Improving case fatality ratio estimates in ongoing pandemics through case-to-death time distribution analysis
Zia Farooq, Henrik Sjödin, Joacim Rocklöv, Åke Brännström

TL;DR
This paper introduces a new method to estimate case fatality ratios during pandemics by accounting for delays between case confirmation and death.
Contribution
A novel distributed-delay method is proposed to improve real-time CFR estimation by incorporating case-to-death time distributions.
Findings
The distributed-delay method recovers true CFR earlier than traditional methods in simulations.
The method outperforms Baud’s and Generalized Baud’s methods in various outbreak scenarios.
A negative association was found between eventual CFR and expected case-to-death time in COVID-19 data.
Abstract
The case fatality ratio (CFR) is a vital metric for assessing the disease severity of novel pathogens. The widely used direct method of CFR estimation—the ratio of total confirmed deaths to total confirmed cases—is inherently simplistic, as it fails to account for the essential time lag between case confirmation to death, and reporting delays. These limitations often lead to biased CFR estimates, particularly in the early stages of outbreaks. This study introduces a novel approach—the distributed-delay method that, like the direct method, utilizes publicly available aggregate time-series data on cases and deaths. It estimates CFR by flexibly incorporating a case-to-death time distribution without requiring a priori assumptions on distribution parameters. Using a fitting approach to forecast case fatalities based on known or assumed case-to-death time distributions, the method…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
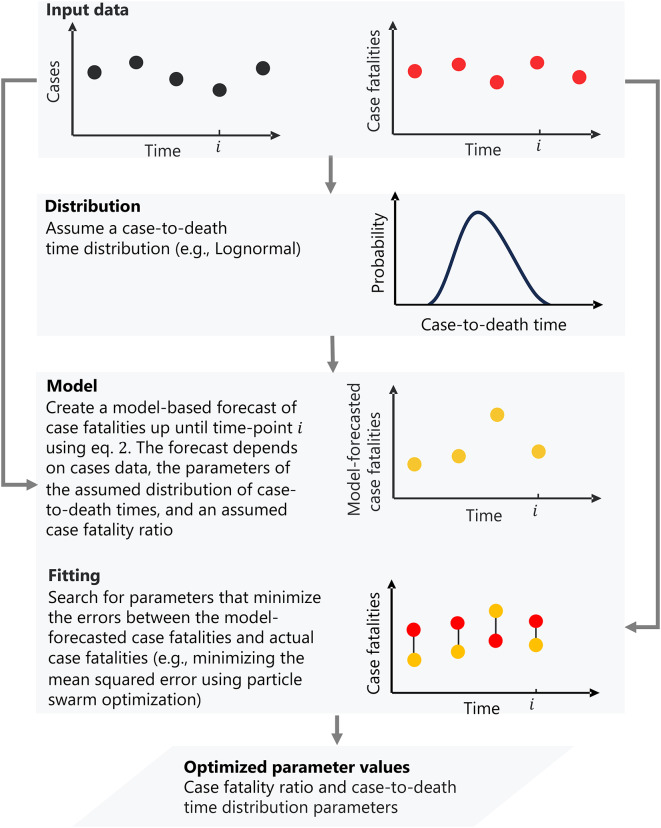 Figure 1
Figure 1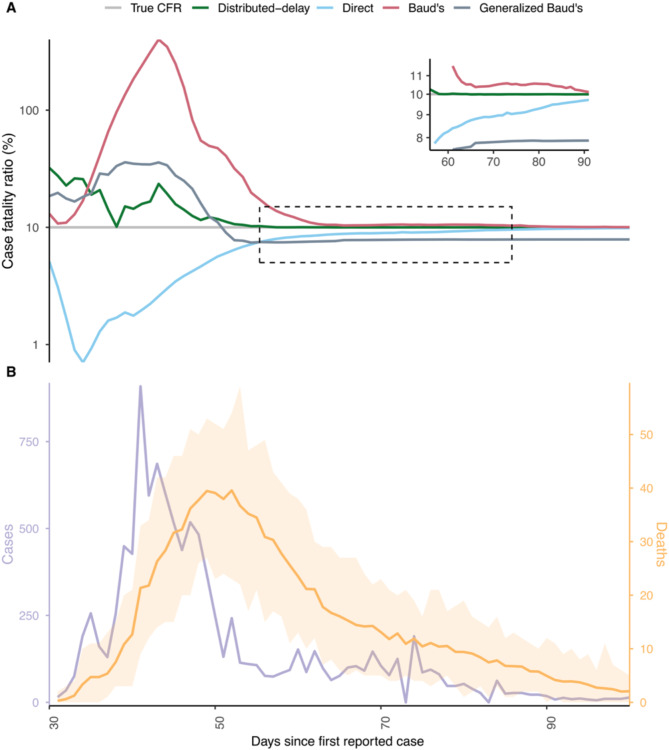 Figure 2
Figure 2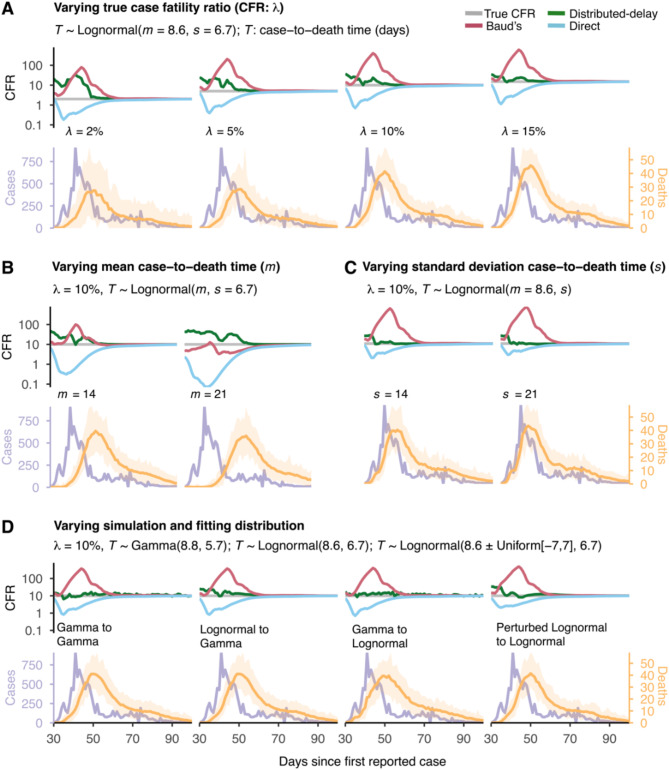 Figure 3
Figure 3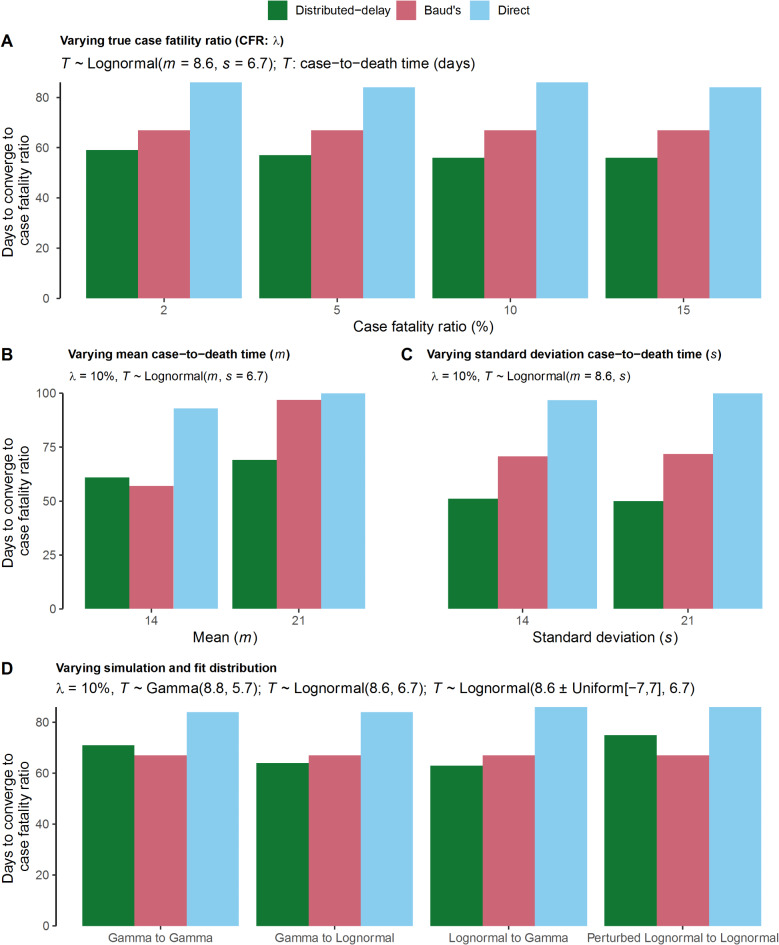 Figure 4
Figure 4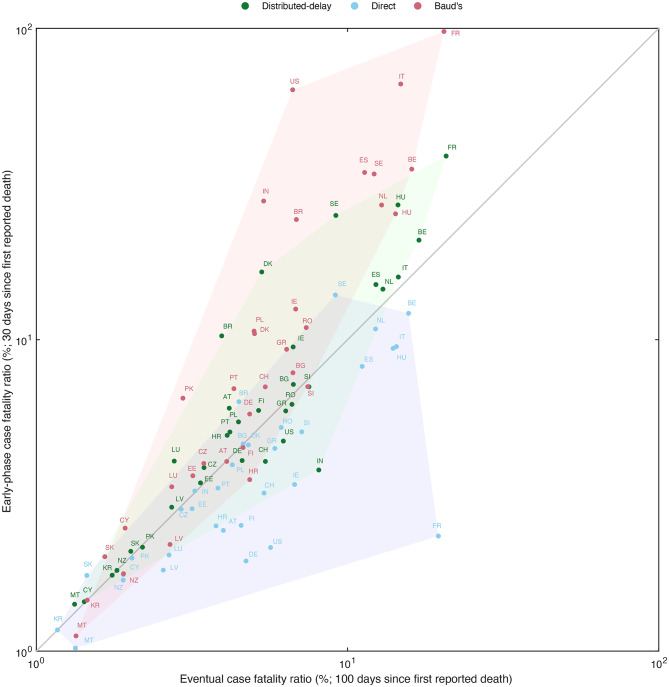 Figure 5
Figure 5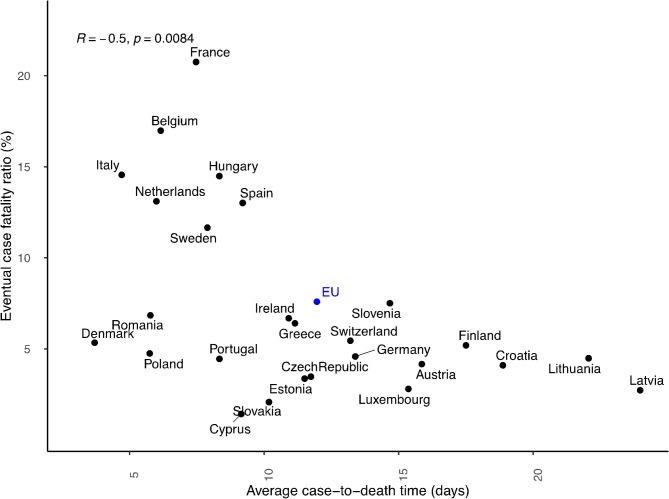 Figure 6
Figure 6- —Umea University
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsCOVID-19 epidemiological studies · Viral Infections and Outbreaks Research · SARS-CoV-2 and COVID-19 Research
Introduction
Accurate disease severity estimation is crucial during disease outbreaks to aid informed decisions about risk assessment and outbreak response actions^1–3^. The case fatality ratio (CFR) is a commonly used quantification of disease severity to provide the proportion of deaths attributed to a given disease among the number of confirmed cases^4^. However, this quantity often becomes clear only sometime after an outbreak when data on the number of disease cases and case fatalities becomes available. The most widely used quantification method, which we refer to as the direct method, for estimating crude estimates of CFR is given simply by the ratio of cumulative fatalities divided by the cumulative cases up to a given day. However, it is well established that the direct method can massively underestimate the true CFR during an ongoing outbreak^5^. This is because actual delays between case registrations and case fatalities do not harmonize with the method’s underlying assumption of zero time from case registration to death, resulting in biased disease severity estimates, particularly during an outbreak^6,7^. The problem becomes particularly acute for diseases that exhibit longer delays between disease infection and following death^8^.
During the COVID-19 pandemic, the direct method was an extensively used estimator of the CFR. There have been several studies on the CFR of COVID-19 ^8–15^, and some have attempted to improve the CFR estimation^8,9,13–15^. In one of the studies, Baud et al. (2020) tried to resolve this problem by accounting for a non-zero case-to-death time, where they assume specifically a fixed 14-day case-to-death time, without variation around that mean^9^. Baud’s method, as previously reported^16^ and we will illustrate here, exhibits tangible deviations from true CFR early during an outbreak.
While Baud et al.’s (2020) method is a relatively straightforward alternative to the direct method, one must also recognize two limitations: (1) The mean case-to-death time needs to be known or estimated by other means, and (2) the variation around this mean is not zero and the case-to-death times actually follow a probability distribution. The notion of distributed case-to-death times is arguably vital for CFR estimation, as it allows probabilistic predictions of future fatalities from present cases. Even if we have information on the number of cases at a given point early in an outbreak, we can only obtain the CFR if we know the fraction of those cases that have or will result in a fatality.
Here, we present a new quantitative method that circumvents these two limitations, with the only requirement being the assumption of a functional form describing how case-to-death times are distributed (see Table 1 for comparison). Case-to-death times should, however, be expected to be positively skewed, and it has been shown that lognormal or gamma-distributed case-to-death times are common^17,18^.
In short, the method acknowledges variable case-to-death times where distribution parameters are emergent by minimizing residuals between estimated and actual case fatalities during ongoing outbreaks. We refer to this method as the distributed-delay method and demonstrate it through simulations and empirical COVID-19 data. By comparing our method with the direct and Baud’s method, we show how our method addresses the key limitations of these simpler methods using publicly available cases and deaths. The method typically generates improved CFR estimates much earlier than these methods and provides interesting insights into the association between the CFR and expected case-to-death times in empirical data settings.
Table 1A comparison of different methods for estimating case fatality ratios with the distributed-delay method.Quantification methodMean case-to-death timeDispersion around the meanMethod brief descriptionA priori information (data)When during an outbreak, it provides reliable estimates?DirectConstant, 00Reported deaths to cases ratioPopulation-level cases and fatalitiesWhen the outbreak wanesGhani^5^Average of empirical case-to-death timeDispersion in empirical case-to-death timeKaplan-MeierIndividualized recoveries and fatalities dataSubject to sufficient data availability/post exponential growth phaseJewell^19^Average of empirical case-to-death timeDispersion in empirical case-to-death timeKaplan-MeierIndividualized fatalities and recoveries dataSubject to sufficient data availability/post the exponential-growth phaseNishiura^17^Mean based on other previous outbreaksDispersion based on other previous outbreaksExponential/gamma distribution with maximum likelihoodDistribution parameters and population-level cases and fatalitiesEarly in an ongoing epidemic subject to the availability of assumed distribution parametersThomas^15^Fitted to population- level case fatalities0Time-shifted distributionPopulation-level cases and fatalitiesPost the exponential-growth phaseBaud’s^9^14 days0Constant case-to-death timePopulation-level cases and fatalitiesPost the exponential-growth phase subject to the availability of case-to-death time of disease under considerationGeneralized Baud’s (this study)Fitted to population-level case fatalities0Delta distribution of case-to-death timePopulation-level cases and fatalitiesPost the exponential-growth phaseDistributed-delay (this study)Fitted to population- level case fatalitiesFitted to population-level case fatalitiesLognormal/gamma distributionPopulation-level cases and fatalitiesIn an ongoing epidemic/pandemic/outbreak
Methods
The case fatality ratio (CFR) is often regarded as an ambiguous term in the literature due to its varying definitions related to what constitutes a ‘case’^8,17,20^. In this study, we define CFR as the ratio of deaths to confirmed cases alone. The denominator could also encompass the total number of infections, which would then appropriately be termed the infection fatality rate (IFR). Nonetheless, identifying all infected individuals is practically infeasible in the early phase of a novel outbreak, so the denominator is, in practice, often restricted to diagnosed cases, which is often a more applicable measure. While the method could easily be applied to data on all infected, would such data be available? The instance of the method we present here is based on confirmed case data and, therefore, restricted to considerations on CFR.
Overview of the distributed-delay method
The fundamental idea of the distributed-delay method is to capture the essential processes that govern the case fatality ratio of a given outbreak.
The key problem is to account for the fact that there is some time between case registration and an eventual fatality. This case-to-death time varies between cases, diseases, and populations depending on, for instance, its age distribution. This is resolved by correctly accounting for a distribution of case-to-death times when quantifying the CFR (Fig. 1). Using this distribution and an assumed CFR value (denoted by \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\lambda$$\end{document} ), we can forecast case fatalities corresponding to that CFR each day until the given time-point \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$i$$\end{document} , described by equation (2) in the next section.
An applicable CFR quantification method should ideally also base estimations on information from the very outbreak for which we estimate the CFR and not depend on earlier outbreak data. Estimation of the CFR and distribution parameters of an outbreak is obtained by fitting model-based case fatalities (i.e., Eq. (2)) to actual or reported daily case fatalities data by minimizing residuals between the two using appropriate optimization methods on the outbreak (Fig. 1) and in that process, the correct CFR value for that outbreak data is estimated.
These are the two fundamental principles of the distributed-delay method.
Fig. 1. Conceptual framework of the distributed-delay method. In the first step, we assume a probability distribution \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:p\left(t,\:\varTheta\right)$$\end{document} , for the time from case registration to death registration with parameters, Θ. Using this distribution and an assumed case fatality ratio \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\lambda$$\end{document} , we forecast case fatalities each day up until time point \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$i$$\end{document} since the start of the outbreak/epidemic. The forecast is created using the model (Eq.2). We then search for the parameters that give the best fit between actual and model-based fatalities through minimization of the error (here, minimizing the squared error using particle swarm optimization, PSO). This gives the estimated case fatality ratio \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\lambda\:$$\end{document} and the estimated distribution parameters Θ.
Modelling case fatalities
We assume that the case-to-death times \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$t$$\end{document} for cases for which the disease proved fatal, follow some probability distribution given by the probability density function \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:p\left(t,\:\varTheta\right)\:$$\end{document} where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varTheta\:$$\end{document} denotes its parametric space. The probability that an individual has died from the disease within \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$t$$\end{document} days after it was reported as a case is then given by the cumulative probability density function
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:P\left(t,\varTheta\right)={\int\:}_{0}^{t}\:p\left(x,\:\varTheta\right)\text{d}x,\:\:\:t>0\:,$$\end{document}such that the number of case fatalities \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{{(F}_{D}}_{i}$$\end{document} ) until the day \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:i$$\end{document} since the start of the outbreak is given by
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{{F}_{D}}_{i}\left(\lambda\:,\varTheta\right)=\lambda\:\sum\:_{t=1}^{i}P\left(t,\varTheta\right){C}_{i-t+1},\:\:$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${C}_{i-t+1}$$\end{document} denotes the number of reported new cases at day \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$i-t+1$$\end{document} since the start of the outbreak.
Estimating the correct CFR and distribution parameters by optimization
To estimate CFR and case-to-death time distribution parameters, the modeled case fatalities (i.e., Eqs. (1)-(2) ) are fitted to case fatality data by finding the minimum of the sum of squared differences between modeled case fatalities and case fatality data (i.e., simulated or empirical; see Results section). We use global optimization by applying a particle swarm optimization (PSO) algorithm (see section: Optimization and parameter estimation for details)^21^. This numerical fitting approach requires the case fatality model \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${F}_{{D}_{i}}\left(\lambda\:,{\Theta}\right)$$\end{document} to be fully parameterized.
Empirical COVID-19 data and generation of simulated data
We evaluated the distributed-delay method on simulations-generated data (see Table 2) and empirical COVID-19 data.
We extracted empirical COVID-19 data on daily cases and case fatalities in 34 countries from online sources (see Supplementary: Table S1 for countries names)^22^.
To eliminate any noise in studying the performance of the distributed-delay method, we also provide a controlled setting with complete information on the underlying processes of case fatalities. By generating simulated case-fatality data based on empirical COVID-19 cases data from the spring 2020 COVID-19 outbreak in South Korea^18^, we could control four factors: (1) true CFR, (2) true mean and (3) standard deviation of case-to-death times, and (4) true functional form of case-to-death time distribution (e.g., lognormal or gamma).
To generate simulated case fatalities data that satisfy a given case fatality ratio \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\lambda$$\end{document} , we draw for each day and reported case a random number \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$r$$\end{document} between 0 and 1 and assume that the reported cases would not survive the disease for \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$r<\lambda$$\end{document} , or else survive the disease. We draw case-to-death time for each of the fatal cases from an assumed time-continuous case-to-death time distributions, i.e., with \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$P\left(t,{\Theta}\right):= P\left(t,m,s\right)$$\end{document} equal to lognormal or gamma with a given mean \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$m$$\end{document} and standard deviation \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$s$$\end{document} of case-to-death times (see Results section). Since we use a daily temporal resolution, the drawn continuous case-to-death times are rounded to nearest integers. Table 2 provides details on parameterization of 14 simulation scenarios across which variation in the four factors are evaluated.
Table 2. Summary of assumed parameters, the simulation and the fitting distributions used to analyze the sensitivity and robustness of distributed-delay method.NoCase-to-death timedistributionMean (m)[a, b]Standard deviation (s) [a, b]CFR ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\varvec{\lambda\:}$$\end{document} )(%)FittingdistributionReferenceFigure:Panel1Lognormal8.6^^ [0.1, 30]6.7^^ [0.1, 30] 2% Lognormal3 A, 4 A2Lognormal8.6^^ [0.1, 30]6.7^^ [0.1, 30] 5% Lognormal3 A, 4 A3Lognormal8.6^^ [0.1, 30]6.7^^ [0.1, 30] 10% Lognormal3 A, 4 A4Lognormal8.6^^ [0.1, 30]6.7^^ [0.1, 30] 15% Lognormal3 A, 4 A6Lognormal14 [0.1, 40]6.7^^ [0.1, 30]10%Lognormal3B, 4B7Lognormal21 [0.1 50]6.7^^ [0.1, 30]10%Lognormal3B, 4B9Lognormal8.6^^ [0.1, 30]14 [0.1, 40]10%Lognormal3 C, 4 C10Lognormal8.6^^ [0.1, 30]21 [0.1, 50]10%Lognormal3 C, 4 C11 Gamma 8.8^^ [0.1, 30]5.7^^ [0.1, 30]10% Lognormal 3D, 4D12 Lognormal 8.6^^ [0.1, 30]6.7^^ [0.1, 30]10% Gamma 3D, 4D13 Perturbed
Lognormal 8.6^^+Uniform[-7,7][0.1, 30]6.7^^ [0.1, 30]10%Lognormal3D, 4D14 Gamma 8.8^*^ [0.1, 30]5.7 [0.1, 30]10%Gamma3D, 4DThe bold-faced text shows the varying parameters/factor in each scenario. [a, b] refers to the lower and upper bound of parametric search space for the Particle-Swarm optimization (PSO) algorithm. *Taken from Linton et al.^18^.
Unifying case fatality ratio quantification methods under a generalized perspective
The direct method and Baud’s method do not estimate CFR through fitting. To compare them with the distributed-delay method, we standardize their evaluation by assigning comparable properties. This is achievable for the direct and Baud et al. methods^9^, both recovered as special cases in equation (2) when \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:p\left(t,{\Theta}\right)$$\end{document} assumes a Dirac delta distribution with mean case-to-death time zero or 14 days. Although the direct and Baud’s methods become identical in the sense that they are both defined by a delta distribution, we refer to this special case as Generalized Baud’s method, which we use to fit case-to-death times.
Case-to-death time distributions
In our analysis, we considered three instances of assumed case-to-death times distributions: (i) lognormal distribution (ii) gamma distribution, and (iii) delta distribution. Below we expand the details on each of the distribution.
Firstly, we used a lognormal distribution \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:p\left(t,{\Theta}\right)\:$$\end{document} of case-to-death time (Eq. 1) with mean \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\mu$$\end{document} , and standard deviation \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\sigma$$\end{document} , with days as a temporal unit^18^. We write the lognormal distribution of case-to-death times given in Eq. (3)
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:p\left(t,{\Theta}\right)=\:p\left(t,\mu\:,\sigma\:\right)=\frac{1}{t\sigma\:\sqrt{2\pi\:}}\text{exp}\left(-\frac{{\left(\text{log}t-\mu\:\right)}^{2}}{2{\sigma\:}^{2}}\right),\:t>0$$\end{document}where the parameters \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\mu\:$$\end{document} , and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\sigma\:$$\end{document} , are computed using the transformation of mean (m) and standard deviation (s) of lognormal random variable as
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\mu\:=\text{log}\left(\frac{{m}^{2}}{\sqrt{{s}^{2}+{m}^{2}}}\right),$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\sigma\:=\sqrt{\text{l}\text{o}\text{g}\left(\frac{s}{{m}^{2}}+1\right)},$$\end{document}Next, we also implemented the distributed-delay method with a gamma distribution of case-to-death times with parameters shape ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:k$$\end{document} ) and scale ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\theta\:$$\end{document} ) given in Eq. (6) as
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:p\left(t,{\Theta}\right)=\:p\left(t,k,\theta\right)=\frac{1}{{\Gamma}\left(k\right){\theta\:}^{k}}{t}^{k-1}{e}^{-\frac{t}{\theta\:}},\:t>0$$\end{document}where the parameters \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:k$$\end{document} , and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\theta$$\end{document} , are computed using the transformation of the mean (m) and standard deviation (s) of gamma random variable as
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:k=\frac{{m}^{2}}{{s}^{2}},$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\theta\:=\frac{{s}^{2}}{m},$$\end{document}We further implemented the method by assuming a delta distribution of case-to-death time for which the Eq. (1) is replaced by Eq. (9) ( see section “Generalized Baud’s method”)
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:P\left(t,\mu\right)=\delta\:\left(t|m\right),\:\:\:t>0\:$$\end{document}Optimization procedure for parameters estimation
To estimate the parameters, i.e., case fatality ratio, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\uplambda}$$\end{document} , and the distribution parameter(s), \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\Theta},$$\end{document} for all the instances of assumed distributions (Eqs. (3)-(9)) we numerically find the combination of these parameters, through a numerical optimization algorithm, that minimizes the residuals between actual and model forecasted case fatalities (Eq. (2)). To apply a numerical optimization algorithm that searches for the combination of parameters that minimizes the residuals, we established an objective function \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:f\left({\uplambda}\:,{\Theta}\right)\:$$\end{document} with parametric constraints given by (10)-(11)
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:f\left(\lambda,\varTheta\right)=\text{a}\text{r}\text{g}\text{m}\text{i}\text{n}\sum\:_{i=1}^{n}{\left({{A}_{D}}_{i}-{{F}_{D}}_{i}\left(\lambda,\varTheta\right)\right)}^{2},\:$$\end{document}subject to parametric constraints;
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\lambda\:\epsilon\left[0\:1\right],\:\:\varTheta\:\epsilon\left[a\:b\right];\:\:a>b>0,$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${{A}_{D}}_{i}$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${{(F}_{D}}_{i})$$\end{document} are respectively the actual daily and model forecasted case fatalities of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:n$$\end{document} days of an outbreak.
Note that in this context, the objective function, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$f$$\end{document} , is not in closed form. Consequently, only a numerical solution using a derivative-free optimization algorithm is feasible. We evaluate the problem against various algorithms using the MATLAB R2020a global optimization toolbox^23^. After testing multiple derivative-free optimization algorithms, we find that the metaheuristic particle swarm optimization (PSO) algorithm performs the best^21^.
Unlike gradient-based or simplex methods (e.g., Nelder-Mead^24^), PSO does not rely on assumptions of a smooth or unimodal objective function. Instead, it employs a population-based search that facilitates a broader exploration of the parameter space and minimizes the risk of convergence to local minima. This characteristic was particularly critical given the need to locate the global minimum in our application, where the simplex methods showed limitations in handling the non-smooth and non-convex nature of the problem. Thus, PSO emerged as the most suitable choice for the optimization process.
To apply PSO, constraints on parameters need to be defined for both simulations and empirical data cases. We set these constraints for simulations as provided in Table 2. For empirical COVID-19 estimates we used a lognormal distribution of case-to-deaths times throughout and set constraints for both case-to-death parameters \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:m$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:s$$\end{document} to \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:a=\:0.1,$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\:b=\:30$$\end{document} . The distribution parameters derived from the fitting process, are reported in Supplementary Information Table 1.
Here, we illustrate an instance implementation of the lognormal distribution for the optimization algorithm (i.e., Eqs. (1)-(2) together with (10)-(11). Since the algorithm is computationally intensive (see Supplementary; Computational cost of the distributed-delay method), we first define and then refine a parametric search space. We define a 3-dimensional grid space for parameters where each dimension corresponds to one parameter, i.e., that is, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\lambda,\:m$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:s$$\end{document} . To create the 3-dimensional parametric grid, we divide the parametric space of each parameter, subject to the constraints described above, into \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:k$$\end{document} grid-points. As a result, the number of model-based forecasted case fatalities and fittings to actual fatalities would be on the order of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${k}^{3}$$\end{document} . Here, we choose \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:k=10$$\end{document} , resulting in 1000 fitted instances of parameter sets and corresponding residuals. We then select the parameter sets that provide the minimum and maximum values of residuals. These parameter sets establish the new constraint limits. This enables us to apply the particle swarm optimization algorithm more efficiently with the newly defined parametric constraints and to find the best fit between actual and model-forecasted case fatalities.
One of the critical hyperparameters of PSO for finding the minimum is its swarm size—the number of particles in the swarm. Generally, the larger the swarm size, the higher the computational time of the method. To that end, we test multiple swarm sizes (1000, 2500, 5000) and find that a swarm size of 5000 particles results in estimating the optimal parameter values from the distributed-delay method. The parameter iteration numbers are also important for the computational time. An insufficiently small number of iterations may bring the search process to an early halt, while extensive iterations could lead to unwarranted computational complexity and extended computational time^25^. In our case, we set this parameter to its default value in MATLAB.
Generalized Baud’s method
The direct method does not estimate CFR by fitting or Baud’s method. To evaluate the distributed-delay method against these methods should they be fitted to data in the same manner as the direct method, we unify them by accrediting each method’s comparable properties. This is possible for the direct method and the method presented by Baud et al. (2020)^9^, which also are the quantification methods we evaluate against in our results. Both methods are recovered as special cases in Eq. (2) when \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\text{P}\left(\text{t},{\Theta}\right)$$\end{document} is assumed to be equal to the Dirac delta distribution (Eq. (9) ) with mean case-to-death time zero (direct method) or 14 days Baud’s method). The delta distribution’s dispersion (e.g., standard deviation) is, by definition, infinitesimal, which is true for both methods since none of them accounts for variation in case-to-death times. We can apply Eq. (2) and obtain case fatalities representing the direct or Baud’s methods.
With this generalization, we can then proceed to estimate CFR and any distribution parameters of the delta distribution, analogous to the distributed-delay method. It follows that the direct methods and Baud’s method converge at this point because the only distribution parameter that can be estimated is the mean case-to-death time since the delta distribution lacks any statistical moment around the mean.
Although the direct method and Baud’s method become identical, we refer to this generalization as the Generalized Baud’s method since it explicitly accounts for non-zero case-to-death times, while the direct method does not.
One could also extend this generalization by allowing for non-zero dispersion, which would recover a method that then assumes normally distributed case-to-death times as the Dirac delta function is obtained in the limit of infinitesimal dispersion in a normal distribution. However, while such a second-order generalization is interesting in and of itself, it would not add to the comparison analyses as it would fall out of scope.
Results
We compare the results of our method with three other methods: (i) the direct method, which assumes a case-to-death time of zero days; (ii) Baud’s method with a constant 14-day case-to-death time; the ratio of total deaths to the total cases two weeks ago and (iii) Generalized Baud’s method with a free case-to-death time parameter.
Distributed-delay outperforms on simulated data
We first present an instance where we test the distributed-delay method on simulation-generated case fatality data (see Methods). We assume that case-to-death times follow a lognormal distribution, as has been shown also to describe the variation of empirical case-to-death times^18^. Following Linton et al.^18^, and for illustration, we assume mean \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:m=8.6$$\end{document} days, and standard deviation \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:s=6.7$$\end{document} days of case-to-death times. For illustration, we assume the true CFR of 10% is also in the range of commonly observed CFR values, including COVID-19. We analyze and compare all the methods over the first 100 days from the onset of the epidemic (Fig. 2A). Figure 1A shows that the distributed-delay method estimates are more accurate than the other quantification methods except for the first few days owing to high stochasticity and data scarcity.
How long does it take for each method to converge to true CFR? For this, we consider a CFR estimate to have converged when the relative error stays less than 5% beyond the initial period of inherent stochasticity. Based on this, the distributed-delay method infers the assumed true CFR on day 56 of the outbreak (Fig. 2A, inset). Conversely, the direct method extremely underestimates the true CFR through the exponential phase and converges only on day 86 of the outbreak. Baud’s method greatly overestimates the true CFR through the exponential phase and converges only on day 66 (Fig. 2A).
We find that the Generalized Baud’s method performs better estimation than the direct and Baud’s method during the exponential phase, yet that it underestimates the CFR at the end of the outbreak—which is a phase in the outbreak where estimates by all the other methods become practically reliable. This is explained fundamentally by the lack of case-to-death times variation. The absence of variations in case-to-death times causes estimated case fatalities to be a shifted and scaled copy of cases. Since the actual case-to-death time distribution has a non-zero variance, the shape of actual case fatalities differs from that of cases. The estimated case fatality curve peaks sooner as it is right skewed. Therefore, fitting the estimated case fatalities to the actual case fatalities results in a lower mean case-to-death time as it reduces the residuals (see Discussion sections for more details).
How do the estimates of the distributed-delay method compare when the model parameters and distributions are varied? This naturally leads us to assess the robustness of the method.
Fig. 2. Comparison of CFR estimation methods on simulated data. Illustration of a distributed-delay method for simulated death data generated with arbitrarily chosen parameter values; case fatality ratio of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:10\%$$\end{document} case-to-death time parameters, a mean of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:m=8.6$$\end{document} days, and standard deviation of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:s=6.7$$\end{document} days. (A) Expected case fatality curve (green) obtained by fitting 100 realizations of simulated data using the distributed-delay method and the corresponding case fatality curve estimated by the direct method (blue), Baud’s method (red), and generalized Baud’s method (grey). The grey horizontal line represents the pre-defined case fatality ratio ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\lambda\:$$\end{document} ) used to generate the death data. (B) Daily COVID-19 case-incidence (purple) in South Korea used to generate the simulated case fatalities (light orange – daily deaths) with the model. The inset figure shows the day our method converged to the true CFR.
Robustness analysis on estimation accuracy
Robustness analyses confirm that the distributed-delay method consistently provides better CFR estimates than the direct and Baud methods (Fig. 3).
We examine the performance of these methods by varying each of the parameters (see Table 2 for details), \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\lambda\:$$\end{document} (Fig. 3A), \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:m$$\end{document} (Fig. 3B), and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:s$$\end{document} (Fig. 3C), and the simulation- and fitting distributions (Fig. 3D). The distributed-delay method provides more accurate estimates than other methods, irrespective of the parameter space.
The estimate of our method remains consistent even if the actual case-to-death times distribution is different from the one with which we fit the data (Fig. 3D; Lognormal to Gamma, Gamma to Lognormal, Perturbed Lognormal to Lognormal). This demonstrates that the method is robust and provides good estimates even if the true distribution does not closely match the assumed distribution. The case of perturbed lognormal (Fig. 3D, Perturbed Lognormal to Lognormal ) reflecting the reporting delays (or censoring bias) underpins that the method is insensitive to noise in the empirical data. For gamma-distributed case-to-death times (Fig. 3D; Gamma to Gamma), while our method’s estimates remain superior to others, its goodness-of-fit (R²) is lower compared to the lognormal distribution (Supplementary; Fig. S1).
To further evaluate the robustness and generalizability of the proposed method, we tested it on simulated fatality datasets derived from COVID-19 time-series case data from multiple countries, including Italy and Brazil. The results remained consistent with our initial findings, highlighting the reliability of the method across different datasets and scenarios (see Supplementary; Fig. S3).
Fig. 3. Robustness analysis under simulations scenarios: Distributed-delay method is robust. A comparison of the estimated case fatality ratio (CFR) (log scale) by distributed-delay method with other methods under various parameter settings and case-to-death times distributions. Each panel represents a simulation scenario in which we vary one of the model parameters, simulation, and (or) fitting distribution while holding others constant. (A) For \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\lambda\:=\:\left(2,\:5,\:\text{10, 15}\right)\%$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:m=\:8.6,\:s=\:6.7.$$\end{document} (B) For \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:m=\:(14,\:21)$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:s=\:6.7,\:\lambda\:=10\%.$$\end{document} (C) For \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:s=\:(6.7,\:\text{14, 21})$$\end{document} with \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:m=\:8.6,\:\lambda\:=10\%.$$\end{document} (D) From left, Panel-1: Gamma to Gamma: data simulated and fitted with a gamma distribution; Panel-2: Gamma to lognormal: data simulated with gamma but fitted with a lognormal distribution; Panel-3: Lognormal to gamma: data simulated with lognormal but fitted with a gamma distribution. Panel-4: Perturbed lognormal to lognormal: data simulated with a perturbed lognormal distribution (i.e., \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:m\pm\:[-\text{7, 7}]$$\end{document} ) but fitted with lognormal distribution gamma, the assumed parameters are \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:m=8.8$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:s=5.7$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\lambda\:=10\%.$$\end{document} For the lognormal, the assumed parameters are \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:m=\:8.6,\:s=\:6.7,\:\lambda\:=10\%$$\end{document} . We made 100 simulations and fitting runs at a daily scale for each case for the defined period.
Robustness analysis on convergence time
We estimate the time (days) each method takes to converge to the true CFR for each simulation scenario listed in Table 2. For that, we again define convergence to be met at a point when the relative error of the estimates remains less than 5%. Depending on the simulation scenario, the distributed-delay method converges 7 to 45 days earlier than the direct method (Fig. 4). Also, the method’s convergence time remains superior to Baud’s methods except for three instances (Fig. 4B; \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:m=14\:$$\end{document} , Fig. 4D; Gamma to Gamma, Fig. 4D; Perturbed Lognormal to Lognormal). These analyses highlight the robustness of our approach concerning the convergence time.
These findings confirm the superiority of our approach in controlled settings. However, examining how well the method performs on empirical data is crucial, which we explore in the following sub-section.
Fig. 4. Robustness analysis on convergence time. Each panel represents a simulation scenario w.r.t constant and varying parameters and (or) distribution. The horizontal axis represents the assumed parameters and (or) distribution scenario. The vertical axis shows the number of days taken by a method to converge to the true CFR (%), considering a threshold relative error (RE) < 5%. (A) For \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\lambda\:=\:(2,\:5,\:10,\:15)$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:m=\:8.6,\:\:s=\:6.7$$\end{document} (B) For \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:m=\:(14,\:21)$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:s=\:6.7,\:\:\lambda\:=10\%$$\end{document} (C) For \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:s=\:(6.7,\:14,\:21)$$\end{document} with \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:m=\:8.6,\:\lambda\:=10\%$$\end{document} (D) From left, panel-1: Gamma to Gamma: data simulated and fitted with a gamma distribution; Panel-2: Gamma to lognormal: data simulated with gamma but fitted with a lognormal distribution; Panel-3: Lognormal to gamma: data simulated with lognormal but fitted with a gamma distribution. Panel-4: Perturbed lognormal to lognormal: data simulated with a perturbed lognormal distribution (i.e., \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:m\pm\:[-\text{7, 7}]$$\end{document} ) but fitted with lognormal distribution gamma, the assumed parameters are \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:m=8.8$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:s=5.7$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\lambda\:=10\%$$\end{document} . For the lognormal, the assumed parameters are \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:m=\:8.6,\:\:s=\:6.7,\:\:\lambda\:=10\%$$\end{document} . In each case, we made \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:100 $$\end{document} simulations and fitting run on a daily scale for the defined period.
Application to empirical COVID-19 data
We analyze COVID-19 data from 34 countries (see Supplementary; Table S1). Unlike simulations, real-world case fatalities are typically unknown before the outbreak wanes or when complete information on the outcomes of cases is available. Typically, the eventual (or true) CFR is averaged across the whole duration of an outbreak and may vary over time as reported for COVID-19. We restrict our analysis to the assumption that CFR remains constant throughout the epidemic (see Discussions). We thus choose the CFR estimates of each method at two time points; (i) early-phase estimations: We define the estimates of day 30 (since the first reported death) as early-phase CFR, and (ii) Eventual CFR: the estimates on day 100 of the pandemic.
To compare the estimates from respective methods, we assess their symmetry along a diagonal line by considering that the method aligning closely to the diagonal line converges sooner to the eventual CFR in the considered time window. We observe that the estimates of the distributed-delay method (green convex hull) closely align with the diagonal and remain between those of the direct (blue convex hull) and Baud’s method (red convex hull) (Fig. 5). The early-phase estimations by the distributed-delay method consistently approach the eventual CFR more than others. Again, for illustration and analogous to simulation-based temporal CFR curves, the country-wise (of European Union countries) empirical CFR curves of each method are provided in Figure S6 of Supplementary material.
Fig. 5. Comparison of CFR estimation methods on empirical COVID-19 data. Comparison of eventual (horizontal-axis) and the early-phase case fatality ratio (vertical-axis) with the distributed-delay method (green), the direct method (blue), and Baud’s method (red) on a log scale for the 34 countries. Each country is represented by its two-letter International Organization for Standardization (ISO) code. The green convex hull of the distributed-delay method shows that the early-phase case fatality is higher than the eventual CFR. The blue convex hull of the direct method’s early-phase CFR largely lies below the diagonal line, showing a substantial underestimation of empirical CFR. Similar to simulations, early-phase CFR estimated from Baud’s (red convex hull) method predominantly lies above the diagonal, depicting more significant errors than the other methods.
Relationship between empirical case fatality ratios and case-to-death times
In addition to the CFR, we also estimate, from our method, the expected case-to-death time for the member countries of the European Union (EU) (Fig. 6). We further examine the association between eventual CFR and case-to-death time for the EU and each country. A significantly \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:(p\sim0.0084)$$\end{document} negative correlation \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:(R\:\sim-0.5)$$\end{document} between the average case-to-death time and the eventual case-fatality ratio was found. This association reveals that countries with more severe outbreaks \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:(CFR >10\%)$$\end{document} generally have had shorter case-to-death time \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:(<7\:days)$$\end{document} for COVID-19 (Fig. 6). These are more tangible for countries such as France, Belgium, Italy, Netherlands, Spain, Sweden, etc.
Fig. 6. Association between the expected case-to-death times and the eventual case-fatality ratio. The horizontal axis represents the mean case-to-death time (days) and the corresponding eventual case-fatality ratio (%) of the European Union (EU) and each of its member countries. The eventual CFR corresponds to the estimates of day 100 of the pandemic in each country.
Discussion
The case fatality ratio (CFR) is a crucial epidemiological measure used to gauge disease severity during new pandemics or epidemics and to evaluate the necessity for control and intervention strategies. At a later stage of a pandemic, complementary estimates of the infection fatality ratio (IFR) become available, which take into account all infections, not just clinical cases. This research shows how well-established and routinely used crude CFR estimators (direct method and Baud’s method) can be associated with notable biases due to their inherently simplified assumptions.
In this study, we have presented a new CFR quantification method that provides improved estimates during disease outbreaks by demonstrating how our approach addresses the key limitations of the above methods and improves CFR estimation using publicly available data. We have also shown the importance of accounting for variable case-to-death times and the distribution of their relative frequencies and that distribution parameters (e.g., mean and standard deviation) along with CFR can be inferred by fitting modeled case fatalities to actual case fatalities. We showed that with these relaxed and more realistic assumptions, estimation errors and convergence times can be improved compared to the direct and Baud’s methods that make oversimplified assumptions on case-to-death times.
The method achieves reliable CFR estimates typically after 40–80 days from the onset of the outbreak, depending on the outbreak size and the case-to-death parameters of the distribution. As simulations demonstrate, it converges up to 45 days earlier than the other methods. The method not only accommodates case-to-death times parametric distribution but also the variability and the distortions in these distributions, as demonstrated in our robustness analyses (Fig. 3).
Beyond the improved CFR estimation, the method provides interesting insights into the relationship between CFR and the expected case-to-death time. One interesting observation is a significantly negative correlation between the estimated CFR and case-to-death times in empirical COVID-19 data (Fig. 6). Is this a characteristic of COVID-19 specifically, or does it reflect a general principle across multiple diseases? Understanding the generality of this relationship can be helpful for rapid CFR assessment early on in outbreaks.
The distributed-delay method builds on four key components. (i) The case-to-death time distribution. This is essential, as was demonstrated through simulations and for empirical COVID-19 data across multiple countries. (ii) A flexibility in accommodating any case-to-death time distribution (as it could potentially differ between outbreaks). (iii) Quantification relies solely on information from the outbreak under consideration. (iv) It requires time series data on reported cases and fatalities that typically are publicly available. These components also contribute to an improved applicability relative to other CFR quantification methods (Table 1).
Quantifying CFR and case-to-death times parameters through the distributed-delay method requires fitting modeled case fatalities into data. Importantly, we fitted the modeled daily case fatalities to daily reported case fatalities data here. While it is easier for any minimization algorithm to settle on residuals minima with respect to cumulative case fatality data – as this involves aligning two sigmoid-shaped curves (i.e., actual and modeled cumulative case fatalities)—it is also prone to settle on false minima and therefore introducing misleading errors. The true minima with respect to daily case fatality data are better defined and, thus, the better option out of the two. Although minimizing with respect to cumulative case fatalities data may, at first sight, appear statistically more appealing (e.g., as it typically generates higher R²), it may fall short in capturing the true underlying relationships of CFR, leading to false CFR and distribution parameter estimations.
The literature offers a range of parametric and non-parametric quantification methods attempting to correct CFR estimations. Indeed, many of these studies incorporate variations in case-to-death times^13,15,17,26–28^. In these studies, however, the shape of case-to-death time distributions depends on parameter prerequisites inferred from other known outbreaks, which may not necessarily be the same for a novel disease. Even if the distribution parameters are available from the disease under consideration, the predicted CFR tends to be sensitive to the choice of distribution parameters and may not accurately reflect the underlying population heterogeneities. Additionally, a few of these methods require information that is not available during the outbreaks for which they are intended and are therefore not applicable when CFR information is needed the most^5,29^. For instance, the modified Kaplan–Meier method described by Ghani et al.^5^. , relies on individual case data, including the dates of hospitalization and death or recovery, to estimate the CFR. In contrast, the distributed-delay method requires only publicly reported data on cases and deaths and no prior information on case-to-death times distribution.
One of the central aspects of the distributed-delay method is that it flexibly considers the distribution of case-to-death times. Only a few earlier studies have acknowledged the importance of this aspect in quantifying CFR^17,28,30^. One of these studies, by Nishiura et al.^17^, presents a method that may provide earlier estimates of CFR than the one presented here – under optimal conditions. However, the quantification method by Nishiura et al. often falls short because it requires inference on case-to-death time parameter values from past outbreaks. Considering the many unknowns associated with novel outbreaks, such a method is rarely applicable in new epidemiological situations, which are also situations where information on outbreak severity is often needed the most.
A notable strength of this study lies in its novel methodology, which, to our knowledge, is the first to simultaneously estimate the case-to-death times (or delay) distribution parameters and case fatality ratio (CFR) directly from aggregate data. This approach circumvents the reliance on external delay distribution estimates, which may not adequately capture outbreak-specific factors such as demographic variations, healthcare infrastructure, or reporting practices. These outbreak-specific factors are critical for accurate estimation, particularly when individual-level data or precise case-to-death delay distributions are unavailable.
While recognizing the strengths of our method, identifying the case-to-death (or delay) distribution from aggregate data can be challenging in the early epidemic stages, especially when cases are growing exponentially. For instance, the collinearity between the distribution parameters and CFR may limit precision in these phases. Nevertheless, our simulation results indicate that the proposed method performs robustly even under these conditions, providing reasonable estimates. Furthermore, as additional data are collected over time, the estimation uncertainty diminishes substantially, even during periods of exponential growth (Supplementary; Fig. S3B).
It is worth noting that the uncertainty in the early phase CFR estimates may be large (Supplementary; Fig S3). This is because during the early phase of an outbreak, the number of reported cases is often small, and the corresponding number of fatalities is subject to considerable randomness. This randomness stems from two factors: the probabilistic nature of death resulting from infection and the variability in the timing of fatalities due to the distribution of case-to-death times. Formally, the variability in the number of deaths arising from \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:n$$\end{document} cases can be expressed as \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\frac{1}{\sqrt{n.p}}\sqrt{1-p}$$\end{document} , where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:p$$\end{document} is the probability of fatality. When \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:p$$\end{document} is small, as it often is for novel diseases, the uncertainty increases further with the number of deaths given \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\frac{1}{\sqrt{n.p}}$$\end{document} , and a high number of cases is required to offset this noise. The additional uncertainty introduced by the timing of deaths further amplifies this variability in the early phase of outbreaks. As the outbreak progresses and case numbers increase, the uncertainty decreases, as reflected in the narrowing of the uncertainty band over time (Figure S3).
This study also highlights an important trade-off: relying on external estimates may introduce biases due to mismatch with outbreak-specific dynamics while deriving estimates directly from aggregate data ensures specificity but may come with higher uncertainty in early stages, as noted above. While our work does not directly evaluate the comparative advantages of these approaches, it provides a foundation for future studies to explore this trade-off under diverse outbreak scenarios. Investigating the conditions under which outbreak-specific estimates become preferable to external estimates—through simulations or empirical comparisons—would represent an important direction for advancing this field.
The distributed-delay method introduces a higher level of complexity than the oversimplified direct or Baud’s methods, and these oversimplified quantification methods typically do not involve any minimization problem. An expected consequence of this increase in complexity and optimization requirement is that more extensive computational resources are required for CFR quantification. The realized computational time of the distributed-delay method is variable. It typically depends on multiple factors, including case incidence, case fatalities incidence, and the degree of required tuning of the parameters of the optimization algorithm. (see Supplementary: Computational cost of distributed-delay method). Although a steep trade-off may be associated with computational cost, this consideration must not undermine the necessity of accurate quantifications of CFR.
As noted in the results (Fig. 2), the Generalized Baud’s method underestimates the parameters \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\lambda\:$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:m$$\end{document} . We find that this is because the shape of the death curve is fixed since \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:s\to\:0$$\end{document} and does not follow the shape of a death curve generated from a case-to-death time distribution. When the case-to-death time distribution has a long tail, it generates many small case-to-death times and a few potentially very long ones. As a result, the realized fatalities data is less sharply peaked than the case data, and the time between the cases and fatalities is often smaller than the average case-to-death time. When we assume a case-to-death time distribution with zero variance (i.e., a delta distribution) as in the Generalized Baud’s method, the estimated fatalities become a time-shifted copy of the curve of the case, which has a fundamentally different shape than the actual fatality curve (see Supplementary; Fig. S5). As a result, the peak of the Generalized Baud’s estimations, given the assumed, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:m$$\end{document} occurs later than the peak of the data, and minimums are therefore found by underestimating the average case-to-death time when the two peaks align. The same principle applies to \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\lambda,$$\end{document} but in terms of the areas under the curve, as this equals the cumulative number of deaths. Residuals are not minimized for the true \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\lambda\:$$\end{document} , as this narrower shape requires many fatalities around the peak.
Any estimator should ideally be unbiased, meaning that variation around the average estimate is symmetrical and that the average estimate is correct in the limit of infinite samples. We have observed a slight overestimation in CFR estimates in the very early phase. From additional analyses, we conclude, however, that the estimator is unbiased in itself but that the average of realizations is systematically repelled from the CFR boundaries as the distribution of realizations becomes, as expected, skewed near the boundaries of the CFR range, i.e., [0, 1] (Supplementary; Fig. S4). Such effects may also arise depending on the choice of minimization algorithm. Applying least squares in sparse data settings, as we did in this study, could generate these types of boundary effects. A more flexible method, like maximum likelihood, could minimize such boundary effects, which we leave for future work.
This study provides point estimates of the estimated parameters. Uncertainty in the estimated CFR may arise from data variability and model assumptions, particularly in early outbreak phases when case-to-death dynamics are not fully observed. Future work can incorporate techniques such as bootstrapping to derive uncertainty bounds such as confidence intervals when using our distributed-delay method.
Our study assumes that the CFR is constant throughout an epidemic, providing a controlled framework to evaluate the convergence behavior of estimation methods. The observed variation in the estimated CFR over time, as shown in Figs. 1 and 2, reflects the error inherent in the estimation process rather than any inconsistency in the true underlying CFR, which is held constant in the simulations. This variation highlights the methods’ ability to converge toward the true CFR, particularly during the exponential growth period of the outbreak.
The CFR, however, can vary over time for various reasons. For example, early in an outbreak of a novel pathogen, severe infections are disproportionately likely to be accounted for as a case due to limited testing or lower disease familiarity among patients and the health system^31,32^. The lack of knowledge about novel infectious agents can also result in many case fatalities initially. Factors like healthcare system readiness, demography, local disease dynamics, testing, tracking systems, and data reporting can influence ongoing disease severity estimates^32^. This is also dependent on how one defines CFR. The conventional concept of the CFR for a given disease outbreak, typically obtained in hindsight past the outbreak, refers to the long-term average CFR. One implication of assuming a constant, or conventional, CFR when comparing the performance of the respective quantification methods on empirical data is that no point of reference exists except for the long-term average. The performance on empirical data was adjudged here concerning how well the long-term average CFR can be inferred by the respective methods already early in the outbreak (Fig. 5).
Capturing the real-time (or time-dependent) CFR requires information on case fatality or recovery for each individual reported as a disease case and the distribution of associated case-to-death times. Such detailed information, particularly during the early phases of novel outbreaks, is often unavailable. Timely reporting of such individualized case data on case fatality or recovery is crucial for accurate disease severity assessment throughout an outbreak. We emphasize that reporting of individualized data should be recommended as it would help enable further improved disease severity quantification early in outbreaks.
While the method indirectly accounts for demographic heterogeneity through aggregated cases and deaths data, it does not explicitly estimate CFR contributions from specific subgroups (e.g., age or gender). Extending the method to stratified analyses, where cases and fatalities are grouped by key demographic variables, could enable more precise subgroup-specific estimates. By applying the distributed-delay method to each subgroup and aggregating the results, a weighted average CFR for the whole population could be obtained, accounting for demographic differences. Such extensions would allow for evaluating the specific contributions of demographic heterogeneities to overall CFR estimates, providing valuable insights for targeted public health interventions.
Recognizing the earlier considerations, the distributed-delay method offers room for further improvements. Future research should focus on modeling the case fatality ratio as a time-varying quantity, further incorporating factors like population demographics (age and gender), and assessing the influence of interventions. Our analysis can be further extended by exploring a broader range of case-to-death time distributions, such as the Weibull distribution, conducting systematic comparisons with similar methodological approaches (e.g., Nishiura et al.^17^), and applying the proposed framework to historical epidemic datasets. These extensions would provide valuable insights into the generalizability of the method across diverse outbreak scenarios and further evaluate its practical utility for real-world applications.
As noted by Lipsitch et al. (2015)^20^, CFR estimates are influenced by multiple biases, including delays in reporting deaths, underascertainment of mild cases, changes in testing practices, and demographic composition of cases. While our study focuses primarily on addressing the delay bias using aggregated time-series data on confirmed cases and death data in improving CFR compared to the widely used direct method in an ongoing outbreak, future work should aim to integrate these dynamic factors to provide a more comprehensive framework for CFR estimation.
In this analysis, we did not factor in the effects of new variants of a pathogen because it mainly addresses the early estimation of overall CFR in an outbreak—when, most likely, only one variant would circulate. If data were stratified by variant (e.g., through genomic surveillance), our method could be applied separately to assess the variant-specific CFR. This would provide valuable insights into how different variants influence disease severity over time.
In conclusion, the distributed-delay method yields more accurate CFR estimates than earlier alternative methods. It adeptly accommodates realistic variability in case-to-death times, revealing limitations in previous methods. Operating solely on data from the specific epidemic under consideration, the method avoids reliance on parametric assumptions, making it useful for, for instance, outbreaks of novel pathogens. The new method could prove valuable in future outbreaks and for pandemic preparedness, if further developed, to estimate real-time CFR effectively.
Electronic supplementary material
Below is the link to the electronic supplementary material.
Supplementary Material 1
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Hashmi, H. A. S. & Asif, H. M. Early detection and assessment of covid-19. Front. Med.7, (2020).10.3389/fmed.2020.00311 PMC 729615332582748 · doi ↗ · pubmed ↗
- 2Giesecke, J. Modern Infectious Disease Epidemiology (3rd Ed.). (2017).
- 3Lui, G. C. Y. et al. Significantly lower case-fatality ratio of coronavirus disease 2019 (COVID-19) than severe acute respiratory syndrome (SARS) in Hong Kong—a territory-wide cohort study. Clin. Infect. Dis. Off Publ Infect. Dis. Soc. Am..10.1093/cid/ciaa 1187 PMC 754325933005933 · doi ↗ · pubmed ↗
- 4Hu, W. et al. Estimation of COVID-19 case fatality ratio based on a bi-directional correction method. med Rxiv (2020).
- 5Angelopoulos, A. N., Pathak, R., Varma, R. & Jordan, M. I. On identifying and mitigating bias in the estimation of the COVID-19 case fatality rate. Spec. Issue 1-COVID-19 (2020).
- 6Thomas, B. S. & Marks, N. A. Estimating the case fatality ratio for COVID-19 using a time-shifted distribution analysis. med Rxiv (2020).10.1017/S 095026882100170934275506 · doi ↗ · pubmed ↗
- 7Spychalski, P., Błażyńska-Spychalska, A. & Kobiela, J. Estimating case fatality rates of COVID-19. Lancet Infect. Dis. (2020).10.1016/S 1473-3099(20)30246-2PMC 727073032243815 · doi ↗ · pubmed ↗
- 8Kennedy, J. & Eberhart, R. Particle Swarm Optimization vol. 4, 1942–1948 (IEEE, 1995).