Characteristics and Cluster Analysis of 18,030 Sepsis Patients Who Were Admitted to Thailand's Largest National Tertiary Referral Center during 2014–2020 to Identify Distinct Subtypes of Sepsis in Thai Population
Phuwanat Sakornsakolpat, Surat Tongyoo, Chairat Permpikul

TL;DR
This study analyzed data from over 18,000 sepsis patients in Thailand to identify 10 distinct subtypes of sepsis using machine learning, revealing differences in risk and clinical features.
Contribution
The study identifies 10 distinct sepsis subtypes in the Thai population using cluster analysis, offering new insights for potential clinical stratification.
Findings
Ten sepsis subtypes were identified, with three classified as low risk and seven as high risk for in-hospital mortality.
Cluster H5 showed multiple organ dysfunction and higher use of life-support therapies like vasopressors and mechanical ventilation.
Cluster H6 was associated with respiratory tract infections and acute respiratory failure with lower SpO2/FiO2 values.
Abstract
This study aimed to investigate the demographic, clinical, and laboratory characteristics of sepsis patients who were admitted to our center during 2014–2020 and to employ cluster analysis, which is a type of machine learning, to identify distinct types of sepsis in Thai population. Demographic, clinical, laboratory, medicine, and source of infection data of patients admitted to medical wards of Siriraj Hospital (Bangkok, Thailand) during 2014–2020 were collected. Sepsis was diagnosed according to the Sepsis-3 criteria. Nineteen demographic, clinical, and laboratory variables were analyzed using hierarchical clustering to identify sepsis subtypes. Of 98,359 admissions, 18,030 (18.3%) had sepsis. Respiratory tract was the most common site of infection. The mean Sequential Organ Failure Assessment (SOFA) score was 4.21 ± 2.24, and the median serum lactate level was 2.7 mmol/L [range:…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
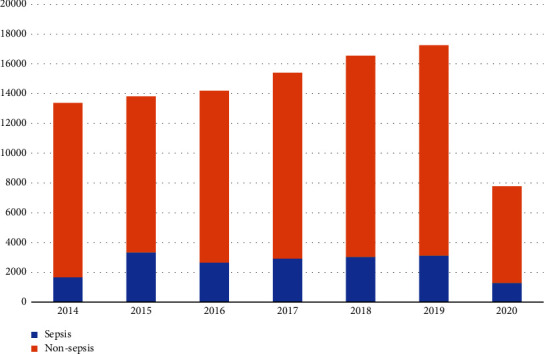 Figure 1
Figure 1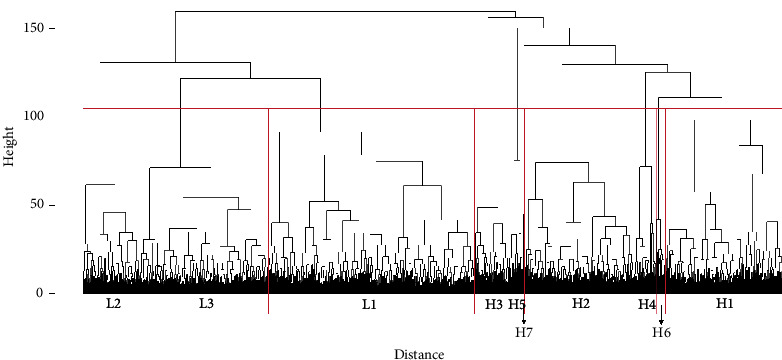 Figure 2
Figure 2Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsSepsis Diagnosis and Treatment · Pneumonia and Respiratory Infections · Statistical Methods in Epidemiology
1. Introduction
Sepsis is a clinical syndrome that is characterized by a dysregulated immune response to infection, which results in organ dysfunction [1]. Despite continuing advances in critical care medicine, the mortality rate among those who develop sepsis remains high. A worldwide survey of hospital mortality among severe sepsis patients revealed a mortality rate ranging from 17% to 26% [2]. At our center, which is Thailand's largest national tertiary referral center, the mortality rate among severe sepsis and septic shock patients was reported to be 37.9% [3]. Apart from the severity of infection, factors that contribute to higher mortality in sepsis patients include the nature of severe generalized inflammation, persistent immunosuppression, the physical and emotional manifestations associated with postsepsis syndrome [4, 5], and the lack of a specific treatment for sepsis. Trials that aimed to ameliorate altered immune response in sepsis were largely unsuccessful. The overriding reason for this failure is that sepsis is a heterogeneous syndrome that is characterized by a number of clinical and pathophysiological features.
Diagnostic tools for sepsis, such as the Systemic Inflammatory Response Syndrome (SIRS) criteria [6] and the Sepsis-2 and Sepsis-3 diagnostic criteria [1], have been developed and implemented; however, in patients with heterogeneous manifestations, these diagnostic tools do not offer specific clues that suggest or indicate the need for additional specific management. Current research interests and efforts have endeavored to classify sepsis based on demographic, clinical, and laboratory characteristics using machine learning, which is an application of artificial intelligence (AI). Grouping methodologies vary from using empirical clinical characters, such as fever [7] and site of infection [8], to the use of an agnostic/generalized concept [9–13]. Moreover, several trials that are investigating the efficacy of specific treatments for patients with different subtypes of sepsis are currently ongoing.
Most of the previous clustering analyses used data from clinical trials conducted in the United States or from the electronic health records of American patients. In addition to differences in data collection, recording, and availability between medical centers in low-, middle-, and high-income countries, differences also exist relative to the nature of sepsis, such as the source of infection, the causative organisms, and the host setting. These differences between advanced and developing countries suggest that there may also be important differences in sepsis subtypes.
Accordingly, the aim of this study was to investigate the demographic, clinical, and laboratory characteristics of sepsis patients who were admitted to our center during 2014–2020 and to employ cluster analysis of those patient characteristics to identify distinct subtypes of sepsis in Thai population.
2. Methods
This retrospective observational study was conducted at the Division of Critical Care of the Department of Medicine, Faculty of Medicine Siriraj Hospital, Mahidol University, Bangkok, Thailand. The protocol for this study was approved by the Siriraj Institutional Review Board (SIRB) on November 4, 2020 (COA no. 850/2563 [IRB4]). Written informed consent to participate was not obtained from included study subjects due to the retrospective, anonymity-preserving nature of this study.
2.1. Study Variables
Patient demographic data, sources of infection, clinical characteristics, and laboratory values were collected from our center's electronic medical record system. To label patients with suspected infection, we retrieved drug administration records from our hospital's electronic medical record system by filtering for intravenous antibiotics available at our center. Concerning laboratory parameters, we collected values available within 24 hours of each patient's admission time. If there were multiple measurements during this initial 24-hour interval, the most abnormal value was recorded. The human body system categories and specific laboratory parameters evaluated in this study are listed in Table 1.
2.2. Determination of Patients with Sepsis
We used the Sepsis-3 diagnostic criteria to define sepsis in this study. The Sepsis-3 criteria comprise two components, including suspicion of infection and evidence of organ failure. For this study, we defined suspicion of infection as the prescription of intravenous antibiotics at least one dose (as documented in drug dispensing records in any day) during the first 24 hours of admission. For organ failure, we used a Sequential Organ Failure Assessment (SOFA) score [14] of greater than 2 as a cutoff value. A SOFA score was determined for each enrolled patient. The components of the SOFA score and how they are measured are shown in Table 2.
2.3. Study Population and Sepsis Patient Selection
To maximize the sensitivity of sepsis diagnosis, we screened all admission data during 2014–2020 from all general medical wards within the Department of Medicine at our center. Admission to a Department of Medicine ward requires a patient age of 16 or older per hospital policy. We then evaluated drug administration records and flagged the cases that received intravenous antibiotics administration for at least one day during hospital admission. This was followed by calculation of the SOFA score using available clinical and laboratory data recorded during the first 24 hours of admission. For missing data, we calculated the SOFA score using only the available variables. No imputation was performed in cases of missing data.
Patients satisfying all of the following criteria were considered to have had sepsis: (1) age 16 years or older; (2) admitted to a general medical ward at Siriraj hospital during 2014–2020; (3) had received at least one dose of intravenous antibiotics; and (4) must have satisfied the Sepsis-3 diagnostic criteria. Patients who were discharged against advice, who left the hospital before being formally discharged from the hospital, or who were referred to other hospitals were excluded. Patients who were missing more than 50% of the data evaluated in this study were also excluded.
2.4. Sample Size Calculation
There is currently no standard method for calculating a sample size for a cluster analysis [16], and testing for statistical significance was not performed due to the exploratory nature of this work. We included all patients hospitalized in a general medical ward at our center (sepsis and nonsepsis) during 2014–2020 in the analysis. There were 98,359 admissions during the 7-year study period, and 18,030 (18.3%) of those were determined to have had sepsis.
2.5. Statistical Analysis
2.5.1. Baseline Characteristics
Patient demographic, clinical, and laboratory data are given as follows: number and percentage (%) for categorical data; mean plus/minus (±) standard deviation for normally distributed continuous data; and median and [range] for non-normally distributed continuous data. No tests between or among groups or clusters were performed.
2.5.2. Data Preparation for Cluster Analysis
To ensure data quality, we performed quality control for each variable by marking records with invalid data as missing. Missing values for cluster analysis were imputed using the multivariate imputation via chained equations (MICE) algorithm in R statistical software version 3.5.0 (the R foundation for statistical computing, Vienna, Austria). To facilitate further cluster analysis, we centered and scaled each data variable. This was achieved by subtracting the mean of each column from each row and dividing each data variable by its standard deviation, using the scale function in R statistical software.
2.5.3. Cluster Analysis
We performed two types of cluster analysis, including K-means clustering and hierarchical clustering. K-means clustering is a centroid-based clustering method [17]. This method determines the similarity between and among individual participants. Then, the distance between the epicenter of the cluster and each individual member is iteratively calculated to maximize the distance between clusters and to minimize the distance between participants in the cluster. We used the elbow and silhouette methods to determine the optimal number of clusters for K-means clustering. Hierarchical clustering computes the distance between two participants (dissimilarity) and then groups participants who had low distance between the two participants (high similarity). This process is iteratively performed, which results in the development of a cluster of cases with similar predominant characteristics. We used Ward's method to measure cluster distance during the aforementioned process, utilizing the hclust function in R statistical software. For hierarchical clustering, we determined the number of clusters by evaluating the cluster dendrogram, where the y-axis represents the height. The number of clusters could be obtained by cutting the dendrogram at a specific height. However, there is no consensus method for determining the optimal number of clusters. We determined the number of clusters by inspecting the characteristics of each cluster and considering their clinical implications for further validation.
It should be noted that we first used K-means clustering for our analysis, but the results of that clustering analysis method did not convince us that it could generate convincing and reliable clusters. It has been shown that different clustering analysis methods can generate different results from the same data structure, which suggests that not all clustering methods and data structures are a favorable match. This may have been the reason that we found the K-means method to not be wholly satisfactory. Alternatively, we tried and adopted the hierarchical clustering method for this study given its demonstrated ability to generate reliable and convincing clusters of sepsis subtypes.
2.5.4. Outcome Assessment
To characterize the outcome for each cluster, we established in-hospital mortality as the primary outcome. We obtained the patient's discharge status to determine if the patient was discharged alive or if the patient had expired during hospital admission. Other outcomes included use of mechanical ventilation, use of renal replacement therapy, and use of vasopressors. We determined vasopressor use by obtaining drug administration data during hospital admission, and we filtered our search to flag only norepinephrine, dopamine, and adrenaline. To identify patients who had received mechanical ventilation and/or renal replacement therapy, we used the hospital billing codes in the International Classification of Diseases-Tenth Revision-Clinical Modification (ICD-10-CM) to obtain these data.
3. Results
3.1. The Characteristics and Prevalence of Sepsis among Hospitalized Patients at Siriraj Hospital
Among the 98,359 admissions to our center during the 7-year study period, 35,996 (36.6%) patients had suspected infection and 18,030 of those satisfied the Sepsis-3 diagnostic criteria. Prevalence of sepsis was 18.3% (18,030/98,359) of all admissions and 50.0% (18,030/35,996) of admissions with suspected infection—all of whom had received intravenous antibiotics for at least one day during their hospital admission. We also investigated the Systemic Inflammatory Response Syndrome (SIRS) criteria as a tool for diagnosing sepsis in this same population. Among 18,030 admissions with sepsis as determined by the Sepsis-3 criteria, only 13,377 admissions had sufficient data to calculate the SIRS score. Of those 13,377 admissions, 6,861 or 51% had an SIRS score of ≥2. After stratification by year of admission, the number of sepsis cases ranged from approximately 2,600 to 3,400 cases per year during 2015–2019, but a lower number of cases was observed in 2014 and 2020 (Figure 1). The drop in both the number of total admissions and the number of sepsis cases during 2020 can most assuredly be attributed to the COVID-19 pandemic. The prevalence of sepsis was steady at 18% during 2016–2019.
3.2. Clinical Characteristics and Laboratory Measurements
Among the 18,030 admissions diagnosed with sepsis using the Sepsis-3 diagnostic criteria, the mean age was 66.2 ± 17.4 years and 54.0% were males. The overall mean Elixhauser Comorbidity Index in this study was 13.0 ± 8.21, which corresponds with the 10% rate of hospital mortality reported in a previous study [18]. The overall mean SOFA score was 4.21 ± 2.24, and the overall mean SIRS score was lower than 2 (Table 3). Vital signs included in the calculation of the SIRS score were taken at admission, not at the initial presentation. This factor could have adversely influenced the sensitivity of the SIRS score for detecting sepsis. The overall median serum lactate level was 2.7 mmol/L [range: 0.4–27.5], and 20% of overall admissions required vasopressor. The in-hospital mortality rate was 19.6%.
3.3. Site of Infection
Respiratory tract infection was the most frequent diagnosis (5,494 patients, 30.5%). Other sites of infection included genitourinary tract infection (3,203 patients, 17.8%), gastrointestinal infection (3,080 patients, 17.1%), skin and soft tissue infection (860 patients, 4.8%), musculoskeletal infection (335 patients, 1.9%), central nervous system infection (219 patients, 1.2%), eye infection (219 patients, 1.2%), infective endocarditis (102 patients, 0.6%), and other infections (3,811 patients, 21.1%).
3.4. Cluster Analysis
By using hierarchical clustering, we created a cluster dendrogram (Figure 2) that shows the distance between individual patients (x-axis) and the height (y-axis) between clusters. To determine the number of clusters, we cut the dendrogram at different heights, resulting in a varying number of clusters ranging from two to more than twenty-four. The hierarchical nature of this clustering method ensures that increasing the number of clusters does not alter the overall structure; the clusters either aggregate or separate from existing groups, maintaining the same hierarchical characteristics.
We determined the optimal number of clusters by examining the dendrogram and found that having ten clusters provided a balance between understanding the underlying data structure and maintaining low heterogeneity within the clusters. To facilitate the interpretation of the cluster analysis concerning the primary outcome (in-hospital mortality), these ten clusters can be aggregated to form two larger clusters by cutting the dendrogram at its highest separation point.
The two clusters obtained at this level can be categorized based on their in-hospital mortality characteristics. One cluster, termed the low-risk group, comprises clusters with a lower mean in-hospital mortality rate, while the other, termed the high-risk group, consists of clusters with a higher mean in-hospital mortality rate.
Three of ten clusters (clusters L1, L2, and L3) were categorized into the low-risk group, whereas the other seven clusters (clusters H1 to H7) were categorized into the high-risk group. Patients with low risk had fewer comorbidities, a lower serum lactate level, and lower in-hospital mortality, while those in the high-risk group had a lower mean arterial pressure and higher in-hospital mortality (Table 4). Comparing between the clusters in the high-risk and low-risk groups, the high-risk clusters had higher rates of mortality that ranged from 27% to 49%. The high-risk clusters also had a higher mean SIRS score than the clusters in the low-risk group.
Each cluster was found to have its own distinct characteristics. Cluster H1 was the most populated cluster among the high-risk clusters. Patients in this cluster had an average comorbidity score higher than that of all other clusters. They also had higher serum creatinine levels, but the rate of renal replacement therapy was average. Cluster H1 also had higher levels of thrombocytopenia and lower serum albumin levels when compared to the other clusters. Cluster H2 was another highly populated cluster. This group comprised mostly older individuals with average levels of comorbidity. Their outcomes, including mortality, were comparable to those observed in the other clusters in the high-risk group. Cluster H3 included younger individuals with an increased incidence of gastrointestinal infection. Even though this was a younger age cluster, these patients had more comorbid diseases than the patients in other high-risk clusters. They also had higher serum bilirubin and alanine transaminase (ALT). Cluster H4 was found to include older age patients with multiple comorbidities. They had a higher prevalence of respiratory tract infection, and they underwent more renal replacement therapy than the other clusters. Patients in cluster H5 were younger, but harbored multiple comorbidities. They had multiple organ failures, which included respiratory failure requiring mechanical ventilation, the use of renal replacement therapy, and vasopressors, and they had a higher SOFA score, serum lactate level, ALT level, and a prolonged prothrombin time. Cluster H6 was older with some comorbidities. A higher percentage of them had respiratory infections and the lowest SpO_2_/FiO_2_ compared to the other clusters. Similar to the other high-risk clusters, a significant proportion of them needed vasopressors and had high mortality. Cluster H7 was the least populated high-risk cluster in our study (n=49), but it had the highest mortality rate. These patients were younger and had less comorbidities compared to the other clusters. The laboratory measurements only showed lower platelet counts and hemoglobin levels. Only small proportion of this cluster used organ support (lower proportion of mechanical ventilation, vasopressors, and renal replacement therapy).
The low-risk clusters were more or less similar with some distinctions. Cluster L1 had male predominance, but Cluster L3 had female predominance. Cluster L2 had higher SOFA scores and serum creatinine levels compared to the other two other low-risk clusters. Their other characteristics were mostly comparable between and among the low-risk clusters.
4. Discussion
A retrospective assessment of 98,359 hospital admissions to our center during 2014–2020 revealed 18,030 admissions that fulfilled the Sepsis-3 diagnostic criteria for sepsis. The prevalence of sepsis was 18.3% of patients admitted to general medicine wards. Of those, 20% required vasopressors, and 20% died in the hospital. Ten clusters of sepsis subtypes were identified using demographic, clinical, and laboratory data that was collected during the first 24 hours of admission. Based on cluster characteristics, each cluster could be classified as either high risk or low risk for in-hospital mortality. Three clusters were determined to be low risk, and the other seven were considered high risk for in-hospital mortality. Each of the 10 identified clusters has its own unique set of characteristics and predominant features. This information and further study will improve our ability to anticipate the course of the disease and will help to facilitate treatment strategies that are more specific to each sepsis subtype.
Previously published works of Seymour et al. and Aldewereld et al. [9, 10] examined K-means clustering and hierarchical clustering in sepsis classification. Seymour et al. used a clustering method called K-means clustering to classify patients with sepsis based on demographic, clinical, and laboratory data. This resulted in four clusters of patients that they named alpha, beta, gamma, and delta, and each cluster had unique characteristics. Alpha cluster patients had relatively normal laboratory measurements without organ dysfunction; beta cluster patients were older with multiple comorbidities and poor renal function; gamma cluster patients had higher fever and elevated inflammatory markers; and delta cluster patients had lower mean arterial pressure and significant liver abnormalities. Alternatively, Aldewereld et al. employed hierarchical clustering in patients with early septic shock who were enrolled in the earlier published 2014 Protocolized Care for Early Septic Shock (ProCESS) trial [10]. From the 1,023 patients who were enrolled in the Aldewereld et al. study, the five following sepsis clusters were identified: (1) the low risk for in-hospital mortality cluster 1 (L1 cluster), which was characterized by a predominance of fluid-refractory shock without multiorgan dysfunction; (2) the L2 cluster, which was characterized by a predominance of fluid-responsive shock; (3) the moderate risk for in-hospital mortality cluster (M cluster), which was characterized by a predominance of respiratory failure; (4) the high risk for in-hospital mortality cluster 1 (H1 cluster), which was characterized by a predominance of multiple organ dysfunction; and (5) the H2 cluster, which was characterized by a predominance of hepatobiliary dysfunction and coagulopathy. Other machine learning techniques that have been used to study sepsis include the self-organizing map [11], support vector machine/random forest [12], and latent Dirichlet allocation [13].
To our knowledge, this is the first study in Thailand to perform a cluster analysis of patients with sepsis. To achieve a high sensitivity for detecting sepsis, we collected the electronic medical records of all patients who were admitted to a general medical ward during the study period. We then screened those records for patients who were prescribed intravenous antibiotics for a least one day during their hospital admission period. The SOFA score was then calculated using clinical and laboratory information. We decided on this strategy because it is superior to case detection using a free text search using the term “sepsis” in the electronic medical records or relying on the ICD-10 code for sepsis. Thus, a total number of patients enrolled in our study are much greater than the number of patients enrolled in previous sepsis studies in Thailand [19, 20].
In our study, the severity of sepsis as measured by in-hospital mortality correlated with the cluster hierarchy. As depicted in Figure 2, clusters that are in proximity to other clusters had the comparable in-hospital mortality. The low-risk and high-risk clusters had in-hospital mortality from 9% to 15% and from 27% to 49%, respectively. This implied that the clinical and laboratory features used in clustering indeed capture the underlying drivers of sepsis severity.
The heterogeneity of sepsis is the strongest presumed reason for the failure of therapeutic trials that aimed to mitigate the disease process. Several studies have set forth to subclassify this syndrome to improve understanding, treatment, and outcomes. Studies that, to some degree, dovetail with ours were conducted by Seymour et al. and Aldewereld et al. [9, 10]. Although Seymour and colleagues reported only four subtypes compared to our 10 subtypes, there was some overlap between studies. Our cluster H5 that had the highest SOFA score and marked ALT elevation (mean 2,080 U/L) was similar to their delta cluster [9]. However, any comparison of findings between or among studies relative to cluster characteristics should be performed with caution due to differences in the study population and the data structure, and the fact that some clustering techniques impose arbitrary limits on the number of clusters. Lastly, we decided to use hierarchical clustering instead of K-means clustering, which was the clustering technique used by Seymour et al. because our preliminary analysis using K-means clustering failed to show any distinct structure that we felt could yield reliable clusters. It is known that different methods of cluster analysis rely on different types of data structures, so our observation may simply reflect a suboptimal match between our data structure and the K-means clustering technique. When comparing our work with that of Aldewereld et al. [10], there are some similarities, including their use of hierarchical clustering methodology and their use of subclassification into high- and low-risk groups; however, a number of patients enrolled in their study were much smaller than our study population.
Some sepsis clusters show promise for integration into the clinical development of new therapeutics. Specifically, Cluster H5, characterized by predominant liver dysfunction and coagulopathy, represents a distinct population that may benefit from interleukin-1 receptor antagonists, as suggested by a post hoc analysis of the ProCESS trial [21]. Additionally, Cluster H7, despite its small population size, exhibits the highest in-hospital mortality and features predominant hematologic abnormalities, including thrombocytopenia. Thrombocytopenia in sepsis serves as a marker for poor prognosis, likely resulting from decreased platelet production, consumption, and immune receptor interactions [22]. Patients within this cluster could potentially benefit from a clinical trial evaluating antiplatelet therapy in sepsis [22].
4.1. Strengths and Limitations
This study and its findings pave the way for further research to better understand sepsis, and for improved management of sepsis in clinical practice. Moreover, this study identified 10 distinct subtypes of sepsis in Thai population. These findings may lead to the development of a scoring system to clinically classify patients with sepsis. All ten of the sepsis subtypes identified in this study were found to have a distinct clinical course, and this information will help to facilitate improved allocation of healthcare resources to the sepsis subtypes with poorer outcomes. This could lead to a triage system that classifies sepsis patients in clinical practice based on their first 24-hour clinical and laboratory parameters. The construction and validation of this triage system in a prospective trial would be of value in predicting disease severity and may facilitate patient care. The unique cluster characteristics identified in this study can inform clinical trials and prospective sepsis studies. However, identifying patients within these clusters may require the establishment of a dedicated prospective cohort with specific criteria to accurately predict the target population. Additionally, multiple parallel trials with distinct characteristics, conducted as part of an umbrella trial, may be needed to fully explore the implications of these clusters.
Our study also has some mentionable limitations. First, our study's retrospective design rendered it vulnerable to missing or incomplete data, and we did find missing or incomplete data for certain variables in some instances. Although imputation was performed for missing data for the cluster analysis, imputation was not performed for missing data when calculating the SOFA score. Another potential concern is that data specific to vital signs and mental status may reflect measurements taken upon admission, not upon first presentation in the emergency room. This factor may have adversely affected the calculation of the SOFA score since the measurements were taken postresuscitation. Therefore, some sepsis cases may not have been included in the analysis; however, the impact would be small due to the minor contribution of these clinical data in the SOFA score. Second, we did not calculate a sample size for our study because there is not yet any established method for calculating a sample size for a cluster analysis. Third, since the main aim of this study was to investigate whether distinct subtypes of sepsis exist in Thai population or how many distinct subtypes there might be, we did not perform any between or among group or cluster analyses to identify significant differences between groups, nor did we perform any linear regression analyses to identify significantly associated factors. We intend to more deeply evaluate and analyze the data yield from this study in future research projects. Fourth and last, we defined sepsis by both calculating the SOFA score using the data available in the electronic medical record and based on evidence of intravenous antibiotics administration for at least one day during hospital admission. However, some cases of organ failure may have been due to causes other than sepsis. Using the Sepsis-3 diagnostic criteria to define sepsis, so we are reasonably confident that the majority of cases were indeed sepsis. A well-designed prospective study that accounts for the aforementioned limitations is needed to shore up our findings and to further elucidate many of the still unknown characteristics of and mysteries associated with sepsis.
In the era of artificial intelligence, there are some considerations when using or implementing these computational models. By using unsupervised clustering method, the direct interpretability of the model is not easily feasible. The single or simple combination of clinical or laboratory parameters might not explain differences in the clustering result very well. Also, the clinician may find it challenging to understand and doubtful in implementing the model in the clinical practice. Given potential differences in patient characteristics and availability of variables, applying the model into different healthcare systems needs validation. Prospective validation in targeting health system is needed to validate the reliability of the model and to ensure patient safety.
5. Conclusion
Cluster analysis revealed 10 distinct subtypes of sepsis in Thai population that were stratified as either low-risk or high-risk for in-hospital mortality. Furthermore, the study is needed to investigate the value and implications of these sepsis subtypes in clinical practice.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Singer M. Deutschman C. S. Seymour C. W. The third international consensus definitions for sepsis and septic shock (Sepsis-3) JAMA 2016315880181010.1001/jama.2016.02872-s 2.0-8495927347526903338 PMC 4968574 · doi ↗ · pubmed ↗
- 2Fleischmann C. Scherag A. Adhikari N. K. Assessment of global incidence and mortality of hospital-treated sepsis. Current estimates and limitations American Journal of Respiratory and Critical Care Medicine 2016193325927210.1164/rccm.201504-0781 oc 2-s 2.0-8497390251426414292 · doi ↗ · pubmed ↗
- 3Tancharoen L. Pairattanakorn P. Thamlikitkul V. Angkasekwinai N. Epidemiology and burden of sepsis at Thailand’s largest university-based national tertiary referral center during 2019 Antibiotics 2022117 p. 89910.3390/antibiotics 1107089935884153 PMC 9312064 · doi ↗ · pubmed ↗
- 4Prescott H. C. Osterholzer J. J. Langa K. M. Angus D. C. Iwashyna T. J. Late mortality after sepsis: propensity matched cohort study British medical journal 2016353 p. i 237510.1136/bmj.i 23752-s 2.0-8496996188127189000 PMC 4869794 · doi ↗ · pubmed ↗
- 5Permpikul C. Sivakorn C. Tongyoo S. In-hospital death after septic shock reversal: a retrospective analysis of in-hospital death among septic shock survivors at Thailand’s largest national tertiary referral center The American Journal of Tropical Medicine and Hygiene 2021104139540210.4269/ajtmh.20-089633146115 PMC 7790065 · doi ↗ · pubmed ↗
- 6American College of Chest Physicians/Society of Critical Care Medicine Consensus Conference: definitions for sepsis and organ failure and guidelines for the use of innovative therapies in sepsis Critical Care Medicine 19922068648741597042 · pubmed ↗
- 7Bhavani S. V. Carey K. A. Gilbert E. R. Afshar M. Verhoef P. A. Churpek M. M. Identifying novel sepsis subphenotypes using temperature trajectories American Journal of Respiratory and Critical Care Medicine 2019200332733510.1164/rccm.201806-1197 oc 2-s 2.0-8506904819030789749 PMC 6680307 · doi ↗ · pubmed ↗
- 8Stortz J. A. Cox M. C. Hawkins R. B. Phenotypic heterogeneity by site of infection in surgical sepsis: a prospective longitudinal study Critical Care 2020241 p. 20310.1186/s 13054-020-02917-3PMC 720674032381107 · doi ↗ · pubmed ↗