Open-access network science: Investigating phonological similarity networks based on the SUBTLEX-US lexicon
John Alderete, Sarbjot Mann, Paul Tupper

TL;DR
This paper creates and analyzes open-access phonological similarity networks using the SUBTLEX-US English corpus, showing they have typical network properties and providing tools for further exploration.
Contribution
The novel contribution is the creation and open release of phonological similarity networks based on the SUBTLEX-US corpus with various configurations.
Findings
The networks exhibit small-world properties, broad degree distributions, and robustness to node removal.
The networks show contrasts in degree and clustering coefficient consistent with prior studies.
The backbone network extraction reveals familiar trends related to network centrality.
Abstract
Network science tools are becoming increasingly important to psycholinguistics, but few open-access data sets exist for exploring network properties of even well-studied languages like English. We constructed several phonological similarity networks (neighbors differ in exactly one consonant or vowel phoneme) using words from a lexicon based on the SUBTLEX-US English corpus, distinguishing networks by size and word representation (i.e., lemma vs. word form). The resulting networks are shown to exhibit many familiar characteristics, including small-world properties, broad degree distributions, and robustness to node removal, regardless of network size and word representation. We also validated the SUBTLEX phonological networks by showing that they exhibit contrasts in degree and clustering coefficient comparable to the same contrasts found in prior studies and exhibit familiar trends…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
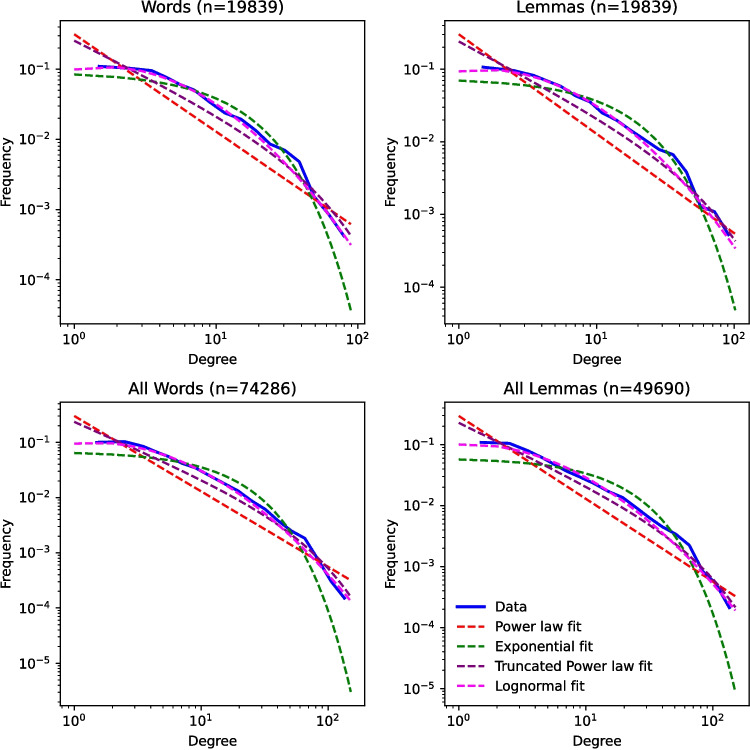 Figure 1
Figure 1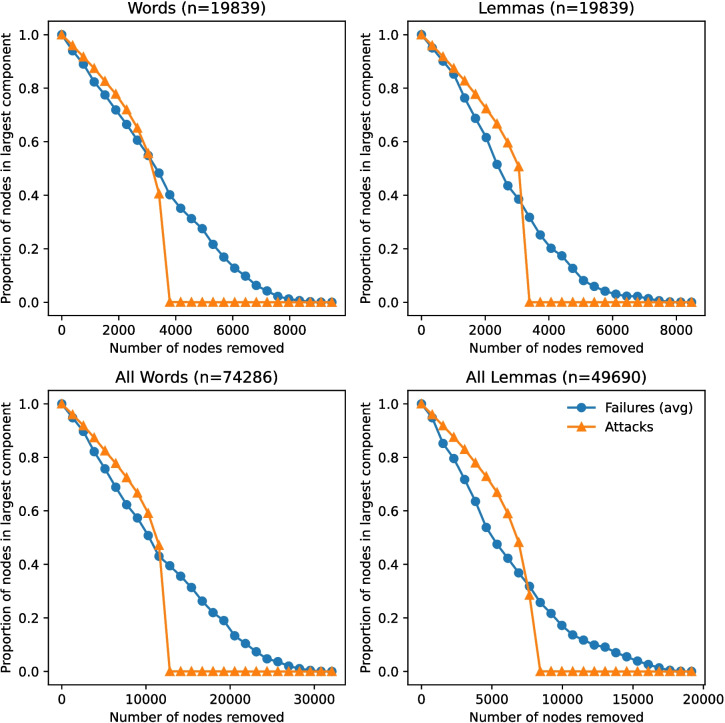 Figure 2
Figure 2Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsComplex Network Analysis Techniques · Topic Modeling · Advanced Graph Neural Networks
Introduction
Over the past 25 years, network science has led to significant progress in psycholinguistics. It has given the field a range of predictive measures for analyzing behavioral data, such as degree (a.k.a., neighborhood density) and clustering coefficient (for review, see Vitevitch and Castro (2015)). These measures and the mathematical methods developed for them enable graph-theoretic analyses of entire lexicons, not just the fragments of lexicons. While network models are not models of psycholinguistic behavior, they capture facts of relevance for these models, and in doing so, provide new insight into language processing in the mental lexicon (Chan & Vitevitch, 2009, 2010; Siew & Vitevitch, 2016). For example, phonological networks based on form resemblance have high assortative mixing by degree, meaning that high-degree nodes tend to be linked to each other, and likewise for low-degree nodes. This mixing pattern accounts for some of the robustness of the network to node removal, and it has natural interpretations in terms of the gradual degradation of word retrieval (Arbesman et al., 2010; Vitevitch et al., 2014). In addition to the role of degree and clustering coefficient in early work on comprehension and production (Dell & Gordon, 2003; Munson & Solomon, 2004; Vitevitch, 1997, 2002), recent research has investigated new measures and data structures in the dynamics of learning and aging (Cosgrove et al., 2021; Fourtassi et al., 2020; Jones & Brandt, 2020), emergent community structure in language networks (Kovács et al., 2021; Siew, 2013; Tiv et al., 2020), and analysis of multiple networks in so-called multiplex network analysis (Castro et al., 2020; Stella, 2019). In sum, network science has room to grow in psycholinguistics.
Despite this progress, two problems currently exist that are constraining this growth. First, there are very few open-access resources that support the creation of network science measures for individual words or lexicons, even for well-studied languages like English, Dutch, and German. While some key measures (e.g., phonological and semantic neighbors) are documented in online repositories like the English Lexicon Project (Balota et al., 2007) and CLEARPOND (Marian et al., 2012), these repositories do not provide the data structures for deeper network analysis, such as adjacency or edge lists, that are required to generate from scratch other measures for individual words and global network properties for an entire lexicon. Perhaps because of the computational difficulty in producing these lists, prior research has not released the structures required for deeper analyses, requiring researchers to pay to use proprietary data repositories like Wolfram Data Repository to tackle new problems.
A second problem is that most psycholinguistic research using network science methods is skewed toward models with specific characteristics. To understand the types of networks studied and the digital resources underlying the research, we examined 47 network models surveyed in two recent review articles (Turnbull, 2021; Vitevitch & Castro, 2015). Because of their importance to form-encoding in psycholinguistics, most studies used phonological similarity networks, or networks of words where words are linked if they differ in the deletion, addition, or substitution of a single phoneme. Almost all these studies (42 or 89.36%) used the Hoosier Mental Lexicon (HML) as the basis for this kind of network. The HML is an electronic data set comprised of the 19,839 words from the 1964 Merriam-Webster Pocket Dictionary (Nusbaum et al., 1984). As many researchers familiar with it know, the HML is a valuable resource because word representations are expertly transcribed, and its size is a realistic approximation of the mental lexicons of university students commonly recruited for psycholinguistic experiments. That said, this data set is not publicly available, nor are the underlying data structures required to fully explore it. In addition, research that employs this network is limited to word lemmas because the entries of the HML are dictionary headwords, and so related word forms are not included (e.g., play, but not plays and playing). In sum, because of these resource limitations, this research is limited by the languages investigated, the type of word representation, and the size of the network.
To address this gap, we have developed and investigated a set of phonological similarity networks based on open-access principles. In particular, we have created 17 phonological networks from the SUBTLEX-US English corpus, a public data set of word forms compiled from movie and TV subtitles (Brysbaert & New, 2009). We chose this corpus because it is developed to a set of standards in psycholinguistics that has made it one of the most popular corpora for investigating psycholinguistic behavior, including open access, published frequency norms, part of speech tagging, and data validation on behaviors like lexical decision times (Brysbaert & New, 2009; Brysbaert et al., 2012, 2014). Following the methods used in (Shoemark et al., 2016), we generated phonological networks of different sizes that distinguish word forms and word lemmas extracted from the corpus in order to test the impact of these factors on network characteristics. We also examine below the mathematical properties of these networks and compare them with other documented networks (Arbesman et al., 2010; Castro & Vitevitch, 2023; Shoemark et al., 2016; Vitevitch, 2008) and validate the new networks by comparing their network properties to those of the HML from several prior experimental and mathematical studies. The resulting digital resources include the phonological networks encoded as adjacency lists, which, by representing all the phonological neighbors for each word, can be explored further with programming frameworks such as Python and R.
Methods
Phonetic transcription
We require a phonetic representation for each of the 74,286 words in SUBTLEX-US in order to build a phonological similarity network. To this end, we first converted a majority of word forms to IPA representations using the Python program eng-to-ipa (Mphilli et al., 2019). This program uses confirmed representations from the Carnegie Mellon University Pronouncing Dictionary (Weide, 2014), which provides phonetic transcriptions of North American English suitable for the SUBTLEX-US data set. However, many word forms (25,931, or roughly 35%) did not have an entry in the CMU dictionary, and so we require grapheme-to-phoneme conversion to include these data. This type of conversion is difficult in a language like English because of grapheme ambiguity and variability, irregular spellings, homophones, and many-to-one mappings, and thus the state-of-the-art employs neural network models like those used in machine translation to address these problems. We selected the grapheme-to-phoneme model developed in Ryan (2020) to construct the missing IPA representations. This model uses the OpenNMT open-source toolkit for neural machine translation (Klein et al., 2017) to train and test an encoder-decoder model that performs with high accuracy. It was also trained in part on the CMU data set we use here, making it suitable for our application.
To test the accuracy of the output forms, we sampled 1000 words of SUBTLEX-US three times and compared the neural model’s output with the CMU reference form when it was available. The neural model’s IPA output was identical to the CMU reference 90% of the time. Non-identical words also resembled the CMU reference forms to a considerable degree. The non-identical output forms had a string edit distance of 1.78 from the CMU reference form, meaning that they were typically only one or two phonemes off. Inspection of these forms showed that errors typically occurred in vowel representations and often involved variant pronunciations that are attested in some speech varieties, as in [dɪspɹuvən], cf. reference [dɪspɹuvɪn] for ‘disproven’. While the IPA representations are not perfect, we believe that they are sufficiently accurate to proceed with building networks.
Building the phonological networks
We used the IPA representations of SUBTLEX-US word forms described above to construct several phonological similarity networks. In particular, we created an adjacency list (adjlist) for each network, which is, in essence, a list of lists in which each list begins with a word (a node in the network) that is followed by all its neighbors. In other words, the adjlist is a long data table in which each row starts with a word in the node network followed by all other phonologically related words linked to it. Following standard practice, phonological neighbors are words that differ in the substitution, addition, or deletion of a single phoneme (Luce & Pisoni, 1998).
To investigate the effect of size on network properties, we sampled from the complete networks to produce smaller ones while retaining the word frequency distributions of the larger corpus. This was achieved by using a technique of thresholding by word frequency, which effectively simulates building a lexicon from a smaller corpus by removing low-frequency words (Shoemark et al., 2016). The logic of thresholding is that smaller corpora would be more likely to contain a higher percentage of high frequency than a larger corpus. Thought of in acquisitional terms, small children will be exposed to less low-frequency words than adults because they experience fewer words, and there is a greater chance of them being high-frequency. Thus, by removing low-frequency words below some frequency cutoff, we approximate the composition of these corpora. Concretely, we created sub-networks with different orders of magnitude by randomly removing low-frequency words (i.e., words below the median word frequency) based on their frequencies in SUBTLEX-US. In addition, to compare networks based on SUBTLEX-US with the HML, we created networks that matched the size of the HML.
Nine of our phonological networks are built with word forms as nodes. We also created eight networks with word lemma nodes using the spaCy lemmatizer (spacy.io) to select appropriate words representing word lemmas. Again, using thresholding by word frequency, the networks differ in orders of magnitude, and we also include the entire SUBTLEX-US lemma list as well as one matched in size with the HML. Finally, because phonological similarity networks are blind to morphology, they will automatically include many inflected word forms as neighbors of a word base (e.g., cat/cats) in networks with word forms as nodes. Though these morphologically related forms may impact phonological processing, we opted to remove these effects because they conflate morphological and phonological relatedness. To this end, we built a special-purpose filter that removes edges between words that share the same stem and differ only in inflection. After experimenting with this filter, we found that it can have a real impact on node relationships in the word-form networks (it was not applied to the lemma networks because they lack the relevant word pairs). For example, 3851 edges (though no nodes) were removed from the word-form network with 19,839 nodes, or 19.41% of the logically possible edges.
Results and discussion
Descriptive statistics
We start with statistics that describe the gross structure of different components of our word form and lemma networks. Following Vitevitch (2008), we distinguish the giant component (i.e., the sub-network with the largest number of connected nodes), the nodes inside so-called lexical islands (all sub-networks other than the giant component with more than one node), and lexical hermit nodes with no neighbors (see the appendix for a glossary of all the technical terms we use). Table 1 gives the node counts (and percentages of all network nodes) for all 17 phonological similarity networks. The size of each network ranges from 1024 nodes and rises by orders of magnitude to the total count of all words in SUBTLEX-US. As expected, network density falls as the networks grow because the number of possible links (= N/(N−1)/2) grows much faster than actual links as the network sizes increase. These statistics and many other measures given below were calculated using methods from the networkX Python package (Hagberg et al., 2008). Table 1. Counts of phonological network components and other descriptive statistics (parentheticals give the percentage of nodes in all three components: giant, island, and hermits)SizeNodesLinksDensityNodes in giantNodes in islandsHermit nodesIslandsWord forms2^10^102416890.00323555 (54.20)100 (9.77)369 (36.04)352^11^204841070.001961066 (52.05)205 (10.01)777 (37.94)782^12^409689070.001062035 (49.68)423 (10.33)1638 (39.99)1632^13^819220,2040.000604020 (49.07)833 (10.17)3339 (40.76)3292^14^16,38445,9000.000347944 (48.49)1673 (10.21)6767 (41.30)6742^15^32,768101,1820.0001914,949 (45.62)3749 (11.44)14,070 (42.94)14962^16^65,536217,1560.0001028,117 (42.90)8837 (13.48)28,582 (43.61)3405All74,286256,5420.0000932,097 (43.21)10,255 (13.80)31,934 (42.99)3936 ~ HML19,83957,6760.000299482 (47.79)2106 (10.62)8251 (41.59)841Lemmas2^10^102417040.003253529 (51.66)106 (10.35)389 (37.99)432^11^204841080.001961028 (50.20)217 (10.60)803 (39.21)822^12^409699020.0011811998 (48.78)448 (10.94)1650 (40.28)1652^13^819222,5140.0006713839 (46.86)858 (10.47)3495 (42.66)3422^14^16,38449,4730.0003697162 (43.71)1807 (11.03)7415 (45.26)7362^15^32,768108,1770.00020213,134 (40.08)4057 (12.38)15,577 (47.54)1636All49,690172,1150.00013919,172 (38.58)7018 (14.12)23,500 (47.29)2782 ~ HML19,83962,4550.0003178485 (42.77)2261 (11.40)9093 (45.83)917
These results reveal a difference between the Hoosier Mental Lexicon and a similarly sized SUBTLEX-US network in component sizes (Table 1, Lemmas, ~ HML). The giant component of the SUBTLEX-US network is somewhat larger, with 8485 nodes (42.77%) as opposed to 6508 nodes (33.65%) in the HML network.1 The uptake in the HML network is principally in the number of hermit nodes, 10,265 (53.08%), which greatly exceeds the giant component nodes in this network. This differs from the sized-matched SUBTLEX-US network, which only has a 3% difference in size between giant components and hermit nodes. While different from the HML network, the size of the SUBTLEX-US giant component is not particularly odd cross-linguistically. The average size of the giant component of phonological similarity networks from five linguistically distinct languages is 45.4% (Arbesman et al., 2010), which compares with the size of our HML-matched network. In our investigations below, we continue to use the lemma-based HML-matched network, despite the differences in component size, because there are no alternative networks that approach the HML giant component size.
Backbone analysis
Given the difference in giant component size, we compared the HML and size-matched SUBTLEX-US networks with the statistical technique of backbone extraction. The creation of a so-called backbone network involves removing redundant links in a network to identify “important” nodes in the sense that they make important contributions to the centrality measures of a network (Neal, 2022). Vitevitch and Sale (2023) analyzed the phonological backbone of the HML network and found that words removed from the original giant component differed significantly from those that were not removed in several network science and psycholinguistic measures. We applied the same tools to a similarly sized SUBTLEX-US network to determine if there were comparable differences before and after backbone extraction.
We employed methods similar to those used in Vitevitch and Sale (2023). We used our own implementation of the L-Spar algorithm (Satuluri et al., 2011) to extract the backbone from the SUBTLEX-US network in order to preserve and investigate community structure. We first tried the same parameters published in Vitevitch and Sale (2023), but this model resulted in a backbone network with far too many nodes removed from the original giant component. After some experimentation, we found that raising the sparsity parameter s from 0.0 to 0.5 resulted in a more reasonable number of extracted nodes (though still higher than the HML analysis). We then examined the same set of network characteristics before and after backbone extraction and analyzed the network science (degree, clustering coefficient, closeness centrality) and psycholinguistic (word length, word frequency) measures of individual words.2
As shown in Table 2, the extracted backbone network follows most of the trends found for the HML. In particular, the backbone network had major drops in the number of edges and average degree in both the giant component and the larger network, and the network’s diameter, average shortest path length, and the number of communities rose with magnitudes comparable to those in the HML backbone. As mentioned above, our chosen parameters had the effect of removing many more words from the backbone giant component, and this probably accounts for the difference in the number of components and their range in size (since backbone networks are guaranteed to have the same number of isolates, a major decrease in the size of the giant component will increase the number of non-giant components and their sizes). Table 2. Comparison of original and extracted backbone networks (GC = giant component)Original networkBackbone networkNumber of nodes in the network19,83919,839Number of edges in the network57,67620,640Number of nodes in GC9482 (47.8%)7069 (35.6%)Number of edges in GC56,347 (97.7%)16,087 (77.9%)Average degree in the network5.812.08Average degree in GC11.894.55Network diameter2574Average shortest path length6.5818.8393Number of connected components8411219Size of components (min.-max.)2–192–53Number of isolates8251 (41.6%)8251 (41.6%)Average clustering coefficient0.140.18Number of communities in the network9124 (Q = 0.72)9539 (Q = 0.96)
Likewise, as shown in Table 3, we found most of the significant differences in word properties found in Vitevitch and Sale (2023). This table contrasts the two relevant word classes (i.e., words from the original giant component and retained in the backbone giant component versus words originally in the giant component but removed from the backbone giant component) and found significant differences in the same direction in all measures: log_10_ word frequency (t(1) = 10.38, p < 0.001), word length (t(1) = −47.82, p < 0.001), degree (t(1) = 40.29, p < 0.001), and closeness centrality (t(1) = 381.68, p < 0.001). The one salient difference between the SUBTLEX-US and HML networks is that Vitevitch and Sale (2023) did not find a significant difference in average clustering coefficient between these two word classes, but we did, with an increase in cluster coefficient in words removed from the giant component in the backbone network (t(1) = – 13.26, p < 0.001). This difference correlates with a modest increase in clustering coefficient in the larger backbone network (Table 2). We do not have an explanation for this difference, other than our backbone network has removed many more relatively important words from the original giant component than the HML backbone network (approximately eight times as many). With such a drastic drop in potential neighbors in the giant component, this may reduce the clustering coefficients of words in this component. If this is true, then this difference is a consequence of our model parameters (see above) and not a major difference between the HML and SUBTLEX-US networks. Table 3. Characteristics of words in and out of GC after backbone analysisOriginal GCGC of backboneOrig. GC/Not BbNumber of nodes948270692413Frequency (log_10_)0.78 (0.75)0.82 (0.78)0.65 (0.64)Word length (# phonemes)4.31 (1.12)4.02 (1.03)5.13 (0.96)Degree11.89 (13.65)13.27 (13.50)4.56 (7.12)Clustering coefficient0.28 (0.24)0.29 (0.22)0.40 (0.40)Closeness centrality0.16 (0.03)0.18 (0.03)0.01 (0.01)
Small-world properties
In networks with so-called small-world properties, nodes tend to be connected to each other with a small number of intermediaries. For example, the US air transportation network has 546 nodes (airports) and only 2791 links (one-stop flights), so the minimum number of connecting flights between two airports could be large theoretically. However, the average path length between any two nodes is 3.2 (data from OpenFlights.org). More formally, small world networks have small average shortest path lengths and high average clustering coefficients when compared to the average clustering coefficients expected in equivalent Erdős-Rényi graphs, which are graphs that have the same number of nodes and edges but the edges are randomly inserted between node pairs (Watts & Strogatz, 1998). We expect our phonological similarity networks to exhibit small-world properties because they have been found in the HML similarity network (Vitevitch, 2008) and even in networks based on pseudo-lexicons in which words were generated by drawing phonological segments at random from a fixed sound inventory (Gruenenfelder & Pisoni, 2009).
We follow standard practice in calculating these measures from the giant component of a network (Vitevitch, 2008) and report average shortest path length and clustering coefficients for all networks in Table 4. To address the potential for variation in the Erdős-Rényi networks, we created ten such networks for each network size and type and report the mean values of each set of ten networks here. We also report the Humphries–Gurney small-world-ness measure S, which is a function of average shortest path length and clustering coefficients in these tables, and another standard technique for evaluating small-world-ness (Humphries & Gurney, 2008). Humphries and Gurney assume that a network with an S greater than 3 has small-world properties and only applies tests of significance to networks with a lower S. Table 4. Average shortest path length, clustering coefficients, and Humphries–Gurney small-world-ness S for SUBTLEX-US and matched Erdős-Rényi (ER) networksLemmasWord formsASPLASPL-ERCCCC-ERHG SASPLASPL-ERCCCC-ERHG S2^10^5.10403.64510.32570.011520.225.09273.77080.31680.010322.672^11^4.95433.62350.31710.007431.435.09893.69360.31190.006932.592^12^5.46903.61030.30720.004842.505.92423.79730.29030.004244.512^13^6.11903.65540.29700.003059.626.34233.88520.28640.002375.432^14^6.10793.69380.29120.001993.216.57613.96060.27640.0014116.752^15^6.20123.71350.27440.0012135.656.75203.98700.27270.0009182.38
It is clear from these results that all networks, regardless of size or word representation, have small-world properties. They all have low average shortest path lengths and high average clustering coefficients. The latter is an order of magnitude greater than the average clustering coefficients of random matched networks, but this is not the case with average shortest path length, as found in prior studies. For example, the network closest in size to the HML network, with 2^14^ nodes (lemma representations), has a logical limit of 16,382 intermediaries (i.e., the number of nodes minus two for the source and target nodes), but an average path length of 6.1 (or 5.1 intermediaries on average). Likewise, the average clustering coefficient, 0.2912, is 153 times larger than the same value for a random matched graph. Finally, all networks have a Humphries–Gurney S far exceeding the threshold of 3 and their S values grow with network size. These facts all support the conclusion that the SUBTLEX-US networks are like other phonological networks in having small world properties, and that network size and word representation do not affect this outcome.
Degree distributions
Many studies have investigated the degree distributions of phonological networks to gain insight into network structure. For example, the breadth of degree distributions, or degree variability across the network, can be indicative of structural constraints in the network, like the limitations imposed by using a limited segment inventory to form words (see Vitevitch (2008) and Arbesman et al. (2010) for discussion). Below we examine the degree distributions in our SUBTLEX networks in order to compare them with known networks used in psycholinguistics.
Following Vitevitch (2008), we analyzed the degree distributions of the interconnected giant components. The facts about these distributions in Table 5 show that all phonological networks are sparse in the sense that average degree is low relative to network size. Further, the low heterogeneity parameter values (see appendix) indicate that, while the degree distributions may be broad, the distribution is weighted toward low-degree nodes. Table 5. Basic information about the degree distribution and the giant components of phonological networksNodesNodes_GC_EdgesAssortativityHeterogeneityDegree_Average_Degree_Max_Degree_SD_Word forms102455516230.590.175.85234.532048106639740.650.127.46356.184096203586360.660.118.49437.418192402019,6650.710.099.78549.5916,384794444,8590.750.0811.297912.6032,76814,94998,8090.770.0713.2211216.1665,53628,117211,3610.770.0615.0314119.3074,28632,097249,8230.770.0615.5715120.3619,839948256,3470.760.0711.898913.65Lemmas102452916380.630.166.19234.992048102839640.660.127.71366.404096199896010.680.099.61498.458192383921,9730.720.0811.456811.7816,384716248,3450.740.0713.509615.5732,76813,134105,6390.760.0616.0913520.2449,69019,172167,6300.750.0517.4915022.7219,839848561,0390.750.0614.3910217.02
Degree distributions plot the count of nodes on the y-axis and degree of these nodes on the x-axis. These distributions are generally plotted in double logarithmic scale in order to resolve their shapes at different orders of magnitude. Prior research has attempted to flesh out the type of function that best characterizes these distributions. For example, Vitevitch (2008) argues that the degree distributions of the giant component of the Hoosier Mental Lexicon network are better characterized by an exponential function than a power-law function. Figure 1 shows the fit of the degree distributions with four classes of functions that have been parameterized to have the best fit within their class (fits with power-law functions were computed with the Python powerlaw toolkit from Alstott et al. (2014)). These fits, and Kolmogorov–Smirnov distances reported in Table 6, support two conclusions. First, the degree distributions from the SUBTLEX networks are curved for the whole range of degrees. This fact suggests that the distributions are not power-law or truncated power-law distributions, which should appear as straight lines on log–log scales. Second, the best fit functions in terms of their KS distance are exponential for networks with 4096 nodes or fewer and log-normal in networks with a greater number of nodes.Fig. 1. Curve fits of degree distributionsTable 6Kolmogorov–Smirnov distance for fit of log–log degree distributions with four classes of functionsNodesNodes_GC_Log-normalExponentialPower lawTruncated power lawWord forms10245550.06690.03590.22880.1396204810660.06040.03040.23360.3602409620350.05900.03200.22460.1329819240200.04140.05320.21380.112616,38479440.03060.08590.21670.107232,76814,9490.02310.10220.22000.105465,53628,1170.01730.11880.21260.093674,28632,0970.01680.12660.21240.091919,83994820.02780.09060.22100.1097Lemmas10245290.06210.02760.22360.1416204810280.05750.03080.24590.1622409619980.06060.03100.23560.1442819238390.04320.06700.21740.111416,38471620.02980.09650.21160.097432,76813,1340.02400.12440.20600.085849,69019,1720.02640.14820.19530.071619,83984850.02880.10780.21560.0998
The fact that some SUBTLEX networks have exponential distributions agrees with Vitevitch’s (2008) findings (though this work did not test for log-normal distributions) and Gruenenfelder and Pisoni (2009), which found similar results for artificially generated phonological networks. The fact that larger networks seem to follow a log-normal distribution is consistent with the findings of Siew and Vitevitch (2019) for degree distributions in a phonographic network that combines both phonological and orthographic similarity in a phonological network, though this type of distribution has only recently been explored.
Robustness
Networks like transportation networks can be fragile in the sense that removing high-degree nodes, or hubs, can greatly impact the connectedness of other nodes. Language networks, on the other hand, have been shown to be robust to node removal (Arbesman et al., 2010; Vitevitch et al., 2023). This robustness has been demonstrated by comparing node removal at random and by descending degree, and then assessing the impact of the node removal on average path length and the size of the giant component. For example, Arbesman et al. showed that there is little difference between these two ways of deleting nodes in five languages, even after removing up to 5% of the nodes. Thus, unlike transportation networks with vulnerable hubs, language networks can lose many high degree nodes and still maintain connectedness.
We also investigated the robustness in order to compare phonological networks based on the SUBTLEX-US lexicon and the HML. In particular, we removed nodes at random and by degree in networks with both lemma and word-form representations matched in size with the HML as well as the largest networks. The impact of these two removal processes is shown in Fig. 2 on the proportion of nodes in the giant component. We opt to measure the impact on the giant component, which is a relatively standard technique (Menczer et al., 2020), rather than on the average shortest path length because when a node is deleted, it can either increase or decrease the average shortest path length, which complicates analysis. As shown in all four plots, there is little difference between random node removal (failures) and node removal by descending degree (attacks) in the beginning stages of node removal. In particular, there are only negligible differences between these two processes up until roughly 39% of the giant component nodes are removed, after which the connectedness of this component drops dramatically in attacked networks. All phonological networks, regardless of word representation and size, are also assortative in the sense that they have large and positive correlations in degree of the nodes they are connected to (see Table 5), which further supports their robustness. These findings are consistent with those of Arbesman et al. (2010) and Vitevitch et al. (2023), which also found that language networks are robust to node removal and had assortative mixing by degree.Fig. 2. Effect of node removal of random nodes (failures) and by highest degree nodes (attacks) on giant component size
Comparison with matched stimuli groups
How do the values of specific measures from the SUBTLEX phonological networks compare to ones derived from other networks? We address this question by comparing network science measures from prior studies and those from a comparable SUBTLEX network. These studies carefully constructed groups of stimuli that differed significantly in network science measure but were matched on other characteristics relevant to the behavioral effects they investigated, such as phonological size and word frequency, so their differences were not predictable from these other variables. Our rationale is that if the SUBTLEX-US words have comparable values, the differences between the two groups should be similar to the differences in these prior studies. The measures used include degree (Arnold et al., 2005; Chan & Vitevitch, 2015; Munson & Solomon, 2004) and clustering coefficient (Chan & Vitevitch, 2009, 2010; Vitevitch et al., 2012). All these studies, except Arnold et al. (2005), used a lemma-based phonological similarity network based on the Hoosier Mental Lexicon. Accordingly, we calculated the same mean values for the two sets using a sized-matched lemma-based network. The rows in Table 7 examine the degree and clustering coefficient values from these studies, and calculate the mean of each group (i.e., high vs. low) and the difference between groups, for both phonological networks. A few stimuli from prior studies could not be compared because they were not present in the SUBTLEX-US corpus, but this was only about 7% of the 387 stimuli words considered. Table 7. Comparison of degree and clustering coefficient for two phonological networks, HML and SUBTLEX-USMeasures from past studiesMeasures from SUBTLEX networkNLow (SD)High (SD)Diff, %ΔLow (SD)High (SD)Diff, %ΔDegree Arnold et al., 2005107.0 (1.2)12.6 (4.6)5.6, 80%17.4 (5.6)48.2 (26.1)30.8, 117% Chan & Vitevitch, 2015 E15915.93 (2.7)27.5 (2.0)11.4, 73%23.96 (6.8)35.7(6.8)11.8, 49% Munson & Solomon 2004 E2a3421.2 (6.3)23.2 (7.7)2.0, 10%29.1 (10.7)30.0 (10.0)0.82, 3% Munson & Solomon 2004 E2b3819 (7.0)24.2 (6.4)5.2, 27%26.2 (8.6)32.5 (8.7)6.3, 24%Clustering coefficients Chan & Vitevitch, 2009720.25 (0.03)0.35 (0.04)0.10, 40%0.27 (0.05)0.37 (0.08)0.09, 34% Chan & Vitevitch, 2010530.28 (0.05)0.34 (0.06)0.07, 23%0.31 (0.06)0.37 (0.12)0.06, 21% Vitevitch et al., 2012 E1270.22 (0.02)0.58 (0.12)0.36, 164%0.25 (0.04)0.56 (0.13)0.31, 122% Vitevitch et al., 2012 E2370.30 (0.05)0.53 (0.15)0.23, 76%0.27 (0.04)0.45 (0.18)0.18, 65% Vitevitch et al., 2012 E3300.24 (0.03)0.35 (0.04)0.11, 47%0.26 (0.03)0.37 (0.06)0.11, 41%
In all nine comparisons, the difference in the SUBTLEX-US network was in the same direction as the HML network. That is, high group means always exceeded low group means. Furthermore, while their absolute means are somewhat different, the magnitude of the change from low to high is comparable. Thus, when a change from low to high is great (e.g., Vitevitch et al., 2012 E2) or small (e.g., Munson & Solomon 2004 E2a), so, too, is the magnitude of the change in the SUBTLEX-US network. However, in a few cases (e.g., Munson & Solomon, 2004 E2a), differences between groups in both networks are inside the standard deviations for the stimuli sets, leaving one to wonder if these groups truly represent a robust contrast. We, therefore, pooled the values for these studies (excluding Arnold et al. (2005)) and calculated how well the actual values are correlated (Table 8). It turns out that degree and clustering coefficient are in general highly correlated between the HML and SUBTLEX-US networks, though this effect drops with low clustering coefficient words. Table 8. Correlations in pooled stimuliDegreeClustering coefficientLow0.730.45High0.700.70All0.770.76
This correlation dip for low-frequency words is not an effect of word length because all words examined from these studies (low and high) are monosyllabic, but it could be an effect of the fact that high-frequency words tend to have higher phonotactic probability (see e.g., Zamuner, 2009). High probability portions of high-frequency words may increase the potential that two similar neighbors are also neighbors, whereas this potential may be more random with low-frequency/low-probability words. Therefore, our SUBTLEX-US network may differ more from these other networks in the neighborhood of low-frequency words, and so they are less well correlated.
Conclusion and accessibility
In order to address resource limitations in network science, we created several phonological similarity networks based on the SUBTLEX-US lexicon (Brysbaert & New, 2009). In particular, we created 17 networks that differed in size and word representation by constructing adjacency lists for them. These adjacency lists were then examined to determine if network size and word representation impacted network characteristics, as well as if the networks based on the SUBTLEX-US lexicon differed in important ways with a network based on the Hoosier Mental Lexicon. While we did find one difference with the size of the HML’s giant component, the comparable SUBTLEX network’s giant component was not unusual cross-linguistically. This difference was rather minor compared with a host of similarities between the HML and SUBTLEX networks. Both networks exhibit small-world properties, similar degree distributions, and robustness to node removal. This common ground was found in all networks, regardless of size or whether lemmas or word forms are used, supporting related findings in Shoemark et al. (2016) and as well as a study that compared the HML network to one based on experimentally elicited phonological associate data (Castro & Vitevitch, 2023). Both networks also exhibited similar effects on network structure after the extraction of a backbone network exposing important words in the network. Finally, we examined differences in specific values of degree and clustering coefficient for experimental items carefully selected to represent contrasts on these measures, and found comparable values, and comparable contrasts between groups, in the SUBTLEX network.
It seems, therefore, that the two networks represent fundamentally the same kinds of graph-theoretic properties, and both data sets can be used in future research. In terms of the practical differences between them, researchers familiar with SUBTLEX-US will know that it contains many odd ‘words’ like agr and some misspellings (approximately 2–3% of the data, based on a 200-word step sample), which introduce some noise into the data. Together with the fact that about a third of the transcriptions were produced programmatically and exhibit some variant pronunciations (see Sect. 2), some researchers may wish to stick to using networks based on the HML data set. On the other hand, we feel that we have convincingly shown that this variability does not lead to significant differences in the networks made from the two data sets. These findings parallel those of Brysbaert and New (2009), who showed that frequency norms based on the word-form representations of the SUBTLEX corpus, which also included some odd words, were just as predictive of behavioral patterns as those based on lemma representations. Furthermore, the access to the underlying data of the networks supports a whole host of research endeavors that are not currently possible for the HML data set. For example, the global measure of closeness centrality is relevant to a host of psycholinguistic behaviors (Castro et al., 2020; Goldstein & Vitevitch, 2017; Sudarshan Iyengar et al., 2012), yet it is generally not available from online psycholinguistic repositories. By applying computational methods like those available in Python’s networkX package to the adjacency lists available with this article, researchers can easily generate measures like this, as well as values for measures that are generally available but are not available for all lexical items they wish to employ in their experiments. A network based on the SUBTLEX-US corpus may be a real benefit in this context because it includes both headwords and related inflected word forms (instead of just the lemmas of the HML) and drawing from TV and film media, it can support research on more colloquial words, as for example found in social media platforms. More broadly, the underlying data gives researchers more room to explore language network science, including important properties like community structure and multi-plex networks (in combination with other data sets).
All of the digital resources for this project are available from the GitHub project page: https://github.com/aldo-git-bit/phonological-similarity-networks-SUBTLEX. This page includes adjlists for all 17 networks, Python programs and functions for generating and analyzing the networks, and documentation that gives an introduction to the functions that underlie the programs. In terms of functionality, the adjlists can be accessed in programming environments such as Python or R, which allows validation and extension of the results reported here for entire networks. Researchers can also use the adjlists and special purpose scripts to extract network science measures for specific experimental items relevant to their research. In addition, our GitHub data pipeline can be expanded in a host of ways, including applying it to other English corpora, languages other than English, and other measures of phonological distance (see the README > Extensions section of the GitHub project page).
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Hagberg, A., Swart, P. J., & Schult, D. A. (2008). Exploring network structure, dynamics, and function using Network X. In G. Varoquaux, T. Vaught, & J. Millman (Eds.), Proceedings of the 7th Python in Science Conference (Sci Py 2008) (pp. 11–15).
- 2Klein, G., Kim, Y., Deng, Y., Senellart, J., & Rush, A. (2017). Open NMT: Open-Source Toolkit for Neural Machine Translation. In Proceedings of ACL 2017, System Demonstrations (pp. 67–72). Association for Computational Linguistics.
- 3Mphilli, Krawiec-Thayer, M. P., Neri, V., T-Cool, & Benetti, B. (2019). Converts English text to IPA notation. In https://github.com/mphilli/English-to-IPA/tree/a 17c 83eadddfd 5888 a 1078 b 5632860 cf 474a 5c 2d
- 4Nusbaum, H. C., Pisoni, D. B., & Davis, C. K. (1984). Sizing up the Hoosier Mental Lexicon: Measuring the familiarity of 20,000 words. In I. University (Ed.), Research on Speech Perception Progress Report No. 10.
- 5Ryan, Z. (2020). English to IPA translation using a neural network. In https://github.com/Lonely Rider-cs/LING 4100_project
- 6Shoemark, P., Goldwater, S., Kirby, J., & Sarkar, R. (2016). Towards robust cross-linguistic comparisons of phonological networks. In Proceedings of the 14th Association for Computational Linguistics SIGNORPHON workshop on computational research in phonetics, phonology, and morphology (pp. 110–120).
- 7Stella, M. (2019). Modelling early word acquisition through multiplex lexical networks and machine learning. Big Data and Cognitive Computing, 3 bdcc 3010010.
- 8Tiv, M., Gullifer, J., Feng, R., & Titone, D. (2020). Using network science to map what Montéal bilinguals talk about across languages and communicative contexts. Journal of Neurolinguistics.10.1016/j.jneuroling.2020.100913 PMC 747300432905520 · doi ↗ · pubmed ↗