A bioinformatician, computer scientist, and geneticist lead bioinformatic tool development—which one is better?
Paul P Gardner

TL;DR
This study finds no strong link between the academic field of developers and the accuracy of bioinformatic tools they create.
Contribution
It introduces a novel analysis of how academic affiliations correlate with software accuracy in bioinformatics.
Findings
Medical Informatics tools showed the highest accuracy in rankings.
Bioinformatics and Engineering tools were less accurate on average.
No results remained statistically significant after multiple testing correction.
Abstract
The development of accurate bioinformatic software tools is crucial for the effective analysis of complex biological data. This study examines the relationship between the academic department affiliations of authors and the accuracy of the bioinformatic tools they develop. By analyzing a corpus of previously benchmarked bioinformatic software tools, we mapped bioinformatic tools to the academic fields of the corresponding authors and evaluated tool accuracy by field. Our results suggest that “Medical Informatics” outperforms all other fields in bioinformatic software accuracy, with a mean proportion of wins in accuracy rankings exceeding the null expectation. In contrast, tools developed by authors affiliated with “Bioinformatics” and “Engineering” fields tend to be less accurate. However, after correcting for multiple testing, no result is statistically significant (P > .05). Our…
Click any figure to enlarge with its caption.
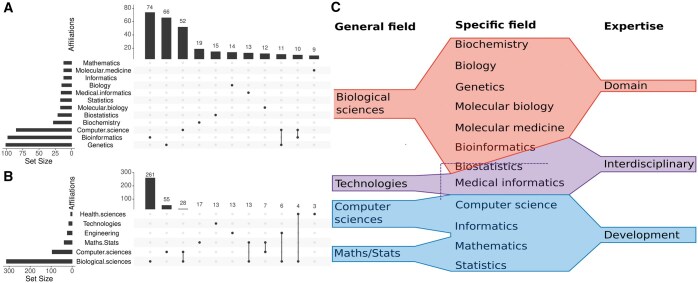 Figure 1
Figure 1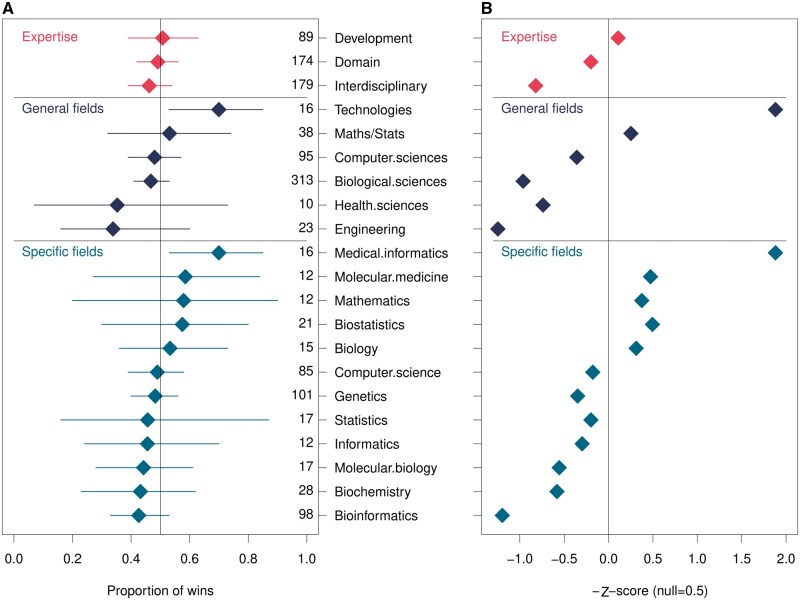 Figure 2
Figure 2- —Ministry of Business, Innovation and Employment data science platform “Beyond Prediction
- —Genomics Aotearoa, and Marsden Grants
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsGenetics, Bioinformatics, and Biomedical Research · Scientific Computing and Data Management · Gene expression and cancer classification
1 Introduction
Departmental divisions in academia signify research expertise, influence hiring decisions, and impact access to funding, publishing opportunities, and student training (Bourke and Butler 1998, Martin 2016). However, interdisciplinary fields such as bioinformatics blur traditional boundaries by integrating data and methods from biology, computer science, and mathematics to address complex research challenges (Ouzounis and Valencia 2003, Eddy 2005, Hogeweg 2011).
Bioinformatics has become essential to modern biological research, facilitating evolutionary, structural, and functional analyses of genomic, transcriptomic, and proteomic data (Clement et al. 2018, Gauthier et al. 2019). The development of accurate and scalable bioinformatic tools is critical for interpreting such large datasets. Which requires both biological insight and advanced computational skills to build algorithms. The advent of high-throughput technologies has driven the growth of bioinformatics, leading to the establishment of specialized groups within biology, computer science, and engineering faculties, each contributing to the field’s expansion (Hogeweg 2011, Gauthier et al. 2019).
The contributions of “domain experts” to bioinformatics from the biological and health sciences, such as genetics and molecular biology are essential as they ensure software tools are relevant and accurate. However, domain experts may lack the advanced computational expertise needed to develop sophisticated software. In contrast, fields like mathematics, engineering, and computational sciences—referred to here as “development experts”—offer expertise in algorithm development, mathematical modeling, statistics, and software engineering, essential for creating efficient and scalable bioinformatic tools.
It is possible that departmental differences may influence bioinformatic tool development by reflecting the distinct expertise, resources, and perspectives offered by different academic fields. Development experts excel in computational efficiency, while domain experts provide essential biological insights. Therefore, the success of a tool may depend on the integration of diverse skills rather than on the specific departmental affiliation of its developers.
The accuracy of bioinformatic software tools are of critical importance to the field (Weber et al. 2019). Yet several factors can influence accuracy assessments. Previous work has shown that author conflicts can bias tool accuracy assessments upwards (Buchka et al. 2021). Conversely, commonly assumed features of accurate software such as author reputation (e.g. H-index), tool citation rates, journal impact, runtime, and age of tools had no significant association with software accuracy (Gardner et al. 2022). Instead, features illustrating sustained development of tools, such as the number of releases, and activity on a popular distributed version control website was significantly associated with accuracy (Gardner et al. 2022).
The primary objective of this study is to examine whether the academic department affiliation of a corresponding author has a discernible outcome on the accuracy (i.e. correctness of predictions) of the bioinformatic tools they develop. Specifically, we aim to determine whether tools created by authors from domain-expert, development-expert of interdisciplinary fields differ in accuracy. This question was motivated by the possibility that certain grant reviewers and other research assessors may base their perception of expertise on departmental affiliation rather than more pertinent information such as research experience. To address this challenge, we have analyzed a published corpus of benchmarked bioinformatic tools and evaluated relative accuracy ranks based on the developers’ academic affiliations.
2 Methods
The data, scripts, figures, and manuscript draft files are available at the GitHub repository: https://github.com/ppgardne/departments-software-accuracy.
Pre-registration: The methods for this study followed the pre-registered proposal outlined prior to any unpublished data collection (Gardner 2024).
Benchmarking data: Software ranks from previously gathered benchmarks are publically available (Gardner et al. 2022), these include data from 68 publications, 128 benchmark rankings of different sets of 498 distinct software tools (summarized in Supplementary Table S1).
In brief, the criteria for inclusion of a benchmark study are based on the definition of “neutral comparison studies” (Boulesteix et al. 2013): (i) the main focus of the article is the comparison and not the introduction of a new tool; (ii) The authors should be neutral (i.e. not tool developers); (iii) The test data and evaluation criteria should be sensible.
Mapping tools to academic field: For each software tool, the corresponding publication(s) were identified, and the addresses of the primary corresponding author were manually extracted when available. If an author listed multiple addresses, only the first two were used. In cases with multiple corresponding authors, the last corresponding author was chosen.
The department names of the authors were mapped to the closest associated “fields of study” as defined by the National Science Foundation U.S. National Science Foundation (2016). We analyzed these fields at three hierarchical levels: first, specific fields (e.g. “genetics,” “computer science,” “bioinformatics,” etc.), which were then mapped to broader general fields (e.g. “biological sciences,” “computer sciences,” etc.). Thirdly, we categorized them into three types of expertise: development experts, domain experts, and interdisciplinary experts. Development experts, from fields such as computer science, mathematics, and engineering, are expected to bring relevant expertise in software engineering and the mathematical modeling of biological problems. Domain experts, from the biological and health sciences, are anticipated to possess detailed knowledge of their subject area and to be invested in producing high-performing software for their research needs. Interdisciplinary experts come from fields such as bioinformatics, biostatistics, and biomathematics, and also include researchers who list both development and domain expertise (e.g. “Computer Science” and “Genetics”). We have treated some fields as synonymous; e.g. “Computational Biology” was mapped to “Bioinformatics,” and “Genomics” is mapped to “Genetics.”
We restricted all subsequent analyses to fields that contain at least 10 software tools in our benchmark corpus. This mitigated against potential issues due to small sample sizes (Fig. 1).
Department overview. The UpSet figures display the number and intersection of bioinformatic tools classified by general fields (A) and specific fields (B). Tools are mapped to the affiliations of corresponding authors who published each tool included in selected benchmark studies. Only the top 11 sets are shown for general and specific fields. (C) The classification of general and specific fields of study used by the “National Science Foundation” relevant to this study. On the right, it shows the additional expertise categories that we introduced for this analysis.
Statistical analysis: The accuracy data is derived from benchmarks using a diverse number of metrics that include sensitivity, specificity, PPV, FDR, error rates, AUROC, MCC, and others (Weber et al. 2019). The number of tools ranked in any benchmark ranged from 3 to 50. In order to obtain a representative measure of accuracy for a field that accounts for the diversity in accuracy measures and number of ranked tools, we used a rank-based and bootstrapping strategy. We randomly sampled, with replacement, sets of 200 tools from the total of 498 tools. For each tool, a corresponding benchmark was selected at random, and the number of times the tool “won” against another tool was recorded, along with the total number of pairwise comparisons made. These counts of wins and total comparisons were then assigned to the corresponding specific and general departments, and expertise areas. In other words, a tool ranked second in a benchmark of 11 tools will contribute 9 wins and 10 comparisons to the totals for its corresponding fields.
This process was repeated 1000 times to estimate the mean proportions of wins for each field, along with a 95% confidence interval for these values (Fig. 2A). In addition, we calculated a Z-score for each field to determine the number of standard deviations the mean number of wins deviates from the expected null value of 0.5 for randomly grouped tools (Fig. 2B).
where μ is the mean, σ is the standard deviation, x is the raw value. In this case, we set *x = *0.5 as this is the null expectation for the proportion of wins for randomly grouped sets of tools. For the purposes of illustration, we plot so that the direction is the same as for the “proportion of wins” forest plot (Fig. 1).
Departments producing the most accurate software. (A) A forest plot, illustrating the mean and 95% confidence intervals of the proportion of times software tools published by a given field “win” in pairwise comparisons. Confidence intervals and the mean was determined using a bootstrapping procedure. Within each field the entries have been sorted by the mean number of wins. The sample size for each field is indicated by the column of numbers on the right of the figure. (B) A Z-score was computed for each distribution of bootstrap samples for each field. The expected proportion of wins for randomly selected groups of tools was used as “x” (i.e. null = 0.5).
P-values are computed from the absolute value of the Z-scores to evaluate if any field is significantly distinguished from the null, i.e. . The P-values are corrected for multiple testing by controlling the false discovery rate method (Benjamini and Hochberg 1995).
3 Results
We explored the relationship between the accuracy of bioinformatic software tools and the academic fields of their developers. Using a previously published corpus of benchmarked accuracy rankings (Gardner 2024), we mapped corresponding authors’ addresses to standardized “fields of study” (U.S. National Science Foundation 2016) and grouped them into broader categories. Fields of study is a hierarchical classification that includes specific fields (e.g. “Genetics” or “Mathematics”) or general fields (e.g. “Biological Sciences” or “Mathematics and Statistics”). We further classified these into expertise areas of “Development” (e.g. Computer Science), “Domain” (e.g. Biological Sciences) and “Interdisciplinary” (e.g. Bioinformatics or listing both a Biological and Computational Sciences affiliation).
Figure 1 shows the number of tools (set/intersection sizes) for the general and specific fields (for sets sizes ), as well as the intersections between fields due to corresponding authors with multiple affiliations. For example, 11 tools have been published by authors who list both a Genetics and Computer Science department as their affiliation. Most bioinformatic tools were developed by authors affiliated with Genetics, Bioinformatics, Computer Science, or similar departments. Among the general fields, Biological Sciences produced the most software tools, followed by Computer Sciences.
We ranked fields based on the mean proportion of “wins” (i.e. for field “1” when its tool “A” outperforms tool “B” in benchmark “X”) and calculated Z-scores to compare them against random expectations (i.e. *wins = *0.5). A higher proportion of wins and lower indicate better overall accuracy.
“Medical Informatics,” a branch of “Technologies,” outperformed other fields, with a mean win proportion of 0.70 (95% CI: 0.53–0.85) and a Z-score of −1.88. However, P = .29 after multiple testing correction. Notably, this category includes five different parameter options for the MAFFT sequence alignment tool (Katoh and Toh 2008), and a further four separate corresponding authors that list either the Department or Center of Biomedical Informatics, Harvard Medical School as their affiliation (Kim et al. 2010, Yang et al. 2013, Kharchenko et al. 2014, Ruan and Li 2020). This and some other redundancies leave just eight departments representing the medical informatics field here.
In contrast, “Bioinformatics” has the lowest rank, with a mean win proportion of 0.43 (95% CI: 0.33–0.53) and a Z-score of 1.20 (P = .46 after correction). Similarly, “Engineering” ranked low, with a win proportion of 0.34 (95% CI: 0.16–0.60) and a Z-score of 1.25.
Other fields showed confidence intervals that included the null value of 0.5, with modest Z-scores ranging from −0.49 to 0.96, and P-values >.05.
When grouped by expertise type–software development experts, biological domain experts, or interdisciplinary experts—all categories had similar win proportions (0.51, 0.49, and 0.46, respectively). Interdisciplinary experts had the lowest Z-score of −0.87 (P = .46 after correction).
4 Conclusions and limitations
We tested the assumption that academic department specialization reflects the quality of research software. After correcting for multiple testing, we found no significant association between academic expertise and the accuracy of bioinformatic tools. This suggests that department affiliation does not correlate with software quality, and neither general nor specific research fields showed any significant links to tool accuracy.
A previous study indicated that maintaining software was the key factor in producing accurate tools, while citation metrics, tool age, speed are not associated with software accuracy (Gardner et al. 2022). Our findings complement this by showing that academic field is also not associated with software accuracy.
While other aspects of bioinformatic tools, such as speed and usability, are important, we emphasize that accuracy should remain the top priority, as poor predictions have long-term impacts on research (Weber et al. 2019).
Medical Informatics was the top-performing field in developing accurate tools, these include methods for structural variation detection, single-cell profiling, long-read assembly, multiple sequence alignment and are derived from a limited number of research teams. However, tools from Bioinformatics and Engineering ranked lower, though these differences were not statistically significant.
Therefore, an individual’s department is not a reliable indicator of the quality of the software they produce. Academic affiliation should not be used as a proxy for assessing the potential success of software development projects.
Limitations: Some benchmarks include multiple tool options, potentially introducing nonindependent effects. The accuracy metrics are diverse, with some limitations [e.g. issues with “accuracy” in class-imbalanced datasets (Luque et al. 2019) and criticisms of the N50 metric for sequence assembly (Xie and Wong 2021)]. In addition, smaller benchmarks and smaller fields may exaggerate rank shifts. We mitigate this in part by only considering departments with 10 or more corresponding tools.
Potential confounding variables may exist for this analysis. However, a prior analysis of this data (Gardner et al. 2022) found no correlation between software accuracy and factors such as citations for tools, authors or journal, as well as tool speed, or age, allowing these variables to be ruled out as confounders.
There may be little connection between a researcher’s training and their listed department, as illustrated by this author’s background which began in mathematics, before taking positions in departments of computer science, molecular biology and bioinformatics, and now is affiliated with a Biochemistry Department.
The corresponding (last) author is typically the principal investigator and may not be the primary tool developer, but rather oversees the project. There is likely to be a strong overlap between the departments of the first and last authors, but this was not explored in the current study.
Final words: This study does not find evidence linking academic department affiliation with bioinformatic software accuracy (*P > *.05 in all instances). Future research should investigate other factors, such as interdisciplinary collaborations and developer training, to understand what drives high-quality tool development. Addressing potential biases against interdisciplinary work (Bromham et al. 2016) and ensuring long-term support for essential software infrastructure will also be critical for advancing the field (Siepel 2019).
Supplementary Material
vbaf011_Supplementary_Data
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Benjamini Y , Hochberg Y. Controlling the false discovery rate: a practical and powerful approach to multiple testing. J R Stat Soc Ser B (Methodological) 1995;57:289–300.
- 2Boulesteix A-L , Lauer S, Eugster MJ. A plea for neutral comparison studies in computational sciences. P Lo S One 2013;8:e 61562.23637855 10.1371/journal.pone.0061562 PMC 3634809 · doi ↗ · pubmed ↗
- 3Bourke P , Butler L. Institutions and the map of science: matching university departments and fields of research. Res Policy 1998;26:711–8.
- 4Bromham L , Dinnage R, Hua X. Interdisciplinary research has consistently lower funding success. Nature 2016;534:684–7.27357795 10.1038/nature 18315 · doi ↗ · pubmed ↗
- 5Buchka S , Hapfelmeier A, Gardner PP et al On the optimistic performance evaluation of newly introduced bioinformatic methods. Genome Biol 2021;22:152.33975646 10.1186/s 13059-021-02365-4PMC 8111726 · doi ↗ · pubmed ↗
- 6Clement L , Emeric D, Laurent M et al A data-supported history of bioinformatics tools. ar Xiv, ar Xiv:1807.06808, 2018, preprint: not peer reviewed.
- 7Eddy SR. “Antedisciplinary” science. P Lo S Comput Biol 2005;1:e 6.16103907 10.1371/journal.pcbi.0010006 PMC 1183512 · doi ↗ · pubmed ↗
- 8Gardner PP. Pre-registration: which department makes the best software? 2024. 10.17605/OSF.IO/92PTZ (10 July 2024, date last accessed). · doi ↗