Nonparametric Expectile Shortfall Regression for Complex Functional Structure
Mohammed B. Alamari, Fatimah A. Almulhim, Zoulikha Kaid, Ali Laksaci

TL;DR
This paper introduces a new risk management method using a nonparametric expectile-based shortfall estimator for financial time-series data.
Contribution
A novel nonparametric expectile shortfall estimator is proposed with theoretical guarantees and practical implementation.
Findings
The estimator's asymptotic properties are established using functional time-series structures.
The new model shows sensitivity to financial time-series fluctuations and is validated with real and simulated data.
Comparative analysis shows the new shortfall outperforms the standard one in real data applications.
Abstract
This paper treats the problem of risk management through a new conditional expected shortfall function. The new risk metric is defined by the expectile as the shortfall threshold. A nonparametric estimator based on the Nadaraya–Watson approach is constructed. The asymptotic property of the constructed estimator is established using a functional time-series structure. We adopt some concentration inequalities to fit this complex structure and to precisely determine the convergence rate of the estimator. The easy implantation of the new risk metric is shown through real and simulated data. Specifically, we show the feasibility of the new model as a risk tool by examining its sensitivity to the fluctuation in financial time-series data. Finally, a comparative study between the new shortfall and the standard one is conducted using real data.
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
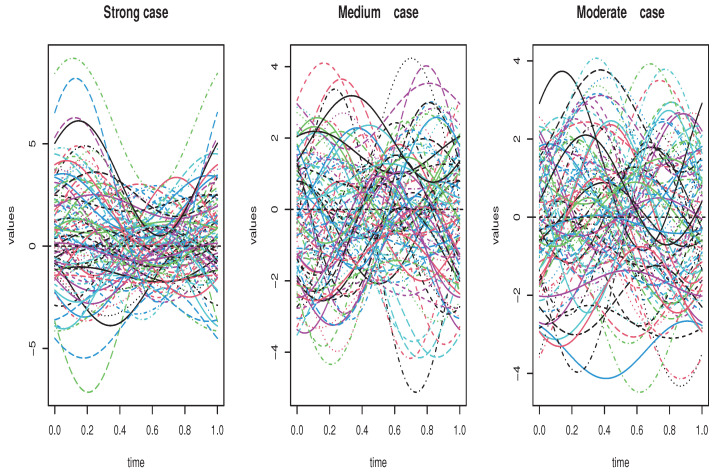 Figure 1
Figure 1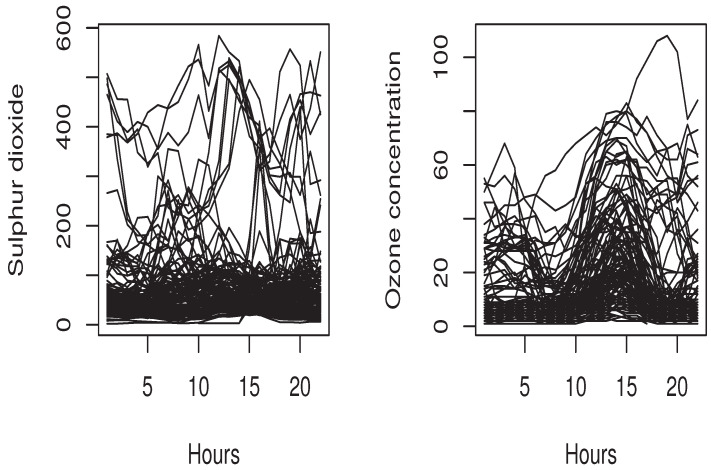 Figure 2
Figure 2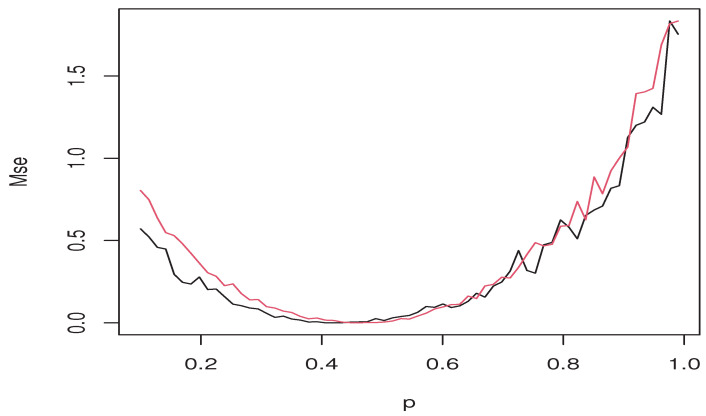 Figure 3
Figure 3- —Princess Nourah bint Abdulrahman University
- —Deanship of Scientific Research and Graduate Studies at King Khalid University
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsFinancial Risk and Volatility Modeling · Statistical Methods and Inference · Stochastic processes and financial applications
1. Introduction
With the huge development and the progress of computer and data science, the statistical modeling of complex and unstructured data is becoming indispensable. In this context, the functional statistics constitutes a good mathematical tool to fit this situation. At this stage, we aim in this contribution to develop a new metric of risk management. More precisely, instead of the standard expected shortfall, we define a new expected shortfall regression (ESR) using the conditional expectile. In fact, the use of the expectile instead of the quantile in the ESR is motivated by the principal feature of the expectile that is very sensitive to the outliers or the extreme risk.
From a historical point of view, the expectile function was introduced by [1]. It constitutes a good alternative to the quantile. In financial time-series analysis, the use of the expectile instead of the VaR function is motivated by its high sensitivity to the outliers, which increase its ability to fit the financial risk. At this stage, the expectile function has gained popularity in risk analysis management. For more motivations on this model in financial risk management, we refer the reader to [2,3,4,5]. Furthermore, the expectile function has been used for other statistical modeling, including the outliers testing (see [6]) or the heteroscedasticity detection (see, for instance, [7,8]). Concerning the use of the expectile in the regression analysis, we cite [9] for the multivariate case and [10] for the functional case. The authors of this last cited work have obtained the asymptotic properties of the nonparametric estimation of the expectile regression with a functional covariate. Alternatively, the functional version of the parametric expectile regression was studied by [11]. They used the reproducing kernel Hilbert space structure to construct their estimator. They obtained the asymptotic upper and lower bounds of the convergence rate. In parallel, the shortfall function was introduced by [12]. The use of this risk metric in financial time-series data is motivated by its coherency property. We return to [12] for a comparative study between the Value at Risk (VaR) and expected shortfall model (ES) in financial time-series analysis. The authors of this cited paper have proved that the VaR is unusable when the profit–loss is not Gaussian. From an analytical point of view, the estimation of the ES model can be performed by multiple ways including parametric, semi, or nonparametric algorithms. The parametric approaches were used by [13,14,15]. Meanwhile, the first results in the nonparametric techniques were obtained by [16]. He used the kernel method to construct an estimator of the ES-model. Ref. [17] established the asymptotic distribution of the kernel estimator of the ES model. Using the Bahadur representation, the authors of [18] have constructed an alternative estimator of the ES-model. Ref. [19] has studied the functional version of the Nadaraya–Watson estimator of the conditional ES model (CESM) under the mixing assumption. They proved that the constructed estimator almost completely converges. Alternative functional time-series data were developed by [20]. In particular, they obtained the almost complete consistency of the kernel estimator of the CESM under the quasi-associated dependency. While in all the previous cited work, the expected loss of the shortfall is defined by the VaR level, in this paper, we introduce an alternative risk threshold that is the expectile regression.
As mentioned below, the main aim of the present contribution is to develop a new risk metric based on the expectile regression. Specifically, we define the expected shortfall with respect to the tail expectile. Such a new risk metric accumulates the advantages for two functions. Indeed, it is well known that the expectile is an elicitable and coherent risk metric. Moreover, it is very sensitive to the magnitude of the lower tail, unlike the VaR, which is not influenced by the outliers. In parallel, the ES model fulfills the condition of spectral risk measures (see [21]). Thus, the ES model based on a tail expectile improves significantly the risk management. The particularity of the present contribution is the treatment of this model using the functional time-series structure. Thus, the principal achievement of this paper is the construction of a computational kernel estimator and the study of its asymptotic property using the mixing assumption. It should be noted that the functional time-series case is more realistic than the independent functional data. The practical implementation of this risk metric has been evaluated using artificial and real data. To the best of our knowledge, no attempt has been made so far to estimate the functional EES regression based on the tail expectile. We may refer to [22,23,24,25,26,27] for more recent advances in ftsa.
The paper is organized as follows. We present our risk metric as well as its estimator in Section 2. Section 3 is dedicated to introducing the functional time-series framework. The almost complete convergence of the constructed estimator is shown in Section 4. Section 5 is devoted to discussing some of the computation ability of the estimator over artificial and areal data applications. Finally, the proofs of the auxiliary results are given in the Section 6.
2. Model and Estimator
Let be n pairs of random pairs in which are identically distributed as . Moreover, we suppose that the regular version of the conditional distribution of Y given X exists. The standard ES regression is defined through the tail-quantile as
where is the quantile regression of order . So, alternatively to this tail quantile, we introduce the ES regression using the tail expectation, which is defined as
where is the expectile regression. The latter is defined by
where is the indicator function of the set A.
It worth noting that the replacement of by permits remedying the lack of risk insensitivity of to the extreme values. This characteristic is very important in practice because the catastrophic losses are located at the extreme values.
Now, for the estimation step, we assume that F is a known measurable function and is a positive sequence of real numbers tending to zero as n tends to infinity. Next, the estimation procedure involves two steps. In the first step, we start by estimating the expectile regression . The latter is estimated by , as a kernel estimator of defined as the root of
with
where
The second step is the estimation of the ES regression. Naturally, the ES regression is estimated by
The main purpose of the theoretical section of this work is to establish the almost complete consistency of the estimator to using strong functional time-series data. For the reader not familiar with this aspect of functional time-series data analysis, we devote the rest of this section to recalling the definition of the strong mixing assumption property, which requires the introduction of the following notations. Firstly, we consider to be a strictly stationary sequence of random variables, and we denote by the algebra generated by Secondly, for a positive integer n, we define
So, the sequence is said to be -mixing (strong mixing) if the mixing coefficient as It is well documented that this condition is verified by many processes including the usual ARMA processes (with innovations satisfying some existing moment conditions) (see [28]), the EXPAR models (see [29]), the ARCH models (see [30]), and the GARCH model (see [31]), among others.
3. Main Asymptotic Result
Before stating the asymptotic properties of the estimator , we need to introduce some notations and assumptions. Firstly, we set by or some strictly positive generic constants, is a given neighborhood of , and, for all , we define . Now, to formulate our main results, we will use the hypotheses listed below:
- (P1) where .
- (P2) , ,
- (P3)The sequence is a strong mixing process that has a coefficient and satisfies and
- (P4) is a function with support such that
- (P5)There exists a sequence of positive real numbers and such that
where
- Comments on the hypotheses.
All these conditions are standards in FTSA. In particular, condition (P1) is checked for several continuous time processes. We refer to [32] for a general Gaussian process viewed as functional space in . This condition relates the functional structure of the data to the probablity measure of the random variable, measuring the concentration of the probability measure of X over a topological ball constructed from the semimetric d. At this stage, the function is affected by two principal factors that are the probability measure and the semimetric d. Such assumption can be viewed as generalization for the multivariate case ( ) when where is the density of X. In this situation, the function is positive as long as the density is structurally positive. A mild regularity condition (P2) is assumed for the distribution function. Such a condition allows for characterizing the nonparametric path of the studied model. (P2) is used to evalaute the bias term of the estimator. Condition (P3) defines the mixing structure of our FTSA framework. The first part of this condition allows for obtaining a convergence rate comprable to the independent case. In conclusion, we can say that the assumed conditions (P1)–(P4) are sufficiently weak to obtain an improved convergence rate, which is comparable to the ideal situation that is the independent case. Of course, these assumptions can be reduced if we are interested in only the convergence estimator without a convergence rate.
Now, we state the following results.
Theorem 1. Under the suppositions (P1)–(P5), we have
Proof of Theorem 1For , we define
So,
Then,
Thusly,
So, Theorem 1 comes from
and
The result (4) is proved in [10]. So, we concentrate only on (3). Indeed, as , we have, for ,
The proof is carried out through Lemmas 1–3. □
Lemma 1. Under the suppositions (P1) and (P3)–(P5), we have
Moreover,
Lemma 2. Under the suppositions (P1)–(P2) and (P4)–(P5), we have
Lemma 3. Under the suppositions (P1)–(P5), we have
4. Empirical Analysis
This section is devoted to examining the practical use of the model studied in this work. This section is divided into three sections. In the first subsection, we discuss the selection of the smoothing parameter, which is the pivotal parameter in our estimation. For this reason, the choice of this parameter is primordial for the computational aspect. After the smoothing parameter selection, we examine the usefulness of the estimator. This practical study is conducted using two examples. The first one concerns artificial data, and the second one treats financial real data coming from some popular index markets according to the Dow–Jones index.
4.1. Smoothing Parameter Selection: Cross-Validation
As mentioned above, the choice of the smoothing parameter r is crucial in this nonparametric framework. Now, as our estimation procedure is based on the expectile regression, the appropriate cross-validation (CV) rule is the mean squared error. The latter is usual in nonparametric functional data:
This rule is motivated by the fact that the conditional mean is associated with with . The popularity of this approach comes from its easy implementation. However, we can employ a more accurate rule that is a generalization of (5). It is explicitly expressed by
where is the scoring function defining . The main advantage of this last rule is its dependence on the threshold p. Of course, it is very beneficial in this area of financial risk analysis. Indeed, in risk analysis, we are interested in the tail which corresponds to small or large values of p. Observe that the challenging issue in expected shortfall is the absence of the scoring function or backtesting measure. Thus, the use of the optimal smoothing parameter associated with the expectile regression is more adequate for the model . Moreover, this choice reduces the time cost of the companionability of the ES expectile regression.
4.2. Artificial Data
In this empirical analysis, we aim to examine the applicability of the constructed estimator as well as its behavior for a finite sample. Clearly, the particularity of this work is the treatment of the dependency case. For this aim, we compare the behavior of the estimator over different levels of dependency. Now, for this purpose, we generate artificial data from the functional autoregressive sampling processes. It is well documented that this kind of process has a strong mixing property and allows controlling the effects of this property on the efficiency of the constructed estimator. We point out that the functional autoregressive process is generated using the R-package version 4.3.1 freqdom.fda through the routine code fts.rar. We point out that this routine code use of the dynamic functional principal component analysis (see [33]) permits simulating the p-order functional autoregressive process using the finite dimensional subspace spanned by given basis functions, such as Fourier basis or spline basis. In this artificial study, we employ this routine code to generate a functional autoregressive process of order . Furthermore, the functional regressors are generated as
where is a kernel operator with kernel and is a white noise random variable. So, under this consideration, the functional covariate is
In practice, the kernel operator is associated with the matrix . Thus, the dependency level is measured by the values of the coefficients . In this empirical analysis, we put . Moreover, in the routine code fts.rar, the operator should be scaled with respect to its Hilbert–Schmidt norms. The parameter of normalization is so-called op.norms. Thus, the dependency degree increases with the value of op.norms. In this sense, the great value of op.norms implies strong dependency and vice versa. So, in order to examine the effect of the dependency on the estimation quality, we generate three levels of dependencies (strong, medium and moderate correlation). Specifically, the strong dependency is obtained by assuming op.norms = 0.999, while the moderate and the medium cases are, respectively, associated with op.norms = 0.48 and op.norms = 0.01. In Figure 1, we plotted the generated samples of different functional regressors.
Next, the response variable is generated using nonparametric regression formula
where is independent of , representing the so-called white noise. Obviously, the conditional distribution is related to the distribution of the random variable . Thus, to cover different situations, we consider two types of white noise distributions. The first one is normal, which is light-tailed distribution. The second one is Lévy distribution, which is heavy-tailed distribution. We point out that there are several definitions of these notions of light or heavy-tailed distribution. However, the most common index to identify the heavy-tailed distribution is the variance, which should be infinite. Thus, the Lévy distribution is certainly heavy-tailed distribution and has many applications in financial time-series analysis (see [34]). Furthermore, the choice of this distribution is also motivated by the its stability with the linear transformation. If U has a standard Lévy distribution , is . For this reason, in both situations (normal or Lévy distribution), the true conditional expected shortfall can be explicitly defined by shifting the distribution of the white noise. In order to highlight the importance of in practice, we compare it to the VaR-based expected shortfall, which is estimated by
Of course, the performance of is strongly linked to the estimation of the function . Thus, in order to provide a more comprehensive comparison with , we calculate with two alternative approaches:
and
where
and . Furthermore, we denote by the estimator associated with the kernel estimator , while denotes the estimator associated with the local linear approach.
Clearly, the applicability of all these estimators , and rests on the easy selection of different parameters defining these estimators. At this stage, we choose the bandwidth parameters r, the semi-metric d and the kernel according to the principal assumptions. For this empirical analysis, we select the optimal bandwidth by the mean square cross-validation rule. The optimization method is performed over a discrete set defined by the -distance from the location point where k is an integer number that belongs in . For the kernel , we choose the -kernel on , which is adequate with this kind of nonparametric approach. We point out that this kernel incorporates the technical assumption (P4). On the other hand, the metric choice is closely related to the nature of the functional variable and its smoothing property. It appears that the PCA metric is more suitable for this type of discontinuous functional regressor.
Finally, the performance of both estimators is evaluated by computing
where (resp. ) means either expectile-based shortfall or VaR-based (respectively, expectile or VaR).
So, for this comparative study, we report estimation error in different situations (degrees of dependency, types of conditional distribution (heavy-tailed and light-tailed)). The results are reported in Table 1.
It is clear that the efficiency of the three estimators is strongly affected by the different axes of this study such as the dependency degree, the nature of the model, as well as the conditional distribution case. In particular, the performance of the three estimators decreases with the level of dependency. On the other hand, it appears clearly that the type of the conditional distribution affects also the behavior of the three estimators. However, it appears that this sensitivity is not very important for the VaR-based expected shortfall and , since the variability of and is small compared to the . This conclusion confirms the high sensitivity of the expectile to the extreme values, which is very beneficial for risk management.
4.3. Real Data Application
This section is devoted to the applicability of our model in real time-series data. Specifically, we compare the efficiency of the new ES expectile model to the standard one using environmental time-series data. Although the financial time-series data are the main area where one can use the ES model, the environmental area is also an interesting applied domain of risk management. In fact, the air quality has a important impact on the quality of life. In particular, it is well known that exposures to ground ozone for a period of more than 8 h impact the pulmonary functions as well as the tissues of the respiratory tract. Therefore, it is very important to control the excessive level of ozone concentration. In this context, the theory of the extreme values has been employed to fit this issue. We cite, for instance, [35] and the references therein that use some financial tools to model the risk of air quality. We point out that the standard expected shortfall model is based on the quantiles function, which can be viewed as tail probabilities, while the expectile is tail expectation. The definition of the quantile measures only the frequency of the risk, but the expectile measures the risk frequency and its severity. For this reason, the expectile seems more informative since it has a high sensitivity to the extreme values, which is very beneficial in risk analysis. It permits better detection of the risk of excessive levels of ozone concentration. In this real data analysis, we use the air quality data of the website https://dataverse.harvard.edu/dataverse/beijing-air (accessed on 20 April 2024). It concerns the air quality in Beijing in the northeast of the Chinese country. We focus on two important indices of air quality: sulfur dioxide (SO_2_) and the ozone concentration (O_3_). Recall that (SO_2_) and the ultraviolet rays have a great impact on the stratospheric ozone. So, the functional sample is defined as , the -daily curve of SO_2_, and by , the total ozone measured on the -day. The sulfur dioxide and the ozone concentration curves are shown in Figure 2.
As discussed below, the principal aim of this real data analysis is to compare the ES expectile regression and the expected shortfall based on the quantile regression, which is defined by
where F is the conditional cumulative function of Y given . We point out that the conditional cumulative distribution function is estimated by
Then, the Value-at-Risk function is defined
Thus, the kernel estimator of the standard expected shortfall regression is
where and So, our aim is to compare the and using real data . Both estimators are calculated using the same techniques as the empirical analysis section. Specifically, we execute the estimators by the same kernel, select the smoothing parameters by the rule (5), and employ the metric obtained by the PCA metric. We return to Ferraty and Vieu [36] for more details on the mathematical formulation of these metrics. The performance of both estimators is evaluated by computing
where represents and . Such an error is evaluated as a function of p. In Figure 3, we show the values of of both estimators and (red line).
The graphs show the superiority of the ES expectile regression over the ES quantile model. In several cases, the black line is under the red line. This superiority is confirmed by reporting the Mse of some p. The values of this are given in the following Table 2.
It appears that the ES expectile is more accurate for various values of p, giving greater precedence as a risk metric.
5. Conclusions and Prospects
In this work, we have investigated the free-parameter estimation of the regression of the ES expectile. We have constructed an estimator by the kernel-smoothing approach. This contribution covers the functional time-series case. The theoretical part of this work focuses on the establishment of the convergence in Borell–Contelli in pointwise performance under strong mixing assumptions. This theoretical devolvement constitutes good mathematical support for the use of the new risk metric in risk management. Moreover, the obtained asymptotic results were established under standard conditions and with the precision of the convergence rate. In practice, the applicability of the estimator is very easy and gives better results compared to the standard one. Specifically, we applied the new model for environmental time-series data. The result confirms the superiority of the ES expectile over the ES quantile. This superiority is confirmed in two directions: The first one is the fact that the ES expectile has a small error compared to the ES quantile. The second one is the variability of the error in the ES expectile, which proves its high sensitivity to outliers. This feature is very important in risk analysis, because the risk is often located in the extreme values. Therefore, the robustness of the qunatile is not beneficial in this kind of area. For this reason, the ES expectile is more adequate than the ES quantile. The importance of our contribution can be viewed, also, through the numerous opens questions for the future. For instance, we will treat more dependent cases such as the quasi-associated case or the spatial case. Let us point out that the mixing assumption is very difficult to handle in practice. Thus, this condition can be considered as the principal practical limitation of the present contribution. For this reason, treating other type correlations is very important in practice. It allows for controlling alternative financial time-series data that are not difficult to handle in practice. In addition, the determination of the uniform UNN convergence of the estimator is also a very important prospect in the future. It permits resolving the problem of the smoothing parameter selection. Furthermore, we can also estimate the model using the additive or the linear case.
6. The Demonstration of Asymptotic Results
This section is devoted to the proofs of our results. To do that, we start by recalling the principal inequalities used to prove the intermediate lemmas:
Lemma 4([36]). Let be an α-mixing process. For , consider two random variables and measurable on and , respectively:
- (1) If and are bounded, then
- (2) If there exist three positive integers p, q and r, such that and and , then
Lemma 5([36]). Let be an algebraic α-mixing process, which is identically distributed:
- (1) If there exist and such that for all , then for all , and
- (2) If there exist such that , then for all and :
where .
Proof of Lemma **1.**We put
We use the Fuck–Nagaev inequality (Lemma 5) to obtain and ,
with
where
and
Now, we must determine the asymptotic term of . For this, we apply the technique of [37] So, we define
and
with Denote by and the covariance sum over and , respectively. Then,
Because of (P1), (P3) and (P5), we can write
Now, the covariance over , can be treated using Davydov–Rio’s inequality (see Lemma 4). Thus, for all , to
Therefore, using we obtain
Choosing , we obtain
Now, the variance part is
Finally, as ,
Therefore, and . Thus,
Next, from (P5),
So, such that
By (9),
Since , we obtain
Thus, for large ,
In conclusion, for large ,
Moreover,
□
Proof of Lemma **2.**Using
Condition (P2) gives
So,
allowing
□
Proof of Lemma **3.**Since then by the compactness feature we obtain
for and . The two functions and are increasing. Thus, for ,
Now, by (P2) we obtain
we have
Hence,
Clearly
Therefore, it suffices to demonstrate that
Then, ,
It remains to assess
Indeed,
We write
Because Y is not necessarily bounded, we use the truncation method by introducing
with . Thus, the result is a consequence of the intermediate results
and
We start by proving (15): We have, ∀
By the Holder inequality, for and such that , and
Thus,
Finally, (15) is consequence of (P5).Now, for (16), we use Markov’s inequality to show that ,
Choosing ,
Now, we prove (17). Define ,
Therefore, ∀
We calculate
We define
and
Let and be the sum of covariance over these two sets, respectively. On , we have
Because of (P1), (P3) and (P5), we have
By Davydov-Rio’s inequality (see, Lemma 4) in the cases we have
Hence,
Choosing , we prove that
On the other hand,
Thus,
Fuck–Nagaev’s inequality (see Lemma 5) over implies that ∀ and ,
where
Taking and , we obtain
for some . Similarly to (11), we prove for that
Then, (19) and (20) permit concluding. Therefore, for ,
□
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Newey W.K. Powell J.L. Asymmetric least squares estimation and testing Econom. J. Econom. Soc.19875581984710.2307/1911031 · doi ↗
- 2Waltrup L.S. Sobotka F. Kneib T. Kauermann G. Expectile and quantile regression—David and Goliath Stat. Model.20151543345610.1177/1471082 X 14561155 · doi ↗
- 3Bellini F. Di Bernardino E. Risk management with expectiles Eur. J. Financ.20172348750610.1080/1351847 X.2015.1052150 · doi ↗
- 4Bellini F. Negri I. Pyatkova M. Backtesting Va R and expectiles with realized scores Stat. Methods Appl.20192811914210.1007/s 10260-018-00434-w · doi ↗
- 5Farooq M. Steinwart I. Learning rates for kernel-based expectile regression Mach. Learn.201910820322710.1007/s 10994-018-5762-9 · doi ↗
- 6Chakroborty S. Iyer R. Trindade A.A. On the use of the M-quantiles for outlier detection in multivariate dataar Xiv 20242401.01628
- 7Gu Y. Zou H. High-dimensional generalizations of asymmetric least squares regression and their applications Ann. Stat.2016442661269410.1214/15-AOS 1431 · doi ↗
- 8Zhao J. Chen Y. Zhang Y. Expectile regression for analyzing heteroscedasticity in high dimension Stat. Probab. Lett.201813730431110.1016/j.spl.2018.02.006 · doi ↗