Triple-0: Zero-shot denoising and dereverberation on an end-to-end frozen anechoic speech separation network
Sania Gul, Muhammad Salman Khan, Ata Ur-Rehman

TL;DR
This paper introduces a new method for speech enhancement that uses a pre-trained network without any fine-tuning to clean up noisy and reverberated speech.
Contribution
The novel contribution is a zero-shot speech denoising and dereverberation method using a frozen pre-trained network without architectural changes or fine-tuning.
Findings
The frozen network performs well in zero-shot testing under noisy and reverberant conditions without prior exposure.
The model outperforms the WPE algorithm in terms of speech quality and intelligibility metrics on the same training dataset.
The proposed model achieves comparable performance to deep learning SD&D algorithms under varying noise and reverberation conditions.
Abstract
Speech enhancement is crucial both for human and machine listening applications. Over the last decade, the use of deep learning for speech enhancement has resulted in tremendous improvement over the classical signal processing and machine learning methods. However, training a deep neural network is not only time-consuming; it also requires extensive computational resources and a large training dataset. Transfer learning, i.e. using a pretrained network for a new task, comes to the rescue by reducing the amount of training time, computational resources, and the required dataset, but the network still needs to be fine-tuned for the new task. This paper presents a novel method of speech denoising and dereverberation (SD&D) on an end-to-end frozen binaural anechoic speech separation network. The frozen network requires neither any architectural change nor any fine-tuning for the new task,…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
 Figure 1
Figure 1 Figure 2
Figure 2 Figure 3
Figure 3 Figure 4
Figure 4 Figure 5
Figure 5 Figure 6
Figure 6 Figure 7
Figure 7 Figure 8
Figure 8 Figure 9
Figure 9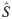 Figure 10
Figure 10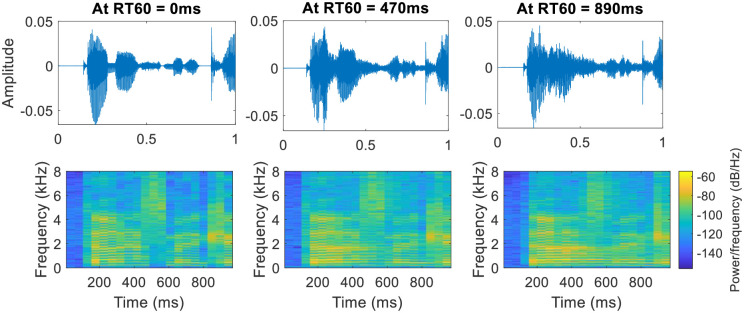 Figure 11
Figure 11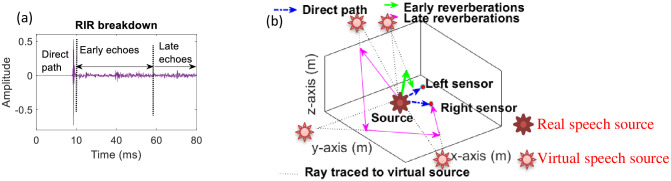 Figure 12
Figure 12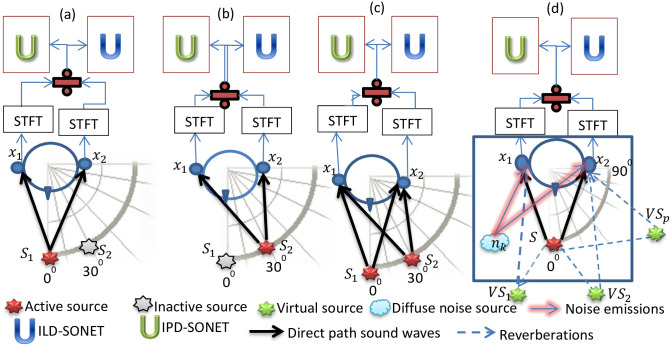 Figure 13
Figure 13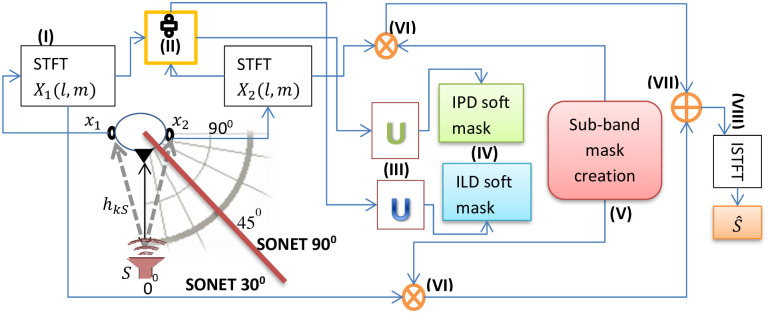 Figure 14
Figure 14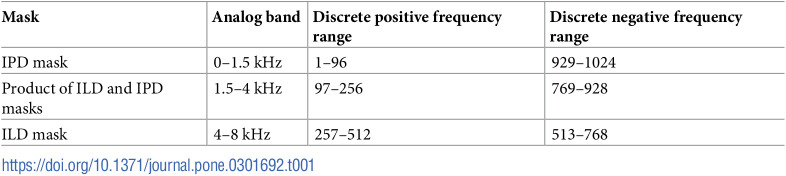 Figure 15
Figure 15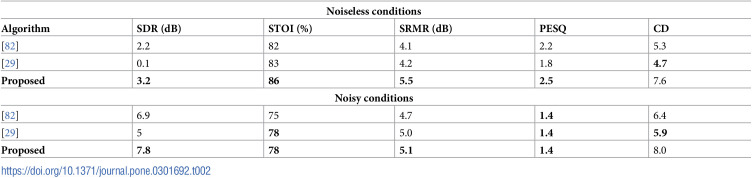 Figure 16
Figure 16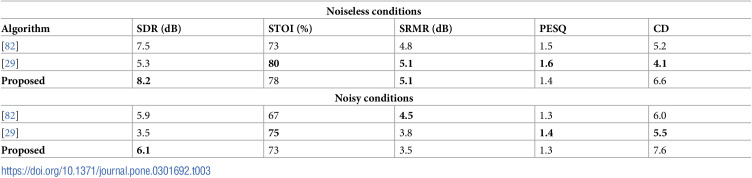 Figure 17
Figure 17Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsSpeech and Audio Processing · Speech Recognition and Synthesis · Music and Audio Processing