Prognostic Properties of Instantaneous Amplitudes Maxima of Earth Surface Tremor
Alexey Lyubushin, Eugeny Rodionov

TL;DR
This paper proposes a method to analyze earth surface tremor data to detect potential earthquake precursors using statistical analysis of amplitude maxima.
Contribution
The novel approach combines EMD, Hilbert transform, and point process modeling to identify predictive patterns in tremor data preceding earthquakes.
Findings
Instantaneous amplitude maxima significantly precede earthquake occurrences more often than vice versa.
The method was applied to GPS data from 1047 stations in Japan, revealing consistent predictive patterns.
A parametric model confirmed the statistical significance of the observed temporal relationships.
Abstract
A method is proposed for analyzing the tremor of the earth’s surface, measured by GPS, in order to highlight prognostic effects. The method is applied to the analysis of daily time series of vertical displacements in Japan. The network of 1047 stations is divided into 15 clusters. The Huang Empirical Mode Decomposition (EMD) is applied to the time series of the principal components from the clusters, with subsequent calculation of instantaneous amplitudes using the Hilbert transform. To ensure the stability of estimates of the waveforms of the EMD decomposition, 1000 independent additive realizations of white noise of limited amplitude were averaged before the Hilbert transform. Using a parametric model of the intensities of point processes, we analyze the connections between the instants of sequences of times of the largest local maxima of instantaneous amplitudes, averaged over the…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
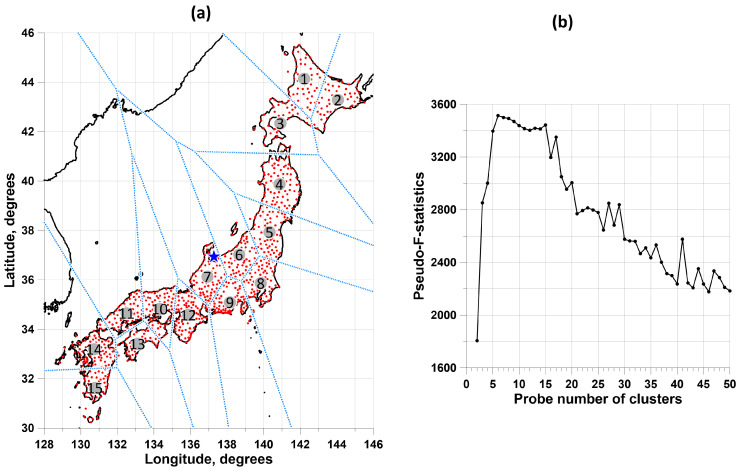 Figure 1
Figure 1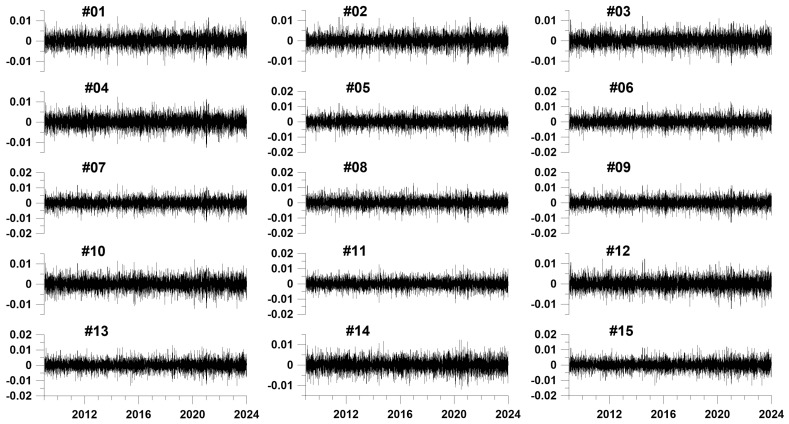 Figure 2
Figure 2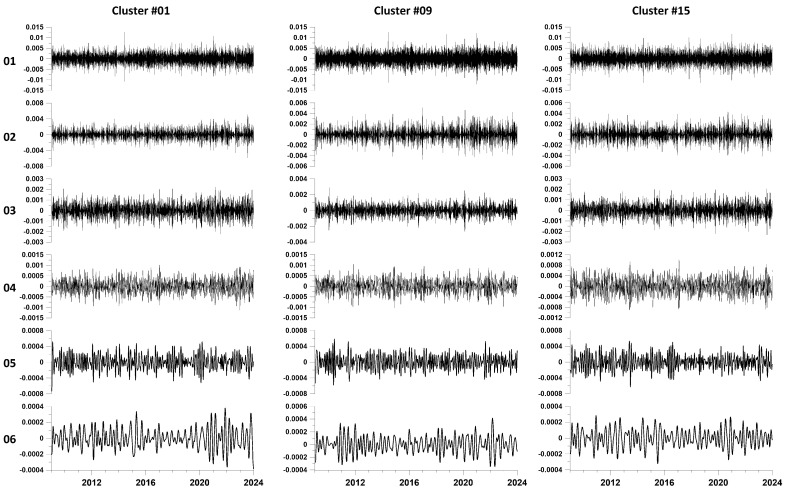 Figure 3
Figure 3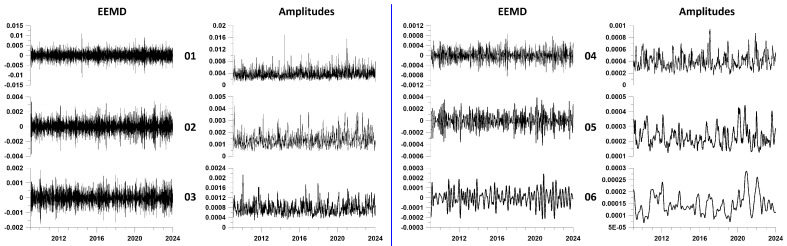 Figure 4
Figure 4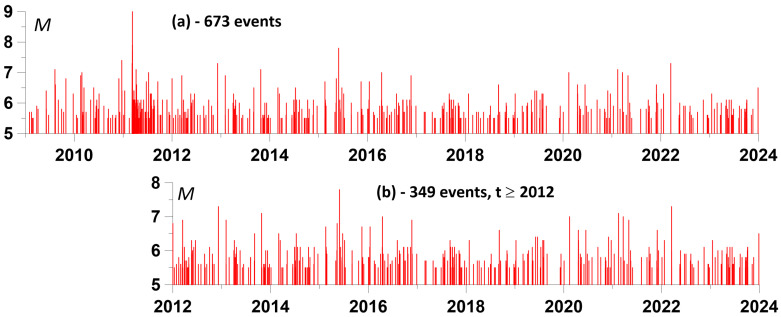 Figure 5
Figure 5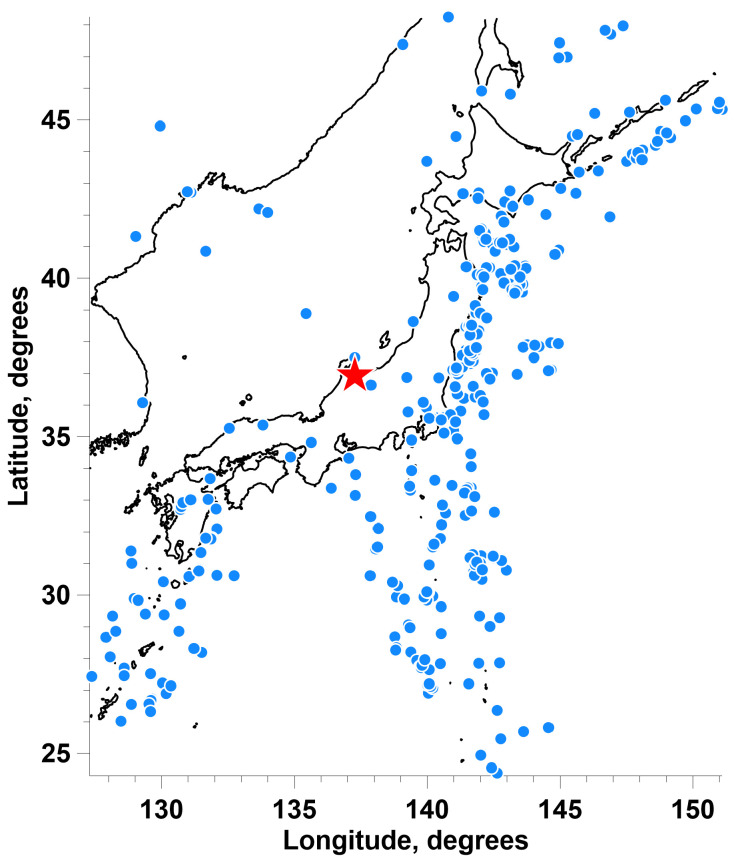 Figure 6
Figure 6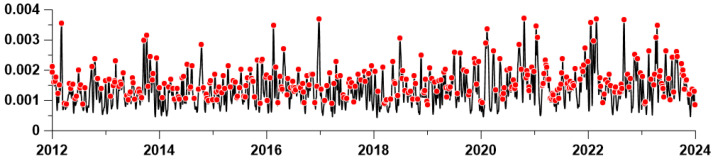 Figure 7
Figure 7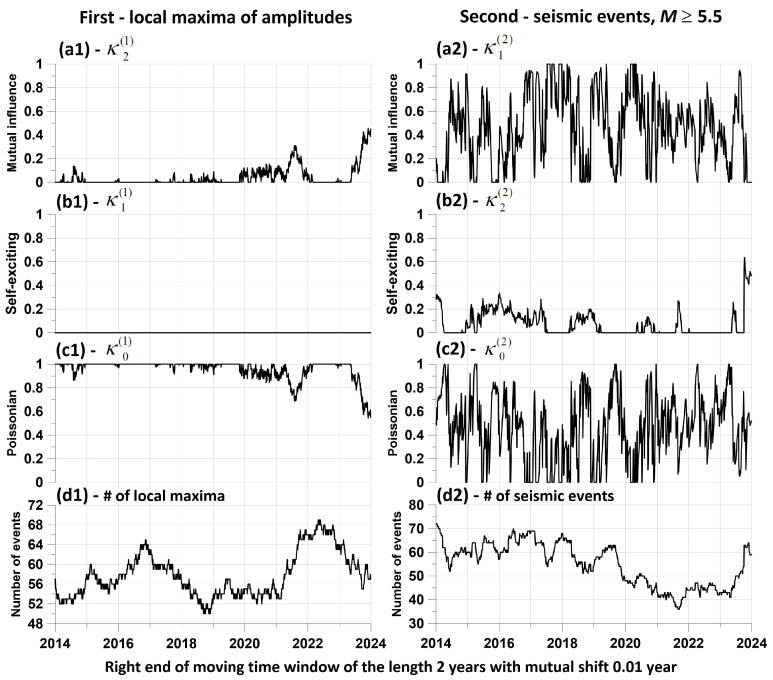 Figure 8
Figure 8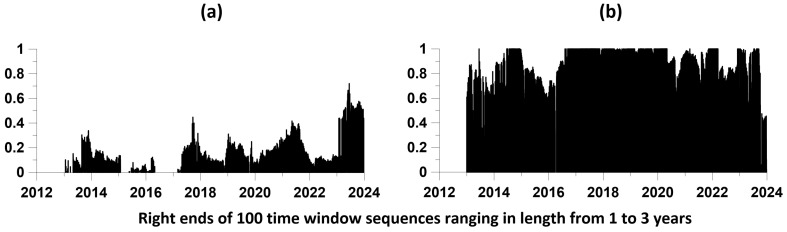 Figure 9
Figure 9Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsEarthquake Detection and Analysis · Geophysics and Sensor Technology · Seismic Waves and Analysis
1. Introduction
This article presents the further development of methods for analyzing ground surface tremor proposed in [1,2,3]. The coherence of the tremor of the earth’s surface was analyzed in [4,5]. In [6,7], coherent analysis of GPS time series was used to assess seismic hazard in Japan and California.
In this case, the main emphasis is on the use of the Hilbert–Huang expansion, which is well suited to take into account the effects of nonstationarity and nonlinearity in time series [8,9]. This method has been successfully used to analyze geodetic time series [10,11], when processing hydrological [12], financial [13], biological [14,15] and seismic [16] data.
The main purpose of the article is to clarify common hypotheses that movements of the earth’s crust recorded by GNSS may contain predictive information. That displacements recorded by geodetic methods respond to the effects of earthquakes is widely known and has been demonstrated many times. But extracting geodetic effects that predict seismic events is much more challenging. In our paper, we propose one method for detecting predictive effects in space geodesy data.
The works [17,18,19,20] analyzed the composition of GPS time series—both their high-frequency part and low-frequency seasonal components—in connection with the estimates of the velocities of tectonic plates. In [21,22,23,24,25,26,27], using multivariate statistical methods, the influence of hydrological loads on tectonic displacements of sections of the earth’s crust was studied. The influence of time delays on the sensitivity of GPS solutions due to the impact of ionospheric and tropospheric factors was analyzed in [28]. The causes of the occurrence of “anomalous harmonics” in the spectral decomposition of GPS time series were considered in [29].
The detailed structure of earth surface displacements presented in GPS time series has been analyzed in the works of a large number of scientists. One of the most popular approaches is the use of the maximum likelihood method for estimating the parameters of GPS time series models [30,31,32,33]. This method was used in [34,35,36] to estimate the parameters of the power spectrum shape and noise amplitude for data from different regions of the world, and the error estimates are discussed in [37,38]. The influence of the spectrum shape and noise amplitude on the errors of displacement velocity estimates was investigated in [39,40]. Phase correlations of GPS time series were studied in [41,42] using parametric models for a number of tectonically active regions.
In [43,44], principal component analysis, empirical orthogonal function analysis, and singular spectrum analysis were used to determine the most common spatial and temporal components of GPS time series. In [45], a joint analysis of accelerometer readings and the noise component of GPS time series was performed. The influence of non-stationary effects on the estimates of relative displacements of crustal blocks and station positions was studied in [46,47,48].
2. Data
GPS data of daily earth displacements are taken from the Nevada Geodetic Laboratory website [49] at: http://geodesy.unr.edu/gps_timeseries/tenv3/IGS14/, access at 19 August 2024.
The set of 1047 GPS stations within domain , , were chosen. These stations presented in Figure 1a have daily time series from the beginning of 2009 to the end of 2023 (15 years), with a total number of gaps of less than 365 samples, and the longest gap less than 182 samples. The vertical components of ground displacement are investigated. The choice of only the vertical component for Japan is due to the fact that it does not contain the catastrophic jump and subsequent long-term relaxation due to the impact of the mega-earthquake of 11 March 2011. Gaps in the GPS time series are filled in using information from the left and right neighborhoods of the gap of the same length as the gap length [4].
The set of stations was previously divided into 15 clusters (Figure 1). The number 15 was chosen as the number of clusters, which optimally splits their “cloud”. Let us split the set of station position vectors into a given number of clusters using the k-means clustering method [50]. Let be clusters, let be the vector of the center of mass of the cluster , and let be the number of vectors in the cluster, . Vector if the distance is the minimum among the positions of all cluster centers. The k-means method minimizes the sum of squared distances:
relative to the position of the cluster centers . Let . We used a trial number of clusters in the range . The problem of choosing the best number of clusters was solved using the maximum pseudo-F-statistic criterion [51]
where
The plot in Figure 1b presents the pseudo-F-statistic values as a function of the trial number of clusters. The number 15 on the pseudo-F-statistics graph is the inflection point of the dependence on the trial number of clusters and realizes one of the largest local maxima for the number of clusters from 2 to 50. On the pseudo-F-statistics graph, they represent two local maxima with close values of the number of clusters 6 and 15. Of these two values, 15 was chosen as the largest in order to provide the most detailed breakdown of the set of stations. Figure 1a shows the division of a set of stations into 15 clusters along with Voronoi cells, which indicate that the stations belong to a particular cluster.
Clusters of stations are ordered by increasing latitude of the position of their centers of gravity. Table 1 shows for each cluster (first row) the number of stations in the cluster (second row).
3. Principal Components of Increments in a Moving Time Window
Since the goal is to study the tremor of the earth’s surface, that is, the high-frequency part of the earth’s surface displacements, the analysis was carried out for increments of time series. Switching to increments reduces the dominant influence of low frequencies in the daily GPS time series and ensures stationarity of time series fragments within the 365-day time windows that are used further.
The division of a set of stations into 15 clusters is used for the subsequent application of the principal component method [52]. For each cluster of stations, the first principal component of the time series of increments of vertical displacements of the earth’s surface was calculated in a sliding adaptation time window of 365 days in length.
Let there be a p-dimensional cloud of similar N-dimensional signals . Let us choose the size of the sliding window and center the signals,
The next step is to calculate the sample estimate of the covariance -dimensional matrix in a sliding window:
Let be the eigenvector of this matrix corresponding to the maximum eigenvalue. Let us put
Having generalized Formulas (4)–(7) with understandable changes to the case , let us determine the weighted average in a sliding time window of length using the formula
Thus, Formulas (7) and (8) determine the values of the weighted average increments of vertical time series of displacements of the earth’s surface. The squared values of the eigenvector of the covariance matrix in the sliding time window corresponding to the largest eigenvalue are taken as weights. The sum of these weights is equal to one.
Within each of the 15 clusters, a transition to a weighted average was made using the method described above; the length of the sliding time window was taken as equal to 365 samples, i.e., 1 year. At the same time, in order to eliminate the influence of large outliers, before calculating the weighted average, the so-called winsorization procedure was carried out [53], which consists in eliminating outliers falling beyond the level by cutting off the values of the time series in a sliding time window ( and are sample estimates of the mathematical expectation and standard deviation for the current time window). The procedure is repeated iteratively until the values and stop changing.
Figure 2 shows graphs of the first principal components of increments (in the form of weighted averages) of vertical displacements of the earth’s surface in each of the identified 15 clusters.
4. Empirical Mode Decomposition
Let be the analyzed discrete signal. Empirical mode decomposition (EMD) [8,9] represents the decomposition of the signal into modes of oscillation:
where is the j-th empirical mode, is the remainder, n is the number of empirical modes.
The algorithm for decomposing into a sequence of empirical modes is iterative for each level . Let us denote by the index of iterations, where is the maximum number of iterations for level . The iterations are described by the formula
Here , where and are both the upper and lower envelopes for the signal, which are constructed using spline interpolation (usually a third order spline) over all local maxima and minima of the signal .
Iterations (10) are initialized with step zero for the first level ( ) of the expansion . Next, the upper and lower envelopes are found, and the middle line is calculated and found using Formula (10). For , the upper and lower envelopes are determined, and the middle line is found, and so on, until the last iteration index , after which it is considered that the first empirical mode has been found.
The condition for stopping iterations is usually chosen in the form of the following inequality:
where is some small number, for example 0.01. After the mode is found, the iterative process of determining the empirical mode of the next level is started. This process is initialized by the formula for the initial iteration index :
According to formula (12), the high-frequency part is subtracted from the original signal and a new, lower-frequency signal is considered as a new signal for subsequent decomposition. The construction of empirical oscillation modes continues until the number of local extrema becomes too small for envelopes to be constructed from them. As the number of the empirical mode level increases, the signals become increasingly low-frequency and tend towards an unchanging form. The sequence is constructed in such a way that its sum gives an approximation to the original signal , which can be represented in formula (9) [8,9]. Empirical modes are orthogonal to each other, thus constituting a certain empirical basis for the decomposition of the original signal.
In the practical implementation of the method, technical difficulties arise due to edge effects, since the continuation of the envelopes beyond the first and last points of local extrema is ambiguous. To overcome this difficulty, there are several approaches, in particular mirror continuation [8,13] of the analyzed sample back and forth for a sufficiently long period of time. It was this approach that was used in this work.
5. Ensemble Empirical Mode Decomposition
One of the key disadvantages of the EMD method is the problem of mode mixing, which occurs when one empirical mode includes signals of different scales or when signals of the same scale are distributed over different empirical modes. For example, if “intermittency” is observed in the signal, that is, against the background of a smooth signal, short-term sections of higher frequency behavior appear, then with EMD decomposition behavior modes with different frequencies are mixed, since relatively rare points of local extrema of smooth behavior are interspersed with much more frequent points of local extrema of the high-frequency component.
To combat this effect, ref. [9] proposed the ensemble empirical mode decomposition (EEMD) method. This is a regularization of the EMD method in which white noise of finite amplitude is added to the original data. This allows the true empirical modes to be determined as the average over an ensemble of trials, each of which is the sum of signal and white noise.
The EEMD algorithm includes the following steps:
- Add a white noise implementation to the original data.
- Decomposition of data with the addition of white noise into empirical modes.
- Repeat steps 1 and 2 quite a large number of times with different implementations of white noise.
- Obtain the ensemble average for the corresponding empirical modes.
Thus, numerous “artificial” observations are simulated:
where is the i-th realization of white noise.
The true component, according to the EEMD definition, for a sequence of all levels of empirical modes is calculated as the average value of the expansions of the noisy modes (13). It is important to note that EEMD largely eliminates this mixing problem [9]. Adding independent white noise to the sample has a regularizing effect, since it simplifies the construction of envelopes (after adding a small amount of white noise, many local extrema are immediately created). The operation of averaging over a sufficiently large number of independent implementations of white noise makes it possible to eliminate the influence of the noise component and to isolate the true internal modes of oscillations.
For each of the resulting 15 time series, EEMD waveforms of principal components were calculated. EEMD waveforms are obtained by averaging 1000 decompositions of the original signals, to which are added independent Gaussian white noises with a standard deviation of 0.1 from the standard deviation of the weighted average from each cluster. Figure 3 shows EEMD waveform plots for the first 6 expansion levels for three of the 15 clusters.
6. Hilbert Transform
The Hilbert transform of the signal is determined by the formula [54]:
where is the convolution of two functions. If and are the Fourier transforms of convolutional functions , then, as is known, the Fourier transform of convolution is equal to the product of the Fourier transforms of convolutional functions. Fourier transform from equals:
Thus, if there is a Fourier transform of , then
If you present , then
In practice, it is more convenient to calculate the Hilbert transform using the concepts of an analytical signal:
where are the amplitudes of the signal envelope, and is the instantaneous phase. The derivative is called instantaneous frequency. The Fourier transform of the analytical signal or:
after which the Hilbert transform is equal to the imaginary part of the result of the inverse Fourier transform of
For each of the resulting 15 time series, EEMD waveforms of principal components were calculated. EEMD waveforms are obtained by averaging 1000 decompositions of the original signals, to which are added independent Gaussian white noises with a standard deviation of 0.1 from the standard deviation of the weighted average from each cluster. Figure 4 shows EEMD waveform plots for the first 6 expansion levels for three of the 15 clusters.
For a discrete-time signal , this transformation can be calculated using the discrete Fourier transform:
after which the second part of the Fourier coefficients (corresponding to negative frequencies) should be reset to zero: while the 1st part should be doubled: . The Hilbert transform is then calculated as the imaginary part of the inverse discrete Fourier transform:
Thus, after determining the instantaneous amplitudes and frequencies of the EEMD, the Hilbert–Huang decomposition can be represented as follows:
7. Influence Matrix
To solve the problem of estimating the connection between two sequences of random events, a parametric intensity model is used. In [55,56,57] this method was used to test the hypotheses that local extrema of the average values of certain properties of seismic noise and magnetic field precede the instants of strong earthquakes.
Let represent the moments in time of 2 streams of events.
In our case it is:
- (1)a sequence of moments in time corresponding to the largest local maxima of the amplitudes of the envelopes at certain levels of the EEMD Huang decomposition
- (2)a sequence of times of seismic events with a magnitude not less than a given value.
Let us present their intensities in the form:
where are parameters, and is the influence function of flow events with number :
According to formula (25), the weight of an event with number becomes non-zero for times and decays with a characteristic time . The parameter determines the degree of influence of the sequence on the sequence . The parameter determines the degree of self-excitation to which the flow influences itself, and the parameter reflects the purely random (Poisson) intensity component. Let us fix the parameter and consider the problem of estimating the parameters .
The log-likelihood function for a non-stationary Poisson process within the time interval equals [58]:
We need to find parameters from maximum of functions (26). It is easy to obtain the following expression:
The parameters are non-negative. It means that each term on the left side of (27) equals to zero at point of maximum of function (26)—either due to the necessary conditions for the extremum (if the parameters are positive), or, if the maximum is reached at the boundary, then the parameters themselves are equal to zero. Therefore, at the maximum point of the likelihood function the equality holds:
Let us substitute the expression from (28) into (27) and divide by . Then we get another form of formula (28):
where
average value of the influence function. Substituting from (29) into (26), we obtain the following maximum problem:
where , under restrictions:
It could be shown that function (31) is convex with a negative definite Hessian. Therefore, problem (31) and (32) has a unique solution. The problem (31) and (32) is solved numerically for a given relaxation parameter . After this step we can define the influence matrix with elements using the formulas:
The value is the share of the average intensity of the process with number , which is purely random, part is caused by the influence of self-excitation , and is due to external influence . From Formula (29) the normalization condition follows:
As a result, the influence matrix can be determined:
The first column of matrix (35) is composed of Poisson shares of average intensities. The diagonal elements of the right submatrix of size 2 × 2 consist of self-exciting elements of mean intensity, while the off-diagonal elements correspond to mutual excitation. The sums of the component rows of the influence matrix (34) equal 1. The influence matrices are estimated in a certain moving time window of length with an offset and with a given value of the relaxation parameter .
8. Estimation of Connections between the Times of Local Amplitude Maxima and Seismic Events
The further plan of the article is to use the apparatus of influence matrices to assess the relationship between the times of maximum average amplitudes of the envelopes and the times of sufficiently strong earthquakes. A magnitude threshold of 5.5 was chosen. There were 673 such seismic events in the vicinity of the Japanese islands during the period of time 2009–2023—see Figure 5a. However, the mega-earthquake of 11 March 2011 with a magnitude of 9 gave rise to a surge in aftershock activity, as a result of which, if we consider the time interval 2012–2023, when the intensity of aftershocks had already decreased, the number of earthquakes with a magnitude of at least 5.5 will decrease by almost 2 times to 349—see Figure 5b. It should be noted that accurately estimating the time of the end of the Tohoku earthquake aftershocks is a difficult task [59] and in this case we used a rough estimate based on the visual perception of the intensity of seismic events.
The working hypothesis is that for certain levels of EEMD decomposition, the times of the largest local maxima of the average amplitudes of the envelopes precedes the times of earthquakes. For a correct comparison of two streams of events, it is necessary that their average intensity be approximately equal. This means that the number of the largest local maxima of the amplitudes of the envelopes during the time period under study should be equal to the number of earthquakes. From these considerations, it becomes clear that for a correct analysis of the connections between the time instants of local maximum amplitudes of envelopes and seismic events, the time interval of aftershock activity must be excluded. Therefore, further analysis is carried out for the time period 2012–2023 lasting 12 years.
Figure 6 shows the distribution of epicenters of earthquakes with a magnitude of at least 5.5.
It should be taken into account that as the number of the decomposition level increases, both the waveforms of the levels themselves and the amplitudes of their envelopes become increasingly low-frequency. As a result, it is possible to select the 349 largest local maxima of average amplitudes in the interval 2012–2023 only for a certain number of lower expansion levels. For the time interval 2012–2023, only the first two levels are suitable for selecting 349 local maxima of amplitudes, since the number of local extrema already at the third level is 242, that is, less than 349. From the first two levels, it was decided to choose the second as the lower frequency, and for which the results of mutual influence assessments are more expressive.
In Figure 7, the red dots represent the selected 349 largest local maxima of the average amplitude of the envelopes at the second level of decomposition.
Let us call the “direct” influence of the moments of time of earthquakes on the occurrence of local maxima of the average amplitudes of the envelopes, and the “reverse” —correspondingly, the advance of the moments of time of local maxima of amplitudes relative to the times of earthquakes. Figure 8 shows graphs of changes in the components of the matrix of “direct” and “reverse” influence for level 2 when assessed in a sliding window of 2 years.
Of these graphs, the pair (a1, a2) is of greatest importance: a1 represents the change in the components of the direct influence of seismic events on the positions of local amplitude maxima, while a2 represents the inverse influence of the times of local amplitude maxima on seismic events. From a comparison of these two graphs, it is clear that the reverse influence significantly exceeds the direct influence; that is, there is a delay effect of seismic events relative to the maximum amplitudes. In other words, there is a predictive effect. Graphs (b1, b2) represent changes in the self-exciting component of average intensities, while graphs (c1, c2) represent changes in the purely random (Poisson) component. Finally, the pair of plots (d1, d2) represents the change in the number of jointly analyzed time points in each time window. Let us recall once again that the sum of the components (a1, b1, c1) and (a2, b2, c2) is equal to 1 for any position of the time window.
Figure 8 presents the results of estimates of the mutual influence of two sequences of events only for a time window of 2 years. In order to increase the representativeness of this result, we will carry out similar estimates for a sufficiently large set of time lengths varying within specified limits. In this case, for each value of the length of the time window, we will identify local maxima of the components of the influence matrix, which are responsible for the mutual influence of sequences of events when the time windows are shifted. Let us describe a method for constructing a set of maximum components of mutual influence matrices in the form of numbered points.
The minimum and maximum lengths of time windows and —the number of lengths of time windows in this interval are selected. Thus, the lengths of the time windows took on the values , , . In our calculations, we took as equal to 1 year, and —3 years, .Each time window of length was shifted from left to right along the time axis with some offset . Let us denote by , the sequence of moments in time of the positions of the right windows with length . The number of time windows in length is determined by their time offset . We used a time window offset of 0.01 year.For each position of a time window of length , the elements of the influence matrix (35) are estimated for a given relaxation time of the model (26–27), corresponding to the mutual influence of the two processes being analyzed. We took a value equal to 0.1 year. For definiteness, we will consider one influence, for example, of the first process on the second. As a result of such estimates, we obtain their values in the form , where is the corresponding element of the influence matrix for a position with a time window number of length .In the sequence , we select elements corresponding to local maxima of values , that is, from the condition . Let us present each element as a vertical segment of length located at a time point . The combination of such vertical graphic elements for all , visualizes the “strength” of the mutual influence of processes on each other.
So, the full set of free parameters of the method: , , , , . The result of such estimates is presented in Figure 9.
The results presented in Figure 9 confirm the conclusions made earlier based on the graphs in Figure 8: the “reverse” influence of the time instants of local maxima of envelope amplitudes at the second level on the time instants of earthquakes is significantly greater (Figure 9b) than the “direct” influence of earthquakes on the occurrence of local maxima in the amplitudes of the envelopes (Figure 9a).
9. Conclusions
Traditional methods of analyzing data on crustal movements obtained using space geodesy are focused on identifying systematic low-frequency components that can be interpreted as manifestations of slow tectonic movements. The high-frequency component of these time series, which can be called the “tremor” of the earth’s surface, is most often interpreted as a manifestation of noise arising from atmospheric and ionospheric fluctuations. Our point is that, despite the presence of this process noise, it is in the high-frequency component of GPS data that there is hidden prognostic information. In this article, the joint use of cluster analysis, principal component analysis, Hilbert–Huang decomposition and evaluation of parametric models of the mutual influence of sequences of events allowed us to obtain a result confirming the presence of predictive information in high-frequency tremor of the earth’s surface.
The authors used software which was written by them using programming languages Fortran and Python.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Lyubushin A. Identification of Areas of Anomalous Tremor of the Earth’s Surface on the Japanese Islands According to GPS Data Appl. Sci.202212729710.3390/app 12147297 · doi ↗
- 2Lyubushin A. Singular Points of the Tremor of the Earth’s Surface Appl. Sci.2023131006010.3390/app 131810060 · doi ↗
- 3Lyubushin A. Entropy of GPS-measured Earth tremor Revolutionizing Earth Observation—New Technologies and Insights Abdalla R.M. Intech Open Rijeka, Croatia 202410.5772/intechopen.1004399 · doi ↗
- 4Lyubushin A. Global coherence of GPS-measured high-frequency surface tremor motions GPS Solut.20182211610.1007/s 10291-018-0781-3 · doi ↗
- 5Lyubushin A. Field of coherence of GPS-measured earth tremors GPS Solut.20192312010.1007/s 10291-019-0909-0 · doi ↗
- 6Filatov D.M. Lyubushin A.A. Fractal analysis of GPS time series for early detection of disastrous seismic events Phys. A Stat. Mech. Its Appl.201746971873010.1016/j.physa.2016.11.046 · doi ↗
- 7Filatov D.M. Lyubushin A.A. Precursory Analysis of GPS Time Series for Seismic Hazard Assessment Pure Appl. Geophys.201917750953010.1007/s 00024-018-2079-3 · doi ↗
- 8Huang N.E. Shen Z. Long S.R. Wu V.C. Shih H.H. Zheng Q. Yen N.C. Tung C.C. Liv H.H. The empirical mode decomposition and the Hilbert spectrum for nonlinear and non-stationary time series analysis Proc. R. Soc. Lond. Ser. A 199845490399510.1098/rspa.1998.0193 · doi ↗