Privacy-preserving ADP for secure tracking control of AVRs against unreliable communication
Kun Zhang, Kezhen Han, Zhijian Hu, Guoqiang Tan

TL;DR
This paper introduces a secure and private control method for autonomous vehicles or robots that works even with unreliable communication.
Contribution
A new encrypted guaranteed-cost tracking control scheme using adaptive dynamic programming for secure AVR systems.
Findings
The proposed algorithm uses encryption to prevent information leakage in vehicular networks.
The method avoids dual-network complexity by solving the Hamilton-Jacobi-Bellman equation in a single-network framework.
The control scheme successfully handles input constraints and stabilizes the tracking system.
Abstract
In this study, we developed an encrypted guaranteed-cost tracking control scheme for autonomous vehicles or robots (AVRs), by using the adaptive dynamic programming technique. To construct the tracking dynamics under unreliable communication, the AVR's motion is analyzed. To mitigate information leakage and unauthorized access in vehicular network systems, an encrypted guaranteed-cost policy iteration algorithm is developed, incorporating encryption and decryption schemes between the vehicle and the cloud based on the tracking dynamics. Building on a simplified single-network framework, the Hamilton-Jacobi-Bellman equation is approximately solved, avoiding the complexity of dual-network structures and reducing the computational costs. The input-constrained issue is successfully handled using a non-quadratic value function. Furthermore, the approximate optimal control is verified to…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
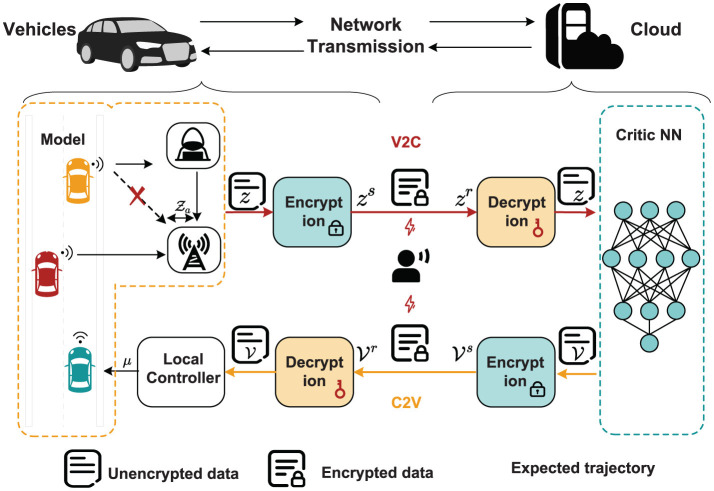 Figure 1
Figure 1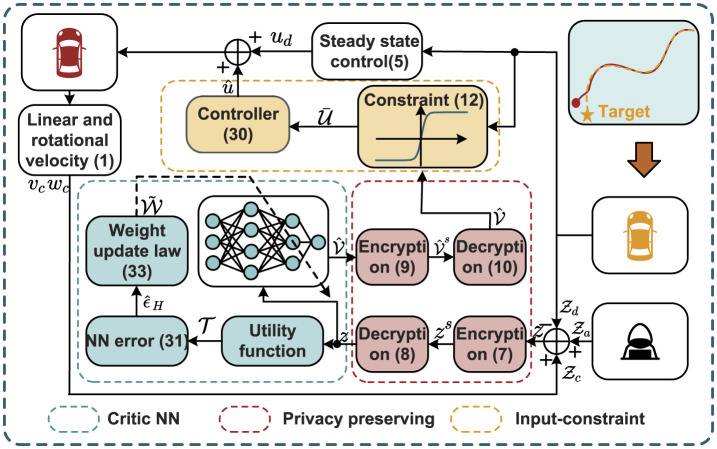 Figure 2
Figure 2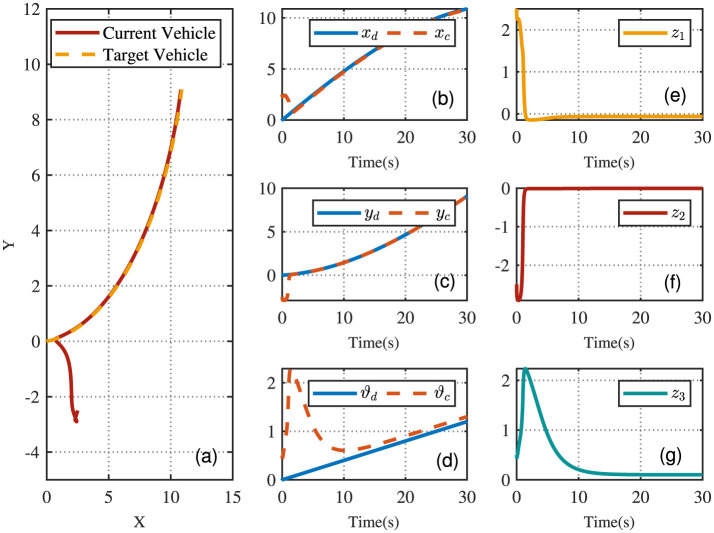 Figure 3
Figure 3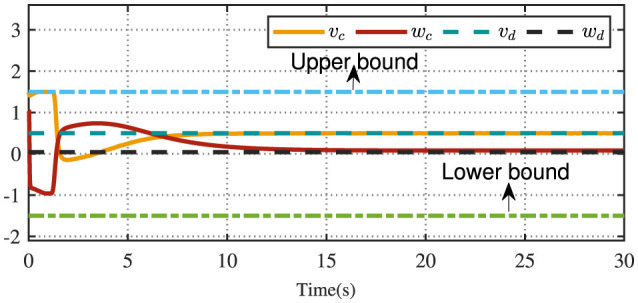 Figure 4
Figure 4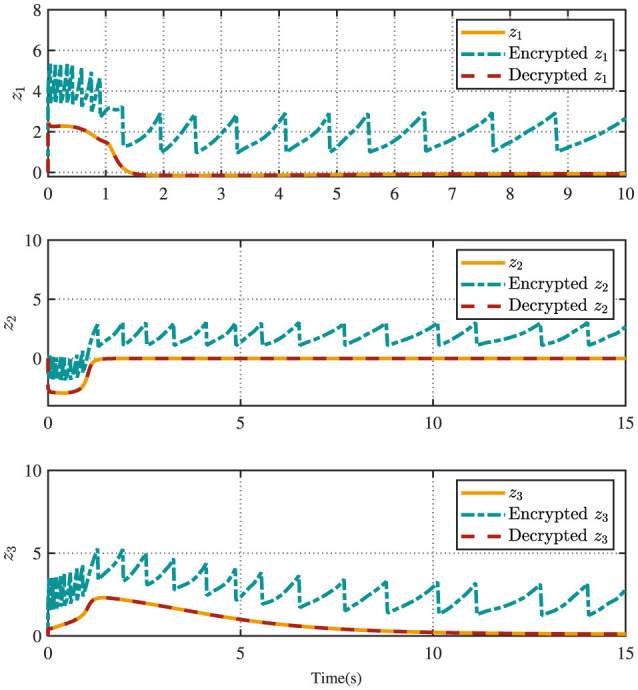 Figure 5
Figure 5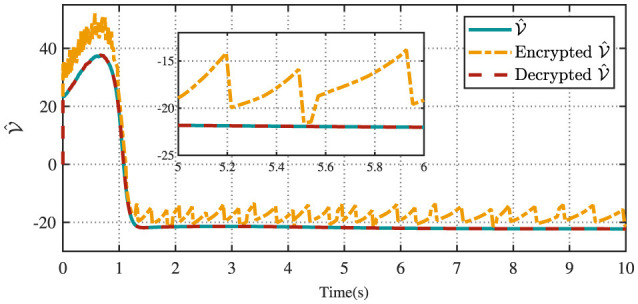 Figure 6
Figure 6Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsAdaptive Dynamic Programming Control · Traffic control and management · Electric Vehicles and Infrastructure
1 Introduction
Autonomous vehicles or robots (AVRs) have rapidly transformed from a futuristic concept to a tangible reality, driving significant advancements in automotive technology. The advancement of autonomous vehicle technology has increasingly focused on improving tracking control systems, which are crucial for effective vehicle guidance (Pan et al., 2023). However, a persistent issue is the unreliable communication between a local vehicle and a reference vehicle, leading to discrepancies in signal reception and affecting tracking precision. In addition to these developments, the emergence of connected vehicles (Li et al., 2019a; Liu et al., 2023b), which leverages cloud computing for data processing and optimization, presents both opportunities and challenges. These systems function as cyber–physical systems (He et al., 2014; Zhang et al., 2014; Mohan et al., 2020), integrating computational and physical processes to enhance real-time data exchange and improve overall traffic management (Jiang et al., 2022; Li et al., 2019b). However, during communication between the vehicle and the cloud, the network's homogeneous and civilian nature makes it, particularly, vulnerable to attacks. This vulnerability, especially in the absence of robust security protocols, exposes these systems to cyber threats, including eavesdropping.
To enhance the security of vehicular cyber-physical systems, researchers from various fields, such as communication, control systems, and information theory, have developed various strategies to address cyberattacks across different layers (Han et al., 2024; Deng and Wen, 2021; Liu et al., 2021, 2023a). Various types of attacks, including denial-of-service (DoS) attacks, false data injection (FDI) attacks, and replay attacks, have been extensively studied (Teixeira et al., 2012; Li et al., 2024; Hu et al., 2023). These types of attacks share the characteristic of being active strategies designed to disrupt system functionality or manipulate transmitted data. Although defense mechanisms have made progress in countering such threats, majority of the existing methods primarily concentrate on detecting and mitigating explicit attacks, often overlooking the fundamental challenge of ensuring communication security. In vehicular cybersecurity, one of the critical issues is the threat of eavesdropping attacks (Yang et al., 2020; Wu et al., 2022). Unlike the direct and active nature of DoS and FDI attacks, eavesdropping operates passively, enabling attackers to intercept sensitive information while remaining undetected. This makes it a significant long-term threat that can compromise communication confidentiality and can even enable more destructive attacks. Addressing this challenge requires advanced encryption and privacy-preserving techniques to ensure secure communication. Although these methods are effective, they do not ensure optimal control performance at minimal energy cost, as they do not incorporate the principles of optimal control.
Optimal tracking control has become a cornerstone of modern control theory, with adaptive dynamic programming (ADP) algorithms attracting considerable interest in recent years (Lu et al., 2020; Mu et al., 2017b). For non-linear optimal control problems, the principal challenge lies in solving the Hamilton-Jacobi-Bellman (HJB) equation—a problem that is nearly intractable through exact mathematical methods. ADP techniques have offered a promising alternative by leveraging neural networks (NNs) to approximate optimal solutions, leading to significant advancements across fields such as automatic control and artificial intelligence (Mu et al., 2017a; Guo et al., 2024). For example, El-Sousy et al. (2021) designed a three-network structure to approximate the solution of the HJB equation for permanent-magnet synchronous motor servo drives. Wang et al. (2020) proposed an dual-network to approximate local Q-functions and control policies, solving optimal consensus control for non-linear multiagent systems. Furthermore, ADP-based optimal tracking control has been widely investigated (Dong et al., 2022; Song et al., 2023), including efforts to address input-constrained systems (Yang et al., 2023; Zhang et al., 2018). However, conventional ADP approaches, particularly those employing actor-critic frameworks, are frequently hindered by significant approximation errors introduced during iterative processes and NN training, thereby restricting their practical applicability.
To address these challenges, researchers have proposed several single-network ADP methodologies designed to streamline system architectures and enhance computational efficiency in handling nonlinear systems (Xu et al., 2023; Chen et al., 2021; Zou and Zhang, 2023). Chen et al. (2021) developed an event-triggered optimal control scheme for a macro–micro stage system, using a single critic NN to solve the modified HJB equation. In Guo et al. (2024), a distributed control strategy for attitude-constrained quadrotor unmanned aerial vehicle is proposed based on a critic network. Among the core ADP algorithms, value iteration and policy iteration (PI) have been widely employed, demonstrating robust performance in numerous applications (Zhang et al., 2020; Lin et al., 2023). However, the two-stage iterative procedures inherent in these methods frequently involve information transmission, which makes them susceptible to interception by adversaries. This vulnerability necessitates additional security measures, thereby increasing computational complexity and further constraining their applicability to complex systems. Although efforts to streamline computational burdens by eliminating actor networks have yielded progress, current ADP methods still inadequately address essential issues such as input saturation and ensuring reliable system performance, leaving these critical areas as potential opportunities for future research.
Unlike the previous studies, this article proposes an encrypted guaranteed-cost tracking control scheme for input-constrained tracking system with unreliable communication, and the main contributions are summarized as follows:
This article introduces an encrypted guaranteed-cost tracking control scheme for AVRs under unreliable communication. Compared with existing works, this is the first attempt to integrate ADP with encryption techniques, addressing both control performance and information security challenges in vehicular networks.The designed privacy-preserving control method introduces a strategy to address eavesdropping attacks in control systems. By applying consistent output masking and encryption mechanisms at both the vehicle side and the cloud side, sensitive data and critical control information are effectively protected from potential breaches. This integrated approach ensures secure data transmission while maintaining the integrity and privacy of the control system.A single-network structure with enhanced computational efficiency is proposed to approximate the HJB equation. Compared to conventional dual-network designs, the single-network structure reduces computational complexity while maintaining theoretical guarantees on weight error convergence and system stability. Additionally, input saturation is explicitly addressed through the adoption of a nonlinear value function, further enhancing the robustness.
2 Preliminaries and problem formulation
Consider an AVR operating in the X-Y plane, the position and orientation of the vehicle's mass center are represented by a posture vector
where x(t) and y(t) denote the horizontal and vertical positions, respectively, and ϑ(t) denotes the heading direction measured counterclockwise from the X-axis. The vehicle's motion is governed by the following kinematic model:
Here, v(t) and w(t) represent the vehicle's linear and rotational velocities, respectively, while is the distance between the vehicle's mass center and its drive axle; and is the Jacobian matrix that links the control inputs to the vehicle's motion. So far, the control objectives are summarized in the following.
Control objective: For an AVR under unreliable communication, design an ADP-based robust optimal controller with secure information exchange to drive the vehicle along the target, such that the following objectives are achieved:
- Robust tracking control objective: For an AVR, c: = [x(t);y(t);ϑ(t)] to track the desired orbit d: = [xd(t);yd(t);ϑ_d(t)] under malicious cyberattacks on the tracking process, as shown in Figure 1. Due to the occurrence of an attack, a small deviation arises between the received signal and the actual signal. This deviation, caused by malicious attacks, is defined as a: = [xa(t);ya(t);ϑa_(t)]. We assume that a and its derivative are bounded.
Proposed scheme for tracking process of AVRs.
With the minor difference a caused by unreliable communication, following the framework in Zhang et al. (2022), we derive the tracking error system as
where e: = [xe(t);ye(t);ϑ_e(t)] denotes the tracking error posture, vd(t) and wd(t) are the desired linear and rotational velocities, vc(t) and wc(t) are the control inputs of the vehicle, and [γx(t);γy(t);γ_ϑ(t)] captures the effect of cyberattacks on the received signals and given by
This model describes the dynamic behavior of the tracking error in AVR control.
To facilitate system description and control implementation, let us consider that z = [xe(t);ye(t);ϑ_e(t)], f(z) = [cos(ϑe(t))vd(t); sin(ϑe(t))vd(t);wd(t)], g(z) = [−1, ye(t);0, −xe(t);0, 1], and u = [vc(t), wc_(t)]. The system (Equation 2) is rewritten as
where u is control input and satisfies the asymmetric constrained set 𝔒 = {u||u| ≤ ℏ}. To follow the conventional optimal tracking architecture, we can rewrite the reference trajectory as follows
where ud is the steady-state control input taking the following form
where , In denotes an n × n identify matrix.
Assumption 1. The unreliable communication γ(t) is bounded by , that is , where is positive constant.
-
Prevent eavesdropping objective: As shown in Figure 1, the cloud handles monitoring, scheduling, optimization, and computation tasks, while the local controller is responsible for distributing control signals, albeit with limited data storage and processing capabilities. The cyberattack considered here is eavesdropping, where unauthorized interception of data during transmission allows attackers to steal sensitive system information, such as real-time control signals and operational states. To mitigate these risks, encryption and decryption mechanisms are implemented to safeguard the confidentiality and integrity of the transmitted data, ensuring secure communication and enhancing the system's overall reliability.
-
Optimal control objective: Based on the optimal control strategy, the AVR can achieve a compromise between performance and cost when running along a target, such that
where , which is the utility function with feedback control μ = u − ud, γ_1_ is positive constant, = ^T^ > 0, and is a positive definite non-quadratic integrand function.
3 Iterative algorithm design
In this section, based on the preceding analysis, the tracking problem is reformulated into a stabilization problem for the error dynamics. To address this, a cryptography-based controller is designed, which not only mitigates the impact of unreliable communication but also ensures the security of information transmission against eavesdropping.
3.1 Encryption and decryption algorithm design
To effectively counter eavesdropping attacks on data transmitted between the vehicle side and the cloud side, privacy-preserving rules are designed for both sides. The encryption and decryption formulas (Han et al., 2024) for each iteration are provided in the following.
- AVR to Cloud:
Encryption process: At the vehicle side, the data z to be sent are extracted from Equation 3 and encrypted using Equation 7, resulting in the encrypted data z^r^. This encrypted data are then transmitted to the cloud. The encryption formula is as follows:
where a(t) and ξ(t) are encryption operators, δ_1_, ρ_1_, and ρ_2_ are constants, and A is the channel assignment matrices. To simplify the presentation of the method, it is assumed that ^s^(z)(t − 1) is already stored in the cloud. The value (z) needs to be calculated on the cloud side. Its design is detailed in Section 3.2 and it serves as an essential component of the controller μ.
Decryption process: The cloud side receives the encrypted data z^r^ and decrypts it to recover the original data z. The decryption formula is as follows:
where c(t) is the counterpart of a(t). It is observed that the design forms of the encryption operators a(t) and ξ(t), and encrypted expressions are shared between the vehicle side and the cloud. Furthermore, the parameters A, δ_1_, ρ_1_, and ρ_2_ are also shared.
- Cloud to AVR:
Encryption process: After policy evaluation, the computed (z) is encrypted using Equation 9 and sent back to the vehicle.
where b(t) and ζ(t) are encryption operators, δ_2_, ϱ_1_, and ϱ_2_ are constants, and B is the channel assignment matrices.
Decryption process: At the vehicle side, the received encrypted data ^r^(z) is decrypted using Equation 10 to recover (z) for policy improvement.
where d(t) is the counterpart of b(t). Similarly, the design forms of the encryption operators b(t) and ζ(t), and encrypted expressions are shared between the vehicle side and the cloud. Furthermore, the parameters B, δ_2_, ϱ_1_, and ϱ_2_ are also shared. At this point, a complete iteration of privacy-preserving processing has been completed.
From the above encryption and decryption processes, it can be observed that the introduced masking signals ξ(t) and ζ(t) and the encryption formula designs effectively ensure privacy during data transmission between the vehicle and the cloud. Notably, the data transmitted over the network are not the raw values z and (z) but their encrypted counterparts, z^s^, z^r^, ^s^(z), and ^r^(z), which effectively prevent unauthorized entities from intercepting sensitive information.
3.2 Encrypted iterative algorithm design
The objective is to stabilize Equation 3 by constructing an encrypted iterative algorithm so that minimizing the performance index function, thereby reducing control costs and enhancing system security. Recalling Equation 6, the performance index is
where
where = diag{[r1, ..., rm]} > 0, . The function h(·) is assumed to be a monotonic odd function satisfying h(0) = 0. For the purposes of this article, h(·) is specifically selected as h(x) = (e^z^ − e^−z^)/(e^z^ + e^−z^).
According to the optimal control theory, Equation 11 is a Lyapunov function for the Equation 3 and the Hamiltonian function can be derived as
with . On defining ^*^(z) as the minimum value of Equation 11, based on Bellman's principle of optimality, we have
and the optimal control u^*^ is obtained from :
Substituting Equation 15 into Equation 12 yields
where and . Then, the HJB equation can be derived as
As highlighted in the preceding analysis, obtaining the optimal controller in Equation 15 necessitates solving the HJB Equation 17, a task well-known for its considerable computational and analytical challenges. To overcome this challenge, an iterative algorithm based on ADP is employed to obtain an approximate solution. The details of this iterative algorithm are presented in Algorithm 1.
Algorithm 1: Encrypted guaranteed cost policy iteration algorithm.
Lemma 1. By utilizing the encrypted PI process as described in Algorithm 1, which incorporates encryption and decryption steps for secure control of the tracking error dynamics in an AVR, the resulting control uς ensures the asymptotic stability of the system dynamics. Additionally, ς(z) will converge to the optimal value function ^^(z) as ς → ∞, ensuring that uς converges to the optimal control u^^.
Proof. Initially, without iterations, the control u1 is considered admissible. For ∀uς produced during iterations, consider the Lyapunov function ς(z), which satisfies
According to HJB Equation 17, we can drive
where μ_ς_ = uς − ud. Then, substituting Equation 21 into Equation 22 yields
Therefore, the iteration process ensures that the error dynamics remain asymptotically stable. Moreover, policy improvement is achieved by minimizing the associated value function, consistent with the Kleinman method, guaranteeing convergence. As the iteration count ς → ∞, , and hold. This concludes the proof. □
Based on Lemma 1, the iterative process, enhanced with secure encryption and decryption, converges, leading to optimal control as the approximation errors diminish.
4 Critic neural network design
In this section, this study employs the fundamental update equations of PI to design a NN, utilizing the critic neural network (CNN) to approximate the solution of the HJB Equation 17 during each iteration step. Therefore, based on the universal approximation property of NNs, there exist ideal weights ^*^ such that the ideal value function can be approximated as
where φ(z) ∈ ℝ^α^ denotes activation functions and α is the number of neurons. Utilizing Equation 23, HJB Equation 17 becomes
where
with and . Therefore, by defining residual error ϵ_H_, Equation 24 can be rewritten as
where
with , 2i(z) ∈ [ i(z), 1i(z)]. Note that if the number of hidden layer neurons α is sufficiently large, the residual error ϵ_H_ will approach zero. Based on the Lipschitz assumption of the system dynamics, this ϵ_H_ is bounded within a compact set, that is, . Therefore, based on Equation 23 the ideal optimal control is
where , ψ_i_ ∈ [ i, 1i].
Since the ideal weight is unknown, the approximated value function is
where is approximated value of ^*^. Then, we can get
Thus, approximated Hamiltonian function is
where is the residual error due to NN approximation error.
Furthermore, let us consider , and to ensure that converge toward the optimal weights ^*^, the weight update formula (Zhang et al., 2018) is
where η is learning rate, τ = ∇φ(z)(f(z)+g(z)û+γ), ϖ = τ^T^ τ + 1, and 1 and 2 are a tuning matrix. , . Based on the Lemma 2 by Zhang et al. (2018), a denotes Lyapunov function, and if ∇ a(f(z)+gû + γ) > 0, then κ = 0, else κ = 1. Defining , we obtain
with , .
Theorem 1. For the optimal control policy described in Equation 30, the weight tuning law of the CNN is determined by the update formula provided in Equation 32. Under this design, the error dynamic system z and the weight errors are uniformly ultimately bounded (UUB).
Proof. Define the Lyapunov function as = 1 + 2, where
First, along Equation 33, the derivative of 2 is
where
Supposing that , , and due to is bound, , . Therefore, is
Owing to κ of 2, is divided into two parts. For κ = 0, we have
From a study by Rudin et al. (1964), we can know , ||z|| ≤ zm, zm > 0, thus, becomes
Moreover, if
or
According to Equation 39, we can derive
For κ = 1, is
Regarding , using the Taylor series, we know
where is the higher order term and satisfies
where ||g|| ≤ ḡ, ḡ > 0 and , .
Recalling Equations 28–30, the term in Equation 41 with respect to ∇ ag can be written as
Until now, Equation 41 can be rewritten as
where , . Let ℓ_1_ and ℓ_2_ satisfy 0 < ℓ_1_ < 1, 0 < ℓ_2_ < 1, and ℓ_1_ + ℓ_2_ = 1. Then, Equation 44 can be rewritten as
Therefore, if
or
Similar to Equation 40, we can derive
By considering the two cases, κ = 0 and κ = 1, and based on the derived results as expressed in Equations 38–40 and Equations 45–47, we can conclude that the function ∇ a and the error weights are UUB. Furthermore, knowing that a is in polynomial form, it follows that the error z is also UUB.
Remark 1. The algorithm designed in this article is depicted in Figure 2, where Algorithm 1 is implemented using a CNN. The CNN generates the estimated value function , which is subsequently used to derive the approximated optimal control law û based on Equation 30. In contrast to the constrained optimal control designs presented in the studies by Zou and Zhang (2023); Chen et al. (2021), this work integrates privacy-preserving mechanisms during information transmission by leveraging encryption and decryption techniques. This incorporation not only safeguards data confidentiality but also enhances the overall security and reliability of the proposed algorithm.
Illustration of tracking for AVRs subject to privacy protection.
5 Simulation results
To analyze the tracking performance of the AVR, we conduct simulations based on a predefined tracking error dynamic model. The tracking error dynamics is modeled as
where represents the distance from the vehicle's center of mass to the rear axle, set to = −1.2m in this article. The desired reference trajectory is initialized with the state:
and the vehicle's trajectory is initialized with the state:
Consequently, the initial value of error denotes
The reference trajectory's desired velocities are vd = 0.5 and wd = 0.04. Under the input constraints, ℏ = 1.5, meaning the constraint range is [−1.5, 1.5]. The unreliable communication γ is defined as
where σ is a random variable uniformly distributed in σ ∈ [−0.1, 0.1]. For the performance evaluation, we define the cost function using the weighting matrices
The activation function vector of CNN is sin(z1), sin(z2), sin(z3), . ρ_1_ = 1.1, ρ_2_ = 1.03, ϱ_1_ = 3.2, ϱ_2_ = 1.08, , , A = 1, and B = 1.
Using the proposed method, Figure 3A illustrates the two-dimensional trajectory of the AVR. The vehicle quickly adjusts its direction and begins tracking the reference trajectory with good accuracy. After the initial phase, the vehicle follows the desired trajectory smoothly and closely. Figures 3B–G depict the tracking performance and error, demonstrating that the position error gradually reduces to zero, while the directional error also diminishes to zero, effectively ensuring precise position tracking throughout the process.
AVR driving trajectories. (A) The X-Y plot of tracking trajectories. (B–D) Tracking trajectories. (E–G) Tracking errors.
Figure 4 displays the evolution of the designed controller during the vehicle's tracking process. The dashed lines indicate the upper and lower bounds of the input constraints, which are set to [−1.5, 1.5]. The privacy-preserving characteristics of the proposed scheme are illustrated in Figure 5. It is evident that masking the vehicle-side output z effectively safeguards its privacy from potential attackers. Meanwhile, as shown in Figure 6, masking on the cloud side further prevents the leakage of critical information related to the designed control strategy. Therefore, these results ensure robust privacy protection during data transmission.
The constrained control input.
Encrypted error and decrypted error.
Encrypted value function and decrypted value function.
6 Conclusion
This study develops an encrypted guaranteed-cost tracking control scheme to address the challenges of information security and computational efficiency in AVR systems using the adaptive dynamic programming technique. By leveraging ADP and integrating encryption mechanisms between the vehicle and the cloud, the proposed method ensures stable tracking performance under unreliable communication. The input constraints are successfully managed using a nonlinear value function, while the CNN facilitates an efficient solution to the HJB equation. Simulation results from a case study confirm the stability and effectiveness of the designed algorithm, demonstrating its potential for real-world applications in AVR networks. Future work will focus on ensuring the security of cloud-based computations by processing encrypted data, further enhancing the safety and reliability of cloud operations in vehicular network systems.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Chen X.Chen X.Bai W.Guo Z. (2021). Event-triggered optimal control for macro–micro composite stage system via single-network ADP method. IEEE Trans. Indust. Elect. 68, 4190–4198. 10.1109/TIE.2020.2984462 · doi ↗
- 2Deng C.Wen C. (2021). Mas-based distributed resilient control for a class of cyber-physical systems with communication delays under dos attacks. IEEE Trans. Cybern. 51, 2347–2358. 10.1109/TCYB.2020.297268632149704 · doi ↗ · pubmed ↗
- 3Dong H.Zhao X.Luo B. (2022). Optimal tracking control for uncertain nonlinear systems with prescribed performance via critic-only ADP. IEEE Trans. Syst. Man, Cybernet.: Syst. 52, 561–573. 10.1109/TSMC.2020.3003797 · doi ↗
- 4El-Sousy F. F. M.Amin M. M.Al-Durra A. (2021). Adaptive optimal tracking control via actor-critic-identifier based adaptive dynamic programming for permanent-magnet synchronous motor drive system. IEEE Trans. Ind. Appl. 57, 6577–6591. 10.1109/TIA.2021.3110936 · doi ↗
- 5Guo Z.Li H.Ma H.Meng W. (2024). Distributed optimal attitude synchronization control of multiple quavs via adaptive dynamic programming. IEEE Trans. Neural Netw. Learn. Syst. 35:8053–8063. 10.1109/TNNLS.2022.322402936446013 · doi ↗ · pubmed ↗
- 6Han K.Zhang K.Wang Z.-P.Su R. (2024). Resilient predictive load frequency control of multi-area interconnected power systems with privacy preserving and active detection against stealthy cyber attacks. IEEE Intern. Things J. 7, 4387–4394. 10.1109/JIOT.2024.3507291 · doi ↗
- 7He W.Yan G.Xu L. D. (2014). Developing vehicular data cloud services in the Io T environment. IEEE Trans. Indust. Inform. 10, 1587–1595. 10.1109/TII.2014.2299233 · doi ↗
- 8Hu S.Ge X.Chen X.Yue D. (2023). Resilient load frequency control of islanded ac microgrids under concurrent false data injection and denial-of-service attacks. IEEE Trans. Smart Grid 14, 690–700. 10.1109/TSG.2022.3190680 · doi ↗