A Bayesian hierarchical hidden Markov model for clustering and gene selection: Application to kidney cancer gene expression data
Thierry Chekouo, Himadri Mukherjee

TL;DR
This paper introduces a Bayesian model using hidden Markov structures to cluster genes and identify relevant features in kidney cancer data.
Contribution
The novelty lies in integrating gene ontology knowledge with HMMs for biclustering and gene selection.
Findings
The model identifies clusters of samples with overexpressed, underexpressed, and irrelevant genes.
The method was validated using simulated data and The Cancer Genome Atlas kidney cancer dataset.
An R package was developed to implement the proposed Bayesian approach.
Abstract
We introduce a Bayesian approach for biclustering that accounts for the prior functional dependence between genes using hidden Markov models (HMMs). We utilize biological knowledge gathered from gene ontologies and the hidden Markov structure to capture the potential coexpression of neighboring genes. Our interpretable model-based clustering characterized each cluster of samples by three groups of features: overexpressed, underexpressed, and irrelevant features. The proposed methods have been implemented in an R package and are used to analyze both the simulated data and The Cancer Genome Atlas kidney cancer data.
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
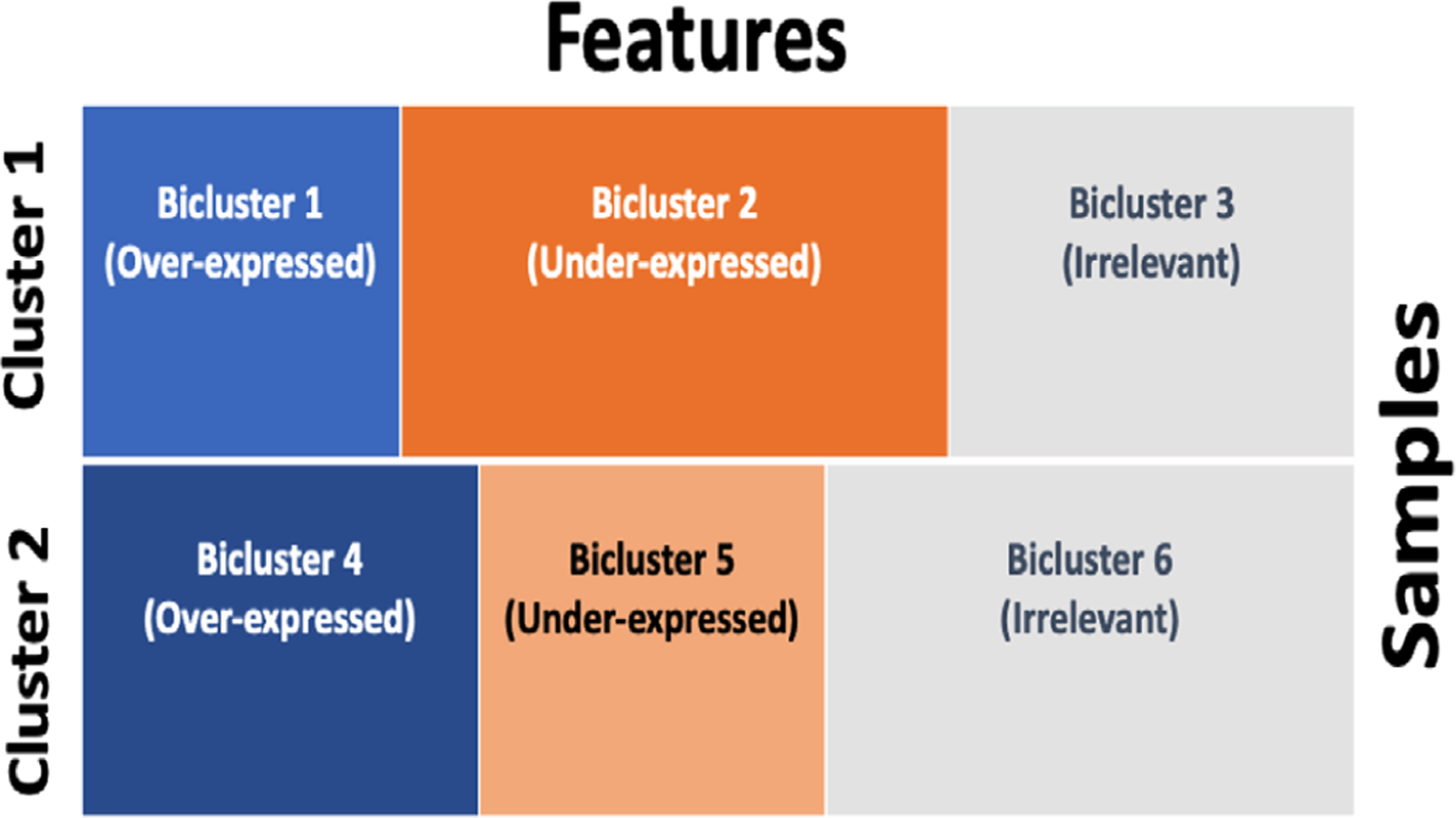 Figure 1
Figure 1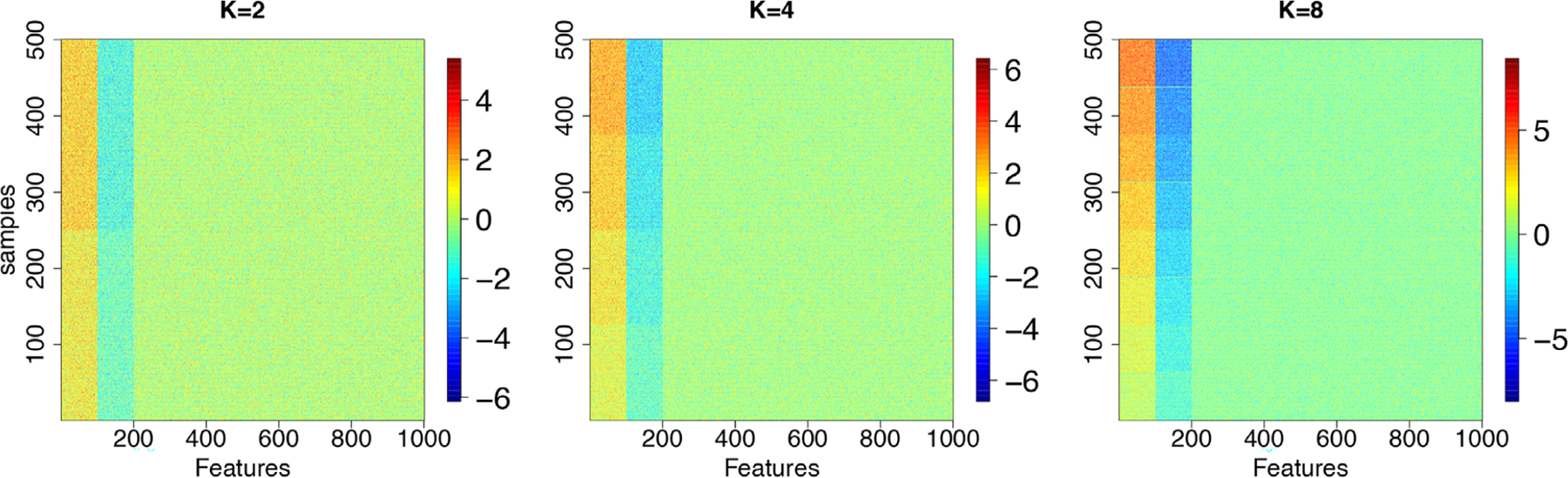 Figure 2
Figure 2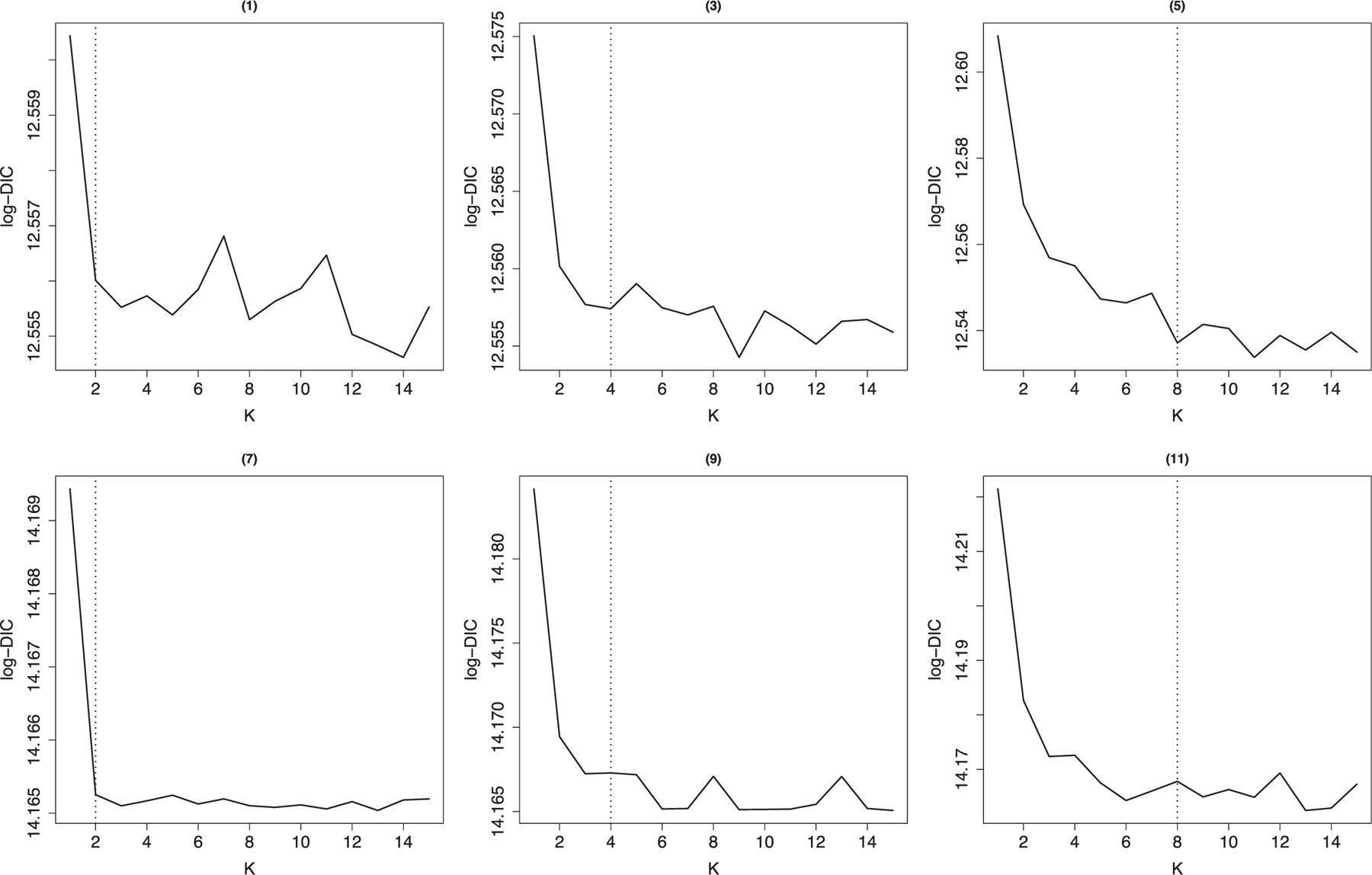 Figure 3
Figure 3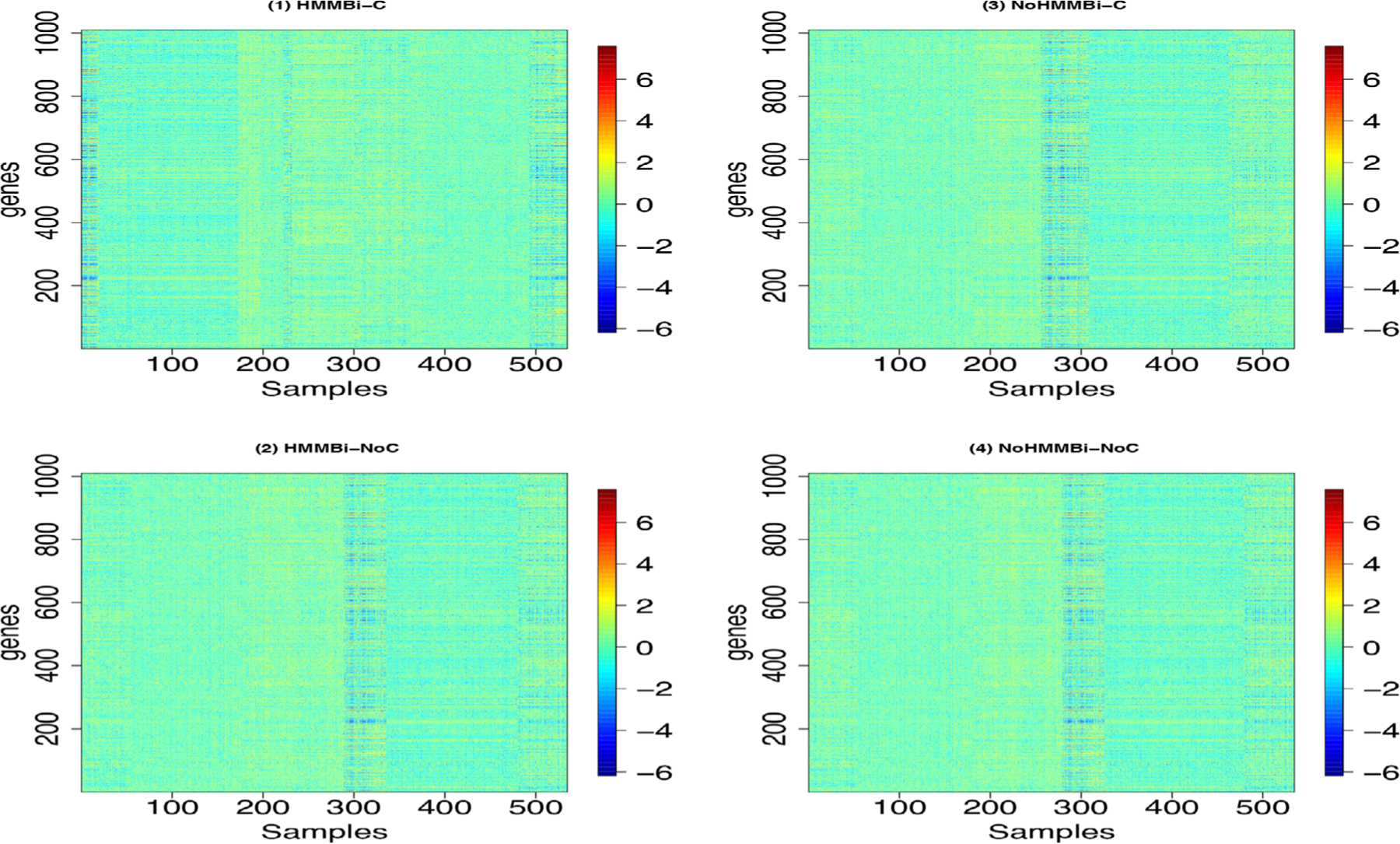 Figure 4
Figure 4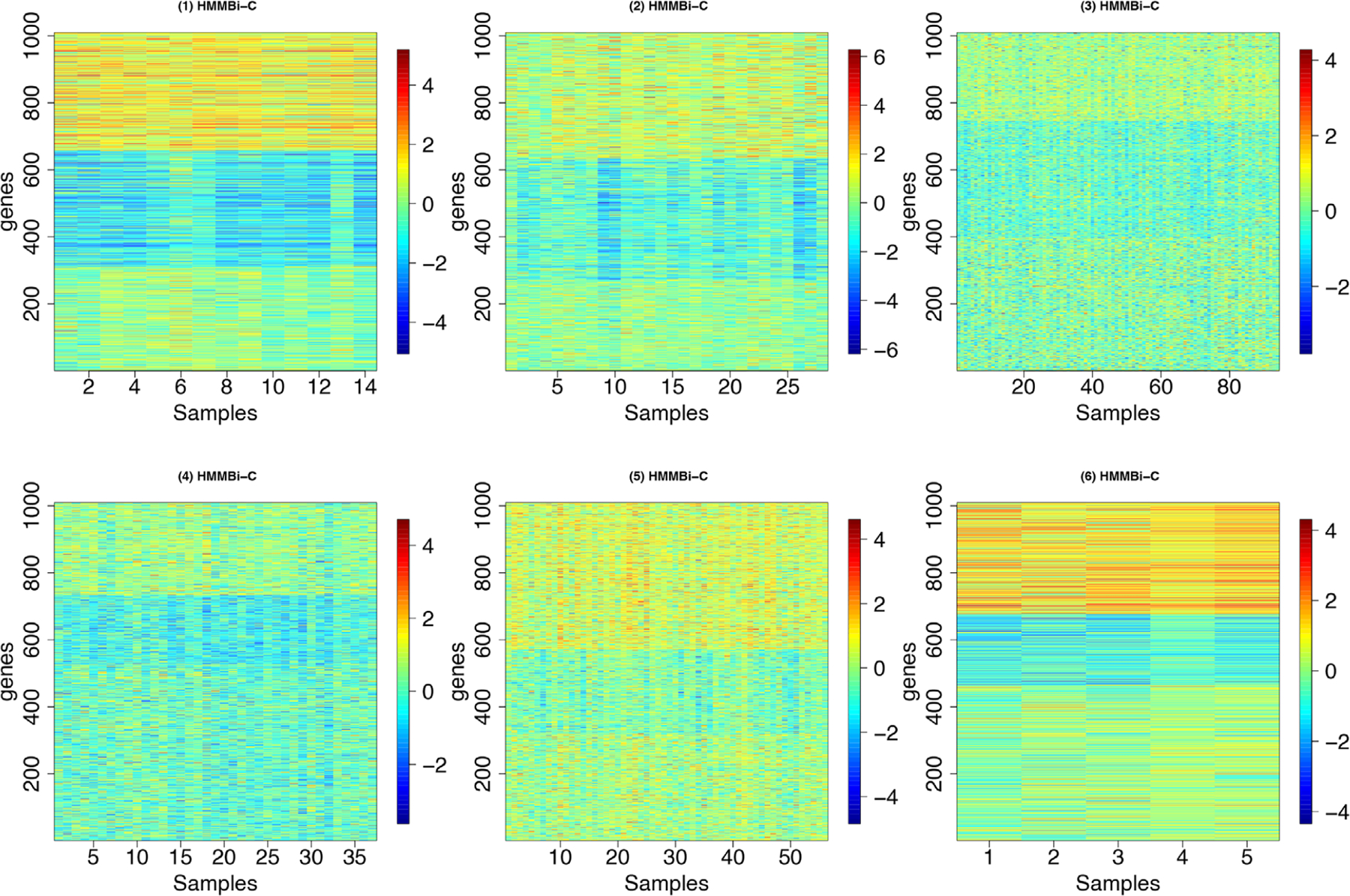 Figure 5
Figure 5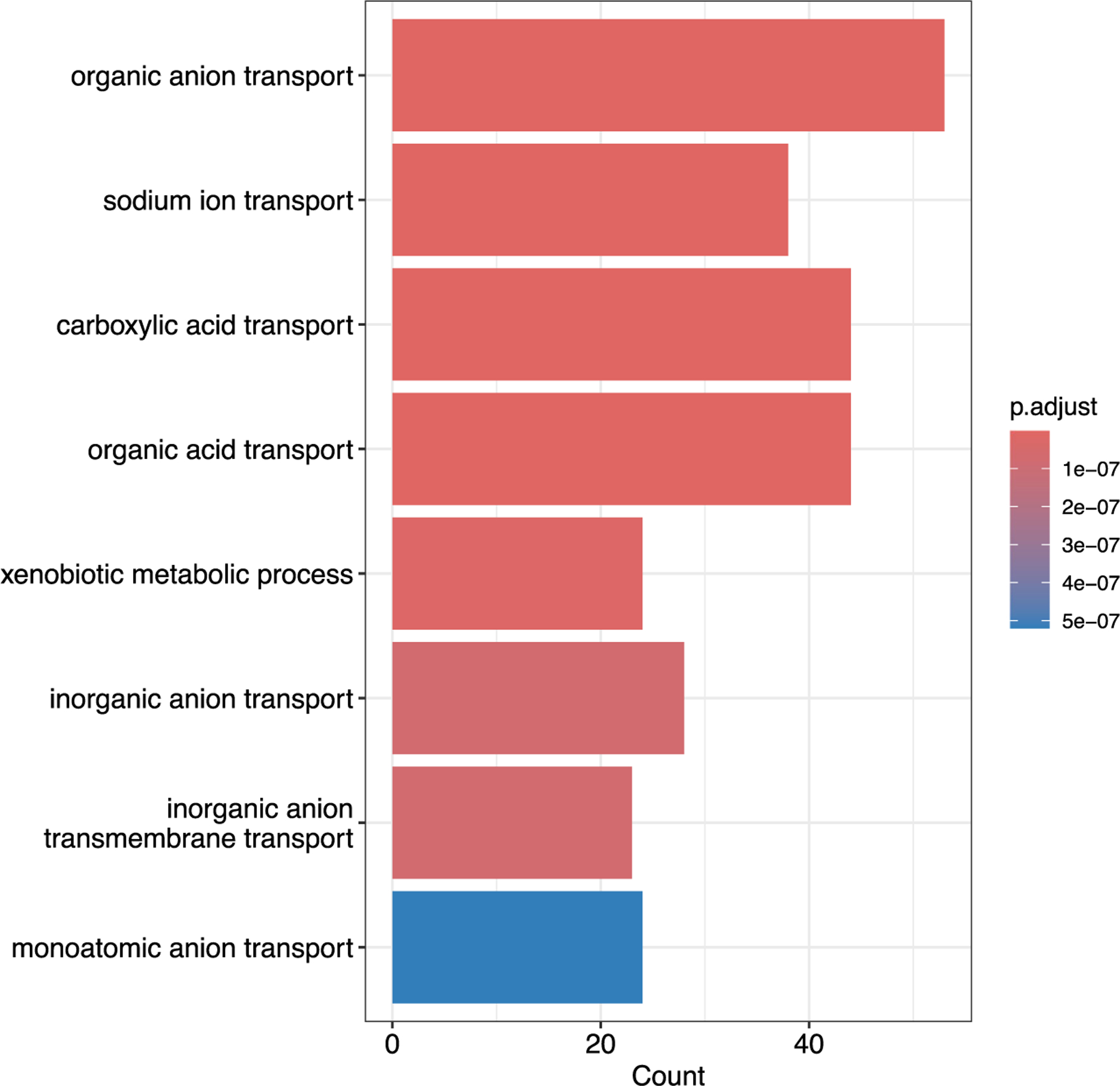 Figure 6
Figure 6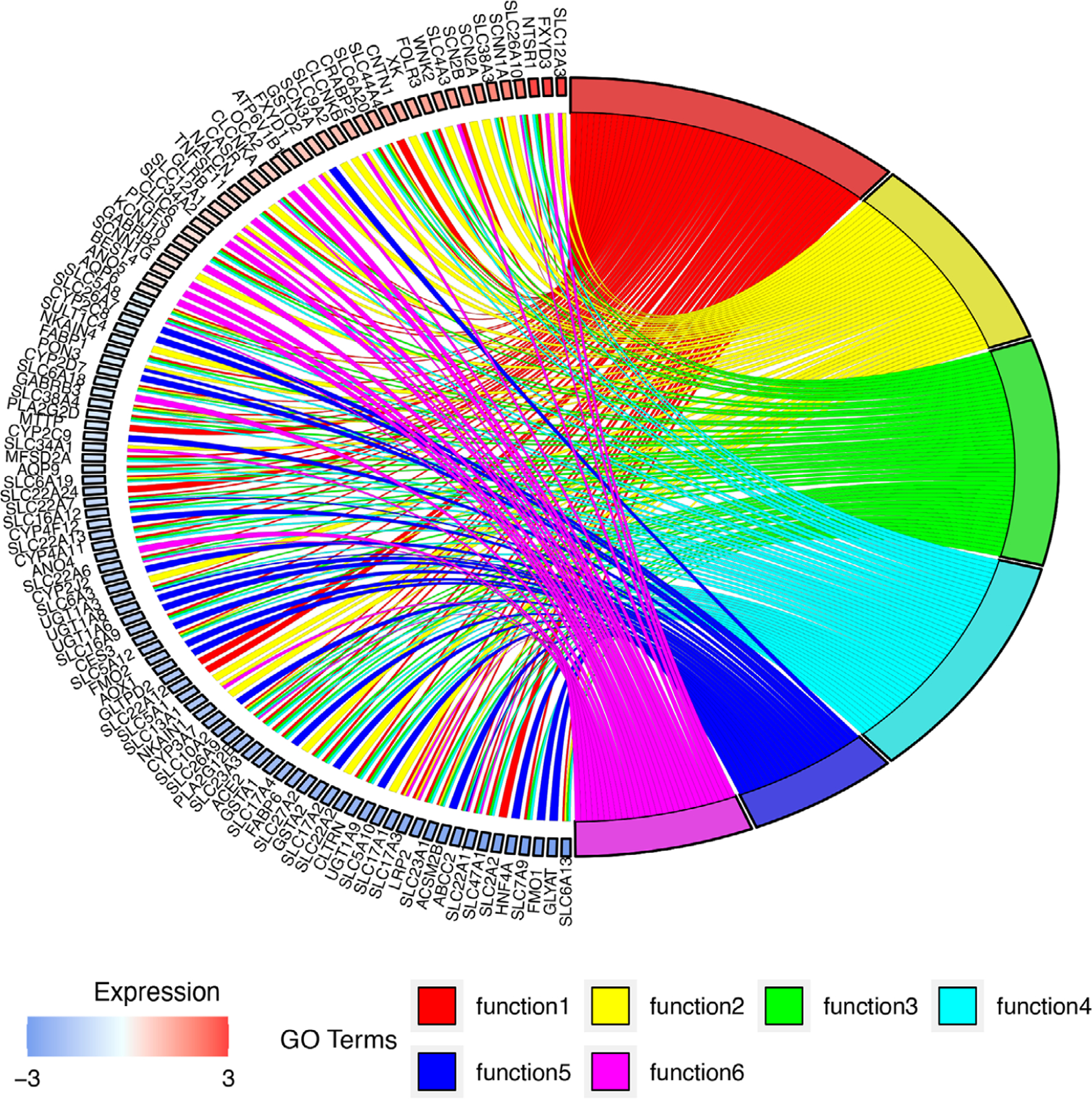 Figure 7
Figure 7Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsGene expression and cancer classification · Bioinformatics and Genomic Networks · Bayesian Modeling and Causal Inference