Single-Molecule Mixture: A Concept in Polymer Science
Yu Tang

TL;DR
This paper explores the concept of single-molecule mixtures in polymers, showing they may exist in real systems.
Contribution
The study introduces a theoretical framework for the existence of single-molecule mixtures in polymer systems.
Findings
Model construction and analysis support the existence of single-molecule mixtures.
Results suggest these mixtures could occur in synthetic or natural polymer systems.
Theoretical evidence aligns with the chemical space concept in polymer science.
Abstract
In theory, two extreme forms of substances exist: the pure form and the single-molecule mixture form. The latter contains a mixture of molecules with molecularly different structures. Inspired by the “chemical space” concept, in this paper, I report a study of the single-molecule mixture state that combines model construction and mathematical analysis, obtaining some interesting results. These results provide theoretical evidence that the single-molecule mixture state may indeed exist in realistic synthetic or natural polymer systems.
Click any figure to enlarge with its caption.
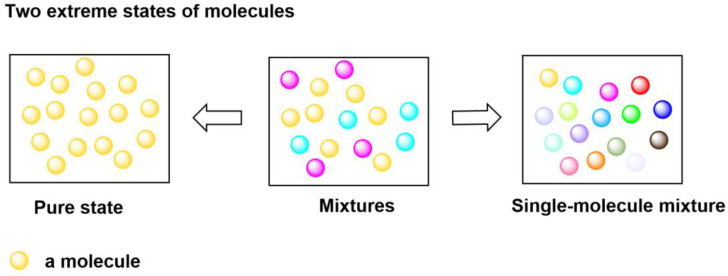 Figure 1
Figure 1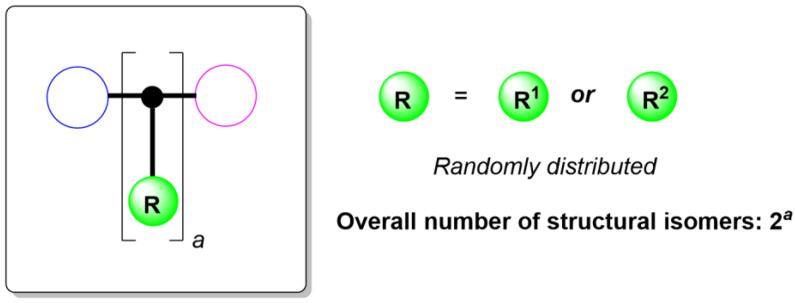 Figure 2
Figure 2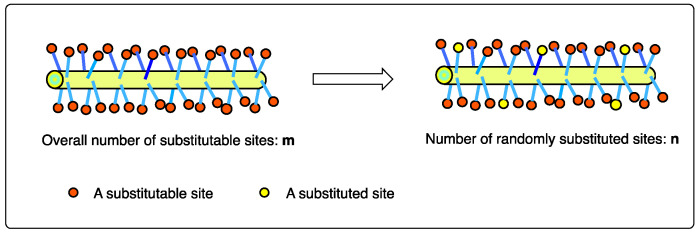 Figure 3
Figure 3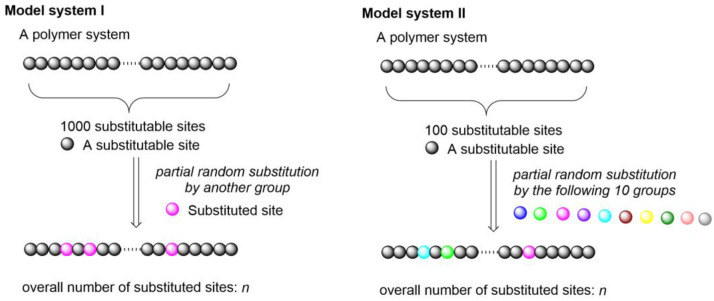 Figure 4
Figure 4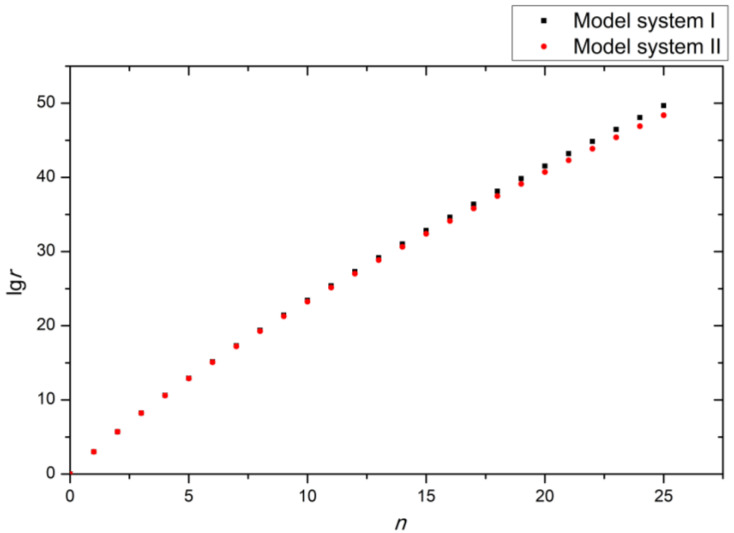 Figure 5
Figure 5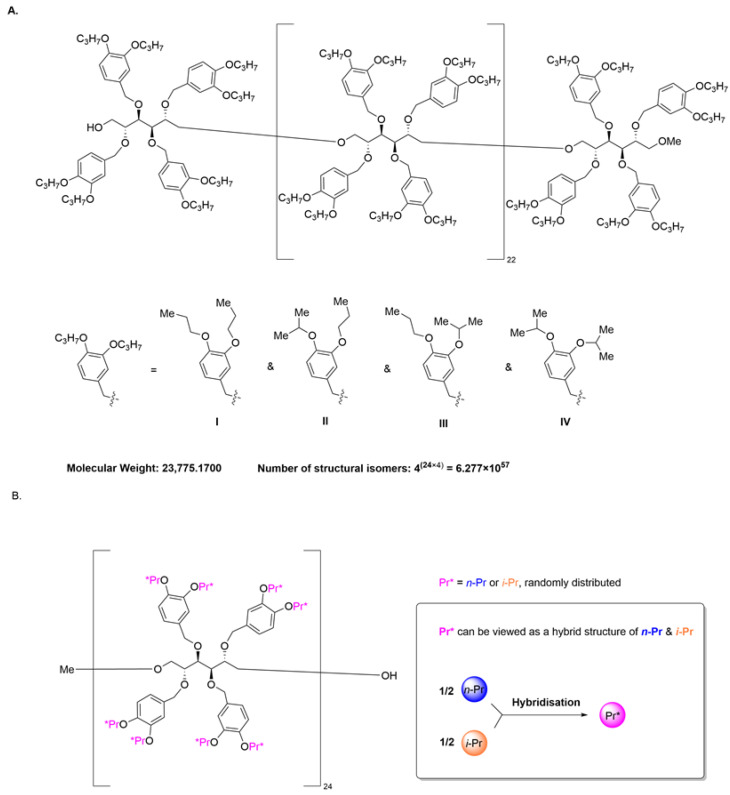 Figure 6
Figure 6- —Youth Innovation Promotion Association of CAS
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsComputational Drug Discovery Methods · Advanced Polymer Synthesis and Characterization · Various Chemistry Research Topics
1. Introduction
Realistic substances always contain a mixture of molecules, and, in theory, two extreme forms of substances—a pure form and a single-molecule mixture form—exist, as shown in Figure 1. The former contains only one kind of molecule, while the latter comprises a mixture of molecules with molecularly different structures. To the best of my knowledge, this elusive molecular form has not yet been explored in the literature. When considering a “single-molecule mixture”, two interesting questions arise: (1) Do “single-molecule mixture”-state molecules exist in nature or synthetic systems? (2) Is there any possible way to synthesize “single-molecule mixture”-state molecules? To explore these questions, I have herein attempted to establish a theoretical approach, combining model construction and mathematical analysis, to study this molecular state and provide theoretical evidence supporting the conclusion that these mixtures may indeed be widely distributed in nature or in synthetic polymer systems. In addition, a possible synthetic route to “single-molecule mixture”-state molecules has also been provided.
Since the beginning of the 21st century, the concept of “chemical space” has gradually attracted the attention of the scientific community [1,2,3,4]. Chemical space—encompassing all possible small organic molecules, including those present in biological systems—is extremely vast. For example, Dobson^1^ estimated that, seeing as there are 20 different amino acid types and the average natural protein comprises about 300 residues, the overall number of possible isomers is a staggering 20^300^, or even more than 10^390^, and, if a single molecule of each of these polypeptides were to be produced, the combined mass would vastly exceed that of the known universe. Inspired by these remarkable results, I envisioned that, if I first constructed a model polymer space containing an extreme number of possible isomers and then (randomly) synthesized molecules with only a tiny fraction of this space’s structures, I would have a very high probability of obtaining a “single-molecule mixture”-state molecule. This consideration constitutes the basic design principle of the current study.
2. Results and Discussion
To start this exploration, a model polymer molecule system is first constructed, as illustrated in Figure 2, where the overall number of substitutable sites is a, and each site is randomly substituted by one of the two possible groups, R^1^ or R^2^. Thus, the overall number of structural isomers in this polymer space is 2*^a^*, exponentially increasing as a increases. For example, if a = 200, then the overall number of isomers in this space is 2^200^—namely, 1.60693804 × 10^60^.
A very interesting question arises: if I were to take a given number (n) of structures from the above structural space (overall number of structures = m) individually and randomly (meaning that the same structure may be taken more than once), how would I calculate the probability (P) of obtaining a single-molecule mixture (where each structure is different)?
This problem can be solved by calculating probability.
Then, one can use Bernoulli’s inequality to approximate (1 + )^n^ as follows:
In this case, I chose n = NA (6.02 × 10^23^) as the given number of molecules taken from the structural space and a = 200 as the number of substitutional sites in the polymer model system (thus, m = 2^200^ = 1.60693804 × 10^60^). As a result, the probability (P) of obtaining a single-molecule mixture is the following:
This result reveals that, if we were to individually and randomly take n = NA (6.02 × 10^23^) molecules from this model structure space (a = 200, m = 1.60693804 × 10^60^), the probabilities (P) of obtaining single-molecule mixtures would be close to 1.
According to Equation (1), the relationship between P and m is
From Equation (2), we can estimate that for a given P, the minimum number of structural isomers m in the model structure space should exceed n + n^2^ .
It has been noted that, in many realistic synthetic polymer systems and natural biopolymer systems, the partial random substitution of the parent molecule by a few substituent groups frequently occurs, such as in the polymer bromination process [5,6] (random partial substitution of the hydrogen atom by a bromine atom), many other post-polymerization modification processes [7,8,9,10,11,12,13,14,15], and the DNA [16] and protein methylation processes (random partial substitution of the hydrogen atom by a methyl group) [17,18], as illustrated in Figure 3 and Figure S1. This substitution process generates a large number of isomers with equal probabilities. In order to calculate the exact number of potential isomers, I constructed two additional model systems, as illustrated in Figure 4.
If the overall number of substitutable sites in the parent molecule is m, that of the substituted sites is n, and that of the possible substitute groups in each randomly substituted site is s, then the overall number of potential isomers from this structural space r can be calculated as follows:
In model system I, I chose m = 1000 and s = 1, implying that the parent molecule contained 1000 substitutable sites. If a few of these sites are randomly substituted by another group (R^0^ → R^1^), the overall number of potential isomers can be calculated as follows:
In model system II, I chose m = 100 and s = 10, implying that the parent molecule contains 100 substitutable sites. If a few of these sites are randomly substituted by one of the ten possible R groups [R^0^ → (R^1 to 10^)], the overall number of potential isomers can be calculated as follows:
The calculated overall numbers of potential isomers (r) (n = 0–25) are listed in Tables S1 and S2, and the relationship between lgr and n is depicted in Figure 5.
From Figure 5, we can see that, for these two model systems, the overall number of potential isomers exponentially increases alongside the number of substituted sites. If n = 25, then the overall number of potential isomers is 4.76 × 10^49^ and 2.43 × 10^48^ for model systems I and II, respectively. According to Equation (1), when taking 1 mmol (6.02 × 10^20^) molecules from these two structural spaces, the probability (P1 and P2 for model systems I and II, respectively) of obtaining a single-molecule mixture is the following:
These calculated results indicate that these two probability values are sufficiently large for single-molecule mixtures to exist at millimole-scale levels.
According to Equation (2), we can estimate that if we take 1 mmol (6.02 × 10^20^) molecules from a structural space, the probability of obtaining a single-molecule mixture state exceeds 0.999; thus, the minimum number of structural isomers r in the model structure space should exceed n + n^2^ ≈ 3.62404 × 10^44^; this value is significantly smaller than the actual isomer numbers of the above two spaces.
Thus, we can conclude that, if a polymer molecule contains 1000 substitutable sites and 2.5% of these sites are randomly substituted by another group, the potential isomers exceed 4.76 × 10^49^, and, if this substitution process proceeds at a millimole scale, then the products most likely exist in a single-molecule mixture state.
Finally, to better illustrate the structural features of single-molecule mixture-state polymers, a 24 mer O-propyl-substituted D-mannitol model system was built, as illustrated in Figure 6A (A possible synthetic route toward this 24 mer was provided in Supporting Information. see Figure S2). This system contained 192 phenolic hydroxyl groups, randomly substituted by the n-propyl or i-propyl group. This system’s molecular weight was 23,775.1700 Da, and the number of structural isomers was 2^192^—namely, 6.277 × 10^57^. According to Equation (1), even if we were to prepare this polymer at a 100 mol scale (ton-scales), the probability (P) of obtaining a single-molecule mixture would be the following:
In this model system, even though each molecular structure was different, as the R group in each substitute site varied, they all came randomly from the same structural space, inspired by the concept of orbital hybridization [19,20,21,22]. If we were to define Pr* as a hybrid structure of n-Pr and i-Pr, then this polymer system could be viewed as a “pure substance system”, in that each phenolic hydroxyl group would be substituted by an unprecedented, hybridized Pr* group, as illustrated in Figure 6B. Thus, certain physical proprieties of this polymer system would be expected, to some extent, to be similar to those of a pure substance system. However, the impact of the single-molecule state on the physical, chemical, and biological properties of natural and synthetic polymers remains a subject of further research.
3. Materials and Methods
The work depicted in this paper is a theoretical research that combines model construction, mathematical analysis, and thought experiments. Model construction was performed using ChemOffice software (PerkinElmer ChemOffice 2020–Version 20.0), probability approximation was performed using Bernoulli’s inequality, detailed calculation was performed on a household computer using free online scientific calculator (Desmos, https://www.desmos.com/scientific?lang=zh-CN, accessed on 8 July 2024).
4. Conclusions
In summary, single-molecule mixtures, opposite to the “absolute pure” extreme molecular state, were theoretically studied by combining model construction and mathematical analysis, obtaining some interesting results. These results support the conclusion that the single-molecule mixture state may be widely distributed in realistic synthetic or natural polymer systems.
Chemical microheterogeneity—the quality of being heterogenous at the microscopic level—is an attribute of all living systems and most soft and crystalline materials [23,24]. According to a recent classification by Gentili et al. [23], natural and synthetic polymer systems are one of the five major sets of microheterogeneous systems. While it has long been recognized that microheterogeneity exerts a major influence on the function of biopolymers such as glycoproteins [25], the concept of a “single-molecule mixture” and the results of the current study shall provide a unique way of understanding “microheterogeneity” at the molecular level. It is hoped that this study will inspire further exploration of this intriguing area.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Dobson C.M. Chemical space and biology Nature 200443282482810.1038/nature 0319215602547 · doi ↗ · pubmed ↗
- 2Reymond J.-L. The Chemical Space Project Acc. Chem. Res.20154872273010.1021/ar 500432 k 25687211 · doi ↗ · pubmed ↗
- 3Llanos E.J. Leal W. Luu D.H. Jost J. Stadler P.F. Restrepo G. Exploration of the chemical space and its three historical regimes Proc. Natl. Acad. Sci. USA 2019116126601266510.1073/pnas.181603911631186353 PMC 6600933 · doi ↗ · pubmed ↗
- 4Liu Y. Mathis C. Bajczyk M.D. Marshall S.M. Wilbraham L. Cronin L. Exploring and mapping chemical space with molecular assembly trees Sci. Adv.20217 eabj 246510.1126/sciadv.abj 246534559562 PMC 8462901 · doi ↗ · pubmed ↗
- 5Semler J.J. Jhon K. Tonelli A. Beevers M. Krishnamoorti R. Genzer J. Facile Method of Controlling Monomer Sequence Distributions in Random Copolymers Adv. Mater.2007192877288310.1002/adma.200602359 · doi ↗
- 6Noble K.F. Noble A.M. Talley S.J. Moore R.B. Blocky bromination of syndiotactic polystyrene via post-polymerization functionalization in the heterogeneous gel state Polym. Chem.201895095510610.1039/C 8PY 01008 K · doi ↗
- 7Boaen N.K. Hillmyer M.A. Post-Polymerization Functionalization of Polyolefins Chem. Soc. Rev.20053426727510.1039/b 311405 h 15726162 · doi ↗ · pubmed ↗
- 8Gauthier M.A. Gibson M.I. Klok H. Synthesis of Functional Polymers by Post-Polymerization Modification Angew. Chem. Int. Ed.200948485810.1002/anie.20080195119040233 · doi ↗ · pubmed ↗