Rate–Distortion–Perception Optimized Neural Speech Transmission System for High-Fidelity Semantic Communications
Shengshi Yao, Zixuan Xiao, Kai Niu

TL;DR
This paper introduces a new neural speech transmission system that improves high-fidelity communication by adapting to speech content and channel conditions.
Contribution
The novel NST framework optimizes rate–distortion–perception performance through adaptive transmission and causal coding for real-time use.
Findings
NST outperforms existing methods in rate–distortion–perception performance.
Streaming NST achieves low-latency transmission with minimal quality loss.
Adaptive coding based on semantic content improves transmission efficiency.
Abstract
We consider the problem of learned speech transmission. Existing methods have exploited joint source–channel coding (JSCC) to encode speech directly to transmitted symbols to improve the robustness over noisy channels. However, the fundamental limit of these methods is the failure of identification of content diversity across speech frames, leading to inefficient transmission. In this paper, we propose a novel neural speech transmission framework named NST. It can be optimized for superior rate–distortion–perception (RDP) performance toward the goal of high-fidelity semantic communication. Particularly, a learned entropy model assesses latent speech features to quantify the semantic content complexity, which facilitates the adaptive transmission rate allocation. NST enables a seamless integration of the source content with channel state information through variable-length joint…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
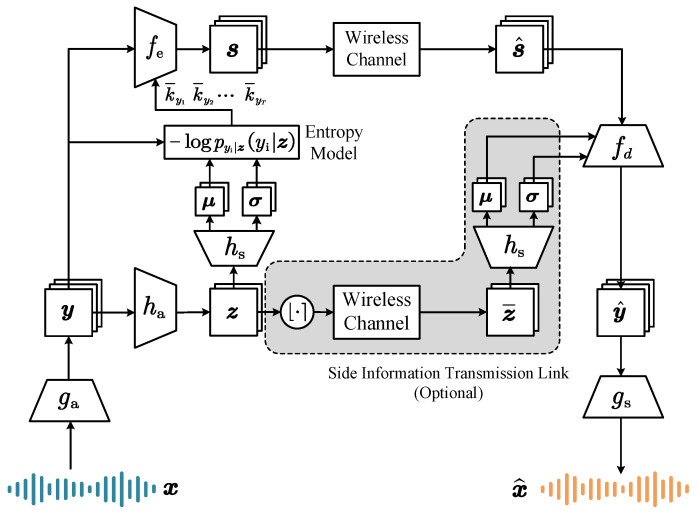 Figure 1
Figure 1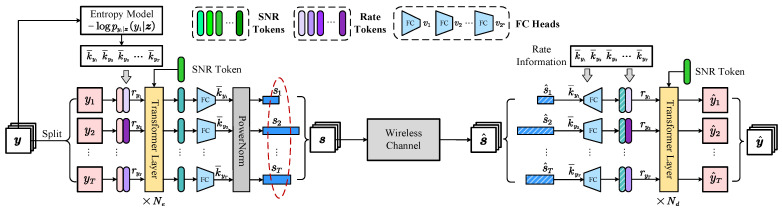 Figure 2
Figure 2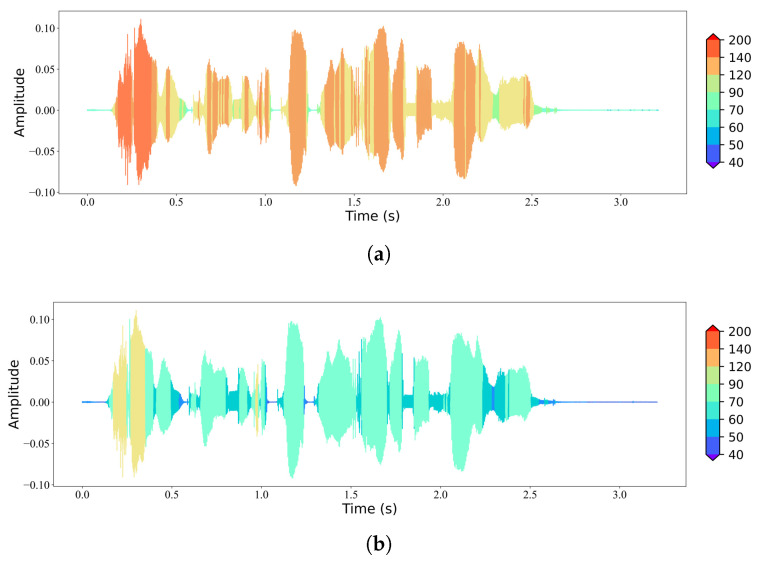 Figure 3
Figure 3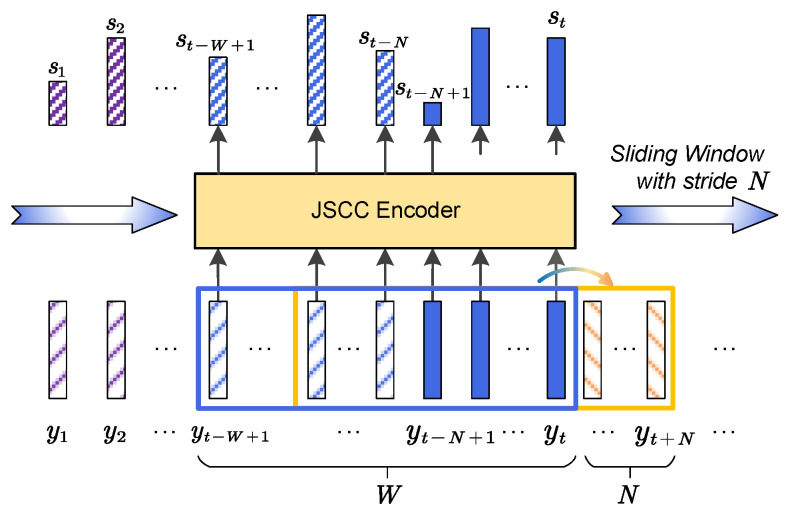 Figure 4
Figure 4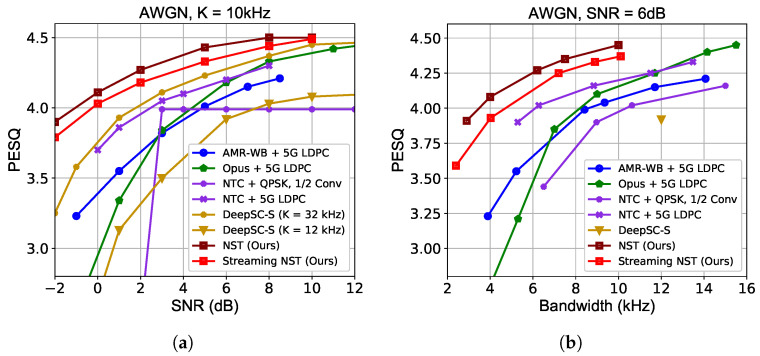 Figure 5
Figure 5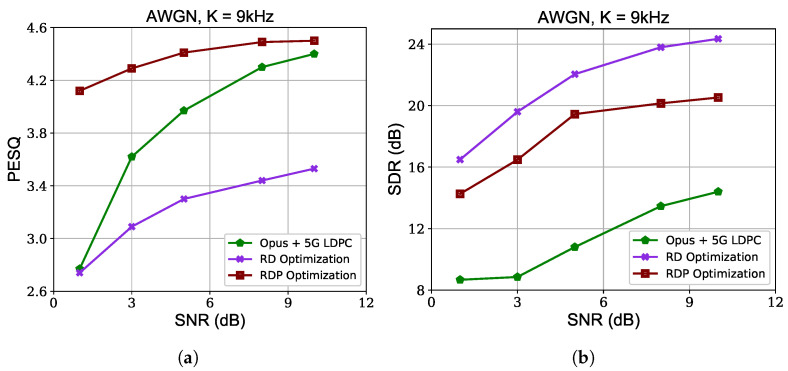 Figure 6
Figure 6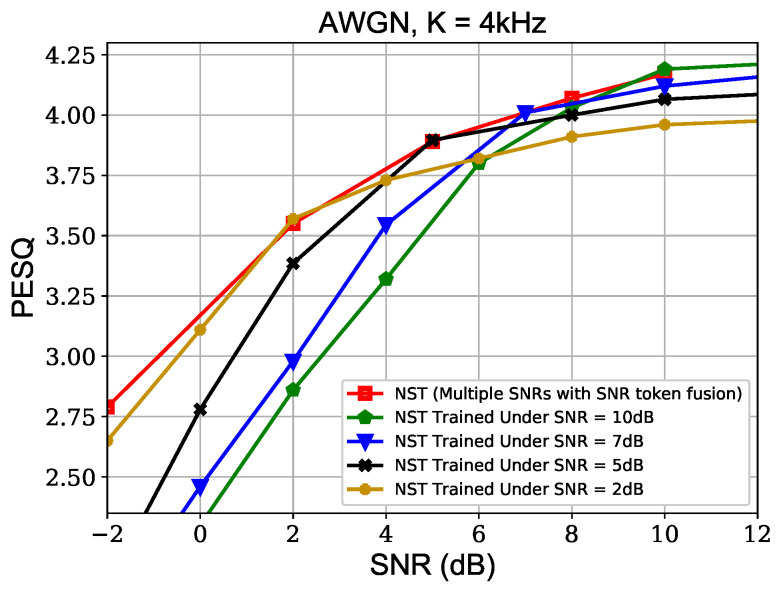 Figure 7
Figure 7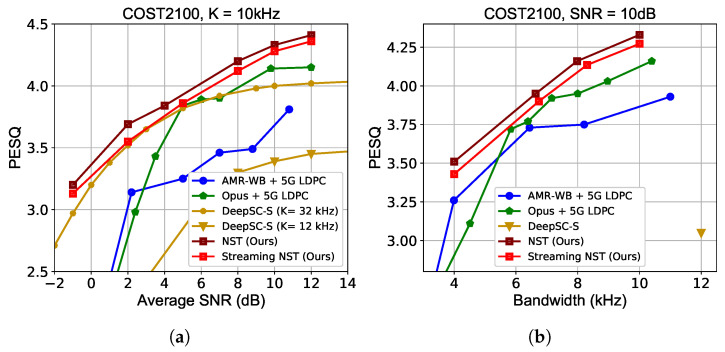 Figure 8
Figure 8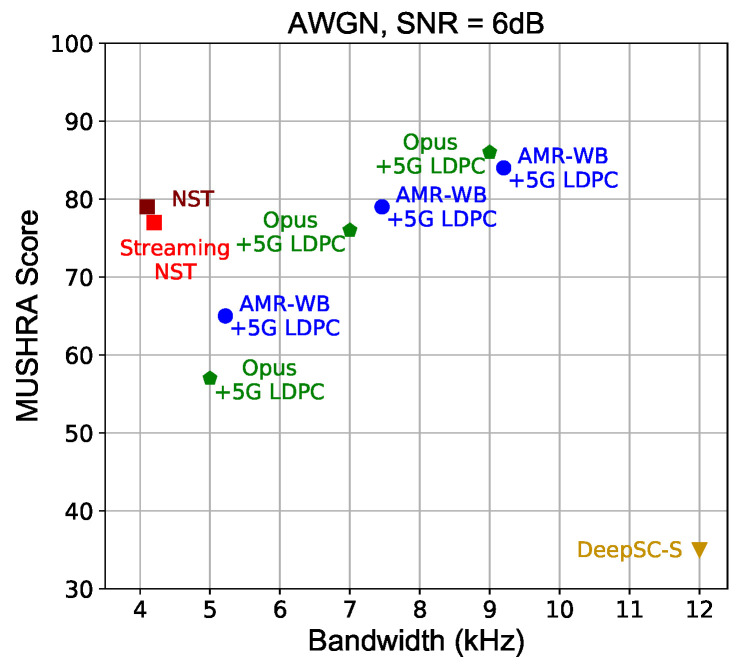 Figure 9
Figure 9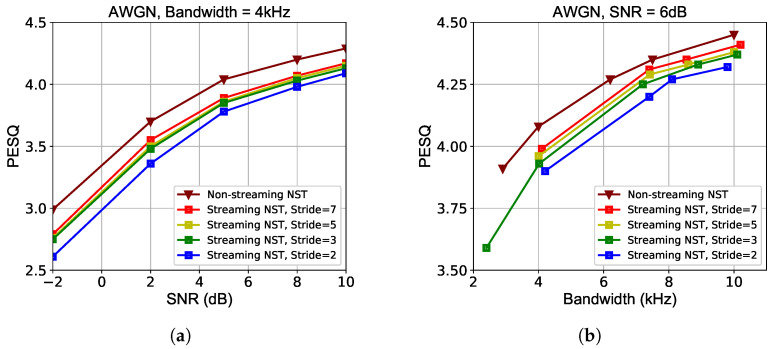 Figure 10
Figure 10Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsSpeech and Audio Processing · Speech Recognition and Synthesis · Music and Audio Processing