Chlomito: a novel tool for precise elimination of organelle genome contamination from nuclear genome assembly
Wei Song, Chong Li, Yanming Lu, Dawei Shen, Yunxiao Jia, Yixin Huo, Weilan Piao, Hua Jin

TL;DR
Chlomito is a new tool that accurately removes contamination from organelle genomes in nuclear genome assemblies, improving genome quality.
Contribution
Chlomito introduces new metrics (ALCR and SDR) for precise identification and removal of organelle genome contamination.
Findings
Chlomito accurately detects organelle-derived contigs in nuclear genome assemblies.
The tool covers most regions of the organelle reference genomes, showing high efficiency and precision.
Chlomito is packaged into a Docker image for user convenience and simplified workflow.
Abstract
Accurate reference genomes are fundamental to understanding biological evolution, biodiversity, hereditary phenomena and diseases. However, many assembled nuclear chromosomes are often contaminated by organelle genomes, which will mislead bioinformatic analysis, and genomic and transcriptomic data interpretation. To address this issue, we developed a tool named Chlomito, aiming at precise identification and elimination of organelle genome contamination from nuclear genome assembly. Compared to conventional approaches, Chlomito utilized new metrics, alignment length coverage ratio (ALCR) and sequencing depth ratio (SDR), thereby effectively distinguishing true organelle genome sequences from those transferred into nuclear genomes via horizontal gene transfer (HGT). The accuracy of Chlomito was tested using sequencing data from Plum, Mango and Arabidopsis. The results confirmed that…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
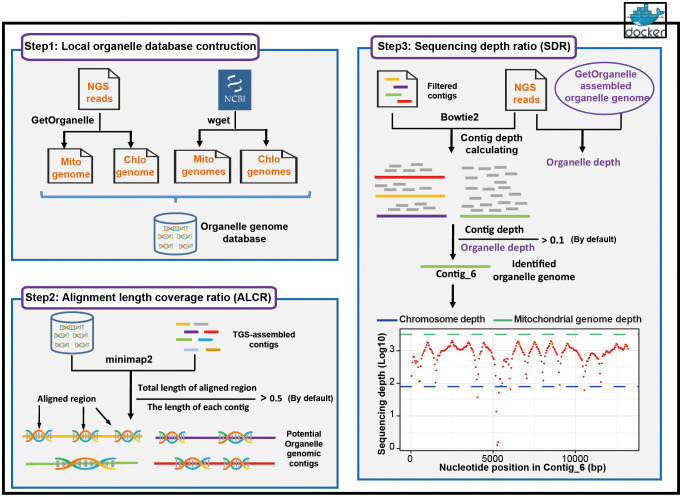 Figure 1
Figure 1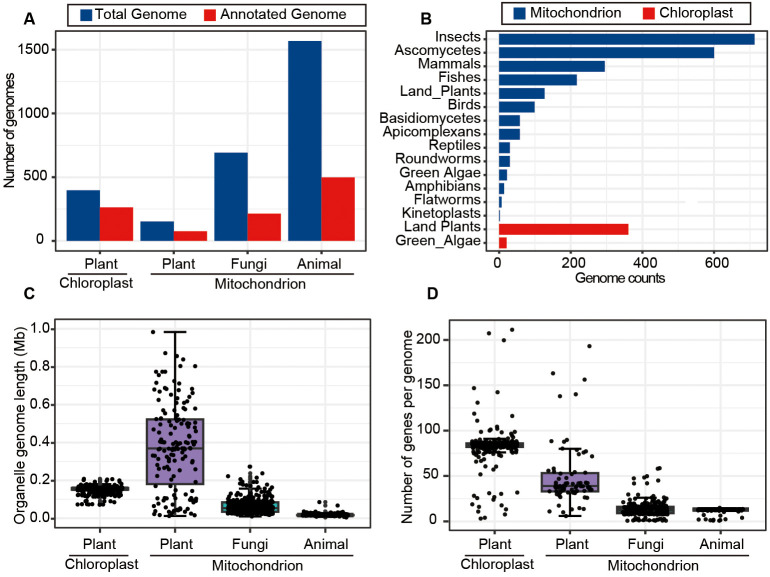 Figure 2
Figure 2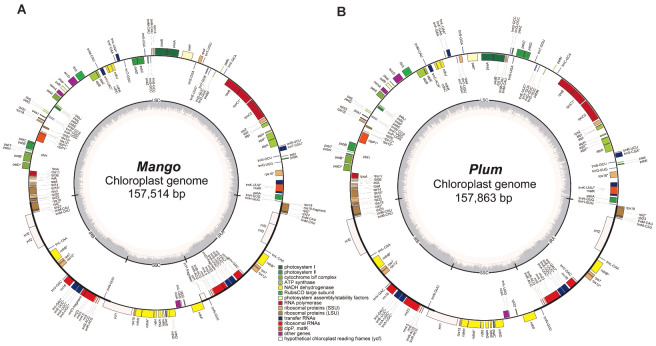 Figure 3
Figure 3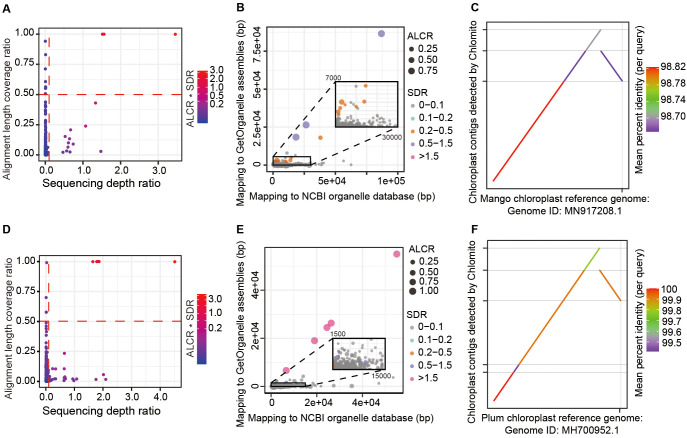 Figure 4
Figure 4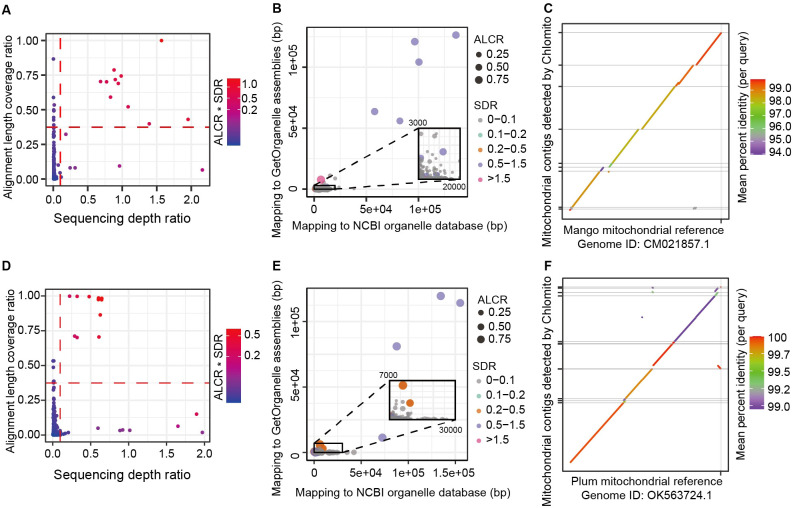 Figure 5
Figure 5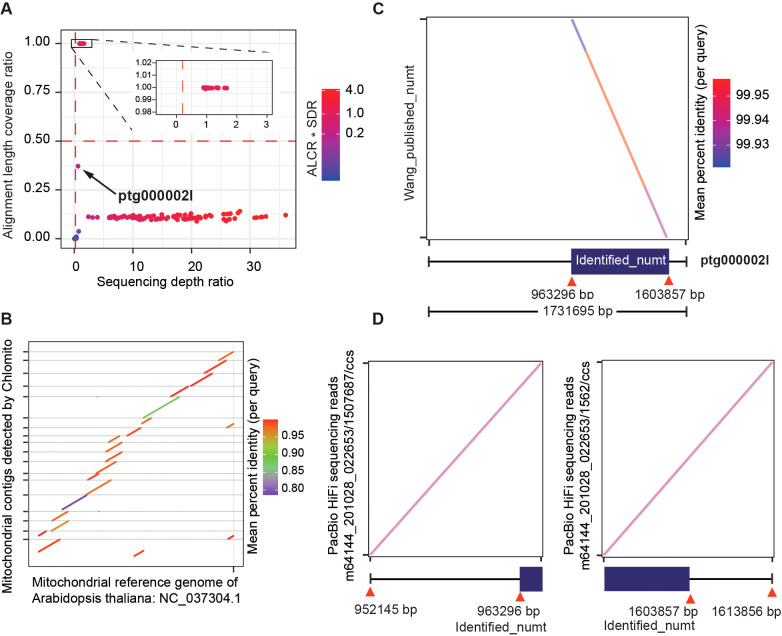 Figure 6
Figure 6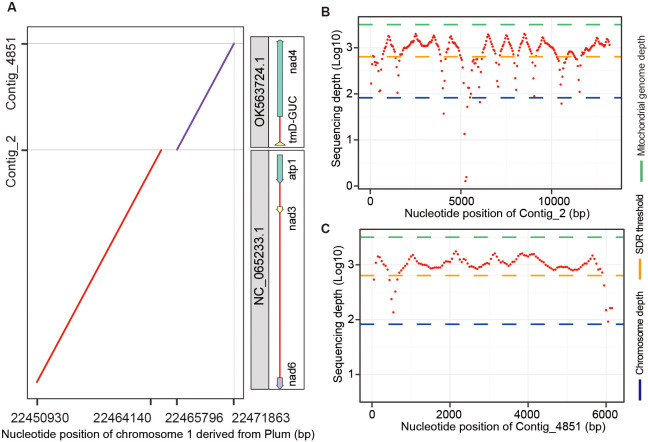 Figure 7
Figure 7Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsGenomics and Phylogenetic Studies · Chromosomal and Genetic Variations · Plant Taxonomy and Phylogenetics
Introduction
1
With the widespread application of high-throughput sequencing technology, researchers can rapidly obtain genomes of various species (Rhoads and Au, 2015; Goodwin et al., 2016; Jain et al., 2018). For chromosome-level de-novo genome assembly, long reads from third-generation sequencing (TGS) or short reads from second/next-generation sequencing (SGS/NGS) are first assembled into contigs. Then, these contigs are anchored into chromosomes based on Hi-C sequencing, thereby compleling nuclear chromosome assembly (Du et al., 2022). However, during genome assembly, the issue of organelle genome contamination often arises, where the sequences from mitochondrial DNA (mtDNA) and chloroplast DNA (cpDNA) are mistakenly assembled into nuclear genome. This phenomenon occurs because organelle DNA is co-extracted with nuclear DNA during genomic DNA purification, producing a mixed sequencing data set. Since hundreds copies of organelle genomes exist within a single cell with extremely smaller sizes compared to the nuclear genomes (Pyke, 1999), they are overrepresented in the sequencing data and high-frequently mis-assembled into nuclear genomes. Furthermore, organelle genome sequences exhibit significant similarity to certain nuclear genome sequences, particularly those organelle genes had transferred into nuclear genomes through horizontal gene transfer (HGT) (Martin, 2003; Timmis et al., 2004; Wei et al., 2022; Wang et al., 2024). Thus, it is challenging to accurately distinguish contigs derived from organelle genomes among all assembled contigs, especially those containing sequences transferred from the organelle genomes through HGT. Accurate identification and elimination of organelle genome sequences are essential for minimizing the contamination issue and will enhance the quality of genome assembly.
To identify and remove organelle genome contamination from nuclear genome assembly data, current methods primarily employ two approaches: the experimental removal prior to sequencing and the bioinformatic identification after assembly. For experimental removal, the density gradient centrifugation technique can be utilized to deplete organelle DNA during nuclear genomic DNA extraction, hence the contamination is reduced in downstream sequencing data (Lutz et al., 2011; Sikorskaite et al., 2013; Sandhya et al., 2020). However, the density gradient centrifugation is not easy to carry out, and requires a large amount of material for DNA extraction but generates low DNA yield. Thus, most reported de-novo genome assembly did not include this step. Also, experimental separation is often incomplete. Alternatively, for bioinformatic identification, the most widely adopted approach is to align assembled contigs to organelle reference genomes, followed by filtering based on alignment lengths (Howe et al., 2021; Mishra et al., 2021; Rhie et al., 2021; Zhang et al., 2024) or sequence similarity (Shirasawa et al., 2021; Bae et al., 2023; Yu et al., 2024). Though effective in reducing contamination, these computational approaches have limitations. It ignored potential HGT of organelle sequences into the nuclear genome (Cecchin et al., 2019; Allio et al., 2020; Kenny et al., 2020; Martin et al., 2023). Due to such transfer, the fragments of organelle genomes were inserted in the nuclear genomes, therefore, traditional sequence similarity-based methods hardly distinguish organelle genomes from the nuclear HGT regions. Additionally, current methods often require pre-assembled reference organelle genomes, limiting their applicability in the species without well-established organelle references. Moreover, the implementation of current methods generally lacks support from integrated and user-friendly software, requires users to manually perform all steps. The data processing is still time-consuming and prone to errors, particularly when dealing with large numbers of data sets.
To address the issue identifying organelle genome sequences from genomic assembly accurately, we established a novel method, which employed two key filtering criteria: the alignment length coverage ratio (ALCR) and sequencing depth ratio (SDR). The ALCR refers to the proportion of a contig’s total length that is aligned with the organelle reference genome relative to the total length of the contig. This criterion can differentiate contigs that contain only small pieces of organelle DNA, which more likely arise from HGT, as these fragments usually constitute only a small portion of the contig. Therefore, a low ALCR may indicate that the contig belongs to nuclear genome rather than organelle genome (Zhu et al., 2021; Nath et al., 2022; Hao et al., 2023; Zhou et al., 2023b). Meanwhile, the SDR refers to the ratio of each coting’s sequencing depth to the average sequencing depth of the organelle genome. Given that organelle genomes exist in many copies within a cell, they typically exhibit higher sequencing depths than nuclear genomes (Sanita Lima et al., 2016; Wang et al., 2018; Li et al., 2021; Giorgashvili et al., 2022; Zhou et al., 2023a). Therefore, a contig with a high sequencing depth ratio, similar to the average of the organelle genome, is more likely to be a part of the organelle genome. By combining these two metrics, we can significantly improve the accuracy of identifying and removing organelle genome sequences from genome assembly data.
Furthermore, to facilitate usage by researchers with limited bioinformatics experience, we have implemented this new approach as easy-to-use software and packaged it as a Docker image, enabling easy distribution and execution across diverse computing platforms with a single command. We validated the accuracy and reliability of our tool using sequencing data from Plum (Prunus salicina) (Liu et al., 2020), Mango (Mangifera indica) (Wang et al., 2020) and Arabidopsis (Arabidopsis thaliana) (Wang et al., 2022). Our software can not only accurately identify organelle genome contigs from genome assembly, but also accurately distinguish native organelle sequences from those inserted into the nuclear genome via HGT. Our tool will offer an accurate and effective solution for eliminating organelle DNA fragments from genome assembly contigs, hold significant merit in improving chromosome assembly, and deepen our understanding of the complex interactions between organelle and nuclear genomes.
Materials and methods
2
Availability of data and materials
2.1
To validate the accuracy of the Chlomito software in detecting organelle genome sequences, we utilized sequencing data of Mango and Plum from the NCBI Bioproject database, with accession numbers PRJNA487154 and PRJNA574159, respectively. The raw sequencing data for the PacBio HiFi reads and Illumina short reads of Arabidopsis were obtained from the National Genomics Data Center, Beijing Institute of Genomics, Chinese Academy of Sciences/China National Center for Bioinformation (GSA: CRA004538). These datasets include high-quality second and third-generation sequencing data, which were utilized for organelle genome identification and chromosome-level genome assembly.
Installation and implementation of Chlomito
2.2
Chlomito is Python (v3.8.5)-based software provided in the form of a Docker image. The image is accessible at https://hub.docker.com/repository/docker/songweidocker/chlomito. All analyses were conducted on an Ubuntu Linux 18.04.3 server, equipped with two Intel Xeon processors (32 cores each, totaling 64 threads) and 512 GB of RAM. The user manual for Chlomito is available on GitHub (https://github.com/songwei-hxb/chlomito).
Chlomito can be installed using the Docker v19.03.5 command:
docker pull songweidocker/chlomito:v1
The command for running Chlomito organelle genome identification and removing is as follow:
docker run –rm -v/var/run/docker.sock:/var/run/docker.sock -v pwd:/data -w/data songweidocker/chlomito:v1 chlomito -species plant -raw_genome genome_contigs.fasta -NGS_1 ngs_1.fastq -NGS_2 ngs_2.fastq -output identify_result -mito_ALCR_cutoff 0.5 -mito_SDR_cutoff 0.1 -chlo_ALCR_cutoff 0.5 -chlo_SDR_cutoff 0.1 -threads 60
Contig-level genome assembly
2.3
Flye v2.9 (Kolmogorov et al., 2019) is genome assembler software designed for long-read sequencing data from third-generation platforms such as PacBio and Oxford Nanopore. It is capable of assembling raw error-prone long reads into contiguous genomic sequences known as contigs. The goal of Flye is to generate high-quality genome assembly, especially for large or complex genomes. In this study, we utilized Flye to assemble PacBio sequencing data of Mango and Plum into genome assembly contigs. Due to the high error rate of TGS data in PacBio CLR reads and Nanopore reads, the assembled contigs were then corrected using Racon v1.3.1 (Vaser et al., 2017) and Pilon v1.22 (Walker et al., 2014).
Construction of organelle genome database
2.4
The mitochondria and chloroplast organelle genomes were firstly assembled from SGS data using GetOrganelle v1.7.1 (Jin et al., 2020). GetOrganelle is a powerful genomics software tool specifically designed for efficient assembly of mitochondrial and chloroplast genomes. It is capable of simultaneously assembling organelle genomes from both mitochondria and chloroplast. Compared to other similar software tools, GetOrganelle demonstrates superior performance in terms of both accuracy and speed for organelle genome assembly. After that, we merged the mitochondrial and chloroplast genomes published in the NCBI organelle database with organelle genomes assembled using GetOrganelle, and created a comprehensive local organelle genome database. Since the local database integrated existing public data resources with high-precision assembly outcomes, it could offer more comprehensive and accurate reference for organelle genomes.
The annotation of chloroplast and mitochondrial genomes
2.5
The chloroplast and mitochondria genome sequences were annotated with GeSeq (Tillich et al., 2017) and OGDRAW (Lohse et al., 2013). GeSeq pipeline analysis was performed using the annotation packages ARAGORN (Laslett and Canback, 2004), blatN (Kent, 2002), Chloe (Zhong, 2020) and HMMER (Eddy, 2011). GeSeq is a user-friendly online service specifically designed for the annotation of mitochondrial and chloroplast genomes. This platform enables researchers to upload unannotated DNA sequences and utilizes its database of existing high-quality annotations to identify and label genes, coding sequences, and other significant genomic features.
Calculation of alignment length coverage ratio
2.6
Following the construction of local organelle genome database, all contigs assembled by the Flye v2.9 software were aligned against this database using Minimap2 v2.17 (Li, 2018). Subsequent to the alignment process, Alignment Length Coverage Ratio (ALCR) was calculated for each contig. The core filtering criterion ALCR is defined as the ratio of the aligned length sum from a contig to its total length, which can be formulated as:
In the formula, ALCR(contig) is the ALCR value for a given contig, Σaligned_length(contig, ref) is the sum of lengths of all aligned regions (1 to n) between the contig and the reference organelle genome, and total_length(contig) is the total length of the contig. A higher ALCR value indicates greater similarity between the contig and the reference organelle genome, and thus a higher chance that the contig is from the organelle genome. Unlike previously reported methods, the calculation of ALCR does not solely rely on the single longest alignment region. Instead, it aggregates the lengths of all contig regions that align with the organelle genome reference. This approach offers a more comprehensive reflection of the alignment coverage between the contig and the organelle genomes. Finally, by comparing the aggregated alignment length of each contig against its total length, the alignment length coverage ratio for each contig is computed.
Calculation of sequencing depth ratio
2.7
The sequencing depth ratio (SDR) refers to the ratio between the sequencing depth of each contig and the average sequencing depth of the organelle genome, which can be formulated as:
In the formula, SDR(contig) is the SDR value for a given contig, depth(contig) is the average SGS depth of the contig, and avg_depth(organelle_genome) is the average SGS depth of the organelle genome assembled by GetOrganelle. The average sequencing depth of the organelle genome is determined by aligning the SGS reads to the organelle genome assembled by GetOrganelle v1.7.1 using Bowtie2 v2.4.2 (Langmead and Salzberg, 2012), which generates a SAM file. This SAM file is then processed by Samtools v1.6 (Li et al., 2009) to produce a sorted BAM file with depth information. Finally, Bedtools v2.30.0 (Quinlan and Hall, 2010) is utilized to analyze this depth data and calculate the average sequencing depth across the organelle genome. The method for calculating the sequencing depth of each contig is identical to that used for the organelle genome. Upon completion of these calculations, the sequencing depth for each contig is divided by the average sequencing depth of the organelle genome to obtain SDR for each contig.
Identification of organelle sequences
2.8
After calculating the ALCR and SDR values for each contig using the locally constructed organelle genome database and SGS data, contigs belonging to the organelle genome are identified from genome assembly contigs based on ALCR and SDR filtering thresholds inputted by the user. Here, we used thresholds ALCR>0.5 and SDR>0.1 at the first round of filtering. The filtering thresholds can be further optimized according to the ALCR and SDR visualization scatter plot generated after running Chlomito. By utilizing adjusted filtering thresholds, the genome assembly contigs can be filtered and selected again, resulting in more precise outcomes.
Chromosomal-level genome assembly
2.9
The genome sizes of various species were calculated using jellyfish v2.2.10 (Marcais and Kingsford, 2011) and GenomeScope v2.0 (Vurture et al., 2017) with SGS data and input into Flye for contig-level genome assembly with TGS data. After contig-level genome assembly, contig sequences were corrected with SGS reads using racon v1.3.1 and pilon v1.22, and redundancy was reduced using purge_dups v1.2.5 (Guan et al., 2020). Hi-C sequencing data were aligned to the deduplicated contigs using HiC-Pro v3.1.0 (Servant et al., 2015), and finally, Allhic v0.9.8 (Zhang et al., 2019) was used to cluster, order, and orient the contigs based on Hi-C alignment results, achieving the final chromosomal-level genome assembly. Gaps or missing regions may be present in genome assembly due to the limitations of sequencing technologies. To obtain more complete and accurate genome sequences, we applied two approaches - Abyss Sealer v2.0.2 (Jackman et al., 2017) and TGS-GapCloser v1.1.1 (Xu et al., 2020) - for closing gaps in our chromosome-level genome assembly. TGS-GapCloser v1.1.1 utilizes long reads from TGS platforms to fill gaps between contigs and extend contig ends based on overlaps between contigs and long reads. Abyss Sealer v2.0.2 is a computational tool that seals gaps in genome assembly by aligning Illumina short reads to contig ends and performing local assembly to generate consensus sequences for gap regions. The methods applied in this study for chromosomal-level genome assembly are based on the previous study (Song et al., 2024).
Results
3
The development of Chlomito software
3.1
Chlomito has two main functions, assembly of organelle genomes with NGS reads and screening contigs originated from organelle genomes. These functions are achieved through the workflow comprising three parts: the construction of local organelle genome database, organelle genome contig identification based on ALCR, and organelle genome contig identification based on SDR (Figure 1).
Workflow of the Chlomito software package.
The construction of local organelle genome database
3.2
At the first step, Chlomito constructs a local organelle genome database by combining two approaches (Figure 1, step 1). The initial approach employs GetOrganelle to assemble mitochondrial and chloroplast genomes with SGS data. This is particularly valuable for the species without publicly-available organelle genome references, although the short-read assembly is sometimes incomplete. To further complement the database, the second approach downloads published high-quality organelle genomes from NCBI organelle database. With these approaches, the constructed local database is able to avoid the limitations from relying on a single data source, offering a broad and reliable organelle genome reference for downstream analysis.
Organelle genome identification based on ALCR
3.3
At the second step of Chlomito, organelle genome contigs are identified based on alignment length coverage ratio (ALCR). Chlomito preliminarily screens for potential organelle genomic sequences by aligning TGS-assembled genome contigs to the local database and filtering based on ALCR of the alignment (Figure 1, step 2). The core filtering criterion ALCR is defined as the ratio of the aligned length sum from a contig to its total length. Traditional methods typically consider only the longest length aligned between a contig and the organelle reference genome. In contrast, the alignment length of a contig in our approach is the sum of all aligned region lengths. This provides a more comprehensive assessment for the similarity between a contig and the organelle genome, improving the accuracy and sensitivity of organelle genome contig identification. In addition, compared to traditional methods, ALCR can also effectively distinguish organelle genome sequences from those inserted into the nuclear genome via HGT, as HGT insertions tend to be smaller, holding a lower ALCR value.
Organelle genome identification based on SDR
3.4
At the third step, Chlomito employs sequencing depth ratio (SDR) to further validate the organelle genome contigs previously filtered by the ALCR criteria (Figure 1, step 3). SDR refers to the ratio of the average sequencing depth of a contig to the average sequencing depth of the organelle genome. Given that the copy number of organelle genome is significantly higher in each cell compared to the nuclear genome, the sequencing depth ratio can be utilized to further distinguish organelle genomes from nuclear genomes. Considering the variable copy numbers of organelle genomes across various tissues and developmental stages (Preuten et al., 2010), it is difficult to accurately estimate the precise ratio of organelle to nuclear genome. Therefore, instead of using nuclear genome sequencing depth as a reference (Wang et al., 2018), the SDR approach adopts a method of comparing the sequencing depth of each contig against the average sequencing depth of organelle genomes to more accurately identify contigs derived from organelle genomes.
In summary, by utilizing both ALCR and SDR filtering methods, Chlomito can accurately identify organelle genome contigs from the total contigs. Furthermore, it can effectively reduce the misidentification of nuclear genome contigs as organelle genomes caused by HGT of organelle genomes.
The investigation into mitochondrial and chloroplast genomes in the NCBI database
3.5
To gain comprehensive understanding about the characteristics of mitochondrial and chloroplast genomes across a wide range of organisms, we explored genome sizes, gene numbers, and other features for mitochondrial and chloroplast genomes listed in the NCBI organelle database (https://www.ncbi.nlm.nih.gov/genome/browse#!/organelles/). The results revealed that the database contains 152 mitochondrial genomes (mitogenomes) and 263 chloroplast genomes (chlorogenomes) derived from plants, with approximately 50% to 60% of these genomes being annotated. In comparison, the numbers of animal and fungal mitogenomes were significantly higher, with 1,568 and 692 genomes respectively. However, the annotation rates for animal and fungal mitogenomes were lower, standing at only 30% (Figure 2A). Further inspection showed that most mitogenomes in the database were from insects in animal and ascomycetes in fungi, while chlorogenomes were predominantly from land plants and green algae (Figure 2B).
Overview of mitochondrial and chloroplast genome data in the NCBI organelle genome database. (A) Counts of the total and annotated mitochondrial and chloroplast genomes across typical kingdoms. (B) The numbers of mitochondrial and chloroplast genomes assembled for various taxonomic groups. (C) The length distribution of mitochondrial and chloroplast genomes for plants, animals and fungi. (D) The numbers of genes contained in mitochondrial and chloroplast genomes across different species.
Plant chlorogenomes exhibited relative stability in terms of genome lengths and gene numbers, averaging around 0.15 Mb in size and containing ~82 genes on average (Figures 2C, D). In contrast, plant mitogenomes displayed greater variability in both lengths and gene numbers as previously reported (Bendich, 2010; Oldenburg and Bendich, 2015), suggesting the potential involvement of more complex evolutionary processes (Kubo and Newton, 2008). In terms of animal mitogenomes, we found a high degree of conservation, with an average size of 0.017 Mb and typically including 13 genes. Fungal mitogenomes, on the other hand, had an average size of 0.063 Mb and contained an average of 14 genes (Figures 2C, D). These analyses thoroughly characterized the features of organelle genome sizes and annotated status, as well as gene numbers, across different kingdoms such as Plantae, Animalia, and fungi, providing crucial support for effectively identifying and removing organelle genome segments from genomic assembly sequences in future research.
The performance of Chlomito on the detection of chloroplast genomes
3.6
To evaluate the performance of Chlomito in identifying chlorogenomes, we tested it with sequencing data derived from Plum (Prunus salicina) and Mango (Mangifera indica). Prior to detecting chloroplast genomic sequences from the contigs assembled from TGS reads, we first assembled the chlorogenomes of Mango and Plum from their NGS reads using Getorganelle respectively, and the assembly of each species generated a single sequence of complete chlorogenome. Collinearity analysis revealed high consistency between the assembled chlorogenomes and the published reference genomes in both Mango and Plum (Supplementary Figure S1). This demonstrated the accuracy and reliability of the Getorganelle assembly for downstream analysis. We then annotated the chlorogenomes of Mango and Plum using Geseq and found that they contained similar numbers of genes with highly similar arrangements (Figure 3). To investigate the structural conservation of chlorogenomes across diverse plant species, we compared the chlorogenomes of Mango and Plum with those of other plant species including Arabidopsis thaliana and Zea mays. The results showed that chlorogenomes were highly conserved in gene contents and orders across diverse plant species analyzed here (Supplementary Figure S2), implying that chlorogenomes may be structurally conserved across diverse plants.
Chloroplast genome annotation of Mango (A) and Plum (B).
After assembling the chlorogenomes of Mango and Plum using GetOrganelle, we integrated these sequences with the NCBI chlorogenome database to create a localized chloroplast database. Then, the TGS-assembled genome contigs were aligned to the local organelle genome database. We next employed two key metrics to identify chloroplast-derived contigs among the total TGS-assembled contigs. The first metric is Alignment Length Coverage Ratio (ALCR), which calculates the ratio of the aligned sum length of each contig to the total length of that contig. The second metric is Sequencing Depth Ratio (SDR), which computes the sequencing depth of each contig to the average sequencing depth of the assembled chlorogenome. Based on default parameters ALCR>0.5 and SDR>0.1, we identified 3 and 5 potential chloroplast-derived contigs from Mango and Plum samples respectively (Figures 4A, D). These contigs showed similar alignment lengths in the GetOrganelle-assembled and the NCBI database chlorogenomes (Figures 4B, E), further validating the reliability of the chloroplast genomic contigs detected by Chlomito. Collinearity analysis displayed excellent consistency between these identified contigs and the chloroplast reference genomes, and two inverted repeat regions of the chlorogenomes (IRA and IRB) were also clearly observed in the co-linearity analysis (Figures 4C, F). These results further confirmed that these contigs were indeed derived from the chlorogenomes and were completely detected.
Chlomito accurately identifies chloroplast-derived contigs and validates their collinearity with chloroplast reference genomes from Mango (A–C) and Plum (D–F). (A, D) Identification of chloroplast-derived contigs in Mango (A) and Plum (D) based on ALCR and SDR metrics. (B, E) Alignment lengths of Mango (B) and Plum (E) contigs with chloroplast genomes assembled using GetOrganelle and downloaded from NCBI database. (C, F) Collinearity analysis of Mango (C) and Plum (F) contigs identified by Chlomito against published chloroplast reference genomes.
In addition to the chloroplast-derived contigs, we also observed some contigs with low ALCR (<0.5) and high SDR (>0.1) in both Mango (11 contigs) and Plum (12 contigs) genomes. In Mango, 8 out of the 11 contigs with low ALCR and high SDR were confirmed to be of mitochondrial origin. These mitogenome contigs were detected during our chlorogenome contamination analysis, likely due to the occurrence of HGT between mitochondrial and chlorogenomes. Such gene transfer events can result in contigs with low ALCR and high SDR. In Plum, 5 of the 12 contigs were similarly identified as mitochondrial derivation. The remaining 7 contigs in Plum were subjected to further analysis using RepeatMasker, which revealed that the majority of these contigs contained repetitive sequences that constituted more than 50% of their lengths (Supplementary Table S1). This high proportion of repetitive sequences likely contributed to the unusually high sequencing depths observed in these contigs.
Based on the alignment results of all contigs from Mango and Plum against the local chloroplast genome database, we identified 226 Mango contigs and 174 Plum contigs that aligned with the database sequences at lengths greater than 5000 bp. However, the ratio of each contig’s length that aligned to the database (ALCR) was low, most of them had less than 10% coverage (Supplementary Figure S3). The chloroplast genomic fragments present in these ultra-long contigs may have been inserted into the nuclear chromosomes through HGT from the chloroplast genome. These results indicated that the traditional method of filtering out chlorogenomes based solely on alignment lengths might erroneously identify some ultra-long nuclear contigs that contain only a small proportion of chloroplast genomic content. Therefore, adopting more refined filtering criteria, such as ALCR and SDR, is critical to accurately differentiate contigs that are truly from the organelle genomes versus those inserted into nuclear genomes through HGT.
The performance of Chlomito on the detection of mitogenomes
3.7
Following the validation of Chlomito’s efficacy in chlorogenome identification, we expanded our investigation to assess its performance in detecting mitogenomes. Mitogenomes of Mango and Plum were first assembled from NGS data using GetOrganelle. Unlike a single sequence of complete chlorogenome assembled by Chlomito above (Supplementary Figure S1), the constructed mitogenomes of Mango and Plum were composed of multiple fragments. The assembled Mango mitogenome consisted of 15 sequences totaling 0.48 Mb, while Plum mitogenome was composed of 11 sequences totaling 0.36 Mb (Supplementary Figure S4). To validate the accuracy of the mitogenome assembly, we performed collinearity analysis between the assembled and the NCBI reference mitogenomes for Mango (MZ751075.1) and Plum (OK563724.1). The results showed that the assembled mitogenomes had high collinearity with the reference and covered most regions of the reference genomes (Supplementary Figure S4), indicating the high accuracy and completeness of the GetOrganelle-assembled mitogenomes. To evaluate the structural conservation of mitogenomes across different plant species, we annotated and compared the mitogenomes of Mango, Plum, Zea mays, and Arabidopsis thaliana with the OGDRAW website. The results showed that unlike chlorogenomes, the mitogenomes from these species did not show conserved gene contents or gene orders (Supplementary Figure S5). Subsequently, we integrated the assembled mitogenomes with those downloaded from NCBI database to establish a local database.
After constructing local mitogenome databases for Mango and Plum, we mapped SGS data to the mitogenomes in the local databases as well as to the TGS-assembled contigs, then calculated ALCR and SDR for each contig. Based on the parameters ALCR and SDR, we identified 11 and 10 contigs likely originating from the mitogenomes in Mango and Plum respectively (Figures 5A, D). These contigs also exhibited similar alignment lengths with the mitogenomes assembled by GetOrganelle and the NCBI database (Figures 5B, E). Moreover, collinearity analysis revealed that the identified contigs and the mitochondrial reference genomes had a high consistency in Mango and Plum, with the majority of the mitogenome regions being covered by these contigs (Figures 5C, F). Similar to the results in chloroplast, we also detected 116 and 52 contigs with alignment lengths exceeding 5000 bp but exhibiting low coverage (less than 10%) in Plum and Mango (Supplementary Figure S6). These results indicated that HGT of large fragments to the nucleus happened in both mitochondrial and chloroplast genomes.
Chlomito accurately identifies mitochondrial-derived contigs and validates their collinearity with mitochondrial reference genomes from Mango (A–C) and Plum (D–F). (A, D) Identification of mitochondria-derived contigs in Mango (A) and Plum (D) using ALCR and SDR metrics. (B, E) Alignment lengths of contigs with GetOrganelle-assembled and NCBI-downloaded mitogenomes for Mango (B) and Plum (E). (C, F) Collinearity analysis of Chlomito-identified contigs against published mitochondrial reference genomes for Mango (C) and Plum (F).
The performance of Chlomito on the detection of HGT in Arabidopsis
3.8
To assess the accuracy of Chlomito in detecting HGT events, we utilized a experimentally-confirmed large nuclear insertion of mitochondrial DNA (numt) in Arabidopsis (Fields et al., 2022) as a test case, representing a HGT event from mitochondria to nuclei. This numt, located on chromosome 2 of Arabidopsis thaliana, spans approximately 641 kb and is one of the largest numts reported in plants to date. Its existence has been validated by fiber-based fluorescent in situ hybridization.
By applying ALCR and SDR as screening criteria, we identified a total of 22 TGS-assembled contigs that potentially belong to the Arabidopsis mitogenome (Figure 6A). Collinearity analysis of these fragments with the NCBI mitogenome reference revealed that these fragments exhibited high collinearity with the reference and covered most of the mitogenome regions (Figure 6B). These results again confirmed that Chlomito could effectively find out mitogenome contigs in Arabidopsis. Interestingly, we noticed one contig ptg0002l, which didn’t pass the mtDNA screening criteria of ALCR and SDR, meaning that it is not a mitogenome contig (Figure 6A). The alignment of ptg00021 with the local database showed a pretty high coverage rate but a low depth ratio, suggesting that it might be an HGT fragment. Surprisingly, comparison of ptg00021 with the previously validated large numt on chromosome 2 of Arabidopsis (Fields et al., 2022) revealed a perfect match between them (Figure 6C). Furthermore, we specifically aligned PacBio HiFi reads (Wang et al., 2022) to the junctions between the identified numt and its flanking regions on ptg0002l. We found that some HiFi reads span these junctions, which further substantiates that this numt was horizontally transferred into chromosome 2, rather than being the result of assembly errors (Figure 6D).
Chlomito accurately identifies mitochondria-derived contigs and a horizontally transferred organelle fragment (numt) from Arabidopsis. (A) Identification of mitochondria-derived contigs in Arabidopsis using ALCR and SDR as screening criteria. (B) Collinearity analysis of Chlomito-identified contigs against published mitochondrial reference genomes for Arabidopsis. (C) Comparison of the ptg000002l fragment with the previously reported large numt on chromosome 2 of Arabidopsis. (D) Alignment of PacBio HiFi sequences (Wang et al., 2022) with the numt and its flanking regions.
Similar to its performance in mitochondrial genome sequence detection, Chlomito accurately distinguished Arabidopsis chloroplast fragments from genomic contigs, as shown in Supplementary Figure S7A. The chloroplast genome fragments detected by Chlomito had similar alignment lengths with the reference genome assembled by GetOrganelle and the NCBI chloroplast reference genome (Supplementary Figure S7B). Furthermore, these detected chloroplast genome fragments showed good collinearity with the chloroplast reference genome and covered most of its regions (Supplementary Figure S7C). This further demonstrates Chlomito’s utility in accurately identifying organelle genome contigs within complex genomic datasets.
In summary, the Chlomito tool accurately identified the contigs of Arabidopsis mitogenome and chlorogenome, and also effectively distinguished genuine mitogenome fragments from numts, the HGT regions existed in nuclear genome. These results validated our method as a reliable tool for understanding complex genomic evolution.
Organelle genome contamination in chromosome assembly
3.9
To evaluate the impact of organelle genome contamination on the accuracy of chromosome assembly, we aligned the Plum chromosomes assembled from all contigs without removing organelle sequences to the contigs identified as organelle DNA by Chlomito. The aligned result indicated that two mitogenome fragments (contig_2 and contig_4851) identified by Chlomito were erroneously assembled into chromosome 1 of Plum (Figure 7A). The full fragments of contig_2 (13,217 bp) and contig_4851 (6,187 bp) showed perfect matches with mitochondrial reference genomes NC_065233.1 and OK563724.1, which are complete mitogenomes of Plum listed in the NCBI organelle genome database. Further analysis demonstrated that the sequencing depths of these two contigs were much higher than the average depth of the chromosomal genome, and were close to the average depth of the mitogenome (Figures 7B, C). This is consistent with the characteristic that organelle genomes have higher copy numbers than nuclear genomes. In addition, we aligned PacBio sequencing reads to these two contigs and their flanking regions, and found that no PacBio reads could be mapped to their junction and flanking regions, further confirming that these two contigs were the result of chromosome assembly errors rather than true nuclear insertion of mitochondrial DNA (numt).
Identification and verification of organelle genome contamination in the assembled chromosome 1 of Plum. (A) The alignment between two mitochondria-derived contigs (identified by Chlomito) and the assembled chromosome 1 of Plum. (B, C) The sequencing depths are shown for contig_2 (B) and contig_4851 (C), in parallel with the average depths of chromosome and mitochondrial genomes.
Altogether, these results highlight that unfiltered organelle sequences can truely contaminate the nuclear genome during chromosome-level genome assembly. Therefore, the prior identification and exclusion of organelle genome sequences using Chlomito are curcial for ensuring the accuracy and integrity of chromosome assembly.
Discussion
4
In this study, we have developed a novel tool called Chlomito that provides an innovative approach for accurately identifying organelle genome sequences from complex genomic assembly. This method significantly improves the accuracy of recognizing organelle genomic fragments by integrally applying two metrics. (1) The first metric is Alignment Length Coverage Ratio (ALCR). Different from previous conventional methods (Nath et al., 2022; Bao et al., 2024), the calculation of ALCR does not solely rely on the single longest alignment region. Instead, it adds the lengths of all regions on the contig that is aligned with the organelle genome database. This metric offers a more accurate and comprehensive reflection of the alignment coverage between the contig and the organelle genome. The introduction of ALCR can significantly reduce the likelihood of incorrectly identifying nuclear genomic sequences as organelle genome sequences, especially for those organelle genome sequences that have been inserted into nuclear genomes via horizontal gene transfer (HGT). (2) The second metric is Sequencing Depth Ratio (SDR). Considering the varying copy numbers of organelle genomes in different tissues and developmental stages of plants (Preuten et al., 2010), the ratio of sequencing depths between organelle genome and nuclear genome is not constant (Wang et al., 2018). Consequently, in this study, we compared the sequencing depths of contigs against the average sequencing depth of organelle genome to enhance the precision of detection outcomes. The application of SDR provides an additional robust filtering dimension, further ensures the identification of sequences truly belonging to organelle genomes among all the assembled contigs.
Moreover, we have noted that recently, some new methods such as ODNA (Martin et al., 2023) and Odintifier (Samaniego Castruita et al., 2015) can also be used for the identification of organelle genomes. ODNA takes a machine learning approach, extracting features from the sequences and training classification models to distinguish organelle and nuclear genome sequences. Odintifier utilizes phasing technology to separate reads containing SNVs into organelle and nuclear genome reads, thereby enabling the identification of organelle genome sequences. Compared to them, Chlomito not only considers sequence alignment information but also takes full advantage of the differences in copy numbers and sequencing depths between organelle and nuclear genomes, thereby enhancing the identification accuracy. The organelle genome contigs identified by Chlomito exhibit high collinearity with its reference and cover most of the reference genome regions (Figures 4C, F, 5C, F, 6B; Supplementary Figure S7), as we tested it using sequencing data from multiple species, including Mango (Mangifera indica) (Wang et al., 2020), Plum (Prunus salicina) (Liu et al., 2020), and Arabidopsis (Arabidopsis thaliana) (Wang et al., 2022). Thus, Chlomito is capable of accurately detecting the organelle genome contaminants scattered in the assembly results. Also, it can effectively pick out the entire organelle genome sequences (Figures 4C, F). In short, Chlomito is a reliable tool in organelle genomic studies, and in supporting precise nuclear genome assembly by removing organelle genome contaminants.
In addition to the contigs identified by Chlomito as belonging to organelle genomes, there were also numerous contigs with alignment lengths to the reference organelle genomes exceeding 5 kb but exhibiting low alignment coverage (ALCR less than 10%) relative to the contig lengths (Supplementary Figure S6). This phenomenon may be attributable to the intracellular insertion of organelle genomes into the nuclear genome via HGT events. HGT is a significant mechanism in the evolutionary process, particularly in the exchange of genetic information between organelle genomes and host nuclear genomes. Similar studies have also observed the phenomenon of large organelle genome fragments over 4 kb being transferred into nuclear genomes via HGT in watermelon and melon (Cui et al., 2021). These findings suggest that large-scale HGT may be a widespread occurrence across diverse species. In this context, it is particularly important to accurately distinguish sequence exchanges between organelle and nuclear genomes caused by HGT. Chlomito is designed to address this challenge by employing two powerful metrics — ALCR and SDR. Two-dimensional grouping and filtering in Chlomito with ALCR and SDR can clearly separate different groups: the organellel genome contigs and the nuclear insertions of organellel sequences (Figures 4A, D, 5A, D, 6A). Additionally, some contigs with low ALCR (<0.5) and high SDR (>0.5) may be the result of either horizontal gene transfer between mitochondrial and chloroplast genomes or a high proportion of repetitive sequences within the contigs. To improve the accuracy of detection, users can initially run Chlomito with lower filtering thresholds and then determine more precise filtering thresholds using the generated ALCR and SDR visualization scatter plot for the following run. The application of Chlomito will deepen our understanding of the complex interactions among mitochondrial, chloroplast, and nuclear genomes through HGT.
The organelle genome contaminants greatly affect chromosome-level genome assembly results. When chromosomes were assembled using all contigs without removing organelle genomes, organelle genome segments were erroneously inserted into chromosomes by genome assembly software (Figure 7). Therefore, identifying and eliminating organelle genome contamination prior to chromosomal-level assembly are critical to ensure the fidelity of the assembly outcomes. The development of tools like Chlomito is important for improving the quality and reliability of chromosomal-level genome assembly in scientific research.
In summary, the development of Chlomito offers a precise and efficient approach for detecting and filtering organelle DNA sequences from genome assembly contigs, which significantly contributes to enhancing the quality of chromosome assembly. Furthermore, as Chlomito is capable of effectively distinguishing genuine organelle genome sequences from what have been integrated into the nuclear genome via HGT, it will facilitate broad investigation into the mechanisms of genetic exchange between chromosomal and organelle genomes across a wide range of species in the future, offering new insights on the dynamic changes and evolutionary processes of organelle genomes.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Allio R.Schomaker-Bastos A.Romiguier J.Prosdocimi F.Nabholz B.Delsuc F. (2020). Mito Finder: Efficient automated large-scale extraction of mitogenomic data in target enrichment phylogenomics. Mol. Ecol. Resour. 20, 892–905. doi: 10.1111/1755-0998.13160 32243090 PMC 7497042 · doi ↗ · pubmed ↗
- 2Bae E. K.Kang M. J.Lee S. J.Park E. J.Kim K. T. (2023). Chromosome-level genome assembly of the Asian aspen Populus davidiana Dode. Sci. Data 10, 431. doi: 10.1038/s 41597-023-02350-5 37414813 PMC 10326025 · doi ↗ · pubmed ↗
- 3Bao Y.Zhang Q.Huang J.Zhang S.Yao W.Yu Z.. (2024). A chromosomal-scale genome assembly of modern cultivated hybrid sugarcane provides insights into origination and evolution. Nat. Commun. 15, 3041. doi: 10.1038/s 41467-024-47390-6 38589412 PMC 11001919 · doi ↗ · pubmed ↗
- 4Bendich A. J. (2010). Mitochondrial DNA, chloroplast DNA and the origins of development in eukaryotic organisms. Biol. Direct 5, 42. doi: 10.1186/1745-6150-5-42 20587059 PMC 2907347 · doi ↗ · pubmed ↗
- 5Cecchin M.Marcolungo L.Rossato M.Girolomoni L.Cosentino E.Cuine S.. (2019). Chlorella vulgaris genome assembly and annotation reveals the molecular basis for metabolic acclimation to high light conditions. Plant J. 100, 1289–1305. doi: 10.1111/tpj.14508 31437318 PMC 6972661 · doi ↗ · pubmed ↗
- 6Cui H.Ding Z.Zhu Q.Wu Y.Qiu B.Gao P. (2021). Comparative analysis of nuclear, chloroplast, and mitochondrial genomes of watermelon and melon provides evidence of gene transfer. Sci. Rep. 11, 1595. doi: 10.1038/s 41598-020-80149-9 33452307 PMC 7811005 · doi ↗ · pubmed ↗
- 7Du Y.Song W.Yin Z.Wu S.Liu J.Wang N.. (2022). Genomic analysis based on chromosome-level genome assembly reveals an expansion of terpene biosynthesis of azadirachta indica. Front. Plant Sci. 13. doi: 10.3389/fpls.2022.853861 PMC 906923935528946 · doi ↗ · pubmed ↗
- 8Eddy S. R. (2011). Accelerated profile HMM searches. Plo S Comput. Biol. 7, e 1002195. doi: 10.1371/journal.pcbi.1002195 22039361 PMC 3197634 · doi ↗ · pubmed ↗