Optimization of indirect wastewater characterization using led spectrophotometry: a comparative analysis of regression, scaling, and dimensionality reduction methods
Daniel Carreres-Prieto, Enrique Fernandez-Blanco, Daniel Rivero, Juan R. Rabuñal, Jose Anta, Juan T. García

TL;DR
This paper compares methods to optimize wastewater pollutant analysis using LED spectrophotometry, finding the best combination of data processing techniques.
Contribution
The study introduces a systematic comparison of 84 data processing pipelines for wastewater characterization using LED spectrophotometry.
Findings
Normalization followed by PCA and Random Forest Regressor provided the best performance for predicting COD and TSS.
Eighty-four pipelines were tested using 7 regression techniques, 3 scaling methods, and 4 dimensionality reductions.
Cross-validation on 15 sub-datasets showed the importance of data preprocessing in LED spectrophotometry for wastewater analysis.
Abstract
LED spectrophotometry is a robust technique for the indirect characterization of wastewater pollutant load through correlation modeling. To tackle this issue, a dataset with 1300 samples was collected, from both raw and treated wastewater from 45 wastewater treatment plants in Spain and Chile collected over 4 years. The type of regressor, scaling, and dimensionality reduction technique and nature of the data play crucial roles in the performance of the processing pipeline. Eighty-four pipelines were tested through exhaustive experimentation resulting from the combination of 7 regression techniques, 3 scaling methods, and 4 possible dimensional reductions. Those combinations were tested on the prediction of chemical oxygen demand (COD) and total suspended solids (TSS). Each pipeline underwent a tenfold cross-validation on 15 sub-datasets derived from the original dataset, accounting for…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
 Figure 1
Figure 1 Figure 2
Figure 2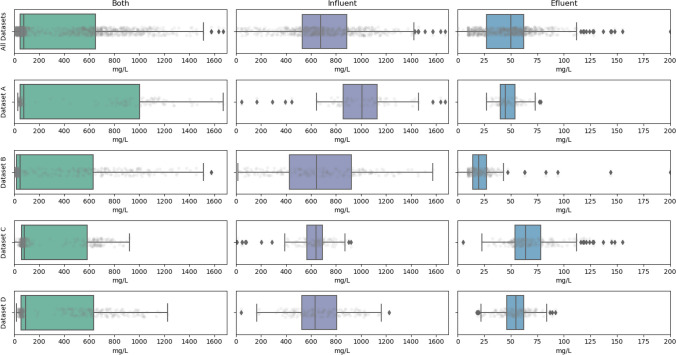 Figure 3
Figure 3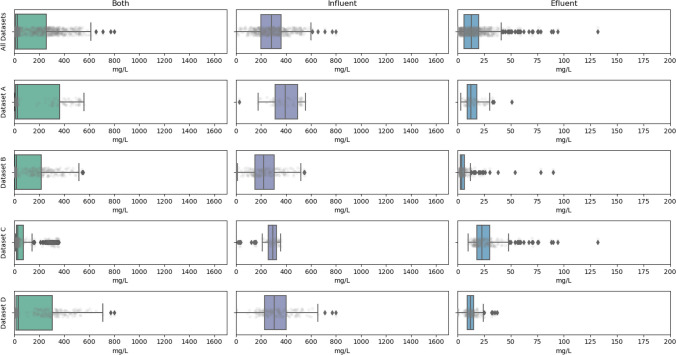 Figure 4
Figure 4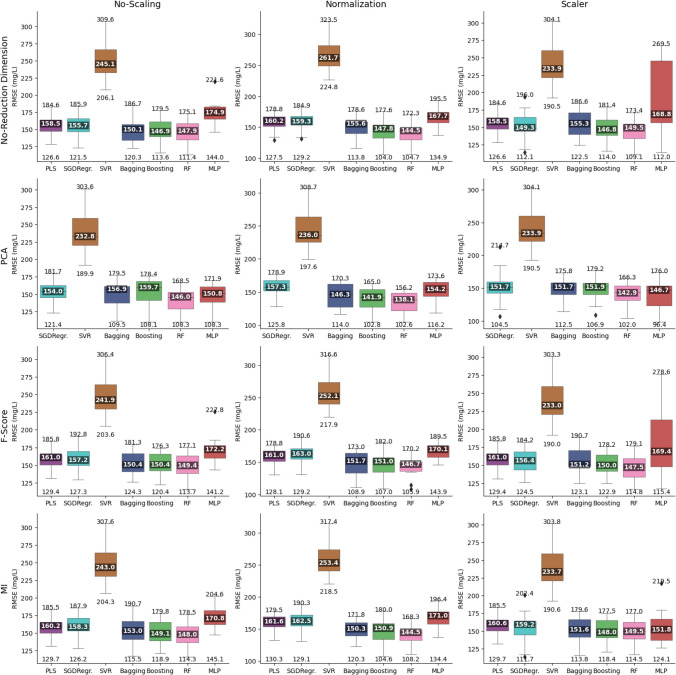 Figure 5
Figure 5 Figure 6
Figure 6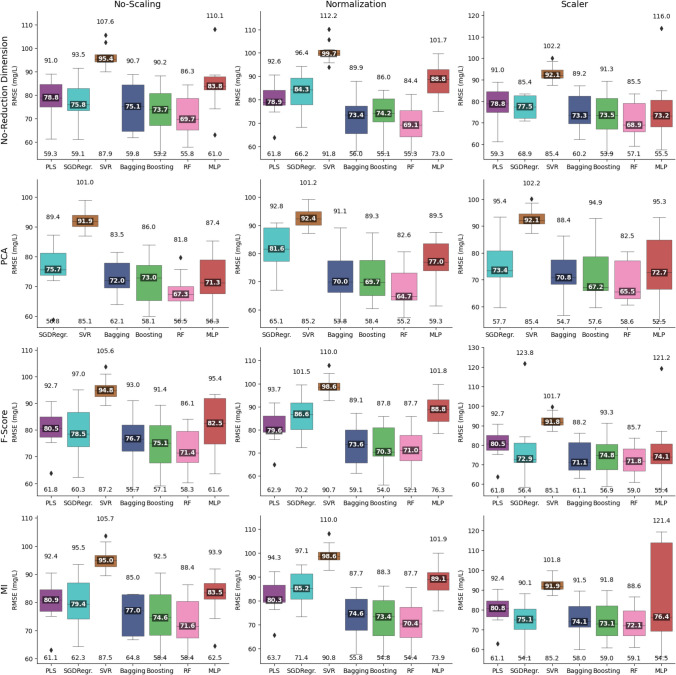 Figure 7
Figure 7 Figure 8
Figure 8- —http://dx.doi.org/10.13039/100014440Ministerio de Ciencia, Innovación y Universidades
- —http://dx.doi.org/10.13039/501100010801Xunta de Galicia
- —Universidad Politécnica de Cartagena
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsWater Quality Monitoring and Analysis · Spectroscopy and Chemometric Analyses · Water Quality Monitoring Technologies
Introduction
Effective water quality monitoring is essential for resource management and environmental protection (Sun et al. 2023 and Shao et al. 2021). Over the past decade, molecular spectrophotometry has emerged as a dependable method for indirectly characterizing pollutants in wastewater. Through this technique, real-time and online monitoring of the entire wastewater network has become feasible. Numerous contributions have provided proof on this topic (Altmann et al. 2016; Lepot et al. 2016; Mesquita et al. 2017; Korshin et al. 2018, Brito et al. 2014, Feng et al. 2018, and Cheng et al. 2022 or Song et al. 2021), reporting the effectiveness of molecular spectrophotometry in identifying and quantifying pollutants in wastewater.
The physicochemical properties of wastewater significantly influence its spectral response, allowing the detection of parameters such as chemical oxygen demand (COD), total suspended solids (TSS), and total nitrogen (TN), among others (Ferree and Shannon 2001; Rieger et al. 2004; Korshin et al. 2018; and Carreres-Prieto et al. 2023a). This is because the chemical and molecular composition of the wastewater directly affects the interaction of light with the sample.
Light absorption and scattering vary according to the dissolved and suspended compounds in the water (Lourenço, et al. 2010); their organic, inorganic, and biological characteristics determine specific absorption and scattering patterns. In addition, interactions within the aqueous matrix, such as the formation of molecular complexes or changes in the molecular structure due to the presence of various ions and materials, modify the optical behavior of contaminants. Interactions between different dissolved molecules can change the optical properties of the solution, while oxidation or reduction processes alter the oxidation state of certain contaminants, which affects their light absorption. These factors create a unique spectral profile for each wastewater sample, allowing the development of accurate and robust predictive models for efficient wastewater management.
This indirect characterization is carried out using correlation models, where research works such as Lepot et al. (2016), Torres (2008), Piro et al. (2012), Qin et al. (2012), or Carreres-Prieto et al. (2023b) have verified the adequacy of these characterization models.
However, the performance of a model is determined by several factors, such as the preprocessing and/or scaling applied to the data or the regression technique employed. Additionally, the nature of the spectral data itself can have a major impact depending on the wastewater matrix or the geographical area where they have been taken from population, presence and type of industrial activity, and purification conditions, among others.
Therefore, this work proposes an in-depth study of this issue considering two objective pollutants, COD and TSS, registered in about 1300 wastewater samples from 45 WWTPs collected over 4 years. The gathered data corresponding with the spectrum recorded from the visible field (380–700 nm) was used to determine which pipeline composed of regressor, scaling, and dimensionality reduction techniques is the most appropriate to tackle the characterization of the pollutant load in the wastewater. This characterization was carried out regardless of the type of water to be studied (raw wastewater, treated wastewater, or a combination of both), as well as the area or WWTP to which it belongs and for each particular case of WWTP and type of water.
In this study, not only did we seek to demonstrate the suitability of LED spectrophotometry as an indirect water analysis technique, but a comprehensive approach was adopted by testing a wide range of preprocessing and dimensionality reduction techniques, along with various regression algorithms. The objective was to evaluate all possible combinations of these methodologies in different scenarios to determine which one optimized performance by minimizing the root mean square error (RMSE). In order that the evaluation was agnostic of the data used for the test, it was made following a cross-validation schema. This evaluation has been carried out for both the overall set of all water and treatment plants as well as individually for each one.
LED spectrophotometry has proven to be a suitable analytical technique to carry out studies on the properties of both drinking water, as demonstrated by works such as Bridgeman et al. (2015) or Prairie et al. 2020, and wastewater (Place 2019 or Carreres-Prieto et al. 2023a, 2023b). The main novelty of the present work lies in the exhaustive development and evaluation of a spectral data analysis pipeline including modeling, scaling, and dimension reduction steps for more than 1300 sample datasets with different wastewater matrices.
The relevance of this study is based on its ability to significantly improve wastewater management in terms of COD and TSS levels. By identifying the most effective combinations of scaling, dimensionality reduction, and regression techniques, this work will provide a solid foundation for accurate spectral analysis of wastewater. This is crucial as accurate pollutant characterization is critical for the design and optimization of more effective and sustainable water treatment strategies (Orhon et al. 1997; Rosal et al. 2010; Saravanan et al. 2021; Muralikrishna and Manickam 2017). Moreover, the findings of this research will have a direct impact on environmental protection and public health by enabling more accurate and reliable water quality monitoring.
The current study presents an advanced methodology in wastewater treatment modeling, based on the analysis of an extensive collection of data collected from a large number of WWTPs from different locations, with wastewater samples of differing compositions, obtained over several years, thus reflecting the temporal variation of the pollutant load and its diversity depending on the type of water and location it originates from. Additionally, a large number of techniques and combinations were used to carry out the study. The inclusion of a wide range of data, including statistical outliers, has enabled the development of high-performance predictive models, characterized by their robustness and applicability under various conditions. This innovative approach overcomes the limitations of previous studies, offering generalizable models with low error levels, which can cope with real operating conditions, thereby representing a significant step towards the optimization of WWTPs.
The rest of the manuscript is organized as follows:
“Materials and methods” section details the experimental campaign carried out, describes the regression, scaling, and dimensionality reduction techniques, and presents an outline of the work carried out.
“Results and discussion” section shows, for both COD and TSS, the analyses carried out for each of the water types and WWTPs, both individually and jointly, to determine, respectively, which type of regressor, scaling, and dimensionality reduction technique is the most appropriate to apply to achieve the best models for characterizing the pollutant load of wastewater, regardless of the type of wastewater and WWTP that they come from.
Finally, “Conclusions” section outlines the main conclusions reached in this research work.
Materials and methods
Experimental campaign
For the present study, 1300 wastewater samples, both raw and after a secondary treatment, were collected over 4 years from 45 WWTPs located in northwestern and southeastern Spain and in Chile, to contribute to the treatment objectives defined in directive 91/271 EEC concerning urban wastewater treatment. These samples represent a 24-h integration and were analyzed using LED spectrophotometry equipment (Carreres-Prieto et al. 2019) operating in the 380–700 nm range (Fig. 1), in order to obtain the spectral response, without employing filtering or chemical reagents, and additionally the analysis of laboratory water properties, to obtain COD and TSS levels and then generate correlation models for indirect characterization. The choice of COD and TSS as key variables in this study is based on their ability to provide a comprehensive assessment of the pollutant load in wastewater. COD is a critical indicator of the amount of organic matter present, providing a direct measure of the potential pollutant that can adversely affect water quality and aquatic life. On the other hand, TSS is essential for determining water clarity and the presence of suspended particles that can carry pathogens, heavy metals, and nutrients, exacerbating eutrophication problems and affecting treatment processes.Fig. 1LED spectrophotometry equipment used (Carreres-Prieto et al. 2019)
This research work used, on the one hand, the results of the spectral analysis of the samples using LED technology in the 380–700 nm range, which produced a total of 81 transmittance values and 81 absorbance values per sample, and on the other hand, the analytical values measured in the laboratory in terms of COD and TSS concentration of the water, so as to generate models that, from the spectral response, can determine the concentration of these pollutants in a simple, fast, and accurate way without the need to alter the samples or use chemical reagents. To carry out this study, a low-cost spectrophotometry equipment developed by the authors of this manuscript (Carreres-Prieto et al. 2019), which operates with LED technology, was used. This equipment, shown in Fig. 1A, can perform multispectral analysis in the mentioned range, with an accuracy comparable to that of commercial equipment based on incandescent lamps.
The LED spectrophotometer, illustrated in Fig. 1B, consists of a disc where 5 mm diameter LEDs are aligned with the sample to be analyzed. The sample is inserted through the top using a standard spectrophotometric test tube with a volume of 2.7 ml. This configuration has made it possible to achieve a working range between 380 and 700 nm using only 33 LEDs covering different areas of the visible spectrum. The choice of LED technology for this spectrophotometer is based on several significant advantages over conventional equipment based on UV–vis lamps. These advantages include low energy consumption, zero heat generation, low cost, and the ability to be used immediately, since, unlike incandescent lamps, they reach their nominal speed almost instantaneously, which translates into shorter analysis times and no heating problems, to which must be added the possibility of miniaturization, which makes LED technology an attractive option for the development of more efficient and versatile spectrophotometry equipment.
The samples were organized into four datasets, each one grouped together samples related to a specific geographic area and/or set of specific WWTPs; Table 7 of Appendix shows information on the different WWTPs that comprise it, as well as their main characteristics. Likewise, to carry out a study with a greater variety of samples from different WWTPs, a dataset called “All Datasets” was generated, which brought the four previous datasets together. In turn, each of the datasets was divided, according to the type of wastewater, into only samples of raw wastewater (Influent); only samples of treated wastewater (Effluent); and a combination of both (Both), in order to analyze the performance of the regressors, scaling and dimensionality reduction technique for each of the types of water, giving rise to a total of 15 sub-datasets.
Tables 1 and 2 show the different datasets used in this research work to generate the different correlation models for COD and TSS, respectively, as well as the total number of samples and their segregation into raw wastewater (influent) and treated water (effluent), sub-datasets, and mean, maximum, and minimum values recorded in each dataset, as well as the standard deviation of the data. Table 1. Characteristics of the different datasets used for the different chemical oxygen demand (COD) estimation modelsDatasetNo. of WWTPsSubType of wastewaterNo. of samplesMean (mg/L)Std. dev. (mg/L)Max valueMin valueDataset A1A1Both174512.74511167227A2Influent86988.62279.84167244A3Effluent8847.6710.277827Dataset B42B1Both420335.64400.2515740B2Influent206660.94344.06157414B3Effluent21422.5118.792000Dataset C1C1Both332257.13277.849210C2Influent116607.76175.029210C3Effluent21668.8222.551555Dataset D1D1Both346360.28342.68122618D2Influent173666.93214.9122640D3Effluent17353.6314.149218All Datasets45L1Both1272346.08382.4816720L2Influent581700.61296.6616720L3Effluent69147.98262000Sub-datasetsTable 2Characteristics of the different datasets used for the different total suspended solid (TSS) estimation modelsDatasetNo. of WWTPsSubType of wastewaterNo. of samplesMean (mg/l)Std. dev. (mg/l)Max valueMin valueDataset A1A1Both156179.45200.855563A2Influent68392.49107.6355625A3Effluent8814.838.04513Dataset B42B1Both406116.11140.795500B2Influent192238.35115.8755012B3Effluent2146.449.8900Dataset C1C1Both28586.69113.4335610C2Influent69272.4282.0935617C3Effluent21627.3716.0513210Dataset D1D1Both345166.7182.838000D2Influent172321.84137.558000D3Effluent17312.466.84370All datasets45L1Both1192132.01161.048000L2Influent501292.63130.028000L3Effluent69115.5514.21320Sub-datasets
Samples were taken at the inlet (pre-treatment) and outlet of the WWTPs to analyze different levels of contamination. Integrated samples were used over 24 h and collected automatically by the WWTPs’ equipment.
For this study, integrated sampling was carried out over 24 h in each of the defined measurement zones at the wastewater treatment plants (WWTPs). Each sample was analyzed using two different approaches: the developed LED spectrophotometry equipment and standard laboratory analysis methods. This allowed the results obtained by both methods to be correlated. The samples analyzed with the LED spectrophotometry kits were not subjected to pre-treatment or addition of chemical reagents, to develop an operational system with raw samples, suitable for continuous monitoring.
The laboratory tests were carried out according to the Standard Methods (SM) and the norms of the International Organisation for Standardisation (ISO), using mainly the following procedures: the dichromate method with UV–VIS spectroscopy (ISO 6060:1989) for COD and the settleable solids method (ME 2540 F) in the case of TSS.
Model performance indicators
Model assessment was performed in terms of the RMSE (Eq. (3)), where, to analyze the performance of regressors, the dimensionality reduction technique and scaling were used separately for each sub-dataset; the median value was taken to avoid possible deviations of the results as a consequence of the random rearrangement of the data.
The R^2^ is a widely used performance indicator, but it has certain limitations, such as the fact that it does not take into account the scale of the data, which means that comparisons between models of different sub-datasets may be invalid. Moreover, in the case of working with new data never seen before by the models (third-party data), in the case of non-linear data or complex relationships, it may underestimate the performance of the model, since it is designed under the assumption of linearity. For this reason, RMSE was used as the main performance indicator. However, the results in terms of R^2^ (Eq. (4)) are also presented in the Supplementary Information to provide a broader view of the effectiveness of the models.
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$RMSE\;(mg/L)=\sqrt{\frac{1}{n}{\sum }_{i}^{n}{\left({X}_{G{T}_{i}}-{X}_{estimate{d}_{i}}\right)}^{2}}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\overline{{R }^{2}}(\%)=1-\frac{\frac{\sum_{i}^{n}{\left({X}_{G{T}_{i}}-{X}_{estimate{d}_{i}}\right)}^{2}}{n}}{\frac{\sum_{i}^{n}{\left({X}_{G{T}_{i}}-\overline{{X }_{G{T}_{i}}}\right)}^{2}}{n}}*100$$\end{document}where n represents the count of the samples, while \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${X}_{GT}$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${X}_{estimated}$$\end{document} are the respective measurements of the polluting parameters obtained by the analytical methods used by the wastewater treatment plant (ground truth) and by the calculation models, respectively, and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\overline{{X }_{GT}}$$\end{document} is the average of the reference values.
Methodology for data analysis
The ability to provide an accurate characterization relies on two elements, the processing pipeline model and the data used on that pipeline to assess its performance. This means that it is not enough merely to determine the different steps of the processing pipeline model, but also which data was presented to that combination to fully understand the results. In this work, the processing pipeline was set with three steps, named scaling, dimensional reduction, and regressor. A set of different techniques has been applied for each one of them; these are detailed below:
- Scaling
- No scaling: the data is not transformed, and the original data is used to determine the influence of the transformation on the performance of the different models.
- Normalization: it brings the data to the interval [0,1] by mean (Eq. (1)) for each feature, where represents the transformed feature \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$(x)$$\end{document} , represents the minimum value, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$min\left(x\right)$$\end{document} among all samples and the maximum, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\text{max}\left(x\right)$$\end{document} .
- Standardization: data is transformed to a normal distribution [− 1, 1], according to Eq. (2), where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${x}_{t}$$\end{document} represents the transformed feature, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\mu }_{x}$$\end{document} represents the mean, and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\sigma }_{x}$$\end{document} the standard deviation of the whole dataset
-
2.Dimensional reduction
-
No transformation: the data is not transformed from the output of the scaling step. This is to determine the influence of any possible transformation and reduction in the performance of the final step, the regressor.
-
Principal components analysis (PCA): the aim of this reduction dimensionality is to transform the original variables into a new set of uncorrelated variables. Those new variables, obtained through linear combinations of the original variables, are arranged in order of their ability to account for variance in the data (Abdi and Williams 2010).
-
F-score: it is a linear regression with feature selection that more specifically uses the Lasso or L1 method. It tries to identify the most relevant features for the target variable based on the premise that input variables with a higher correlation with the target variable have a higher significance for the model. This is determined by a cross-correlation analysis between a predictor variable and the target variable, using the p-value statistic to assess significance (Zhao et al. 2017, Zou 2006).
-
The Mutual Information (MI) measure is used to assess the dependency between variables, and it allows for the removal of those that exceed a predetermined threshold (Seth and Príncipe 2010).
Details of the setting parameters of the dimensional reduction processes are shown in Table 3.
-
3.Regressors
-
Partial least square (PLS): A regression technique that models linear relations between input and output variables, seeking the most appropriate subset of variables for the model based on their importance (Geladi and Kowalski 1986).
-
Stochastic gradient descent (SGD): An optimization algorithm that updates model weights iteratively using small data sets to train regression models (Bottou. 2012).
-
Support vector regression (SVR): Based on the behavior of support vector machines, it is a machine learning algorithm regression task. For regression, they seek to find an optimal hyperplane that approximates the relationship between input variables and their corresponding target values.
-
Regression ensemble methods:
-
Random Forest (RF): Classical ensemble regression technique that leverages decision trees for prediction. In this approach, each tree is trained on the entire dataset without partitions, deviating from some other methods. The final prediction is obtained by aggregating the outputs of the constituent trees within the forest. This methodology yields robust and accurate regression results (Breiman. 2001).
-
Bagging Tree Regressor: Also a Decision Tree-based ensemble approach which follows the principle of the knowledge of the crowd. It uses a Bootstrapping or Bagging approach to build random partitions to train each of the regressors which conform the ensemble. The results would be the average of the partial regressors (Breiman 1996).
-
Gradient Boosting (Boosting): This ensemble approach uses the 11 decision trees as the base model, but the splitting schema is called Boosting. It begins with a single regressor and, based on the errors exceeding a specified threshold, trains additional regressors to improve predictions in those cases, thereby increasing overall accuracy (Natekin and Knoll 2013).
-
Multilayer Perceptron (MLP): One of the most well-known artificial neural network architectures. It comprises multiple layers of interconnected artificial neurons connected in a feedforward schema, meaning that information flows from the input layer through hidden layers to the output layer. The MLP’s structure consists of an input layer, one or more hidden layers, and an output layer, with each layer containing multiple neurons. It is one of the most widely used techniques for pattern recognition (Taud and Mas 2018) and has a long record of successful applications. Table 3. Dimensional reduction settingDimensional reductionSettingPCASolver = Singular value decompositionNumber features = 162F-scoreFeatures = 90% of the totalMINumber of neighbors = 3Features = 90% of the total
Table 4 details the configuration used for each of the regressors. Table 4. Regressor settingRegressorSettingPLSNumber of components = 2Number of iterations = 500SGDLoss function = ‘Squared Error’Penalty = L2Number of iterations = 1000Learning rate = 0.1SVRkernel = ‘rbf’Gamma = 0.7C = 1Epsilon = 0.1Random ForestNumber of estimator = 100Split_criterion = Squared ErrorMax depth of the trees = unlimitedBagging Tree RegressorBase estimator = Decision TreeNumber of estimator = 10,Gradient BoostingNumber of estimator = 10Learning rate = 0.1Loss function = Squared ErrorSplit criteria = Friedman’s MSEMLPArchitecture layer = [162, 100, 1]Activation function = ReLUMax. iterations = 1000Batch size = 200Learning rate = 0.001Regularization = 0.001*L2Early stopping = TrueValidation subset = 10% of the training
All the steps and analyses carried out were performed using Python and Scikit-Learn library (Pedregosa et al. 2011). A total of 7 regressors, 4 dimensionality reduction techniques, and 3 data scaling options were used; therefore, 84 different combinations were tested. Each of these pipelines utilized the 81 transmittance values and 81 absorbance values obtained from the sensors as the input, with the output being one of the laboratory measurements, i.e., COD or TSS values.
It should be mentioned that the dimensional reduction step was exclusively applied to the signals obtained from the sensors, i.e., the input data. In contrast, the output data obtained from laboratory measurements remained unchanged throughout the analysis. This distinction ensures that the preprocessing step of dimensional reduction was focused solely on the input data, while the integrity of the output data remained preserved.
However, since data play such a fundamental role in the performance of a model, a cross-validation procedure was also carried out for each pipeline, so the results achieved are independent of the random partition of data used for their adjustment and evaluation. In this work, a tenfold cross-validation schema was used, so each pipeline was adjusted and evaluated 10 times to generate 10 test values, from which the average value was obtained. To this end, each of the 15 sub-datasets presented in Table 1 was divided into 10 equal randomly sampled partitions, and 10 different experiments were performed. In each step of the cross-validation procedure, 9 of the partitions were used for adjustment or training, while the remaining partition was used for validation of the results. Each data point is used only once for testing, but the models differ because they have been trained and adjusted with different data. The focus is on selecting the steps of the pipeline rather than on a specific model. This approach allows the pipeline to be extrapolated to other locations, while the models themselves perform based on the data they were trained on.
Therefore, a total of 840 pipelines were tested for each sub-dataset. Considering that 15 different sub-datasets were generated according to geographical location and type of water, the results therefore represent the information extracted from 12,600 models for each target pollutant, COD, and TSS. The objective of this extensive model generation was to establish a three-level classification system (Lepot et al. 2016). This system ranks the times that each regression, scaling, and dimensionality reduction technique achieves a certain position in the rankings across the different subsets of data. In addition, this ranking was performed taking into account the type of wastewater studied, differentiating between raw and treated wastewater.
To clarify the process carried out, Fig. 2 shows a diagram of the pipeline followed to determine which regressor, scaling, and dimensionality reduction provided the best results with each dataset for raw and treated wastewater samples, both jointly and individually. For clarity in the exposition of the process, the diagram in Fig. 2 only shows the process for a single partition of only one of the sub-datasets, when in practice it was carried out on all the partitions of all the sub-datasets under study.Fig. 2. Diagram of the analysis process carried out in this research work
Thus, and as can be seen in Fig. 2, over 1300 wastewater samples were collected from different wastewater treatment plants (WWTPs) using LED spectrophotometry (Carreres-Prieto, et al 2019) to obtain spectral response data and laboratory analytical values for COD and TSS. As a result, five datasets were generated for each pollutant: four corresponding to data from a single WWTP or from a localized set of them (datasets A–D*)*, as well as an additional dataset that combined all the previous ones together (all datasets). Subsequently, a cross-validation process was performed with a tenfold partitioning scheme, applying 84 different models per partition, resulting in a total of 12,600 models trained and evaluated across 15 sub-datasets. The mean and standard deviation of each cross-validation were calculated to compare pipeline configurations. Based on the median values of the combinations of regression, dimensionality reduction, and scaling techniques, a comparative heat map was produced in matrix form, ranking the types of wastewater and data sets worked on according to the frequency with which each configuration achieved a top three position in performance.
In order to obtain a general analysis from the heatmap information (one in terms of COD and the other in terms of TSS), where the number of times that a regression, scaling, or dimensionality reduction technique occupied a certain position in the ranking was determined, expressed as a percentage of the times that it occupied a certain position with respect to the set, a ranking for all the study datasets and segregated by type of water was established. This was based on the sum of the number of times that a given regressor, dimensionality reduction technique, and scaling occupied a given position for all the study datasets, in order to determine the most appropriate one to apply for each type of water (or combination thereof) regardless of where the data come from, i.e., regardless of the WWTP or geographic area.
Results and discussion
Analysis of datasets
The distribution of the data in terms of COD and TSS associated with each of the study sub-datasets, i.e., by dataset and wastewater type: effluent, influent, or both, are shown in Figs. 3 and 4, using box-and-whisker plots.Fig. 3COD data distribution diagram by datasetFig. 4TSS data distribution diagram by dataset
As expected, the overall distribution of COD and TSS records presented a bimodal distribution. Thus, effluent pollutants showed a very narrow range of variation with threshold values ideally below EU environmental legislation limits. On the other hand, influent records showed far greater variability, due to the differences in the origin of the wastewater, produced at different geographical locations, and to a lesser extent due to the daily and seasonal variation patterns produced internally in each catchment area. This data clusterization will have some implications when performing model adjustments, as will be discussed later.
Furthermore, the datasets also presented some statistical outliers which have been maintained in some of the datasets, to enable the conditions for analyzing and understanding the variability inherent in the real data to be considered and to develop models that more accurately adapt to the complexity and natural fluctuations of the phenomena studied. Data which, in the opinion of an expert, undeniably correspond to analytical failures in the WWTP laboratories were eliminated.
Benchmark chemical oxygen demand
In this section, the impact of factors such as regressor type, scaling techniques, and dimensionality reduction techniques on the performance of characterization models was examined using a cross-validation methodology on each sub-dataset. The same data partitions were used to analyze each technique on each sub-dataset.
The results obtained from the different regressors as a function of dimensionality reduction methods (organized by rows) and scaling techniques (arranged in columns) in terms of COD are shown in Fig. 5 using a matrix structure. For clarity, the figure only presents the results related to sub-dataset L1 of Table 1, which encompasses all types of water and WWTPs analyzed, with the results for the other datasets being given in the Supplementary Information.Fig. 5. Comparative box-and-whisker plot, organized by dimension reduction and scaling, for each of the study regressors, for the dataset that included all water types and WWTPs (sub-dataset L1) for COD
As can be observed, the median was taken as the measure of the central trend for each of the partitions, in order to mitigate the effect of outlier partitions (those providing the best and worst performances), thereby ensuring that the results presented better represented the overall performance of the combinations studied.
The performance of each of the regressors, dimensionality reduction, and scaling technique as a function of the type of wastewater under study (raw wastewater, treated wastewater, or a combination of both) and the working datasets (including the one covering all WWTPs under study) are presented in matrix form in Fig. 5. Within each cell of this matrix (representing one of the sub-datasets in Table 1), three heatmaps are presented, in terms of minimizing the root mean square error (RMSE). Figure S1 in the Supplementary Information provides the results of this analysis in terms of R^2^. The values shown in the heatmaps indicate the percentage of times that a given combination occupies a given position in the ranking in terms of RMSE minimization.
Each heatmap focuses on one of the three key aspects of the analysis: regressors, dimensionality reduction, and scaling, and establishes a ranking, in terms of how many times each combination ranked first, second, or third in terms of performance. This ranking provides an intuitive view of trends and patterns in the data, facilitating the identification of the most effective combinations for each specific scenario.
As can be seen in Fig. 6, in the combination of all the datasets, the RF regressor stood out, leading with a notable frequency, reaching 75% in the global analysis. The dimension reduction technique PCA proved to be the most effective, dominating in 57% of the cases at the global level, while its relevance rose to 67% in specific treated water samples. Scaler normalization was preferred in 43% of the cases globally, although for raw water samples specifically, standard normalization emerged as the predominant option with 75%.Fig. 6. Comparative performance matrix by dataset and water type, broken down by dimension reduction, scaling, and regressor, evaluated by RMSE, for COD
Detailing the results by dataset, it must be highlighted that in dataset A, RF led in 67% of the cases when combining all types of water, followed by the Boosting technique with 25%. For dimension reduction, F-score and MI alternated as leaders, depending on the specific context, while PCA took the lead with 33% in treated water samples. In terms of normalization, Scaler was shown to be the most successful option in most scenarios, highlighting that the absence of normalization provided the best results 57% of the times for raw wastewater.
Datasets B to D reflected similar patterns, with RF maintaining a solid lead in raw and combined water scenarios, reaching 67% and 50%, respectively, in some contexts. SGDR and PLS emerged as the leading regressors in specific situations, aspect observed in works such as Lepot et al. (2016), where PLS stands out in first position in the ranking., with SGDR leading in 50% of cases for raw and treated water combinations in dataset C. Variability in the choice of dimension reduction and normalization techniques highlighted the adaptability needed depending on the sample type, with MI dominating at 52% in certain contexts and simple normalization leading at 54% in others.
To complement the detailed analysis presented in Fig. 6, Table 5 consolidates and synthesizes key information on the effectiveness of the different dimensionality reduction, scaling, and regressor configurations. That table focuses on the accumulation of ranking positions based on minimizing RMSE, providing a quantitative perspective on how often each approach performed outstandingly well on the different data sets and water types analyzed, so the study variable (regressor, scaling, or dimensionality reduction) that occupied the 1st position, for a given wastewater type, a greater number of times indicated a higher suitability for treating and analyzing that specific type of wastewater. Table 5. Summary of ranking frequencies for each regressor technique (A), dimensionality reduction (B), scaling (C) by RMSE for CODRMSEBothInfluentEffluent1º2º3º1º2º3º1º2º3º****PLS101110111SGDR100110011SVM000000101Bagging013002112Boosting021013010RF****320421211MLP000000000**(A)BothInfluentEffluent1º2º3º1º2º3º1º2º3ºNo-D.Reduc.^1^003123140PCA200200310F-score122311013MI230122113(B)BothInfluentEffluent1º2º3º1º2º3º1º2º3ºNo-scaling041250051Normal.^2^204311302Scaler****310004202(C)**^1^ No-Dimension Reduction applied^2^ Normalization
The analysis relating to the type of regressor employed based on the water type is shown in Table 5 part A. When combining all types of wastewaters, Random Forest stood out, ranking first in three out of the five datasets analyzed. This was closely followed by PLS and SGDR, although the latter two only demonstrated a notable performance in minimizing RMSE in one single dataset each, specifically datasets D and C, respectively. Random Forest and Boosting tied in the second position with two datasets each.
When considering raw wastewater exclusively, the superiority of Random Forest was once again highlighted, leading in the first position in four out of the five datasets studied. In contrast, PLS only achieved the top position in dataset C. However, in terms of the second position, there was a greater variety of regressors observed, with Random Forest still leading, followed by Boosting, PLS, and SGDR.
Regarding the specific analysis of treated water, it was observed that Random Forest remained the most effective regressor, closely followed by PLS, SVM, and Bagging, leading in datasets C and B.
In relation to the dimensionality reduction technique (Table 5 part B), its effectiveness varied depending on the type of wastewater considered. When all types of wastewaters were combined, PCA and MI each led in two datasets in terms of reducing the RMSE, followed by the F-score. However, MI stood out in the second position of the ranking, followed by the F-score.
For raw wastewater samples, the F-score enabled the greatest reduction in RMSE in three of the datasets, followed by PCA in two, while MI and the absence of dimensionality reduction techniques led in only one dataset each. It should be noted that in certain datasets, there was a tie between two techniques, as in the case of dataset A, where there was a tie between F-score and MI, and in dataset D between PCA and F-score. On the other hand, the second position in the ranking was led by MI and the absence of dimensionality reduction techniques.
As for treated wastewater samples, PCA led in three datasets, followed by the absence of dimensionality reduction techniques and MI, albeit to a lesser extent. In contrast, the second position in the ranking was led by the absence of dimensionality reduction techniques, presenting the greatest reductions in RMSE in four datasets.
In terms of the normalization techniques applied to the data, interesting patterns emerged across different contexts of wastewater samples. In datasets combining both raw and treated wastewater samples, Scaler ranked first in three datasets, followed by normalization in two. However, it should be remarked that in the second position of the ranking, not applying any normalization technique occupied the top spot.
In the specific case of the analysis of raw wastewater samples, normalization stood out, taking the first position in three of the datasets studied. Interestingly, the second position in the ranking was again dominated by the decision not to apply any normalization technique.
On the other hand, when focusing on treated wastewater samples, it is evident that the application of data normalization yielded the best results in terms of minimizing the RMSE, followed by scaling (Scaler). However, in accordance with previous findings, the second position in the ranking was led by the choice of not applying any normalization technique.
Benchmark total suspended solids
The performance of the models for each of the 10 partitions, organized by type of scaling technique (columns) and dimensionality reduction technique (rows), is shown in Fig. 7 for sub-dataset L1 of Table 2 (which collects all WWTPs and wastewater types). The Supplementary Information contains the analysis for the rest of the sub-datasets.Fig. 7. Comparative box-and-whisker plot, organized by dimension reduction and scaling, for each of the study regressors, relative to the dataset including all water types and WWTPs (sub-dataset L1) for TSS
As can be seen, the median RMSE did not vary greatly between the different types of scaling and dimensionality reduction.
Regarding the performance of the different combinations of regressor, scaling, and dimension reduction techniques, in terms of TSS characterization, a comparative matrix analysis for each type of water and dataset, in terms of minimizing RMSE, is shown in Fig. 8. Figure S16 in the Supplementary Information details the results of this analysis in terms of R^2^.Fig. 8. Comparative performance matrix by dataset and water type, broken down by dimension reduction, scaling and regressor, evaluated by RMSE, for TSS
Upon analyzing the effect of each of the regression, dimension reduction, and normalization techniques on each of the study datasets, it was observed that in the case of combining all the datasets and types of wastewater, the RF regressor appeared as dominant, in the first position 83% of the times. The PCA dimension reduction technique excelled by securing the first position in 76% of the cases. In terms of data normalization, Scaler stood out significantly. Within the specific analysis by sample type, when focusing on raw water, RF remained the preferred regressor, leading 75% of the time, although diversification was observed in dimension reduction with a tie between no dimension reduction and PCA, each with 43%. For normalization, the standard technique clearly prevailed and was the most used in 68% of the cases. On the other hand, in treated water samples, RF was less predominant, at 50%, and in dimension reduction, PCA and MI tied at 38%, which reflects the existence of several effective approaches. Scaler normalization was the most frequent, with a 46% prevalence.
In dataset A, RF led 67% of the times in an overall analysis, with a moderate preference for MI in dimension reduction (29%) and a tie between standard normalization and Scaler (36%). In dataset B, RF stood out as the most effective regressor (58%), PCA dominated in dimension reduction (38%), and standard normalization was the predominant technique (57%). Dataset C showed PLS as the main regressor (58%), with a remarkable diversity in dimension reduction and normalization techniques, with no technique emerging as common in certain contexts. Finally, in dataset D, PLS again led as a regressor (67%), with PCA as the most common choice for dimension reduction (38%) and a balance between standard and Scaler normalization techniques (39%).
Table 6 summarizes the information shown in Fig. 8 regarding the cumulative accumulated value of the ranking positions based on the RMSE metrics as a function of the regressor, scaling, and dimension reduction technique employed. Table 6. Summary of ranking frequencies for each regressor technique (A), dimensionality reduction (B), scaling (C) by RMSE for TSSRMSEBothInfluentEffluent1º2º3º1º2º3º1º2º3º****PLS200200121SGDR011010001SVM000001200Bagging001003012Boosting022030010RF****321331201MLP000000010**(A)BothInfluentEffluent1º2º3º1º2º3º1º2º3ºNo-D.Reduc.^1^110122042PCA400100300F-score024311112MI132132311(B)BothInfluentEffluent1º2º3º1º2º3º1º2º3º****No-Scaling131140150Normal.^2^404410302Scaler320005103(C)**^1^ No-Dimension Reduction applied^2^ Normalization
In Table 6 part A, dedicated to analyzing the performance of different regressors, Random Forest stands out as the algorithm with the best performance both in the configuration that included both types of wastewater (both) and in the influent. However, for the effluent, RF and SVM shared the leading position, leading in the same number of datasets. This performance pattern was also reflected in the R^2^ values, indicating consistency in the results obtained.
Regarding the size reduction techniques (Table 6 part B), PCA ranked first when considering all types of wastewater combined. On the other hand, in the specific analysis of the influent (raw wastewater), the F-score showed a superior performance, occupying the first position. For effluent, a tie was observed between PCA and MI in terms of leadership in the same number of cases. The second position varied depending on the type of water analyzed, where in combined wastewater, MI and F-score demonstrated outstanding performance, while for influent, MI excelled followed by the option of not applying dimension reduction.
Table 6 part C shows that data normalization significantly improved the results in all the contexts analyzed, positioning it as the most effective strategy for each type of wastewater. This underscores the importance of data normalization as a preliminary step in model performance analysis.
Conclusions
LED spectrophotometry has proven to be an effective technique for the indirect characterization of the contaminant load in wastewater, obviating the need for pretreatment or chemical reagents by correlation models. The construction of these models, in terms of the regressor selected, the type of scaling, and the pretreatment method applied, is key to ensure their accuracy and validity in different wastewater contexts, influenced by variables such as population demographics, the presence of industry, and climate conditions.
This study evaluated the influence of seven regression techniques, three scaling strategies, and four dimensionality reduction methods on 1300 raw and treated wastewater samples from 45 treatment plants in different regions of Spain and Santiago of Chile, over 4 years.
The RMSE was used to analyze the performance of the models as it has been established as the best indicator of performance, since the R^2^ is not always reliable, especially because it does not consider the scale of the data and underestimates the performance in the face of non-linear or complex relationships.
The analyses indicated that the Random Forest model excelled in the characterization of COD, proving to be the most suitable algorithm due to its high efficiency, evidenced in 75% of the cases analyzed. Furthermore, the importance of a meticulous selection of preprocessing techniques, especially normalization and dimensionality reduction, was highlighted in order to adapt to the specific characteristics of each water sample.
Regarding the characterization of TSS by spectrophotometric analysis, RF emerged as the most efficient regressor, predominating in 83% of the cases. The PCA dimensionality reduction technique proved its relevance and was the most effective in 76% of the situations. This study underscores the need for adequate data preprocessing, with the Scaler method as the most recurrent normalization option.
Overall, Random Forrest models obtained the best performance the 75% and 83% of the model-assessed combinations for COD and TSS, respectively. In the work of Lepot et al. (2016), a small number of regression techniques were assessed for a dataset of UV–vis spectrometry data. In Lepot et al. study, PLS (partial least squares) and SVM (support vector machine) techniques occupy the top positions in the rankings. This finding is consistent with the results obtained in our research work, where PLS and SVM tend to occupy the second positions in certain datasets (datasets B to D), although with a lower performance than the RF regressor, which was not considered in the Lepot et al. study.
Significant advances in wastewater treatment process modeling have been achieved by integrating a large data set from different WWTPs and wastewater samples. This approach has enabled the development of robust and generalizable models that surpass previous studies, offering valuable tools for the optimization of treatment plants under several operational and geographical conditions.
This research work has found the effectiveness of LED spectrophotometry, in combination with advanced modeling and data analysis techniques, in the indirect characterization of wastewater pollutant load. The findings highlight the importance of properly selecting the regressor, scaling method, and dimensionality reduction techniques to maximize the accuracy and applicability of models in different wastewater contexts. The adaptability and robustness of these models open new possibilities for efficient and sustainable wastewater management, enabling more advanced monitoring.
The use of LED spectrophotometry in combination with a trained characterization model for the detection of important pollutants present in wastewater, such as COD or TSS, allows for real-time monitoring of water quality at a low cost, enabling rapid incident detection, and swift action by plant personnel, which is impossible with laboratory analysis.
Electronic supplementary material
Below is the link to the electronic supplementary material.Supplementary file1 (DOCX 17280 KB)
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Cheng W, Zhang X, Duan N, Jiang L, Xu Y, Chen Y, ... Fan P (2022) Direct-determination of high-concentration sulfate by serial differential spectrophotometry with multiple optical pathlengths. Sci Total Environ 811:152121. 10.1016/j.scitotenv.2021.15212110.1016/j.scitotenv.2021.15212134871678 · doi ↗ · pubmed ↗
- 2Song ZM, Xu YL, Liang JK, Peng L, Zhang XY, Du Y, ... Guan YT (2021) Surrogates for on-line monitoring of the attenuation of trace organic contaminants during advanced oxidation processes for water reuse. Water Res 190:116733. 10.1016/j.watres.2020.11673310.1016/j.watres.2020.11673333341034 · doi ↗ · pubmed ↗