OM-VST: A video action recognition model based on optimized downsampling module combined with multi-scale feature fusion
Xiaozhong Geng, Cheng Chen, Ping Yu, Baijin Liu, Weixin Hu, Qipeng Liang, Xintong Zhang

TL;DR
This paper introduces OM-VST, a video action recognition model that improves accuracy and reduces training parameters through optimized downsampling and multi-scale feature fusion.
Contribution
The novel OM-VST model combines an optimized downsampling module with multi-scale feature fusion for better video classification performance.
Findings
OM-VST improves classification accuracy by 2.81% compared to existing models.
The model reduces training parameters by 54.7%, decreasing training time and energy consumption.
OM-VST outperforms VST, SlowFast, and TSM on a public dataset.
Abstract
Video classification, as an essential task in computer vision, aims to identify and label video content using computer technology automatically. However, the current mainstream video classification models face two significant challenges in practical applications: first, the classification accuracy is not high, which is mainly attributed to the complexity and diversity of video data, including factors such as subtle differences between different categories, background interference, and illumination variations; and second, the number of model training parameters is too high resulting in longer training time and increased energy consumption. To solve these problems, we propose the OM-Video Swin Transformer (OM-VST) model. This model adds a multi-scale feature fusion module with an optimized downsampling module based on a Video Swin Transformer (VST) to improve the model’s ability to…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
 Figure 1
Figure 1 Figure 2
Figure 2 Figure 3
Figure 3 Figure 4
Figure 4 Figure 5
Figure 5 Figure 6
Figure 6 Figure 7
Figure 7 Figure 8
Figure 8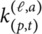 Figure 9
Figure 9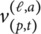 Figure 10
Figure 10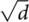 Figure 11
Figure 11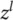 Figure 12
Figure 12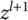 Figure 13
Figure 13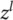 Figure 14
Figure 14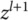 Figure 15
Figure 15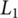 Figure 16
Figure 16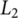 Figure 17
Figure 17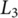 Figure 18
Figure 18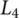 Figure 19
Figure 19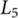 Figure 20
Figure 20 Figure 21
Figure 21 Figure 22
Figure 22 Figure 23
Figure 23 Figure 24
Figure 24 Figure 25
Figure 25 Figure 26
Figure 26 Figure 27
Figure 27 Figure 28
Figure 28 Figure 29
Figure 29 Figure 30
Figure 30 Figure 31
Figure 31 Figure 32
Figure 32 Figure 33
Figure 33 Figure 34
Figure 34 Figure 35
Figure 35 Figure 36
Figure 36 Figure 37
Figure 37 Figure 38
Figure 38 Figure 39
Figure 39 Figure 40
Figure 40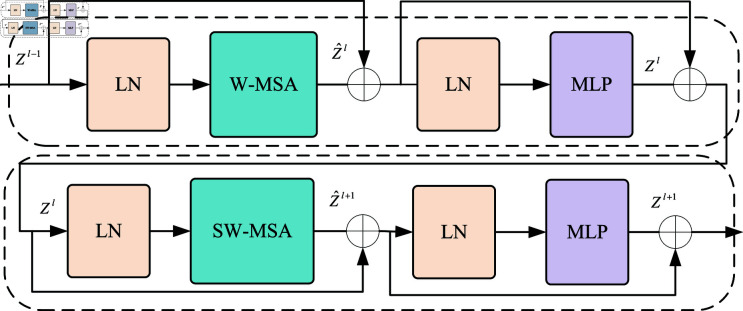 Figure 41
Figure 41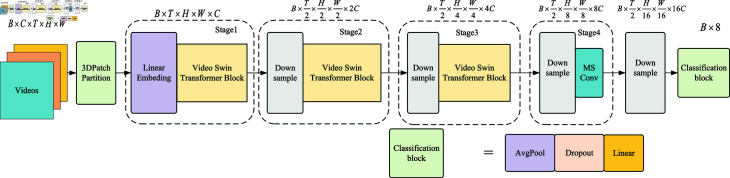 Figure 42
Figure 42 Figure 43
Figure 43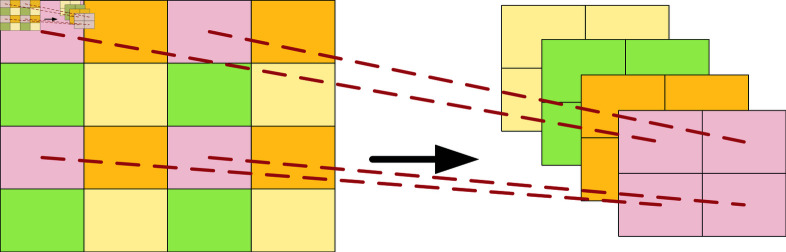 Figure 44
Figure 44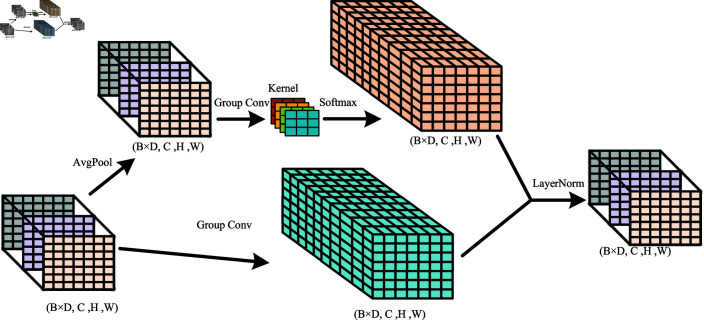 Figure 45
Figure 45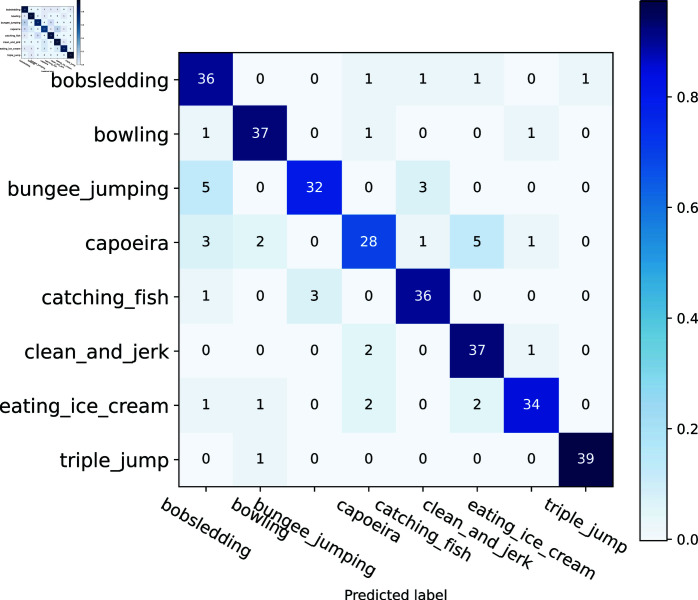 Figure 46
Figure 46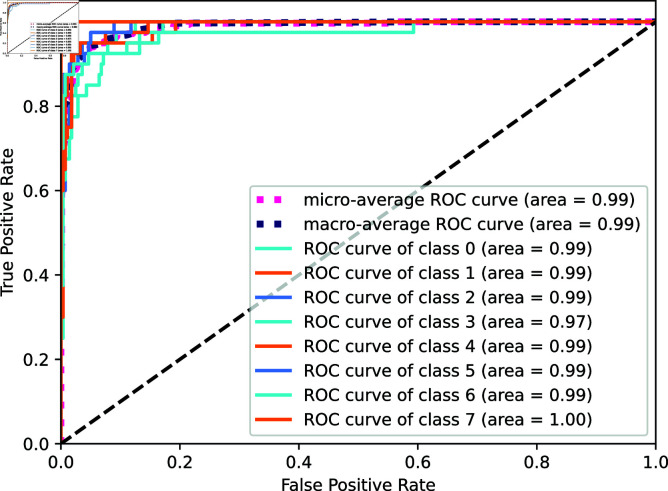 Figure 47
Figure 47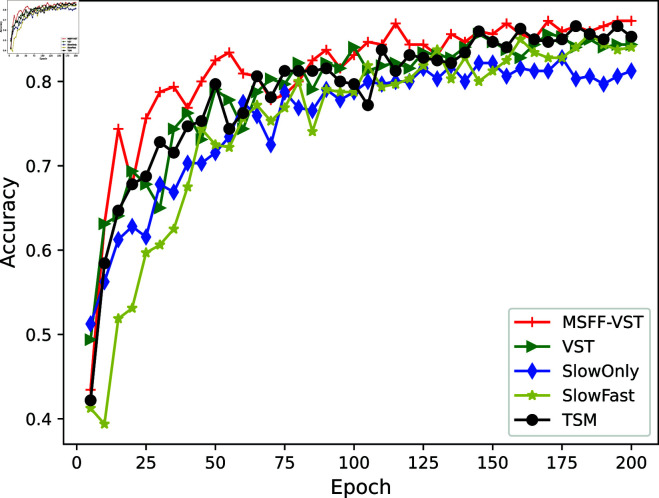 Figure 48
Figure 48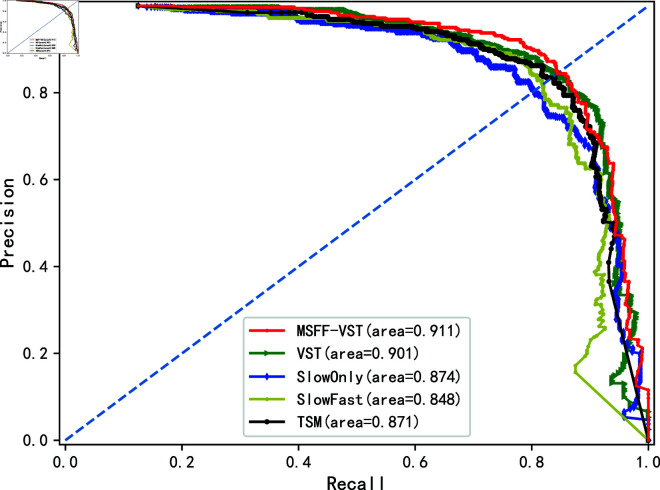 Figure 49
Figure 49 Figure 50
Figure 50Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsHuman Pose and Action Recognition · Anomaly Detection Techniques and Applications · Gait Recognition and Analysis