Building a benchmark dataset for the Kurdish news question answering
Ari M. Saeed

TL;DR
The paper introduces a new Kurdish news question-answering dataset with 15,002 news paragraphs and manually created question-answer pairs.
Contribution
The KNQAD dataset is novel for Kurdish language QA tasks and includes lexical analysis of question-answer complexity.
Findings
The dataset includes question-answer pairs across multiple news domains like social, religion, and science.
Lexical similarity analysis reveals the complexity of question-answer pairs in the dataset.
The dataset is cleaned and normalized using stemming and stop word removal.
Abstract
This article presents the Kurdish News Question Answering Dataset (KNQAD). The texts are collected from various Kurdish news websites. The ParsHub software is used to extract data from different fields of news, such as social news, religion, sports, science, and economy. The dataset consists of 15,002 news paragraphs with question-answer pairs. For each news paragraph, one or more question-answer pairs are manually created based on the content of the paragraphs. The dataset is pre-processed by cleaning and normalizing the data. During the cleaning process, special characters and stop words are removed, and stemming is used as a normalization step. The distribution of each question type is presented in the KNQAD. Moreover, the complexity of the QA problem is analyzed in the KNQAD by using lexical similarity techniques between questions and answers.
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
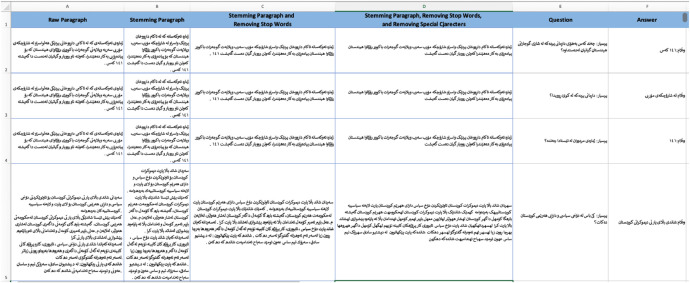 Figure 1
Figure 1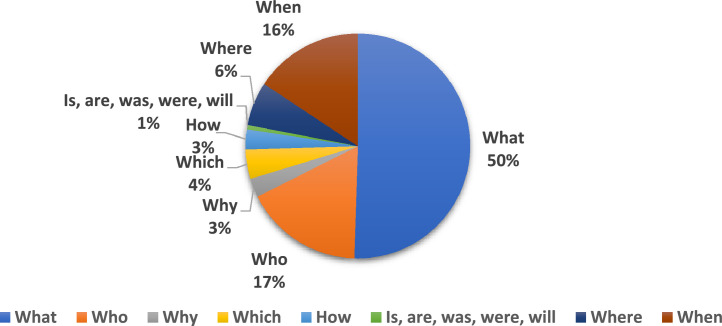 Figure 2
Figure 2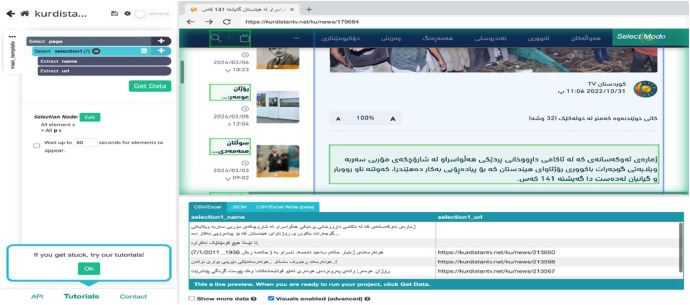 Figure 3
Figure 3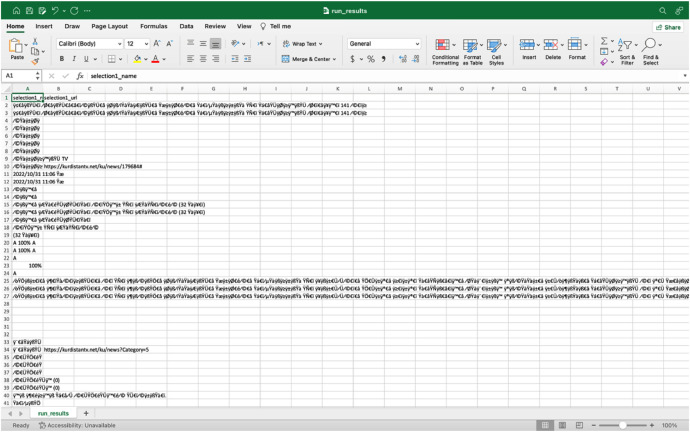 Figure 4
Figure 4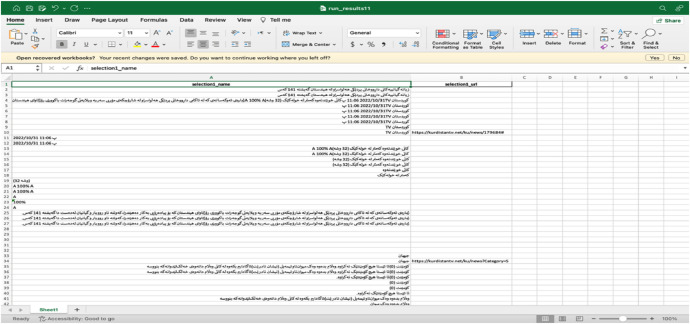 Figure 5
Figure 5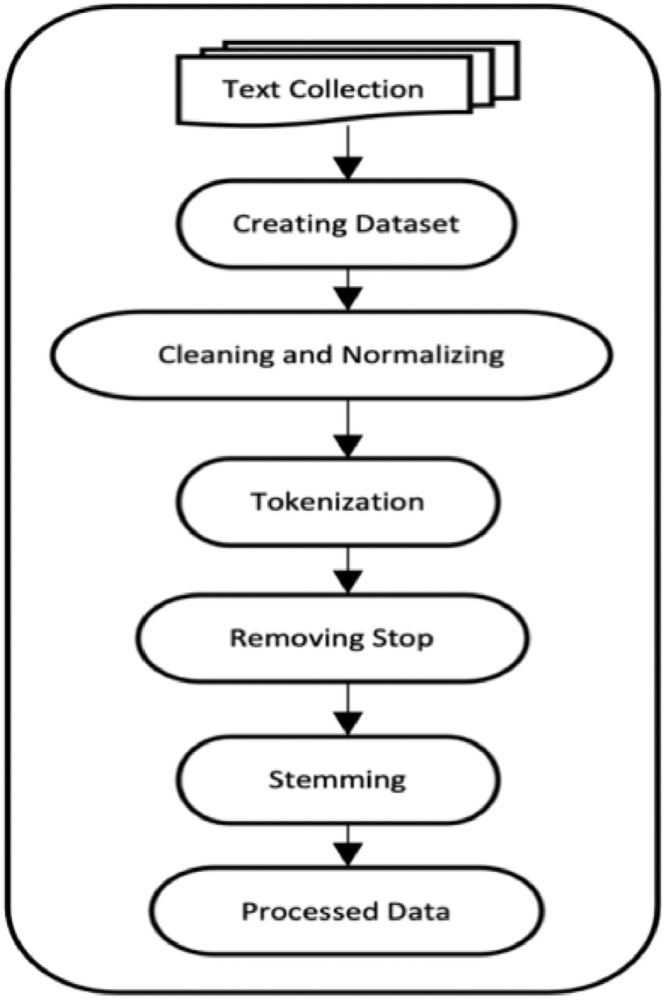 Figure 6
Figure 6Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsTopic Modeling · Natural Language Processing Techniques · Advanced Text Analysis Techniques