GAD-PVI: A General Accelerated Dynamic-Weight Particle-Based Variational Inference Framework
Fangyikang Wang, Huminhao Zhu, Chao Zhang, Hanbin Zhao, Hui Qian

TL;DR
This paper introduces GAD-PVI, a new framework for Bayesian inference that improves particle-based methods by combining accelerated updates and dynamic weight adjustments.
Contribution
The novel SHIFR flow and GAD-PVI framework enable simultaneous accelerated position updates and dynamic weight adjustments in particle-based variational inference.
Findings
GAD-PVI converges faster than existing methods in both score-based and sample-based tasks.
The framework reduces approximation error and is compatible with various dissimilarities and gradient flow approximations.
GAD-PVI can generate high-quality samples even when analytical scores are unavailable.
Abstract
Particle-based Variational Inference (ParVI) methods have been widely adopted in deep Bayesian inference tasks such as Bayesian neural networks or Gaussian Processes, owing to their efficiency in generating high-quality samples given the score of the target distribution. Typically, ParVI methods evolve a weighted-particle system by approximating the first-order Wasserstein gradient flow to reduce the dissimilarity between the particle system’s empirical distribution and the target distribution. Recent advancements in ParVI have explored sophisticated gradient flows to obtain refined particle systems with either accelerated position updates or dynamic weight adjustments. In this paper, we introduce the semi-Hamiltonian gradient flow on a novel Information–Fisher–Rao space, known as the SHIFR flow, and propose the first ParVI framework that possesses both accelerated position update and…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
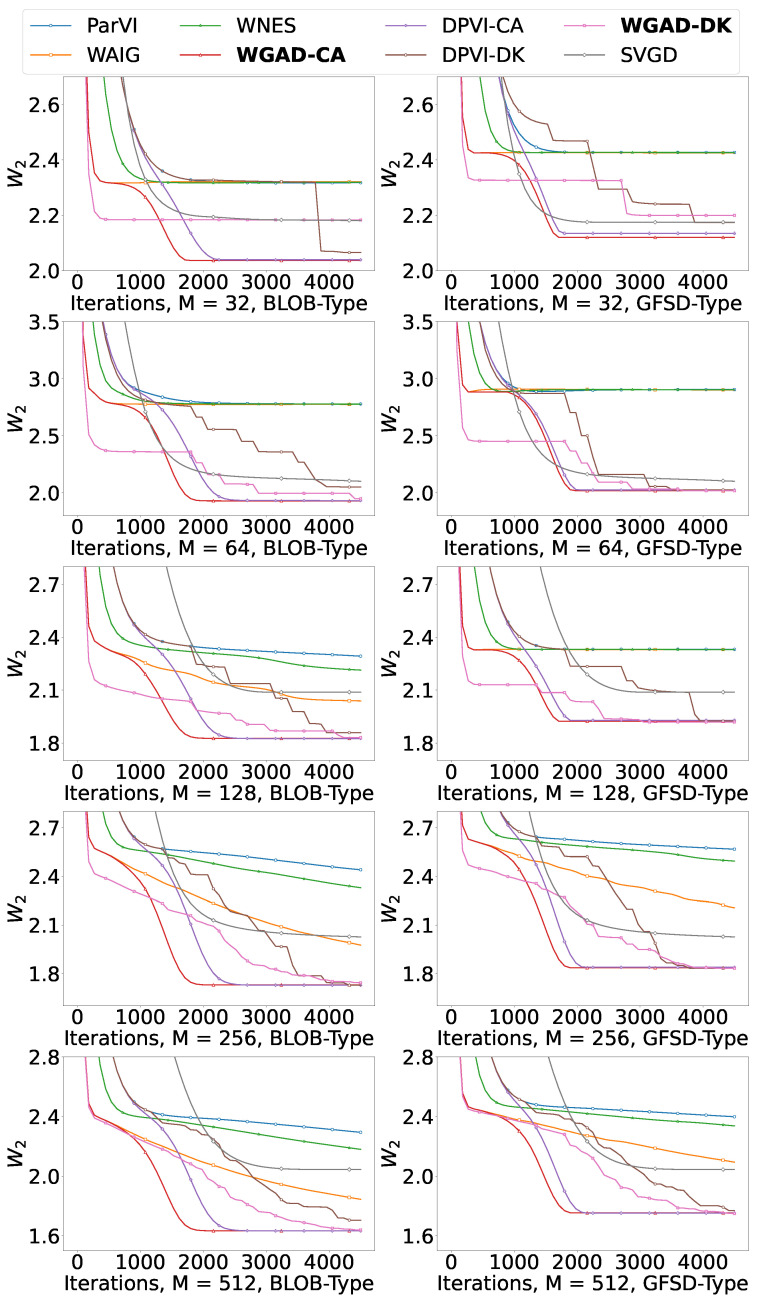 Figure 1
Figure 1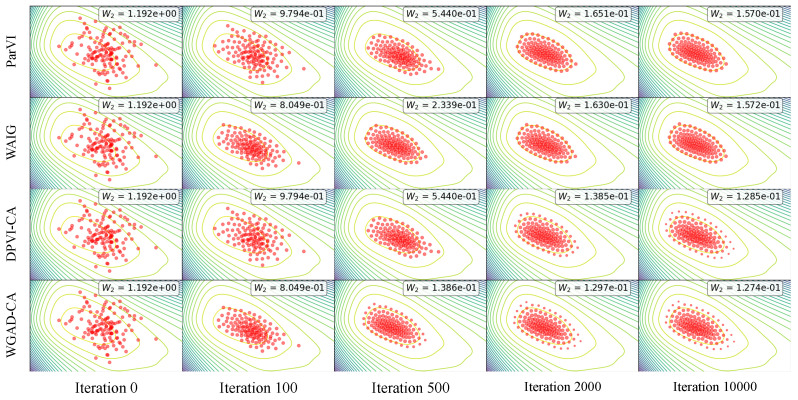 Figure 2
Figure 2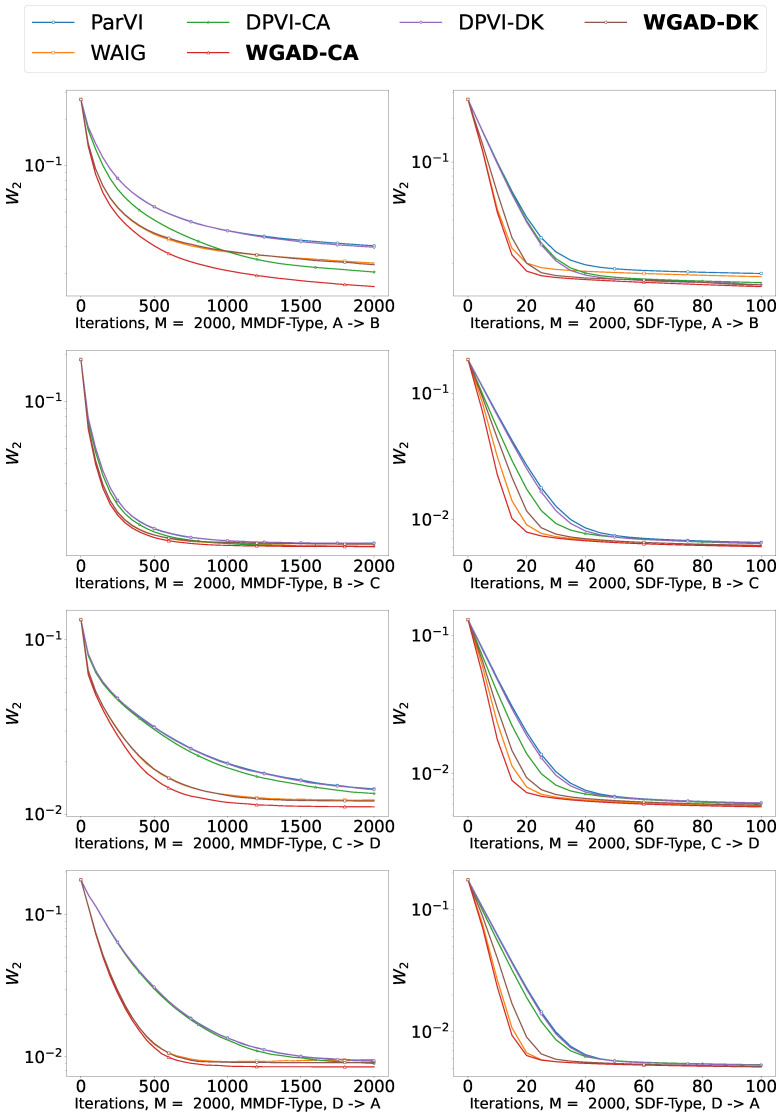 Figure 3
Figure 3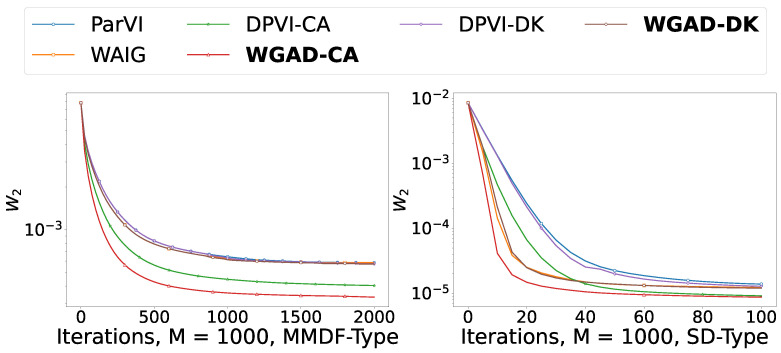 Figure 4
Figure 4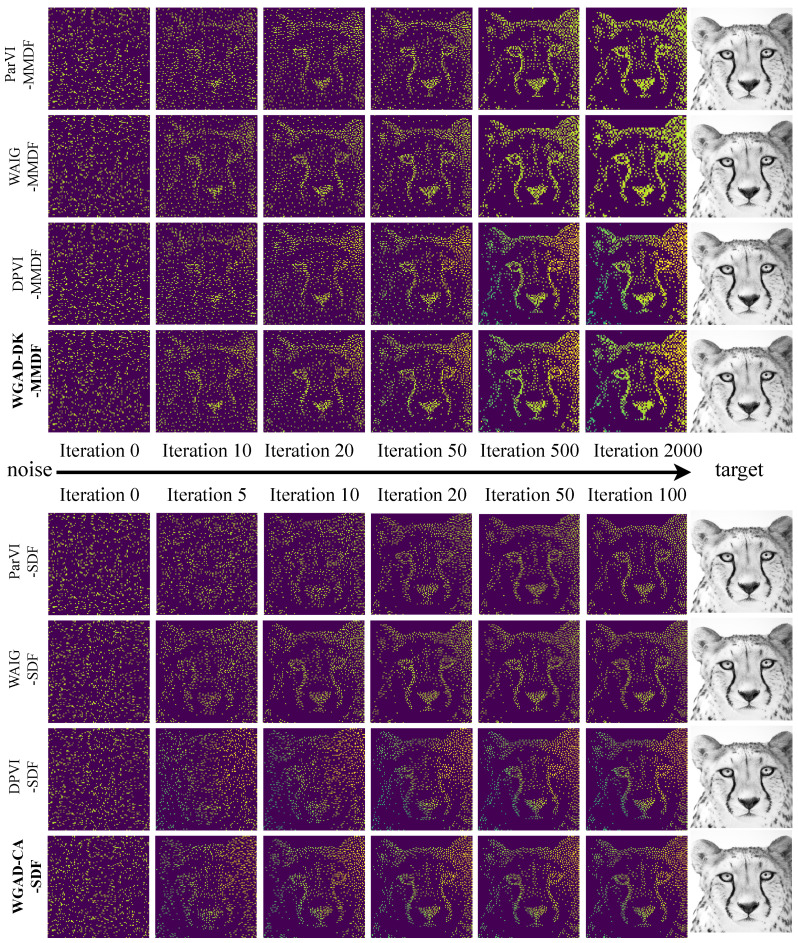 Figure 5
Figure 5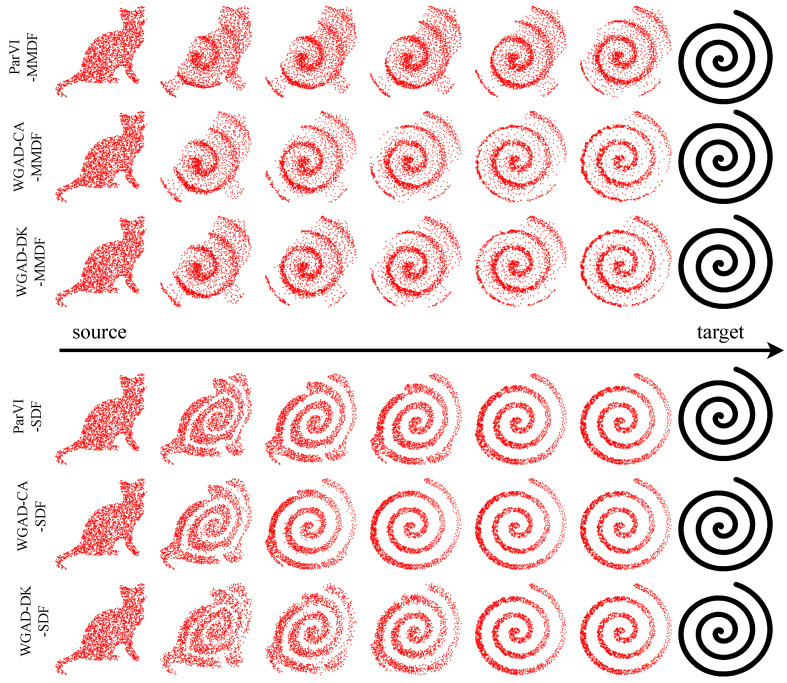 Figure 6
Figure 6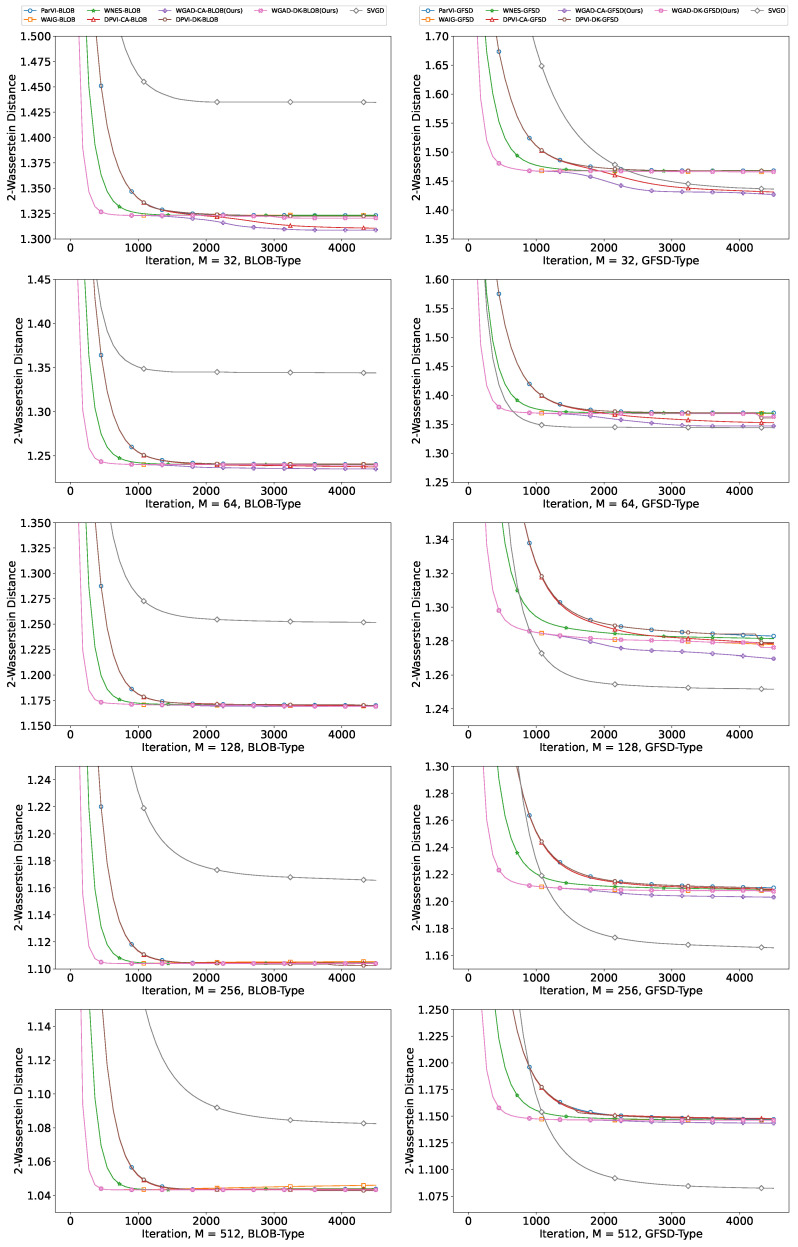 Figure 7
Figure 7 Figure 8
Figure 8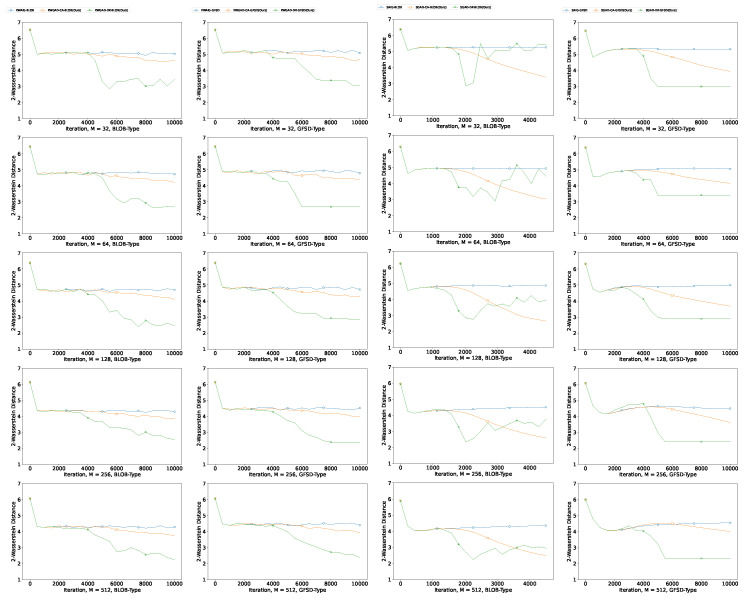 Figure 9
Figure 9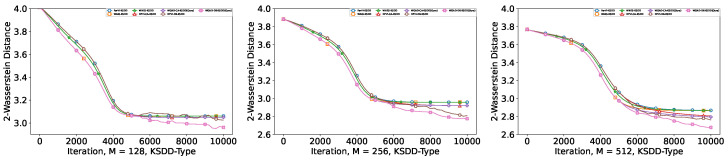 Figure 10
Figure 10- —National Natural Science Foundation of China
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsGaussian Processes and Bayesian Inference · Advanced Neural Network Applications · Domain Adaptation and Few-Shot Learning
1. Introduction
Bayesian inference is an active area in modern machine learning that provides powerful tools for modeling unknown distributions and reasoning under uncertainty. Its applications range from natural language processing [1,2,3] and image processing [4,5,6,7] to knowledge representation [8,9,10,11]. The core of Bayesian inference is to estimate the target posterior distribution given the data.
Markov Chain Monte Carlo (MCMC) methods have been extensively employed in Bayesian inference, serving as a cornerstone for sampling from complex probability distributions. These methods rely on constructing a Markov chain that has the desired distribution as its equilibrium distribution. Through iterative sampling, MCMC methods facilitate the exploration of the sample space, providing a robust framework for estimating the posterior distributions critical to Bayesian approaches [12,13,14]. In the MCMC literature, acceleration methods such as Hamilton Monte Carlo (HMC) and underdamped Langevin dynamics, which optimize sampling efficiency and convergence speed, have been widely studied [15,16]. Furthermore, Sequential Monte Carlo (SMC) methods use dynamic weight techniques combined with resampling to tackle particle degeneracy and have been integrated with Hamiltonian Monte Carlo (HMC) to boost convergence [17,18,19].
Recently, Particle-based Variational Inference (ParVI) methods have gained significant attention in the Bayesian inference literature owing to their effectiveness in providing approximations of the target posterior distribution [20,21,22,23,24,25]. The essence of ParVI lies in deterministically evolving a system of finite particles iteratively and approximating the target distribution with this set of finite particles. Compared to traditional MCMC methods, PVI introduces repulsive forces among particles. This fundamental addition prevents the particles from collapsing or degenerating, ensuring a more robust distribution coverage. This feature is particularly beneficial in high-dimensional spaces, where MCMC methods may encounter difficulties due to particle degeneration. Typically, the rule of updating the particles is designed by simulating the probability space gradient flow of certain dissimilarity functional vanishing at . Since the seminal work on Stein Variational Gradient Descent (SVGD) [20] to the subsequent BLOB method [26], the Gradient Flow with Smoothed Density (GFSD) method [27], and the Kernel Setin Discrepancy Descent (KSDD) method [28], various effective ParVI methods have been proposed that adopt different dissimilarities or empirical approaches to simulate the probability gradient flow. (See Table 1).
However, these classical ParVIs only focus on simulating the first-order gradient flow in the Wasserstein space. To improve the efficiency of ParVIs, recent works explore different aspects of the underlying geometry structures in the probability space and design two types of refined particle systems with either accelerated position update or dynamic weight adjustment.
Accelerated position update. By considering the second-order information of the Wasserstein probability space, different accelerated position update strategies have been proposed [27,32]: Liu et al. [27] follows the accelerated gradient descent methods in the Wasserstein probability space [34,35] and derives the Wasserstein Nesterov’s (WNES) and Wasserstein Accelerated Gradient (WAG) methods, which update the particles’ positions with an extra momentum. Inspired by the Accelerated Flow on the space [36], the Accelerated Flow (ACCEL) method [32] directly discretizes the Hamiltonian gradient flow in the Wasserstein space and updates the position with the damped velocity field, effectively decreasing the Hamiltonian potential of the particle system. Later, Wang and Li [33] considered the accelerated gradient flow for general information probability spaces [37], and derived novel accelerated position update strategies according to the Kalman–Wasserstein/Stein Hamiltonian flow. Following similar analyses as in [36], they theoretically show that, under mild conditions, the Hamiltonian flow usually converges to the equilibrium faster compared with the original first-order counterpart, aligning with the Nesterov acceleration framework [38]. Numerous experimental studies demonstrate that these accelerated position-update strategies usually drift the particle system to the target distribution more efficiently [27,32,33,39].Dynamic weight adjustment. Dynamic weight techniques, developed within Markov Chain Monte Carlo (MCMC) frameworks, have shown significant promise in improving sampling efficiency by adapting the weight of samples throughout the computation process. Building on these foundations, ref. [23] introduces the novel application of dynamic weights within the Wasserstein–Fisher–Rao (WFR) space to develop Dynamic-weight Particle-based Variational Inference (DPVI) methods. Specifically, they derive effective dynamical weight adjustment approaches by mimicking the reaction variational step in a JKO splitting scheme of first-order WFR gradient flow [40,41]. The seminal papers [42,43] provide foundational insights into the WFR geometry, particularly discussing an un-normalized dynamic weight variant based on a novel metric interpolating between the quadratic Wasserstein and the Fisher–Rao metrics, which is critical for developing these dynamic weight adjustment schemes. Compared with the commonly used fixed weight strategy, these dynamical weight adjustment schemes usually lead to less approximation error, especially when the number of particles is limited [23].
Given the contributions of both the acceleration technique and the dynamic-weight technique in enhancing the efficiency of ParVI, researchers have increasingly focused on developing a ParVI algorithm that can effectively integrate these features. One natural idea is to consider a ParVI algorithm that incorporates the second-order gradient flow in the WFR space, serving as a direct combination of an accelerated position update method (e.g., ACCEL, WNES, AIG) with a dynamic weight adjustment method (e.g., DPVI). However, we demonstrate that discretizing this flow generally does not yield a practical algorithm. Through our investigation, we discover that the primary obstacle lies in the intractable kinetic energy on the Fisher–Rao structure. For a detailed discussion on the IFR Hamiltonian flow, please refer to Appendix A.2.
1.1. Contribution
In this paper, we propose the first ParVI method, which possesses both accelerated position update and dynamical weight adjustment simultaneously. Specifically, we first construct a novel Information–Fisher–Rao (IFR) probability space, whereby the original information space is augmented with a Fisher–Rao structure. Infinitesimally, this Fisher–Rao structure is orthogonal to the Information structure. The orthogonality between metrics typically means orthogonality between tangent spaces, and details can be found in the work of [40]. Then, we present a novel Semi-Hamiltonian IFR (SHIFR) flow in this space, which simplifies the influence of the kinetic energy on the Fisher–Rao structure in the Hamiltonian IFR flow. By discretizing the SHIFR flow, a practical General Accelerated Dynamic-weight Particle-based Variational Inference (GAD-PVI) framework is proposed. The main contributions of our paper are as follows:
- We investigate the convergence property of the SHIFR flow and show that the target distribution is the stationary distribution of the proposed semi-Hamiltonian flow for proper dissimilarity functional . Moreover, our theoretical result also shows that the augmented Fisher–Rao structure yields an additional decrease in the local functional dissipation, compared to the Hamiltonian flow in the vanilla information space.
- We derive an effective finite-particle approximation to the SHIFR flow, which directly evolves the position, weight, and velocity of the particles via a set of ordinary differential equations. The finite particle system is compatible with different dissimilarity and associated smoothing approaches. We prove that the mean-field limit of the proposed particle system converges to the exact SHIFR flow under mild conditions.
- By adopting explicit Euler discretization for the finite-particle system, we create the General Accelerated Dynamic-weight Particle-based Variational Inference (GAD-PVI) framework, which updates positions in an acceleration manner and dynamically adjusts weights. We derive various GAD-PVI instances by using three different dissimilarities and associated smoothing approaches (KL-BLOB, KL-GFSD, and KSD-KSDD) on the Wasserstein/Kalman–Wasserstein/Stein IFR space, respectively.
- Furthermore, we showcase the versatility of our GAD-PVI by extending its applicability to scenarios where the analytic score is unavailable. We illustrate that the GAD-PVI algorithm can be utilized to develop methods for generating new samples from an unknown target distribution, given only a set of i.i.d. samples. This is achieved by employing suitable dissimilarities and their associated approximation approaches, such as Maximum-Mean-Distance–Maximum-Mean-Distance Flow (MMD-MMDF) and Sinkhorn-Divergence–Sinkhorn-Divergence Flow (SD-SDF), in the GAD-PVI framework.
We evaluate our algorithms under both the variational inference scenario tasks and the i.i.d. sample’s accessible sampling tasks. The empirical results demonstrate the superiority of our GAD-PVI methods.
1.2. Notation
Given a probability measure on , we denote if its second moment is finite. For a given functional , denote its first variation at . We use to denote the set of continuous functions map from to . We denote as the i-th particle, for and as a positive semi-definite kernel function. We also denote the Dirac delta distribution with point mass located at as , and use to denote the convolution operation between and . Furthermore, we use ∇ and to denote the gradient and the divergence operator, respectively. We denote a general information probability space as , where denotes the one-to-one information metric tensor mapping elements in the tangent space to the cotangent space . The inverse map of is denoted as .
2. Related Works
The core of Bayesian inference is to estimate the posterior distribution given the data. By reformulating the inference problem into an optimization problem, variational inference (VI) seeks an approximation within a certain family of distributions that minimizes the Kullback–Leibler (KL) divergence to the posterior. However, the construction of approximating distributions can be restrictive, which may lead to poor approximation [44].
Recently proposed Particle-based Variational Inference methods (ParVIs) use a set of samples, or particles, to represent the approximating distribution and deterministically update particles by minimizing the KL divergence to the target. ParVIs are more non-parametrically flexible than VIs. Stein Variational Gradient Descent (SVGD) [20] is the first and most representative of the ParVI-type algorithms. It updates the set of particles by incorporating a proper vector field that minimizes the kernelized Stein discrepancy with respect to the target. SVGD was later understood as simulating the Wasserstein gradient flow of the KL-divergence on a certain kernel-dependent probability space [45]. The unique benefits of SVGD make it popular in various applications, including Generative Models [46,47], reinforcement learning [48,49], and recommendation systems [50].
Inspired by this gradient flow understanding of SVGD, more ParVIs have been developed by simulating the gradient flow on the Wasserstein space . Like the BLOB method [29], the Gradient Flow with Smoothed Density (GFSD) method [27] and the Kernel Stein Discrepancy Descend (KSDD) method [28] utilize different kernel tricksters to approximate the vector field form of the gradient flow and update the finite set of particles.
On accelerating ParVI, initially, Wasserstein Nesterov’s (WNES) method and Wasserstein Accelerated Gradient (WAG) method [27] leveraged the geometry of the underlying space to devise the Riemannian acceleration mechanism of ParVI with auxiliary points. More recently, The Accelerated Flow (ACCEL) [32] method has utilized the Hamiltonian dynamic on the original probability space to develop an accelerated ParVI method by incorporating a set of momentum variables. Further, the Accelerated Information Gradient Flow (AIG) method [33] extends such technique to general metric probability space beyond the Wasserstein metric. We follow the idea of leveraging the Hamiltonian flow on the probability space to develop second-order accelerated ParVIs, as this approach provides theoretical guarantees.
Regarding the dynamic-weight ParVIs, DPVI methods [23] include the first dynamic-weight ParVI method, which maintains a set of weighted particles and hence has a better approximation ability. DPVIs are proposed by leveraging the augmented Wasserstein–Fisher–Rao space rather than the vanilla Wasserstein space. The idea behind DPVI originates from MCMC–Birth–Death (MCMC-BD) [51], an MCMC-type sampling algorithm that is the first algorithm to introduce the Wasserstein–Fisher–Rao flow into the sampling literature. However, it is important to note that while MCMC-BD can transfer particles, it is unable to obtain weighted particles.
Recently, several studies have begun utilizing the mechanism of probability gradient flow to generate new samples from an unknown target distribution when only given a set of i.i.d. samples. One pioneering study introduced the Maximum Mean Discrepancy Flow (MMDF) method [30], which considers a particle flow to minimize the Maximum Mean Discrepancy (MMD) between the model particles and the accessible set of i.i.d. samples. The Sinkhorn Divergence Flow (SDF) method [52] instead considers the Sinkhorn Divergence (SD), which operates by finding the push-forward mapping in a Reproducing Kernel Hilbert Space that allows the fastest descent of SD and consequently solves the SD minimization problem iteratively. Note that this sampling setting is closely related to the emerging field of Generative Models (GMs), which includes well-known models such as Generative Adversarial Networks (GANs) [53], variational autoencoders (VAEs) [54], and Diffusion Models (DMs) [55,56]. However, it is important to clarify that the objective of this paper is not to achieve state-of-the-art performance in Generative Models but rather to demonstrate the extensibility of our technique within this particular setting. Indeed, there have been studies attempting to obtain state-of-the-art Generative Models based on Wasserstein Gradient Flow, such as the Neural Sinkhorn Gradient Flow (NSGF) method [31] and the S-JKO (JSD) method [57]. However, these methods typically require complex network design and additional components. Addressing this challenge remains an open question and is not the primary focus of this paper.
3. Preliminaries
When dealing with Bayesian inference tasks, variational inference methods approximate the target posterior with an easy-to-sample distribution and recast the inference task as an optimization problem over [58]:
To solve this optimization problem, Particle-based Variational Inference (ParVI) methods generally simulate the gradient flow of in a certain probability space with a finite particle system, which transports the initial empirical distribution toward the target distribution iteratively. Given an information metric tensor , the gradient flow in the information probability space takes the following form [59]:
3.1. Wasserstein Gradient Flow and Classical ParVIs
Since the seminal work on Stein Variational Gradient Descent (SVGD) [20], many ParVI methods have focused on flows in the Wasserstein space, where the inverse of the Wasserstein metric tensor is defined as
and the Wasserstein gradient flow is defined as
Based on the probability flow (4) on the density, existing ParVIs maintain a set of particles and directly modify the particle position according to the following ordinary differential equation:
where denotes the empirical distribution. Since the first total variation of might not be well defined for the discrete empirical distribution, various ParVI methods have been proposed by choosing different dissimilarities and associated particle approaches, depending on the accessible information of the target distribution . When the score of the target distribution is accessible, some have ParVIs adopted the KL divergence or Kernel Stein Discrepancy (KSD) as the , e.g., KL-BLOB [26], KL-GFSD [27], and KSD-KSDD [28]. When only samples of are provided, integral-based dissimilarities like Maximum Mean Divergence (MMD) and Sinkhorn Divergence, which are naturally compatible with sample approximation, are adopted to develop ParVIs, like the MMDF method [30] and SD method [52].
3.2. Hamiltonian Gradient Flows and Accelerated ParVIs
The following Hamiltonian gradient flow in the general information probability space has recently been utilized to derive more efficient ParVI methods
where represents the Hamiltonian momentum variable, while signifies the Hamiltonian potential. It is pertinent to note that the Hamiltonian momentum variable can be interpreted as the momentum of . Note that the Hamiltonian flow (6) can be regarded as the second-order accelerated version of the information gradient flow (2) and usually converges faster to the equilibrium of the target distribution under mild conditions [32,33,39]. By reformulating the partial differential equations in terms of into Lagrangian formulations with respect to samples and and further finite approximation, we obtain a simple augmented particle system , which evolves the position and velocity of particles simultaneously. As the position update rule of also uses the extra velocity information, the induced system is said to have an accelerated position update. By discretizing the continuous particle system, several accelerated ParVI methods have been proposed, which converge faster to the target distribution in numerous real-world Bayesian inference tasks [32,33].
3.3. Wasserstein–Fisher–Rao Flow and Dynamic-Weight ParVIs
Recently, the Wasserstein–Fisher–Rao (WFR) Flow has been used to derive effective dynamic weight adjustment approaches to mitigate the fixed-weight restriction of ParVIs [23]. The inverse of the WFR metric tensor is
where , and the WFR gradient flow are written as
Since the WFR space can be regarded as the orthogonal sum of the Wasserstein space and the Fisher–Rao space, ref. [23] mimics a JKO splitting scheme for the WFR flow, which deals with the position and the weight with the Wasserstein transport and the Fisher–Rao variational distortion, respectively. Given a set of particles with position, and weight , the Fisher–Rao distortion can be approximated by the following code
According to (9), ref. [23] derive two dynamical weight-adjustment schemes and propose the Dynamic-Weight Particle-based Variational Inference (DPVI) framework, which is compatible with several dissimilarity functionals and associated particle approaches. The dynamic weight technique employed here differs from the one utilized in the dynamic-weight Sequential Monte Carlo (SMC) literature [19]. SMC-type algorithms achieve dynamic weight sampling through importance sampling, which is predicated on maintaining an estimated posterior. The weights of each incoming particle are individually calculated upon their arrival. The dynamic weight technique combined with sequential importance resampling is employed to circumvent degeneracy. In contrast, the Fisher–Rao dynamic weight technique iteratively adjusts the weights of the existing particles in an interactive way to augment the final approximation accuracy.
3.4. Dissimilarity Functionals
ParVIs typically select the probability gradient flow functional to be a divergence with respect to the target distribution, denoted as . In this context, we will now introduce four frequently employed dissimilarities, along with their corresponding first variation forms. The first two dissimilarities are typically employed in score-based tasks due to their logarithmic form. On the other hand, the last two dissimilarities are commonly utilized in sample-based tasks, where only a set of i.i.d. samples is available, as they have an integral form that can be estimated using the Monte Carlo method. In this subsection, K denotes a positive semi-definite kernel function.
3.4.1. Kullback–Leibler Divergence
The Kullback–Leibler (KL) divergence is the most often used divergence in the ParVI field [20,27,33], when selecting KL divergence, the functional is written as
The first variation of this function has the form
3.4.2. Kernel Stein Discrepancy
The Kernel Stein Discrepancy (KSD) has recently been adopted as the dissimilarity functional in the ParVI method KSDD [28], which is written as follows:
where is the Stein Kernel, defined through . We follow the KSDD method to consider ; then, the first variation of this functional is written as
3.4.3. Maximum Mean Discrepancy
The Maximum Mean Discrepancy is a widely used integral probability metric, which has the following form:
Consider ; then, the first variation of this functional is written as
3.4.4. Sinkhorn Divergence
Sinkhorn divergence (SD) is derived as a computationally efficient counterpart to the famous Wasserstein distance by utilizing the regularization technique. The entropy-regularized Wasserstein distance is defined as
where is a regularization coefficient, denotes the product measure, i.e., and we fix and abbreviate . According to the Fenchel–Rockafellar theorem, the entropy-regularized Wasserstein problem (16) has an equivalent dual formulation, which is given as follows [60]:
where C is the cost function in (16) and is the tensor sum: . The maximizers and of (17) are called the -potentials of . Note that, although computationally more efficient than the distance, the distance is not a true metric, as there exists such that when , which restricts the applicability of . As a result, the following Sinkhorn divergence is proposed [60]:
Consider . Let be the -potentials of and let be the -potentials of . The first variation of the Sinkhorn functional is
4. Methodology
In this section, we present our General Accelerated Dynamic-weight Particle-based Variational Inference (GAD-PVI) framework, detailed in Algorithm 1. We first introduce a novel augmented Information–Fisher–Rao space, and the Semi-Hamiltonian-Information–Fisher–Rao (SHIFR) flow in the space. The theoretical analysis of SHIFR shows that it usually possesses an additional decrease in the local functional dissipation compared to the Hamiltonian flow in the original information space. Then, effective finite-particle systems, which directly evolve the position, weight, and velocity of the particles via a set of ordinary differential equations, are constructed based on SHIFR flows in several IFR spaces with different underlying information metric tensors. We demonstrate that the mean-field limit of the constructed particle system exactly converges to the SHIFR flow in the corresponding probability space. Next, we develop the GAD-PVI framework by discretizing these continuous-time finite-particle formulations, which enables simultaneous accelerated updates of particles’ positions and dynamic adjustment of particles’ weights. We present nine effective GAD-PVI algorithms that use different underlying information metric tensors, dissimilarity functionals, and the associated finite-particle empirical approximation. Algorithm 1 General Accelerated Dynamic-weight Particle-based Variational Inference (GAD-PVI) frameworkInput: Initial distribution , position adjusting step-size , weight adjusting step-size , velocity field adjusting step-size , velocity damping parameter .
- 1:Choose a suitable functional and its empirical approximation according to the sampling setting.
- 2:for do
- 3: for do
- 4: Update positions ’s according to (26).
- 5: end for
- 6: for do
- 7: Adjust velocity field ’s according to (27).
- 8: end for
- 9: if Adopt CA strategy then
- 10: for do
- 11: Adjust weights ’s according to (28).
- 12: end for
- 13:else if Adopt DK strategy then
- 14: for do
- 15: Calculate the duplicate/kill rate:
- 16: end for
- 17: for do
- 18: if then
- 19: Duplicate the particle with probability and kill one which is uniformly chosen from the rest.
- 20: else
- 21: Kill the particle with probability and duplicate one which is uniformly chosen from the rest.
- 22: end if
- 23: end for
- 24: end if
- 25:end for
- 26:Output: .
4.1. Information–Fisher–Rao Space and Semi-Hamiltonian-Information–Fisher–Rao Flow
To define the augmented Information–Fisher–Rao probability space, we introduce the Information–Fisher–Rao metric tensor , whose inverse is defined as follows.
where and denotes certain underlying information metric tensor. Note that is formed by the inf-convolution of and Fisher–Rao metric tensor.
Based on , we introduce the following novel semi-Hamiltonian flow of on the Information–Fisher–Rao space
where denotes the Hamiltonian velocity and
denotes the Hamiltonian potential in the IFR space. Compared to the full Hamiltonian flow of in the IFR space, the SHIFR flow (21) ignores the influence of the Fisher–Rao kinetic energy on the Hamiltonian field . Intuitively, at the gradient flow level, the Fisher–Rao metric modifies the mass in the vertical dimension, while the Wasserstein metric redistributes mass in the horizontal dimension. In the finite particle approximation system, we manipulate the weights and positions of particles to emulate the underlying infinite-dimensional mass of the distribution . The Fisher–Rao metric exclusively adjusts the weights of particles, serving as an analogy for altering the mass in the vertical dimension in the infinite case. Conversely, the Wasserstein metric changes the position of particles, acting as an analogy for adjusting the mass in the horizontal dimension. These two techniques interact with each other, collectively facilitating faster convergence.
Later, we will show that SHIFR can be directly transformed into a particle system consisting of odes on the positions, velocities, and weights of particles for proper underlying information metric tensor, while it is generally infeasible to obtain such a direct particle system according to the corresponding full Hamiltonian flow because it is difficult to handle the Fisher–Rao kinetic energy. Given that the Fisher–Rao kinetic energy term diminishes when approaching the flow’s equilibrium, it is acceptable for the SHIFR flow to disregard this complex term while still maintaining the target distribution as its stationary distribution. The following proposition establishes that the stationary property of the SHIFR Flow (21) is still the target distribution.
Proposition 1. The target distribution and zero-velocity ( means that a function defined on that always maps to zero) is the stationary distribution of the SHIFR flow (21) with dissimilarity functional , which satisfies with any information metric tensor .
Moreover, this semi-Hamiltonian flow would converge faster than the Hamiltonian flow in the original information space on account of the extra functional dissipation property. Here, we establish the extra decrease property in terms of functional dissipation of the SHIFR gradient flow (21) in the following proposition.
Proposition 2. For arbitrary and , the local dissipation of functional following the SHIFR gradient flow (21) starting from has an additional functional dissipation term compared to the ones following the Hamiltonian flow in non-augmented space (6). Take the Wasserstein case as an example. Denote the probability path starting from following the W-SHIFR flow as , and following the Hamiltonian flow in vanilla space as . We have
We acknowledge that these theoretical analyses are currently limited to the variational inference case, where the functional is set to a dissimilarity with respect to a target distribution , denoted as . Future work will aim to explore the semi-Hamiltonian system in a broader statistical physics context.
With different underlying information metric tensor in , we can obtain different SHIFR flows. Suitable includes the Wasserstein metric tensor, the Kalman–Wasserstein metric tensor (KW-metric) and the Stein metric tensor (S-metric). For instance, the SHIFR flow with Wasserstein metric (Wasserstein–SHIFR flow) is written as
Note that in the subsequent section, we focus on the Wasserstein–SHIFR flow and defer the detailed formulations with respect to KW-SHIFR and S-SHIFR to Appendix B.1 and Appendix B.2 due to limited space.
4.2. Finite-Particles Formulations to SHIFR Flows
Now, we derive the finite-particle approximation to the SHIFR flow, which directly evolves the position , weight , and velocity of the particles. Specifically, we construct the following ordinary differential equation system to simulate the Wasserstein–SHIFR flow (24):
While the dynamic weight adjustment component of the proposed method (25) is quite similar to the ones in [23], as both are derived based on the Fisher–Rao structure of the underlying gradient flow, the proposed method can further achieve accelerated position updates. The following proposition demonstrates that the mean-field limit of the particle system (25) corresponds precisely to the Wasserstein–SHIFR flow in (24).
Proposition 3. Suppose the empirical distribution of M weighted particles weakly converges to a distribution when . Then, the path of (25) starting from and with initial velocity weakly converges to a solution of the Wasserstein–SHIFR gradient flow (24) starting from and as :
Here, Proposition 3 serves as a bridge, substantiating that our proposed particle methods (25) possess appealing theoretical properties, as they are rooted in a mean-field limit of the Wasserstein–SHIFR flow (24) with superior theoretical attributes.
4.3. GAD-PVI Framework
Generally, it is impossible to obtain an analytic solution of the continuous finite-particle formulations (25); thus, a numerical integration method is required to derive an approximate solution. Note that any numerical solver, such as the implicit Euler method [61] and the higher-order Runge–Kutta method [62], can be used. Here, we follow the tradition of ParVIs to adopt the first-order explicit Euler discretization [63], since it is efficient and easy to implement [23], and propose our GAD-PVI framework, as listed in Algorithm 1. Like other ParVI methods, our GAD-PVI algorithm also sustains a set of particles and alters their attributes. However, the distinctive feature of GAD-PVI methods is their unique capacity to concurrently modify three different attributes, namely position, weight, and velocity. This pioneering approach sets GAD-PVI methods apart from other ParVI variants.
4.3.1. Updating Rules
Suppose the functional and its empirical approximation of the first variation is decided. We adopt a Jacobi-type strategy to update the position , velocity field , and weight ; i.e., the calculations in the -th iteration are totally based on the variables obtained in the k-th iteration. Therefore, starting from M weighted particles located at with weights and , GAD-PVI with respect to the Wasserstein–SHIFR flow first updates the positions of particles according to the following rule:
Then, it adjusts the velocity field as
and particles’ weights as follows:
Here denotes the empirical distribution, and are the discretization step sizes. It can be verified that the total mass of is conserved and remains a valid probability distribution during the whole procedure of GAD-PVI, i.e., for all k. The detailed updating rules of GAD-PVI with respect to the KW-SHIFR and S-SHIFR can be found in Appendix B.3.
Notice that, in comparison to traditional ParVIs, the incorporation of a position acceleration scheme and dynamic-weight scheme results in minimal additional computational costs. This is due to the fact that the number of operations that contribute to time complexity bottlenecks, specifically the calculation of and , remains unchanged.
4.3.2. Dissimilarities and Approximation Approaches
Our GAD-PVI framework is compatible with different dissimilarities ( ) and their associated approximation approaches of the first variation. By selecting appropriate dissimilarities and approximation approaches, our GAD-PVI framework can be employed effectively for both score-based tasks and sample-based tasks.
Score-Based Scenario
When the score function value of the target distribution is accessible, the commonly used underlying dissimilarities in ParVIs are KL-divergence [20,27,33] and KSD [64].
For KL divergence, the total variation (11) includes the term , which is ill-defined for the discrete empirical distribution . Consequently, the use of approximation approaches is necessary to resolve this issue. Commonly employed approximation approaches include BLOB [29] and GFSD [27].
The BLOB approximation approach reformulates the intractable term as and smooth the density with a kernel function K, resulting in the approximation
for a discrete density . This leads to the following approximation results:
The GFSD approximation approach directly approximates by smoothing the empirical distribution with a kernel function K: , which leads to the following approximations:
The KSDD directly approximates the first variation and its gradient of KSD (12) by employing Monte Carlo sampling with the empirical distribution . KSDD constructs the following finite-particle approximations:
Sample-Based Scenario
When only the samples of the target distribution is accessible, we then take as a surrogate of ; the commonly used underlying dissimilarities in this case are MMD [30] and SD [52].
MMDF directly approximates the first variation and its gradient of MMD (14) by employing Monte Carlo sampling with both the empirical distribution and samples from the target distribution. Let and ; MMDF constructs the following finite-particle approximations:
SDF directly leverages samples from and to obtain the approximated Sinkhorn potentials and . Consequently, it is able to approximate the first variation of SD as follows.
The details of utilizing samples to obtain the approximated Sinkhorn potential can be found in [31,52].
4.3.3. An Alternative Weight Adjusting Approach
Except for the Continuous Adjusting (CA) strategy, the Duplicate/Kill (DK) strategy, which is a probabilistic discretization strategy to the Fisher–Rao part of (24), can also be adopted in GAD-PVI. This strategy duplicates/kills particle according to an exponential clock with an instantaneous rate:
Specifically, if , we duplicate the particle with probability and kill another one with uniform probability to conserve the total mass; if , we kill the particle with probability , and duplicate another one with uniform probability. By replacing the CA strategy (28) in the GAD-PVI framework, we could obtain the DK variants of GAD-PVI methods.
4.3.4. GAD-PVI Instances
With different underlying information metric tensors (W-metric, KW-metric and S-metric), weight adjustment approaches (CA and DK), and dissimilarities/associated approximation approaches (KL-BLOB, KL-GFSD, KSD-KSDD, MMD-MMDF, SD-SDF), we can derive various instances of GAD-PVI, named as WGAD/KWGAD/SGAD-CA/DK-BLOB/GFSD/KSDD/MMDF/SDF. While the aforementioned updating rules, approximation approaches, and weight adjustment methods have been previously proposed, we conduct a comprehensive investigation of these components within a single framework and view them from a modular standpoint. Moreover, GAD-PVI designs a general inference framework for both the score-function scenario and the sample-based scenario, whereas previous works have only focused on one of these.
5. Experiments
In this section, we conduct empirical studies with our GAD-PVI algorithms. Our empirical studies include score-based tasks where the score function value of the target distribution is accessible, as well as sample-based tasks where only i.i.d. samples from the target distribution are available. Here, we focus on the instances of GAD-PVI with respect to the W-SHIFR flows. The experimental results for methods with respect to the KW-SHIFR and S-SHIFR flows are provided in Appendix A.3. Given that the Full Hamiltonian Flow on the IFR Space does not facilitate the development of practical algorithms, it is not feasible to incorporate the direct combination of an accelerated position update method (such as ACCEL, WNES, AIG) with a dynamic weight adjustment method (such as DPVI) into our experiments.
Our proposed algorithm simultaneously incorporates both accelerated position updates and dynamic weight adjustments. Therefore, comparing it to these baseline methods, which only possess one of these characteristics, can function as an ablation study for the components within our method.
Compared to existing dynamic-weight ParVIs, GAD-PVI benefits from the accelerated position update derived from the Hamiltonian acceleration mechanism of the SHIFR flow, enabling it to converge more quickly to the target distribution. When compared to ParVIs with only accelerated position updates, GAD-PVI benefits from the dynamic weight adjustment resulting from the Fisher–Rao component of the SHIFR flow, achieving superior approximation accuracy to the target distribution.
5.1. Score-Based Experiments
In the setting where we can access the analytical score function value of the target distribution, we choose KL-BLOB and KL-GFSD as the dissimilarity and empirical approximation of our GAD-PVI methods. Note that we do not include GAD-PVI methods with the KSDD empirical approaches, as they are more computationally expensive and have been widely reported to be less stable [23,64]. We include four classes of methods as our baseline: classical ParVI algorithms (SVGD, GFSD, and BLOB), the Nesterov accelerated ParVI algorithms (WNES-BLOB/GFSD), the Hamiltonian accelerated ParVI algorithms (WAIG-BLOB/GFSD), and the Dynamic-weight ParVI algorithms (DPVI-CA/DK-BLOB/GFSD).
In this score function setting, we consider four tasks, comprising two simulations: a 10-D Single-mode Gaussian model (SG) and a Gaussian mixture model (GMM), as well as two real-world applications: Gaussian Process (GP) regression and Bayesian neural network (BNN). For all the algorithms, the particles’ weights are initialized to be equal. In the first three experiments, we tune the parameters to achieve the best distance. In the BNN task, we split of the training set as our validation set to tune the parameters. Note that the position step size is tuned via a grid search for the fixed-weight ParVI algorithms and then used in the corresponding dynamic-weight algorithms. The acceleration parameters and weight adjustment parameters are tuned via grid search for each specific algorithm. We repeat all the experiments 10 times and report the average results. Due to limited space, only parts of the results are reported in this section. We refer readers to Appendix C for the results on SG and additional results for GMM, GP, and BNN.
5.1.1. Gaussian Mixture Model
We consider approximating a 10-D Gaussian mixture model with two components, weighted by and respectively. We run all algorithms with particle number . In Figure 1, we report the 2-Wasserstein ( ) distance between the empirical distribution generated by each algorithm and the target distribution with respect to iterations of different ParVI methods. We generate 5000 samples from the target distribution as a reference to evaluate the distance by using the POT library http://jmlr.org/papers/v22/20-451.html (accessed on 16 August 2023).
The results demonstrate that our GAD-PVI algorithms consistently outperform their counterpart with only one (or none) of the accelerated position update strategy and dynamic weight adjustment approach. Furthermore, the CA weight-adjustment approach usually results in a lower compared to the DK scheme, and WGAD-CA-BLOB/GFSD usually has the fastest convergence and the lowest final distance to the target.
5.1.2. Gaussian Process Regression
The Gaussian Process (GP) model is widely adopted for uncertainty quantification in regression problems [65]. We follow the experimental setting in [66], and use the dataset LIDAR (denoted as ), which consists of 221 observations. Of scalar variables and . We denote and , and the target log-posterior with respect to the model parameter is defined as follows:
Here, is a covariance function with , and represents the identity matrix. In this task, we set the particle number to for all the algorithms.
We report the distance between the empirical distribution after 10,000 iterations and the target distribution in Table 2. The target distribution is approximated by 10,000 reference particles generated by the HMC method after it achieves its equilibrium [67]. It can be observed that both the accelerated position update and the dynamic weight adjustment result in a decreased , and GAD-PVI algorithms consistently achieve the lowest to the target. Furthermore, the results also show that the CA variants usually outperform their DK counterpart, as CA is able to adjust the weight continuously on while DK sets the weight to either 0 or .
In Figure 2, we plot the contour lines of the log posterior and the particles generated by four representative algorithms, namely BLOB, WAIG-BLOB, DPVI-CA-BLOB, and WGAD-CA-BLOB, at different iterations (0, 100, 500, 2000, 10,000). The results indicate that the particles in WAIG-BLOB and WGAD-CA-BLOB exhibit a faster convergence to the high probability area of the target due to their accelerated position updating strategy, and the DPVI-CA and WGAD-CA algorithms finally offer broader final coverage, as the CA dynamic weight adjustment strategy enables the particles to represent the region with arbitrary local density mass instead of a fixed mass.
5.1.3. Bayesian Neural Network
In this experiment, we study a Bayesian regression task with a Bayesian neural network on four datasets from UCI, http://archive.ics.uci.edu/ml/datasets (accessed on 16 August 2023), and and LIBSVM, https://www.csie.ntu.edu.tw/~cjlin/libsvmtools/datasets/ (accessed on 16 August 2023). Given a training dataset , where denotes the input covariate vector and is the corresponding prediction, this task aims at predicting the output for a new input from the perspective of Bayesian inference:
where denotes the model parameter of the neural network and is the target posterior given training dataset . Since the explicit integration is intractable, one can resort to sampling methods to approximate the target posterior and transfer the integration problem into calculating the average with a set of samples. We follow the experimental setting from [20,23], which models the output as a Gaussian distribution and uses a prior for the inverse covariance. We use a one-hidden-layer neural network with 50 hidden units and maintain 128 particles. For all the datasets, we set the batch size as 128.
We present the Root Mean Squared Error (RMSE) of various ParVI algorithms in Table 3. The results demonstrate that the combination of the accelerated position updating strategy and the dynamically weighted adjustment leads to a lower RMSE. Notably, WGAD-CA type algorithms outperform other methods in the majority of cases.
5.2. Sample-Based Experiments
In the setting where we can only obtain the i.i.d. samples of the target distribution, we choose MMD-MMDF and SD-SDF as the dissimilarity and empirical approximation of our GAD-PVI methods.
We are the first to consider the intricate structure of the underlying gradient flow within the ParVI algorithm under the sample-based setting. Consequently, we include classical ParVI algorithms (MMDF and SDF) as our baseline methods, along with DPVI-type and WAIG-type algorithms as ablation baselines. In this sample-based setting, we consider two tasks: the shape morphing task between different 2-D icons and the Sketching task of high-resolution pictures. For all the algorithms, the particles’ weights are initialized to be equal.
Note that the position steps are tuned via grid search for the baseline ParVI algorithms and then used in the corresponding GAD-PVI algorithms. The acceleration parameters and weight adjustment parameters are tuned via grid search for each specific algorithm. We repeat all the experiments 10 times and report the average results.
5.2.1. Shape Morphing
In this experiment, we study the task of shape morphing between different icons. The source shape and target shape are distributions lying in . We need to move points sampled uniformly from shape A to shape B. This task is often considered in the Wasserstein Barycenter literature [68,69,70]. Note that, to make the task more complex, we add an unbalanced distortion on the X-axis to the target distribution so that the probability distribution density on the left side of the target distribution is greater than that on the right. We consider a single loop shape morphing between the four icons, i.e., A(CAT), B(SPIRAL), C(HEART), and D(CHICKEN).
In Figure 3, we report the 2-Wasserstein ( ) distance between the empirical distribution generated by each algorithm and the target icon with respect to iterations of different ParVI methods. We generate 2000 samples from the target distribution as a reference to evaluate the distance. The results demonstrate that our GAD-PVI algorithms consistently outperform their baselines.
Table 4 presents the average distance to the target distribution after 2000 iterations (MMDF-Type) or 100 iterations (SDF-Type). It can be observed that GAD-PVI methods consistently achieve the lowest distance to the target, attributed to their dynamic weight adjustment.
5.2.2. Picture Sketching
This section presents the results of the picture sketching experiment, a task that can be viewed as approximating a given picture with particles and is therefore called picture sketching. Specifically, this section uses real cheetah images as original data, image pixels as particle points, and gray values of pixels as weights to generate discrete target distribution in space. In this experiment, all algorithms are initialized to 1000 equal-weight particle points, and all particle points are initially sampled from uniform noise distribution.
In Figure 4, we report the 2-Wasserstein ( ) between the empirical distribution generated by each algorithm and the target picture with respect to iterations of different ParVI methods. The results demonstrate that our GAD-PVI algorithms consistently outperform their baselines and the CA weight-adjustment approach usually results in the lowest distance to the target and fastest convergence.
Figure 5 shows the sketching process from the initial noise to the target picture of different ParVIs. In this visualization, particle points with higher weights are represented as pixels with brighter intensities. The results demonstrate that ParVI with accelerated position updates converges more rapidly towards the target picture. Furthermore, ParVI with dynamic-weight adjustment exhibits superior ability in accurately depicting the target picture. Specifically, the ParVI algorithm with dynamic-weight adjustment effectively captures the chiaroscuro between the cheetah’s two ears, which is not evident in the fixed-weight baseline approach.
6. Conclusions
In this paper, we propose the General Accelerated Dynamic-Weight Particle-based Variational Inference (GAD-PVI) framework, which adopts an accelerated position update scheme and dynamic weight adjustment approach simultaneously. Our GAD-PVI framework is developed by discretizing the Semi-Hamiltonian Information Fisher–Rao (SHIFR) flow on the novel Information–Fisher–Rao space. The theoretical analysis demonstrates that the SHIFR flow yields an additional decrease in the local functional dissipation compared to the Hamiltonian flow in the vanilla information space. We propose an effective particle system that evolves the position, weight, and velocity of particles via a set of odes for the SHIFR flows with different underlying information metrics. By directly discretizing the proposed particle system, we obtain our GAD-PVI framework. Several effective instances of the GAD-PVI framework have been provided by employing three distinct dissimilarity functionals and associated empirical approaches under the Wasserstein/Kalman–Wasserstein/Stein metric. Empirical studies demonstrate the faster convergence and reduced approximation error of GAD-PVI methods over the SOTAs.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Akbayrak S. Bocharov I. de Vries B. Extended variational message passing for automated approximate Bayesian inference Entropy 20212381510.3390/e 2307081534206724 PMC 8307095 · doi ↗ · pubmed ↗
- 2Sharif-Razavian N. Zollmann A. An overview of nonparametric bayesian models and applications to natural language processing Science 20087193 Available online: https://www.cs.cmu.edu/~zollmann/publications/nonparametric.pdf(accessed on 16 August 2023)
- 3Siddhant A. Lipton Z.C. Deep bayesian active learning for natural language processing: Results of a large-scale empirical studyar Xiv 20181808.05697
- 4Luo L. Yang J. Zhang B. Jiang J. Huang H. Nonparametric Bayesian Correlated Group Regression With Applications to Image Classification IEEE Trans. Neural Netw. Learn. Syst.2018295330534410.1109/TNNLS.2018.279753929994456 · doi ↗ · pubmed ↗
- 5Du C. Du C. Huang L. He H. Reconstructing Perceived Images From Human Brain Activities With Bayesian Deep Multiview Learning IEEE Trans. Neural Netw. Learn. Syst.2019302310232310.1109/TNNLS.2018.288245630561354 · doi ↗ · pubmed ↗
- 6Frank P. Leike R. Enßlin T.A. Geometric variational inference Entropy 20212385310.3390/e 2307085334356394 PMC 8307522 · doi ↗ · pubmed ↗
- 7Mohammad-Djafari A. Entropy, information theory, information geometry and Bayesian inference in data, signal and image processing and inverse problems Entropy 2015173989402710.3390/e 17063989 · doi ↗
- 8Jewson J. Smith J.Q. Holmes C. Principles of Bayesian inference using general divergence criteria Entropy 20182044210.3390/e 2006044233265532 PMC 7512964 · doi ↗ · pubmed ↗