Efficient and Flexible Method for Reducing Moderate-Size Deep Neural Networks with Condensation
Tianyi Chen, Zhi-Qin John Xu

TL;DR
This paper introduces a method to shrink moderate-sized neural networks while keeping their performance, using a phenomenon called condensation.
Contribution
A novel condensation-based reduction method is proposed for both fully connected and convolutional networks.
Findings
The method reduced network size to 41.7% in combustion tasks without losing accuracy.
In image classification, network size was reduced to 11.5% with satisfactory accuracy.
The approach is broadly applicable to most trained neural networks.
Abstract
Neural networks have been extensively applied to a variety of tasks, achieving astounding results. Applying neural networks in the scientific field is an important research direction that is gaining increasing attention. In scientific applications, the scale of neural networks is generally moderate size, mainly to ensure the speed of inference during application. Additionally, comparing neural networks to traditional algorithms in scientific applications is inevitable. These applications often require rapid computations, making the reduction in neural network sizes increasingly important. Existing work has found that the powerful capabilities of neural networks are primarily due to their nonlinearity. Theoretical work has discovered that under strong nonlinearity, neurons in the same layer tend to behave similarly, a phenomenon known as condensation. Condensation offers an opportunity…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
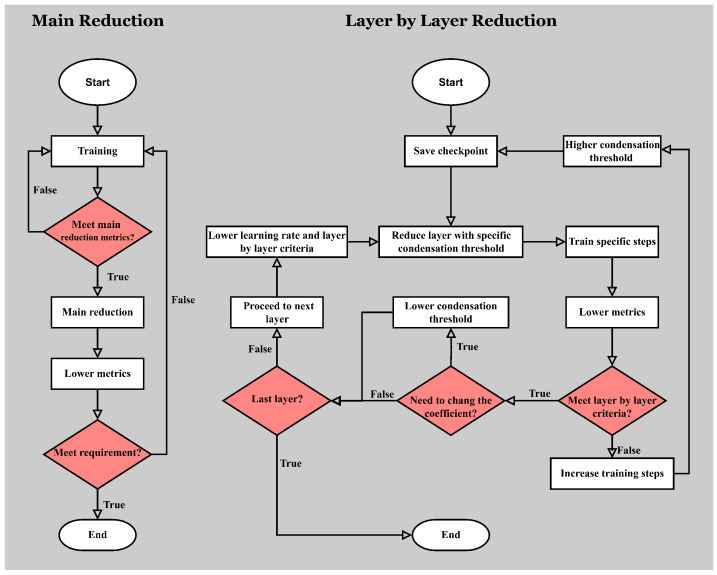 Figure 1
Figure 1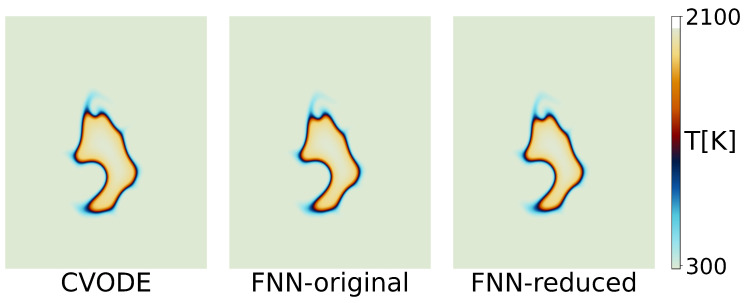 Figure 2
Figure 2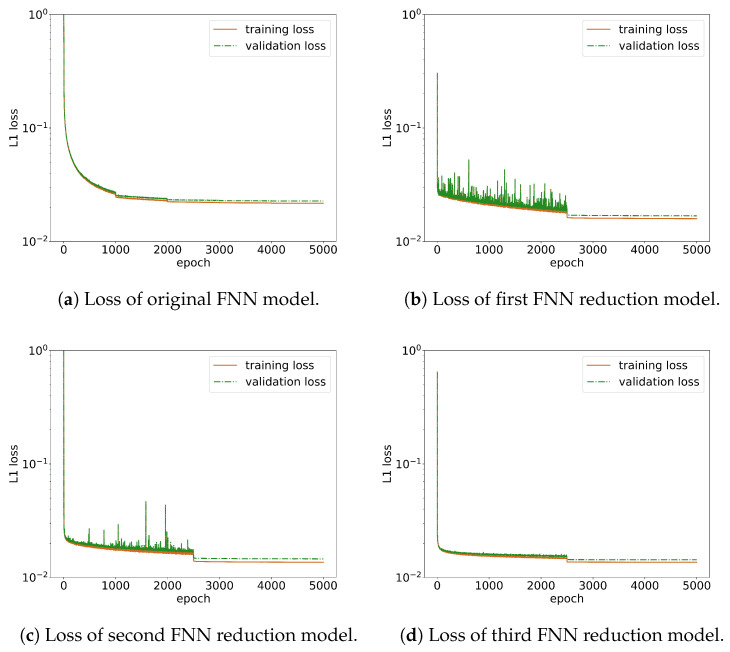 Figure 3
Figure 3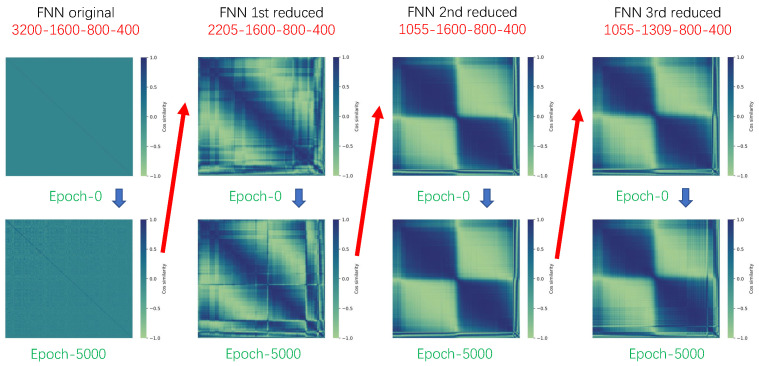 Figure 4
Figure 4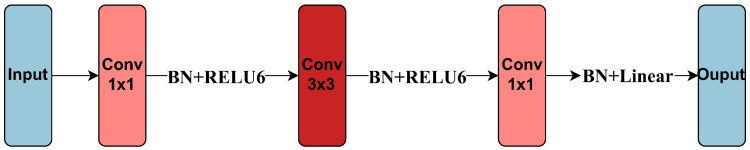 Figure 5
Figure 5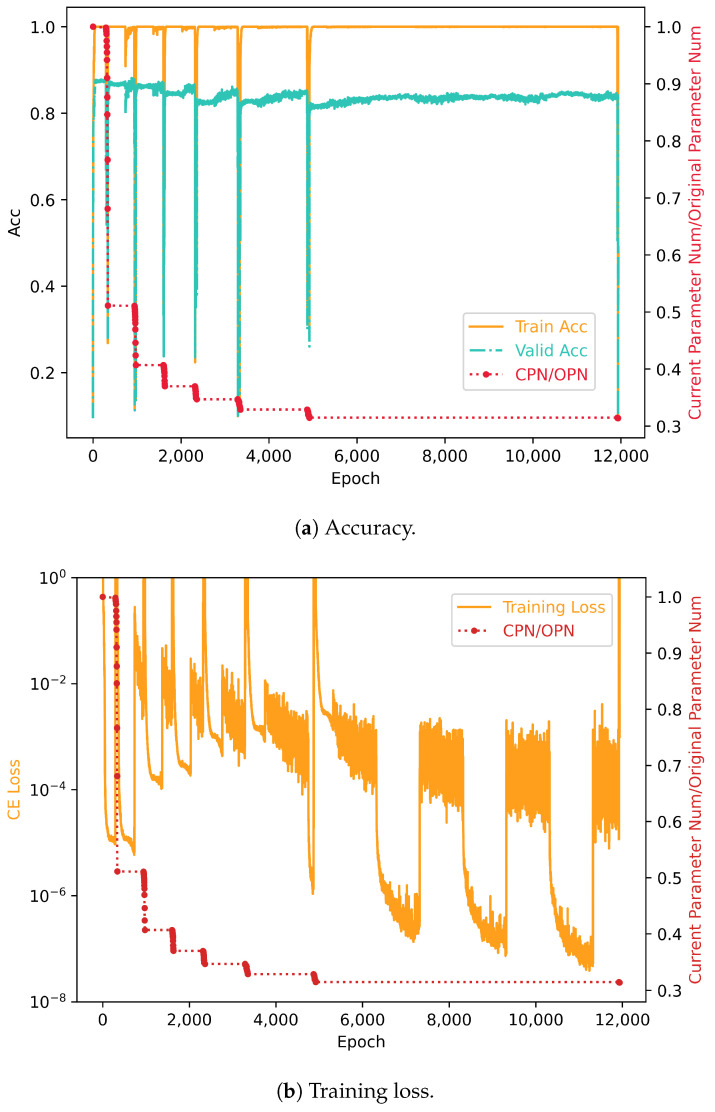 Figure 6
Figure 6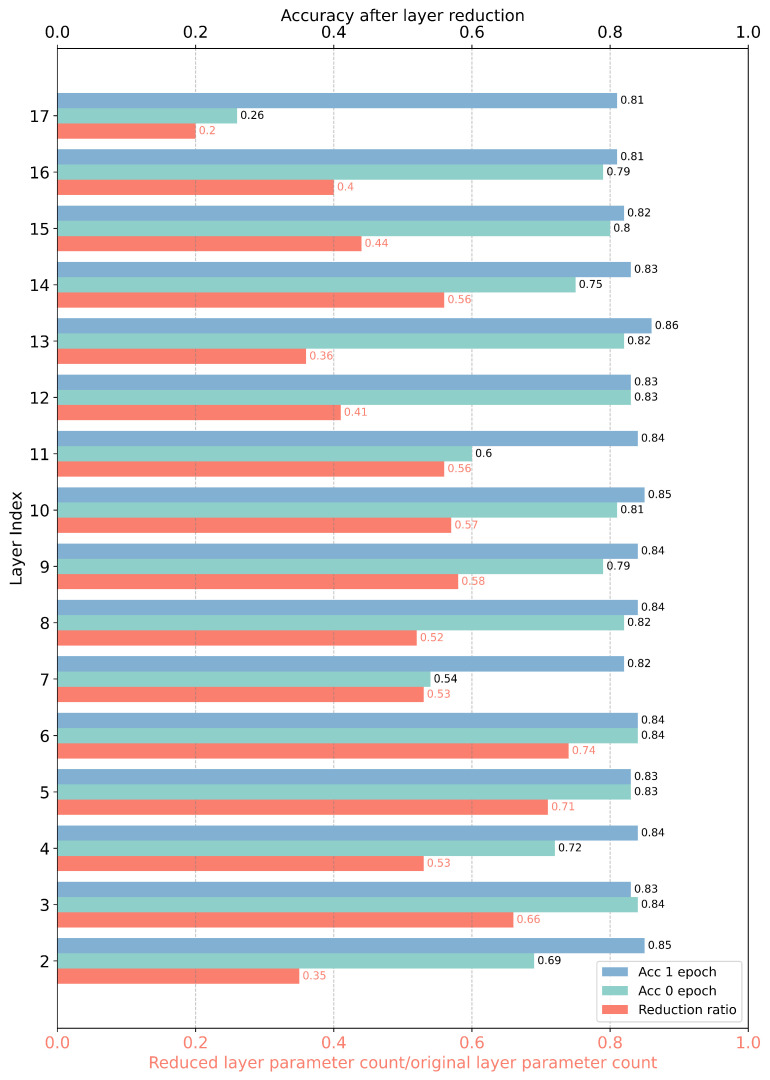 Figure 7
Figure 7- —National Key R&D Program of China
- —Natural Science Foundation of Shanghai
- —National Natural Science Foundation of China
- —Shanghai Municipal of Science and Technology Major
- —HPC of School of Mathematical Sciences and the Student Innovation Center
- —Siyuan-1 cluster supported by the Center for High Performance Computing at Shanghai Jiao Tong University
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsAdversarial Robustness in Machine Learning · Machine Learning in Materials Science · Anomaly Detection Techniques and Applications
1. Introduction
Neural networks have achieved globally astounding results, demonstrating an exceptional performance across a range of tasks in scientific fields including biology, medicine, astronomy, environmental science, physics, chemistry, etc. [1,2,3,4,5,6]. Serving as a novel numerical solution tool, neural networks have been effectively applied in solving partial differential equations within various domains [7,8,9,10]. Neural networks can learn multiscale models from data by designing appropriate network structures and sampling methods, offering insights into these intricate systems [11].
Currently, the scale of neural networks applied in the scientific field is generally moderate size [7]. Compared to the industrial and internet sectors, obtaining experimental data in the scientific field often incurs high costs, resulting in significantly fewer data samples available for neural network training [7]. This limitation in sample size restricts the scale of networks that can be trained. In addition, training large-scale neural networks requires expensive computational resources. The computing conditions in academia generally lag behind those in the industrial sector, making it challenging to support the training and inference of overly large neural network models.
Reducing the scale of neural networks applied in the scientific field holds significant importance [12,13]. Many traditional numerical algorithms, such as multigrid methods and fast Fourier transforms, exhibit quasi-linear or even linear time complexity, boasting an extremely high computational efficiency [14]. When applying neural networks to time-sensitive scientific computing tasks, it is crucial to reduce the network size to enhance its inference speed [11]. Additionally, many scientific applications require deploying models in resource-constrained environments, such as embedded systems, mobile devices, and sensors [15,16]. The computational power of these deployment platforms often falls far short of the platforms used for the original training of the tasks. Therefore, it is essential to reduce the network size as much as possible while maintaining the performance of the original network model, enabling efficient deployment in these contexts.
Nonlinearity is the fundamental characteristic that endows neural networks with their powerful expressive, learning, and generative capacities [17]. Nonlinear activation functions grant neural networks the ability to learn complex patterns, enabling neurons to model complex nonlinear relationships and approximate any continuous function with arbitrary precision. The superposition of multiple layers of nonlinear transformations allows neural networks to construct highly nonlinear decision boundaries and learn complex nonlinear mappings between inputs and outputs. Theoretical findings indicate that in the presence of strong nonlinearity within neural networks, neurons in the same layer tend to exhibit a condensation phenomenon, known as condensation [17]. Condensation refers to the gradual alignment of the direction of neurons’ parameter vectors during the training process, implying a uniform preference for the inputs from the previous layer. This phenomenon is prevalent across various neural network architectures, suggesting that condensed neurons function similarly, or are nearly equivalent to a single neuron. Condensation implies the presence of a large number of similar neurons in neural networks, indicating that the structural complexity of neural networks may not be as high as it appears. When the network reaches an extreme point, the condensation phenomenon becomes more pronounced. In this case, the embedding principle suggests that the extreme point reached by the network is actually an extreme point of one of its subnetworks [18].
Based on the above idea, we propose the condensation reduction method to validate existing theories. The main contribution of this paper is the successful validation of the universality of the condensation phenomenon and the applicability of the embedding principle in practical applications through the condensation reduction method. The use of the condensation reduction method requires a pretrained network, which could be considered a drawback. However, this limitation might be quite common, as seen in the work related to the “Lottery Ticket Hypothesis” [19].
From the perspective of reduction algorithms, our method can be approximated as a pruning method. The key difference is that our approach merges branches instead of merely removing redundant ones. The work by Liu et al. [20] proposed a network condensation method, but their definition of condensation differs from ours. In their work, the term “condense” is primarily used as a verb to denote operations such as simplifying, refining, and compressing the network. However, in this study, “condensation” is defined as a significant phenomenon commonly observed during neural network training and can be directly observed using cosine similarity. Most pruning methods measure the importance of parameters based on certain metrics and remove the less important ones [21], which can be either structured or unstructured. These metrics usually include parameter norms, impact on loss, and sensitivity [22,23,24].
In contrast, our condensation reduction method is a structured network reduction approach. Unlike structured pruning, we do not delete neurons or parameters based on metrics. Instead, we merge neurons based on their similarity (degree of condensation). Merging neurons involves deleting redundant neurons and modifying the parameters of the retained neurons, ensuring that the merged neurons have similar expressive capabilities as before. In the following sections, we prove the consistency of the neural network’s output before and after the merger under strict conditions.
By leveraging the condensation phenomenon for neural network reduction, we aim to strike a balance between model performance and model size to identify an appropriate subnet. Utilizing the embedding principle, we understand that when a neural network reaches an extremum, it is likely at an extremum of a smaller subnet, making the neural network approximately equivalent to this subnet [18]. At this point, we merge neurons that have condensed into a single neuron, resulting in a subnet of the original network and thereby achieving a reduction in the neural network’s scale. The reduction based on the condensation phenomenon requires only the calculation of angles between neurons, making the time required for each reduction negligible compared to the training time. Owing to the universality of the condensation phenomenon, our reduction algorithm can be broadly applied to various types of models.
We are currently capable of reducing two major categories of neural networks: fully connected neural networks (FNNs) and convolutional neural networks (CNNs), achieving promising results. We selected two representative tasks for model reduction: fitting and classification. The fitting task involved neural network acceleration for combustion simulation, while the classification task focused on image classification on the CIFAR10 dataset, corresponding to fully connected neural networks and convolutional neural networks, respectively. In the acceleration of the combustion simulation, we reduced the original model to 40.9% of its parameter count, maintaining consistency in both zero-dimensional and one-dimensional combustion simulations with the original model, and observed virtually no difference in complex turbulent flame simulations. For the CIFAR10 image classification task, we reduced the model to 11.5% of its original parameter count, with the classification accuracy dropping only to 94% of the original accuracy.
The rest of the article is organized as follows: The second part, Materials and Methods, introduces the concept of condensation and the details of condensation reduction. The third part, Results, presents the outcomes of condensation reduction in combustion tasks and CIFAR10 image classification tasks. The fourth part, Discussion, provides a discussion on the results and methods.
2. Materials and Methods
2.1. Condensation Reduction in FNN
2.1.1. FNN
Consider an -layer fully connected neural network with a structure of
where is the width of the i-th hidden layer. The neural network can be defined as
where consists of both the weight matrix and bias vector, and is the activation function. The parameter matrix of the i-th layer of the neural network is
wherein is the t-th neuron in the i-th layer.
2.1.2. Cosine Similarity
We define the cosine similarity between the i-th layer neurons as
When considering neurons as vectors, if the cosine similarity between them is very close to 1, their directions are very similar, indicating that these two neurons are highly similar. The calculation of the cosine similarity is straightforward. Furthermore, in the following section, we will demonstrate that when the cosine similarity is exactly 1, the functions expressed by the original network and the reduced network are consistent.
2.1.3. Condensation of FNN
Consider a neural network with a single hidden layer, whose activation function satisfies homogeneity, i.e., satisfies
The ReLU activation function is an activation function that satisfies homogeneity.
If the directions of the p-th and q-th neurons are the same, i.e, when the cosine similarity is 1, we have
The neural network at this point can be represented as
At this point, the function expression of the neural network is completely identical to the new neural network formed by merging neurons p and q. This means that neuron p and neuron q are equivalent to a single neuron at this moment. The above derivation can be generalized to any fully connected neural network of arbitrary depth that meets the criteria of homogeneity.
2.1.4. Condensation Reduction
Leveraging the phenomenon of condensation for reduction involves merging neurons that have condensed into a single neuron. Determining whether two neurons have condensed is a matter of judging whether their directions are similar. Thus, we only need to artificially set a threshold for the cosine similarity. When the cosine similarity between two neurons exceeds this threshold, they are considered to have condensed. We will henceforth refer to the cosine similarity threshold as the condensation threshold.
To perform a condensation-based reduction, we first need to obtain the cosine similarity among neurons in the l-th layer targeted for reduction. By utilizing the formula for cosine similarity, we can easily calculate it using the parameter matrix of that layer of the neural network, specifically:
wherein
After obtaining the cosine similarities among neurons, we need to group neurons that have condensed together. In each grouping session, given the condensation threshold, we calculate the number of neurons that have condensed with each ungrouped neuron. Subsequently, we select the neuron with the highest number of condensed neurons as the main neuron for that group.
After grouping all neurons, the next step is to merge the condensed neurons. We merge all neurons in each group toward the main neuron of that group. Let us assume, for simplicity, that the first N neurons are classified into one group. Then, we have
wherein
The new neural network parameter matrix obtained is
By using the new neural network parameter matrix, we can create a new neural network, thus completing the condensation-based reduction process.
2.2. Condensation Reduction in CNN
2.2.1. CNN
Convolutional neural networks can be understood as fully connected neural networks with shared weights. Therefore, all the definitions related to fully connected networks mentioned above can naturally be extended to apply to CNNs as well.
Consider a neural network that contains only convolutional layers and fully connected layers; its structure is as follows:
wherein
wherein and are the dimensions of the input channel and output channel of the i-th layer, respectively, and is the size of the convolution kernel. We view the i-th convolutional layer as containing outchannel neurons, each neuron being a convolutional kernel, represented by a vector as follows:
The parameter matrix of this layer can be represented as
Corresponding to the small data processed by each convolution kernel, a layer of convolution operations can be represented as
Then, we calculate the cosine similarity between neurons according to the previous definition.
2.2.2. Condensation of CNN
Similar to fully connected neural networks, when there are two neurons in a convolutional layer with the same orientation, the function represented by the network is completely identical to the function represented by the new network after merging the two neurons. Refer to Appendix A.1 for proof details. Therefore, for convolutional neural networks, the phenomenon of condensation will be consistent with that of fully connected networks, thereby reducing the complexity of the model.
2.2.3. Condensation Reduction
The traditional definition of condensation reduction in convolutional neural networks, following the above derivation, is completely identical to that in fully connected networks. It simply requires unfolding each convolutional layer into a matrix composed of convolutional kernel parameters, specifically:
Thus, the corresponding cosine similarity matrix can be calculated according to the previous definition. Afterward, the neurons that have condensed are grouped in the exact same manner as during the condensation reduction of fully connected networks. Subsequently, neurons belonging to the same group are merged into a single neuron.
When the layer following the condensation-reduced layer is a fully connected layer, the process of obtaining new network parameters is entirely the same as during the condensation reduction of fully connected networks. When the layer following the condensation-reduced layer is a convolutional layer, the situation is, in fact, consistent with that of fully connected networks; details are shown in Appendix A.2.
The concept of condensation reduction can indeed be extended to various types of convolutional layers, such as depthwise separable convolutions, achieving satisfactory application results. Taking the structure of MobileNetV2 as an example, a complete module within MobileNetV2 consists of a sequence that includes a pointwise convolution followed by batch normalization and a ReLU6 activation function; a depthwise convolution followed by batch normalization and a ReLU6 activation function; and another pointwise convolution followed by batch normalization and a linear activation function [25]. In such a complete module, the depthwise convolution layer plays a primary role, while the pointwise convolution layers mainly serve to expand and reduce dimensions. Therefore, condensation reduction is applied only to the depthwise layer. Due to the characteristics of the complete module, reducing the depthwise layer accordingly reduces the size of the adjacent pointwise layers. The details of derivation for the depthwise separable convolutions are shown in Appendix A.3.
2.3. Manual Condensation Reduction and Automatic Condensation Reduction
2.3.1. Manual Condensation Reduction
In the face of complex application scenarios, neural networks can present challenging metrics that are intricate, time-consuming, or require subjective judgment by supervisors. In such cases, it is necessary to pause and conduct model testing each time a reduced model is obtained. Manual condensation reduction is primarily employed in these situations.
Manual condensation reduction involves reducing a neural network layer by layer after achieving a neural network that meets performance standards. This approach ensures that the neural network does not deviate significantly due to a single reduction. Each manual condensation reduction requires setting a condensation threshold. The appropriate threshold is determined by observing changes in the loss before and after reduction. If the loss increases significantly after reduction, the condensation threshold is raised; if the loss is too small, the threshold is lowered. If the neural network’s performance meets the requirements after a certain amount of training post-reduction, further reduction is performed; otherwise, the condensation threshold is increased, and the process is repeated. This cycle continues until an appropriately sized subnet is obtained. An appropriate subnet must meet two criteria: first, it must achieve the set performance metrics, such as accuracy in combustion simulation predictions. Secondly, the neural network parameters should be difficult to reduce further, indicating that the number of neurons condensing together is scarce or that even slight reductions significantly impact the network’s performance.
2.3.2. Automatic Condensation Reduction
The main steps of automatic condensation reduction are consistent with manual condensation reduction, except that the reduction process does not require manual control. Automatic condensation reduction is mainly used in scenarios with clear neural network performance metrics and where testing is convenient and rapid, such as using validation accuracy to assess performance in image classification problems. The process of automatic condensation reduction is shown in Figure 1.
The main flow of automatic condensation reduction begins with training the original model and periodically testing its performance. Once the test meets the main reduction criteria, main reduction is carried out. After the main reduction, the reduced model continues training until it meets the main reduction criteria again, and this cycle repeats until the model reduction reaches the anticipated extent. After each main reduction, the criteria for the next main reduction are slightly lowered because reduction inevitably affects the network’s performance. Keeping the same criteria would make the reduction cycle very slow or even impossible, wasting a lot of time on model training.
Main reduction involves sequentially reducing each layer of the model. Before each layer-by-layer reduction, the model’s relevant data are saved, creating a save point, followed by the reduction. For each layer to be reduced, a specific condensation threshold is applied during its reduction. After reducing a layer, a specific number of training steps are performed, the same for each layer. Upon completion, the model is automatically tested to see if it meets the layer-by-layer reduction criteria, which are generally lower than the main reduction criteria to expedite the overall main reduction process. If the model meets the layer-by-layer criteria and the current layer is not the last to be reduced, reduction proceeds to the next layer. Simultaneously, the layer-by-layer criteria are lowered, as is the initial learning rate for the next reduction. Specifically, if the model’s parameters have hardly decreased after a reduction, the specific layer’s condensation threshold is lowered for a more aggressive reduction next time. If the model does not meet the layer-by-layer criteria, it reverts to the previous save point to restart reduction. Simultaneously, the specific training steps for layer-by-layer reduction increase, and the specific condensation threshold for that layer is raised. This aims to improve model performance by extending the training time for the reduced model to recover performance and by performing stricter condensation reduction, as a higher condensation threshold means neurons deemed for condensation are more directionally aligned, thus reducing error upon merging. Since the condensation threshold can be adjusted up to 1, where the model remains unchanged, such layer-by-layer reduction can always be completed. When the last layer’s reduction is finished, the main reduction concludes.
Automatic condensation reduction merely requires setting initial values for the algorithm beforehand. Aside from the main and layer-by-layer reduction criteria, the quality of other initial values does not sensitively affect the final reduction outcome, as the key condensation threshold can be automatically adjusted. However, excessively deviated initial values will waste considerable time on model training. Before using the automatic reduction algorithm, it is advisable to make reasonable estimates based on the training process of the model to be reduced. The main reduction criteria are mainly based on the highest performance of the model to be reduced and the minimum performance requirements of the reduced model. The automatic reduction algorithm ensures these criteria are met, obtaining a subnetwork that is appropriately sized between the minimal subnetwork that retains structure and the original network.
3. Results
3.1. Acceleration for Combustion Simulation
3.1.1. Background on Task
Numerical simulation is indispensable in both scientific research and industrial production. In problems involving various multiscale dynamic systems, such as combustion, numerical simulation requires solving high-dimensional stiff ordinary differential equations, whereas traditional numerical solution methods often require very small time steps, as in [11]. Moreover, in numerical simulations of combustion, the direct integration of chemical reactions required by traditional methods is time-consuming [11]. It has been proven reasonable and efficient to use neural networks to replace traditional numerical solution methods. Neural networks, by fitting state mapping functions, can map the current state of a system to the state of the system at the next time step. This method can be applied with larger time steps and replaces the time-consuming chemical reaction calculation process with the rapid inference process of neural networks [11].
The simulation of combustion requires integrating computational fluid dynamics (CFD) with chemical reactions. In this task, a fully connected neural network computes the rate of change of chemical substances as source terms for the CFD. The CFD code used is EBI [26], and the chemical mechanism employed is the drm19 mechanism for methane, which involves 21 components and 84 reactions. In the depicted turbulent ignition test, as shown in Figure 2, a computational domain of 1.5 cm × 1.5 cm is set with 512 × 512 cells. The velocity field is generated using the Passot–Pouquet isotropic kinetic energy spectrum. The initial conditions are set at , , and . An ignition round is placed at the center of the domain, with a radius of 0.4 mm. Figure 2 compares the results at 1ms simulated using the fully connected neural network and CVODE, both utilizing EBI. For more details, please refer to the original text [11].
The task at hand involves condensing and simplifying the classic neural network fitting problem applied in a real-world scenario using fully connected neural networks. It aims to validate the occurrence of traditional defined condensation phenomena in practical applications. Specifically, due to the complexity of combustion simulation, it can highlight the ability of condensation reduction to maintain the performance of neural networks.
3.1.2. Training Setup
The original model in this experiment is a fully connected neural network with the architecture of 23-3200-1600-800-400-23. The parameters of the neural network are initialized using the following Gaussian distribution:
wherein and are the input dimension and output dimensions of the specific layer of the model, respectively. The initial learning rate is set to 0.0001 and is reduced to 50% of its original value every 1000 steps to prevent the learning rate from becoming too large. The entire training process uses the Adam optimizer, sets , , . The starting batch size is set to 1024 and is increased by a factor of 3.07 every 1000 steps to gradually accelerate training and enhance the model’s generalization performance. The initial model undergoes training for 5000 steps, resulting in a training loss of 0.02172. Post-training, the model’s accuracy across the 0th, 1st, and 2nd dimension is evaluated. The training and validation loss of the original model is shown in Figure 3a.
3.1.3. Reduction Setup and Result
Due to the complex and time-consuming nature of evaluating neural network metrics in the combustion simulation task, a manual reduction approach is adopted. Please refer to Table 1 for a comparison of the reduction processes. In the first reduction, the first layer of the original network is reduced, with a set condensation threshold of 0.9, resulting in a modified model architecture of 23-2205-1600-800-400-23. The initial learning rate is set at 0.0001, decreasing to 10% of its previous value every 2500 steps, with Adam as the optimizer. The starting batch size is 1024, increasing to 128 times its original size every 2500 steps. After training for 5000 steps, the training loss is 0.01592. This reduction in loss is considered indicative of the model’s performance being between that of the original model trained for 5000 steps and the original model trained for 10,000 steps. This suggests that consolidating condensed neurons has a minimal impact on the neural network’s performance. Furthermore, it is observed from the loss graph that the loss of the reduced neural network rapidly decreases to a satisfactory level within a few training steps, similar to the case of perturbing the parameters of the original model. This indicates that the condensed neurons are approximately equivalent to a single neuron, a finding that is validated by subsequent reductions. The training and validation loss is shown in Figure 3b.
The second reduction further reduces the first layer of the neural network, with a set condensation threshold of 0.8, resulting in a model architecture of 23-1105-1600-800-400-23. This reduction uses the same training settings as the first reduction. After training for 5000 steps, the training loss is 0.01358, showing continued decline. At this point, the first layer of the original model has been reduced to 34.5% of its initial size, yet it still maintains accuracy in the 0th and 1st dimensions and performs exceptionally well in two-dimensional turbulent flame simulations. This reflects that a significant number of neurons in the neural network are condensed, and the condensed model is approximately equivalent to the subnet resulting from the merged condensed neurons, further proving the feasibility of using condensation for network reduction. These two reductions indicate that the extreme points reached after training the original model are likely equivalent to those of a significantly smaller subnet in the first layer. The training and validation loss is shown in Figure 3c.
The third reduction targeted the second layer of the network, setting a condensation threshold of 0.999, resulting in a model architecture of 23-1105-1309-800-400-23. The condensation threshold was set so high because, after the first two reductions, the second layer of the neural network became highly condensed. A slightly lower condensation threshold would have led to a significant reduction in the network, potentially reducing the second layer to fewer than ten neurons and greatly impacting model performance. The phenomenon where reducing one layer of the neural network causes a higher degree of condensation in the subsequent layer is interesting. In practice, the network parameter matrices for the first and second layers, which we use for reduction, can be understood as the input and output parameter matrices of the first layer of the neural network, respectively. They are inherently related, and reducing the first layer of the network decreases the number of rows in the input parameter matrix while also decreasing the number of columns in the output parameter matrix. The relationship between them will be explored further in future research. As shown in Figure 4, it can be clearly seen that the reduction in the first layer of the neural network can immediately change the condensation state of the second layer of the neural network. After the first and second reductions, when examining the cosine similarity matrix of the second layer of the neural network in the untrained state, we can see that the previously inconspicuous condensation in the second layer appeared after the first reduction, and a strong condensation phenomenon emerged after the second reduction, making the second layer neural network capable of extremely strong condensation even at a high condensation threshold of 0.9. Since the previous model had already been trained for 15,000 steps and reached a vicinity of a good extreme point, a smaller learning rate was used for this training phase. The initial learning rate was adjusted to , with all other settings remaining the same as in the first reduction. After training for 5000 steps, the training loss was recorded at 0.01360, showing almost no change from the second reduction. The training and validation loss is shown in Figure 3d. The results of the two-dimensional turbulence simulation of the reduced model are shown in Figure 2, which is almost identical to the original model. According to existing theories, we know that training a large network and gradually reducing its size can yield better results compared to directly training a small network. We retrained a small network with the same size as the reduced network, using the same training settings as previously described. The directly trained small network even failed to converge when predicting two-dimensional turbulent flames.
From the performance and training process of the model after three rounds of reduction, it is evident that each reduction preserved the performance capabilities of the previous model, demonstrating that the phenomenon of condensation ensures the quasi-equivalence between the original network and the subnetworks. The final reduced model has an architecture of 23-1105-1309-800-400-23, with a total of 2,848,260 parameters. In contrast, the original model, with an architecture of 23-3200-1600-800-400-23, had a total of 6,802,800 parameters, making the reduced model’s size only 41.7% of the original model. However, observations from various aspects show that the performance of the original and reduced models is nearly identical, proving the effectiveness of the reduction.
3.2. Classification of CIFAR10
3.2.1. Background on Task
Image classification is a critical problem in neural network applications, and convolutional neural networks (CNNs) hold a prominent position among all neural network architectures. Choosing the image classification task can validate the universality of the condensation phenomenon in practical problems while demonstrating the wide applicability of condensation reduction.
The CIFAR10 dataset is a common dataset for image classification tasks, consisting of 60,000 color images categorized into 10 classes. Each class contains 6000 images, totaling 50,000 training images and 10,000 testing images. Choosing the CIFAR10 dataset is due to the need for a reasonably sized network to achieve good performance and moderate training time, making it convenient for applying the automatic condensation reduction method.
MobileNetV2 is a convolutional neural network model that adopts depthwise separable convolutions and is dedicated to mobile device deployment [25]. Its main network structure is shown in Table 2. For detailed information about MobileNetV2, please refer to the original text [25]. It concatenates 16 modules with the same structural characteristics, and the structure is shown in Figure 5. The reasons for using MobileNetV2 for condensation reduction are as follows. First, MobileNetV2 targets mobile deployment scenarios, which is also an important application scenario for model reduction. MobileNetV2 itself contains a small number of parameters, and further reduction in MobileNetV2 can reflect the reduction capability and practical application value of the condensation reduction method. Second, MobileNetV2 has 16 modules with the same structural characteristics, which is very suitable for using automatic condensation reduction methods for layer-by-layer reduction. Finally, MobileNetV2 mainly adopts depthwise separable convolutions, which will further extend the definition of condensation and enrich the application fields of condensation reduction.
3.2.2. Training and Reduction Setup
For convolutional networks, we similarly adopt an initialization similar to that of fully connected networks, utilizing the following Gaussian distribution:
wherein and the are input dimension and output dimension of the specific layer of the model.
The initial learning rate is set to 0.01, and a cosine annealing strategy with a period length of 200 and a minimum learning rate of 0 is used for the first 400 steps. The optimizer during this phase is SGD with . This part of the training can be seen as the process of quickly finding a good critical point for the model. After 400 steps, the learning rate changes to 0.001, and the optimizer switches to Adam, sets , , . Subsequently, every 1000 steps, the learning rate alternates between 0.001 and 0.0001. The main idea behind this learning rate strategy is to first use the cosine annealing strategy to find a suitable parameter region for the neural network and then use the Adam optimizer to refine the network parameters.
In our multiple experiments, we observed a noticeable improvement in test accuracy after switching to Adam. The accuracy obtained using this mixed strategy was higher compared to using Adam throughout the entire training process. Throughout the entire training process, the batch size remained at 128.
After each reduction, the above learning rate strategy will be reapplied for model training, but with a change in the initial learning rate. The method for changing the initial learning rate is
wherein represents the current time of reductions, is set to 200, is set to 0.0001, and is set to 0.01. The reason for this approach is that each reduction can be considered as the model reaching a critical point that meets our requirements. At this point, the learning rate should be appropriately lowered to further enhance the model’s performance. The model initiates the main reduction process when the accuracy on the validation set reaches 0.88. Once the model achieves this main reduction criterion, it automatically begins the layer-by-layer reduction. The criterion for the layer-by-layer reduction is set at an accuracy of 0.84 on the validation set. After initiating the layer-by-layer reduction, whenever the model meets this criterion, it automatically reduces the corresponding neural network layer. After each reduction, both the main reduction and layer-by-layer reduction criterion are automatically adjusted in the following manner:
wherein is set to 100. and are set to 0.88 and 0.85, respectively, for the main reduction. and are set to 0.84 and 0.81, respectively, for the layer-by-layer reduction. When the reduction is not the final layer in the layer-by-layer reduction, the initial limit for the number of training steps after reduction is set to 20 steps. If the layer-by-layer reduction criterion is not met within this limit, the model will revert to a previously saved checkpoint to reattempt the reduction of that layer, with the limit on training steps permanently increasing by 10 steps. This limit on training steps is consistent for every layer except the final one in the layer-by-layer reduction. This is because encountering difficulties in reducing one layer often implies that reducing each layer will pose a challenge.
The initial condensation threshold for each layer of the neural network is set at
If a layer of the neural network fails to meet the layer-by-layer reduction criterion after reaching the limit of restricted training steps following reduction, the condensation threshold for that layer is set at
wherein represents the number of times reduction has failed. If, after a reduction, the amount of parameters reduced in a certain layer of the neural network is too small, and the layer-by-layer reduction criterion can be met after reaching the limit of restricted training steps, then the condensation threshold for that layer is set at
A parameter reduction is considered too small if the proportion of the model’s parameters after reduction, compared to before reduction, is greater than 0.999.
For the final layer in a layer-by-layer reduction, there are specific, larger limits for training steps and validation set accuracy criterion, as the reduction in the last layer often results in the largest decrease in parameters within the MobileNetV2 model, leading to significant changes in model performance. Here, the limit for training steps is set to 200, and the validation accuracy criterion is set at 0.8.
We have also established a criterion for significant model deviation following model reduction. If, after model reduction, the accuracy on the validation set is below 0.5 after 10 training steps, it is considered that the model has undergone a significant deviation, and it will be reverted to a previously saved checkpoint to undergo reduction again. This approach saves time that would have otherwise been spent training up to the limit of training steps.
Finally, upon achieving an appropriate parameter count through the main reduction cycle, the final classification layer is reduced using a condensation threshold of 0.4 for this last layer.
3.2.3. Reduction Result
In the CIFAR10 image classification task, we can quickly measure the performance of neural networks using the accuracy of the validation set; thus, we adopt automatic condensation reduction. Please refer to Table 3 for a comparison of the reduction processes. The total condensation reduction training process is shown in Figure 6a,b. From the start of training to the beginning of the first major reduction, it took 293 steps, at which point the model reached a validation set accuracy of 88.16%. The major reduction was completed in 338 steps, reducing from the 2nd layer to the 17th layer, totaling 16 reductions. Initially, the main reduction criterion was set at 0.88 and the layer-by-layer reduction criterion at 0.84; by the end, these were adjusted to 0.87837 and 0.83837, respectively. During this major reduction, the condensation threshold for each layer was maintained at the original value of 0.88080. The original model’s parameter count was reduced from 2,236,682 to 1,143,421, meaning the reduced model’s parameters accounted for only 51.1% of the original model. As shown in Figure 7, throughout the major reduction process, most layers underwent significant reductions, with reduction ratios around 50%. The greatest reduction was in the 17th layer, with a reduction ratio of 19.69% and a single-layer parameter reduction of 380,103. Generally, the model exhibited minor performance deviations after each layer’s reduction, with post-reduction, untrained validation set accuracies mostly above 70%. After significant reductions, accuracy could reach over 80% with just one step of training per layer. The observed reduction in parameter count validates the prevalence of condensation phenomena in convolutional neural networks, with a significant number of neurons condensing around a condensation threshold of approximately 0.88. The minor shifts resulting from reductions confirm that the condensation reduction method extended from fully connected to convolutional neural networks is reasonable and effective. The ability to rapidly restore model performance post-reduction suggests that the critical points achieved by the original model likely coincide with those of the reduced subnetworks. At step 385, 47 steps post-reduction, the reduced model’s validation set accuracy exceeded 87%. Considering model deployment objectives, it is only necessary to proceed with an additional 45 steps of reduction training after meeting deployment requirements to reduce nearly half of the parameter count. An additional 47 steps of training can yield a reduced model with negligible performance differences from the original, offering substantial practical value.
The second main reduction began at step 942, with the model’s validation set accuracy reaching 0.8801, and was completed by step 975. Initially, the main reduction criterion was set at 0.87837 and the layer-by-layer reduction criterion at 0.83837; by the end, these were adjusted to 0.87343 and 0.83343, respectively. Throughout this major reduction process, the condensation threshold for each layer remained at the original value of 0.88080, with no instances of reduction failure necessitating a rollback. The model’s parameter count was further reduced from 1,143,421 (after the first reduction) to 910,370, with the new reduced model’s parameters representing only 40.7% of the original model. After the first reduction, the condensation level of the neural network’s layers decreased, which was expected. According to the embedding principle, reduction starts from a specific critical point of the original model, which should correspond to a critical point of a certain fixed subnetwork. The reduction process progressively approximates this subnetwork by merging condensed neurons. As reduction proceeds, the reduced model becomes increasingly similar to the subnetwork, resulting in fewer condensed neurons and a decrease in the neural network’s redundant complexity, making further reductions increasingly challenging. When applying condensation reduction to practical problems, the reduction process can be prematurely concluded based on specific needs. In this study, to explore the limits of condensation reduction, we continued the reduction process as far as practically possible. Similar to the first reduction, each layer’s reduction resulted in minimal performance deviation of the neural network, with a rapid recovery of performance after just one step of training.
Our experiments continued until the completion of the sixth major reduction, with the third to sixth major reductions starting at steps 1601, 2316, 3286, 4867, and 11,919, and ending at steps 1633, 2362, 3351, 4921, and 12,127, respectively. The initial main reduction criteria at the start were 0.87343, 0.86641, 0.85904, 0.85315, and 0.85018, while the layer-by-layer reduction criteria were 0.83343, 0.82641, 0.81904, 0.81315, and 0.81018, respectively. The parameter counts of the reduced models were 827,032, 776,011, 735,527, 704,004, and 669,228, respectively; after the sixth major reduction, the reduced model’s parameters accounted for only 29.9% of the original model. It can be observed that each subsequent reduction became increasingly difficult, with longer training steps required, aligning with the expectation of approximating the ideal subnetwork. Each layer’s reduction still kept the model’s performance relatively unchanged. By the time of the sixth reduction’s completion, there had been a total of 96 successful reductions, with a parameter decrease of 1,567,454, but only a slight decrease in the model’s validation set accuracy, achieving 83.13%, which is not significantly lower than the historical highest validation set accuracy of 88.16%.
The final layer reduction, starting at step 15,200, utilized a condensation threshold set at 0.4, resulting in the model’s parameter count being reduced to 258,212. This is merely 11.5% of the original model’s parameters, and it is considered a very small model for tasks on CIFAR10. The reduction in the final layer alone eliminated 411,016 parameters, cutting over 60% of the model’s parameters following the sixth major reduction. Despite this significant reduction, the accuracy rate on the validation set without further training still reached 75.45%. After training, the final reduced model achieved a peak accuracy of 83.21%, virtually unchanged from before the reduction. This serves as yet another powerful validation of the effectiveness of condensation reduction.
4. Discussion
The successful application of condensation reduction in both fully connected and convolutional networks for practical problems demonstrates the universality of the condensation phenomenon. In the complex task of combustion simulation, condensation reduction effectively reduces network size while maintaining the accuracy of turbulence ignition predictions, confirming that a condensed network and its subnetworks are approximately equivalent. In image classification tasks, particularly in the broader application within depthwise separable convolutional neural networks, the definition and scope of condensation have been expanded. This extension enables the broader application of condensation reduction across various network types and tasks.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Reiser P. Neubert M. Eberhard A. Torresi L. Zhou C. Shao C. Metni H. van Hoesel C. Schopmans H. Sommer T. Graph neural networks for materials science and chemistry Commun. Mater.202239310.1038/s 43246-022-00315-636468086 PMC 9702700 · doi ↗ · pubmed ↗
- 2Sarvamangala D. Kulkarni R.V. Convolutional neural networks in medical image understanding: A survey Evol. Intell.20221512210.1007/s 12065-020-00540-333425040 PMC 7778711 · doi ↗ · pubmed ↗
- 3Shlomi J. Battaglia P. Vlimant J.R. Graph neural networks in particle physics Mach. Learn. Sci. Technol.2020202100110.1088/2632-2153/abbf 9a · doi ↗
- 4Smith M.J. Geach J.E. Astronomia ex machina: A history, primer and outlook on neural networks in astronomy R. Soc. Open Sci.20231022145410.1098/rsos.22145437266039 PMC 10230190 · doi ↗ · pubmed ↗
- 5Zhang X.M. Liang L. Liu L. Tang M.J. Graph neural networks and their current applications in bioinformatics Front. Genet.20211269004910.3389/fgene.2021.69004934394185 PMC 8360394 · doi ↗ · pubmed ↗
- 6Zhong S. Zhang K. Bagheri M. Burken J.G. Gu A. Li B. Ma X. Marrone B.L. Ren Z.J. Schrier J. Machine learning: New ideas and tools in environmental science and engineering Environ. Sci. Technol.202155127411275410.1021/acs.est.1c 0133934403250 · doi ↗ · pubmed ↗
- 7Raissi M. Perdikaris P. Karniadakis G.E. Physics-informed neural networks: A deep learning framework for solving forward and inverse problems involving nonlinear partial differential equations J. Comput. Phys.201937868670710.1016/j.jcp.2018.10.045 · doi ↗
- 8Blechschmidt J. Ernst O.G. Three ways to solve partial differential equations with neural networks—A review GAMM-Mitteilungen 202144 e 20210000610.1002/gamm.202100006 · doi ↗