Joint Imbalance Adaptation for Radiology Report Generation
Yuexin Wu, I-Chan Huang, Xiaolei Huang

TL;DR
This paper introduces a new model for radiology report generation that addresses data imbalance issues to improve report accuracy.
Contribution
The novel Joint Imbalance Adaptation (JIMA) model uses a curriculum learning strategy to handle imbalanced data in radiology reports.
Findings
JIMA improves evaluation metrics by 16.75% to 50.50% on radiology datasets.
The model's focus on rare labels and clinical tokens enhances clinical accuracy in reports.
Curriculum learning reduces overfitting to frequent patterns and underfitting to rare ones.
Abstract
Radiology report generation, translating radiological images into precise and clinically relevant description, may face the data imbalance challenge – medical tokens appear less frequently than regular tokens; and normal entries are significantly more than abnormal ones. However, very few studies consider the imbalance issues, not even with conjugate imbalance factors. In this study, we propose a Joint Imbalance Adaptation (JIMA) model to promote task robustness by leveraging token and label imbalance. JIMA predicts entity distributions from images and generates reports based on these distributions and image features. We employ a hard-to-easy learning strategy that mitigates overfitting to frequent labels and tokens, thereby encouraging the model to focus more on rare labels and clinical tokens. JIMA shows notable improvements (16.75% - 50.50% on average) across evaluation metrics on…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
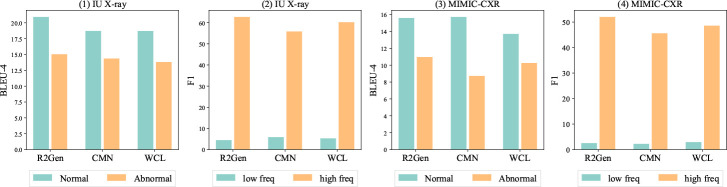 Figure 1
Figure 1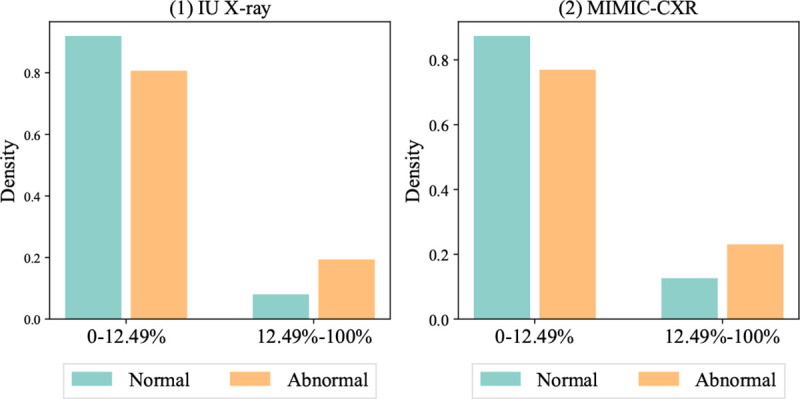 Figure 2
Figure 2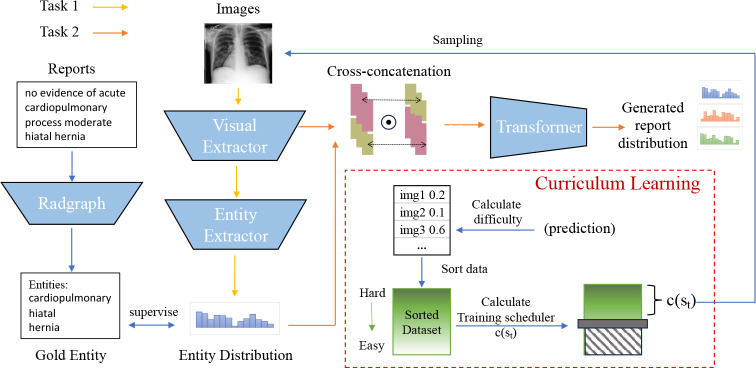 Figure 3
Figure 3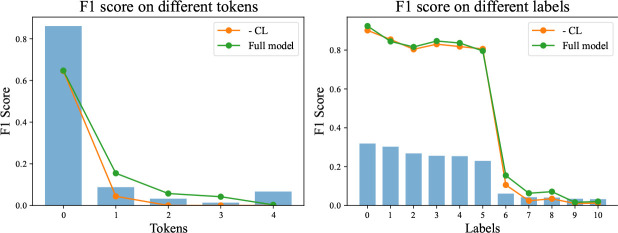 Figure 4
Figure 4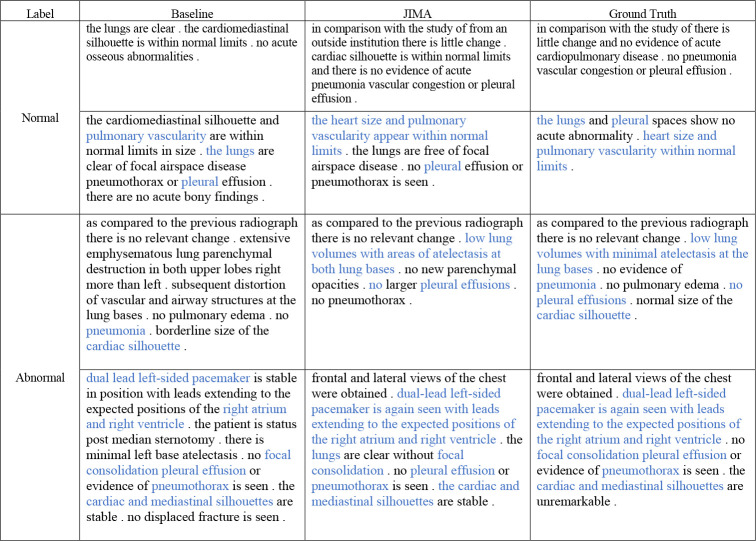 Figure 5
Figure 5| 1: |
| 2: Rank entries by the two difficulty measurers ( |
| 3: Calculate |
| 4: Select top |
| 5: Select top |
| 6: Sample a batch from |
| 7: Sample a batch from |
| 8: |
- —National Science Foundation
- —National Cancer Institute
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsTopic Modeling · Natural Language Processing Techniques · Biomedical Text Mining and Ontologies
Introduction
1
Radiology report generation is a multimodal and medical image-to-text task that generates text descriptions for radiographs (e.g., X-ray or CT scan), which may reduce the workloads of radiologists [1, 2]. The task has own unique characteristics than general image-to-text tasks (e.g., image captioning), such as lengthy medical notes, medical annotations, and clinical terminologies. As demonstrated in Figure 1, data imbalance can significantly impact model robustness that prevents model deployment in practice – models can easily overfit on frequent patterns. However, modeling data imbalance to augment the robust generation of the radiology report is understudied.
Two major data imbalances exist in the radiology generation task, label and token. Label imbalance pertains to a disproportionate ratio of normal and abnormal diagnosis categories, which exist in radiological images and text reports. For instance, normal cases (images and reports) dominate radiology data, which can easily lead to underperformance in disease detection and professional description. As shown in Table 1, abnormal reports are considerably longer than normal reports while can only count less than 15%. These abnormal reports are much harder to generate than shorter reports [3–5] and can be worse with fewer samples than normal cases.^1^ Existing imbalance learning studies of radiology report generation primarily focus on label imbalance [7, 8]. Token imbalance is a critical challenge in generation that tokens have varied occurrence frequencies, and the issue is more critical in the medical task. Learning infrequent tokens can be harder than frequent tokens for generation models [9, 10]. Medical tokens appear less frequently than regular ones, and the infrequent tokens may contain more medical results, highlighting the very unique challenge of this task. Figure 1 illustrates the learning progress of the state-of-the-art (SOTA) model RRG [11] in predicting a report with predominantly normal diagnoses. The model shows strong performance on normal cases but struggles on abnormal reports.
To promote the quality of generated reports, we propose Joint Imbalance Adaptation (JIMA) model by curriculum learning [12]. JIMA automatically guides the model learning process by leveraging optimization difficulties, strengthening learning capability on infrequent samples, and alleviating overfitting on frequent patterns on both label and token. We incorporate the token and label metrics as a joint optimization and design a novel Training Scheduler that sampling and sorting training instances with a multi-aspect scoring mechanism. The scheduler automatically adjust training samples when model performance varies across multiple imbalance factors. We conduct experiments on two publicly available datasets, MIMIC-CXR [13] and IU X-ray [14] with automatic and human evaluations. By comparing with six state-of-the-art (STOA) baselines on overall and imbalance performance settings, our approach shows promising results over the STOA baselines. Our ablation and qualitative analyses show that JIMA can generate more precise medical reports, alleviating label and token imbalance.
Data
2
We collected two publicly accessible datasets for this study, IU X-ray [14] and MIMIC-CXR [13], de-identified chest X-ray datasets to evaluate radiology report generation. IU X-ray [14], collected from the Indiana Network for Patient Care, includes 7,470 X-ray images and corresponding 3,955 radiology reports. MIMIC-CXR [13], collected from the Beth Israel Deaconess Medical Center, contains 377,110 X-ray images and 227,827 radiology reports for 65,379 patients. Each report is a text document and associates with one or more front and side X-ray images. Table 1 summarizes statistics of data imbalance and Figure 2 visualize the distributions of frequent (ranked in the top 12.5% of the vocabulary) and infrequent tokens. We include preprocessing details in Appendix A.
Table 1 presents imbalance patterns in tokens and labels. Abnormal entries are predominant in both datasets, and MIMIC-CXR displays a more skewed label distribution, as more abnormal samples were collected during diagnosis phases not for screening purposes. MIMIC-CXR has a longer average length than IU X-ray. The lengthier documents may pose a unique multimodal generation challenge in the medical field. To conduct our analysis, we define the low and high frequency using the top 12.5% frequent tokens. Figure 1 suggests a joint relation between label and token imbalance and higher ratios of low-frequency tokens in abnormal reports. This observation motivates us to investigate how the imbalance impacts model robustness and reliability.
Imbalance Effects
2.1
We examine the potential impact of label and token imbalance on model performance. To ensure consistency, we keep the top 12.5% to split low- and high-frequent tokens for evaluation purposes. The analysis includes three state-of-the-art models, R2Gen [15], WCL [16], and CMN [17]. We use BLEU-4 [18] and F1 scores to measure performance across both token (low vs high frequency) and label (normal vs. abnormal) imbalance. We visualize performance variations in Figure 2.
The results suggest that the models exhibit significant difficulties in coping under label and token imbalance. Models consistently perform worse on abnormal reports, which are lengthier and have more infrequent tokens than normal reports. For example, the top 12.5% frequent tokens count > 80% tokens in two datasets, and low-frequent tokens have much worse performance than frequent tokens, as infrequent tokens are harder to optimize [19]. However, infrequent tokens contain higher ratios of medical terms (e.g., silhouettes and pulmonary) describing health states. The significantly varying performance highlights the unique challenges to adapt token and label imbalance. While existing work [7] has considered label imbalance, however, the study did not examine the performance effects of label or token imbalance. The findings inspire us to propose our model Joint Imbalance Adaptation (JIMA) to model token and label imbalance.
Joint Imbalance Adaptation
3
In this section, we present our approach Joint Imbalance Adaptation (JIMA) in Fig 3 by using curriculum learning. JIMA aims to augment model robustness under label and token imbalance. As optimizing data imbalance has been demonstrated difficulty, deploying such a learning strategy will strengthen model robustness and reliability. Our proposed approach deploys curriculum learning (CL) [20] that automatically adjusts the optimization process by gradually selecting training data entries from learning difficulty — learning from hard to easy samples as our optimization strategy [21]. To achieve the goal, we design two major CL modules, difficulty measurer for assessing the difficulty of samples, and a training scheduler for determining the percentage of training data. Then we employ our CL training strategy to two tasks. Task 1 aims to predict entities from the images and Task 2 can generate a report from images’ features and entity distribution.
Difficulty measurer is to measure sample difficulties. To diversify learning aspects and jointly incorporate imbalance factors, we propose a novel measurement to improve model performance over imbalance patterns. Our measurement adopts a competitive mechanism that encourage correct options with higher ranking over incorrect ones, rather than independently increasing the likelihood of correct options and decreasing the likelihood of incorrect options. This approach helps mitigate overfitting on common samples and underfitting on rare samples since it focuses on ranking of correct option rather than prediction confidence. Specifically, given a reference token , vocabulary list and the prediction , we calculate the token reference probability ranking in the prediction as the following,
where is the vocabulary size. assigns a rank to in descending order and identifies the position of within this ranking. ranges from 0 to 1 under regularization with . A higher value of indicates that the sample is more difficult. Then, we feed the difficulty information to the next step, Training Scheduler.
Training scheduler aims to automatically leverage imbalance effects by selecting training samples via the difficulty measurers. Our goal is to increase the number of easier samples when the performance decreases and vice versa. According to our goal, we design our scheduler function, as following:
, where is the average performance of all training samples, measuring the model’s learning ability. is the training step. Given decreasing performance as an example, will be negative. During the process, the ratio will allow the model to include more easy training data than the last step . When the performance increase, the scheduler feed less easy samples to the model and reduce the over-fitting on these samples. After multiple epochs of training, harder samples receive more training iterations than easier samples. In this way, we can alleviate the the challenge from imbalanced tokens and labels in radiology report generation task. To start our curriculum learning, we record the samples’ average performance of the last two regular training epochs as and , where we empirically initialize as 1.
CL-Task 1
3.1
CL-Task 1 is to exploit imbalance patterns of radiology labels to generate clinically accurate reports. Entities in clinical reports play a crucial role in disease diagnosis. However, these clinical tokens often occur infrequently and are significantly underestimated during model training. Hence, we assess the accuracy of clinical entities to evaluate performance. Our intuition is that as abnormal cases contain more infrequent entities, focusing on the clinical entities may benefit the abnormal cases. If our generated reports are clinically correct, the visual extractor can accurately extract the same entities as gold entities from images.
The computing process is as the following. Given a radiology image and the corresponding report with the length , we extract the features from images with a visual extractor. We use ResNet101 [22] as our visual extractor and obtain image features from different convolutional channels, . , where is the size of the feature vector. To predict entities distribution, we feed the feature from into the Entity Extractor with parameters and average the value on each patch(1st dimension),
Then we obtain the entity distribution representation . To optimize the model, we minimize Binary Cross Entropy as follows,
where is the prediction probability of the i-th token and if i-th token is the entities. We extract the gold entities by radgraph [23]. To evaluate sample’s difficulty in this task, we input the entity distribution prediction into e.q 1 and obtain .
CL-Task 2
3.2
CL-Task 2 implements an image-to-text generation pipeline with the objective of improving the infrequent tokens prediction in reports. To generate a report containing more clinically useful information, we integrate the probability prediction of entities in e.q. 3 with image’s feature . Since , we cannot interact and directly. To facilitate their interaction and information sharing, we employ a cross-concatenation and perform a dot product operation on their cross-concatenated matrix as follows:
where Finally, we adopt a transformer structure to encode and generate i-th token probability distribution from encoding feature and i-th token, . To optimize the model, we minimize negative log-likelihood loss (NLL) as follows,
We can access the sample’s difficulty with by e.q. 1, .
Algorithm 1: Optimization Process of JIMA
<table><colgroup><col align="left"/></colgroup><tbody><tr><td align="left" rowspan="1" colspan="1"><bold>Require:</bold> <inline-formula><math xmlns:mml="http://www.w3.org/1998/Math/MathML"><mi>r</mi><mi>a</mi><mi>t</mi><mi>e</mi><mi>α</mi><mi>β</mi></math></inline-formula></td></tr><tr><td align="left" rowspan="1" colspan="1"> 1: <bold>for</bold> each epoch <bold>do</bold></td></tr><tr><td align="left" rowspan="1" colspan="1"> 2: Rank entries by the two difficulty measurers (<inline-formula><math xmlns:mml="http://www.w3.org/1998/Math/MathML"><msup><mrow><mi>k</mi></mrow><mrow><mi>t</mi><mi>a</mi><mi>s</mi><mi>k</mi><mn>1</mn></mrow></msup></math></inline-formula> and <inline-formula><math xmlns:mml="http://www.w3.org/1998/Math/MathML"><msup><mrow><mi>k</mi></mrow><mrow><mi>t</mi><mi>a</mi><mi>s</mi><mi>k</mi><mn>2</mn></mrow></msup></math></inline-formula>), and obtain two sorted datasets <inline-formula><math xmlns:mml="http://www.w3.org/1998/Math/MathML"><msub><mrow><mi>𝒟</mi></mrow><mrow><mn>1</mn></mrow></msub></math></inline-formula>, <inline-formula><math xmlns:mml="http://www.w3.org/1998/Math/MathML"><msub><mrow><mi>𝒟</mi></mrow><mrow><mn>2</mn></mrow></msub></math></inline-formula></td></tr><tr><td align="left" rowspan="1" colspan="1"> 3: Calculate <inline-formula><math xmlns:mml="http://www.w3.org/1998/Math/MathML"><mi>c</mi><mfenced><mrow><msubsup><mrow><mi>k</mi></mrow><mrow><mi>t</mi></mrow><mrow><mi>t</mi><mi>a</mi><mi>s</mi><mi>k</mi><mn>1</mn></mrow></msubsup></mrow></mfenced></math></inline-formula> and <inline-formula><math xmlns:mml="http://www.w3.org/1998/Math/MathML"><mi>c</mi><mfenced><mrow><msubsup><mrow><mi>k</mi></mrow><mrow><mi>t</mi></mrow><mrow><mi>t</mi><mi>a</mi><mi>s</mi><mi>k</mi><mn>2</mn></mrow></msubsup></mrow></mfenced></math></inline-formula> training schedulers</td></tr><tr><td align="left" rowspan="1" colspan="1"> 4: Select top <inline-formula><math xmlns:mml="http://www.w3.org/1998/Math/MathML"><mi>c</mi><mfenced><mrow><msubsup><mrow><mi>k</mi></mrow><mrow><mi>t</mi></mrow><mrow><mi>t</mi><mi>a</mi><mi>s</mi><mi>k</mi><mn>1</mn></mrow></msubsup></mrow></mfenced></math></inline-formula> samples from the sorted datasets <inline-formula><math xmlns:mml="http://www.w3.org/1998/Math/MathML"><msub><mrow><mi>𝒟</mi></mrow><mrow><mn>1</mn></mrow></msub></math></inline-formula> obtained by step 1 as training sets</td></tr><tr><td align="left" rowspan="1" colspan="1"> 5: Select top <inline-formula><math xmlns:mml="http://www.w3.org/1998/Math/MathML"><mi>c</mi><mfenced><mrow><msubsup><mrow><mi>k</mi></mrow><mrow><mi>t</mi></mrow><mrow><mi>t</mi><mi>a</mi><mi>s</mi><mi>k</mi><mn>2</mn></mrow></msubsup></mrow></mfenced></math></inline-formula> samples from the sorted datasets <inline-formula><math xmlns:mml="http://www.w3.org/1998/Math/MathML"><msub><mrow><mi>𝒟</mi></mrow><mrow><mn>2</mn></mrow></msub></math></inline-formula> obtained by step 1 as training sets</td></tr><tr><td align="left" rowspan="1" colspan="1"> 6: Sample a batch from <inline-formula><math xmlns:mml="http://www.w3.org/1998/Math/MathML"><msub><mrow><mi>𝒟</mi></mrow><mrow><mn>1</mn></mrow></msub></math></inline-formula> and update Task 1: <inline-formula><math xmlns:mml="http://www.w3.org/1998/Math/MathML"><msub><mrow><mover><mrow><mi>f</mi></mrow><mo>~</mo></mover></mrow><mrow><mi>ℛ</mi></mrow></msub><mo>←</mo><msub><mrow><mi>f</mi></mrow><mrow><mi>ℛ</mi></mrow></msub><mo>−</mo><mi>α</mi><msub><mrow><mo>∇</mo></mrow><mrow><msub><mrow><mi>f</mi></mrow><mrow><mi>ℛ</mi></mrow></msub></mrow></msub><msub><mrow><mi>ℒ</mi></mrow><mrow><mi>t</mi><mi>a</mi><mi>s</mi><mi>k</mi><mn>1</mn></mrow></msub><mo>,</mo><msub><mrow><mover><mrow><mi>f</mi></mrow><mo>~</mo></mover></mrow><mrow><mi>E</mi></mrow></msub><mo>←</mo><msub><mrow><mi>f</mi></mrow><mrow><mi>E</mi></mrow></msub><mo>−</mo><mi>α</mi><msub><mrow><mo>∇</mo></mrow><mrow><msub><mrow><mi>f</mi></mrow><mrow><mi>E</mi></mrow></msub></mrow></msub><msub><mrow><mi>ℒ</mi></mrow><mrow><mi>t</mi><mi>a</mi><mi>s</mi><mi>k</mi><mn>1</mn></mrow></msub></math></inline-formula></td></tr><tr><td align="left" rowspan="1" colspan="1"> 7: Sample a batch from <inline-formula><math xmlns:mml="http://www.w3.org/1998/Math/MathML"><msub><mrow><mi>𝒟</mi></mrow><mrow><mn>2</mn></mrow></msub></math></inline-formula> and update Task 2: <inline-formula><math xmlns:mml="http://www.w3.org/1998/Math/MathML"><msub><mrow><mover><mrow><mi>f</mi></mrow><mo>~</mo></mover></mrow><mrow><mi>𝒯</mi></mrow></msub><mo>←</mo><msub><mrow><mi>f</mi></mrow><mrow><mi>𝒯</mi></mrow></msub><mo>−</mo><mi>α</mi><msub><mrow><mo>∇</mo></mrow><mrow><msub><mrow><mi>f</mi></mrow><mrow><mi>𝒯</mi></mrow></msub></mrow></msub><msub><mrow><mi>ℒ</mi></mrow><mrow><mi>t</mi><mi>a</mi><mi>s</mi><mi>k</mi><mn>2</mn></mrow></msub></math></inline-formula></td></tr><tr><td align="left" rowspan="1" colspan="1"> 8: <bold>end for</bold></td></tr></tbody></table>CL-Joint Optimization
3.3
We propose a joint optimization approach to integrate two tasks. Algorithm 1 summarizes the overall optimization process of our approach. We set the learning rate of task 1 as and refers to the learning rate of tasks 2. In each training step, we sample different data for different tasks and each task focuses on optimizing its own module of the models. For example, we update the visual extractor and the entity extractor in task 1. Next, we freeze the parameters of the visual extractor and the entity extractor, and update the parameters of the transformer specifically for task 2. Our optimization approach integrates with curriculum learning to tailor joint imbalance learning for each module . Curriculum learning empowers the model to concentrate on optimizing hard samples while mitigating the risk of overfitting to easier samples. The joint optimization scheme facilitates each task to manage different module parameters optimization and learn a transferable knowledge from the simpler to more complex task. As a result, all modules collaborate to enhance error reduction from previous tasks.
Experiments
4
We design our experiments to evaluate performance on both regular and imbalanced settings via automatic and human evaluations. The automatic evaluation includes NLG-oriented and clinical-correctness metrics. NLG-oriented metrics measure the similarity between generated and reference reports. Clinical correctness and human evaluation belong to factually-oriented metrics, and domain-specific evaluation methods. To be consistent with our baselines [10, 11, 15], we utilize the F1 CheXbert [24] for the clinical-correctness metrics. The experiments compare our proposed approach (JIMA) and the state-of-the-art baselines. Two of our five baselines (CMM + RL & RRG) are designed to solve label imbalance by improving the abnormal findings generation. We conduct ablation and case analyses to fully understand the capabilities of our proposed approach. We include more implementation details and hyperparameter settings in Appendix B.1.
Baselines
4.1
To examine the validity of our method, we include five state-of-the-art baselines under the same experimental settings: R2Gen [15], CMN [17], WCL [16], CMN + RL [25], RRG [26], TIMER [10] and RGRG [27] – and obtain from their open-sourced code repositories.
R2Gen [15] is a transformer-based model with ResNet101 [22] as the visual extractor. To capture some patterns in medical reports, R2Gen proposes a relational memory to enhance the transformer so that the model can learn from the patterns’ characteristics. Furthermore, R2Gen deploys a memory-driven conditional layer normalization to the transformer decoder facilitating incorporating the previous step generation into the current step.
CMN [17] is a novel extension to the transformer architecture that facilitates the alignment of textual and visual modalities. The cross-modal memory network record the shared information of visual and textual features. The alignment process is carried out via memory querying and responding. The model maps the visual and textual features into the same representation space in memory querying and learns a weighted representation of these features in memory responding.
WCL [16] utilizes the R2Gen framework and incorporates a weakly supervised contrastive loss. Specifically, WCL leverages the contrastive loss to enhance the similarity between a given source image and its corresponding target sequence. Furthermore, the model enhances its ability to learn from difficult samples by assigning more weights to instances sharing common labels.
CMM + RL [25] is a cross-modal memory-based model with reinforcement learning for optimization. CMM + RL designs a cross-modal memory model to align the visual and textual features and deploy reinforcement learning to capture the label imbalance between abnormality and normality. The author uses BLEU-4 as a reward to guide the model to generate the next word from the image and previous words.
RRG [11, 26] aims to generate clinically correct reports by weakly-supervised learning of the entities and relations from reports. RRG is a BERT-based model with Densenet-121 [28] as a visual extractor. RRG leverages RadGraph [23] to extract the entities and relation labels in a report. RRG utilizes reinforcement learning to optimize the model. The reward assesses the consistency and completeness of entities and the relation set between generated reports and reference radiology reports. RRG addresses label imbalance issues by maximizing the reward of predicting more complicated entities and relations in abnormal samples.
TIMER [10] aims to decrease the over-fitting of frequent tokens by introducing unlikelihood loss to punish the error on these tokens. The tokens set of unlikelihood loss is automatically adjusted by maximizing the average F1 score on different frequency tokens.
RGRG [27] adopts GPT2 as the language generation model and generate a report based on the localized visual features of anatomical regions, which are extracted by a object detection. This baseline experiment was specifically carried out on the MIMIC-CXR dataset, as the IU X-ray dataset lacks anatomical region information, resulting in the inability to train an object detection module effectively.
Imbalance Setting
4.2
We evaluate model robustness under token and label imbalance settings and present results in Section 5.2 and 5.3.. For token imbalance, we compare F1-scores of frequent and infrequent tokens separately. We introduce three different scales to define frequency token sets, 1*/4, 1/6, and 1/8 respectively. The splits define the top 1/4, 1/6, and 1/*8 vocabulary as frequent tokens and the rest vocabulary as infrequent tokens. The setting is to demonstrate the effectiveness of our approach in adapting token imbalance. For label imbalance, we divide our samples into a binary category, normal and abnormal.
Results and Analysis
5
In this section, we present overall performance and report results of imbalance evaluations and include an ablation analysis and a case study. Generally, JIMA outperforms the state-of-the-art baselines by a large margin, especially under imbalance settings. Our qualitative studies show our method can achieve more clinically accuracy and generate more precisely clinical terms.
Overall Performance
5.1
Table 2 presents the performance of JIMA by NLG and clinical-correctness metrics. JIMA outperforms baseline models (both imbalance and regular methods) on BLEU scores by a large margin, confirming the validity of selecting training samples by our curriculum learning method. The approach enables the model to learn multiple times from the samples with lower BLEU-4, resulting in a better performance compared to the baseline models. For example, JIMA shows an improvement of 16.59% on average for IU X-ray and 16.28% for MIMIC-CXR. We infer this is as our task 1 and 2 jointly work to improves the token and label imbalanced problem.
Second, our model achieves the best performance in F1 of the clinical metric, which indicates the Task 1 (Section 3.1) can enable the model to put more attention on difficult samples with lower F1 scores. Additionally, our method promotes clinical token prediction as performance on infrequent tokens and medical terms have been improved. For example, our generation significantly outperforms the baselines on F1 score by 72.10% on IU X-ray and 31.29% on the MIMIC-CXR average. CMN + RL performs better than other baselines on IU X-ray but not on MIMIC-CXR. JIMA maintains a stable performance on both IU X-ray and MIMIC-CXR. We infer this as our joint imbalance adaptation can yield more improvements.
Token Imbalance
5.2
Table 3 compares high- and low-frequent tokens F1 in different ratio splits. Our method consistently outperforms baselines in the low-frequent tokens across frequency splits ( , , and ) on IU X-ray and MIMIC-CXR. While RRG and CMN + RL approaches have adapted label imbalance, the approaches may not be able to adapt the token imbalance. Our approach achieves better performance on the token imbalance. Generating rare tokens with accuracy remains a difficult task despite the high performance achieved on frequent tokens. Common tokens are prone to overfitting while rare tokens are predicted with less precision. For example, the 0.00 score by R2GEN on 3*/*4 split of the MIMIC-CXR vocabulary. Performance imbalance can deteriorate the clinical correctness of generated reports as medical terminologies are usually infrequent. Nonetheless, our joint imbalance adaptation approach has shown considerable improvements in this area, indicating a promising direction to enhance the robustness of radiology report generation, a critical clinical task.
Label Imbalance
5.3
We report NLG evaluations on label imbalance (normal vs. abnormal) in Table 4. JIMA significantly outperforms baseline models both on normal and abnormal splits, which demonstrates its effectiveness under label imbalance. JIMA also performs better than the label imbalance methods, RRG and CMM+RL, indicating that the joint imbalance adaptation is a promising direction to improve model robustness. It is worth noting that models generally perform better on normal samples than on abnormal ones. We infer this for two reasons: 1) abnormal reports contain more infrequent medical tokens, and 2) abnormal reports are longer, as discussed in Section 2. JIMA shows more improvements on abnormal samples over baselines while maintains a similar performance on samples with normal labels. The observations suggest that our approach can successfully learn from lengthier documents with more medical tokens.
Ablation Analysis
5.4
In this section, we carry out ablation experiments to analyze the impact of our curriculum learning approach on tokens and labels with different frequencies. To investigate the performance across different tokens, we categorize tokens into five groups based on their frequency, with “0” representing the most frequent tokens and “4” representing the least frequent tokens. Each group contains an equal number of tokens. In order to compare the performance across different labels, we present their performance individually. We conduct our ablation experiments on the MIMIC-CXR dataset, and the results are depicted in Figure 4.
First, we notice that removing curriculum learning does not result in a significant detrimental impact on highly frequent tokens and labels. For instance, the performance is comparable in the “0” token group and the “0–5” label groups. Curriculum learning empowers the model to allocate increased attention to challenging samples, thereby reducing the likelihood of predictions on highly frequent samples. However, our curriculum learning strategy selects training samples based on the ranking of the correct answers. Therefore, despite the reduced probability of the correct answer, the ranking remains unchanged. For example, the correct option still holds the highest estimation). As a result, our curriculum learning approach does not diminish the performance on highly frequent samples. Next, our curriculum learning approach significantly enhances performance primarily on moderately frequent samples. The average improvement amounts to 6.49% in the “1–3” token group and 2.58% in the “6–10” label group. However, our method exhibits limitations in enhancing the performance of exceedingly rare tokens. Notably, the model struggles to predict tokens in the “4” group.
Human Evaluation
5.5
To verify the factual correctness, we invite two health professionals to perform evaluation. First, we randomly select 50 test instances per data from IU X-ray and MIMIC-CXR, respectively. We choose CMM+RL as our targeting comparison, as the model is the best performing baseline by automatic metrics. In evaluation, we show the X-ray images, corresponding ground truth reports, and two generated reports (one from our model and the other from CMM+RL) to the expert without disclosing their sources. The experts selected a better description from two candidate reports or chooses the “Same” option if both reports are of similar quality.
We present our human evaluation results in Table 5, which shows a consistent result with automatic evaluation results. Generally, JIMA outperforms the baseline with 11 reports in total. Notably, our approach exhibits significant improvements in abnormal samples. Even though JIMA has only one more vote than the baseline in normal samples, our model secures ten more votes in abnormal samples. This is because abnormal samples have lengthier reports on average and encompass more medical entities, indicating that our approach generates more clinically precise reports. Furthermore, our human evaluation is consistent with the automated evaluation results shown in Table 2.
Case Study
5.6
To verify our model’s effectiveness in generating clinically correct descriptions, we perform a case study in this section and present the result in Fig 5. We select four samples from IU X-ray and MIMIC-CXR datasets and compare the normal and abnormal samples’ performance separately. The correct pathological and anatomical entity predictions are remarked in blue color. Generally, our predictions cover more than 90% entities in reference reports. Compared to normal samples, abnormal samples have longer descriptions and contain more complex entities. These entities usually are rare in corpus and suffer under-fitting from models. Therefore, models underperform in abnormal samples. However, JIMA can capture most of the entities in all kinds of samples and achieve similar performance in both normal and abnormal samples, which proves our model’s effectiveness in improving the factual completeness and correctness of generated radiology reports.
Related Work
6
Radiology report generation is a domain-specific image-to-text task that has two major directions, retrieval- [29, 30] and generation-based [15, 25, 31]. The retrieval-based approach compares similarities between an input radiology image and a set of report candidates, ranks the candidates, and returns the most similar one [5, 26, 29, 30, 32]. In contrast, our study focuses on the generation-based task, which automatically generates a precise report from an input image. The task has domain-specific characteristics in the clinical field. The clinical data contains many infrequent medical terminologies and longer documents than image captioning from general domains [6]. As radiology report generation can reduce the workloads of radiologists, generating highly qualified and precise can be a critical challenge, especially under the imbalance settings. Differing from previous work, we aim to promote model robustness and reliability under imbalance settings, which have been rarely studied in the radiology report generation.
Imbalance learning aims to model skewed data distributions. The primary focus of imbalance learning is on class or label imbalance, such as positive or negative reviews in sentiment analysis [33]. While previous studies proposed new objective functions (e.g., focal-loss [34]) or oversampling [35], those methods may not be applicable to our primary generation unit, token, which has large vocabulary sizes and extreme sparsity. In terms of radiology report generation, reports may have disease-related labels. Recent studies have augmented model robustness by balancing performance between disease and normal by reinforcement learning [7, 8]. However, those methods ignore a fundamental challenge of generation task, token imbalance – a long-tail distribution. The token imbalance can be even more critical for the clinical domain, as medical tokens appear less frequently than regular tokens in radiology reports. Our study makes a unique contribution to the radiology report generation that jointly consider multiple imbalance factors via curriculum learning.
Conclusion
7
In this study, we have demonstrated the critical imbalance challenge and developed a curriculum learning-based model to jointly adapt label and token imbalance. Extensive experiments, ablation analysis, and human evaluations show that JIMA leads to significant improvements over the existing state-of-the-art baselines, especially in handling token and label imbalance. Our future work will examine the proposed approach on more imbalance factors (e.g., demography).
Limitations
8
Limitations should be fully acknowledged before fully interpreting this study, as no research can be fully perfect. Evaluation. We are aware of other evaluation metrics, such as RadGraph [23] and CheXpert [36]. However, additional metrics may only be applicable to the MIMIC-CXR or have overlapped with our existing method, such as CheXpert and CheXbert [24]. We have included diverse metrics, including NLG, clinical correctness, and human evaluations. To keep consistency with our state-of-the-art baselines, we utilize a similar evaluation schema. Having consistent observations between our human and automatic evaluations may also prove our evaluation validity.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Jing B., Xie P., Xing E.: On the automatic generation of medical imaging reports. In: Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 2577–2586. Association for Computational Linguistics, Melbourne, Australia (2018). 10.18653/v 1/P 18-1240 . https://aclanthology.org/P 18-1240 · doi ↗
- 2Jing B., Wang Z., Xing E.: Show, describe and conclude: On exploiting the structure information of chest X-ray reports. In: Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pp. 6570–6580. Association for Computational Linguistics, Florence, Italy (2019). 10.18653/v 1/P 19-1657 . https://aclanthology.org/P 19-1657 · doi ↗
- 3Lovelace J., Mortazavi B.: Learning to generate clinically coherent chest X-ray reports. In: Findings of the Association for Computational Linguistics: EMNLP 2020, pp. 1235–1243. Association for Computational Linguistics, Online (2020). 10.18653/v 1/2020.findings-emnlp.110 . https://aclanthology.org/2020.findings-emnlp.110 · doi ↗
- 4Tan B., Yang Z., Al-Shedivat M., Xing E., Hu Z.: Progressive generation of long text with pretrained language models. In: Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pp. 4313–4324. Association for Computational Linguistics, Online (2021). 10.18653/v 1/2021.naacl-main.341 . https://aclanthology.org/2021.naacl-main.341 · doi ↗
- 5Wang Z., Liu L., Wang L., Zhou L.: Metransformer: Radiology report generation by transformer with multiple learnable expert tokens. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 11558–11567 (2023). https://openaccess.thecvf.com/content/CVPR 2023/html/Wang_ME Transformer_Radiology_Report_Generation_by_Transformer_With_Multiple_Learnable_Expert_CVPR_2023_paper.html
- 6Lin T.-Y., Maire M., Belongie S., Hays J., Perona P., Ramanan D., Dollár P., Zitnick C.L.: Microsoft coco: Common objects in context. In: Fleet D., Pajdla T., Schiele B., Tuytelaars T. (eds.) Computer Vision – ECCV 2014, pp. 740–755. Springer, Cham (2014). 10.1007/978-3-319-10602-148 · doi ↗
- 7Nishino T., Ozaki R., Momoki Y., Taniguchi T., Kano R., Nakano N., Tagawa Y., Taniguchi M., Ohkuma T., Nakamura K.: Reinforcement learning with imbalanced dataset for data-to-text medical report generation. In: Findings of the Association for Computational Linguistics: EMNLP 2020, pp. 2223–2236. Association for Computational Linguistics, Online (2020). 10.18653/v 1/2020.findings-emnlp.202 · doi ↗
- 8Yu H., Zhang Q.: Clinically coherent radiology report generation with imbalanced chest x-rays. In: 2022 IEEE International Conference on Bioinformatics and Biomedicine (BIBM), pp. 1781–1786. IEEE Computer Society, Los Alamitos, CA, USA (2022). 10.1109/BIBM 55620.2022.9994871 . 10.1109/BIBM 55620.2022.9994871 · doi ↗