model performance. To address this, a sliding window mechanism is incorporated into the linear model, with recursive formulas derived for real-time parameter updates. This approach minimizes the impact of outdated data on current model accuracy. For nonlinear models, a forgetting mechanism is introduced, with recursive formulas developed for online updating of output weights, reducing the influence of historical data on new detections. Additionally, network pruning and stochastic configuration methods are used to optimize the model structure, enhancing its adaptability to new data distributions. Weighted least squares and regularization methods are integrated during the stochastic configuration process to evaluate output weights, improving the model’s generalization capabilities. Experimental results show that the proposed method achieves superior accuracy and stability when handling concept drift, significantly improving the reliability of slurry density detection. This research has both academic significance and industrial value. The real-time update algorithm enhances slurry density detection precision and stability, providing an efficient monitoring tool for production processes. Accurate slurry density detection is vital for optimizing process parameters, improving coal preparation accuracy, and minimizing resource waste. By quickly responding to operational changes, the proposed method prevents fluctuations in concentrate quality caused by detection errors, improving production controllability. Its low computational cost makes it suitable for real-time industrial applications, while also reducing resource waste and the need for frequent manual adjustments or shutdown maintenance in high-frequency production scenarios. Beyond slurry density detection, the proposed model framework is versatile and can be applied to other industrial domains. For example, it can be used for sensor data monitoring in equipment fault prediction and dynamic load regulation in energy management. By addressing concept drift effectively, this method adapts to various complex industrial scenarios, providing robust support for intelligent manufacturing in the Industry 4.0 era.
Supplemental Information
10.7717/peerj-cs.2683/supp-1Supplemental Information 1Datasets.The results of the offline model running on the test set; the raw data for the tables in the article; the processed dataset used in this article; the experimental results.
10.7717/peerj-cs.2683/supp-2Supplemental Information 2Code.The algorithm can be executed using ‘the_proposed_algorithm.py’ function. The experimental results are visualized using two scripts: ‘visualization_of_experimental_results_1.py’ and ‘visualization_of_experimental_results_2.py’.The ‘tabular_data.py’ script corresponds to the data used for the tables.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Bayram F Ahmed BS Kassler A From concept drift to model degradation: an overview on performance-aware drift detectors Knowledge-Based Systems 202224510863210.1016/j.knosys.2022.108632 · doi ↗
- 2Bradley D The hydrocyclone: international series of monographs in chemical engineering 20134 Amsterdam, Netherlands Elsevier
- 3Cao Z Wu X Tang B Cai W Gaussian process regression for prediction of hydrogen adsorption temperature–pressure dependence curves in metal–organic frameworks Chemical Engineering Journal 2023476314655310.1016/J.CEJ.2023.146553 · doi ↗
- 4Chen Y Li M An effective online sequential stochastic configuration algorithm for neural networks Sustainability 202214231560110.3390/su 142315601 · doi ↗
- 5Cui B Wang H Li R Xiang L Zhao H Xiao R Li S Liu Z Yin G Cheng X Ma Y Huo H Zuo P Lu T Xie J Du C Ultra-early prediction of lithium-ion battery performance using mechanism and data-driven fusion model Applied Energy 202435312208010.1016/J.APENERGY.2023.122080 · doi ↗
- 6Dai W Liu J Wang L Cloud ensemble learning for fault diagnosis of rolling bearings with stochastic configuration networks Information Sciences 20246581011999110.1016/j.ins.2023.119991 · doi ↗
- 7Fan W Systematic data selection to mine concept-drifting data streams 2004 Proceedings of the Tenth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining New York, NY Association for Computing Machinery 128137
- 8Gu M Fei J Sun S Online anomaly detection with sparse Gaussian processes Neurocomputing 20204031138339910.1016/j.neucom.2020.04.077 · doi ↗