Universal Image Restoration with Text Prompt Diffusion
Bing Yu, Zhenghui Fan, Xue Xiang, Jiahui Chen, Dongjin Huang

TL;DR
This paper introduces a new framework for restoring images with various types of degradation using text prompts and a diffusion model.
Contribution
The novel ETDiffIR framework uses text prompts and a fusion block to enhance universal image restoration performance.
Findings
The proposed ETDiffIR outperforms existing methods in tasks like dehazing, deraining, and denoising.
A new text–image fusion block improves degradation type encoding in the diffusion model.
An efficient restoration U-shaped network reduces computational costs while maintaining noise prediction accuracy.
Abstract
Universal image restoration (UIR) aims to accurately restore images with a variety of unknown degradation types and levels. Existing methods, including both learning-based and prior-based approaches, heavily rely on low-quality image features. However, it is challenging to extract degradation information from diverse low-quality images, which limits model performance. Furthermore, UIR necessitates the recovery of images with diverse and complex types of degradation. Inaccurate estimations further decrease restoration performance, resulting in suboptimal recovery outcomes. To enhance UIR performance, a viable approach is to introduce additional priors. The current UIR methods have problems such as poor enhancement effect and low universality. To address this issue, we propose an effective framework based on a diffusion model (DM) for universal image restoration, dubbed ETDiffIR. Inspired…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
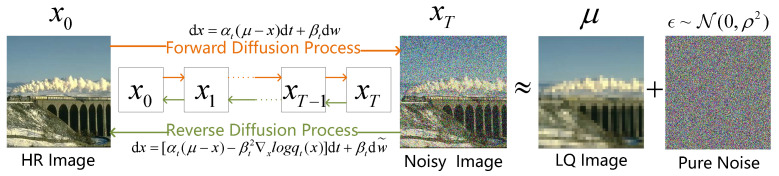 Figure 1
Figure 1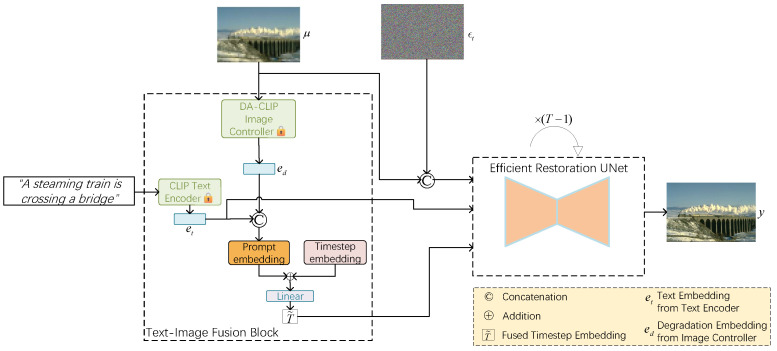 Figure 2
Figure 2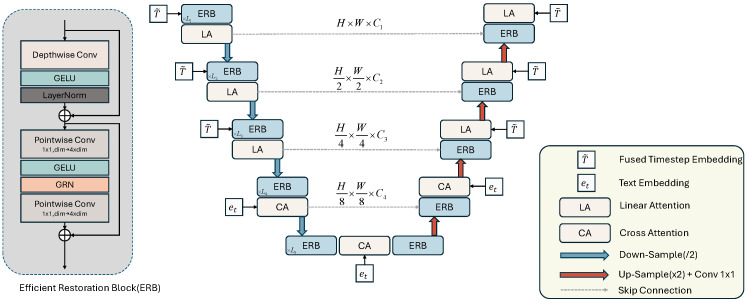 Figure 3
Figure 3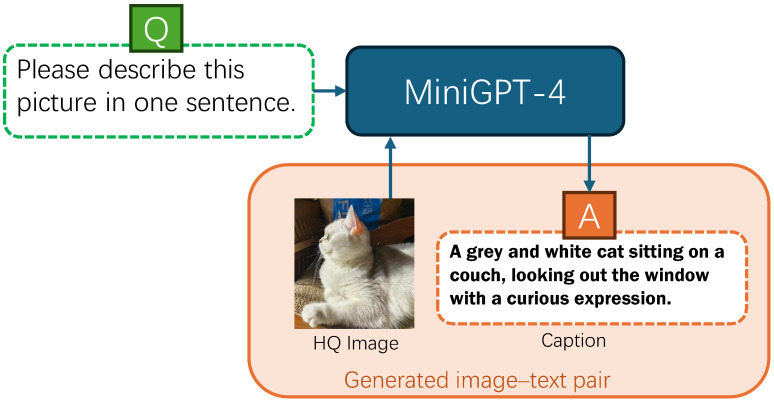 Figure 4
Figure 4 Figure 5
Figure 5 Figure 6
Figure 6 Figure 7
Figure 7 Figure 8
Figure 8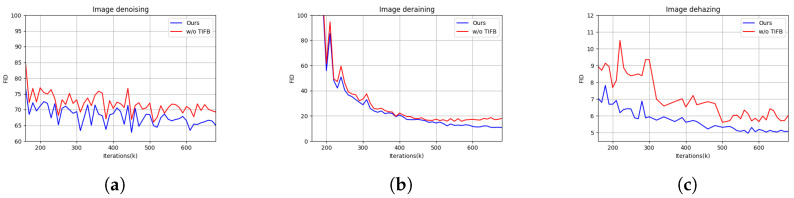 Figure 9
Figure 9 Figure 10
Figure 10- —Shanghai Natural Science Foundation
- —development fund for Shanghai talents
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsAdvanced Image Processing Techniques · Image and Signal Denoising Methods · Image Enhancement Techniques
1. Introduction
High-quality images exhibit clear texture details and more realistic colors, not only enhancing visual experiences but also facilitating subsequent image processing and analysis. However, image quality is affected during processes such as acquisition, transmission, and storage, making it challenging to obtain clear, high-quality images. The various types of degradation of images (such as blur, noise, raindrops, and haze) not only significantly impact visual perception but also pose difficulties and challenges for subsequent applications of the images. Therefore, restoring degraded images to high-resolution images while preserving as much information as possible, and recovering their color and texture, holds significant research significance.
Given that there are multiple degradation types, single-task image restoration methods [1,2,3,4,5,6,7,8,9,10] involve training a single-task model for each type of degradation. While such an approach may yield favorable metrics for individual tasks, its applicability to complex real-world scenarios is challenging. Additionally, if there is a shift in the degradation type or corruption ratio, the model’s performance could become unsatisfactory. This dissatisfaction arises due to the misalignment between the actual scenario encountered and the previously chosen parameters for either model construction or training. More recently, many works have achieved universal image restoration by training a learning-based model to be effectively capable of recovering images from various types of degradation. Methods can be roughly divided into two categories [11]: The first category comprises methods [12,13,14,15,16] that model image restoration tasks as linear inverse problems, using pretrained diffusion models as generative priors to solve any linear inverse problem. However, these methods require a precise definition of a function for each specific type of degradation. The second category comprises methods [11,17,18,19,20,21] that explicitly or implicitly train a degradation-type classifier in an end-to-end manner, using it as the foundation for image restoration. However, they lack the ability to generate missing or deteriorated details in images [11].
In summary, an essential aspect of enhancing image restoration lies in effectively modeling degradation, especially in intricate application contexts. However, most methods heavily rely on low-quality (LQ) image features for restoration guidance, which is challenging and limits restoration performance. In cases of severe image degradation, the degradation process may lead to the loss of essential feature information from the original image, making it challenging for the model to accurately reconstruct the original image. The introduction of additional prior information can effectively enhance the performance of image restoration. Recently, text prompts have attracted considerable attention in various fields such as image segmentation [22], image generation [23,24], and image editing [25]. Inspired by this, we incorporate text prompts as prior information for image restoration tasks.
In this paper, we propose a framework that utilizes a text prompt corresponding to a low-quality image to assist the diffusion model in restoring the image. Firstly, we use the visual language model Minigpt-4 [26] to generate corresponding textual descriptions for high-resolution images in the dataset. We utilize text prompts to represent the image’s semantic content to provide additional prior information. Considering that the LR image can provide the majority of low-frequency [27] and semantic information related to the content [23], we utilize DA-CLIP [18] to extract features related to the degradation type from the image and perform classification, facilitating the universal restoration of different degradation types. Firstly, we input the textual caption into the pretrained CLIP text encoder [28] to obtain the text encoding. Subsequently, the LQ image is fed into the pretrained DA-CLIP image controller to obtain the image degradation embedding. We then combine the text encoding and degradation embedding, followed by prompt encoding, to obtain the complete text prompt. In addition, to enhance the performance of the diffusion model in image restoration tasks, we made improvements to its denoising network. Inspired by ConvMixer [29] and ConvNeXtV2 [30], we designed a novel module for the denoising network that functions as both an encoder and a decoder. We further propose a network, efficient text prompt diffusion image restoration (ETDiffIR), to realize the text prompt universal image restoration (UIR). ETDiffIR utilizes an advanced score-based diffusion model [31]. Overall, our main contributions can be summarized as follows:
- We proposed a text prompt diffusion model to solve the universal image restoration problem. To the best of our knowledge, this is the first attempt to incorporate text prompts into universal image restoration.
- We pioneered an effective denoising network for diffusion-based image restoration. By introducing text prior information into the diffusion model using an efficient restoration block (ERB), ETDiffIR can achieve excellent image restoration results.
- We constructed a combined dataset containing three different degradation types and generated synthetic captions using the visual-language model Minigpt-4, resulting in a high-quality dataset comprising paired text and images.
2. Related Work
2.1. Universal Image Restoration
While single-task image restoration methods [1,2,3,4,5,32,33,34,35] have matured over time, universal image restoration methods are currently still in the early stages of development. Universal image restoration refers to the use of a single model to handle various types of degradation, also known as “all-in-one” image restoration. Universal image restoration methods can be broadly categorized into two categories: methods based on unsupervised generation priors and methods based on end-to-end training.
Using pretrained diffusion models as generative priors [12,13,14,15,16] for image restoration has become a popular approach in recent times. These types of methods model image restoration as a linear inverse problem. Kawar et al. [12], building upon the use of a diffusion model prior, introduced the singular value decomposition of the degradation operator during the inverse diffusion process to obtain restoration results. Similarly, Wang et al. [13] refined only the null space content during the inverse diffusion process, obtaining diverse results that achieved both data consistency and realism. Garber et al. [15] proposed a guided technique based on preprocessing, which reduces the number of iterations in the inverse diffusion process and enhances robustness. The mentioned methods require a manually defined precise degradation function for each degradation type and are limited to linear degradation.
The second category of methods is based on end-to-end learning, typically utilizing an explicitly or implicitly embedded degradation classifier within the network to determine the degradation type of the image, guiding the image restoration process [11,17,18,19,20,21]. For example, Li et al. [17] designed a contrastive learning-based encoder that leverages the consistency among images with the same type of degradation and the inconsistency present among images with different types of degradation to learn degradation representations. Chen et al. [21] employed knowledge distillation to obtain a universal image restoration model from multiple image restoration networks specializing in different degradation types. Jiang et al. [11] designed a blind image quality assessment module that automatically detects and identifies the degradation type of an image, guiding the diffusion model in image restoration. Zhang et al. [20] proposed a general image restoration method based on principal component analysis. This method established a corresponding prior center for each type of degradation and constructed task-oriented centers as single-component centers through learnable principal component analysis. Luo et al. [18] designed an image controller based on CLIP [28]. Through contrastive learning, the controller outputs degradation features that match the input image’s degradation characteristics, resulting in a natural classifier for different degradation types. More recently, Yan et al. [36] fine-tuned language models to identify and restore different types of degradation through user interaction. However, many methods still face challenges in terms of reconstruction quality. Our approach utilizes scene descriptions as additional priors to enhance image reconstruction under severe degradation.
2.2. Diffusion-Based Restoration
Diffusion models employ a fixed Markov chain to optimize the change boundary of the likelihood function, and they have recently gained increasing attention because of their outstanding performance in generative tasks [23]. In IR tasks, the application of diffusion models is still in its early stages. Xia et al. [37] utilized Transformer blocks to simulate long-range dependencies for noise prediction, achieving effective image reconstruction. Li et al. [38] introduced residual prediction into a diffusion model for image SR. Luo et al. [31] proposed the concept of an averaging equation to simulate the image degradation process, concurrently achieving a faster diffusion process. However, image restoration based on diffusion models often relies on a complex network to predict noise, which affects the efficiency of the model in practical applications. To address this, the proposed ETDiffIR utilizes a lightweight network, ERUNet, to predict noise, achieving satisfactory results.
3. Method
To enhance reconstruction performance in image restoration tasks, based on stochastic differential equations (SDEs), we design a text-conditioned diffusion model suitable for universal image restoration. Given a degraded image and a textual description of the scene in that image, we use the diffusion model to generate a high-quality (HQ) image. We train the diffusion model on a synthetic dataset of image–text pairs. In the following sections, we describe our data processing procedure and the main architecture of the model.
3.1. Preliminary
Here, we describe the main components of the diffusion model relevant to our process. We adopt a mean-reverting stochastic differential equation (SDE) [31] to define the diffusion process. Given input data sampled from distribution q, after T time steps of increasing noise in the forward diffusion process, is transformed into a noisy image . The high-quality image is defined as . As shown in Figure 1, SDE can simulate the degradation process from an HQ image to an LQ image by approximating as a combination of the LQ image and pure noise . Specifically, the forward diffusion process can be described as
Here, and are two time-dependent parameters, controlling the mean-reversion speed and the stochastic volatility, respectively. w represents the standard Wiener process. We set to ensure a closed-form solution for Equation (1), where represents the stationary variance. Given any and time step , the corresponding intermediate state can be expressed by the solution of Equation (1) as follows:
where is defined to be equal to , and and are the mean and variance of this Gaussian distribution, respectively. When , converges to and converges to .
In the inverse diffusion process, the reversal of the process is achieved by iteratively recovering a signal from . With the reversed-time SDE [39], the reverse diffusion process can be described as
The score of the marginal distribution at time step t is the only unknown in the inference phase. Since the HQ image is available during the training process, we can train a neural network to predict the unknown score. During the training process, the ground-truth score can be represented as
Furthermore, if is reparameterized as , where is noise that follows a standard normal distribution , the ground-truth score can be expressed as a noise term using
Since noise is the only unknown parameter, we only need to train a conditional time-dependent noise prediction network to predict the noise. Similar to DDPM [40], the training objective for this noise prediction network can be expressed as
Here, is a positive weight.
3.2. Overview
Figure 2 illustrates the architecture of our proposed ETDiffIR. To achieve a better condition for the noise prediction of the diffusion model, we introduce conditional augmentation in the input section. The LQ image is concatenated with noise image ( ) as the input to the ERUNet. The caption c is transformed into embedding by the text encoder. The image controller predicts the degradation features from the LQ image . ETDiffIR takes the LQ image and the corresponding textual caption c as inputs, and it outputs the restored image . We designed a text–image fusion block (TIFB), which integrates the caption to enhance the restoration effect and extracts damage-type-related information to guide the diffusion model in image restoration. Specifically, the TIFB takes the LQ image , the corresponding textual caption c, and time step t as the input, and then it generates a fused time step embedding using the following formula:
Here, represents TIFB. Subsequently, the LQ image , caption c, and fused time step embedding are fed into a conditional time-aware network, , aiming to obtain pure noise:
Here, ⌢ represents concatenation. We use an efficient restoration U-shaped network (ERUNet) to predict the noise, and, finally, we optimize until convergence.
3.3. Text–Image Fusion Block
To leverage text information when recovering degraded images, we encode the caption and then integrate it into the diffusion model. Additionally, to make the model adaptable to different degradation types, a degradation-type classifier is required to encode the degradation type of the image. Our text–image fusion block (TIFB) integrates text encoding and degradation encoding into the time step encoding of the diffusion model, facilitating the restoration of images with different degradation types.
Pretrained language models have strong text comprehension capabilities. Therefore, we use a pretrained text encoder to build our network. As shown in Figure 2, our TIFB uses a pretrained CLIP text encoder to encode input caption c into a caption embedding, . It also uses a pretrained DA-CLIP [18] image controller to discern the degradation features of the LQ image and obtain the degradation embedding . The captions are processed by the text encoder of CLIP, which is a ViT-B/32 model, producing a 512-dimensional representation vector. This step encodes textual information into image-level features that align with high-definition image content, optimizing the restoration results with additional semantic signals. The LQ images are passed through the DA-CLIP image controller, also generating a 512-dimensional representation vector . The DA-CLIP image controller is derived from a fine-tuned CLIP image encoder, and its output vectors include image content features and image degradation features. Then, we concatenate and and embed them as prompts. The time step t of the diffusion model is encoded as a time embedding . Finally, we add the prompt to the of the diffusion model and pass them through a linear layer to obtain the fused time embedding . The prompt, which combines caption embeddings and degradation embeddings, can facilitate degradation-type classification in universal image restoration, thereby improving the restoration results.
3.4. Efficient Restoration Block
To efficiently extract contextual information and reduce the parameter count, inspired by ConvNeXtV2 [30] and ConvMixer [29], we designed an efficient restoration block (ERB). The core of the ERB is depthwise separable convolution (DSC), which is the combination of depthwise convolution and pointwise convolution, which are well known due to Xception [41] and MobileNet [42]. Depthwise convolution independently convolves each input channel using filters specific to each channel. Pointwise convolution combines the results of the depthwise convolution through pointwise convolution, utilizing a 1 × 1 convolution kernel. The separated depthwise convolution is used to extract the spatial dimension information, and the pointwise convolution is used to amalgamate the features learned by different channels to form the final output. DSC is commonly employed in lightweight model design to reduce the number of parameters and calculation quantity. Figure 3 details the structure of our proposed ERB: we employ depthwise convolution with a large kernel size to extract global information for each channel, followed by residual connections. After depthwise convolution, we apply two pointwise convolutions with an inverted bottleneck design to fully fuse spatial and channel information. The inverted bottleneck design has been explored using ConvNeXt [43]. The expanded hidden dimensions allow for a comprehensive fusion of the globally extracted spatial information through depthwise convolution. Additionally, we apply GELU activation and post-activation global response normalization (GRN) [30] after each convolution to enhance channel contrast and selectivity. Our ERB is defined as follows:
Here, represents the output feature map of layer l in the ERB, represents the layer normalization layer, represents the GLUE activate function, represents the depthwise convolution, and represents the pointwise convolution.
3.5. Efficient Restoration U-Shaped Network for Noise Prediction
As shown in Figure 3, we introduce the ERB into the encoder–decoder part of the efficient restoration U-shaped network (ERUNet). Compared to complex UNet architectures that include self-attention mechanisms, this lightweight design significantly reduces the computational complexity of the network. In tasks related to image restoration, the majority of the image pixels are known [44]. Therefore, large models with a high computational complexity are inefficient for IR tasks. Our ERUNet achieves optimal performance while remaining relatively lightweight.
As illustrated in Figure 3, our proposed ERUNet consists of a total of five layers from the top layer to the bottom layer, and it is divided into the encoder stage and the decoder stage. In the encoder stage, we use the ERB to extract multiscale global context information. After each ERB, a linear attention module is placed to capture long-range information, enhancing the model’s understanding of the overall structure of the feature. Then, a vanilla convolution with a stride of 2 is used to downsample the feature map. Since the bottom of the U-shaped structure retains high-level abstract features from the input, providing additional contextual information for the decoder, we utilize a cross-attention mechanism [45] to map the text embedding to the intermediate layer of UNet, enhancing the guidance of the caption in image restoration. In the decoder stage, we utilize multiple ERBs to decode features, and a nearest-neighbor interpolation is used to upsample the features, followed by a 3 × 3 convolution operation to adjust the number of channels. The numbers of ERBs in the encoder and decoder are denoted as and , respectively. Additionally, we place k ERBs in the bottom layer of the ERUNet.
3.6. Optimization and Inference
While Equation (6) provides a straightforward optimization objective for the ERUNet, training can become unstable when the diffusion model encounters complex image degradation. This is because predicting instantaneous noise at a given moment is challenging. Following previous work [31], we employ a maximum likelihood learning strategy to alter the optimization objective. To train the ERUNet, we optimize the following function:
Here, represents the theoretical state reversed from . The closed form of can be represented by the following equation:
For the proof, please refer to [31]. Briefly, we replace the distance between the predicted state and the ideal state with the distance between the predicted noise and the true noise. Given that the majority of pixels are known to be in the reversed state, this approach helps to stabilize the optimization process. In the inference phase, the pretrained samples the initial state , and the Euler–Maruyama method [46] iteratively solves the SDE. Algorithms 1 and 2 describe the training and inference processes of our ETDiffIR, respectively. Algorithm 1 Training of ETDiffIR
- Input:LR image , HR image , text caption c, total step T.
- 1: Initialization: Random sample , , .
- 2: repeat
- 3: ; ▷Enhance
- 4: ; ▷Predict noise
- 5: ; ▷Substitute score into Equation (6)
- 6: ; ▷Loss
- 7: ; ▷Gradient descent
- 8:until converged
Algorithm 2 Inference of ETDiffIRInput: LR image , text caption c, total step T.Output: The restored image .
- 1: Initialization: Random sample , is the pretrained ERUNet, T = 100. EM is Euler-Maruyama method.
- 2: for to 1 do
- 3: ; ▷Enhance
- 4: ▷Predict noise
- 5: ; ▷Substitute score into Equation (6)
- 6: ; ▷Reverse SDE
- 7: end for
- 8: ;
4. Experiments
In Section 4.1, Section 4.2 and Section 4.3, we introduce the experimental settings, including the experimental details, hardware specifications, datasets, and evaluation metrics. The performance comparisons and ablation experiments are specifically described in Section 4.4, Section 4.5 and Section 4.6, respectively.
4.1. Datasets
To validate the effectiveness of the ETDiffIR, we evaluated our method on three popular image restoration tasks: image denoising, image deraining, and image dehazing. We trained and evaluated the model separately in a universal setting and a single-task setting.
For the universal setting, following Airnet, we used WED [47], BSD400 [48], CBSD68 [49], Rain100L [50], and SOTS [51] for training and testing. For the image denoising task, we used the mixed datasets of WED and BSD400. The WED dataset contains 4744 high-quality training images, while the BSD400 dataset contains 400 training images. We added Gaussian noise with a variance of 50 to clean images from these datasets to obtain noisy images. The CBSD68 dataset was used for testing. For the image deraining task, the Rain100L dataset was employed, which comprises 200 clean–rainy image pairs for training and 100 image pairs for testing. For the image dehazing task, the SOTS dataset was used, consisting of 72,135 training images and 500 testing images. Finally, to train a unified model in the general setting, we combined the above datasets and trained a single model, which was then evaluated on multiple tasks.
For the single-task setting, we trained and evaluated the model using more challenging datasets and compared it against advanced methods for each task. The Rain100H [50] dataset was used for image deraining in the single-task setting. This dataset comprises 1000 clean–rainy image pairs for training and 100 image pairs for testing. For the image dehazing task, the RESIDE-6k [51] dataset was utilized, consisting of 6000 training images and 1000 testing images. For the image denoising task, we continued to train on the WED and BSD400 datasets, with CBSD68 for testing.
To train the ETDiffIR, we used the advanced visual language model MiniGPT-4 to generate synthetic captions for the HQ images in the dataset. Following TFRGAN [52], we also used the captions corresponding to the HQ images as prompts during testing. Since the inputs were high-resolution images, the generated captions were accurate. As shown in Figure 4, we directly used these captions to generate the text–image pairs.
4.2. Implementation Details
In this research, we designed an efficient diffusion probabilistic model guided by text to recover visually pleasing HQ images from LQ images. The network is designed to receive 3-channel image inputs and tokenized text inputs. During training, we performed data preprocessing by reading text–image pairs from the dataset. The images were cropped to 256 × 256 pixels patches and the corresponding captions are encoded into 512-dimensional tokens using CLIP ViT-B/32 text encoder. To enhance the model’s robustness, we performed random horizontal and vertical flips on the images for data augmentation. To ensure that our model has an appropriate size, the depth of our ERUNet is set to 4 layers. The inner-channel number in the ERUNet is set to 64. The number of ERBs in each depth of and is set to [2, 2, 2, 2] and [1, 1, 1, 1], respectively. There are two ERBs in the bottom layer of the ERUNet. Our experiments were carried out on a Linux server running Ubuntu 22.04. The CPU version was Intel Xeon w7-3465X, and two NVIDIA RTX A5000 graphics cards were used. The PyTorch version was 2.1.1, and the Python version was 3.8.18. We performed 600,000 iterations with a batch size of 12. The initial learning rate was set to 2 × . The cosine annealing learning rate adjustment strategy was employed. We utilized the AdamW optimizer, with set to 0.9 and set to 0.99. The total time steps for the diffusion process were set to T = 100.
4.3. Metrics
In this paper, we use five metrics to comprehensively evaluate the performance of the image restoration model. The peak signal-to-noise ratio (PSNR) and the structural similarity index (SSIM) [53] are used to measure the low-level difference between the restored result and the ground truth. To evaluate IR models from a perceptual perspective, we introduce learned perceptual image patch similarity (LPIPS) [54] and Fréchet inception distance (FID) [55]. These metrics measure the distance between the distribution of the restored images and the ground-truth images. Among them, FID considers more comprehensive feature statistics rather than solely focusing on image quality or diversity, and it is widely used to assess the generative performance of models.
4.4. Multiple Degradation Universal Restoration Results
We compared our proposed ETDiffIR with fouruniversal methods, namely, Stable Diffusion (SD) [23], AirNet [17], TKMANet [21], and Universal-IR [18]. These selected methods, as the mainstream methods in the field, ensure the comprehensiveness of the evaluation. Among them, SD and Universal-IR are diffusion-model-based methods, with SD also incorporating text prompts. Specifically, AirNet leverages contrastive learning to obtain degradation features from images and then restores the images through a series of regular convolutions and deformable convolutions [56]. TKMANet utilizes knowledge distillation to learn an universal model from multiple restoration models. Universal-IR is a diffusion-based model, and it shows good performance across multiple datasets. We followed the official experimental settings and retrained these comparative methods on a noisy–rainy–hazy combined dataset.
In Table 1, we report the quantitative comparison results in terms of distortion and perceptual metrics with the state-of-the-art (SOTA) IR approaches in the universal restoration setting. It can be observed that, in the majority of cases, our method outperforms most of the baselines in terms of perceptual metrics, while also showing good performance in terms of distortion metrics. Specifically, our method outperforms the second-best method (Universal-IR), with an average FID improvement of 2.53 across the three degradation types. These results indicate that our method is capable of providing a robust high-quality data distribution for various degradation types, highlighting its strong generative capabilities. Specifically, ETDiffIR outperforms the second-best method (TKMANet) by 1.16 dB in terms of the PSNR on the image dehazing task. From the visual comparisons in Figure 5, it can be observed that our method is able to remove fog at different levels, generating visually pleasing dehazed images. In Table 1, it can be seen that, on the image deraining task, the proposed ETDiffIR provides a substantial gain of 0.8 dB compared to Universal-IR [18]. From the visual comparison in Figure 6, it can be observed that ETDiffIR effectively removes rain streaks, demonstrating strong image reconstruction capabilities. Finally, for the image denoising task, on high-level noise with = 50, our method outperforms the Universal-IR [18] method with a significant improvement of 7.06 in terms of FID. Ours-LQ represents the results obtained from testing using captions corresponding to LQ images. When captions corresponding to LQ images are used for restoration, the captions tend to describe the contents of the image less accurately due to the damage in the LQ images. Consequently, all the metrics are slightly inferior compared to the results obtained using the captions corresponding to the HQ images. Figure 7 displays the qualitative comparison results, demonstrating that our method produces denoised images that are more visually pleasing and closer to human perception.
4.5. Single Degradation Results
In this section, we evaluate the performance of our ETDiffIR in a single-task setting, training a separate model for each restoration task. We evaluate our model on three distinct degradation tasks. For a more comprehensive evaluation of our model’s performance, we make comparisons using three datasets: we compare image dehazing on the RESIDE-6k dataset [58], image deraining on the Rain100H dataset [59], and image denoising on the CBSD68 dataset [49]. For all three tasks, we compare our method with the prevailing methods in each domain using: GCANet [60], GridDehazeNet [61], and DehazeFormer [62] for image dehazing, and JORDER [63], PReNet [64], and MPRNet [65] for image deraining. We also make a comparison with the advanced multiple-degradation-specific method MAXIM [5] and IR-SDE [31]. Table 2 summarizes the quantitative comparison results on different datasets. On each dataset, our method demonstrates superior performance in terms of perceptual metrics.
4.6. Ablation Studies
In Section 4.6.1, we describe the ablation experiments conducted to demonstrate the effectiveness of the guidance generated by the text–image fusion block (TIFB) and efficient restoration UNet (ERUNet). In Section 4.6.2, we analyze why textual prompts can enhance image restoration performance.
4.6.1. Importance of TIFB and ERUNet
To investigate the overall effectiveness of each component in ETDiffIR, we removed the text–image fusion block (TIFB) and efficient restoration UNet (ERUNet) to form the three models reported in Table 3. Baseline represents the model without TIFB and using vanilla UNet for noise prediction. By comparing Baseline and Model-1, we found that EANet demonstrated a 3.4% improvement in terms of FID compared to UNet, while reducing the parameter count and FLOPS by 31.14% and 41.24%, respectively. By comparing Model-1 and our model, we observed that the parameter count of the model increased after adding TIFB, mainly due to the inclusion of the pretrained CLIP text encoder and DA-CLIP image controller in the TIFB. However, the model’s FLOPS only increased by 0.39%, and there was a significant improvement in FID.
Furthermore, a visual comparison of the models with and without the proposed TIFB is shown in Figure 8. Specifically, the restored images using the TIFB exhibit lower distortion and higher quality. For instance, in the images generated by the TIFB, the color of the grass is more vivid and distinct. Figure 9 illustrates the training curves of our proposed model compared to those of the model without the TIFB in three different image restoration tasks: image denoising, image deraining, and image dehazing. It can be observed that our model’s training is significantly superior.
4.6.2. Effect of Text Prompts
In Figure 10, we compare the restoration results using different captions. As shown, replacing captions with empty text or using inappropriate captions leads to poor image details, while appropriate prompts yield better restoration results. For the upper example, using incorrect captions (i.e., “a cup of milk”) results in insufficient dehazing. For the lower example, using captions results in more accurate details compared to not using captions. This is because text prompts can provide the model with high-level semantic features. These results confirm the effectiveness of text prompts.
5. Discussion
The development of deep-learning-based image restoration methods has been rapid and has achieved good results. Due to the potential severe loss of information in low-quality images, the development of image restoration methods is limited. In this paper, we analyzed the limitations of diffusion models in image restoration tasks and proposed a text-guided diffusion model to overcome these limitations in an universal image restoration task. We conducted comparative experiments between the proposed method and other state-of-the-art methods. The experimental results indicate that our model demonstrates improved performance in image restoration on multiple tasks. Additionally, we anticipate the potential of using text prompts to assist image reconstruction in obtaining restoration strategies that are more in line with human visual perception.
The TIFB in ETDiffIR is designed to incorporate text prompts to assist in image restoration. The ERUNet in ETDiffIR is designed to combine text prompts and predict noise conditionally. Specifically, the TIFB utilizes a pretrained CLIP text encoder to encode the textual description corresponding to the image. This encoding is then fused with the degradation encoding obtained from the pretrained DA-CLIP image controller to generate a prompt. Finally, we use this prompt, along with a cross-attention mechanism, to assist the denoising network in obtaining satisfactory results. In the ERUNet, the efficient restoration module extracts global information for each channel and efficiently integrates spatial and channel features. We conducted related ablation experiments to elucidate the functionalities of the TIFB and ERUNet. The related experiments indicate that removing the TIFB and ERUNet leads to an increase in FID, demonstrating the importance of these two components for image restoration.
However, our work still has some limitations. As shown in Table 1 and Table 2, the proposed method achieved competitive results across various metrics for the deraining and dehazing tasks. However, for image denoising, the proposed method performed poorly in terms of the distortion metrics, PSNR and SSIM. Following previous work [18], we set the noise value to a challenging 50. While using a lower noise value would indeed result in better distortion metrics, denoising large noise is more valuable for research. As a universal restoration model, our model needs to consider the universality of restoration, taking into account the characteristics of other restoration tasks. Additionally, another reason is that the diffusion process is difficult to recognize from Gaussian noise. When using diffusion models for image restoration, additional noise introduced from the Wiener process makes it difficult for the model to distinguish between the Gaussian noise that needs to be restored and the noise from the diffusion process in image denoising tasks. Additionally, due to the iterative sampling required by the diffusion model, our method lacks real-time capabilities. In this paper, we only used synthetic datasets to train the model and did not train it on real degraded datasets. Therefore, the proposed model may require additional optimization for specific use cases.
6. Conclusions
In this paper, we designed an effective diffusion probabilistic model guided by text to recover visually pleasing high-quality images from low-quality images. To achieve this, we introduced a text–image fusion module to fully exploit textual information. The text–image fusion block (TIFB) utilizes a pretrained CLIP text encoder to embed textual descriptions corresponding to the images. These embeddings are then fused with image embeddings provided by a pretrained DA-CLIP image controller. Additionally, the proposed efficient restoration U-shaped network (ERUNet) demonstrates superior performance in noise prediction compared to vanilla UNet. Our extensive experiments demonstrate that our proposed method is competitive with state-of-the-art approaches.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Chen C. Shi X. Qin Y. Li X. Han X. Yang T. Guo S. Real-world blind super-resolution via feature matching with implicit high-resolution priors Proceedings of the 30th ACM International Conference on Multimedia Lisbon, Portugal 10–14 October 202213291338
- 2Ji S.W. Lee J. Kim S.W. Hong J.P. Baek S.J. Jung S.W. Ko S.J. XY Deblur: Divide and conquer for single image deblurring Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition New Orleans, LA, USA 21–24 June 20221742117430
- 3Yao M. Huang J. Jin X. Xu R. Zhou S. Zhou M. Xiong Z. Generalized Lightness Adaptation with Channel Selective Normalization Proceedings of the IEEE/CVF International Conference on Computer Vision Paris, France 4–6 October 20231066810679
- 4Jiang K. Wang Z. Yi P. Chen C. Huang B. Luo Y. Ma J. Jiang J. Multi-scale progressive fusion network for single image deraining Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Seattle, WA, USA 13–19 June 202083468355
- 5Tu Z. Talebi H. Zhang H. Yang F. Milanfar P. Bovik A. Li Y. Maxim: Multi-axis mlp for image processing Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition New Orleans, LA, USA 21–24 June 202257695780
- 6Chen J. Zhao G. Contrastive Multiscale Transformer for Image Dehazing Sensors 202424204110.3390/s 2407204138610257 PMC 11014309 · doi ↗ · pubmed ↗
- 7Zhao M. Yang R. Hu M. Liu B. Deep Learning-Based Technique for Remote Sensing Image Enhancement Using Multiscale Feature Fusion Sensors 20242467310.3390/s 2402067338276366 PMC 11154389 · doi ↗ · pubmed ↗
- 8Xu J. Chen Z.X. Luo H. Lu Z.M. An efficient dehazing algorithm based on the fusion of transformer and convolutional neural network Sensors 2022234310.3390/s 2301004336616639 PMC 9823512 · doi ↗ · pubmed ↗