Marginal semiparametric accelerated failure time cure model for clustered survival data
Yi Niu, Duze Fan, Jie Ding, Yingwei Peng

TL;DR
This paper introduces a new statistical model for analyzing survival data with long-term survivors, accounting for correlations within groups of patients.
Contribution
The paper extends the semiparametric accelerated failure time cure model to clustered survival data using a novel estimation approach.
Findings
The proposed method is robust to misspecification of correlation structures.
Higher efficiency is achieved when the working correlation structure matches the true structure.
The model provides new insights in a breast cancer study by considering patient correlations.
Abstract
The semiparametric accelerated failure time mixture cure model is an appealing alternative to the proportional hazards mixture cure model in analyzing failure time data with long-term survivors. However, this model was only proposed for independent survival data and it has not been extended to clustered or correlated survival data, partly due to the complexity of the estimation method for the model. In this paper, we consider a marginal semiparametric accelerated failure time mixture cure model for clustered right-censored failure time data with a potential cure fraction. We overcome the complexity of the existing semiparametric method by proposing a generalized estimating equations approach based on the expectation–maximization algorithm to estimate the regression parameters in the model. The correlation structures within clusters are modeled by working correlation matrices in the…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
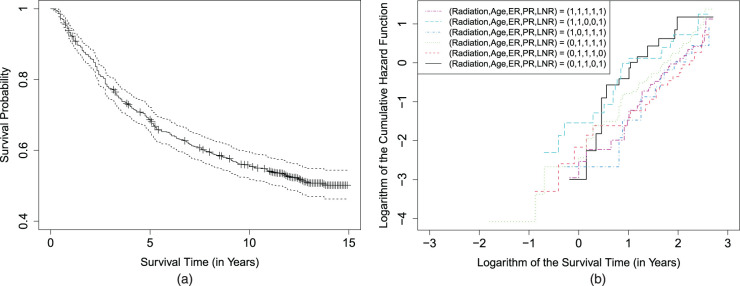 Figure 1
Figure 1- —National Natural Science Foundation of Chinahttps://doi.org/10.13039/501100001809
- —Fundamental Research Funds for the Central Universitieshttps://doi.org/10.13039/501100012226
- —Natural Sciences and Engineering Research Council of Canadahttps://doi.org/10.13039/501100000038
- —Dalian High-level Talent Innovation Project
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsStatistical Methods and Inference · Statistical Methods and Bayesian Inference · Genetic and phenotypic traits in livestock
Introduction
Many studies involving time-to-event analysis have a fraction of study subjects who will not experience the event of interest even after an extended follow-up. They are often deemed as cured or long-term survivors who are immune or non-susceptible to the event. For instance, only 5% to 50% of patients with head and neck cancer^ 1 ^ experienced local recurrences, and many patients were free of symptoms of cancer at the end of the sufficiently long observation period and can be considered cured. Due to the existence of cured subjects, using classical survival models, such as Cox’s proportional hazards (PH) model, for such data, can result in biased estimates and information loss, and cure models^2,3^ that have been developed to take the cured subjects into account should be considered.
In addition to potentially cured subjects, clustered survival times are often observed in the studies. Clustering may occur when there are multiple events from one subject^ 4 ^ or multiple subjects from the same family or hospital,^ 5 ^ and the times to the event of interest from the same cluster tend to be correlated due to shared genetic or other common environments.
To appropriately account for the correlation in a cluster, the two most studied approaches are marginal models and frailty models. The marginal models focus on the population average on the marginals of the joint distribution of data from one cluster. The correlation within a cluster is either estimated by a working correlation or treated as a nuisance parameter in the marginal models. Alternatively, frailty models explicitly formulate the underlying dependence structure by random effects or frailties, and the failure times are assumed to be independent conditional on the unobservable frailty. These models have been studied extensively in the literature. For example, Rubio and Drikvandi^ 6 ^ developed a novel parametric mixed-effects general hazard model for the analysis of clustered survival data. The heterogeneity between clusters is modeled via the incorporation of random effects into a hazard-based regression model. Chiou et al.^ 7 ^ considered a semiparametric accelerated failure time (AFT) model for clustered failure times from stratified random sampling and proposed weighted rank-based estimating equations for fitting the model with the induced smoothing approach. The generalized estimating equations (GEE) method^ 8 ^ has been adopted in both the marginal AFT models^9,10^ and the marginal PH models.^11,12^
To model clustered survival data with a cured fraction, the marginal mixture cure model is often assumed and a robust variance estimation is used for inference.^5,13^ The PH assumption was considered for survival times among uncured subjects in the marginal models. This approach was further generalized with a transformation model for survival times among uncured subjects^14,15^ and with GEE to allow for more efficient estimation.^16?–18^ Other approaches for modeling clustered survival data were also considered in cure models, including the random effects/frailty approach^19???–23^ and the copula approach.^24??–27^
The existing models for clustered/correlated survival time with a cured fraction are largely based on the PH assumption when modeling the effects of covariates on the survival time of uncured subjects. Although the PH assumption is widely used in modeling censored survival data, it is not an assumption that is easier to satisfy in practice than other assumptions. It also suffers from difficulty in interpreting the estimated effects. Researchers will benefit from having more than one analytic technique at their disposal when the PH assumption is not appropriate.
One alternative assumption to the PH assumption is the AFT assumption. The attractive feature of the AFT model is that the effects of covariates are modeled directly on the expected value of the survival time, making the interpretation more intuitive and straightforward than the effects from the PH assumption.^ 28 ^ The AFT model also enjoys other desirable properties, including collapsibility, that are not exhibited by a PH model. The collapsibility makes the AFT model particularly attractive when quantifying confounding effects^ 29 ^ and mediation effects of covariates^30,31^ in causal inference.
The AFT assumption has been considered in models for survival data with a cure fraction, including parametric AFT mixture cure models^32,33^ and semiparametric AFT mixture cure models.^34??????–41^ However, we are not aware of any existing work on modeling clustered survival data with a cured fraction using the AFT assumption, particularly under semiparametric models. This may be due to the challenges in extending the existing semiparametric estimation methods to clustered survival data. It motivates us to consider AFT assumption-based cure models for clustered survival time with a cured fraction. This work is important because it fills the gap in the literature and provides useful alternatives to the PH-based models for clustered survival data with a cured fraction. The interpretation of covariate effects in the AFT assumption-based models is more straightforward and intuitive, and the models are more suitable for future work in causal inference.
In this paper, we propose a marginal semiparametric AFT mixture cure model for clustered survival time data with a cured fraction. An estimating equation approach is employed to estimate the regression parameters in the model with flexible working correlation structures for cure statuses and for the survival times of uncured subjects within clusters. The paper is organized as follows. Section 2 introduces the marginal semiparametric AFT mixture cure model for clustered survival data with a cure fraction. A semiparametric estimation method of the model based on a set of GEE is presented and the asymptotic properties of the estimators are investigated in this section. A simulation study is conducted in Section 3 to evaluate the finite sample performance of the proposed estimation method. The proposed model and the estimation method are applied to contralateral breast cancer data in Section 4. Conclusions and discussions are presented in Section 5.
Marginal AFT mixture cure model
Let and be the failure time and censoring time of the th subject in the th cluster, where , is the number of clusters, , and is the number of subjects in the th cluster. The total number of subjects in all clusters is . Denote as the observed failure time and as the censoring indicator. Let and denote a vector of covariates and a vector of covariates, respectively. Given and , the censoring time is assumed to be independent of . Let be the cure status of the th subject in the th cluster, where if the subject is cured and if not. We further assume that given , , , and , and , and and for are correlated, respectively. However, for , and , and and are assumed independent, separately. For cured subjects with , we assume (a finite value is possible as long as it is beyond the support of the distribution of ). It is clear if , and is usually unknown if .
Let denote the survival function of . We propose the following semiparametric marginal AFT mixture cure model for the data above:
where (referred to as the incidence part of the model) is the uncured probability specified as
is a vector of unknown parameters (the intercept is included), is the survival function of (referred to as the latency part of the model), which is assumed to follow the AFT model:
where is a vector of unknown parameters (the intercept is excluded), and is an error term with an unspecified survival function . It is clear that .
If we assume all are known and ignore the correlation within clusters, the likelihood function for the marginal survival model (1) based on available data is
where and is the corresponding density function of . The first term involves whereas the second term involves and . The expectation–maximization (EM) algorithm can be employed to maximize the likelihood function. Let , , and denote the estimates of , , and , respectively, in the th iteration of the algorithm. The E-step in the next iteration of the EM algorithm calculates the conditional expectation of with respect to , which is equivalent to replacing in with its posterior expectation conditional on observed data and the current estimates:
The M-step solves the following estimating equations with respect to and separately to obtain and
Due to the unspecified baseline distribution, the estimating equation (6) cannot be solved directly. Following Ritov,^ 42 ^ we replace with a score function and center to account for the unknown intercept term in (6) to obtain the following estimating equation:
where and is the corresponding distribution function of . To obtain from this estimating equation, an estimate of is needed. It can be nonparametrically estimated by Zhang and Peng^ 35 ^
where are the distinct uncensored failure residuals , denotes the number of subjects with failure at , and is the risk set at . To enhance the identifiability of the parameter estimation, we also set when as in other semiparametric cure model estimation methods.^ 2 ^
To take the potential correlation within clusters into account in the estimation, we consider incorporating working correlation matrices into the estimating equations (5) and (7). Let and be the working correlation matrices that approximate the correlation structure among s and the correlation structure among s, respectively, within the th cluster. Following Liang and Zeger,^ 8 ^ we propose the following GEE for that includes the working correlation matrix for :
where , is a diagonal matrix with diagonal elements , , and is the scale parameter to accommodate potential over- or under-dispersion. When there is no correlation within clusters and , reduces to an identity matrix and equation (9) reduces to equation (5).
To develop the GEE for , we rewrite equation (7) as follows:
where
which is if and is if . A similar estimating equation was also proposed by Buckley and James.^ 43 ^ We propose the following GEE for that includes the working correlation matrix :
where , is an vector of 1s, is an diagonal variance matrix with element , is the diagonal matrix with , , and is the scale parameter to accommodate potential over- or under-dispersion. When there is no correlation within clusters and , reduces to the identity matrix and the GEE (10) reduces to equation (7). Similar to (7), equation (10) relies on the unknown . We suggest to use (8) to estimate . It is a consistent estimate but may not be efficient. In the simulation, we demonstrate that it still allows efficient estimation of from (10).
Using the generalized estimation equations (9) and (10) also requires a full specification of and . Depending on the nature of the correlation structure, the working correlation matrices and can be specified in some special structures. The common working correlation structures are the independent correlation structure, the exchangeable correlation structure (equicorrelated, compound symmetric), and the first-order autoregressive correlation structure. Although the exchangeable correlation structure may be popular for clustered data, the first-order autoregressive correlation structure or other more complicated correlation structures could be considered for clustered data if there is a temporal or spatial distance among the subjects in the cluster that may affect the strength of the correlation. The working correlation matrices are the matrices with the diagonal elements equal to 1, and the off-diagonal elements equal to 0 for the working independent correlation structure, for the exchangeable correlation structure, and at the th row and th column for the first-order autoregressive correlation structure. Let and be in and when and are assumed to have the exchangeable correlation or the first-order autoregressive correlation structures. Consistent estimates of and can be obtained based on the standardized Pearson residuals while consistent estimates of and can be obtained based on the residual of the log-linear model. Specifically, if and are in the exchangeable correlation structure, then
and if and are in the first-order autoregressive correlation structure, then
where
The proposed algorithm for the semiparametric marginal AFT mixture cure model can be summarized as follows:
-
(a)Set initial values , , and .
-
(b)E-Step: Calculate via (4).
-
(c)M-Step:
-
(i)Calculate the estimate of using (8).
-
(ii)Given the current estimates of and , calculate the residuals and the estimates of , , , and via (11), (12), (15), or (13) to (15), depending on the working correlation structure used.
-
(iii)Update the estimate of from (9) and the estimate of from (10).
-
(iv)Repeat steps (ii) and (iii) until convergence. Denote the estimates as , , and .
-
(d)Repeat steps (b) and (c) until the algorithm converges. The stopping criterion is that the sum of the squares of the differences in estimates between two adjacent iterations is below . Let be the final estimator of . Under certain regularity conditions, we establish the asymptotic properties for in the following theorem.
Theorem 1Let be the true value of . Given the consistency of , under some regularity conditions provided in the Appendix, we have that
- (a)the estimator is a consistent estimator of ;
- (b)as , in distribution, where , , , , , , , and .
A proof of the theorem is provided in the Appendix. Note that the theorem only provides the asymptotic properties of and when other parameter estimates are viewed as fixed. The asymptotic properties of other parameter estimates in the model remain to be worked out. It implies that the variance estimates of and based on in the theorem may not be accurate due to the unaccounted variation in other parameter estimates. To obtain better variance estimates for and and to obtain variance estimates of other parameter estimates in the model, we consider the bootstrap method.^ 44 ^ This method has been adopted by other researchers to deal with the variance estimation in models based on AFT assumption.^9,35,45^ In this method, a bootstrap sample is obtained by sampling clusters with replacement. That is, all observations from one cluster are either included or excluded in one bootstrap sample. Our numerical study in the next section shows that the bootstrap method works well in approximating the standard errors of the parameter estimates in the model.
Simulation study
We conduct an extensive simulation study to investigate the finite sample performance of the proposed method. Simulated clustered survival data are generated from a mixture cure model with the marginal specified by (1) to (3). Two covariates are considered in and , one is from the Bernoulli distribution , and the other is from the uniform distribution . For each simulated dataset, the number of clusters and the cluster size are set as and separately.
To generate correlated s with the marginal model (2), we follow the method by Emrich and Piedmonte.^ 46 ^ That is, given the marginal probabilities and within a cluster, we solve for in the following equation:
where is the standard bivariate normal distribution with correlation coefficient , is the th quantile of the standard normal distribution, for , and for all if the exchangeable correlation structure is assumed for s and for all if the first-order autoregressive correlation structure is assumed for s. We then generate from the multivariate normal distribution where has as the matrix elements, and then obtain correlated s by . The value of measures the strength of the correlation among the generated s within a cluster. The R package mvtBinaryEP is available to produce binary data using the procedure above.
To generate correlated s given in the AFT model (3), we produce from a multivariate normal distribution , where the covariance matrix has elements defined in a similar way as in and is used to measure the strength of the correlation among s within a cluster. Then can be obtained following (3). The R package mvtnorm can be used to generate the data.
We set , , and to have strong, weak, and no correlation within clusters. We set and and so that the average cure rate is about 0.5 and 0.35, respectively. The censoring times are noninformative and generated from the uniform distribution which results in a censoring rate of 0.55 when the cure rate is 0.5 and a censoring rate of 0.40 when the cure rate is 0.35. Without loss of the generality, we assume equal cluster sizes and let and consider and .
Table 1.: Bias, Var, Var * , CP of 95% confidence intervals of γ^0,γ^1,γ^2,β^1,β^2 from the proposed method under the IND working correlation , EX correlation , and AR(1) correlation and from the method of ZP 35 for data simulated under the cure rate 0.35 and the EX structure.
Table 2.: Bias, Var, Var * , CP of 95% confidence intervals of γ^0,γ^1,γ^2,β^1,β^2 from the proposed method under the IND working correlation , EX correlation , and AR(1) correlation and from the method of ZP 35 for data simulated under the cure rate 0.5 and the EX structure.
Table 3.: Bias, Var, Var * , CP of 95% confidence intervals of γ^0,γ^1,γ^2,β^1,β^2 from the proposed method under the IND working correlation , EX correlation , and AR(1) correlation and from the method of ZP 35 for data simulated under the cure rate 0.35 and the AR(1) correlation structure.
Table 4.: Bias, Var, Var * , CP of 95% confidence intervals of γ^0,γ^1,γ^2,β^1,β^2 from the proposed method under the IND working correlation , EX correlation , and AR(1) correlation and from the method of ZP 35 for data simulated under the cure rate 0.5 and the AR(1) correlation structure.
For each setting above, we generate 1000 datasets and then fit each dataset with the proposed marginal model and the estimation method. As a comparison, we also fit the data with the AFT mixture cure model of Zhang and Peng^ 35 ^ (referred to as the ZP method) that does not consider the correlation within clusters. This method is available in the R package smcure.^ 47 ^ The average biases, empirical variances, average bootstrap variances (based on 100 bootstrap samples), and empirical coverage percentages of 95% confidence intervals of the estimators are reported in Tables 1 to 4. The results in the tables show that the average estimated variances of the regression parameters from the proposed method are close to their empirical variances in all cases, and the 95% confidence interval coverage rates are satisfactory and close to the nominal level. When the cure statuses and the failure times of uncured patients within a cluster are correlated, particularly for , the empirical variances of the regression parameters from the proposed method are less than those from the ZP method. When the working correlation structure in the proposed method coincides with the true correlation structure, the empirical variances are in general smaller than those with the misspecified one. For the same correlation strength, a higher cure rate generally implies smaller empirical variances in the incidence, especially for and , but larger variances in the latency, which is intuitive because in this case, fewer subjects are uncured. Given the same sample size, the empirical variance estimates tend to decrease as the correlation decreases. When the correlation reduces to zero, the biases and empirical variances based on the proposed method and the ZP method are comparable.
To further evaluate the efficiency gain of the proposed method, we calculate the relative efficiency defined as the ratio of mean squared errors (MSEs) of the estimates from the ZP method and the proposed method with the working independent, exchangeable, and first-order autoregressive correlation structures to the MSE of the estimates from the proposed method with the correctly specified working correlation structure. The results are summarized in Table 5, which shows that the MSEs from the proposed method with three working correlation structures are generally smaller than those from the ZP method when the values of are nonzero. That is, the proposed method improves the estimation efficiency potentially when the correlation exists. The MSEs from the proposed model with the correctly specified working correlation structure are less than those with a misspecified correlation structure, which indicates that using the correct working correlation structure can achieve higher efficiency, especially when the correlation within clusters is strong. The improvement in efficiency diminishes when the correlation within clusters becomes weak.
Table 5.: Relative efficiencies (ratios of MSEs) from the proposed method under the IND working correlation, EX correlation, and AR(1) correlation and from the method of ZP 35 against the proposed method under the correct correlation structure for data simulated under the cure rate 0.35 and 0.5 and the EX and the AR(1) correlation structures.
The proposed estimation method also produces estimates of and , the correlation coefficients in the two working correlation matrices. Even though they do not necessarily correspond to the correlation measures and in the data generation, Table 6 shows that the estimated values of and agree well with the values of and in the sense that when the latter decrease, the former tend to decrease too. When there is no correlation in clusters, the estimates of and are very close to zero. In other words, the estimated values of and provide good measures of the strength of the correlations between the cure statuses and between the failure times of uncured subjects in a cluster. The variance estimates of and are obtained based on the bootstrap method. We observe that the empirical variance estimates and the average of bootstrap variances are quite close, which indicates that the bootstrap variance estimator works well for calculating the variance estimates of and .
Table 6.: Mean, Var, and the Var of ( ρ^1,ρ^2 ) based on the proposed method with the working EX or the AR(1) correlation structure.*
Contralateral breast cancer analysis
We apply the proposed method to a dataset of contralateral breast cancer patients from the SEER database of the National Cancer Institute (https://seer.cancer.gov/data/). Patients with unilateral breast cancer diagnosed between 2005 and 2008 and followed for contralateral breast cancer cases, invasive ductal carcinoma of no special type (ICD-O-3: 8500/3), positive lymph node statuses, and positive histology are considered along with the following baseline covariates: radiation therapy, age at diagnosis, estrogen receptor (ER) status, progesterone receptor (PR) status, and the lymph node ratio (LNR) defined as the ratio between the number of positive lymph nodes and the total number of examined lymph nodes.^ 48 ^ Patients with these characteristics are extracted from the SEER Plus Data 17 Registries database using SEER*Stat 8.4.0.1 software.
There are 694 eligible patients included in our study with a censoring rate of 52.6%. The survival time of interest is defined as the time (in years) to relapse or death due to the cancer. We plot the Kaplan–Meier survival curve in Figure 1(a) and observe that the survival curve presents a high plateau and levels off at a value substantially greater than 0 after 10 years of follow-up due to a large number of long-term survivors of the cancer. It indicates that the long-term survivors may be considered cured since they are unlikely to relapse or die of the cancer. We also conduct a nonparametric test^ 49 ^ for the existence of long-term survivors and the obtained -value <0.05 shows significant evidence for the existence of cured or long-term survivors. Therefore, it is appropriate to consider a cure model for the data.
(a) The Kaplan–Meier survival curve and its pointwise 95% confidence interval and (b) the logarithm of estimated cumulative hazard functions of survival time distribution from some groups defined by the covariates in the cure model for the breast cancer data.
The 694 patients are from 44 clusters formed by SEER registries. Patients from the same cluster may share a similar lifestyle, a similar socioeconomic status, and a similar healthcare system, and their cure statuses and failure times of uncured patients may tend to be correlated due to the shared environments. Due to the number of clusters in the data, it will not be efficient to consider clusters as a categorical variable in the model. Therefore, the proposed marginal mixture cure model is suitable for analyzing the data to take into account the potential correlation within clusters.
Since we do not have any a priori subject knowledge about which of the baseline covariates should be in which part of the cure model, we consider all of them in both parts. The covariates are denoted and coded as follows: Radiation (a binary covariate with value 1 if a patient received radiation therapy and 0 otherwise), Age (a binary covariate with value 1 if a patient’s age is more than or equal to 50 years old and 0 otherwise), ER (a binary covariate with value 1 if a patient’s ER status is positive and 0 otherwise), PR (a binary covariate with value 1 if a patient’s PR status is positive and 0 otherwise), and LNR (the LNR between 0 and 1).
To examine the suitability of the AFT assumption and the PH assumption in the marginal mixture cure model for the data, following the idea of Zhang and Peng,^ 35 ^ we plot the logarithm of the cumulative hazard functions obtained from the weighted Kaplan–Meier survival estimators for the groups determined by the five covariates considered (LNR is dichotomized at 0.15^ 50 ^). The weight is estimated by in (4) so that the weighted Kaplan–Meier survival estimator can be viewed as an estimator of the distribution of uncured subjects in the groups. If the PH assumption holds for the covariates in the latency part, then the logarithm of the estimated cumulative hazard functions from the groups should be parallel to each other. Figure 1(b) shows the logarithm of the estimated cumulative hazard functions for some groups. It is obvious that many of them are not parallel to each other substantially, indicating that the PH assumption for the uncured patients may not be appropriate. Furthermore, we follow the method of Peng and Taylor^ 51 ^ to calculate the Cramér–von Mises criterion based on the modified Cox–Snell residuals with all the covariates for both the fitted semiparametric PH mixture cure model and the semiparametric AFT mixture cure model by ignoring the clusters (the clusters should have no impact on the effects of covariates in the marginal model) and obtain the corresponding values and , respectively. The smaller value, which indicates a better fit to the data, suggests that the marginal semiparametric AFT mixture cure model is a better choice than the PH-based model for the data.
We fit the proposed model to the data under two working correlation structures: the working independent correlation and the working exchangeable correlation structures. As a comparison, we also fit the data with the AFT mixture cure model using the ZP method. The standard errors of estimates from the models are obtained using 100 bootstrap samples. The results from the models, summarized in Table 7, show some substantial differences. For example, in the latency part, we observe that Radiation is significant ( -value = 0.047) under the proposed method with the working exchangeable correlation structure instead of marginal significant with the working independent correlation structure ( -value = 0.052) and under the ZP method ( -value = 0.093). This finding is perhaps due to the strong correlation ( ) among the survival times of susceptible subjects within clusters revealed by the proposed method with the working exchangeable correlation structure. LNR is significant in both the incidence and the latency from all methods, which indicates that the higher the LNR, the lower the probability of being cured and the earlier events for uncured patients. Both ER and PR are significant in the latency for all methods, which implies that the uncured patients with either positive ER or positive PR tend to have later events. The results in the incidence part from the three methods are generally similar because of the weak correlation ( ) among the cure statuses of subjects within clusters.
Table 7.: Estimated parameters and their SEs from the ZP method and from the proposed marginal semiparametric AFT mixture cure model under the working IND correlation and the working EX correlation structures for the breast cancer data.
Conclusion and discussion
Marginal cure models have been widely used for analyzing multivariate survival data with a cure fraction. However, most efforts have been focused on the marginal PH mixture cure models which may be improper for the applications when the PH assumption is not satisfied for the latency. In this paper, we considered a semiparametric marginal AFT mixture cure model for correlated survival data with a cure proportion. A novel estimation approach is developed based on the GEE in the marginal AFT mixture cure model. We showed that the regression estimators are consistent and asymptotically normal, and employed a bootstrap method to estimate the variances of the estimated parameters. Our work relaxes the independent observations assumption for potentially correlated survival data on the usage of the AFT mixture cure model^ 35 ^ by incorporating working correlation structures in the estimation procedure. The proposed method is also an extension of the marginal AFT model,^ 9 ^ which was proposed for correlated failure time data without a cure fraction.
Our numerical studies show that the proposed method for clustered survival data improves the estimation efficiency of the regression estimators compared with the method in Zhang and Peng,^ 35 ^ especially when the correlation is strong and the cluster size is large. When the prespecified working correlation structure matches the underlying true correlation structure, the empirical variances are in general smaller than those under other working correlation structures. The results from the proposed method are comparable with the results from the method in Zhang and Peng,^ 35 ^ when the correlation strength declines or the cluster size decreases. Hence, the proposed semiparametric marginal AFT mixture cure model provides a new approach for the analysis of correlated lifetime data with a cure proportion, particularly when one is interested in characterizing covariate effects on the failure times of uncured patients directly, and the dependence among the survival times of uncured patients and among the cure statuses can be described by a few unknown parameters. The proposed model and estimation method also facilitate for future development of causal inference for clustered survival data with a cured fraction.
It is worth noting that although the models with random effects or frailties are often considered for clustered data where the random effects/frailties formulate the underlying dependence in a cluster, for clustered survival data with a cure fraction, we are not aware of any existing work based on the AFT assumption. Therefore, as pointed out by one reviewer, considering the AFT mixture cure model with random effects/frailties for clustered survival data should be an important and interesting topic for future research. However, a random effects/frailty model may not always be written as a marginal model unless under special cases such as a linear model with normal random effects. Thus, the estimates from a marginal model are generally not comparable with those from a random effects/frailty model.^ 52 ^
The bootstrap method is employed to estimate the variances of the estimators in the model in all the numerical work reported in this paper. This method is relatively straightforward to implement but can be computationally intensive. Having a computationally efficient method for variance estimation is always preferable to the bootstrap method.^ 53 ^ One interesting work in the future is to explore possibilities to simplify the variance estimation in the proposed method.
The proposed semiparametric estimation method for the marginal AFT mixture cure model was implemented in our R package smgeecure, which is publicly available at http://github.com/yiniu06/smgeecure.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Taylor JMG . Semi-parametric estimation in failure time mixture models. Biometrics 1995; 51: 899–907.7548707 · pubmed ↗
- 2Peng Y Yu B . Cure models: Methods, applications, and implementation. Boca Raton, FL: CRC/Chapman & Hall, 2021.
- 3Amico M Van Keilegom I . Cure models in survival analysis. Annu Rev Stat Appl 2018; 5: 311–342.
- 4Mc Gilchrist C Aisbett C . Regression with frailty in survival analysis. Biometrics 1991; 47: 461–466.1912255 · pubmed ↗
- 5Peng Y Taylor JMG Yu B . A marginal regression model for multivariate failure time data with a surviving fraction. Lifetime Data Anal 2007; 13: 351–369.17641970 10.1007/s 10985-007-9042-4 · doi ↗ · pubmed ↗
- 6Rubio FJ Drikvandi R . MEGH: A parametric class of general hazard models for clustered survival data. Stat Methods Med Res 2022; 31: 1603–1616.35668699 10.1177/09622802221102620 PMC 9315191 · doi ↗ · pubmed ↗
- 7Chiou SH Kang S Yan J . Semiparametric accelerated failure time modeling for clustered failure times from stratified sampling. J Am Stat Assoc 2015; 110: 621–629.
- 8Liang K-Y Zeger SL . Longitudinal data analysis using generalized linear models. Biometrika 1986; 73: 13–22.