Single-Index Mixed-Effects Model for Asymmetric Bivariate Clustered Data
Weihua Zhao, Dipankar Bandyopadhyay, Heng Lian

TL;DR
This paper introduces a new statistical model for analyzing periodontal disease data that accounts for non-linear relationships and asymmetric data patterns.
Contribution
The novel contribution is a single-index mixed-effects model using asymmetric Laplace distribution for clustered bivariate data.
Findings
The proposed model efficiently handles asymmetric and heavy-tailed data with outliers.
Simulation studies confirm the model's effectiveness in finite samples.
The EM-type algorithm provides reliable maximum-likelihood inference.
Abstract
Studies/trials assessing status and progression of periodontal disease (PD) usually focus on quantifying the relationship between the clustered (tooth within subjects) bivariate endpoints, such as probed pocket depth (PPD), and clinical attachment level (CAL) with the covariates. Although assumptions of multivariate normality can be invoked for the random terms (random effects and errors) under a linear mixed model (LMM) framework, violations of those assumptions may lead to imprecise inference. Furthermore, the response-covariate relationship may not be linear, as assumed under a LMM fit, and the regression estimates obtained therein do not provide an overall summary of the risk of PD, as obtained from the covariates. Motivated by a PD study on Gullah-speaking African-American Type-2 diabetics, we cast the asymmetric clustered bivariate (PPD and CAL) responses into a non-linear mixed…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
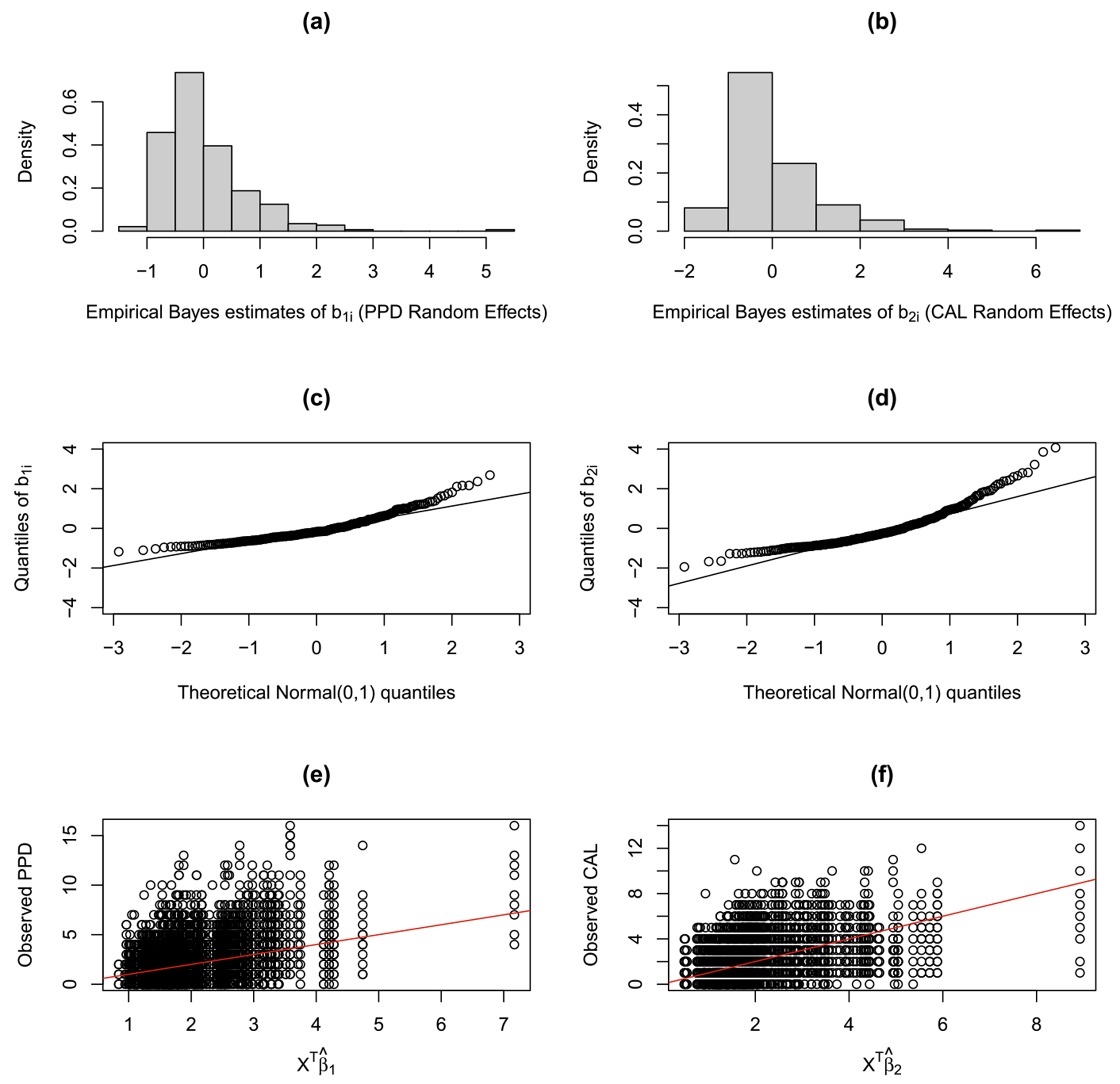 Figure 1
Figure 1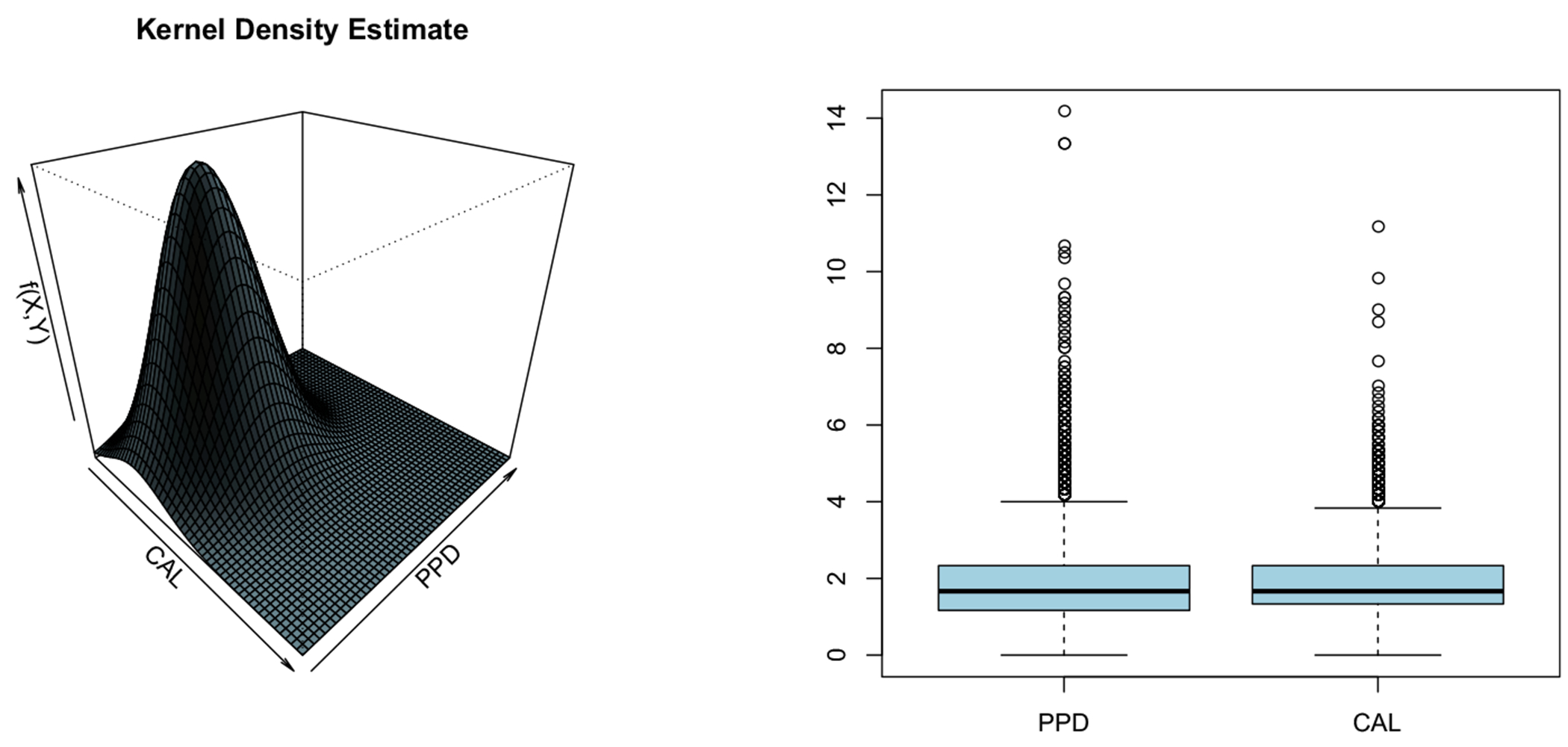 Figure 2
Figure 2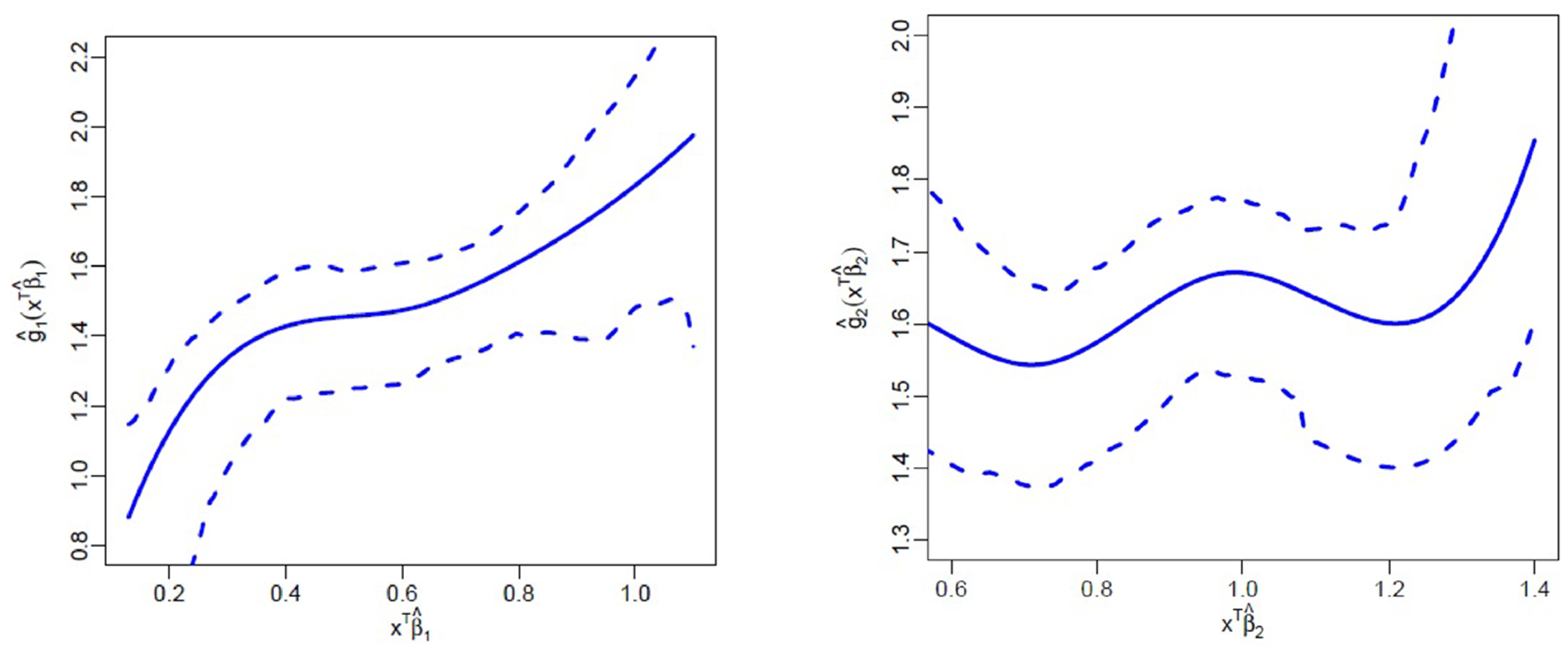 Figure 3
Figure 3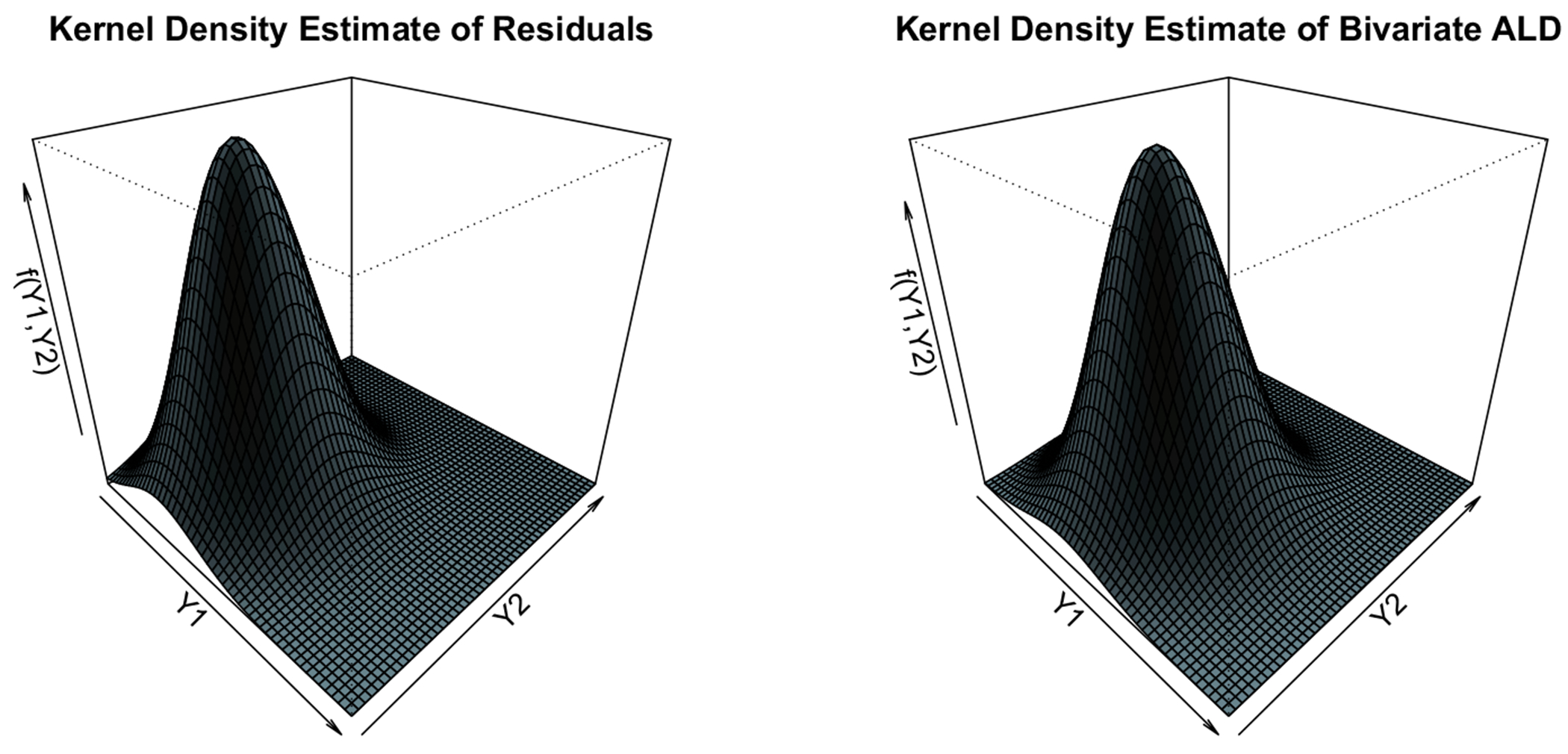 Figure 4
Figure 4Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsStatistical Methods and Bayesian Inference · Bayesian Methods and Mixture Models · Statistical Methods and Inference
Introduction
1
Epidemiological studies in a clustered, or longitudinal data setting often generate multivariate (repeated) outcomes that are analyzed under the ubiquitous multivariate normal (MVN) assumptions of the random terms (random effects, and within-subject random errors) via standard software, such as SAS, or R. However, violations of those assumptions can lead to imprecise parameter estimates (Bandyopadhyay et al. 2010). These non-Gaussian features are usually manifested through skewness of the response vector, and/or thick-tails. Although achieving close-to-normality via suitable data transformations of the responses (such as log, or Box-Cox) for standard linear mixed model (LMM) analysis are possible, they maybe avoided due to their non-universality, and difficulty in covariate interpretation on the original scale (Jara et al. 2008). To address this, various flexible (parametric) alternatives to the MVN density exists, such as the multivariate skewnormal density (Azzalini and Capitanio 1999; Gupta et al. 2004; Azzalini 2010), the heavy-tailed multivariate skew t-density (Azzalini and Capitanio 2003), and others, that can accommodate departures from normality without resorting to adhoc data transformations.
In practice, this setup can be further complicated in presence of multiple outcomes recorded at each cluster units/components. The motivating data example in this paper comes from a clinical study of periodontal disease (PD) conducted on Gullah-speaking African-American Type-2 diabetics (henceforth, GAAD). Here, the multiple outcomes of interest are the tooth-level (mean) probed pocket depth (PPD) and clinical attachment level (CAL), which are recorded (in mm, via a periodontal probe) simultaneously for each tooth nested/clustered within a subject. While PPD quantifies the current PD status, CAL measures the (past) disease history and progression (Page and Eke 2007). An oral clinician may be interested in studying the joint evolution of these outcomes over some features of covariates, and the complexity is induced from two different sources of correlation—(a) Between repeated observations of any given outcome (PPD, or CAL) measured at a cluster unit (tooth), and (b) Between multiple outcomes (PPD and CAL) measured at the same tooth. The existing literature (both classical and Bayesian) in this context of multiple repeated outcomes modeling is also very rich (Luo and Wang 2014; Verbeke et al. 2014; Lin and Wang 2013; Michaelis et al. 2018; Bandyopadhyay et al. 2010). However, a vast majority of these models are developed under the restrictive assumption of linearity of the covariate effects over the multivariate responses.
To motivate further, consider Fig. 1, which presents plots of the empirical Bayes’ estimates of random effects (panels a and b), corresponding Q-Q plots (panels c and d), and observed versus estimated (non-linear) curve (panels e and f), obtained from fitting a LMM separately to the PPD and CAL responses in the GAAD data, using the lme function in R. The plots clearly reveal evidence of asymmetryq (departures from the Gaussian assumptions), which cannot be explained by a standard LMM fit. In addition, the predictor space restricted to be linear combinations of covariates may not provide an elegant picture of their cross-sectional association with the (bivariate) response. Formulating an index for PD (that handles possible nonlinearity, confounding, and interaction effects between the PD outcomes and the covariates) via a single-index model, or SIM (Hardle et al. 1993) can be a clinically elegant alternative. SIMs are a popular class of semiparametric regression models that relaxes the assumption of linearity, and bypass the ‘curse of dimensionality’ by reducing the multi-dimensional predictor space into an univariate (scalar) index . A link function g(.) now connects the covariate space to the response , offering a pragmatic compromise between a fully nonparametric (and often non-interpretable) multiple regression, and a restrictive (parametric) linear regression. Here, the magnitude of the index coefficient determine the relative importance of the -th predictor on the index, and denotes the location of interest in the response curve at the index . In biomedical research, the recent work by Wu and Tu (2016) develops an adiposity index via a (multivariate) SIM to efficiently predict multiple longitudinal outcomes (systolic and diastolic blood pressure) in children. However, their proposal considers the usual MVN assumptions for the random terms (errors and effects), and may not well accommodate heavy tailed and other non-Gaussian features. Furthermore, they did not provide rigorous theoretical justification.
Considering Wu and Tu (2016) as our starting point, we seek to develop an index that can efficiently predict the clustered bivariate (PPD and CAL) PD outcomes. Such a clinical index that links both outcomes is vastly absent in the oral health literature. Our bivariate single-index mixed (BV-SIM) model tackles non-Gaussian features in the responses via the multivariate asymmetric Laplace density (ALD; Kotz et al. 2001) assumptions in the random terms. The multivariate ALD can accommodate asymmetric, peaked, and heavy-tailed data using fewer number of parameters than the popular multivariate skew-t density (Gupta 2003). The multivariate symmetric Laplace density (Naik and Plungpongpun 2006), a special case of the ALD, has been applied in other fields, such as speech clustering, classification problems, and image/signal analysis. Under this framework, we consider a polynomial spline approximation to the nonparametric index function, and propose an efficient EM-type algorithm for estimation and inference. The spline approximation, and the mixture normal representation of the multivariate ALD presents a computationally efficient, and intuitively appealing estimation setup, quantifying correlations from both sources.
The rest of the paper is organized as follows. In Sect. 2, we propose the BV-SIM model under the assumptions of a multivariate asymmetric Laplace density. Using the polynomial splines approximation for the nonparametric (index) functions, we derive the maximum likelihood (ML) estimate, and establish the large sample properties of the proposed estimators in Sect. 3, with the detailed technical proofs relegated to the Appendix, where we use the projection method to prove the asymptotic normality of parametric part. In Sect. 4, we develop an efficient MLE procedure based on the EM-algorithm. Simulation studies comparing finite sample performance of our approach to other alternatives appear in Sect. 5, while Sect. 6 illustrates the method via application to the PD dataset. Finally, some concluding remarks are presented in Sect. 7.
Statistical Model
2
We begin with a sketch of the multivariate shifted Laplace density (Kotz et al. 2001), and then develop our SIM mixed effects framework for bivariate clustered data. The multivariate ALD has the density
where is the modified Bessel function of the third kind with index , is a skewness parameter and is a positive definite (p.d.) scatter matrix with dimension . We denote (2.1) as . Note, the ALD forces each component density to be joined at the same origin. An extension, the multivariate shifted asymmetric Laplace distribution (SALD; Kotz et al. 2001), has the form
where , and are defined in (2.1). Here, we use the notation to denote the random variable following a -dimensional SALD. After some calculations, the mean and variance of SALD are given by
It is clear that the mean depends on the shifted location parameter and skewness parameter , while its variance depends on scatter matrix and skewness parameter . Also, must be p.d. if is p.d. The parameter plays an important role in multivariate asymmetric data analysis, besides the location and scatter matrix . Note, the multivariate density in (2.2) reduces to (2.1) when , and it further reduces to the multivariate symmetry Laplace distribution (Eltoft et al. 2006) when . Moreover, (2.2) reduces to the univariate ALD when dimension and , and is popularly used in the likelihood framework for quantile regression with density , where . The SALD in (2.2) has the following stochastic representation
where is a random variable from an exponential distribution with mean 1 and is generated independent of . Using Bayes’s theorem, the density of given is generalized inverse Gaussian, with the density
where and are as defined in (2.2). The SALD allows for peakedness, heavy tails, and skewness, and hence provides more flexibility in modeling multivariate data with non-Gaussian features. More properties, extensions and applications of SALD appear in Kozubowski and Podgórski (2001); Franczak et al. (2014); Bouveyron and Brunet-Saumard (2014).
Single-Index Mixed-Effects Model
2.1
Let be the observed values of two response variables (here, mean PPD and CAL) for the subject at the th location (here, tooth), where and . We assume
where and are two unknown nonparametric functions, , and , and are the (fixed) index coefficients and random effect for the -th response ( ), is a vector of skewness parameters, and is the scatter matrix with dimension for the random error . To accommodate a robust specification, we also assume the random effects , where is an unstructured covariance matrix with dimension . Note, carries information pertaining to both the clustering correlation within a response found on the two blocks of diagonal sub-matrices, with dimensions and , and the cross-correlations between responses, found on the off-diagonal sub-matrices. In addition, we further assume the joint density of is , . We call model (2.5) as the single-index mixed-effects (SIME) model for bivariate clustered data.
For identifiability, we assume both and , and their first components are positive, respectively. In this paper, the popular “delete one component” method is used to avoid the equality constraints (Yu and Ruppert 2002; Cui et al. 2011). Specifically, we write where, . Under this parametrization, is a smooth deterministic function of , with its Jacobian matrix given by
where is the identity matrix with rows/columns. The true parameter satisfies the constraint , which implies that it is a interior point in a unit ball in . Therefore, is infinitely differentiable in a neighborhood of . Similarly, we define and , and let , . Applying the stochastic representation in (2.3), model (2.5) admits the following hierarchical structure:
where , E denotes the exponential distribution, , where denotes the kronecker product, and is a column vector with element 1 . From (2.5) and (2.6), it is clear that conditional on and are independent. Integrating out in (2.6), we have the following hierarchical model
where with , . Moreover, it follows from (2.7) that the are independent and marginally distributed as
where . From (2.7) and by the properties of the generalized inverse Gaussian distribution in (2.4), we have
where and .
Modeling the Index Functions
2.2
Since the two functions and in (2.5) are unknown, we use polynomial splines to approximate them in the subsequent ML estimation. Polynomial splines are simple, yet practical tools with computational tractability and statistical efficiency, and has been proven to be an extremely powerful method for smoothing.
For simplicity, we assume that the covariates and are bounded and the supports of and are contained in the finite interval . Such a compactness assumption is almost always used in nonparametric regression with spline approximation. We use polynomial splines to approximate the nonparametric functions and . Let be the partitions of into subintervals with internal knots. A polynomial spline of order is a function whose restriction to each subinterval is a polynomial of degree and globally times continuously differentiable on . The collection of splines with a fixed sequence of knots has a B-spline basis , with . We assume the B-spline basis is normalized to have , although, any scaling can be used without changing the theoretical results.
Let and , where and with number of knots and for and . Then, we have where . As a result, we can write
for . By letting the number of knots increase with the sample size at an appropriate rate, the spline estimate of the unknown function can achieve the optimal nonparametric convergence rate.
Theoretical Properties
3
In this section, we will investigate the theoretical properties for the index parameters and the index functions. In the following we establish the large sample properties based on the marginal distribution (2.8) of the proposed BV-SIM model in (2.5). For simplicity, we assume , with the response viewed as i.i.d. data, . In (2.8), and , with . We first introduce some notations.
Let and be the true index parameters, and and the corresponding true index functions. Let , with . Denote the support of as , where and , with . Let be the collection of all functions on the support whose -th order derivative satisfies the Hölder condition of the order with . Then, for each , there exists a positive constant such that . From De Boor (2001), there exists a constant (see page 149) such that
if , where are the true value of spline coefficients, which can be viewed as the best approximation coefficient vectors for .
Denote and as the parameter space of . Given the covariates and , let be the log-likelihood of the marginal distribution for response in (2.8) and be the corresponding spline-approximated log-likelihood. Let be the true value of and . Define as the MLE, given by
where with . Define the space of square integrable single-index functions , where with . Denote and . Then, the projection of a -dimensional random vector onto (defined as is the minimizer of
Note, the definition of projection involves the distributions of both and since we take the expectation over these random variables. This definition can be extended to any matrix by column-wise projection. In the following, we list the regularity conditions (Wang et al. 2014; Lian and Liang 2013; Zhao et al. 2017) that are necessary to study the asymptotic behavior of the MLEs.
- (A1)Both and for some s ≥ 2.
- (A2)Both and , are bounded, with density supported on a convex set.
- (A3)The true parameter point is an interior point of the parameter space .
- (A4)The log-likelihood is at least thrice differentiable on parameters . Furthermore, the second derivatives of the likelihood function satisfy the equations
Also, there exists functions , such that
for , and . Here denotes the -th component of .
- (A5)The Fisher information matrix satisfies the conditions
where and denote the smallest and largest eigenvalues of a matrix.
- (A6)Suppose . Assume all with . We also assume that
is positive definite, where is evaluated at .
Remark 1 The smoothness condition in (A1) is a requirement to attain the best convergence rate for single-index functions approximated in the spline space. Condition (A2) is widely used in the single-index modeling literature, ensuring that the index functions are defined in a compact set and thus facilitates the technical derivations. Conditions (A3) and (A4) are two common assumptions in the literature of maximum likelihood estimation with spline approximations (Wang et al. 2011, 2014), implying that the information matrix of the likelihood function is positive definite. Condition (A5) is slightly stronger than that used in the usual asymptotic likelihood theory, however, widely used in high-dimensional likelihood estimation literature Fan and Peng (2004). Finally, Condition (A6) is related to the ‘projection’, or the ‘orthogonalization’ technique common in a semiparametric setup, which includes partially linear model (Li 2000), partially linear additive model (Lian and Liang 2013), and single-index models (Cui et al. 2011; Zhao et al. 2017).
Denote , and let . Then, we have the following result.
Theorem 1 Under the Conditions (A1)–(A5), suppose that , , then we have
As an immediate implication of Theorem 1, we have and .
Remark 2 Note that the rate of convergence for nonparametric functions is if the optimal , which is the same as that found in the nonparametric and semiparametric literature.
Theorem 2 Under Conditions (A1)–(A6), suppose that and . Then, we have
where
and is evaluated at the true .
Following Theorem 2 and invoking the Delta method, we have
Maximum Likelihood Estimation
4
In this section, we develop the ML estimation for our BV-SIM model. We utilize EM-type algorithms for obtaining the MLE, based on two types of missing data structures in (2.6). The EM algorithm is a popular iterative algorithm for MLE in models with incomplete data (Dempster et al. 1977), where each iteration of the EM algorithm consists of two steps, the expectation (E) step and the maximization (M) step. Despite desirable features, the M-step in the EM algorithm is often difficult to implement for complicated models, and is replaced with a sequence of computationally simple conditional maximization (CM) steps, i.e. maximizing over one parameter with the other parameters held fixed. This leads to a simple extension of the EM algorithm, called the ECM algorithm (Meng and Rubin 1993).
Consider the hierarchical multivariate Laplace model in (2.6), where both and are missing data. Let and . The log-likelihood for the complete data in the multivariate Laplace single-index mixed-effects model up to an additive constant can be written as
where
and
where is defined in (2.5) and . Note that can be further written as
Denote as the full parameter vector to be estimated. We firstly compute the conditional posterior mean and variance of at the current estimate , leading to
for , where
After obtaining the estimates of the conditional mean and conditional covariance of the random effect , we proceed to calculate the expectation of . Define the quantities
which can be computed from (2.9), using the current estimate . After some simple calculations, we have
and
Next, maximizing over parameters and , and maximizing over , we can obtain their estimates, which constitutes the CM-steps 1-5 in the following ECM algorithm:
E-step Given current parameter estimates, for , update and using (4.3), and update and by (4.2).
CM-step 1 Fix and , and update by maximizing (4.4) over , which gives
CM-step 2 Fix and , update by maximizing (4.4) over , i.e.,
CM-step 3 Fix and , and update by maximizing (4.4) over . Since there is no explicit expression for the estimate of the index parameter , we use the Newton–Raphson method to obtain , leading to the following iterative formula
where and denotes the first derivative of the spline basis .
CM-step 4 Fix and , and update by maximizing (4.4) over . Denote
Applying the result in Lemma 1, we obtain .
CM-step 5 Update by maximizing (4.5) over , which gives
Repeat the above E-step and CM-steps, until all parameters achieve the desired convergence criterion. Since our estimation procedure requires initial values, we set , and the estimates of and are obtained from fitting a linear mixed model via the R package lmer, where and are the design matrices corresponding to the fixed effects and random effects, respectively. Simulation studies (in Sect. 5) show that the above strategy works well.
Simulation Studies
5
In this section, we conduct extensive simulation studies using synthetic data to study the finite-sample performance of the model parameters in our proposed method (Simulation 1), and the robustness of our method when compared to existing alternatives, under data generated under various settings (Simulation 2).
Knots Selection
5.1
It is well-known that the performance of any spline estimation depends on the knots selection. Here, we employed Schwartz information criteria (SIC) for adaptive know selection (Ma and Song 2015; Lu 2017; Zhao et al. 2017). In view of the order (of knots) to attain optimal convergence rate of nonparametric functions in 1, a sequence of knots are selected in a neighborhood of , such as , where , and is the smoothing parameter. We choose in both simulation studies and real data application. For simplicity, we use cubic polynomial splines and the number of interior knots are the same for the two nonparametric link functions. The number corresponding to the minimum SIC value is defined as the optimal number of knots , where denotes the estimated value of the log-likelihood function obtained from(2.8), with the given knots.
Simulation 1: Assessing Finite-Sample Properties
5.2
Here, data is generated from the model (2.5), where the two nonparametric functions are and , with the true index parameters and , respectively. Both covariates and are generated independently from the trivariate uniform distribution . The random effects are generated from , with covariance matrix
and the corresponding covariates and , where and are generated from the standard normal distribution. The random error is generated from with and . The sample size is set to be 50, 100 and 200, and the number of cluster members in each subject is generated from the discrete uniform distribution on . Table 1 presents the averages of bias, absolute bias, and the empirical standard error estimates for the index parameters and the skewness parameter, over 400 replications.
From Table 1, all biases are close to zero for all sample sizes, implying our proposed estimators are consistent. Moreover, the absolute biases and the standard errors are smaller with increasing sample sizes, with the estimation performance of index parameters significantly better than the skewness parameters. To further assess the estimation results, we calculate the integrated mean squared error (IMSE), defined as
where is the spline approximation to in the sth simulation run. We report the average of the as in Table 2. For evaluating the estimation performances of the scatter matrix (corresponding to the bivariate responses) and the covariance matrix (for the random effects), we use the Frobenius-norm of the matrix of differences between the estimated and true values, i.e. , where is either or . Simulation results, together with the root of mean square error (RMSE) for and are listed in Table 2, where the RMSE for an arbitrary parameter is defined as . It is clear from Table 2 that the finite-sample performances of our proposed estimation procedures are satisfactory, with increasing sample sizes. In sum, the simulation results show that both index parameters, the non-parametric functions, and other parameters associated with the mixed effect models are reliably estimated, thereby confirming that our proposed algorithm works well in synthetic data settings.
Simulation 2: Assessing Robustness, in Light of Competing Methods
5.3
Here, the data is generated similar to Simulation 1 (from a BV-SIM), except that the random effects and errors are independently generated under the following four distributional assumptions:
Case 1: ;
Case 2: ;
Case 3: ;
Case 4: ,
for ,
Here, Case 1 corresponds to random effects and errors independently generated from the multivariate normal distribution. For Case 2, both are generated from the multivariate -distribution with degree of freedom (setting ). For Case 3, the random effects and errors are generated from the multivariate symmetric Laplace distribution with covariance matrix and , respectively. Finally, Case 4 corresponds to generating both the random terms (effects and errors) from multivariate normal mixtures. Note, for the above four cases, the bivariate clustered response is symmetric, since both the random effects and errors are generated from symmetric distributions. This is to make our approach comparable to the following two existing alternatives, (a) The bivariate normal mixed effect single-index model of Wu and Tu (2016), and (b) The bivariate mixed effect single-index model using the multivariate -distribution, which extends the univariate linear mixed model proposal of (Pinheiro et al. 2001). In (a), penalized splines were used to approximate the nonparametric index function, whereas we use polynomial splines. At each replication, we use the same dataset to obtain the estimates from these three competing methods. We focus on the estimation of the index parameters and the index functions for the fixed effect part, with the same interpretation for all cases.
The results are summarized in Table 3. For all cases, RMSEs and AIMSEs decrease quickly as the sample size increases for all three methods. That said, our proposed method performs well for all four cases, and is significantly better than both the alternatives for Cases 3 and 4. The advantages of our method appears more prominent if we further reduce the mixing proportion of the mixture distribution in Case 4 from 0.8 to or 0.5 (results not reported here). In Cases 1 and 2, the performances of our method is comparable to the two others. In particular, our method performs almost similar to Pinheiro’s -distribution method in Case 2 when , while they are both better than the normal mixed-effects method of Wu and Tu (2016). To summarize, the performance of our proposed method appears to be satisfactory in all cases, and is robust to misspecified (non-Gaussian) random effects and errors, under a bivariate mixed model framework.
Application: GAAD Dataset
6
In this section, we illustrate our method via application to the GAAD dataset. Here, the tooth-level mean PPD and CAL measures are non-Gaussian bivariate responses representing PD status, and our objective is to evaluate the distribution of PD status for this population, and quantify the effects of various subject-level covariates such as Age (in years), body mass index (BMI), Gender (1 = Female, 0 = Male), Smoking status (1 = Smoker, 0 = Never Smoker) and glycemic level or HbA1c (1 = High/Uncontrolled), 0 = Controlled) on the PD status. For our analysis, we have subjects with complete covariate information. About 30% of the subjects are smokers. The mean age of the subjects is about 54 years with a range from 26–87 years. There is a predominance of female subjects (around 76%) in the data. Around 60% of subjects are obese (BMI ≥ 30), and 59% are with uncontrolled HbA1c. Each subject has varying number of teeth, ranging from 3 to 28, with a total of 5461 observations. A full dentition will constitute 28 teeth, however, missing tooth is very common in any oral health studies, with the actual cause of missingness mostly unknown. Hence, in order to avoid unverifiable missing data assumptions, we did not resort to missing data analysis, and present only complete case analysis.
As part of explanatory analysis, we present the bivariate kernel density estimate of the PPD and CAL responses in Fig. 2 (left panel). The plot reveals significant (right) skewness for both responses. Also, the right panel in Fig. 2 indicates presence of possible outliers. Recent research (Zhao et al. 2018) confirmed possible non-linear relationship between oral health responses, and continuous covariates, like Age. Motivated by this, we set forward to estimate a clinically meaningful single-index structure determining PD for the subjects in this database.
We consider fitting the following model to the GAAD data
where with , , , and with , , . We further assume and . The estimates for index parameters, skewness parameter and their 95% confidence intervals are presented in Table 4, where the 95% confidence intervals are obtained by bootstrap resampling with 200 replications. We observe that all parameters (except corresponding to Gender for the PPD regression) were positive and significant. Interestingly, the estimate of Gender is negative yet significant for PPD, while, the corresponding estimate for CAL is positive and significant, implying that Gender is contributing to the index development for the two responses in opposite directions. Figure 3 presents the estimated curves corresponding to the two index functions, along with their 95% confidence bands using bootstrap method. Compared to the CAL, the 95% band is tighter for the PPD.
It is immediate that the correlation between PPD and CAL are significant, implying the need to account for the crosswise correlation between the two responses, and the cluster-wise correlation of the responses within the same subject, while modeling the bivariate clustered responses. Furthermore, Fig. 4 presents the bivariate kernel density surface of the estimated residuals (left panel), and the same from random draws of observations from the bivariate ALD density , where and are plugged-in estimates derived from our fit. We observe that the estimated surfaces are very similar, confirming the adequacy of model fit to the GAAD dataset.
Correlation matrices and are estimates as:
and
To further evaluate the usefulness of our proposed new model, we consider the fitted and prediction errors in light of two alternatives, denoted as “AM1” (bivariate normal, mixed effects SIM) and “AM2” (bivariate, asymmetric Laplace SIM, without random effects). We randomly partition the data into training and testing sets, where the training data is used to fit the 3 models, and the test data to evaluate the prediction errors. Using varying sizes of training and testing data, the average absolute fitted errors (AAFE), and the average absolute prediction errors (AAPE) for the two responses, based on 200 random partitions, are reported in Table 5, where
and
for , with , the fitted value based on training data, and , the predicted value based on the test data, and denote the number of subjects in the training data.
From Table 5, we observe that our model performs the best in terms of AAFE and AAPE, for various sizes of the training and testing set. More specifically, our proposed mixed-effects SIM model is superior to the bivariate asymmetric Laplace SIM (excluding random effects), implying the necessity to account for the within-subject correlation. Furthermore, our proposed model is also better than the SIM with the usual multivariate normal specification for the random effects, thereby providing evidence of the gain in accounting for data asymmetry during modeling.
Conclusions
7
Derivation of useful medical indices that correlate with multiple health outcomes is an issue of significant practical importance. In this paper, we propose a single-index mixed-effects regression model for bivariate responses, where both the error term and random effect are assumed to follow multivariate asymmetric Laplace distribution. By the polynomial spline smoothing for index functions, we proposed a scalable ML estimation method based on EM-type algorithm, and study the asymptotic properties of the ML estimates under some mild conditions. Simulations and real data analysis reveal the potential of the proposed model under data asymmetry, compared to existing alternatives.
There exists a number of future directions to pursue. To further improve model fit and prediction, we can consider the joint modeling of the location, skewness, and scatter matrix, within a multivariate ALD setup. When the number of covaiates is large in both fixed effects and random effects, it is of interest to select important variables in both parts to obtain a concise model. Some existing variable selection work of linear mixed effects model are available for univariate response case; see, for example, Kinney and Dunson (2010); Bondell et al. (2010); Fan and Li (2012); Schelldorfer and Geer (2011); Pan and Huang (2014), and others. However, for the case of single-index mixed effects models for multivariate responses, there is limited work, and pursuing the variable selection is a non-trivial journey. Another extension is to consider mixed effects quantile regression (Waldmann and Kneib 2015) for bivariate responses. These will be pursued elsewhere.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Anderson TW (1984) An introduction to multivariate statistical analysis. John Wiley & Sons, USA
- 2Azzalini A (2010) The skew-normal distribution and related multivariate families. Scand J Stat 32:159–188
- 3Azzalini A, Capitanio A (1999) Statistical applications of the multivariate skew normal distribution. J Roy Stat Soc 61:579–602
- 4Azzalini A, Capitanio A (2003) Distributions generated by perturbation of symmetry with emphasis on a multivariate skew t-distribution. J R Stat Soc Series B (Stat Methodol) 65:367–389
- 5Bandyopadhyay D, Lachos VH, Abanto-Valle CA, Ghosh P (2010) Linear mixed models for skew-normal/independent bivariate responses with an application to periodontal disease. Stat Med 29:2643–265520740568 10.1002/sim.4031 PMC 2962692 · doi ↗ · pubmed ↗
- 6Bondell HD, Krishna A, Ghosh SK (2010) Joint variable selection for fixed and random effects in linear mixed-effects models. Biometrics 66:1069–107720163404 10.1111/j.1541-0420.2010.01391.x PMC 2895687 · doi ↗ · pubmed ↗
- 7Bouveyron C, Brunet-Saumard C (2014) Model-based clustering of high-dimensional data: a review. Comput Stat Data Anal 71:52–78
- 8Cui X, Haerdle WK, Zhu L (2011) The EFM approach for single-index models. Ann Stat 39:1658–1688