Variable calling of m6A and associated features in databases: a guide for end-users
Renhua Song, Gavin J Sutton, Fuyi Li, Qian Liu, Justin J-L Wong

TL;DR
This paper reviews m6A databases and warns that differences in data processing can lead to unreliable results if users are unaware of these issues.
Contribution
The paper highlights variability in m6A peak calling across databases and warns of potential false positives/negatives from outdated methods.
Findings
Differences in peak-calling pipelines lead to variability in peak numbers and coordinates.
Early m6A sequencing protocols may introduce false positives or negatives.
End-users should be aware of database limitations to avoid unreliable data.
Abstract
N6-methyladenosine (m\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \end{document}A) is a widely-studied methylation to messenger RNAs, which has been linked to diverse cellular processes and human diseases. Numerous databases that collate m\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \end{document}A profiles of distinct cell types have been created to facilitate quick and easy mining of m\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb}…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
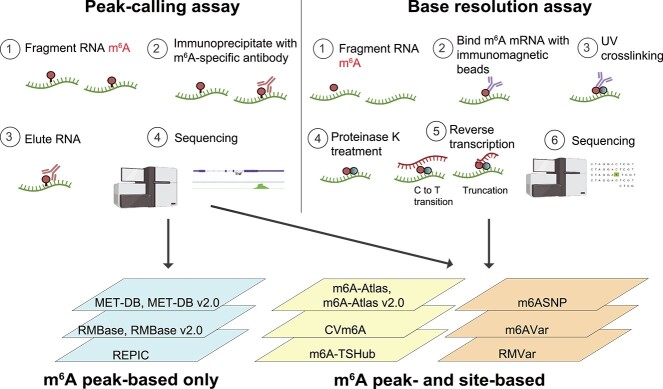 Figure 1
Figure 1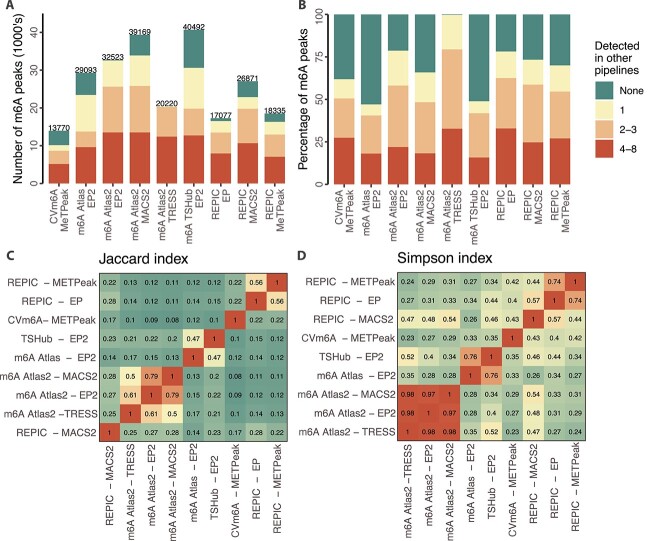 Figure 2
Figure 2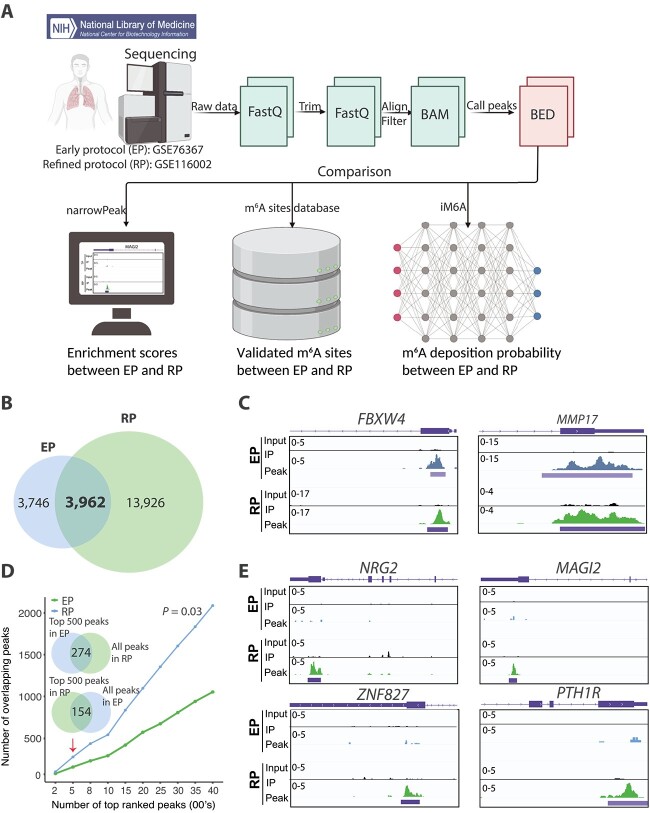 Figure 3
Figure 3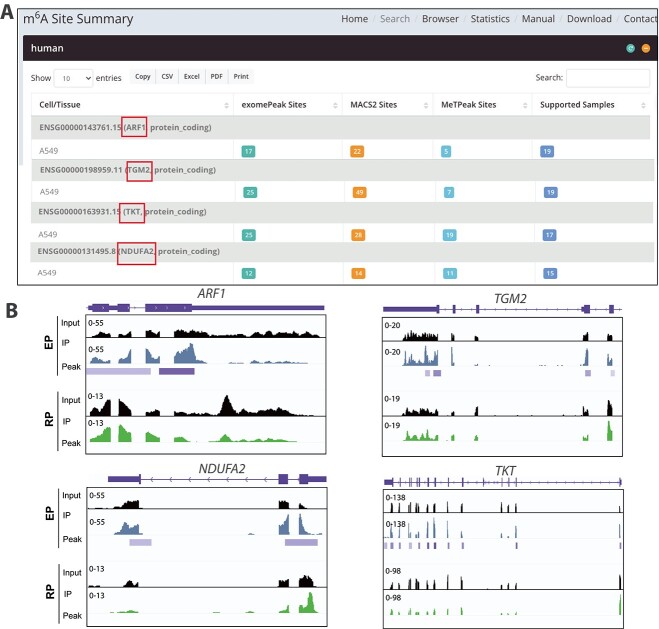 Figure 4
Figure 4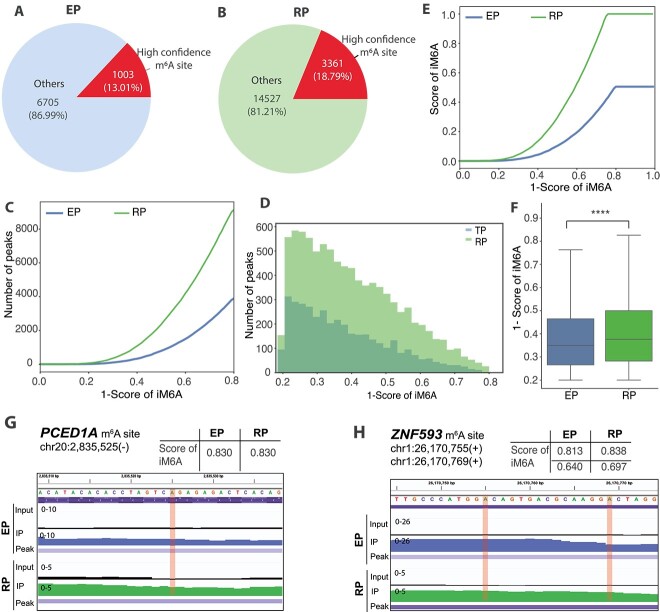 Figure 5
Figure 5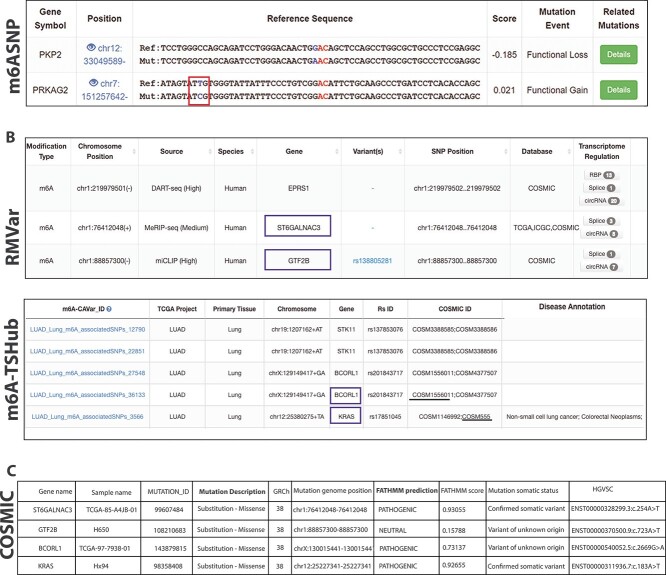 Figure 6
Figure 6| Databases | Functions | Modifications | Samples |
|---|---|---|---|
| MeT-DB [ | binding sites of miRNA, splicing factor (SF), RBPs | m | 74 meRIP-seq from 22 different conditions |
| MeT-DB v2.0 [ | miRNA target sites, SF binding sites,RBPs,Cancer related genes | m | 185 samples for seven species from 26 independent studies |
| RMBase [ | protein genes, miRNA target sites, disease-related SNPs, regulatory ncRNAs |
| 18 independent studies |
| RMBase v2.0 [ | miRNA targets, RBP binding sites, SNVs and GWAS data | m | 47 studies among 13 species |
| CVm6A [ | regulation of cell-dependent m | m | 23 human and eight mouse cell lines |
| REPIC [ | cell- or tissue-specific m | m | 672 samples of 49 studies, 61 cell lines in 11 organisms |
| m6ASNP [ | if methylation status of an m | m | 59 234 human m |
| m6AVar [ | RBPs, miRNA-targets and splicing sites associated with variants, GWAS and ClinVar | m | 2 PA-m |
| RMVar[ | RBPs, miRNA targets, splicing events, circRNAs and isease-related information from ClinVar and GWAS | m | 150 independent studies in human and mouse |
| m6A-Atlas [ | RBPs, miRNA targets and splicing sites | m | 67 datasets from seven base-resolution methods and 1363 m |
| m6A-Atlas v2.0 [ | RBPs, miRNA targets, SNPs, and splicing sites | m | 2712 MeRIP-seq and 109 base-resolution samples |
| m6A-TSHub [ | RBPs, miRNA targets, and splicing sites, along with their known disease and phenotype linkage integrated from GWAS and ClinVar | m | 23 healthy human tissues and 25 tumour conditions |
| Databases | Filtering | Peak-calling | Reported-peaks | Customizable setting of parameters for peak calling? | Reported m |
|---|---|---|---|---|---|
| MeT-DB/ | exomePeak | FDR<0.05, | unavailable | Searching the RRACH motif | |
| RMBase/ | exomePeak | FDR<0.05, | not allowed | Searching the RRACH motif | |
| CVm6A | Picard (remove | MeTPeak | FDR<0.05, FE>1 | not allowed | miCLIP-seq/PA-m |
| REPIC | Removed rRNAs, | exomePeak, MeTPeak, | FDR<0.05, MAPQ>20, | not allowed | m |
| m6ASNP/ | MACS2, MeTPeak, | Consensus peak by MSPC | not allowed | miCLIP/MAZTER-seq/m | |
| m6A-Atlas/ | exomePeak2, MACS2 | Fold-enrichment>1 | not allowed | m | |
| m6A-TSHub | exomePeak2 | P <1e-10, contain | not allowed | miCLIP/m |
| Sample | SRA | RL | RD | Platform | CL | Genome | Antibody |
|---|---|---|---|---|---|---|---|
| m | SRX1503161 | 50 | 30.9 | HiSeq2000 (S | A549 | Human | |
| m | SRX1503162 | 50 | 29.9 | HiSeq2000 (S | A549 | Human | Synaptic Systems, 202003 |
| RIP-seq (RP) INP | SRX4239819 | 51 | 42.9 | HiSeq2500 (S | A549 | Human | |
| RIP-seq (RP) IP | SRX4239820 | 51 | 33.8 | HiSeq2500 (S | A549 | Human | Synaptic Systems, 202003 |
- —National Health and Medical Research Council of Australia
- —National Natural Scientific Foundation of China
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsRNA modifications and cancer · Cancer-related gene regulation · Genomics and Phylogenetic Studies
Introduction
N6-methyladenosine (m \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} ^{6}\end{document} A) is the modification to adenosine (A) in RNAs via the addition of a methyl group at the nitrogen-6 position. It is the most prevalent, abundant, and conserved modification to messenger RNA (mRNA) molecules [1–5], but has also been found in other RNA species including long non-coding RNAs and circular RNAs [6–12]. In mature mRNAs, m \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} ^{6}\end{document} A is typically enriched in the 3 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} ^{\prime }\end{document} UTRs and near the stop codons [13] and within a consensus motif, DRACH (D=A, G or U; R=G or A; H=A, C or U) [2, 13, 14]. m \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} ^{6}\end{document} A has been implicated in myriad cellular processes including mRNA transcription, stability, splicing, export, and translation [15–18]. Not surprisingly, aberrant levels of m \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} ^{6}\end{document} A have been associated with the development of diverse human diseases [19–26].
To understand the roles of m \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} ^{6}\end{document} A in human diseases and biological processes, various techniques have been developed to profile m \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} ^{6}\end{document} A. Two widely used techniques are specific antibody-based high-throughput m \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} ^{6}\end{document} A sequencing and crossing linking-assisted m \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} ^{6}\end{document} A sequencing (Fig. 1). Antibody-based RNA immunoprecipitation (IP) uses high-throughput sequencing with peak-calling [2, 13, 27]. m \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} ^{6}\end{document} A- and meRIP-seq [2, 13, 27, 28] are the earliest and most commonly used methods under this class of techniques. They profile m \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} ^{6}\end{document} A methylated regions as peaks in transcript coverage from immunoprecipitated RNA relative to input RNA. The early version of this protocol [29] typically requires 300 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \mu \end{document} g of total RNA, which limits its application to cell lines. Subsequently, a refined protocol was developed by reducing the amount of total RNA to as low as 0.5 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \mu \end{document} g and has been applied to low-input RNA samples, including those obtained from primary human tumors [27]. Both early and refined methods map m \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} ^{6}\end{document} A enrichment within 200-nt peak regions, and cannot precisely identify methylated adenosine at a single-base resolution [13]. To overcome this issue, novel techniques, such as crossing linking-assisted m \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} ^{6}\end{document} A sequencing, were developed to accurately detect m \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} ^{6}\end{document} A at single-nucleotide resolution. These methods include miCLIP [30, 31], PA-m \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} ^{6}\end{document} A-seq [32], m \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} ^{6}\end{document} A-REF-seq [33], MAZTER-seq [34], DART-seq [35], miCLIP2 [36], and scDART-seq [37]. Among them, miCLIP/m \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} ^{6}\end{document} A-CLIP is well known for single-nucleotide detection of m \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} ^{6}\end{document} A methylation sites by crosslinking at the antibody binding site to induce mutations of methylated bases during reverse transcription. However, these techniques may give rise to a considerable level of background signal due to the limited specificity of antibodies.
Experimental methods used to profile m\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \end{document}A and databases that catalogue the resulting data; databases incorporate m\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \end{document}A peaks from publicly available m\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \end{document}A-seq and RIP-seq data sets or m\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \end{document}A sites from publicly available miCLIP and miCLIP2 data sets. Parts of the figure were generated using Bio-Render.
Nevertheless, consequent to implementing these m \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} ^{6}\end{document} A detection methods, a large amount of m \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} ^{6}\end{document} A modification data is now publicly available. To collate these data, several bioinformatics web servers and databases have been designed to collect, organize, integrate, and annotate m \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} ^{6}\end{document} A data sets (Fig. 1) [38–50]. These databases can be categorized into three main groups. The first group of databases provides the status of RNA modifications based only on enriched peaks over input control obtained from immunoprecipitation sequencing experiments using antibodies against specific RNA modification marks. MeT-DB is the first epitranscriptome database that compiled the m \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} ^{6}\end{document} A profiles for seven species in 26 different studies with a total of 74 meRIP-seq samples from 22 different experimental conditions [42, 43]. It contains additional functional data such as microRNA (miRNA) target sites, single nucleotide polymorphisms (SNPs), binding sites of splicing factors and RNA-binding proteins (RBPs), and information related to cancer genes. RMBase [40, 41] is another comprehensive epitranscriptome sequencing database that covers more than 100 types of RNA modifications in 13 species from 47 independent studies. These RNA modifications include pseudouridine ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \psi \end{document} ) modifications, 5-methylcytosines (m \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} ^{5}\end{document} C), m \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} ^{6}\end{document} A, and 2 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} ^{\prime }\end{document} -O-methylations (2 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} ^{\prime }\end{document} -O-Me). RMBase provides novel web-based visualization tools for metagene profiles, logos of motifs associated with specific modifications, and various types of genomic features. In addition, it integrates epitranscriptome sequencing data to explore post-transcriptional modifications of RNAs and their relationships with miRNA binding events, RBP binding sites, disease-related SNPs, and genome-wide association study (GWAS) data. Recently, REPIC was released to record \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \sim \end{document} 10 million peaks from 672 samples of 49 independent studies, covering 61 cell lines or tissues in 11 organisms [44]. It also integrates 1418 histone ChIP-seq and 118 DNase-seq data to present a comprehensive atlas of m \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} ^{6}\end{document} A methylation sites, histone modification sites, and chromatin accessibility regions. Accordingly, it allows users to explore cell/tissue-specific m \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} ^{6}\end{document} A modifications and to investigate potential interactions between m \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} ^{6}\end{document} A modifications and histone marks or chromatin accessibility.
The second group of databases collects m \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} ^{6}\end{document} A both with peak-calling and at a single-base resolution from crossing linking-assisted m \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} ^{6}\end{document} A sequencing. For instance, CVm6A compiles both m \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} ^{6}\end{document} A-seq and miCLIP-seq/PA-m \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} ^{6}\end{document} A-seq datasets in 23 human and eight mouse cell lines, and provides a visualization interface for searching and comparing the m \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} ^{6}\end{document} A patterns in different cell lines [45]. Another database, m6A-Atlas, assembles over 400 000 high-confidence m \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} ^{6}\end{document} A sites, and investigates cross-species conservation of m \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} ^{6}\end{document} A sites among several species: seven vertebrate species (including human, mouse, and chimpanzee), 10 virus species (including HIV, KSHV, and DENV), and their host cells [46]. More recently, an updated version of m \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} ^{6}\end{document} A-Atlas (v2.0) was generated to include nearly 800 000 reliable m \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} ^{6}\end{document} A sites from 13 high-resolution methods and over 16 million m \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} ^{6}\end{document} A peaks from meRIP-seq experiments [50].
Based on high confidence m \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} ^{6}\end{document} A sites and m \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} ^{6}\end{document} A peaks from datasets, some databases have included genetic variants that affect m \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} ^{6}\end{document} A modification sites. Thus, the third group of databases provides information concerning the effects of genetic variants on m \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} ^{6}\end{document} A to understand how they alter RNA methylation status to impact biological functions. For example, m6ASNP [47], m6AVar [48], and RMVar [51] adopted a random forest model to predict whether the methylation status of a m \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} ^{6}\end{document} A site is altered by the disease-associated genetic variants within and flanking m \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} ^{6}\end{document} A sites in human and mouse. m6AVar [48] and RMVar [51] collect a large number of m \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} ^{6}\end{document} A-associated variants derived from millions of germline and somatic variants from miCLIP, PA-m \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} ^{6}\end{document} A-seq, and meRIP-Seq experiments. The m \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} ^{6}\end{document} A-associated variants are determined based on whether they localize to RBP-binding regions, splicing, and miRNA target sites. RMVar also explores the underlying relationship between the m \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} ^{6}\end{document} A machinery and diseases by integrating the disease-association data from GWAS [52] and ClinVar [53] databases. m6A-TSHub presents a comprehensive platform for context-specific m \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} ^{6}\end{document} A methylation and m \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} ^{6}\end{document} A-affecting mutations in 23 human tissues in four key components (m6A-TSDB, m6A-TSFinder, m6A-TSVar, and m6A-CAVar) [49]. Inspired by m6AVar, m6A-Atlas [46] and m6A-Atlas v2.0 [50] inferred whether disease-associated genetic mutations could directly destroy the m \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} ^{6}\end{document} A forming motif DRACH. A detailed summary of these databases is documented in Table 1.
Table 1: A detailed summary of m\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \end{document}A databases
All these m \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} ^{6}\end{document} A-related databases have been created with the aim of providing useful information to study m \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} ^{6}\end{document} A-associated functions, but the lack of understanding of what these data present may lead to misinterpretation of m \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} ^{6}\end{document} A. First, databases include meRIP-seq experiments that lacked reproducibility even when data were generated in the same cell types [55]. meRIP-seq experiments are also unable to determine the stoichiometry of m \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} ^{6}\end{document} A. The sensitivity of m \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} ^{6}\end{document} A calling is highly variable between different cells and tissues, making the interpretation of m \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} ^{6}\end{document} A challenging. In addition, databases include datasets generated using both early and refined m \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} ^{6}\end{document} A profiling methods that vary in sensitivity and specificity. Second, cell/tissue-specific m \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} ^{6}\end{document} A profiles are not available in several of these databases, hindering m \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} ^{6}\end{document} A investigations for specific cells or tissues. Indeed, certain m \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} ^{6}\end{document} A modifications are tissue-dependent and are dynamically altered in response to different stimuli [56–60]. Third, reliable m \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} ^{6}\end{document} A sites that can be detected using improved technologies including GLORI [61] and eTAM-seq [62] on new datasets are not yet incorporated into databases. Base-resolution datasets, often generated using technologies like miCLIP [30, 31], remain the minority in databases due to the comparative difficulty to generate them and consequent rarity in the literature (e.g. only 109/2821 samples (3.6%) in m6A-Atlas v2.0). Fourth, main analysis methods, such as MACS2 and exomePeak used to analyse m \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} ^{6}\end{document} A datasets in databases, do not model the variation of methylation within transcripts and across biological replicates. Fifth, databases detailing m \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} ^{6}\end{document} A-related SNPs have included genetic variants in sequences that flank the DRACH motifs, but these variants are not known to affect m \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} ^{6}\end{document} A modification. Sixth, databases have included m \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} ^{6}\end{document} A-related SNPs that contribute to non-synonymous variants. Therefore, it is unclear whether disease pathogenicity is consequent to altered amino acid sequence or m \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} ^{6}\end{document} A function(s).
In this study, we explore currently available m \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} ^{6}\end{document} A databases and describe their characteristics and limitations. We start by determining the number of m6A peaks and sites in specific cell lines reported in databases, highlighting a huge variability in the reported numbers. Next, as a significant portion of datasets compiled in databases was generated using the early m \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} ^{6}\end{document} A-RIP-seq methods [2, 28, 29], we compared an example of the dataset obtained with the early method to the one obtained using the refined m \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} ^{6}\end{document} A-RIP-seq protocol [27] in the same cell-line. We pinpoint potential errors in the early m \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} ^{6}\end{document} A profiling method, which implies the need for additional filtering to minimize erroneous calling of m \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} ^{6}\end{document} A. We describe the challenges of linking m \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} ^{6}\end{document} A-associated SNPs to disease pathogenicity when these SNPs also constitute non-synonymous variants. Finally, we propose future directions towards generating better m \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} ^{6}\end{document} A-related databases from an end-user perspective.
Materials and methods
Evaluation of peak variability within accessions across databases
To explore how peak calls varied in response to differences in the preprocessing pipelines of databases, we compared database peak coordinates derived from two public accessions: NOMO-1 m6A-seq from Su et al. 2018 [63] (GSE87190, with input in GSM2324291, and immunoprecipitation in GSM2324292); and H1299 meRIP-seq from Lin et al. 2016 [64] (GSE76367, with input in GSM1982262, immunoprecipitation in GSM1982263). We note these two cell-types were chosen as each has only a single m6A-seq / meRIP-seq sequencing run in the literature; this controls for one source of variability across databases, which is that when a cell-type has multiple sequencing runs, some databases call peaks separately per run (e.g. REPIC), while others derive a combined peak list from processing all runs together and thus uses more information (e.g. m6A-TSHub). For m6A-Atlas and m6A-TSHub, coordinates were converted from hg19 to hg38 using rTrackLayer [65]. For database pipelines using MACS2, intergenic peaks were excluded from analyses. Peaks coordinates were standardized to a width of 125bp centred around the midpoint, and intersected using intersectBed from the BedTools suite [66], requiring a minimum overlap of 1bp.
Comparison of m\documentclass[12pt]{minimal}
\usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \end{document}A peaks detected in the human A549 cell line using early and refined m\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \end{document}A-seq
To demonstrate variable calling of m \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} ^{6}\end{document} A generated by widely used m \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} ^{6}\end{document} A-seq protocols in existing databases, we compared the m \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} ^{6}\end{document} A peaks identified using the early m \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} ^{6}\end{document} A-seq protocol [67] and the refined RIP-seq protocol [27] in human A549 cell line. Data generated using either methods are publicly available for this cell line, and have been incorporated into m \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} ^{6}\end{document} A-related databases. To call m \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} ^{6}\end{document} A peaks, adaptor sequences, and low-quality reads were first trimmed from raw reads using Trimmomatic v0.38 [68] under default settings. FastQC v0.11.8 [69] was used to assess read quality, and STAR v2.5.2a [70] aligner was used to align clean reads to the human reference genome hg38 (ENSEMBL version 86). Samtools v1.6 [71] was used to select uniquely mapped reads to minimize the rate of false positives. MACS2 v2.1.0 [72] was used to call peaks enriched in immunoprecipitated over corresponding input samples. Peaks with enrichment scores >4 were selected for further analysis.
Validation of A549 cell line-associated peaks
To identify potential false positive m \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} ^{6}\end{document} A, a total of 10 704 high confidence m \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} ^{6}\end{document} A sites in the human A549 cell line quantified by the m \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} ^{6}\end{document} A-CLIP were downloaded from the m6A-Atlas database [46]. Bedtools was used to validate the m \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} ^{6}\end{document} A peaks identified using the early m \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} ^{6}\end{document} A-seq protocol and refined RIP-seq protocol by intersecting them with the existing high confidence m \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} ^{6}\end{document} A sites [66]. A pie chart was used to visualize the percentage of verified m \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} ^{6}\end{document} A sites in each method.
Calculation of m\documentclass[12pt]{minimal}
\usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \end{document}A scores by an intelligent m6A (iM6A) model for m\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \end{document}A sites in A549 cell lines
The intelligent m6A (iM6A) model was further used to show the potential erroneous m \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} ^{6}\end{document} A sites generated by the early m \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} ^{6}\end{document} A-seq protocol [67] and the refined RIP-seq protocol. To do this, the narrow peak output of MACS2 was expanded to +/- 250bp from its peak position. A 501bp sequence is used as input of iM6A (a deep learning model) to calculate the probability of the site being a m \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} ^{6}\end{document} A site, consistent with the original article describing this model [73]. Each position in the peak sequence was assigned a probability ranging from 0 to 1: the larger the score, the higher the probability of a site being m \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} ^{6}\end{document} A-methylated. The maximum probability of the sequence is used as m \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} ^{6}\end{document} A probability of the called peaks. The line and box plots were used to visualize the difference in the m \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} ^{6}\end{document} A probability between the early m \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} ^{6}\end{document} A-seq protocol and the refined RIP-seq protocol.
Results and discussion
Existing databases are affected by highly variable calling of m\documentclass[12pt]{minimal}
\usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \end{document}A peaks
Although existing m \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} ^{6}\end{document} A databases have been useful in providing a wealth of m \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} ^{6}\end{document} A profiles of different cell-types and tissues, there are inherent complexities that may impact the meaningful derivation of data. Non-specialist end-users usually pay little attention to these complexities and neither do they realize that these complexities affect the reliability of m \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} ^{6}\end{document} A profiles reported in these databases. The awareness of these complexities will help end-users to be more cautious when extracting data directly from these databases and understand how to make the most of these invaluable resources.
In most databases, m \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} ^{6}\end{document} A enrichment in RNA transcripts is determined by peak calling which usually involves five steps. (1) QC: check reads’ quality; (2) trimming: remove adapters and low-quality reads; (3) mapping: align reads to the genome; (4) filtering: remove rRNAs and PCR duplicates; (5) peak calling: identify the regions enriched in IP RNA relative to input RNA. The first three are standard steps employed by all databases. However, steps (4) and (5) are executed differently by various databases as summarized in Table 2.
Table 2: Comparison between settings applied in databases to call m\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \end{document}A
The levels of stringency and filtering can affect the confidence of true m \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} ^{6}\end{document} A peaks being included in these databases. For example, some databases define RNA regions as being enriched for m \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} ^{6}\end{document} A when peaks show fold-change (FC) > 1 against input (Table 2). However, low fold-change (FC < 1.5) of signal over input may lead to false positives. On the other hand, higher stringency of FC settings may lead to false negatives in some cell types that may have generally lower levels of m \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} ^{6}\end{document} A compared with others. Ideally, end-users should be allowed to alter the default settings to obtain more reliable results, but this is not possible with most m \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} ^{6}\end{document} A databases (Table 2). While some databases have included base-resolution methods to validate the presence of m \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} ^{6}\end{document} A sites in enriched m \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} ^{6}\end{document} A peaks, others have performed such validation based on the presence of the consensus m \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} ^{6}\end{document} A motif, DRACH or RRACH (Table 2). It is important for end-users to recognize that not all DRACH or RRACH motifs are methylated and m \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} ^{6}\end{document} A sites defined using such criteria require further verification.
We thus compared how the same input data can produce variable output in peak calls using an exemplar m6A-seq dataset from NOMO-1 cells (GSE87190) [63]. Peak calls derived from this accession were selectable in five databases (CVm6A, m6A-Atlas, m6A-Atlas v2.0, m6A-TSHub, and REPIC), but were either absent or unavailable for download from the other databases described in this review. A total of nine different processing pipelines were compared, as two databases reported results from multiple peak calling algorithms (m6A-Atlas v2.0 and REPIC). Database pipeline stringency varied greatly, with the number of peaks ranging from 13 770 in CVm6A to approximately 40 000 in m6A-Atlas v2.0 (when using the MACS2 caller) and m6A-TSHub, nearly a three-fold difference (Fig. 2A). CVm6a may have called the fewest peaks as it filtered out PCR duplicate reads using PICARD. Indeed, within each of the nine pipelines, the percent of peak calls that failed to intersect any of the other pipelines’ averaged 30.5%, but was highly variable (range: 0.8%–53.4%) (Fig. 2B). In contrast, only an average of 24.2% of peak calls per pipeline were highly reproducible, i.e. intersected with a peak from at least half the other pipelines (Fig. 2B). The database with the fewest unique peak calls was TRESS output from m6A-Atlas v2.0 (0.8%), while ExomePeak2 output from REPIC had the highest percentage of its peaks being highly reproducible (32.4%) (Fig. 2B).
Comparison of peak calls from NOMO-1 cells (GSE87190) across nine database pipelines from five databases; (A) barplot of the total number of peaks reported by each database pipeline, with colours representing the number of other database pipelines each peak has an intersection with; colours are per the legend of (B); (B) barplot of the percentage of each database pipeline’s peak set that intersects a peak in none, one, two to three, or \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \end{document} of the eight other database pipelines; (C, D) clustered heatmap of the Jaccard Index (C) and Simpson Index (D) for the pairwise intersections between peak coordinates reported by each database pipeline; EP: ExomePeak; EP2: ExomePeak2.
We next evaluated the pairwise concordance between each of the database pipeline peak calls. Using the Jaccard Index (number of intersecting peaks / number of peaks in set union), we observed very low similarity overall, with similarity above 0.5 only observed within databases when multiple peak callers were used (Fig. 2C). However, as Jaccard penalizes set size imbalances, we also controlled for this using Simpson Similarity (number of intersecting peaks / number of peaks in smaller set), which further highlighted that the strongest concordance was within databases rather than across them (Fig. 2C). Interestingly, the highest across-database similarity was between m6A-TSHub and m6A-Atlas, where both used ExomePeak2 as their peak caller, suggesting that algorithm choice also drives similarity. These numbers are also broadly consistent with REPIC’s statistics comparing its three peak callers, where REPIC MACS2 calls rarely reached a Jaccard similarity of >0.5 to REPIC exomePeak or MeTPeak calls within the same accession (13.6% and 3%, respectively).
We also repeated these analyses using a second accession (H1299 meRIP-seq from GSE76367 [64]), which broadly replicated these trends (Fig. S1).
Overall, we found that a single accession can produce vastly different peak calls depending on the database a user queries, owing to different (re)processing pipelines. This variability is likely in addition to that present across experiments even when controlling for the pipeline; while replicates reach approximately 80% peak overlap, this figure falls to 45% when considered across studies in a single tissue [55]. Newer databases like REPIC and m6A-Atlas v2.0 have begun to incorporate peak calls from multiple algorithms, and while this added transparency may help users prioritize reproducible results, our results show that peak calls cluster most strongly according to databases rather than algorithms, and thus that robustness should be evaluated across rather than within databases.
We note that the above example demonstrates substantial cross-database variability in the simplest case, where, for a given cell type, there exists only one accession with no replicates. However, for more common model cell types, multiple different accessions may be available, each of which may have several replicates and/or perturbations. Using HepG2 as an example, CVm6A has re-processed one accession (GSE37005), REPIC uses two (GSE37002, GSE37003), m6A-TSHub takes three (GSE90642, GSE102336, and GSE110320), and m6A-Atlas calls from four (GSE37002, GSE90642, GSE102336, and GSE110320). Given that peaks called across m6A-seq experiments already show poor concordance [55], this may serve as an additional factor reducing agreement across databases, one which end-users should be cognizant of.
Differences in the sensitivity of the early m\documentclass[12pt]{minimal}
\usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \end{document}A-seq protocol and the refined RIP-seq protocol impact the accuracy of m\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \end{document}A calling in databases
m \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} ^{6}\end{document} A-seq protocol was originally reported in 2012 and has been widely used to profile m \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} ^{6}\end{document} A in diverse cells and tissues [2]. However, to circumvent the requirement of over 300 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \mu \end{document} g of total RNA [29] or 5 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \mu \end{document} g of mRNAs, the RIP-seq protocol [27] was developed and requires as low as 0.5 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \mu \end{document} g of total RNA. For the purpose of this discussion, we termed the original m \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} ^{6}\end{document} A-seq protocol the ‘early protocol’ (EP) and RIP-seq as the ‘refined protocol’ (RP). Most m \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} ^{6}\end{document} A databases only collected the m \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} ^{6}\end{document} A-seq data generated using EP [40–43, 45] while few others included data generated using RP [44, 46, 51]. Given that the sensitivity of m \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} ^{6}\end{document} A detection using EP and RP varies considerably, the sensitivity of m \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} ^{6}\end{document} A calling varies between databases.
We compared the m \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} ^{6}\end{document} A profile of a human lung cancer cell line, A549, previously generated using EP and RP protocols, and illustrated the erroneous m \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} ^{6}\end{document} A peak calling in databases. Both EP and RP protocols utilized single-end sequencing and immunoprecipitation were performed using the same m \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} ^{6}\end{document} A-antibody (Table 3). The read length and sequencing depth of the different protocols were similar, thereby minimizing any biases in the quality of data analysed (Table 3) [27, 29]. We applied our pipeline in Fig. 3A to reanalyse m \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} ^{6}\end{document} A data generated from EP and RP, and used MACS2 to call narrow peaks. We selected peaks with fold enrichment > 4 over input control, consistent with the recommended calling of reliable peaks in chromatin immunoprecipitation sequencing (ChIP-seq) data [74].
Table 3: Comparison of the sequencing parameters, output, and antibodies used in two studies that profiled m\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \end{document}A in A549 using the early (EP) and refined (RP) protocols
Comparison of the m\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \end{document}A peaks in A549 identified using early and refined m\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \end{document}A-seq protocols; (A) a workflow to process and compare data generated using the early and refined m\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \end{document}A-profiling protocols; m\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \end{document}A profiling data sets used in the work were generated from early m\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \end{document}A-seq protocol (EP) [29] and refined RIP-seq protocol (RP) [27] for the human A549 cell line; MACS2 was used to call narrow peaks; iM6A was implemented to calculate the methylation probability of m\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \end{document}A peaks (iM6A score); (B) overlap of m\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \end{document}A peaks detected in the early m\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \end{document}A-seq protocol (EP) and the refined RIP-seq protocol (RP); (C) IGV plots of FBXW4 and MMP19 showing m\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \end{document}A peaks that are detectable by both EP and RP; (D) the number of overlapping m\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \end{document}A peaks called by both methods in the top 4000 peaks ranked by the peaks′ fold-enrichment; Venn diagram showing top 500 m\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \end{document}A peaks detected in EP that overlap with all peaks in RP and vice versa; (E) m\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \end{document}A peak signals in NRG2, MAGI2, ZNF827 and PTH1R transcripts detected using RP but not EP. Parts of the figure were generated using Bio-Render.
First, we checked the percentage overlap of peaks detected by the two protocols (Fig. 3B). In A549, the RP protocol detected three times more m \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} ^{6}\end{document} A peaks (17 888) than those detected using EP (7708). 3962 m \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} ^{6}\end{document} A peaks that account for 20 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} %\end{document} of peaks detected using RP overlapped with 50 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} %\end{document} of peaks detected using EP (Fig. 3B). Among the overlapping genes detected by EP and RP, we observed key oncogenes and tumour suppressor genes including FBXW4, MMP17, RBM15, SETDB1, PAX8, IRS1, ABL2, HDAC4,* MST1R*, GATA2, FOXL2, SOX2, TET3, TMEM127, VHL, XPC, TRAF5, RASA1, SPRTN, and CDKN2C (Figs 3C and S2), indicating the consistency in detecting m \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} ^{6}\end{document} A genes relevant to a cancer cell line. Notably, nearly 78 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} %\end{document} of peaks detected in RP are not detected using EP, indicating that RP is more sensitive than EP (Fig. 3B).
Second, we ranked the peak signals from high to low and determined whether the top 500 peaks detected in EP are also detectable using RP. We then performed the opposite by overlapping the top 500 peaks in RP with all peaks detected using EP. RP m \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} ^{6}\end{document} A peaks that overlapped with EP (274/500) were two times more than top EP peaks that were detectable using RP (154/500) (Fig. 3D), reaching a statistical significance of P < 0.03 (Kolmogorov–Smirnov test). Our analysis further suggests that peak signals detected using EP may be weaker and potentially lead to false negatives. Examples of m \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} ^{6}\end{document} A peaks in cancer-associated genes (NGR2, MAGI2, ZNF827, and PTH1R) [75–78] detected using RP but not EP are shown in Fig. 3E. Our analysis indicates that the contribution of m \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} ^{6}\end{document} A to these functionally essential genes may be missed if the profiling is based solely on EP.
In addition, some of the peaks detected exclusively by EP need to be interpreted with caution because the m \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} ^{6}\end{document} A profile indicates enriched peaks that mapped perfectly to all exons end-to-end, similar to the mRNA-seq profile. Illustrations of these types of peaks (generated using the EP protocol and documented in the REPIC database) are shown in Fig. 4A and 4B. The peaks (indicated by purple bars) were not identified as being enriched over input in the RP data (Fig. 4B). Thus, data generated by EP require additional filters to remove these potential false-positive peaks, which may be caused by the non-specific binding of the m \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} ^{6}\end{document} A antibody during library preparation.
Inconsistencies of the m\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \end{document}A peaks in A549 identified using early and refined m\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \end{document}A-seq protocols; (A) a screenshot from REPIC that indicates m\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \end{document}A sites in ARF1, TGM2, NDUFA2, and TKT in human A549 cell lines; (B) IGV plots showing m\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \end{document}A peaks in ARF1, TGM2, NDUFA2, and TKT detected in EP- but not RP-generated data.
Third, we checked the overlap of the high confidence m \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} ^{6}\end{document} A sites in the human A549 cell line among all detected m \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} ^{6}\end{document} A sites (Fig. 5A and 5B). As shown in Fig. 5B, m \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} ^{6}\end{document} A peaks detected by the RP protocol reported a higher overlap percentage (18.79 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} %\end{document} , 3361) than the EP protocol (13.01 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} %\end{document} , 1003) in Fig. 5A. Furthermore, we ranked the m \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} ^{6}\end{document} A peaks detected via EP and RP protocols separately using the scores generated by a recently published predictor of m \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} ^{6}\end{document} A sites based on deep-learning (iM6A) [73]. We found that for sites with high confidence iM6A scores (probability value > 0.1), RP detected twice as many m \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} ^{6}\end{document} A sites as EP (Fig. 5C and 5D). We further examined 1000 m \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} ^{6}\end{document} A sites with top-ranked iM6A scores and found that m \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} ^{6}\end{document} A sites generated using RP have significantly higher iM6A scores with a P value of 1e-230 (Fig. 5E and 5F). While in some cases both EP and RP protocols can discover peaks with equally high iM6A scores (Fig. 5G and 5H, Fig. S3), in many cases, the iM6A score imputed by the RP method was higher than that of EP. This result indicates that the RP method of m \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} ^{6}\end{document} A profiling is typically more sensitive. Collectively, understanding the protocols used to generate the m \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} ^{6}\end{document} A data is essential to determine whether m \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} ^{6}\end{document} A are likely to be correctly identified in mRNA transcripts presented in m \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} ^{6}\end{document} A-related databases.
High confidence m\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \end{document}A peaks in A549 called in data generated using early and refined m\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \end{document}A-seq protocols via miCLIP-seq validation and iM6A scores; (A, B): the distribution of peaks containing a high confidence m\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \end{document}A site detected using the early m\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \end{document}A-seq protocol, EP (A), and the refined RIP-seq protocol, RP (B); (C) the distribution of m\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \end{document}A scores for all identified sites; (D) histogram showing the number of m\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \end{document}A sites in EP and RP, plotted against m\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \end{document}A score; (E) the distribution of m\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \end{document}A scores for all identified top 1000 sites (cut-off at 0.8 for x-axis); (F) boxplot of m\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \end{document}A scores for top 1000 sites identified using EP and RP; (G, H): IGV plot of PCED1A (G) and ZNF593; (H) containing a peak with a high score of iM6A in data generated using EP and RP; m\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \end{document}A sites with a high iM6A score are highlighted in orange; the table above the plots shows iM6A scores.
The association between m\documentclass[12pt]{minimal}
\usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \end{document}A and SNPs reported in databases
The presence of SNPs within the DRACH motifs can lead to the loss or gain of m \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} ^{6}\end{document} A sites, thereby affecting the expression, stability, and translation of mRNAs. Most databases employed a random forest model to predict whether the methylation status of a m \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} ^{6}\end{document} A site is altered by variants that are within the flanking regions 30 nucleotides (both upstream and downstream) of a given m \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} ^{6}\end{document} A residue in the DRACH motif. One example is shown in Fig. 6A where PPKAG2 has a SNP (highlighted in red rectangle) which is 21bp apart from the DRACH motif.
Issues of m\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \end{document}A-related SNP databases; (A) screenshot showing examples of SNPs outside m\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \end{document}A motifs; red rectangles are used to highlight the SNP variant; (B) screenshot from RMVar and m6A-TSHub showing high-confidence mutations that altered m\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \end{document}A motifs; selected SNPs are underlined; blue rectangles are used to highlight the example of genes; (C) mutation information from COSMIC for cases highlighted in blue rectangles in (B).
In addition, databases do not include information on the status of SNPs within m \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} ^{6}\end{document} A sites regarding whether they are synonymous or non-synonymous SNPs. If an SNP within a given m \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} ^{6}\end{document} A site is non-synonymous and located in a coding exon, the SNP will lead to amino acid substitution. Consequently, the pathogenicity of the SNP cannot be attributed to a change in m \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} ^{6}\end{document} A alone. Four examples to illustrate this scenario extracted from RMVar and m6A-TSHub are shown in blue rectangles in Fig. 6B and 6C. According to the Catalogue of Somatic Mutations in Cancer (COSMIC) database, all these four high-confidence somatic variants are described as missense and at least three of them may lead to disease pathogenicity regardless of whether m \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} ^{6}\end{document} A is present at these sites (Fig. 6C).
Towards overcoming the pitfalls in m\documentclass[12pt]{minimal}
\usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \end{document}A-related databases generated based on peak-calling experiments
Several improvements can be performed to generate reliable m \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} ^{6}\end{document} A-related databases that will benefit non-specialist end-users. First, m \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} ^{6}\end{document} A-related databases that incorporate data from peak-calling experiments should disclose information regarding the m \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} ^{6}\end{document} A-profiling methods used to obtain the data and allow end-users to select data that they desire based on analysis methods. Second, end-users should be allowed to alter the stringency of the analysis method used to minimize false positive and negative results. Third, datasets included in databases should be reanalysed using superior tools such as TRESS rather than MACS2 or exomePeak to correct for biological variance between replicates and improve the accuracy [79]. Indeed, the analysis using TRESS in m6A-Atlas v2.0 revealed fewer but more reproducible peaks compared with other methods, which indicates that additional peaks detected by other methods may not be as robust. Where available, METTL3 depletion experiments performed in parallel should be included as negative controls to identify true m \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} ^{6}\end{document} A peaks in databases. Fourth, the iM6A model can be incorporated into databases to predict the probability of m \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} ^{6}\end{document} A peaks being real. This feature was not previously possible in most m \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} ^{6}\end{document} A-related databases as they were created prior to the publication of iM6A. Finally, databases reporting m \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} ^{6}\end{document} A-associated SNPs should contain a filter for synonymous and non-synonymous SNPs and focus on SNPs in the DRACH motifs that are confirmed to be methylated.
Conclusion and future work
In conclusion, while m \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} ^{6}\end{document} A databases provide a rich source to infer biological roles of m \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} ^{6}\end{document} A in different cellular contexts, the understanding of how the data were generated and parameters that have been set to call m \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} ^{6}\end{document} A are critical to derive biologically meaningful conclusions. By discussing the variability and undisclosed information related to m \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} ^{6}\end{document} A databases we hope that end-users will become aware of ‘traps’ that may lead to inaccurate interpretation of data. Some of these ‘traps’ arise consequent to issues associated with older m \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} ^{6}\end{document} A-seq technologies such as non-specific binding of antibodies and arbitrary cut-off used to call m \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} ^{6}\end{document} A, and not due to variability in the data processing parameters per se. Recently, long-read techniques, such as Oxford nanopore sequencing, provided a novel way to measure m \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} ^{6}\end{document} A levels for each adenosine at a transcriptomic scale, but few large-scale studies are available due to higher sequencing costs to acquire sufficient sequencing depth [80]. Similarly, base-resolution m \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} ^{6}\end{document} A profiling methods analogous to bisulfite-sequencing of DNA methylation have recently been developed including GLORI [61], m \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} ^{6}\end{document} A-SAC-seq [81], and eTAM-seq [62] but very few studies are currently available. Future generation of databases based on these base-resolution methods of m \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} ^{6}\end{document} A profiling may provide more reliable resources to mine m \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} ^{6}\end{document} A datasets with higher accuracy. However, until that becomes possible, databases generated based on antibody-based techniques are likely to be utilized and continue to be created. Our recommendations should give future creators of m \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} ^{6}\end{document} A-related databases insights into creating more useful databases that will benefit non-specialist end-users. As antibody-based methods have also been used to profile other mRNA modifications including m \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} ^{1}\end{document} A, m \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} ^{6}\end{document} Am, and 5hmC, lessons learned from m \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} ^{6}\end{document} A-related databases would be applicable to interpreting the data in current and future databases created for these emerging RNA modifications.
Key Points
- Current m \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} ^{6}\end{document} A databases re-call peaks from sequencing data. Differences in processing pipelines drive variability in peak number and coordinates, with only moderate reproducibility.
- Databases that report m \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} ^{6}\end{document} A peaks do not explicitly disclose the protocols used for generating the m \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} ^{6}\end{document} A-immunoprecipitation sequencing data for each sample. We reveal that a more recent refined RIP-seq protocol is more sensitive and reliable than the m \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} ^{6}\end{document} A-seq protocol developed prior. The inclusion of data generated using the early m \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} ^{6}\end{document} A-seq protocol needs further filtering to avoid false positives.
- Several m \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} ^{6}\end{document} A-related databases reported m \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} ^{6}\end{document} A-associated SNPs that are located over 20 nucleotides from m \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} ^{6}\end{document} A sites, raising the question of whether they lead to altered m \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} ^{6}\end{document} A. Moreover, databases do not include information related to synonymous and non-synonymous SNPs. Non-synomymous SNPs may lead to functional consequences independently of m \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} ^{6}\end{document} A status.
Supplementary Material
SupplementaryInformation_bbae434
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Desrosiers R , Friderici K, Rottman F. Identification of methylated nucleosides in messenger RNA from Novikoff hepatoma cells. Proc Natl Acad Sci U S A 1974-10;71:3971–5. 10.1073/pnas.71.10.3971.4372599 PMC 434308 · doi ↗ · pubmed ↗
- 2Dominissini D , Moshitch-Moshkovitz S, Schwartz S. et al. Topology of the human and mouse m 6A RNA methylomes revealed by m 6A-seq. Nature 2012;485:201–6. 10.1038/nature 11112.22575960 · doi ↗ · pubmed ↗
- 3Shi H , Wei J, He C. Where, when, and how: Context-dependent functions of RNA methylation writers, readers, and erasers. Mol Cell 2019;74:640–50. 10.1016/j.molcel.2019.04.025.31100245 PMC 6527355 · doi ↗ · pubmed ↗
- 4Yang Y , Hsu PJ, Chen Y-S. et al. Dynamic transcriptomic m 6A decoration: Writers, erasers, readers and functions in RNA metabolism. Cell Res 2018;28:616–24. 10.1038/s 41422-018-0040-8.29789545 PMC 5993786 · doi ↗ · pubmed ↗
- 5He PC , He C. m 6a rna methylation: From mechanisms to therapeutic potential. EMBO J 2021;40:e 105977. 10.15252/embj.2020105977.33470439 PMC 7849164 · doi ↗ · pubmed ↗
- 6Liu N , Pan T. N 6-methyladenosine–encoded epitranscriptomics. Nat Struct Mol Biol 2016;23:98–102. 10.1038/nsmb.3162.26840897 · doi ↗ · pubmed ↗
- 7Zhang C , Jinrong F, Zhou Y. A review in research progress concerning m 6A methylation and immunoregulation. Front Immunol 2019;10:922. 10.3389/fimmu.2019.00922.31080453 PMC 6497756 · doi ↗ · pubmed ↗
- 8Wei W , Ji X, Guo X. et al. Regulatory role of N 6–methyladenosine (m 6A) methylation in RNA processing and human diseases. J Cell Biochem 2017;118:2534–43. 10.1002/jcb.25967.28256005 · doi ↗ · pubmed ↗