HOTSPOT: An ad hoc teamwork platform for mixed human-robot teams
João G. Ribeiro, Luis Müller Henriques, Sérgio Colcher, Julio Cesar Duarte, Francisco S. Melo, Ruy Luiz Milidiú, Alberto Sardinha

TL;DR
This paper introduces HOTSPOT, a new framework for human-robot collaboration without prior coordination, using decision-making and communication modules.
Contribution
HOTSPOT is the first framework for ad hoc teamwork in human-robot teams, combining decision-making and natural language communication.
Findings
The decision-theoretic module enables task identification and planning in real-world scenarios.
The communication module successfully parses natural language interactions between robots and humans.
HOTSPOT demonstrates effective collaboration in a cooperative object collection task.
Abstract
Ad hoc teamwork is a research topic in multi-agent systems whereby an agent (the “ad hoc agent”) must successfully collaborate with a set of unknown agents (the “teammates”) without any prior coordination or communication protocol. However, research in ad hoc teamwork is predominantly focused on agent-only teams, but not on agent-human teams, which we believe is an exciting research avenue and has enormous application potential in human-robot teams. This paper will tap into this potential by proposing HOTSPOT, the first framework for ad hoc teamwork in human-robot teams. Our framework comprises two main modules, addressing the two key challenges in the interaction between a robot acting as the ad hoc agent and human teammates. First, a decision-theoretic module that is responsible for all task-related decision-making (task identification, teammate identification, and planning). Second,…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
 Figure 1
Figure 1 Figure 2
Figure 2 Figure 3
Figure 3 Figure 4
Figure 4 Figure 5
Figure 5 Figure 6
Figure 6 Figure 7
Figure 7 Figure 8
Figure 8 Figure 9
Figure 9 Figure 10
Figure 10 Figure 11
Figure 11 Figure 12
Figure 12 Figure 13
Figure 13 Figure 14
Figure 14 Figure 15
Figure 15 Figure 16
Figure 16 Figure 17
Figure 17 Figure 18
Figure 18 Figure 19
Figure 19 Figure 20
Figure 20 Figure 21
Figure 21 Figure 22
Figure 22 Figure 23
Figure 23 Figure 24
Figure 24 Figure 25
Figure 25 Figure 26
Figure 26 Figure 27
Figure 27 Figure 28
Figure 28 Figure 29
Figure 29 Figure 30
Figure 30 Figure 31
Figure 31 Figure 32
Figure 32 Figure 33
Figure 33 Figure 34
Figure 34 Figure 35
Figure 35 Figure 36
Figure 36 Figure 37
Figure 37 Figure 38
Figure 38 Figure 39
Figure 39 Figure 40
Figure 40 Figure 41
Figure 41 Figure 42
Figure 42 Figure 43
Figure 43 Figure 44
Figure 44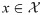 Figure 45
Figure 45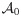 Figure 46
Figure 46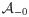 Figure 47
Figure 47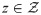 Figure 48
Figure 48 Figure 49
Figure 49 Figure 50
Figure 50Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsReinforcement Learning in Robotics · Human-Automation Interaction and Safety · Multi-Agent Systems and Negotiation