Few-shot learning for non-vitrified ice segmentation
Alma Vivas-Lago, Daniel Castaño-Díez

TL;DR
This paper introduces Ice Finder, a new tool using few-shot learning to identify crystalline ice in cryo-electron tomography, improving adaptability and efficiency.
Contribution
The first application of meta-learning to cryo-electron tomography for ice segmentation, enabling rapid adaptation with minimal data.
Findings
Ice Finder demonstrates strong domain generalization across diverse cryo-electron tomography datasets.
The tool achieves fast processing and millisecond inference times on in situ datasets from EMPIAR.
Few-shot learning significantly improves adaptability to new datasets with minimal examples.
Abstract
This study introduces Ice Finder, a novel tool for quantifying crystalline ice in cryo-electron tomography, addressing a critical gap in existing methodologies. We present the first application of the meta-learning paradigm to this field, demonstrating that diverse tomographic tasks across datasets can be unified under a single meta-learning framework. By leveraging few-shot learning, our approach enhances domain generalization and adaptability to domain shifts, enabling rapid adaptation to new datasets with minimal examples. Ice Finder’s performance is evaluated on a comprehensive set of in situ datasets from EMPIAR, showcasing its ease of use, fast processing capabilities, and millisecond inference times.
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
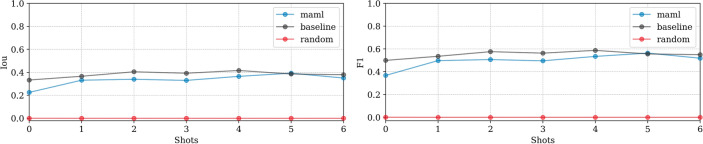 Figure 10
Figure 10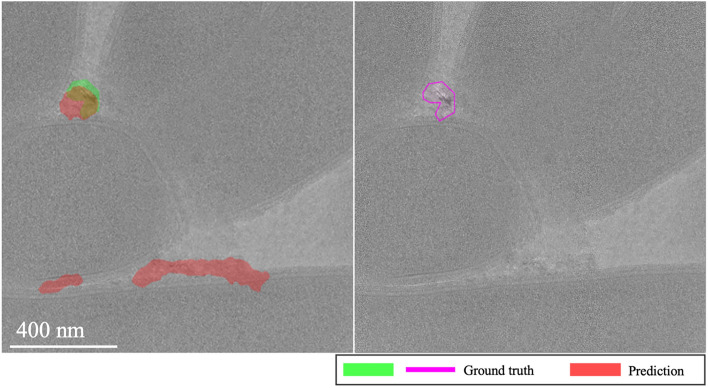 Figure 11
Figure 11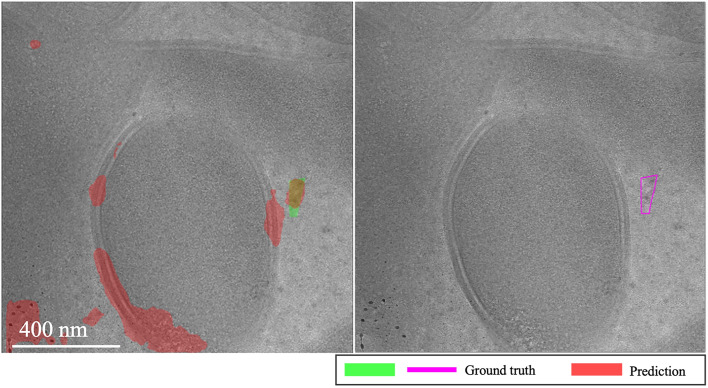 Figure 12
Figure 12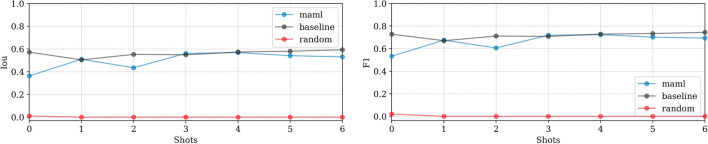 Figure 13
Figure 13 Figure 14
Figure 14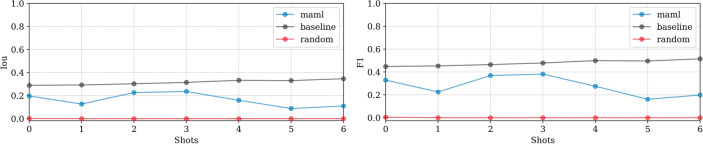 Figure 15
Figure 15 Figure 16
Figure 16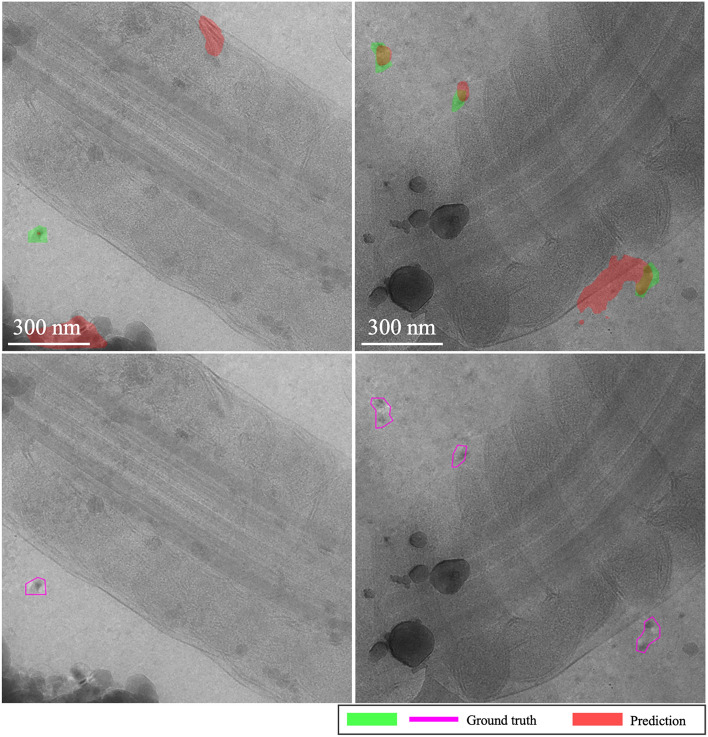 Figure 17
Figure 17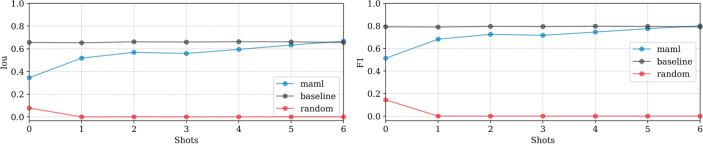 Figure 18
Figure 18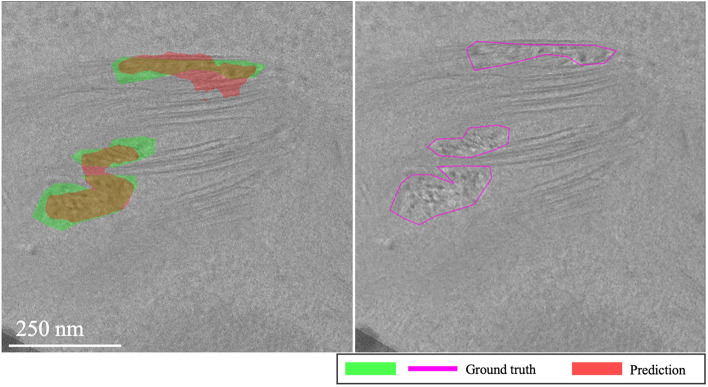 Figure 19
Figure 19 Figure 1
Figure 1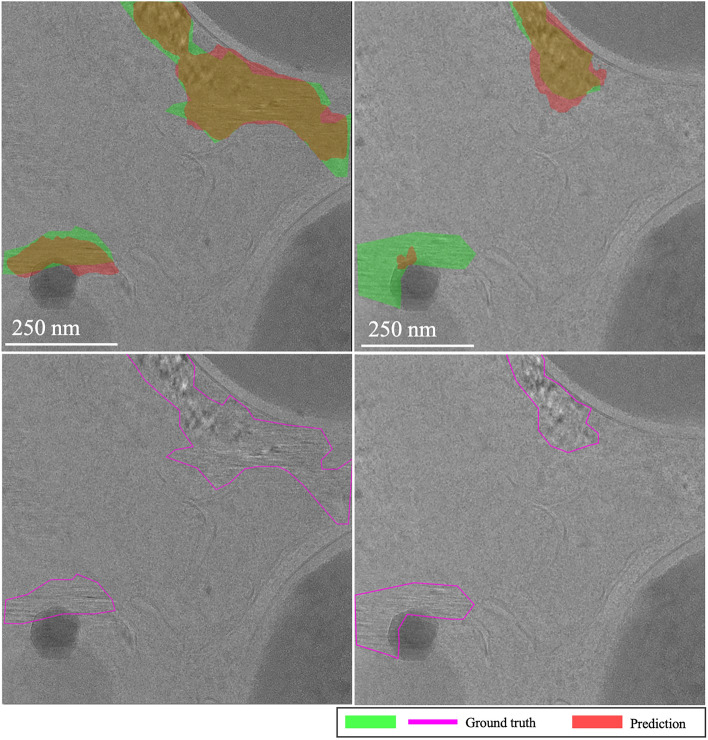 Figure 20
Figure 20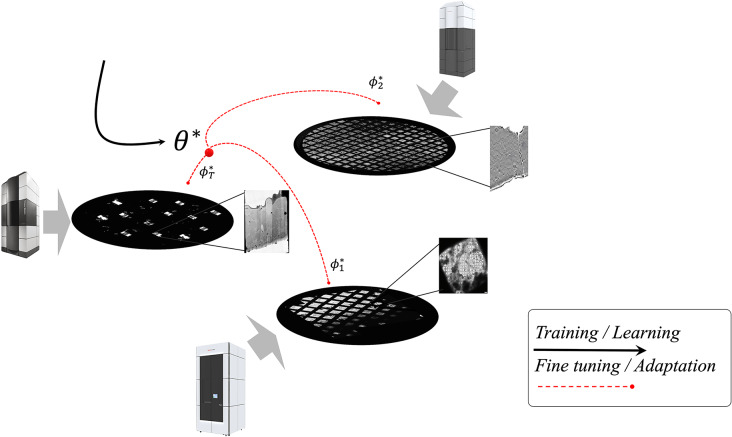 Figure 2
Figure 2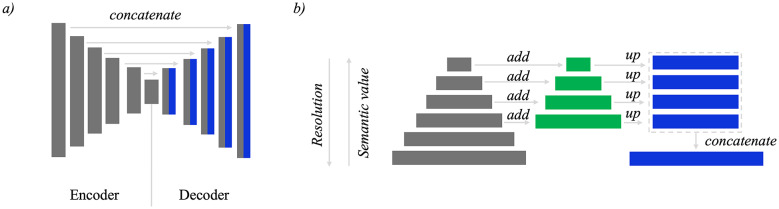 Figure 3
Figure 3 Figure 4
Figure 4 Figure 5
Figure 5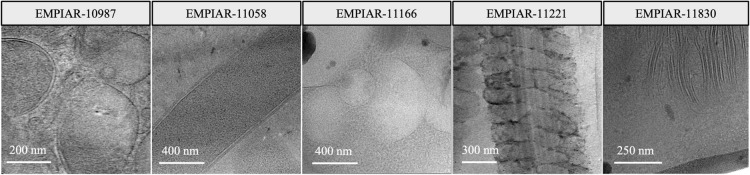 Figure 6
Figure 6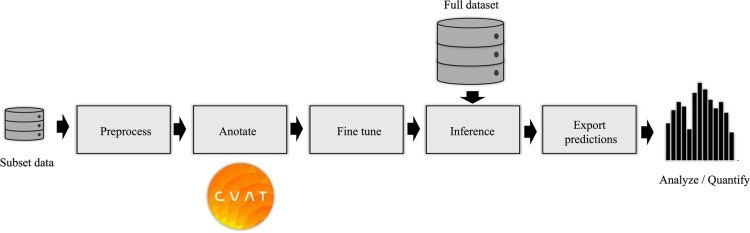 Figure 7
Figure 7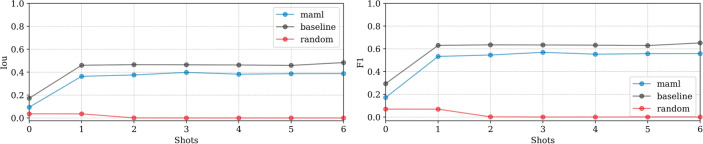 Figure 8
Figure 8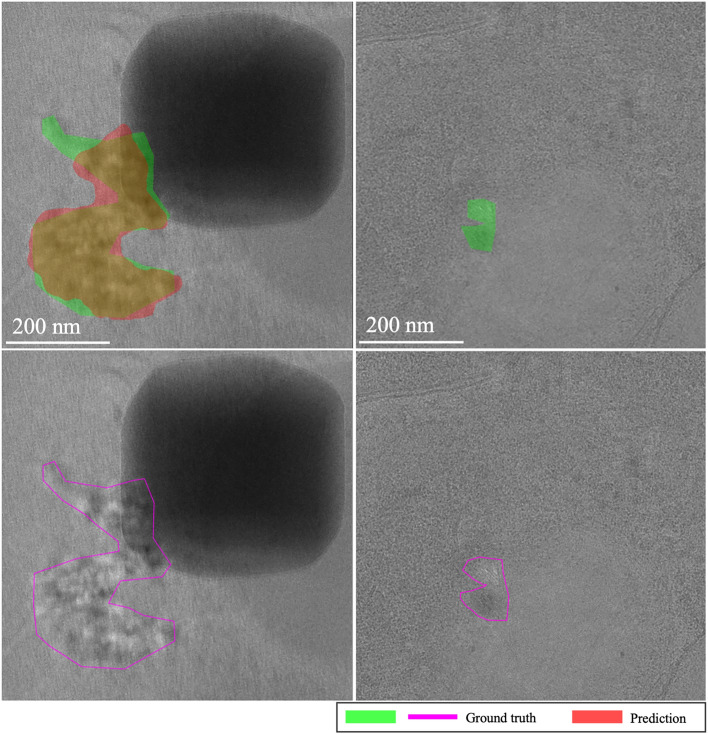 Figure 9
Figure 9 Figure 21
Figure 21 Figure 22
Figure 22- —Consejo Superior de Investigaciones Cientificas (CSIC)
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsAdvanced Electron Microscopy Techniques and Applications · Geophysical and Geoelectrical Methods · RNA modifications and cancer
Introduction
In the realm of structural biology, cryo-electron tomography (cryo-ET) has become indispensable for capturing detailed molecular landscapes of cells and tissues under conditions that closely mimic their natural state^1^. Historically significant, electron microscopy launched modern cell biology over sixty years ago by enabling the study of cellular ultrastructure. Today, cryo-ET extends this legacy by bridging the divide between molecular and cellular structural studies, providing subnanometer resolution within the cellular context^2^.
At the core of this technique is the process of vitrification, which preserves biological structures by rapidly freezing water into amorphous or vitreous ice^3^. This method avoids the formation of structured ice that could disrupt and distort cellular architecture, ensuring that samples retain a state nearly indistinguishable from their natural, hydrated condition^4^.
Traditionally, the stringent requirements of cryo-ET—such as precise control over sample thickness^5^ and the use of advanced preparation methods like cryo-sectioning^6,7^ or focused ion beam (FIB) milling^8–10^—limited its application to a few specialized labs^11–19^. These methods are crucial not only for achieving ultra-thin sections necessary for clear imaging but also for the meticulous optimization of cryoprotectants^20^, tailored specifically to each sample to prevent ice crystal formation^21,22^.
However, the field is experiencing a significant transformation. Advances in technology and procedural enhancements^23^, including the integration of light microscopes within FIB chambers^24–27^ and the automation of sample preparation^28,29^ and imaging^30–33^, have made cryo-ET more accessible. The availability of user-friendly, commercial equipment and the standardization of methods have broadened the technique’s appeal, supported by a growing network of specialized facilities that offer both essential tools and expert guidance, solidifying its role as a fundamental technique in structural biology^1^.
This democratization has expanded its use among novices and experts alike, facilitating complex workflows such as those integrating cryo-correlative light and electron microscopy (cryo-CLEM)^34^ to identify specific macromolecular complexes within crowded cellular environments^35^. Despite these advancements, challenges in sample preparation remain, particularly with vitrification. As the field pushes towards studying increasingly complex macromolecular assemblies^36^, the steps required to ensure complete vitrification frequently fall short^21^. This issue is compounded by prolonged workflows that increase the likelihood of crystal nucleation^37^. The subsequent growth of these crystals and further devitrification lead to significant phase changes, producing dramatic diffraction contrasts that can obscure and distort the structures of interest, ultimately complicating the interpretation of micrographs due to artifact-driven image formation^38^.
Despite the emergence of numerous new software tools aimed at enhancing image analysis and data quality^39^, a crucial gap remains: there is currently no tool that can effectively quantify the presence of structured ice within tomographic samples. While detection is straightforward in single-particle cryo-EM, where tools like CryoSPARC^40^ efficiently remove problematic micrographs, cryo-ET encounters greater challenges. In single-particle cryo-EM^41^, each sample is imaged only once, allowing the full electron dose to be utilized. This maximizes the signal-to-noise ratio, generating high-resolution datasets containing hundreds of thousands to millions of particle images of the biological molecule of interest, providing an ideal “portrait” of the target molecule^42–45^. In contrast, tomography^46^ acquires a series of images at different tilts, fractionating the dose across multiple images. This method often involves cellular or tissue environments where the surroundings are more crowded and complex^47^. Consequently, cryo-ET faces lower signal-to-noise ratios and sometimes inadequate pixel sizes, complicating the detection of diffraction peaks (see Fig. 1). Addressing this gap with the introduction of an automated tool capable of quantifying structured ice presence in in situ workflows is critical. Such a tool would diminish the need for manual inspection of hundreds of tomograms and significantly accelerate structural studies, better meeting the demands of modern biological research^48^.Fig. 1. Comparison of data collection strategies. Single-particle cryo-EM (left) with a single high-dose image (32 e^−^ Å^−2^), and cryo-ET (right) with multiple lower-dose tilt images (2.7 e^−^ Å^−2^). The sample is Apoferritin from the EMPIAR-10491 frame and tilt-series data collected from the same grid square under identical conditions.
The inherent complexity and variability in biological samples pose significant challenges for standardizing image analysis in tomography. Each sample exhibits unique characteristics, leading to substantial intra- and inter-sample variability. This reality underscores the need for systems that can quickly adapt to new datasets and learn effectively from just a few examples. Encouraging the ability of a system to learn from a limited number of examples is referred to in the literature as few-shot learning (FSL). This property can be achieved by enhancing with prior knowledge three building blocks of the system: data, model, and algorithm^49^. The overall objective of the modifications is to make the empirical risk minimizer reliable again.
Typically, when data is enhanced, the goal is to increase the number of instances in the training dataset. This can be achieved through various methods: learning a transformation function to apply to the original training samples, developing a predictor based on the original training data which is then used on a weakly labeled or unlabeled dataset, or creating an aggregator function that modifies samples from similar datasets.
Conversely, solutions that focus on modifying the model aim to use prior knowledge to constrain the hypothesis space. Several strategies have been developed for this purpose, known in the machine learning literature as multi-task learning, embedding learning, learning with external memory, and generative modeling. Delving into each of them is out of the scope of this manuscript, the interested reader is referred to^49^.
Finally, prior knowledge is utilized to modify the search strategy within the hypothesis space to identify the parameters of the best hypothesis. Approaches like these impact the parameter discovery process by either providing well-initialized parameters or teaching the optimizer to navigate the search steps effectively. A well-known technique that falls within this category is transfer learning, where an initial parameter set is learned from a different task and then refined using training data specific to the current task. Since this technique often does not work well when the target dataset is small, our study explores an alternative approach known as model-agnostic meta-learning (MAML), which refines meta-learned parameters for effective few-shot learning applications^50^.
Meta-learning, often described as “learning-to-learn”^51^, leverages the experience accumulated over multiple learning episodes, each encompassing a distribution of related tasks. This methodology aims to enhance the efficiency and effectiveness of future learning processes. By distilling^52,53^ insights from these episodes, meta-learning improves both data and computational efficiency, aligning more closely with human and animal learning, where learning strategies evolve over both individual lifetimes and evolutionary timescales^54–57^.
Historically, neural network meta-learning has a rich lineage, but its potential has only recently catalyzed a surge in research within the deep learning community^58–62^. This resurgence is driven by meta-learning’s promise to address key limitations of traditional deep learning, particularly through enhanced data efficiency and superior knowledge transfer capabilities^57^.
Meta-learning excels in multi-task environments, where task-agnostic knowledge derived from a diverse array of tasks can be harnessed to expedite learning in new, related tasks^63^. This approach aligns with the perspective of using meta-learning to mitigate the “no free lunch” theorem^64^ by optimizing the inductive biases that best suit specific problem domains. Beyond the traditional scope, contemporary neural network meta-learning is formulated as end-to-end learning of explicitly defined objective functions, thereby refining the learning processes through these tailored goals^57^.
While transfer learning^65^ is traditionally favored for its ability to utilize prior knowledge from related tasks to enhance performance on new tasks, our study also considers the broader spectrum of learning strategies, including meta-learning. Both approaches will be explored to determine which is more effective at meeting our objectives in the context of limited data availability.Fig. 2. Schematic view of the few-shot learning framework applied to tomographic analysis. This diagram illustrates the process of adapting initial optimized weights \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\theta ^*$$\end{document} to new datasets with limited examples, resulting in optimized task-specific parameters \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\phi ^*_{\tau }$$\end{document} . This visualization underscores the complexity of tomographic datasets, which can encompass thousands of micrographs across multiple grids, each with unique sample contents and configurations. The diversity and scale of these datasets pose significant computational challenges, necessitating robust few-shot learning strategies for effective adaptation and learning.
We present a general schematic view of our learning framework tailored to few-shot learning. This illustration, depicted in Fig. 2, demonstrates the process of fine-tuning initially learned parameters based on a few labeled examples from the target domain. Our aim is to identify the most efficient method—be it transfer learning or meta-learning—for achieving sample-efficient learning, domain generalization, and robustness to domain shifts within the challenging environment of tomography.
Our main contributions are threefold: (1) we developed a new tool to quantify crystalline ice, addressing a significant gap in current methodologies; (2) we demonstrated the first proof of concept of applying the meta-learning paradigm to tomography, showing that tomographic tasks across datasets can be unified under a single meta-learning framework; and (3) we evaluated the performance of our Ice Finder tool for few-shot segmentation using a comprehensive set of publicly available in situ datasets.
Proposed method
Segmentation model
In this study, we employ the Feature Pyramid Network (FPN) architecture for the segmentation task. The choice of FPN over other architectures such as U-Net is driven by its superior handling of objects at different scales. The general architectures of both U-Net and FPN are illustrated in Fig. 3.Fig. 3. The architectural overview of U-Net and FPN models. (a) U-Net employs a symmetric encoder-decoder structure with skip connections to enhance detail preservation. (b) FPN leverages a top-down pathway with lateral connections, enabling multi-scale feature mapping for efficient handling of objects of varying sizes.
The U-Net architecture, widely recognized for its success in semantic segmentation tasks^66^, follows a symmetric encoder-decoder structure. This design includes multiple upsampling layers and skip connections that concatenate features from the encoder to the decoder, enhancing the ability to capture fine details. However, in our scenario, the regions of interest within each micrograph vary significantly in size, which necessitates a model that can efficiently manage such scale variations.
FPN^67^ leverages the inherent multi-scale, pyramidal hierarchy of deep convolutional networks to construct feature pyramids with minimal additional computational cost. This architecture consists of a top-down pathway combined with lateral connections, which enables the creation of high-level semantic feature maps at multiple scales. The result is a robust representation that maintains strong semantic features across different resolution levels, making it particularly effective for detecting and segmenting objects of varying sizes within the same image.
Backbone architectures
In the context of fine-tuning, the choice of backbone architecture is crucial^68^ due to its impact on gradient behavior and training stability. The ResNet family is renowned for its efficacy in fine-tuning tasks, often leading to well-behaved gradients^69^. Despite their robustness, ResNet architectures can be challenging to train. To address this, we explore DenseNet, a natural extension of ResNet, which offers enhanced feature reuse and efficiency^70^.
Residual network
The key idea of Residual Networks is the use of identity mappings. Formally, a building block is to be defined as:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} y = F(x, {W_i}) + x. \end{aligned}$$\end{document}where x and y are the input and output vectors of the layers considered. The function \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$F(x, {W_i})$$\end{document} represents the residual mapping to be learned^71^.
In the revisited version, the propagation formulations allow signals (information) to be directly propagated from one block to any other block if an additive identity transformation is used. Coupling this idea with the original model’s skip connections and post-addition activation yields promising results^72^.
DenseNet
DenseNet builds on ResNet, offering a natural extension with unique properties. Instead of adding the input to the mapping function, it concatenates it. This approach allows each layer to have direct access to the feature maps of all its preceding layers, creating a “collective knowledge” of features within its blocks. This architecture facilitates feature reuse, resulting in higher parameter efficiency. Furthermore, DenseNet networks are considered easier to train^73^ due to the improved gradient flow through the network.
Few-shot learning framework
Transfer learning
Transfer learning tasks consist of a source and a target dataset, differing in terms of their underlying distribution.
- Stated formally^74^:
- Given a source domain \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$D_S$$\end{document} with input data \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$X_S$$\end{document} , a corresponding source task \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$T_S$$\end{document} with labels \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$Y_S$$\end{document} , as well as a target domain \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$D_T$$\end{document} with input data \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$X_T$$\end{document} and a target task \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$T_T$$\end{document} with labels \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$Y_T$$\end{document} , the objective of transfer learning is to learn the target conditional probability distribution \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$P_T (Y_T |X_T )$$\end{document} with the information gained from \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$D_S$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$T_S$$\end{document} where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$D_S \ne D_T$$\end{document} or \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$T_S \ne T_T$$\end{document} .
In this regard, in a fully supervised setting, there are two possible scenarios: domain adaptation, task containing a small amount of additional labeled target data, or domain generalization task, where the access is restricted to labeled source data.
Meta-learning
Meta-learning strategies differ significantly in how they utilize meta-knowledge, which determines the aspects of a learning strategy that are adaptive versus those that are fixed^57^. In our research, we employ optimization-based meta-learning methods, valued for their robust consistency and superior generalization capabilities over black-box or non-parameterized approaches^50^. Notably, MAML stands out for maintaining inductive bias, crucial for expressive model performance without a loss in generality^75^.
MAML, an exemplar of optimization-based meta-learning, employs a computation graph embedded with gradient operations, making it distinct from conventional single-level optimization frameworks. This method requires a meta-dataset—a collection of diverse yet related datasets^63^—supporting bi-level optimization.
- Key Concept: Within MAML, tasks are treated as independent data points drawn from a shared task distribution \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$p(\mathcal {T})$$\end{document} , assumed to be independently and identically distributed (i.i.d.).
The meta-learning framework is formalized through key components:
- Task \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\tau$$\end{document} : Defined by its unique support and query sets.
- Support Set \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$(D_{\text {support}}^{\tau })$$\end{document} : Data subset for model parameter adaptation.
- Query Set \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$(D_{\text {query}}^{\tau })$$\end{document} : Data subset for evaluating model adaptation performance.
- Task Distribution \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$p(\mathcal {T})$$\end{document} : The probabilistic distribution from which tasks are sampled.
- Model Parameters \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\theta$$\end{document} : Initial shared parameters optimized across tasks during meta-training.
- Task-Specific Parameters \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\phi _{\tau }$$\end{document} : Adapted parameters specific to each task.
To contrast with traditional model training, where parameters \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\theta$$\end{document} are optimized through gradient descent to perform well on a single dataset (Algorithm 1), MAML optimizes initial model parameters \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\theta$$\end{document} to facilitate rapid adaptation across a spectrum of tasks (Algorithm 2). This dual-level optimization process, especially the adaptation in the meta-learning scenario, involves second-order gradient computations. Specifically, the gradient of the loss with respect to \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\theta$$\end{document} is contingent upon the gradients of the task-specific adapted parameters \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\phi _{\tau }$$\end{document} , making the method computationally expensive but highly effective for generalization across varied tasks.
By optimizing the learning process itself, MAML ensures robust generalization across different, but related tasks, thereby broadening the scope and applicability of the learned models in real-world scenarios.
Algorithm 1Regular gradient descent
Algorithm 2Model-Agnostic Meta-Learning (MAML)
Task design
In meta-learning, tasks must share a common structure, akin to the principle in transfer learning^76^. This shared structure can be either abstract or concrete. In our context, the structure refers to the optical characteristics of ice in its various phases, as shown in Fig. 4. We primarily deal with hexagonal ice ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\text {I}_h$$\end{document} ), cubic ice ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\text {I}_c$$\end{document} ), and, in the majority of cases, stacking-disordered ice ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\text {I}_{\text {sd}}$$\end{document} )^77^. Studies have shown that distinguishing between cubic ice and stacking-disordered ice, which is a mixture of cubic and hexagonal sequences, can be challenging^78^. Our preliminary experiments, indicated by diffuse diffraction patterns, confirm the presence of both phases (see Supplementary Fig. S1 online). Typically, poor vitrification from insufficient rapid freezing leads to hexagonal ice formation, while cubic ice formation suggests that an initially vitreous sample has warmed and subsequently devitrified^79^. These findings indicate that in many cases, poor initial vitrification followed by warming leads to the formation of stacking-disordered ice.Fig. 4. Crystalline phases of ice. Representative images of structural characteristics of hexagonal ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\text {I}_h$$\end{document} ) (a), cubic ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\text {I}_c$$\end{document} ) (b), and stacking-disordered ice ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\text {I}_{\text {sd}}$$\end{document} ) (c).
To design a task, we conceptualize it as a collection of micrographs—projections or images recorded from the microscope—from the same dataset, ensuring that they share the same microscope parameters/configuration, sample content, and preparation. For simplicity, we denote the dataset as a single grid, although it may encompass multiple grids. Each micrograph in a task comes from a different lamella—a thin slice of the sample—different tilt series, and different projection. This design ensures that the model learns the common features of crystalline ice while being exposed to diverse views and conditions, thus mimicking the behavior we aim to reproduce at meta-test time (see Fig. 5).Fig. 5. Illustration of task design for MAML. Each task is derived from a dataset consisting of micrographs captured under consistent microscope parameters and sample preparation conditions. The tasks include images from different lamellae, tilt series, and projections, divided into support sets ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$x^{\tau }_{\text {support}}, y^{\tau }_{\text {support}}$$\end{document} ) for model adaptation and query sets ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$x^{\tau }_{\text {query}}, y^{\tau }_{\text {query}}$$\end{document} ) for inner loop performance evaluation. While the goal remains semantic segmentation, variations in data distribution make each task distinct. This division allows the model to learn generalizable features across different but related tasks.
In a supervised learning setting, each task is split into a support set and a query set. The support set \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$(D_{\text {support}}^{\tau })$$\end{document} is used to adapt the model parameters to the specific task \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\tau$$\end{document} , while the query set ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$D_{\text {query}}^{\tau }$$\end{document} ) is used to evaluate the performance of the adapted model. This approach ensures that the model is trained to generalize well across different but related tasks, leveraging the shared structure of the data.
Results
This study leverages datasets from EMPIAR (Electron Microscopy Public Image Archive)^80^, hosted by EMBL-EBI. This public repository provides a wide range of datasets from various biological samples collected via EM, commonly used for development and validation in this field. Our dataset selection, detailed in Table 1, was strategically chosen to maximize diversity in biological characteristics, ensuring a varied test set as depicted in Fig. 6.Table 1. Details of EMPIAR entries used in the study.Entry IDPixel size [Å]Image size [pixels]SampleEMPIAR-10987(1.64, 1.64)(4092, 5760)80S ribosomesEMPIAR-11058(3.52, 3.52)(3712, 3712)Thermoanaerobacter kivuiEMPIAR-11166(3.52, 3.52)(3712, 3712)Saccharomyces cerevisiae autophagyEMPIAR-11221(3.46, 3.46)(3710, 3838)Mouse sperm flagellaEMPIAR-11830(1.90, 1.90)(4096, 4096)Chlamydomonas reinhardtii
Fig. 6. Overview of data used in the test set, showcasing the diversity of biological samples.
A comprehensive list of all in situ study samples considered is provided in Supplementary Table S1 online. This includes samples not directly analyzed in our study but available for future research. Datasets consisting solely of tomograms, single tilt series, or those derived from alternative modalities such as X-ray tomography were excluded to maintain consistency and relevance to our study’s objectives.
From each dataset, tilt series with vitrification issues were identified, and three tilt series per dataset were selected. Of these, one was used for training during k-shot testing, while the remaining two served as replicates to simulate real-world scenarios where fine-tuned models were applied in inference mode to evaluate performance. For further implementation details, please refer to the Supplementary Information online.
The Ice Finder workflow operates seamlessly within a Jupyter notebook^81^, with each step compartmentalized into distinct cells for clarity and ease of use (see Fig. 7). Users begin by preprocessing their selected tilt series (1 to 10 micrographs) by placing the stack in the designated folder and executing the preprocessing notebook cell. After preprocessing, images are annotated using CVAT^82^, where crystalline regions are marked with polygons. The annotations are exported, and their paths are input back into the system for fine-tuning the model. This process is streamlined with pre-configured hyperparameters, and the selected micrographs are automatically split into training and testing sets with a single action.Fig. 7. Workflow for using the Ice Finder tool. Users preprocess their data, annotate ice regions using CVAT, fine-tune the model with annotated examples from a pre-trained checkpoint on a large dataset, run inference on the full dataset, and export the analysis results. This streamlined process is integrated onto a Jupyter notebook, where each step is compartmentalized into distinct notebook cells.
A pre-trained checkpoint trained on a large dataset is provided as a starting point. Fine-tuning (k-shot) is performed on the new sample, and the best model is automatically selected upon completion. During inference, users place the complete dataset in the designated folder, allowing the model to analyze all images. Equipped with functions to save predictions and ground truth annotations, the workflow provides users with greater intuition to support decision-making. In the final analysis phase, segmented masks can be exported or used to generate statistics on the percentage of ice present, enabling a rapid and informed assessment of vitrification quality across samples.
Table 2 presents a quantitative analysis of the models’ domain generalization capabilities by comparing the predicted percentages of non-vitrified areas against the ground truth across various datasets.Table 2. Quantitative analysis of domain generalization across different datasets, measured as percentages of non-vitrified areas correctly identified in inference mode.ExperimentGround truth mean % (95% CI)Prediction mean % (95% CI)EMPIAR-109876.34% ± 1.93%7.35% ± 2.34%EMPIAR-110584.82% ± 1.19%10.96% ± 2.09%EMPIAR-111661.55% ± 0.39%3.55% ± 0.62%EMPIAR-112211.77% ± 0.45%2.56% ± 0.52%EMPIAR-118301.53% ± 0.41%3.98% ± 0.51%
The percentage of non-vitrified areas was chosen as the primary quantitative metric over the standard Intersection over Union (IoU) due to its simplicity and greater relevance for end-users. This metric directly aligns with the study’s objective of quantifying vitrification and provides a straightforward, interpretable measure tailored to practical needs.
This assessment offers a comprehensive view of model performance while laying the groundwork for a deeper analysis of each experiment’s adaptability to its domain. To this end, we systematically compare the performance of the baseline (vanilla transfer learning), MAML, and a randomly initialized model as a control under diverse and challenging biological conditions.
EMPIAR-10987: The models displayed consistent performance (see Fig. 8). This is attributed to effectively identifying the most prominent (i.e. salient), high-intensity ice patterns, while subtly revealing the lower frequency footprints as well. Figure 9 highlights their capability to detect pronounced patterns atop ethane blobs, although they occasionally underestimated the dimensions (see Fig. 9 first column). Notably, in the upper right of the extension, the ice was not detected, underscoring a limitation in recognizing less distinct features mixed with cubic phases (see Fig. 9, second column).Fig. 8. Domain adaptation performance: EMPIAR-10987. The graphs display the performance metrics of different models (MAML, baseline, and random) evaluated using IoU and F1 scores across multiple k-shot scenarios. The consistency in performance reflects the models’ capability to generalize across various domains by effectively learning and adapting to new data distributions.Fig. 9. Main sources of error for EMPIAR-10987. The images illustrate the primary challenges faced by the models, such as underestimating the dimensions of ice regions (first column) and failing to detect less distinct ice features mixed with cubic phases (second column). Despite these challenges, the models successfully identified prominent ice patterns, demonstrating their robustness and adaptability in complex scenarios.
EMPIAR-11058: Both models exhibited slight fluctuations in performance, synchronizing until the 4th k-shot where both achieved peak performance. Subsequently, at the 5th shot, the baseline model’s performance declined while MAML’s improved (see Fig. 10). This turning point corresponds to an image of a very thick lamella where the ice, appearing outside the bacterial structure and resembling a fluid-like, low-frequency pattern, offered a minor success for MAML—albeit still systematically below the baseline—highlighting its purported flexibility and robustness. The soft, fluid-like appearance, often shallow and weak, was typically unlabelled leading to false positive predictions as exemplified in Fig. 11. Another source of unexpected failures included misidentifications of bubbles caused by ion beam sample damage as depicted in Fig. 12.Fig. 10. Domain adaptation performance: EMPIAR-11058. The graphs display the performance metrics of different models (MAML, baseline, and random) evaluated using IoU and F1 scores across multiple k-shot scenarios. The performance variability reflects the models’ capability to generalize and adapt to new data distributions, with notable fluctuations corresponding to specific challenging samples.Fig. 11. Sharp features misidentification in EMPIAR-11058. The images highlight the misidentification of soft, fluid-like ice features, often leading to false positive predictions due to the unlabelled shallow and weak appearance of these patterns.Fig. 12. Ion beam damage misinterpretation in EMPIAR-11058. The images illustrate the misidentification of bubbles caused by ion beam sample damage, demonstrating a challenge in distinguishing these artifacts from actual ice features.
EMPIAR-11166: Initial shots exhibited turbulence, with the baseline struggling to integrate labels and MAML adjusting to optimize task performance. By the third and fourth k-shots, performances of both models aligned closely, matching exactly at the fourth shot. Thereafter, the baseline model showed slight improvement with a minimal slope, while MAML’s performance diverged (see Fig. 13). This variability largely stemmed from inconsistencies between the models’ recognition of ice and the provided labels, which only marked prominently salient ice relative to the feature signal of the image. Consequently, predictions captured weaker yet existent areas affected by vitrification. This issue was apparent in sheet-like patterns (Fig. 14, first column) and isolated spots to small regions of low-frequency crystalline ice reflections (Fig. 14, second column).Fig. 13. Domain adaptation performance: EMPIAR-11166. The graphs display the performance metrics of different models (MAML, baseline, and random) evaluated using IoU and F1 scores across multiple k-shot scenarios. The performance shows minor variability due to label inconsistencies, despite the nearly constant performance reflecting the target’s similar distribution. This highlights the models’ capability to adjust and generalize across various domains.Fig. 14. Variability in ice detection in EMPIAR-11166. The images highlight the challenges in detecting less prominent ice features. The first column shows sheet-like patterns, while the second column depicts isolated spots and small regions of low-frequency crystalline ice reflections, demonstrating the models’ adaptability and limitations.
EMPIAR-11221: Performance was notably lower across models (see Fig. 15). The baseline model showed gradual improvements with some instability, while MAML exhibited volatile behavior due to the diversity and difficulty of the examples encountered during fine-tuning. A primary error source was the significant variety in vitrification combined with a substantial domain shift. Extreme cases illustrated in Fig. 16 show challenges like unvitrified matrices with “brushstroke” reflections, where predictions inaccurately formed extensive ice sheets, leading to substantial mismatches with ground truth annotations (see Fig. 16, first column). Conversely, high-quality samples with minor “brushstroke-like” features were overly conservative, predicting virtually no vitrification issues (see Fig. 16, second column). Additionally, unusual artifacts caused false positives, particularly when contamination was clustered and off-axis, as opposed to when it was unclustered and aligned with the sample, where the model correctly identified and distinguished contamination from ice (see Fig. 17, first and second columns, respectively).Fig. 15. Domain adaptation performance: EMPIAR-11221. The graphs display the performance metrics of different models (MAML, baseline, and random) evaluated using IoU and F1 scores across multiple k-shot scenarios. The performance highlights the challenges of adapting to diverse and difficult examples, with significant domain shifts affecting model accuracy.Fig. 16. Brushstroke reflections and ice sheet formation in EMPIAR-11221, contrasting extremes from prevalent ice mispredictions to scenarios with no predicted ice issues. The images illustrate the challenges faced by the models in detecting and accurately predicting the extent of vitrification in diverse samples.Fig. 17. Contamination identification versus ice detection in EMPIAR-11221. The images show the model’s ability to distinguish between clustered contamination and ice, highlighting the difficulties in correctly identifying and labeling these features in challenging conditions.
EMPIAR-11830: The baseline model exhibited nearly constant performance, indicating a minimal domain shift from the training dataset. In contrast, MAML performance improved smoothly, matching the baseline by the 6th k-shot iteration (see Fig. 18). Challenges included misidentifying sharp chloroplast features as ice patterns, illustrated in Fig. 19. During fine-tuning, examples showcased ice in various phases (see Fig. 20, second column). Nevertheless, at test time it struggled with the recognition of cubic phases alone (see Fig. 20, first column), reflecting a typical class imbalance issue.Fig. 18. Domain adaptation performance: EMPIAR-11830. The graphs display the performance metrics of different models (MAML, baseline, and random) evaluated using IoU and F1 scores across multiple k-shot scenarios. The MAML model shows a gradual improvement, matching the baseline by the 6th k-shot iteration, while the baseline model’s nearly constant performance indicates minimal domain shift.Fig. 19. Misidentification of chloroplast features in EMPIAR-11830. The image shows instances where the model incorrectly identified sharp chloroplast features as ice patterns, highlighting the challenges faced in differentiating between these structures.Fig. 20. Class imbalance in cubic phase recognition in EMPIAR-11830. The images illustrate the model’s difficulty in recognizing cubic phases during testing, despite fine-tuning examples showcasing ice in various phases. This challenge reflects a typical class imbalance issue where less represented classes are harder to identify accurately.
Discussion
In this work, we introduced a novel tool for quantifying crystalline ice in cryo-ET, addressing a critical gap in existing methodologies. By applying the meta-learning paradigm to tomography, we unified multiple tomographic tasks within a single framework, demonstrating its potential for adaptability and domain generalization. However, the reliance on data from a single distribution proved to be a major limitation, hindering meta-learning’s ability to achieve optimal performance. This highlights the urgent need for diverse and balanced datasets to mitigate out-of-distribution challenges and enhance model performance across varied scenarios.
Interestingly, transfer learning outperformed meta-learning in practical applications, offering faster training times and easier fine-tuning. This reinforces the importance of leveraging algorithmic approaches that align with the current data landscape.
A key insight from this study is that inconsistencies in label quality significantly impact domain generalization. To address this, we advocate for the integration of temporal dimensions (e.g., LSTM^83^, GRU^84^, transformers^85^) into future models. These architectures can provide richer contextual understanding, improving labeling consistency, prediction accuracy, and overall model robustness.
Our Ice Finder tool, optimized for few-shot segmentation, demonstrates the ability to adapt rapidly to new conditions with minimal examples, offering a user-friendly and versatile solution. This functionality not only underscores the practicality of few-shot learning in this domain but also enables users to filter tilt series by crystallization percentages, reducing reliance on manual inspection and streamlining analytical workflows. We emphasize that user-defined fine-tuning is a crucial feature, allowing researchers to flexibly apply their specific labeling criteria. By prioritizing usability, the tool delivers simple yet powerful metrics that provide clear, actionable insights, enhancing both user experience and operational efficiency.
Supplementary Information
Supplementary Information.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Bäuerlein, F. J. et al. Cryo-electron tomography of large biological specimens vitrified by plunge freezing. bio Rxiv (2023).
- 2Sven, K. et al. A modular platform for automated cryo-FIB workflows. e Life 10 (2021).10.7554/e Life.70506 PMC 876965134951584 · doi ↗ · pubmed ↗
- 3Bharat, T. A. & Kukulski, W. Cryo-correlative light and electron microscopy: Toward in situ structural biology. Correlative Imaging: Focusing on the Future 137–153 (2019).
- 4Finn, C., Abbeel, P. & Levine, S. Model-agnostic meta-learning for fast adaptation of deep networks. In International Conference on Machine Learning, 1126–1135 (PMLR, 2017).
- 5Thrun, S. & Pratt, L. Learning to learn: Introduction and overview. In Learning to Learn, 3–17 (Springer, 1998).
- 6Hinton, G., Vinyals, O. & Dean, J. Distilling the knowledge in a neural network. ar Xiv preprint, ar Xiv:1503.02531 (2015).
- 7Wang, T., Zhu, J.-Y., Torralba, A. & Efros, A. A. Dataset distillation. ar Xiv preprint, ar Xiv:1811.10959 (2018).
- 8Andrychowicz, M. et al. Learning to learn by gradient descent by gradient descent. Advances in Neural Information Processing Systems 29 (2016).