What/Why/When/Where/How Framework and Faculty Development Workshop to Improve the Utility of Narrative Evaluations for Assessing Internal Medicine Residents
Dheepa R. Sekar, Kristen Ann Ehrenberger, Allie Dakroub, Scott Rothenberger, Thomas Grau, Andrea E. Carter

TL;DR
A workshop using a structured framework improves the quality and usefulness of narrative evaluations for assessing internal medicine residents.
Contribution
A new What/Why/When/Where/How framework and faculty development workshop to enhance narrative evaluations for Clinical Competency Committees.
Findings
Participant confidence in writing evaluations improved pre-, post-, and 3 months postworkshop.
Mock and real evaluation utility scores increased, though only some subcomponents improved significantly.
The framework shows promise in improving narrative evaluations for resident assessment.
Abstract
Clinical competency committees (CCCs) rely on narrative evaluations to assess resident competency. Despite the emphasis on these evaluations, their utility is frequently hindered by lack of sufficient detail for use by CCCs. Prior resources have sought to improve specificity of comments and use of evaluations by residents but not their utility for CCCs in assessing trainee performance. We developed a 1-hour faculty development workshop focused on a newly devised framework for Department of Medicine faculty supervising internal medicine residents. The what/why/when/where/how framework highlighted key features of useful narrative evaluations: behaviors of strength and growth, contextualized observations, improvement over time, and actionable next steps. Workshop sessions were implemented at a large multisite internal medicine residency program. We assessed the workshop by measuring…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
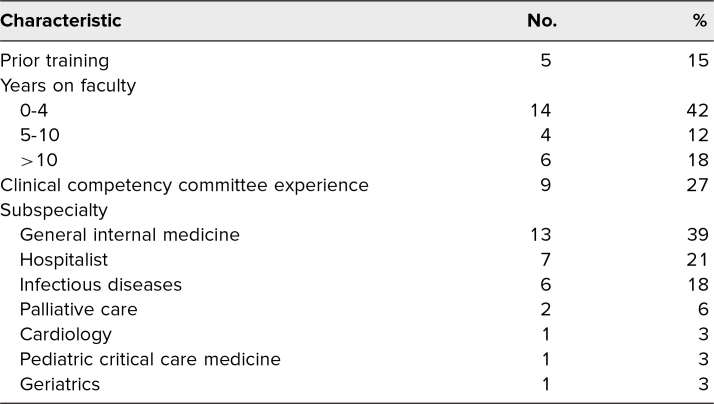 Figure 1
Figure 1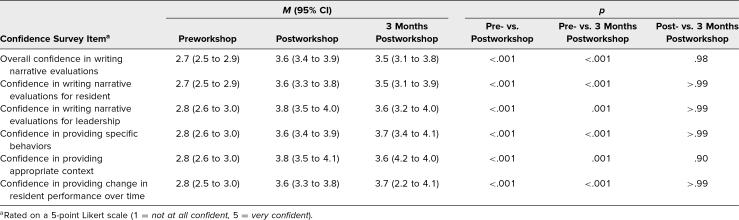 Figure 2
Figure 2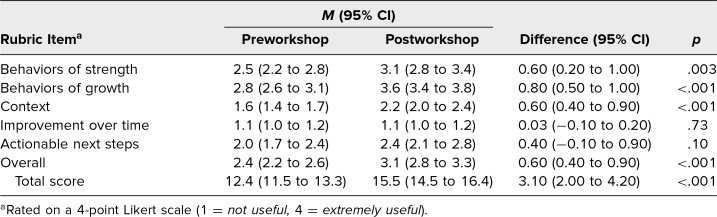 Figure 3
Figure 3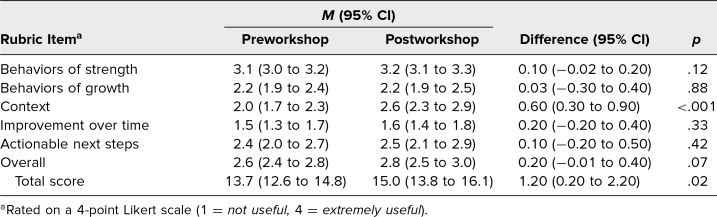 Figure 4
Figure 4Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsInnovations in Medical Education · Clinical Reasoning and Diagnostic Skills · Radiology practices and education
Educational Objectives
By the end of this workshop, participants will be able to:
- 1.Describe important features of a useful narrative evaluation.
- 2.Apply the what/why/when/where/how framework to guide observations of residents.
- 3.Examine sample narrative evaluations for features of a useful narrative evaluation.
- 4.Formulate a useful narrative evaluation by applying the what/why/when/where/how framework.
Introduction
Evaluation of trainees has undergone extensive revision by the Accreditation Council for Graduate Medical Education (ACGME) with the adoption of six core competencies in 2001 and developmentally based, specialty-specific educational milestones in 2013.^1,2^ With these changes came the requirement that each training program establish a clinical competency committee (CCC), whose charge is to ensure trainees achieve competence for independent practice by the time of graduation as well as demonstrating ongoing development over the course of training.^1^ Most CCCs rely on multiple mediums to inform assessment of residents along this developmental trajectory, but the most valued source is evaluation comments from end-of rotation evaluations forms completed by faculty who directly supervise residents in the clinical setting.^3,4^
End-of-rotation evaluation forms vary in ability to capture resident performance. While attempts have been made to optimize the scales for measuring resident performance, they do not always reflect the nuances of resident performance, making narrative comments essential.^3,5–8^ In fact, comments alone can accurately rank order the performance of learners.^9^ Narrative comments are crucial for CCCs to provide trainees with steps for improvement, so it is important to improve the quality and utility of written comments for use by CCCs.^5–8,10^
The literature describes high-quality written evaluations as being specific, with contextualized examples.^6,10^ However, faculty face high cognitive load in converting observations to written comments as they try to recall examples or consider which might be useful in reflecting resident competency.^6,9,11^ Several studies have attempted to improve the quality of written evaluations. These studies have looked at improvement in the context of resident reception of feedback, specificity of comments provided, and overall quality of narrative comments.^7,12–17^ To our knowledge, no previous resources have been created with the goal of improving the utility of written comments for use by CCCs.
We implemented and evaluated a faculty development workshop aimed at improving the utility of narrative comments for use by the CCC at our internal medicine residency program.
Methods
Setting and Participants
We implemented and evaluated a 1-hour workshop for faculty with the goal of improving the utility of narrative comments for use by CCCs. We delivered the workshop at standing faculty development sessions in four divisions within the Department of Medicine at the University of Pittsburgh Medical Center in May-August 2021. All faculty who regularly supervised internal medicine residents were invited via email to attend. Participation in the workshop was entirely voluntary. We created the workshop to be delivered both in person and virtually. A 1-hour interactive adaptable workshop model was chosen for feasibility in reaching a large faculty body located at multiple sites in multiple divisions of varying clinical structures.
Workshop
The workshop was an interactive didactic (Appendix A) that focused on the use of a what/why/when/where/how framework (Appendix B) that not only consolidated the core features that CCC members used in evaluating residents but also decreased cognitive load of observing faculty.
Workshop content focused on (1) the value of narrative comments, (2) actionable feedback as described in Kim Scott's book Radical Candor,^18^ and (3) key features of useful narrative comments using a what/why/when/where/how framework. The workshop demonstrated the framework through step-by-step analysis of examples of useful and not useful narrative comments. The framework was informed by a local formal qualitative needs assessment of our CCC, which highlighted the usefulness of comments on behavioral content, performance relative to peers, and next steps for improvement in assessing residents. These concepts were also highlighted in the literature that we incorporated in developing the what/why/when/where/how framework. The “What behaviors did you observe?” and “Why are these behaviors reflective of their performance?” components emphasized the importance of including specific behavioral examples and reflecting on why these behaviors were salient representations of performance.^19^ The “When in training?” and “Where were the behaviors observed?” components emphasized the contexts of the observation, allowing observing faculty to provide comparisons to a mental scale.^20^ The “How can the trainee improve?” component emphasized the importance of providing next steps for improvement in guiding the resident for continued improvement.^20^
Participants were asked to apply the framework to mock learner videos. We created two 5-minute mock learner videos (Appendices C and D) that captured typical skills of senior internal medicine residents during an inpatient general medicine service. Participants wrote mock evaluations (MEs) immediately prior to the workshop, which demonstrated priming, and immediately after the workshop using our framework, which demonstrated deliberate practice of the new skill.
Outcomes Measured
We evaluated effects of the workshop on (1) participants’ confidence in writing narrative comments, (2) utility of participants’ narrative comments on mock resident cases, and (3) utility of participants’ narrative comments on real end-of-rotation resident evaluations in MedHub.
Confidence survey
We assessed confidence through electronic Qualtrics XM surveys (Appendix E) prior to, after, and 3 months after the workshop. Survey question responses were based on a 5-point Likert scale (1 = not at all confident, 5 = very confident). Each item was developed and iteratively refined with input from CCC members and observing faculty.
Utility of comments on mock resident cases
We assessed skill development by evaluating utility of comments on mock resident cases. Participants submitted a narrative ME of the learner case prior to and after the workshop. We deidentified and randomized the pre- and postworkshop MEs. Two medicine-pediatric CCC members graded each ME for its utility in providing useful information for the CCC using the utility grading rubric (Appendix F). We chose CCC members outside of the internal medicine residency program to allow for generalizability of the content, and we specifically chose medicine-pediatric CCC members for similarity of resident milestones of this discipline to internal medicine. We used the average of the two graders’ item scores and total scores in the final analysis.
Utility of comments on real resident evaluations
We assessed practice change by evaluating the utility of narrative comments written by participants on end-of-rotation MedHub real evaluation (RE) forms routinely collected by the residency program pre- and postworkshop. MedHub evaluations with no written comments were excluded. We performed deidentification, randomization, and scoring as described above for MEs. Participants were not informed of the time frame in which postworkshop narrative evaluations would be assessed in an attempt to decrease the likelihood of a Hawthorne effect.
Methods of Analysis
Development of utility grading rubric
To assess utility of narrative evaluations for use by the CCC, we created a grading rubric (Appendix F) modeled after a previously published grading rubric for assessing the overall quality of narrative evaluations.^21^ Our grading rubric included an overall score as well as components of the framework: behaviors of strength, behaviors of growth, context, improvement over time, and actionable next steps. The items and scale of the adapted graded rubric were discussed and iteratively optimized with a focus group of four members of the internal medicine CCC, resulting in six items rated on a 5-point Likert scale. Then, two medicine-pediatric residency CCC members scored six randomly selected sample narrative evaluations and discussed for consensus. This discussion resulted in the final grading rubric with the same six items but now rated on a 4-point Likert scale (1 = not useful, 4 = extremely useful), for a total score of 24. We assessed the rubric for interrater reliability using interclass correlation coefficients based on all analyzed MEs.
Statistical analysis
We assessed changes in confidence pre-, post-, and 3 months postworkshop for each confidence item using a mixed-effects linear regression model fit with time as the categorical predictor variable. Bonferroni adjustments were employed when analyzing pairwise differences between time points. The evaluation utility overall score and subdomains on both the MEs and REs were also analyzed using mixed-effects linear regression models. We chose this modeling approach to account for repeated measures per participant and make maximum use of all available data. We used Stata (StataCorp) for statistical analysis and Excel for data management, deidentification, and randomization where needed, and a significance level of 5% was assumed.
Facilitator Guide
We include here a guide for facilitation of the workshop (Appendix G).
This project was designated exempt by the University of Pittsburgh Institutional Review Board.
Results
Participants
Fifty-four participants started the presurvey, and 33 completed the workshop, for a response rate of 61%. The participants represented varying time on faculty, experience on the CCC, and several subspecialities (Table 1).
Table 1.: Characteristics of Participants (N = 33)
Utility Grading Rubric
The interclass correlation for interrater reliability for the total score on the utility grading rubric (Appendix F) was .83.
Confidence Survey
The 33 faculty who participated in the workshop and completed both pre- and postsurveys were included in the confidence analysis. All confidence items significantly improved pre- to postworkshop and sustained at 3 months: overall confidence (2.7 to 3.6 to 3.5), confidence in writing narrative evaluations useful for the resident (2.7 to 3.6 to 3.5) and program leadership (2.8 to 3.8 to 3.6), and confidence in providing specific features: specific behaviors (2.8 to 3.6 to 3.7), context (2.8 to 3.8 to 3.6), and improvement over time (2.8 to 3.6 to 3.7), with p < .05 for all comparisons between pre- and postworkshop and pre- and 3 months postworkshop (Table 2). There was no significant difference between immediate postworkshop and 3 months postworkshop for all comparisons.
Table 2.: Confidence in Writing Narrative Evaluations
Utility of comments on mock resident cases
Thirty-seven MEs were submitted preworkshop, and 33 MEs were submitted postworkshop. The total utility score of learner case narrative evaluations significantly improved postworkshop from 12.4 to 15.5, with p < .001. Scores for specific behaviors of strength, specific behaviors of growth, context, and overall scores significantly improved. Scores for improvement over time and actionable next steps did not significantly improve (Table 3).
Table 3.: Utility of Mock Evaluations
Utility of comments on real resident evaluations
Of the 33 participants who completed the workshop, 17 participants had REs both pre- and postworkshop that met inclusion criteria. From these 17 participants, we collected 128 REs preworkshop and 95 REs postworkshop. We randomly selected up to five evaluations for each participant for each pre- and postworkshop for the final analysis. Three postworkshop REs did not include a narrative comment and were excluded. The final analysis included a total of 73 preworkshop and 58 postworkshop REs.
The mean total utility score was 13.7 preworkshop and 15.0 postworkshop, with p < .05. Context significantly improved from 2.0 preworkshop to 2.6 postworkshop, with p < .001, but there was no significant improvement in the other domains. The overall utility score was 2.6 preworkshop and 2.8 postworkshop, with p = .07 (Table 4).
Table 4.: Utility of Real Evaluations
Discussion
This 1-hour faculty development workshop to improve the utility of narrative evaluations in assessing internal medicine residents was designed for feasibility in impactfully reaching a broad audience through a short session focused on decreasing cognitive load. This framework and deliberate practice led to improved confidence, skill, and behavioral practice of faculty in writing narrative comments on internal medicine residents that would be useful for CCCs.
The workshop's design focused on capturing behavioral details of resident performance in narrative comments through a framework. The framework built upon prior resources that also focused on behavioral examples. Prior resources used a process flow or a reference card for competencies but not specific descriptors of behaviors useful for CCCs.^7,14^ We highlighted the key features of behaviors CCCs use in assessing residents that had not been captured in previous resources, namely, the components of when, where, and how/next steps.^7,13,14^ Additionally, the framework addressed concerns of faculty time and cognitive load by providing an anchor for these details and a reference tool to use in practice. Another study provided direct in-person feedback to faculty on their narrative comments, which can be time consuming to implement.^12^ This workshop relied on an easily distributable framework to guide narrative writing. Furthermore, the workshop's evaluation addressed an important question about the utility of narrative comments for the purpose of resident evaluation. Prior studies evaluated syntax for specificity or resident reception, but it was unclear if CCCs found them more useful.^13,14^ In the assessment of this workshop, we used a scale of utility and demonstrated local content, face validity, and interrater reliability. This scale can be used by other programs attempting to assess local narrative comments for utility for their CCCs.
Not all subcomponents of the narrative comments improved in the MEs and REs. In the MEs, improvement over time and next steps did not improve. These components require more depth of reflection on resident performance and may also require additional faculty training. Additionally, the level of detail in the mock videos may not have been sufficient to accurately capture this skill. In the REs, only the context subcomponent improved significantly. Context of time in training and patient acuity may be simpler concepts to report. The assessment of REs shows application in both a different and a delayed setting, which may have led to loss in some detail of the skill.
An important limitation of this project is that we did not specifically assess the role of bias in narrative evaluations. Several studies have shown that the use of language changes based on reported gender and race,^22,23^ and this would be an interesting area for future study. Other limitations include delivery and assessment at a single large academic institution in a specific residency specialty, so results may not be generalizable across other institutions or specialties. Participation was voluntary across many divisions, but participation outside of general internal medicine and hospital medicine was limited. Additionally, voluntary participation may have introduced self-selection bias as participants could have been more likely to use workshop concepts in future narrative evaluations than others would. Confidence surveys were based on Likert scales, which might have introduced response bias. We are unable to comment on the effect of this workshop compared to a broader baseline including faculty who did not participate. In addition, writing narrative evaluations using the what/why/when/where/how framework may take more time and effort than traditional narrative evaluations. Finally, while the scoring tool was adapted from a previously published rubric, was reviewed and revised by local content experts, and was assessed for interrater reliability, its use may require further reliability and validity testing before application in other settings.
Next steps for continued improvement through use of the workshop's content and framework may require repetition of practice. Addressing this gap could be as simple as providing the framework as a reference at the beginning of each rotation, as a reference in the evaluation form itself, or both. Another important next step is to assess whether this framework's focus on objective comments helps decrease gender or racial bias in evaluations. If programs are able to incorporate the framework into learning management software, building in components that flag biased language may mitigate overall bias in narrative evaluations. Such an implementation would require careful assessment and validation. Additionally, this workshop relies on individual reflection on content and skills. The focus on individual reflection can be improved by allowing participants to apply the utility rubric to their evaluations as a form of ongoing formative self-feedback. Future iterations could be further improved by including small-group discussions of mock learner videos, allowing participants to learn from each other's observations and reflections, or employing a mock CCC approach. Future implementations could also provide regular application of the utility rubric to REs for ongoing formative feedback to faculty as well as assessment of the workshop's long-term impact. Finally, future implementations should assess whether subsequent interactive sessions are needed or if a reference to the framework will provide a similar effect but allow for maintained feasibility for busy academic faculty.
Overall, this short workshop provides a high-yield framework resulting in improved overall utility of real narrative comments for use by CCCs. The workshop fulfills the needs of two important stakeholders in narrative comments—CCCs and observing faculty—by addressing inconsistent views and providing a simple high-yield framework. While the workshop was implemented at a single institution, its materials are translatable to training programs with CCCs that use a developmental approach.
Appendices
- Workshop Slides.pptx
- Framework.docx
- Mock Learner Video 1.mp4
- Mock Learner Video 2.mp4
- Surveys.docx
- Utility Grading Rubric.docx
- Facilitator Guide.docx
All appendices are peer reviewed as integral parts of the Original Publication.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Andolsek K, Padmore J, Hauer KE, Ekpenyong A, Edgar L, Holmboe E. Clinical Competency Committees: A Guidebook for Programs. 3rd ed. Accreditation Council for Graduate Medical Education; 2020. Accessed June 17, 2024. https://www.acgme.org/globalassets/acgmeclinicalcompetencycommitteeguidebook.pdf
- 2Nasca TJ, Philibert I, Brigham T, Flynn TC. The Next GME Accreditation System—rationale and benefits. N Engl J Med. 2012;366(11):1051–1056. 10.1056/NEJ Msr 120011722356262 · doi ↗ · pubmed ↗
- 3Hemmer PA, Hawkins R, Jackson JL, Pangaro LN. Assessing how well three evaluation methods detect deficiencies in medical students’ professionalism in two settings of an internal medicine clerkship. Acad Med. 2000;75(2):167–173. 10.1097/00001888-200002000-0001610693850 · doi ↗ · pubmed ↗
- 4Hauer KE, Chesluk B, Iobst W, et al. Reviewing residents’ competence: a qualitative study of the role of clinical competency committees in performance assessment. Acad Med. 2015;90(8):1084–1092. 10.1097/ACM.000000000000073625901876 · doi ↗ · pubmed ↗
- 5Lurie SJ, Mooney CJ, Lyness JM. Measurement of the general competencies of the Accreditation Council for Graduate Medical Education: a systematic review. Acad Med. 2009;84(3):301–309. 10.1097/ACM.0b 013e 3181971 f 0819240434 · doi ↗ · pubmed ↗
- 6Ginsburg S, Mc Ilroy J, Oulanova O, Eva K, Regehr G. Toward authentic clinical evaluation: pitfalls in the pursuit of competency. Acad Med. 2010;85(5):780–786. 10.1097/ACM.0b 013e 3181 d 73fb 620520025 · doi ↗ · pubmed ↗
- 7Holmboe ES, Fiebach NH, Galaty LA, Huot S. Effectiveness of a focused educational intervention on resident evaluations from faculty: a randomized controlled trial. J Gen Intern Med. 2001;16(7):427–434. 10.1046/j.1525-1497.2001.016007427.x 11520379 PMC 1495246 · doi ↗ · pubmed ↗
- 8Crossley J, Jolly B. Making sense of work-based assessment: ask the right questions, in the right way, about the right things, of the right people. Med Educ. 2012;46(1):28–37. 10.1111/j.1365-2923.2011.04166.x 22150194 · doi ↗ · pubmed ↗