Deep learning with mixup augmentation for improved pore detection during additive manufacturing
Bulbul Ahmmed, Elisabeth G. Rau, Maruti K. Mudunuru, Satish Karra, Joshua R. Tempelman, Adam J. Wachtor, Jean-Baptiste Forien, Gabe M. Guss, Nicholas P. Calta, Phillip J. DePond, Manyalibo J. Matthews

TL;DR
This paper uses deep learning with Mixup augmentation to improve pore detection in additive manufacturing, achieving high accuracy on imbalanced datasets.
Contribution
The novel contribution is applying Mixup augmentation to enhance ML model performance for rare pore detection in AM.
Findings
Mixup augmentation improved model accuracy from 95% to 99% on test datasets.
Optimal Mixup parameters were identified for CNN performance in pore prediction.
Dataset size was found to influence model performance in AM monitoring.
Abstract
In additive manufacturing (AM), process defects such as keyhole pores are difficult to anticipate, affecting the quality and integrity of the AM-produced materials. Hence, considerable efforts have aimed to predict these process defects by training machine learning (ML) models using passive measurements such as acoustic emissions. This work considered a dataset in which keyhole pores of a laser powder bed fusion (LPBF) experiment were identified using X-ray radiography and then registered both in space and time to acoustic measurements recorded during the LPBF experiment. Due to AM’s intrinsic process controls, where a pore-forming event is relatively rare, the acoustic datasets collected during monitoring include more non-pores than pores. In other words, the dataset for ML model development is imbalanced. Moreover, this imbalanced and sparse data phenomenon remains ubiquitous across…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
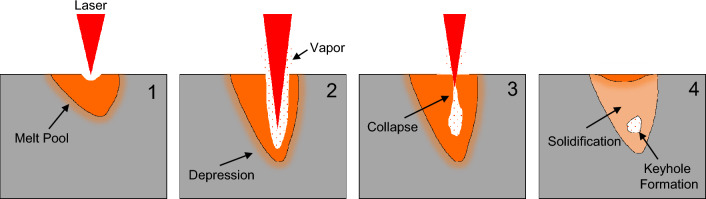 Figure 1
Figure 1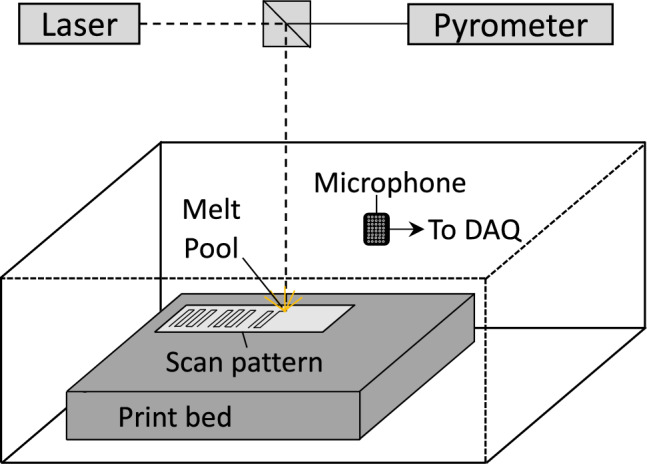 Figure 2
Figure 2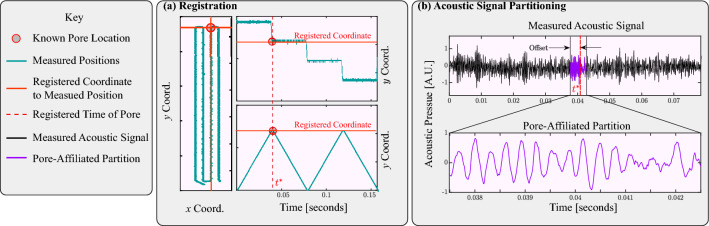 Figure 3
Figure 3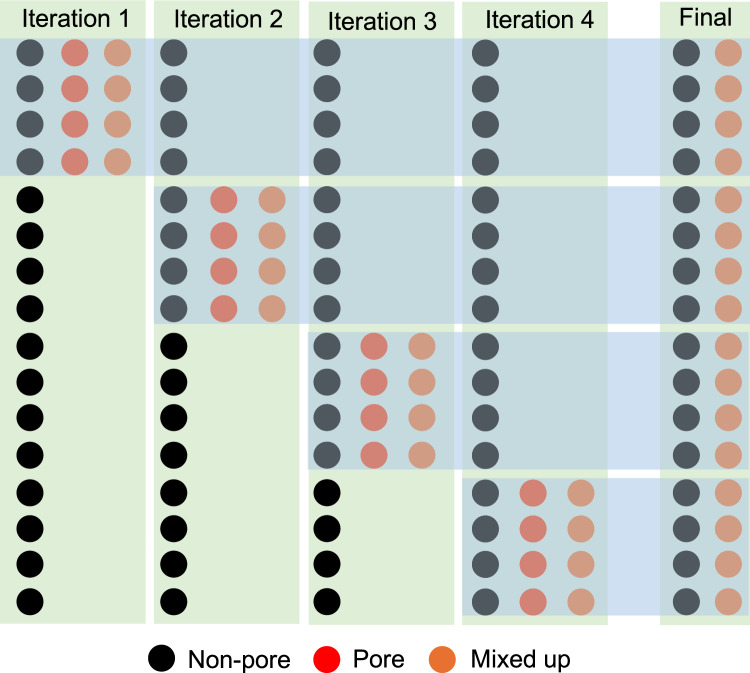 Figure 4
Figure 4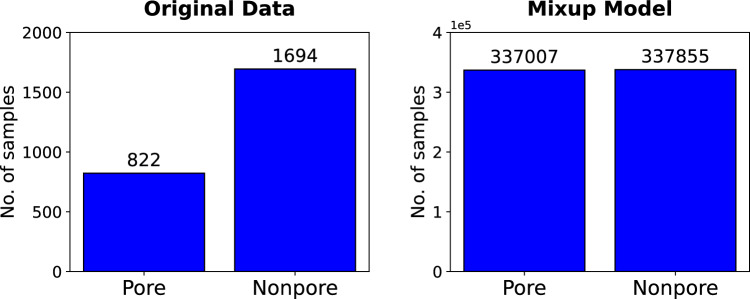 Figure 5
Figure 5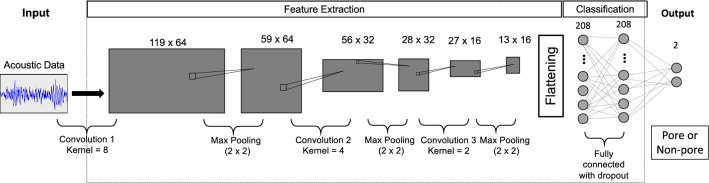 Figure 6
Figure 6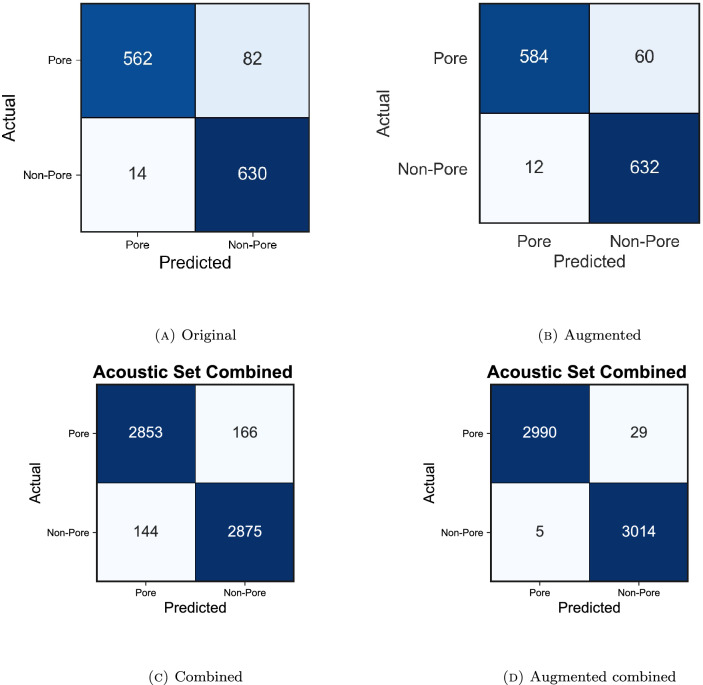 Figure 7
Figure 7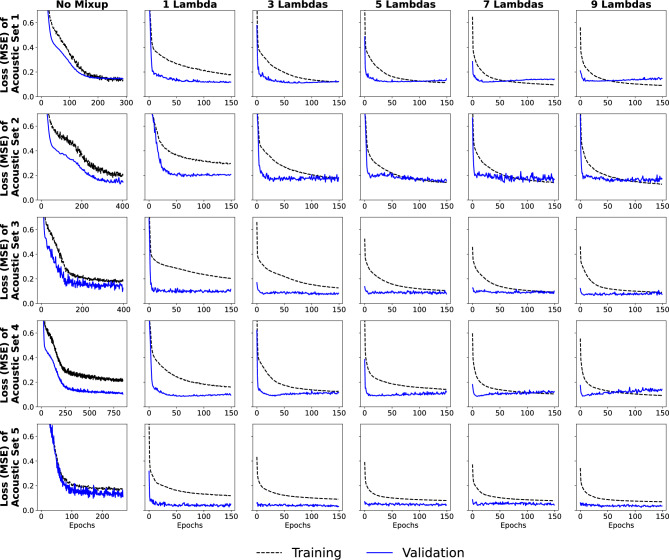 Figure 8
Figure 8- —LANL LDRD
- —http://dx.doi.org/10.13039/100006132Office of Science
- —EMSL, PNNL
- —NSF
- —LLNL
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsYouth Substance Use and School Attendance · Homelessness and Social Issues · Child and Adolescent Psychosocial and Emotional Development
Introduction
Additive manufacturing (AM) is a process of creating objects by adding layers of material. AM has revolutionized manufacturing in the medical, aerospace, and automotive industries because of its wide range of applications, from large-scale production to one-of-a-kind objects doing all with low material consumption^1–4^. With the AM technology, one can design and develop custom designs and complex shapes that are difficult or impossible through conventional production means^5^.
Laser powder bed fusion (LPBF) is an AM technology that fuses powder material to form three-dimensional objects. One of the primary challenges in LPBF-enabled AM manufactured parts is the reproducibility of the design due to defect formation^5^. Some common defects associated with LPBF are surface roughness, dimensional accuracy, balling, cracking, and formation of unintentional pores^1,6–8^. Porosity defects are particularly critical because they have a significant impact on fatigue performance^9^. During the LPBF process, a depression, which can transition to a keyhole, forms due to metal vaporization (Fig. 1)^10^. Under certain conditions, this keyhole can become unstable, causing bubbles in the melt pool^11,12^. Rapid solidification of the melt pool traps these bubbles in the solid part, resulting in pores that remain in the final part, known as keyhole pores. This formation of pores can cause significant quality issues for the manufactured part, such as sub-par mechanical behavior. Methods such as X-ray tomography are available to determine the size and location of pores ex situ. However, this technique is complex and costly, and the intricate geometries of additive manufacturing only sometimes allow for straightforward imaging. Hence, pore defects must be determined, preferably in situ, to remediate the formation by modifying the LPBF process parameters.
Recently, machine learning (ML) techniques have been used to classify pores and non-pores from acoustic emissions^13–21^. Pandiyan et al., 2020^19^ performed blind clustering to demonstrate that pore-associated LPBF sintering conditions cluster in a spectra-based feature space. However, they could not localize these findings because no spatiotemporal registration exists within their work. Tempelman et al.^14^ trained and tested an ML model utilizing a support vector machine (SVM) on a spatiotemporal registered acoustic data of LPBF. The high-throughput acoustic data were collected using a microphone in the print chamber at 100kHz. They were able to classify keyhole pores from the waveforms with an accuracy of up to 97%. Another key finding of this research is that spectral featurization (e.g., frequency bands) was essential for predicting pore formation. Further studies^14^ investigated the role of power spectral densities (PSDs) on pore detection. Specifically, on this same acoustic dataset, Tempelman et al.^14^ used non-negative matrix factorization with customized k-means clustering (NMFk)^22–24^ to correlate PSDs with pore formation. An outcome of this analysis is that NMFk blindly (no defined outputs) confirms that the power spectra are the important spectral patterns to detect pore formation. This NMFk decomposition projects the high-throughput data onto a lower-dimensional space, allowing further processing and development of latent feature space or key signatures, successfully classifying the pore formation. The discovered pore formation signature was a broadband signal with dominant frequencies between 10 kHz and 40 kHz that agrees with the work by Pandiyan et al., 2020^19^. The lower-dimensional projected data was then used to build a series of unsupervised and supervised ML classifiers. Classification of our test datasets was performed based on a supervised ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\sim$$\end{document} 95% accuracy) and unsupervised ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\sim$$\end{document} 90% accuracy) training labeling scheme and using a suite of ML classifiers. More recently, computational studies performed byKhairallah et al. ^25^ have predicted the onset of melt-pool oscillations immediately preceding keyhole formation in a similar frequency range to those found important in the References^13,15,19^.
In a recent study, Ren et al.^20^ performed computational predictions of melt pool oscillations, which were corroborated with thermal measurements of the melt pool in a real-time X-ray radiography experiment to train a machine learning model. This resulted in near-perfect predictions of in situ pore detection for single-scan experiments, which delivered invaluable context to the dynamics of the melt pool as pore formation occurs and validated the frequency-driven approaches of previous acoustics studies. However, this study was limited to single-track scans in an X-ray beamline setting rather than commercial-level builds, although a compelling data registration scheme was presented for future works.
To this end, the focus of ex situ registered experiments with commercially relevant datasets remains a topic worthy of further study. In the context of passive acoustics-based monitoring for pore-registered commercial-level experiments^14,15^), accuracy scores are likely not to represent pores because the number of pores is fewer than non-pores due to the intrinsic control of the AM process. Because the likelihood of a pore-forming event is less than non-pore, the labeled acoustic data has more non-pore samples than pore samples, naturally leading to an imbalanced problem^26^. Moreover, datasets that register pores locations to AM process measurements are notoriously small in size and sparse in the number of recorded pores, as such data collection campaigns remain highly nontrivial endeavors^26^. For such a dataset, accuracy scores covering both pores and non-pores may mispredict new datasets. Additional data needed to balance an existing dataset can also be expensive or inaccessible to collect to avoid such pitfalls. Data augmentation, oversampling, and undersampling techniques are generally used to address imbalanced data^27–32^. Since one would ideally like to utilize as much of the data as possible, it is disadvantageous to use undersampling on smaller datasets. Because the datasets used in this study are small, we use oversampling to tackle the class imbalance. The effectiveness of oversampling data augmentation in enhancing the ML model’s training and prediction for AM processes has yet to be compared between the original and augmented datasets.
Data augmentation techniques have been increasingly applied in additive manufacturing research to enhance the performance and generalization of machine learning models. These methods aim to artificially increase the size and diversity of the training dataset by applying various transformations to the existing data. Some common data augmentation techniques used in additive manufacturing include geometric transformations, such as rotation, scaling, and flipping^33^, which help the ML model learn invariance to these transformations. Another approach is the use of generative adversarial networks (GANs) to synthesize new, realistic samples that mimic the distribution of the original data^34–37^. While these techniques have shown promising results, they may not effectively address the challenges of imbalanced datasets, where certain classes (e.g., defects) are significantly underrepresented. In contrast, the Mixup algorithm^38^ directly tackles the class imbalance problem by creating new samples through a weighted combination of input features and their corresponding labels. Mixup generates a more balanced and diverse dataset by interpolating between samples from different classes, enabling the ML model to learn more robust decision boundaries. This makes Mixup particularly well-suited for additive manufacturing applications, where the detection and classification of rare defects or anomalies are of critical importance.
The primary objectives of this study are: (1) apply ML on original and augmented acoustic datasets to predict pore formation, (2) provide performance metrics in terms of pore and non-pore formation events, and (3) provide a guideline on when to use original or augmented data for training ML models. We trained and tested a convolutional neural network (CNN) utilizing one-dimensional kernels and filter sizes on five different acoustic datasets collected during LPBF experiments to achieve this objective. We performed data augmentation using Mixup^38^, a weakly supervised labeling process on this collected experimental data. The performance of the trained CNN model is expressed in: (1) F1 scores for pore and non-pore formations and (2) accuracy (combined F1 scores for both pore and non-pore formations) along with the non-pore to pore ratio control in all five datasets. Furthermore, we describe how the dataset size impacts CNN model performance and then assess the effect of data augmentation on ML model performance/efficiency. Finally, we propose guidelines for when a user can use original or augmented data for in situ monitoring of the AM process.Figure 1. Schematic of the formation of a keyhole pore during the LPBF process. (1) Formation of the initial melt pool. (2) Formation of depression. (3) Collapse of the materials along the walls of the depression due to overheating. (4) Formation of a keyhole pore with entrapped vapor and the surrounding material undergoes rapid solidification.
Methods
Data acquisition and processing
The LPBF experiments were performed at Lawrence Livermore National Laboratory with variable laser powder and speed, which were presented in^13–15^. The system utilized a 1070 nm continuous wave 400 W Yb-fiber with a beam diameter of approximately 100 μm at the focal point. The material used in all studies was 316L stainless steel powder with 50 μm layer thickness placed on 316L plates. Single patches measuring between \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$2\times 5$$\end{document} mm^2^ and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$1\times 5$$\end{document} mm^2^ were melted with laser powers ranging between 50–375 W and scan speed between 100 and 400 mm/s at a 100 μm hatch spacing. The physical distance that the beam has moved is between 1 and 4 mm based on laser speeds between 100 and 400 μm/s. A microphone recorded acoustic measurements affixed to the build chamber positioned approximately 25 cm from the center of the build plate. Data was recorded at a sampling rate of 100 kHz with an AC-coupled low-pass filter at 6 dB via a Stanford Research System preamplifier. The distance from the microphone to the tracks was far greater than the size of the lasing tracks themselves, meaning that acoustic measurements were largely agnostic to the specific positions or direction of the laser. Acoustic emissions of the build process are recorded using an acoustic transducer synchronized to the x and y coordinates of the laser using a similar experimental design described in Reference^39^ and data registration scheme described in Reference^13^. The schematics presented in Figs. 2 and 3 illustrate the data acquisition and co-registration process. Data are collected at a sampling rate of 100 kHz with an AC-coupled low pass filter of 6 dB and a 10X gain via a Stanford Research Systems preamplifier. Post-build X-ray radiography was performed at beamline 8.3.2 of the Advanced Light Source at Lawrence Berkeley National Laboratory to identify the spatial locations of pores ex-situ. Then, the laser position synchronizes pores with the corresponding acoustic emission time histories. An important limitation of this experimental dataset is that it only looks at single-layer scans and cannot probe the lack of fusion pore formation events.Figure 2A schematic of an experiment to collect acoustic emission data during the LPBF process to assess pore formation.Figure 3. The spatial-temporal registration scheme involves two main steps. First, the pore location(s) identified in radiography images are registered to the corresponding laser-measured locations on an \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$x-y$$\end{document} coordinate grid (a). Second, the time(s) at which the measured x and y coordinates align with a registered pore are denoted as \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$t^*$$\end{document} , representing the registration time(s) (b). The acoustic signal is then partitioned into a pore-affiliated segment based on the registered pore time (t) and a random offset. This segmentation allows for the isolation and analysis of the acoustic data associated with the registered pore(s).
The acoustic data was divided into 10 ms windows and labeled as either pore or non-pore based on radiography images. The start of the acoustic waveform windows was offset so that the pores appeared randomly within the 10 ms window. An additional offset was included to compensate for the time-of-flight of the acoustic signal based on the speed of sound in Argon gas with an assumed distance of 25 cm separating the melt pool from the acoustic sensor. This window selection ensures that the pores sometimes occur within the same position in their corresponding acoustic window. This acoustic window partitioning replicates an in situ monitoring scheme where data is likely to be randomly partitioned into segments without knowing the location of a possible pore before ML analysis. The remaining acoustic emissions are labeled as non-pores.
Acoustic data alignment (or co-registration)^40^ with the pores has already been performed before the data is provided to ML model training. To account for the time-of-flight delay, we apply an offset when collecting time series partitions affiliated with pores based on the speed of sound in Argon and an approximate distance of 25 cm between the acoustic source and the microphone (roughly a 0.77 ms delay). Table 1 reports the acoustic microphone calibration data. Additionally, please refer to Sec-2 and references within Tempelman et al.^14^, which provides more information on the acoustic emission data collection process from the LBPF experiment.Table 1. Acoustic microphone calibration data.Maximum sound level (dB SPL)Sound pressure (Pa)Output signalNoise floor measured (V)Noise floor mic (mV)Dynamic range (SNR)Dynamic range (dB)12020159.620.1279.8183.04
Data description
We used acoustic datasets from five different experimental trials to train and test ML models, each corresponding to a different substrate used in the LPBF machine. In addition, we also used a combination of all these five datasets for training and testing, which we refer to as a combined dataset. Table 2 summarizes the details of the training and testing data split and the pore/non-pore labels. Each of these samples within the 10 ms window had a time series of 1000 points. The trained ML models are then used to classify the test data samples as either pore or non-pore. All five experimental acoustic datasets have a different number of pores and non-pores and exhibit class imbalance. The non-pore-to-pore ratio of acoustic sets 1, 2, and 4 is greater than 3, while the ratio is less than 2 for acoustic sets 3 and 5.
Note that each set (i.e., 1, 2, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\ldots$$\end{document} , 5) refers to an individual LPBF experiment. During the experiment, acoustic emissions are collected for each set. As the collected data is imbalanced, stratification is performed to split this data into two sets: training (imbalanced) and testing (balanced). That is, stratified sampling offers a significant advantage in this context. Since the population density of pores (air pockets within the material) varies significantly across different regions within each experiment, stratified sampling ensures the ML model receives a balanced representation of these variations. This, in turn, helps the CNNs trained on this data achieve more consistent accuracy across different regions of the LPBF experiments, as shown in Fig. 7, Tables 3 and 4. Furthermore, combining the acoustic data from all five experiments into a single training set allows us to compare the predictive performance of the CNNs across different sets. This comparative analysis provides valuable insights into the models’ generalizability in the LPBF process. Undersampling techniques can be employed alongside stratified sampling to address the class imbalance within the training set. Undersampling reduces the representation of the majority class to match the size of the minority class. The testing set size is carefully chosen to ensure it contains enough samples for a statistically robust evaluation of CNN’s generalizability under limited and imbalanced training data. By incorporating such a data preprocessing step, we can ensure the ML models are trained on a balanced and representative dataset, ultimately leading to more robust and generalizable CNN predictions for real-world LPBF applications.Table 2A summary of training and testing datasets for developing ML models.SetTraining dataTesting dataSamplesPoresNon-poreRatioSamplesPoresNon-poresRatio1370732974.112886446441.02222421804.313766886881.037032494541.810885445441.04415983173.212616306311.058063604461.29754625131.1Combined251682216942.066038301930191.0The five sets refer to the data acquired from five different LPBF experiments. The details of the combined dataset are also shown. Training data are the samples used to train the model, and the testing data are used as blind data to test overall ML model performance. Non-pore to pore ratio refers to the number of data points mixed to make a balanced dataset.Table 3ML model results comparing original data to one \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\lambda$$\end{document} for data augmentation.Acoustic setOriginalAugmented#T. ratioF1 poreF1 non-poreAccuracyF1 poreF1 non-poreAccuracy14.10.920.930.930.940.950.9424.30.930.930.930.940.940.9431.80.940.930.940.950.950.9543.20.890.910.900.900.920.9151.20.940.940.940.920.930.93Combined2.060.950.950.950.990.990.99Here, T. ratio refers to non-pore to pore ratio in each acoustic dataset.Table 4. Comparison of true positive (TP), true negative (TN), false positive (FP), and false negative (FN) classifications of original datasets and augmented datasets (with one \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\lambda$$\end{document} value) for each respective acoustic set.SetOriginalAugmentedTPTNFPFNTPTNFPFN1562630148258463212602618657317064565434433500523214450752618374515621101155226274108543048825324064991456Combined2853287516614429903014295
Data augmentation
Mixup data augmentation is a technique that enhances ML model performance by addressing class imbalance problems and promoting better generalization^32,38,41,42^. In the Mixup approach, given a training dataset with input and output, augmented data is created by randomly selecting two samples and assigning weights \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\lambda$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$1-\lambda$$\end{document} to each instance, where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\lambda$$\end{document} is randomly drawn from a beta distribution^38^. The beta distribution is a continuous probability distribution defined on the interval [0, 1]. It is commonly used to model random variables representing proportions or probabilities^43^. The resulting input-outputs are combined using linear interpolation, generating weakly labeled data. Training on weakly labeled data introduces a regularization effect on the ML models, which helps prevent overfitting and improves the neural network’s ability to generalize to unseen data^44,45^. By reducing the reliance on exact (or true/strong) labels and allowing the model to learn from a mixture of samples, Mixup effectively mitigates the impact of class imbalance, where the minority class (in this case, pores) is underrepresented compared to the majority class (non-pores). As a result, Mixup data augmentation strikes a balance between fitting the minority class and the majority class. This avoids underfitting, leading to improved ML model performance. By creating augmented (or weakly labeled) samples that blend the characteristics of different instances, Mixup enables the ML model to capture a broader range of variations. Hence, trained ML models become more robust in detecting potential discrepancies in the collected experimental data. This technique has proven to be effective in various domains, including image classification and segmentation tasks, where the class imbalance is a common challenge^32,38,41,42^. The data augmented sample \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$(\hat{x}, \hat{y})$$\end{document} can be represented by:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \hat{x}&= \lambda \times x_{i} + (1-\lambda ) \times x_{j}\nonumber \\ \hat{y}&= \lambda \times y_{i} + (1-\lambda ) \times y_{j} \end{aligned}$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$(x_i, y_i)$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$(x_j, y_j)$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$x_i, x_j \in X$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$y_i, y_j \in Y$$\end{document} , which are strongly labeled samples. X is the input time-series vector, and Y is the target pore or non-pore labels. As we are working with a classification problem, we assign a value of 1 to \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$y_i \in Y$$\end{document} for a pore and 2 for a non-pore. \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\hat{y}$$\end{document} is rounded to the nearest integer during interpolation. This process adds noise to the datasets, forcing the neural network to learn from them.
We used the non-pore-to-pore ratios to optimize the number of combinations or ‘mixups’ between two samples with our class imbalance data. By re-using the uncommon event (in this case, pores) multiple times, we effectively increase the size of the training data set. This Mixup-enabled data augmentation strategy accurately trains ML models by reducing the emphasis on a handful of identical rare events, reducing reliance on uncommon events, increasing robustness when learning from corrupt pore/non-pore labels, and improving generalization when faced with adversarial examples. For example, if there are 16 non-pore and four pore samples, the non-pore-to-pore ratio would be 4:1. As indicated in Fig. 4, four iterations of this are performed for each test. In the first iteration, augmented training data is constructed from combinations between the four pore acoustic events and the first four non-pore data. In iteration 2 (Fig. 4), the same four-pore acoustic events are mixed with the subsequent four non-pore events. This Mixup process continues for the next two iterations until an approximate 1:1 ratio number is met. For the combined dataset (Table 2), the original non-pore-to-pore ratio is approximately 2:1. Accordingly, we perform two iterations for this case, which leads to a balance in the data. Figure 5 shows the pore and non-pore sample distribution for the combined dataset before and after this Mixup process. The ratio improves from 2:1 (1694 non-pore and 822 pore samples) to 1:1 (337855 non-pore and pore 337007 samples).
The data augmentation method described in the preceding paragraphs discusses a one-to-one ratio between the unique combination and the synthetically constructed sample (one augmented selection for each combination). Multiple \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\lambda$$\end{document} values were used to generate more samples per combination to increase the sample size further. For example, two different \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\lambda$$\end{document} values will construct two augmented samples for one combination. This research analyzed 1–10 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\lambda$$\end{document} values for each acoustic set and 1–3 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\lambda$$\end{document} values for the combined dataset.
Reusing pores many times increases the size of the training data set, facilitating better training of ML models by placing less emphasis on a handful of identical pores. Therefore, a trained ML model barely memorizes the identical uncommon events, which increases the robustness of neural networks when learning from mixed pore/non-pore labels. Moreover, such ML models generalize better when faced with adversarial examples.Figure 4. This is a schematic of a non-pore:pore = 4:1 Mixup method, where an equal number of non-pore and pore samples are mixed to generate mixed-up data. This process is repeated until the pore data is mixed with all non-pore data, making the dimensions of non-pore and mixed-up data the same.Figure 5. Distribution of pore and non-pore samples before and after data augmentation.
ML-model using CNN
We develop a CNN to learn a mapping function between acoustic raw time series and pore/non-pore labels using the original and augmented training data. The convolutional neural layers and associated kernels allow us to learn this mapping by extracting representative features from the acoustic raw time series. Max pooling was employed to condense the number of abstract features, which are finally connected to a dense layer. It calculates the maximum value in each patch of each feature map. The convolutional layer outcomes are downsampled, and the pooled feature maps provide the most present feature in the patch. Dropout is used in these dense layers to reduce overfitting. Moreover, early stopping was used to overcome overfitting. Mathematically, this CNN architecture for acoustic measurement classification can be described as:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \textrm{output}\left( N_i, C_{\textrm{output}_j}\right) =F\left( \sum _{k=1}^{C_{\textrm{input}}}\varvec{W} \left( C_{\textrm{output}_j},k\right) *\textrm{input}\left( N_i, k\right) +\varvec{b}\left( C_{\textrm{output}_j}\right) \right) \end{aligned}$$\end{document}where N is the batch size, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$C_{\textrm{input}}$$\end{document} is the number of acoustic measurements in the 10 ms window, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$C_{\textrm{output}}$$\end{document} is the value of pore and non-pore labels (i.e., 2), \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{b}$$\end{document} is the bias, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{W}$$\end{document} is the weight, F is an activation function, and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$*$$\end{document} is a valid cross-correlation operator. Specifically, within the context of our problem:
- \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textrm{Output}\left( N_i, C_{\textrm{output}_j}\right)$$\end{document} : Represents the output value at the i-th sample in the batch ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$N_i$$\end{document} ) for the j-th output channel ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$C_{\textrm{output}_j}$$\end{document} ). This indicates the network produces multiple outputs corresponding to different pore/non-pore classifications.
- F: Activation function that introduces non-linearity. Common choices include ReLU or sigmoid.
- \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\sum _{k=1}^{C_{\textrm{input}}}$$\end{document} : Summation over all input channels (k) from 1 to \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$C_{\textrm{input}}$$\end{document} .
- \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{W}\left( C_{\textrm{output}_j},k\right)$$\end{document} : Weight matrix specific to the j-th output and k-th input channels. This captures how the network learns to combine features from different input acoustic emission measurements.
- \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$*$$\end{document} : This cross-correlation operator differs from the typical convolution used in CNNs for images. It performs a ‘sliding dot product’ between the filter (weights) and the input, resulting in the same output size as the input. Here, it extracts correlations within the 10 ms window of acoustic emission measurements.
- \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textrm{input}\left( N_i, k\right)$$\end{document} : Represents the k-th acoustic measurement for the i-th sample in the batch.
- \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{b}\left( C_{\textrm{output}_j}\right)$$\end{document} : Bias term for the j-th output channel. The above Eq. (2) calculates a single neuron’s activation in the CNN’s output layer. The network essentially learns weights ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{W}$$\end{document} ) to combine different acoustic measurements (captured by the input channels) within a 10 ms window using valid cross-correlation. The activation function (F) then introduces non-linearity to create a more expressive pore/non-pore classification model.
We minimize sparse categorical cross-entropy loss function ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathcal {L}$$\end{document} ) to find the best model:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \mathcal {L}(\varvec{y}, \varvec{\hat{y}}) =-\sum _{i=1}^{N}y_{i}\textrm{log}\left({ \hat{y}}_{i}\right) , y_i \in \varvec{y}, \hat{y}_{i} \in \varvec{\hat{y}} \end{aligned}$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{y}$$\end{document} is the ground truth, and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{\hat{y}}$$\end{document} is the prediction. \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$y_i$$\end{document} is the true label (pore or non-pore) for the i-th sample. \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\hat{y}_{i}$$\end{document} is the predicted probability for the i-th sample belonging to the pore class (other classes will have their own probabilities summing to 1).
The Eq. (3) defines the sparse categorical cross-entropy loss function, commonly used for multi-class classification problems. It penalizes the network for making incorrect predictions, aiming to minimize the overall loss during training. Here, the network strives to minimize the difference between the predicted pore class probabilities ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\hat{y}_{i}$$\end{document} ) and the true labels ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$y_i$$\end{document} ).
For the activation function, we used a rectified linear unit (ReLU). ReLU is described as:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} f(x) = \max (0, x) \end{aligned}$$\end{document}where x is an input to a neuron.Figure 6. Schematic overview of the CNN architecture employed in this study. We are training a CNN on acoustic emission data to identify whether a signal is a pore or non-pore. The acoustic emission signal is co-registered to the location of individual pores/non-pores.
Figure 6 depicts a schematic of the CNN used in this study, developed after studying similar architectures in literature^46–48^. The input is an acoustic raw time series of size 1000 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\times$$\end{document} 1. Three convolutional and max-pooling layers perform feature extraction. The three convolutional layers use ReLU activation function with 64, 32, and 16 filter sizes, respectively. After the training samples pass through all these layers, the extracted features are flattened to a 1-dimensional array. This 1D array is then connected to a dense layer with dropout where pore labels are predicted. The output of the fully connected layer is the pore or non-pore classification. Several ML frameworks, such as deep neural networks, convolutional neural networks, and recurrent neural networks, may be employed for pore predictions. These frameworks are all suitable for handling complex datasets. CNN was deemed optimal because its kernels allow us to extract better features than a fully connected dense neural network.
Evaluation metrics
Accuracy is a metric commonly used for evaluating classification tasks. However, caution must be exercised for class imbalanced data such as those presented in Table 2 since the accuracy metric may be artificially high due to the majority. To have a complete evaluation of the model, precision, recall, and F1 scores are implemented to measure CNN’s performance^49^:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \textrm{Precision}= & {} \frac{\textrm{TP}}{\textrm{TP} + \textrm{FP}} \end{aligned}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \textrm{Recall}= & {} \frac{\textrm{TP}}{\textrm{TP} + \textrm{FN}} \end{aligned}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \mathrm{F1\ Score}= & {} \frac{\mathrm{(2 \times Precision \times Recall)}}{\textrm{Precision} +\textrm{Recall}} \end{aligned}$$\end{document}where TP, FP, and FN refer to true positive, false positive, and false negative. F1 Score is a precision and recall function commonly used to evaluate individual classes in an unbalanced dataset. In this study, a TP is an acoustic event correctly identified as a pore; FP is an acoustic event incorrectly identified as a pore; and FN is an acoustic event that is a pore but incorrectly identified as a non-pore.
Results and discussion
The ML model built using CNN was applied to the original and augmented acoustic datasets with one \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\lambda$$\end{document} value for data augmentation. We discuss the resulting performances of both classification experiments, summarized in Table 3.
Impact of data augmentation
Figure 7. Confusion matrices comparing (A) the original dataset and (B) the augmented dataset (with one \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\lambda$$\end{document} value) for acoustic set 1. Confusion matrices for the combined (C) and augmented combined-acoustic dataset (D). The correctly classified samples are along the diagonal, and the misclassified samples are off-diagonal.
Augmentation affects CNN model performance as the evaluation scores slightly increased compared to the original data, with F1 scores and accuracy rising by at least 0.01 across all sets. Moreover, the individual datasets 1, 2, 3, and 4 all slightly increased evaluation scores, although set 5 shows a slight decrease in scores. The combined data returned the highest F1 and accuracy scores for both augmented and original data (Table 3). Note that while these accuracy increases are numerically small (< 0.05), the error rates are substantially improved as the models trained on the original data perform near 0.95 for accuracy and F1 scores as is. With augmented data, all three scores increase to 0.99.
Figure 7 shows the confusion matrix for acoustic dataset 1, which summarizes the classification accuracy. While the F1 score and accuracy for acoustic set 1 increased nominally by a value of 0.01, Figure 7 shows a fairly significant decrease in misclassifications with data augmentation, improving CNN performance on test datasets. In particular, when data augmentation is applied, 24 more samples are classified correctly compared to their original counterpart data. Specifically, 22 more pores and two more non-pores, which were misclassified before data augmentation, are now correctly classified when Mixup is applied. Table 4 details the model performance values for each acoustic dataset before and after data augmentation with one \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\lambda$$\end{document} value. For all but acoustic set 5, TP and TN increased with data augmentation. The combined dataset has the overall best model when data augmentation is applied with a total of 34 misclassifications (Fig. 7).
Figure 8 depicts the training and validation loss of the five datasets with and without Mixup. For the cases with the Mixup, training details of up to nine \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\lambda$$\end{document} values are shown. Note that the number of epochs used to train the CNN is generally less when applying data augmentation than the original data. For the original data, the number of epochs needed to train the model varies across the acoustic sets, ranging from 150 to over 400, with set 5 requiring the fewest epochs and set 2 requiring the most. In contrast, all acoustic datasets are trained well within 50 epochs with data augmentation. Although training requires fewer epochs for the augmented data, the training time required is more than one magnitude higher for \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$1 \, \lambda$$\end{document} (Table 5), which is expected with the increased data in data size. Moreover, the training time for augmented data grows higher for multiple \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\lambda$$\end{document} .Figure 8. Training and validation loss plots of the five acoustic datasets. Both unmixed and mixed scenarios with up to 9 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\lambda$$\end{document} values are shown.Table 5. Training time for original and augmented data.Data setTraining time for original data (s)Training time for augmented data (s)Set 140.99829.46Set 228.16372.96Set 346.622884.87Set 433.651042.82Set 542.015982.22The time taken to process each acoustic series is in the order of milliseconds. The ML models are trained on a laptop with the following configuration: Intel(R) Xeon(R) CPU E5-2695 v4 2.10GHz with 64GB of RAM and 64-bit processor. Set 1 to Set 5 refer to each acoustic experiment data.
Influence of \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\lambda$$\end{document}λ in data augmentation
We now examine the effect of using multiple \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\lambda$$\end{document} values on the misclassification rate. Here, we quantify the classification rate simply by summing TP and FP predictions. Table 6 details the number of misclassifications for each acoustic set with the number of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\lambda$$\end{document} values. The number of misclassifications is smallest when using only 1 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\lambda$$\end{document} for all acoustic datasets. Furthermore, with two and higher \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\lambda$$\end{document} , there is no consistent trend in the misclassification, but they are all consistently higher than what was found for 1 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\lambda$$\end{document} . Using more than one \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\lambda$$\end{document} value does not necessarily lead to improved modes since it does not decrease the number of misclassified predictions. On the contrary, it increases the number of misclassifications, suggesting a degradation in the CNN performance due to data augmentation. In addition, from Fig. 8, we observe that there is little change in the loss plots after 1 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\lambda$$\end{document} , as all loss plots look similar and reach a minimum loss within 50 epochs. While a single Mixup step improves performance, applying multiple augmentation steps leads to overfitting because subsequent augmentations do not provide sufficiently informative and independent new observations. This redundant information leads to overfitting and reduced CNN’s performance. Such multi-augmentation eventually increases noise in the data. Therefore, trained CNNs fail to predict original test datasets more accurately than a single Mixup step.Table 6. Total number of misclassifications for each acoustic set as more lambda values augment dataset size. More data augmentation iterations provide more misclassifications.SetOriginal1 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\lambda$$\end{document} 2 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\lambda$$\end{document} 3 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\lambda$$\end{document} 4 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\lambda$$\end{document} 5 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\lambda$$\end{document} 6 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\lambda$$\end{document} 7 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\lambda$$\end{document} 8 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\lambda$$\end{document} 9 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\lambda$$\end{document} 10 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\lambda$$\end{document} 1967290757818511212616012212021017712695107123131149951501513655592751118778115102115101412511212516715117314315016315214555770113119136108121130111113142
Dataset size and non-pore to pore ratio
The non-pore-to-pore ratio in the training dataset significantly controls CNN model performance. Acoustic sets 1–4 have non-pore-to-pore ratios between 1.8 and 4.3, whereas acoustic set 5 has a ratio of 1.2. Also, acoustic sets 1–4 show increased model performance with augmented data, as indicated by increased F1 scores and accuracy (Table 3). Acoustic set 5 slightly decreases model performance with augmentation, as indicated by the reduction of F1 scores and accuracy in Table 3. The combined data has the largest training dataset of 2516 independent and informative observations (Table 2). Out of all the acoustic sets, the combined dataset provided the best ML performance with both the original and augmented data (Table 3). The combined dataset also significantly increased evaluation scores compared to the original data after the implementation of data augmentation. This is because the combined set has more independent and informative pore and non-pore events than individual sets.
Conclusions
This study used a CNN-based ML model to predict the formation of pore/non-pores in the AM processes for acoustic datasets that were spatially registered ex situ to pore locations. CNNs were developed for original datasets and on augmented (up to 10 times) datasets to examine the efficacy of data augmentation for the intrinsically sparse datasets available to study pore formation. For each dataset, the performance of a single augmentation was better than multi-augmentations (e.g., 2–10), indicating that an optimal augmentation is achieved with \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$1 \lambda$$\end{document} for the considered data. However, multi-augmentation increased dataset size and training time without necessarily increasing accuracy.
Our results indicate that data augmentation had advantages and disadvantages (when the dataset is nearly balanced) on ML model performance depending on non-pore-to-pore ratio and dataset size. Generally, the ML models for augmented datasets perform better than corresponding original datasets except for acoustic dataset 5. For dataset 5, the Mixup strategy did not improve results as the dataset is close to balance (non-pore to pore ratio of 1.2). This may be a limitation of the Mixup strategy for already balanced datasets. The CNN trained on the combined dataset performed best, with an overall performance of 95% and 99% for original and augmented datasets, respectively. Even though the non-pore-to-pore ratio of the combined set is similar to acoustic set 3, this CNN model performed the best after data augmentation, potentially because of the larger sample size and more informative observations compared to individual datasets.
In AM processes monitoring, registered datasets such as the one considered herein are expensive to collect, highly imbalanced, and notoriously sparse in observation counts. Hence, this augmentation methodology can greatly enrich the information extracted from the experimental recordings. Furthermore, this enhanced data has been shown to effectively produce models with improved performance, indicating that practical implementations of such models could be achieved without the traditional burden of large amounts of training data required for neural network approaches. However, while we have shown when to use augmentation or not, the question remains on how we can utilize such CNNs during real-time AM processes. Once a CNN model is trained, a test or unseen acoustic emission signal is inferred in milliseconds. This makes trained CNNs attractive for deployment on a smart computing device (e.g., Raspberry Pi) attached to the data acquisition systems to monitor changes in pore formation during the LBPF process. We may need to retrain a CNN model (or fine-tune it with minimal data) for a different AM system. Future work could investigate the trained ML model on a system with a different setting, transfer knowledge to the existing system for our CNN model configuration, and investigate the potential benefits of hyperparameter tuning in CNN models.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Grasso M Colosimo B Process defects and in situ monitoring methods in metal powder bed fusion: A review Meas. Sci. Technol.201728404400510.1088/1361-6501/aa 5c 4f · doi ↗
- 2Pérez M Carou D Rubio E Teti R Current advances in additive manufacturing Proced. CIRP 20208843944410.1016/j.procir.2020.05.076 · doi ↗
- 3Reichardt A Shapiro A Otis R Dillon R Borgonia J Mc Enerney B Hosemann P Beese A Advances in additive manufacturing of metal-based functionally graded materials Int. Mater. Rev.202066112910.1080/09506608.2019.1709354 · doi ↗
- 4Colomo A Wood D Martina F Williams SA comparison framework to support the selection of the best additive manufacturing process for specific aerospace applications Int. J. Rapid Manuf.202092/319410.1504/IJRAPIDM.2020.107736 · doi ↗
- 5Tapia G Elwany AA review on process monitoring and control in metal-based additive manufacturing J. Manuf. Sci. Eng.2014136606080110.1115/1.4028540 · doi ↗
- 6Deb Roy T Wei H Zuback J Mukherjee T Elmer J Milewski JO Beese AM Wilson-Heid A De A Zhang W Additive manufacturing of metallic components-process, structure and properties Prog. Mater Sci.20189211222410.1016/j.pmatsci.2017.10.001 · doi ↗
- 7Everton S Hirsch M Stravroulakis P Leach R Clare A Review of in-situ process monitoring and in-situ metrology for metal additive manufacturing Mater. Des.20169543144510.1016/j.matdes.2016.01.099 · doi ↗
- 8Cui W Zhang Y Zhang X Li L Liou F Metal additive manufacturing parts inspection using convolutional neural network Appl. Sci.202010254510.3390/app 10020545 · doi ↗