High-Quality Text-to-Speech Implementation via Active Shallow Diffusion Mechanism
Junlin Deng, Ruihan Hou, Yan Deng, Yongqiu Long, Ning Wu

TL;DR
This paper introduces a new text-to-speech model that uses a two-stage process to generate high-quality speech quickly.
Contribution
The novel contribution is the cascaded model with an active shallow diffusion mechanism for fast and efficient text-to-speech synthesis.
Findings
The CMG-TTS model achieves high-quality speech with only one denoising step.
The model outperforms others in real-time performance metrics.
Both stages of the model are effective, as shown in ablation studies.
Abstract
Denoising diffusion probabilistic models (DDPMs) have proven to be useful in text-to-speech (TTS) tasks; however, it has been a challenge for traditional diffusion models to carry out real-time processing because of the need for hundreds of sampling steps during the iteration. In this work, a two-stage fast inference and efficient diffusion-based acoustic model of TTS, the Cascaded MixGAN-TTS (CMG-TTS), is proposed to address this problem. An active shallow diffusion mechanism is adopted to divide the CMG-TTS training process into two stages. Specifically, a basic acoustic model in the first stage is trained to provide valuable a priori knowledge for the second stage, and for the underlying acoustic modeling, a mixture combination mechanism-based linguistic encoder is introduced to work with pitch and energy predictors. In the following stage of processing, a post-net is used to…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
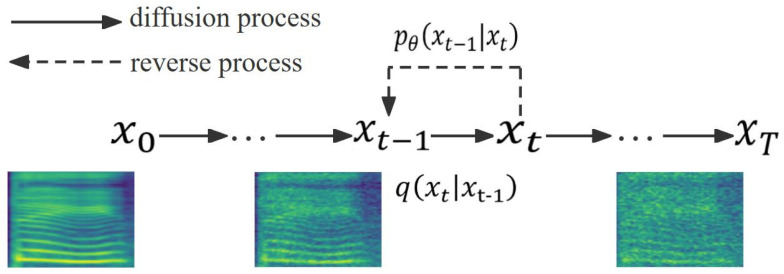 Figure 1
Figure 1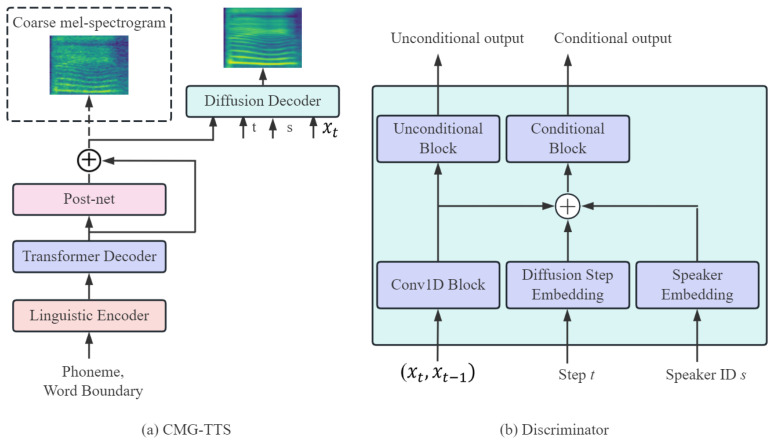 Figure 2
Figure 2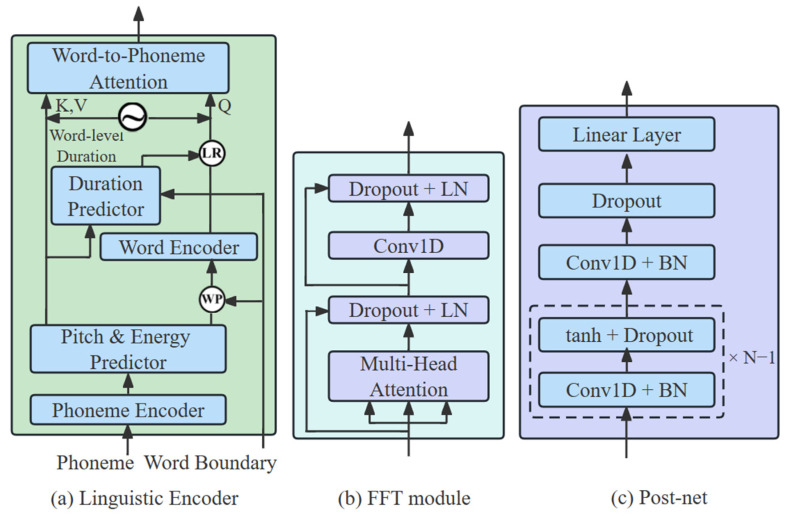 Figure 3
Figure 3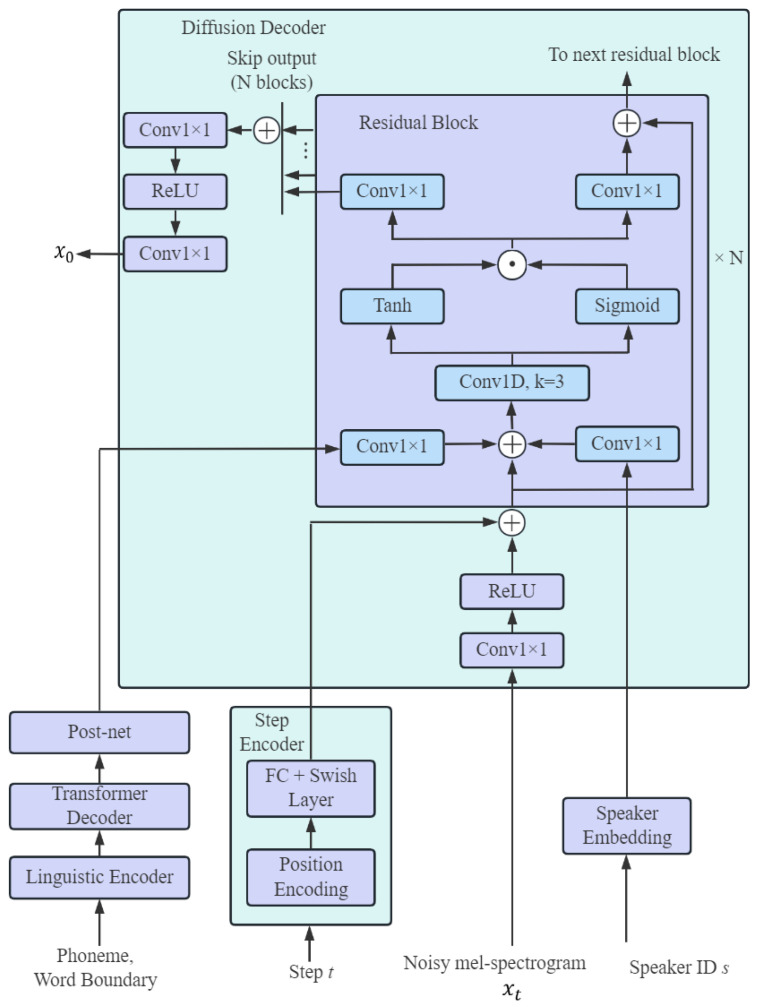 Figure 4
Figure 4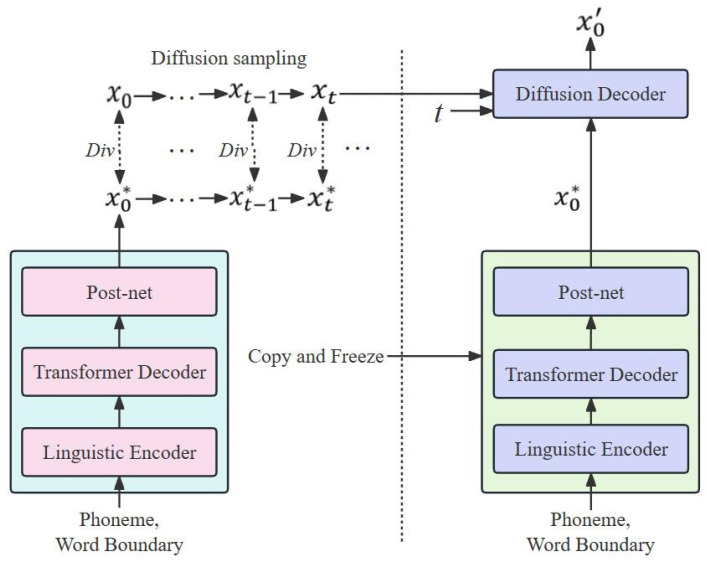 Figure 5
Figure 5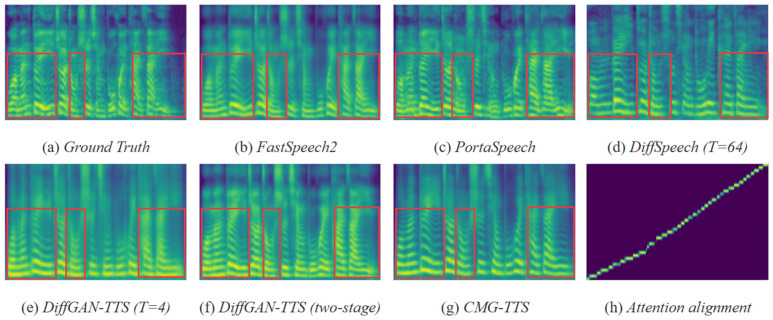 Figure 6
Figure 6Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsSpeech Recognition and Synthesis · Music and Audio Processing · Speech and Audio Processing