The Personalized Inherited Signature Predisposing to Non-Small-Cell Lung Cancer in Non-Smokers
Viola Bianca Serio, Diletta Rosati, Debora Maffeo, Angela Rina, Marco Ghisalberti, Cristiana Bellan, Ottavia Spiga, Francesca Mari, Maria Palmieri, Elisa Frullanti

TL;DR
This study identifies unique inherited genetic mutations in non-smokers with lung cancer, suggesting personalized treatment strategies.
Contribution
The study introduces a novel approach to uncovering a personalized, inherited genetic signature in non-smoker lung cancer patients.
Findings
Each patient has a unique combination of six private mutations in tumor-predisposing genes.
RNA sequencing confirmed the pathogenic role of identified variants through gene expression changes.
The findings suggest a 'private genetic epidemiology' model for non-small-cell lung cancer in non-smokers.
Abstract
Building on the idea of a germline oligogenic origin of lung cancer, we performed WES of DNA from patients’ peripheral blood and their unaffected sibs. Filtering for rare variants and potentially damaging effects, we identified 40 deleterious variants mapping in genes previously associated with cancer exclusively identified in patients. Transcriptome profiling on both tumor and normal lung tissues revealed that, among the selected mutated genes, 16 variants mapping in 16 genes were either down- or upregulated in cancer specimens. Among the downregulated genes, 9 variants in 9 genes carried the mutated allele suggesting a loss of heterozygosity. Notably, the group of mutated genes was unique for each patient, pinpointing to a “private” oligogenic germline signature. In the era of precision medicine, this report emphasizes the importance of an “omic” approach to uncover an oligogenic…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
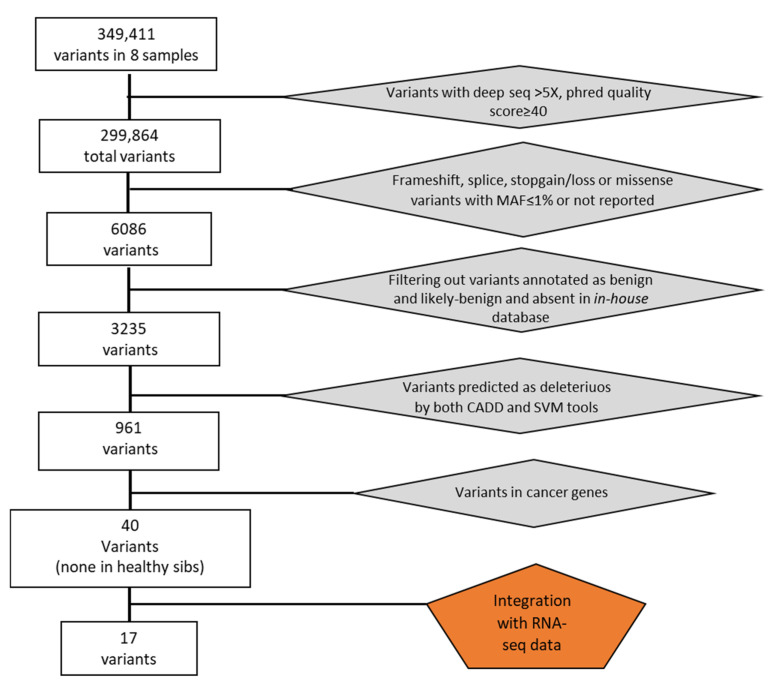 Figure 1
Figure 1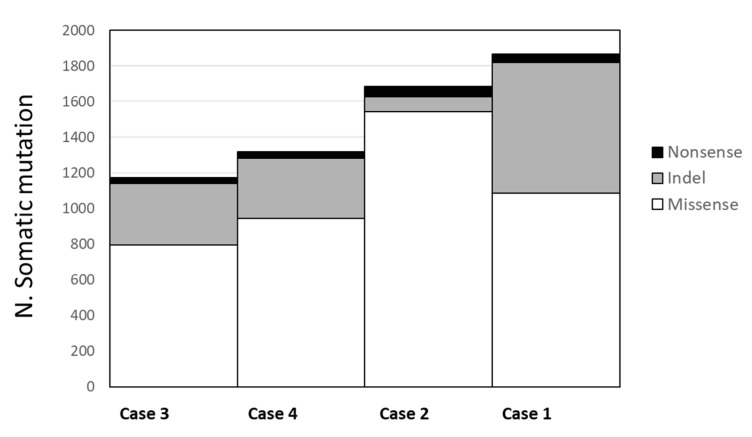 Figure 2
Figure 2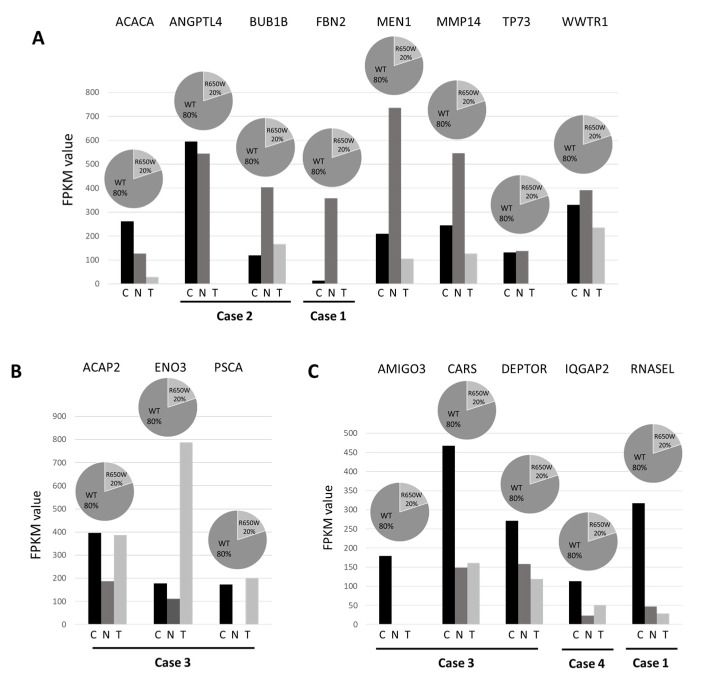 Figure 3
Figure 3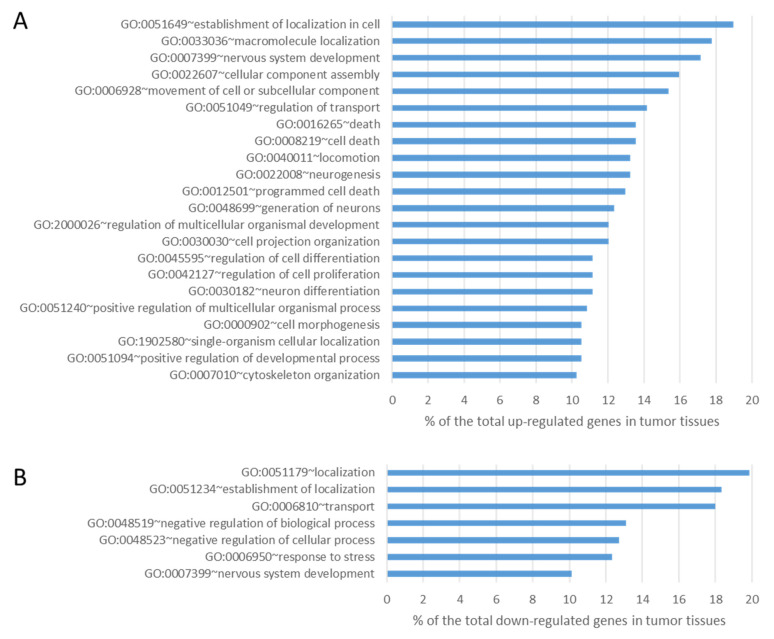 Figure 4
Figure 4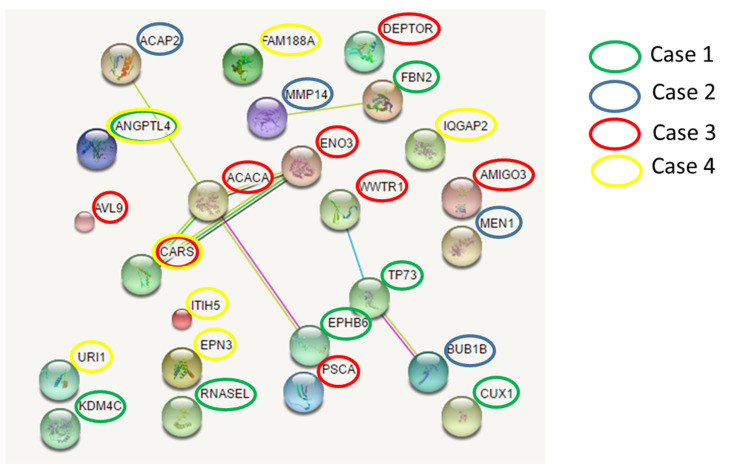 Figure 5
Figure 5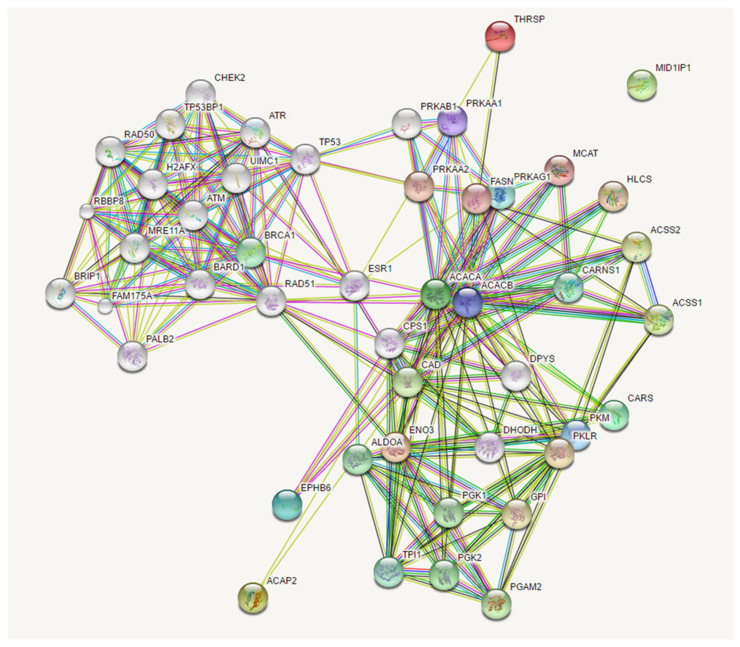 Figure 6
Figure 6- —NextGenerationEU of PNRR “Piano Nazionale di Ripresa e Resilienza” Missione 4 Componente 2–M4C2a–Project THE–Tuscany Health Ecosystem–SPOKE 6
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsRNA modifications and cancer · Cancer-related molecular mechanisms research · Lung Cancer Treatments and Mutations
1. Introduction
Lung cancer (LC) is an important public health problem and a major cause of cancer death worldwide [1]. Despite the strong relationship to tobacco smoking, less than 1 out of 5 heavy smokers develop lung cancer [2], whereas 25% of patients with lung cancer never smoked [3], suggesting a role for genetic factors in the individual susceptibility to lung cancer. Thus far, no specific environmental or genetic risk factors have been detected in these individuals.
Previous genome-wide association studies (GWASs) have identified up to 45 susceptibility loci for lung cancer in population-based series, mainly including smokers [4,5,6,7,8,9,10,11,12,13,14,15]. On the other hand, several studies found the rare germline T790M mutation in EGFR correlated with the familial clustering of lung cancer [16,17,18,19,20,21,22,23]. The EGFR is a major cancer-predisposition gene with an estimated 31% risk of lung cancer development in non-smoking carriers [19]. However, the EGFR T790M mutation is weakly oncogenic and became significantly enhanced when associated with a second activating mutation [18], more frequently with the female sex and non-smoking status. Nevertheless, today, there is a need to better understand the genetic factors associated with lung cancer in never-smokers’ patients in non-predisposed families.
In this frame, using the whole-exome sequencing approach, in a previous study analyzing discordant sib-pairs, we identified a combination of germline disruptive mutations in known cancer susceptibility genes in never-smokers with lung adenocarcinoma (ADCA) of early onset, that were not present in their healthy control sibs [24]. These results demonstrated that each affected subject had an oligogenic combination of disrupted cancer-predisposing genes. This evidence gives experimental support to a model of “private genetic epidemiology” for lung cancer susceptibility that has previously only been hypothesized. The oligogenic nature of the model may therefore explain the non-heritability of the condition.
In the present study, we used a combination of genetic technical tools (whole-exome sequencing analysis and RNA sequencing) coupled with a pedigree model in discordant pairs of non-smokers with lung cancer of early onset. Healthy sibs were used as controls. We identified in affected subjects a unique combination of private “predisposing signatures” that further confirms and exploits the oligogenic model of the disease.
2. Materials and Methods
2.1. Study Design and Samples
This study analyzed four non-smoker lung cancer patients with lung cancer (cases), who underwent lung lobectomy in the Thoracic Surgery Unit at the Azienda Ospedaliero-Universitaria Senese (AOUS, Siena, Italy), in comparison with their healthy sibs (controls). The genetic comparison of discordant sibs, that share 50% of the genome, facilitates the identification of variants associated with lung cancer susceptibility. For each patient, formalin-fixed paraffin-embedded (FFPE) samples of tumoral and non-tumoral lung tissues were obtained from the Pathology Unit of the recruiting hospital and analyzed through whole-exome sequencing and RNA sequencing (RNA-seq).
Each patient and sib signed the informed consent declaration for the use of their biological samples and clinical data for research purposes. The study protocol was approved by the Institutional Ethical Committees. Information on histological diagnoses (by the Pathology Unit) was retrieved from the clinical records.
2.2. DNA and RNA Extraction
Genomic DNA of cases and controls was isolated from EDTA peripheral blood using QIAamp DNA Blood Kit (Qiagen^®^, Hilden, Germany) according to the manufacturer’s protocol. DNA was extracted from FFPE lung tumoral and non-tumoral tissue samples using MagCore^®^ Genomic DNA FFPE One-Step Kit for MagCore^®^ System (Diatech Pharmacogenetics srl, Jesi, Ancona, Italy). RNA was extracted from FFPE lung tumoral and non-tumoral tissue samples using High Pure FFPE-Tissue RNA Isolation Kit (Roche, Basel, Switzerland) following the manufacturer’s instructions. RNA samples (1 µg) were processed to remove ribosomal RNA (rRNA) using Ribo-Zero rRNA Removal Kit for Human samples (Illumina, Grand Island, NE, USA) following the manufacturer’s instructions. RNA integrity was verified using the Agilent Eukaryote Total RNA Nano Kit (Agilent Technologies, Palo Alto, CA, USA) on Agilent2100 Bioanalyzer (Agilent Technologies). Both DNA and RNA were quantified by spectrophotometry (ND-2000c; NanoDrop Products, Wilmington, DE, USA) and Qubit^®^ Fluorometer with Qubit^®^ dsDNA HS Assay and Qubit^®^ RNA HS Assay Kits (Life Technologies, Carlsbad, CA, USA), respectively.
2.3. Whole-Exome Sequencing and Data Analysis
Whole-exome sequencing was performed using the Illumina Nextseq 550 on genomic DNA samples (500 ng) of cases and controls and tumor tissues as previously described [25]. After variant annotation against external datasets, including 1000 genomes [(http://www.1000genomes.org/), accessed on 19 February 2024] and dbSNP, in order to identify susceptibility variants, we selected for rare variants (minor allele frequency—MAF ≤ 0.01) with a potentially damaging effect and with a functional link to cancer development. Additional filtering procedures were thus implemented for: (i) retrieving exonic rare variants with a potential detrimental impact on protein function, i.e., truncating frameshift insertion and deletion and nonsense variants predicted as deleterious that were present in affected but not in unaffected sibs and vice versa; and (ii) identifying somatic mutations present in tumor tissues.
2.4. RNA Sequencing and Data Analysis
RNA sequencing was performed using Illumina HiSeq2500 platform (Illumina), in a 2 × 100 bp paired-end (PE) configuration in High Output mode (V4 chemistry), with a total of at least 250 million reads per lane. After quality check, RNA (50 ng) was used to prepare sample libraries. Sequencing library construction included these steps: library construction using Illumina TruSeq RNA Sample Pre Kit (Illumina), library purification using Beckman AMPure XP beads (Beckman Coulter s.r.l., Milan, Italy), insert fragments test using Agilent High Sensitivity DNA Kit on Agilent 2100 Bioanalyzer (Agilent Technologies), quantitative analysis of library (ABI 7500 real time PCR instrument; KAPA SYBR green fast universal 2 9 qPCR master mix. GRN), and cBOT automatic cluster (TruSeq PE Cluster Kit v3-cBotHS). Post-library quality controls were performed using the Agilent RNA 6000 Nano kit (Agilent Technologies) on Agilent2100 Bioanalyzer (Agilent Technologies) and Qubit^®^ Fluorometer (Life Technologies). Libraries were then loaded on HiSeq2500 sequencing platform (Illumina) and sequenced using 2 × 100 bp pair-end High Output Mode (V4 chemistry) per lane. The reads generated on the HiSeq2500 were provided under FASTQ format.
Sequence reads in FASTQ format were processing using the Fastqc software [(http://www.bioinformatics.babraham.ac.uk/projects/fastqc/), accessed on 4 March 2024, Version 0.12.0] for data quality check and removing excess adaptors to obtain high-quality and clean reads. The high-quality reads were aligned to the GRCh38/hg38 reference human genome [(ftp://jgi-psf.org/pub/compgen/phytozome/v9.0/Ptrichocarpa/assembly/Ptrichocarpa_210.fa.gz), accessed on 4 March 2024] using the TopHat software (version 2.1.1) [26]. Transcript assembling and expression quantification were carried out using Cufflinks (version 2) [27]. Gene expression was expressed as fragments per kilo-base transcript per million mapped reads (FPKM) value [28]. This normalized value was used for visualization on a genome browser [(http://genome.ucsc.edu/), accessed on 20 March 2024] [29], as well as to compare read coverage between and throughout different genes. Statistical analysis was performed to compute the mean FPKM level with the associated P-value for lung normal tissues together with the mean FPKM level with the associated P-value for lung cancer tissues. Cuffdiff tool from Cufflinks was used to identify differentially expressed genes [30]. Potential gene fusion events were detected by TopHat-fusion [31] with spanning reads ≥10 in cancer and normal tissue. The cancer-specific fusion genes were obtained by excluding the fusion genes that were also identified in distant normal tissue. Gene Ontology (GO) and pathways analyses were performed using the Database for Annotation, Visualization, and Integrated Discovery functional annotation tool [(DAVID Bioinformatics Resources v2024q1, https://david.ncifcrf.gov), accessed on 16 April 2024].
3. Results
3.1. Exome Analysis of Constitutive DNA
We carried out the whole-exome sequencing of DNA from blood tissue in four discordant sib pairs (Table 1). Patients had early-onset lung cancer in the absence of smoking history, and we used as controls their unaffected sibling. Exome sequencing generated a mean of 28,960,442 reads per sample with a mean read length of 160 bp.
Overall, we identified a total of 349,411 genetic variants in eight samples. After removing variants with low coverage and filtering for exonic mutations with MAF ≤ 0.01 or not reported, we obtained 6086 total variants (Figure 1). We then filtered by excluding variants with clinical significance as “benign” or “likely benign” and present in an in-house database of variants identifying 3235 variants. Among them, we selected deleterious variants applied to the Combined Annotation Dependent Depletion (CADD) and the MetaSVM (Support Vector Machine) bioinformatics tools. In this way, we obtained 961 potential deleterious variants of which 370 were non-synonymous and 591 were truncating variants (insertions and deletions (indels) causing exonic frameshifts, and nonsense mutations leading to truncated proteins).
Out of these, 40 variants mapped in genes that have been found previously associated with cancer of lung or other tissues and, interestingly, all of these were present exclusively in the affected sib (Table 2). The validation of these variants was carried out using a custom next-generation sequencing (NGS) panel for the Ion PGM sequencer (Life Technologies) and led to the confirmation of 40 variants probably responsible for lung cancer susceptibility in our cases. All the 40 sequence variants identified were in a heterozygous state. No common variants to all four cases were found. However, three variants were common to two out of four patients (ANGPLT4, CARS, and ESRRA). The two variants in Angiopoietin-Like 4 (ANGPLT4) and Estrogen-Related Receptor Alpha (ESRRA) genes were common to case 1 and case 4, while the same variant in the Cysteinyl-TRNA Synthetase (CARS) gene was found in case 3 and case 4. Each of the 40 variants were also present in the relative lung tumor tissue in the heterozygous state.
3.2. Somatic Mutations in Tumor Lung Tissues
In the four tumor lung samples, we identified an average of 2.568 somatic mutations per tumor (ranging from 2.169 to 3.348). When we limited the mutations in the coding regions, the average number of mutations in each tumor was 1.510 (range 1.172–1.865), among which an average of 1092 (range 797–1542) were missense, 374 (range 85–735) were frameshift ins/del, and 43 (range 32–56) were nonsense mutations (Figure 2). The number of mutations was not associated with clinical and pathological variables (stage and age at diagnosis). No recurrent mutations, such as mutations in EGFR, KRAS, or AKT genes, were present in our tumor samples.
3.3. RNA-Seq Analysis of Tumors and Non-Involved Lung Tissues
To detect differences in the expression level, splicing pattern, and/or polyadenylation sites that could both help the understanding of the functional role of germline variants in the development of lung cancer and shed light on the pathogenic mechanisms, we performed an RNA sequencing (RNA-seq) analysis of RNA extracted from both the FFPE tumor and non-involved lung tissues of the four lung cancer patients. RNA-seq generated a mean of 73,865,049 reads per sample and 91.07% of bases sequenced above the Q30 quality score (Supplementary Table S1).
To assess the potential functional role of the 40 germline variants identified by whole-exome sequencing (WES) and predicted as deleterious by bioinformatics tools, we combined the results from the WES experiments with the respective expression profile from RNA-seq. In 16 variants mapping in 16 genes, the RNA sequencing data reinforced the pathogenic role of the identified variants showing three different effects (Figure 3). Firstly, eight genes [Acetyl-CoA carboxylase alpha (ACACA), Angiopoietin like 4 (ANGPTL4), BUB1 mitotic checkpoint serine/threonine kinase B (BUB1B), Fibrillin 2 (FBN2), Menin 1 (MEN1), Matrix metallopeptidase 14 (MMP14), Tumor protein 73 (TP73), and WW domain-containing transcription regulator protein 1 (WWTR1)] showed a downregulation in lung cancer tissue, indicating a possible “second hit” in tumor suppressor genes responsible for gene inactivation (Figure 3A). Secondly, three genes [ArfGAP With Coiled-Coil, Ankyrin Repeat And PH Domains 2 (ACAP2), Enolase3 (ENO3), and prostate stem cell antigen (PSCA)] showed an upregulation in lung cancer tissue, suggesting their role as an oncogene (Figure 3B). Lastly, five remaining genes [Adhesion Molecule With Ig Like Domain 3 (AMIGO3), Cysteinyl-tRNA synthetase (CARS), DEP Domain Containing MTOR Interacting Protein (DEPTOR), IQ Motif Containing GTPase Activating Protein 2 (IQGAP2), and Ribonuclease L (RNASEL)] were downregulated in both normal and cancer tissue, indicating a possible transcript instability (Figure 3C). In addition, a nonsense variant that was predicted as deleterious in the putative tumor suppressor URI1 Prefoldin Like Chaperone (URI1) gene, although it was not associated with changes in mRNA levels, was also retained in the panel of candidate genes.
The data obtained from tumor tissues were then compared with those from normal tissues in order to identify differences in the expression level using well-established and accepted analysis tools such as Cufflink-Cuffdiff [30]. Cuffdiff differential expression analysis identified 315 genes significantly downregulated (fold ≤ −2 change, p-value ≤ 0.05) and 347 genes significantly upregulated (fold change ≥ 2, p-value ≤ 0.05) in lung tumor tissues compared to normal tissues. We then interrogated these data both for the enrichment of genes involved in peculiar cell functions and for the involvement of specific pathways. A GO analysis of upregulated differentially expressed genes revealed a statistically significant enrichment for genes mainly involved in the cellular process (p-value = 1.29 × 10^−4^), cellular component organization (p-value = 1.78 × 10^−4^), and developmental process (p-value = 0.002) (Figure 4A). The GO terms of downregulated differentially expressed genes were mainly related to the acute inflammatory response (p-value = 0.015) and cell adhesion (p-value = 0.028) (Figure 4B).
Pathways analysis individually performed on the differentially expressed genes between each normal–tumor tissue pair showed the ECM–receptor interaction pathway as the common involved pathway in all four lung tumor tissues (Table 3).
3.4. Analysis of Tumor Loss of Heterozygosity
We performed the whole-exome sequencing of DNA from the four tumor tissues in order to identify potential driver genes. An analysis of the exome sequencing in DNA from blood compared to the exome sequencing in DNA from tumor tissues allowed us to identify the presence of nine variants in nine genes that were in a heterozygous state in DNA from the patient’s blood and in a homozygous state in tumor tissue (Figure 5), thus representing a possible second hit responsible for gene inactivation in this tissue.
3.5. Protein–Protein Interaction
To explore possible pathogenic mechanisms in lung cancer, we further investigated the existence of possible interactions among the involved cancer genes that had germline mutations. We found three networks involving mutated genes belonging to different cases (Figure 5). The main network connects the EPHB6 gene (mutated in case 1) with the ACACA and ENO3 genes (mutated in case 3), CARS gene (mutated in case 3 and 4), and ACAP2 gene (mutated in case 2). Overall, each patient had deleterious germline variants in genes belonging to this network.
Expanding the analysis of this network with a threshold of 20 interactors, we identified associations between the mutated genes in our patients with many genes involved in cancer development. In particular, the network clustered in two relevant groups, the former involving PRKA interactors, which comprised our mutated genes, and the latter involving RAD51 interactors (Figure 6).
4. Discussion
In this study, we used an integrative approach of next-generation sequencing technologies to dissect the genetic susceptibility to lung cancer in non-smoker patients for the identification of a genetic profile that could be predictive of the individual risk for lung cancer. The whole-exome sequencing technique, coupled with a model of cases and controls deriving from the same kindred, demonstrated that each patient has a combination of an average of 10 (range 7–14) deleterious “private” germline variants in tumor-predisposing genes. These mutations were absent in unaffected sibs.
In addition to performing a genome-wide analysis in the search of oligogenic signatures that could differentiate affected from non-affected siblings, we also analyzed, in the same patients, the RNA-seq data in tumor specimens, comparing tumoral vs non-tumoral tissue. Using this approach, we confirmed the potential functional effect of most of the identified variants with an average of 6 (range 4–8) variants per patients. In particular, we distinguished three class of alterations: (1) variants associated with the downregulation of the gene in lung tumoral tissue compared to non-tumoral tissue, indicating the presence of a “second hit” in a putative tumor suppressor gene; (2) variants associated with upregulation in tumoral compared with non-tumoral tissue of the gene that could represent a likely oncogene; and (3) variants associated with downregulation in both tumoral and non-tumoral tissue, indicating possible mechanisms for transcript instability.
Concerning oncogenic genes, the comparison of RNA-seq data in the tumoral vs non-tumoral tissue showed the involvement of genes belonging to molecular localization, cell movement, and cellular component assembly pathways among the upregulated genes, while, among the downregulated genes, the mainly involved pathways were cell localization, transport, negative regulation of cellular processes, and response to stress. These results seem to suggest that cancer cells miss proper intracellular molecular localization and are more resistant to stress. Comparing differentially expressed genes in matched tissue pairs, we showed the involvement of the ECM–receptor pathway in all four pairs of siblings. Similar findings have already been reported in prostate cancer [32]. Since the pathways analysis showed the ECM–receptor interaction pathway as the common involved pathway in all four lung tumor tissues, we also found that there is a relationship between this pathway and 7 of the 17 variants associated with an effect at the RNA level. The WWTR1 in its Wwtr1/Yap Hippo pathway is known to play an essential role in the mechanosensing of alterations in cell rigidity and in the extracellular matrix (ECM) [33]. The ANGPTL4 overexpression decreases the mRNA levels of ECM-related genes [34], the Fibrillin 2 (FBN2) is a glycoprotein of the elastin-rich ECM, being a ubiquitous glycoprotein that self-polymerize into filamentous microfibrils and is critical for ECM formation and remodeling [35]. The MMP-14 is the driving force behind the ECM destruction during cancer invasion, and metastasis also influences both intercellular and cell–matrix communication by regulating the activity of several plasma-membrane-anchored and extracellular proteins [36]. Interestingly, RNASEL regulates the matrix metalloproteinases activities remodelling the ECM and plays a critical role in cell migration, invasion, tissue metastasis, and impact tumor progression [37]. The ancestor role of TP73 was associated with the tissue organizer, but, in the developing ovary, p73 regulates a set of genes involved in ECM interactions, and other biological processes required for proper follicle development [38]. Finally, the role of IQGAP2 in receptor signaling has recently emerged, although the functions of the LGR4:IQGAP2 complex remain unidentified. However, the best known and most studied isoform of the known three, IQGAP1, promote the degradation of the ECM by matrix metalloproteinases, thereby coordinating cell invasion [39].
Network analysis concerning the identified cancer susceptibility genes showed three networks that were shared by different patients, suggesting a possible common path for private oligogenic signatures. The main network involving genes mutated in all four patients (ACACA, ACAP2, ENO3, EPHB6, and CARS) connected the candidate mutated genes with the group of RAD51 (RAD51 recombinase) and PRKA interactors. RAD51 encodes for a key recombinase that seems to be essential for homologous recombination and DNA repair [40]. It interacts with a large number of proteins involved in double-strand DNA breaks and in the cell cycle with important implications in tumorigenesis, such as BRCA1 and TP53 (as reviewed in [41]). PRKA encodes for the catalytic subunit of AMP-activated protein kinase (AMPK) that is a cellular energy sensor that maintains energetic homeostasis [42] and has been suggested as a novel target for anticancer therapy since its activation determines a reduction in mRNA translation and protein synthesis [43]. Figure 5 and Figure 6 show the possible network (Figure 5) and “expanded” network (Figure 6) of proposed cooperation among the main mutated genes in the occurrence of “increased susceptibility” to NSCLC. We have previously discussed the putative role of each gene in the occurrence of lung cancer.
Our study has a number of strengths and limitations. One of the main strengths is that we used an integrative next-generation sequencing approach combining the whole-exome sequencing technique (germline and tumor DNA) with transcriptome sequencing (tumor and matched normal tissue). In addition, the original selection strategy of discordant sibs has been used. Among the limitations, variants in noncoding regions, copy number variations, genome rearrangements, and common susceptibility variants have been missed due to the study design. Secondly, the number of samples analyzed is relatively small. However, the private nature of the oligogenic susceptibility reduces the potential contribution of additional discordant sib-pairs.
In any case, the “novelty” that present results strongly suggest is the following. Opposite to what occurs in inherited multitumoral syndromes, such as Familial Adenomatous Polyposis (FAP), where germline mutations of a single gene (i.e., APC gene) determines colon cancer in 100% of affected patients, in the present model, that is likely to occur in most frequent sporadic cancers, variable oligogenic combinations of germline mutations, that change from an individual to another, all together are responsible for the occurrence of a “susceptible” or “resistant” phenotype towards a given cancer.
In this “omics” study, in which various next-generation technologies were used, a lot of data both in quantitative and qualitative terms for each patient were produced, and this is a clear example of how their interpretation is the keystone to uncovering the oligogenic germline signature and achieving personalized precision medicine in lung cancer. Precision medicine in lung cancer is already a reality in the metastatic stage, but studies like this must be implemented to extend this approach to all lung cancer patients at different stages. Indeed, our findings showed that private oligogenic signatures could be part of an individual way to cancer. We suggest that every patient has his/her peculiar signature of germline mutations, governing personal cancer susceptibility. This signature may play a major role in the development and growth of lung cancer, namely, in non-smoker patients, and this may therefore explain the non-heritability of the condition. In fact, lung cancer in non-smokers rarely shows familial aggregation but rather seems sporadic or occurs in phratries. These two possibilities were perfectly explained by our private oligogenic model of inheritance [24]. The proposed model may have important implications in the evaluation of individual risk for lung cancer and may lead to a “germline genetic signature”, which, in the modern era of personalized medicine, could be of benefit to the early detection of cancer.
5. Conclusions
In conclusion, further studies are necessary in order to confirm the present findings in larger studies. In any case, our “focused analysis” in a small number of patients could contribute to a deeper insight into the complexity of the various subtypes of lung cancer and the variable interplay among gene programs involving biological processes, which could seem apparently distinct and/or distant from each other.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Wild C. Weiderpass E. Stewart B.W. World Cancer Report: Cancer Research for Cancer Prevention 2020 International Agency for Research on Cancer Lyon, France 2020
- 2Peto R. Darby S. Deo H. Silcocks P. Whitley E. Doll R. Smoking, smoking cessation, and lung cancer in the UK since 1950: Combination of national statistics with two case-control studies BMJ 200032132332910.1136/bmj.321.7257.32310926586 PMC 27446 · doi ↗ · pubmed ↗
- 3Long E. Patel H. Byun J. Amos C.I. Choi J. Functional studies of lung cancer GWAS beyond association Hum. Mol. Genet.202231 R 22R 3610.1093/hmg/ddac 14035776125 PMC 9585683 · doi ↗ · pubmed ↗
- 4Wang Y. Broderick P. Webb E. Wu X. Vijayakrishnan J. Matakidou A. Qureshi M. Dong Q. Gu X. Chen W.V. Common 5p 15.33 and 6p 21.33 variants influence lung cancer risk Nat. Genet.2008401407140910.1038/ng.27318978787 PMC 2695928 · doi ↗ · pubmed ↗
- 5Mc Kay J.D. Hung R.J. Gaborieau V. Boffetta P. Chabrier A. Byrnes G. Zaridze D. Mukeria A. Szeszenia-Dabrowska N. Lissowska J. Lung cancer susceptibility locus at 5p 15.33Nat. Genet.2008401404140610.1038/ng.25418978790 PMC 2748187 · doi ↗ · pubmed ↗
- 6Landi M.T. Chatterjee N. Yu K. Goldin L.R. Goldstein A.M. Rotunno M. Mirabello L. Jacobs K. Wheeler W. Yeager M. A genome-wide association study of lung cancer identifies a region of chromosome 5p 15 associated with risk for adenocarcinoma Am. J. Hum. Genet.20098567969110.1016/j.ajhg.2009.09.01219836008 PMC 2775843 · doi ↗ · pubmed ↗
- 7Wang Y. Mc Kay J.D. Rafnar T. Wang Z. Timofeeva M.N. Broderick P. Zong X. Laplana M. Wei Y. Han Y. Rare variants of large effect in BRCA 2 and CHEK 2 affect risk of lung cancer Nat. Genet.20144673674110.1038/ng.300224880342 PMC 4074058 · doi ↗ · pubmed ↗
- 8Mc Kay J.D. Hung R.J. Han Y. Zong X. Carreras-Torres R. Christiani D.C. Caporaso N.E. Johansson M. Xiao X. Li Y. Large-scale association analysis identifies new lung cancer susceptibility loci and heterogeneity in genetic susceptibility across histological subtypes Nat. Genet.2017491126113210.1038/ng.389228604730 PMC 5510465 · doi ↗ · pubmed ↗