Application of elementary probability models for text homogeneity and segmentation: A case study of Bible
Berhane Abebe, Roy Cerqueti, Roy Cerqueti, Roy Cerqueti, Roy Cerqueti

TL;DR
This study uses probability models to analyze the structure of Bible translations in Tigrigna, Amharic, and English, finding that they are made up of heterogeneous segments.
Contribution
The paper applies newly developed probability models to detect text homogeneity and change points in religious texts.
Findings
Bible translations in Tigrigna, Amharic, and English show heterogeneous concatenation of different books or genres.
The Pauline letters in the English Bible are found to be heterogeneous, composed of two homogeneous segments.
Abstract
For the purpose of this study, A statistical test of Biblical books was conducted using the recently discovered probability models for text homogeneity and text change point detection. Accordingly, translations of Biblical books of Tigrigna and Amharic (major languages spoken in Eritrea and Ethiopia) and English were studied. A Zipf-Mandelbrot distribution with a parameter range of 0.55 to 0.88 was obtained in these three Bibles. According to the statistical analysis of the texts’ homogeneity, the translation of Bible in each of these three languages was a heterogeneous concatenation of different books or genres. Furthermore, an in-depth examination of the text segmentation of prat of a single genre—the English Bible letters revealed that the Pauline letters are heterogeneous concatenations of two homogeneous segments.
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
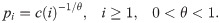 Figure 1
Figure 1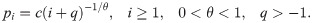 Figure 2
Figure 2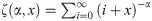 Figure 3
Figure 3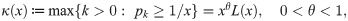 Figure 4
Figure 4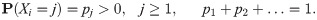 Figure 5
Figure 5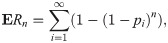 Figure 6
Figure 6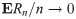 Figure 7
Figure 7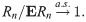 Figure 8
Figure 8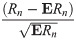 Figure 9
Figure 9 Figure 10
Figure 10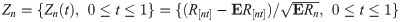 Figure 11
Figure 11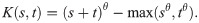 Figure 12
Figure 12 Figure 13
Figure 13 Figure 14
Figure 14 Figure 15
Figure 15 Figure 16
Figure 16 Figure 17
Figure 17 Figure 18
Figure 18 Figure 19
Figure 19 Figure 20
Figure 20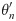 Figure 21
Figure 21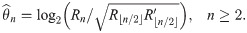 Figure 22
Figure 22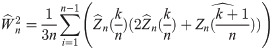 Figure 23
Figure 23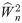 Figure 24
Figure 24 Figure 25
Figure 25 Figure 26
Figure 26 Figure 27
Figure 27 Figure 28
Figure 28 Figure 29
Figure 29 Figure 30
Figure 30 Figure 31
Figure 31 Figure 32
Figure 32 Figure 33
Figure 33 Figure 34
Figure 34 Figure 35
Figure 35 Figure 36
Figure 36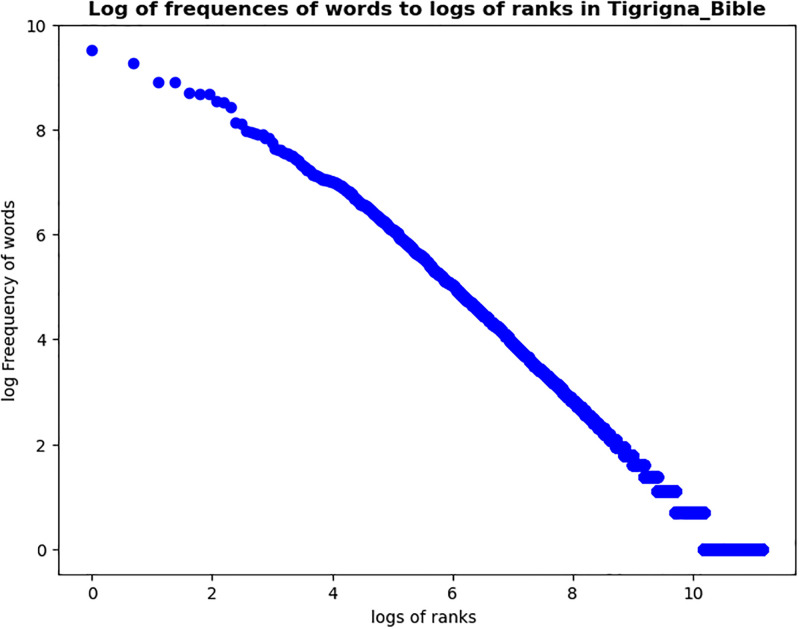 Figure 37
Figure 37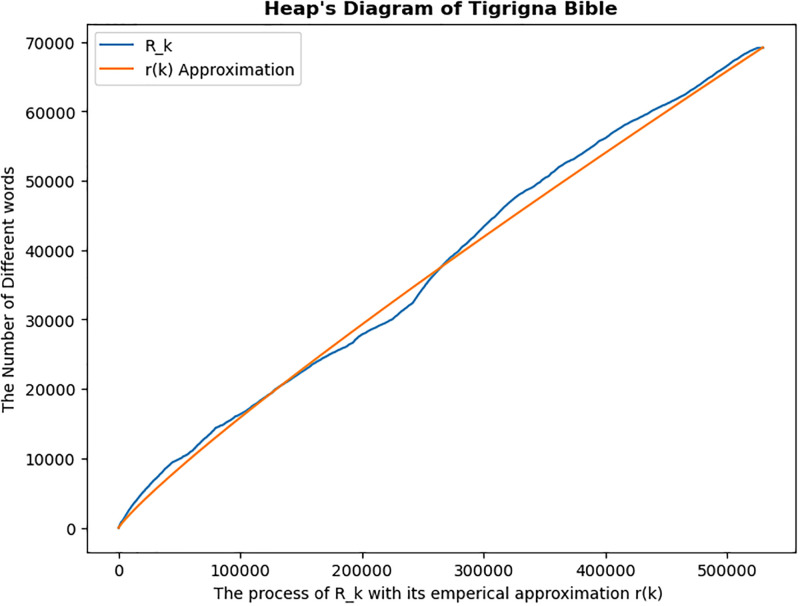 Figure 38
Figure 38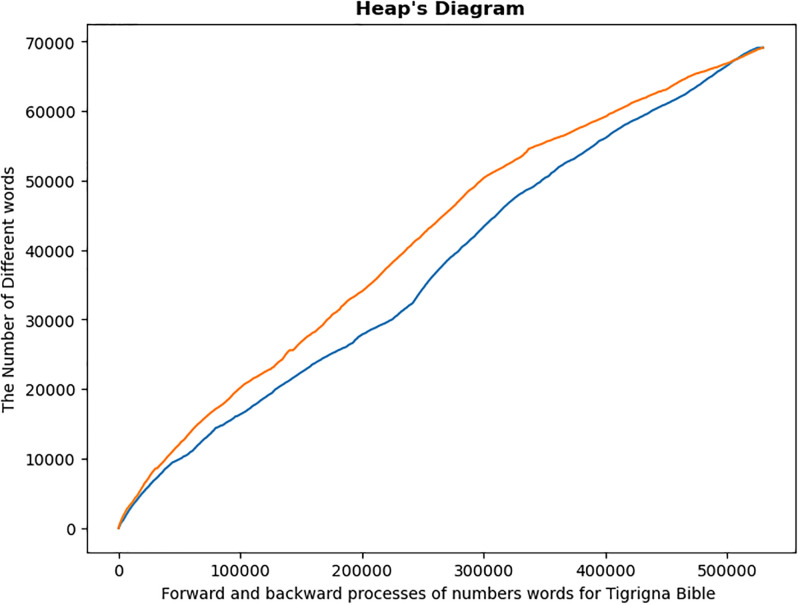 Figure 39
Figure 39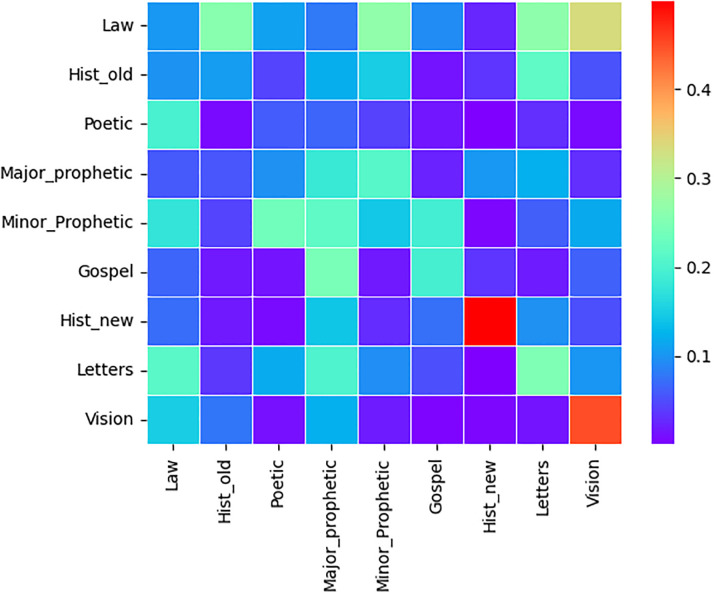 Figure 40
Figure 40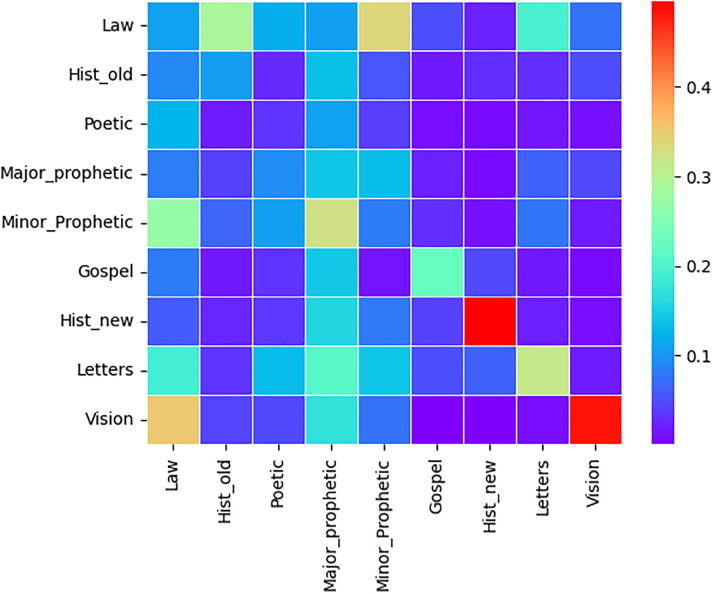 Figure 41
Figure 41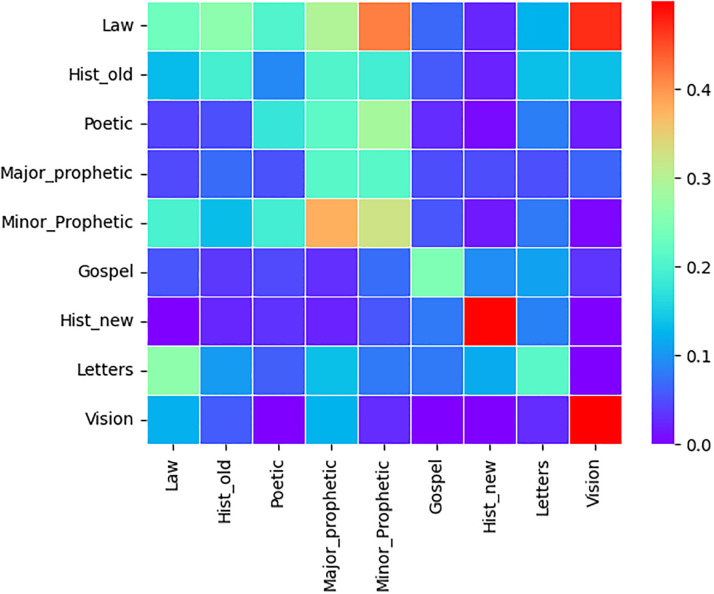 Figure 42
Figure 42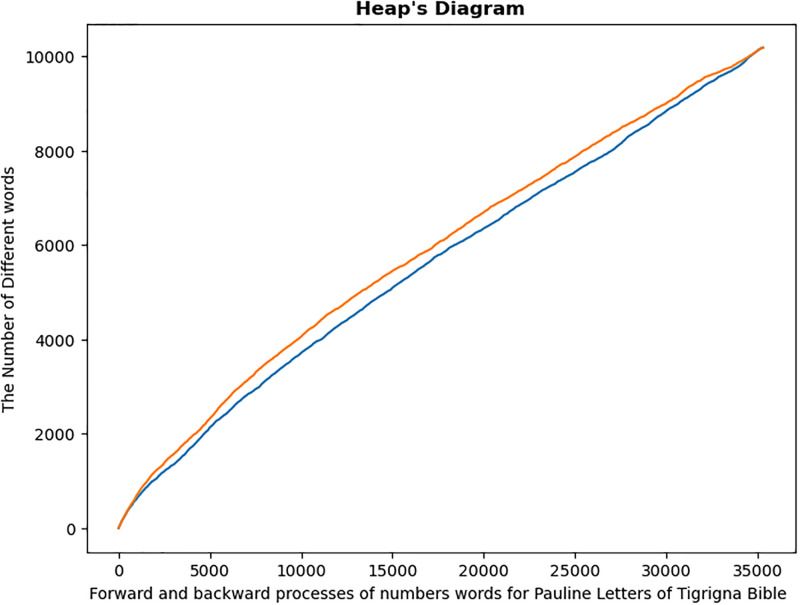 Figure 43
Figure 43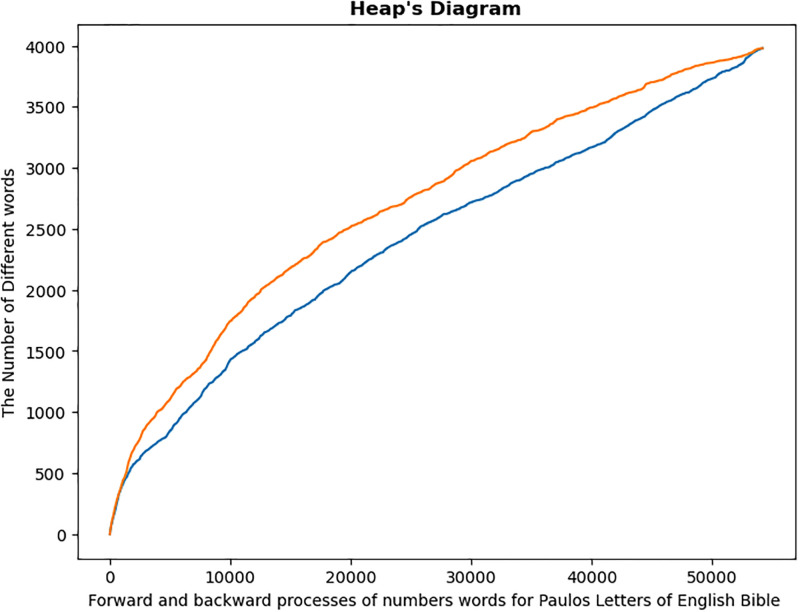 Figure 44
Figure 44 Figure 45
Figure 45 Figure 46
Figure 46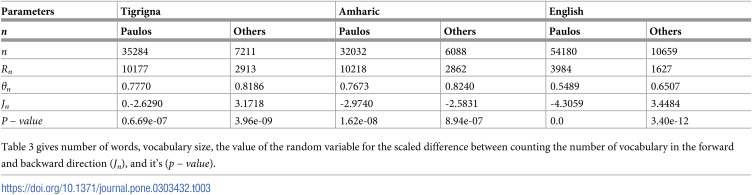 Figure 47
Figure 47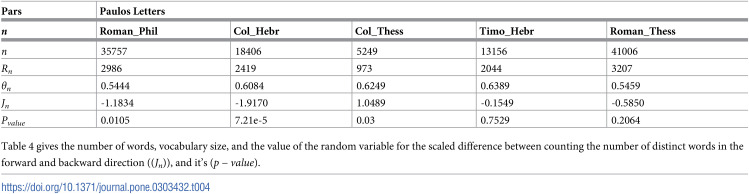 Figure 48
Figure 48Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsNatural Language Processing Techniques · Advanced Text Analysis Techniques · Text and Document Classification Technologies