Optimizing Word Embeddings for Patient Portal Message Datasets with a Small Number of Samples
Qingyuan Song, Congning Ni, Jeremy L. Warner, Qingxia Chen, Lijun Song, S. Trent Rosenbloom, Bradley A. Malin, Zhijun Yin

TL;DR
This paper introduces a new method to improve word embeddings for patient portal messages when only a small number of samples are available.
Contribution
The paper proposes PK-word2vec, a novel adaptation of word2vec that incorporates prior knowledge to enhance performance on small-scale patient messages.
Findings
PK-word2vec outperformed standard word2vec in generating more relevant similar words in over 90% of tasks.
The performance difference between AMT workers and medical students was negligible, indicating consistent evaluation results.
PK-word2vec effectively learns from a small dataset of 137,554 patient portal messages.
Abstract
Patient portal messages often relate to specific clinical phenomena (e.g., patients undergoing treatment for breast cancer) and, as a result, have received increasing attention in biomedical research. These messages require natural language processing and, while word embedding models, such as word2vec, have the potential to extract meaningful signals from text, they are not readily applicable to patient portal messages. This is because embedding models typically require millions of training samples to sufficiently represent semantics, while the volume of patient portal messages associated with a particular clinical phenomenon is often relatively small. We introduce a novel adaptation of the word2vec model, PK-word2vec, for small-scale messages. PK-word2vec incorporates the most similar terms for medical words (including problems, treatments, and tests) and non-medical words from two…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
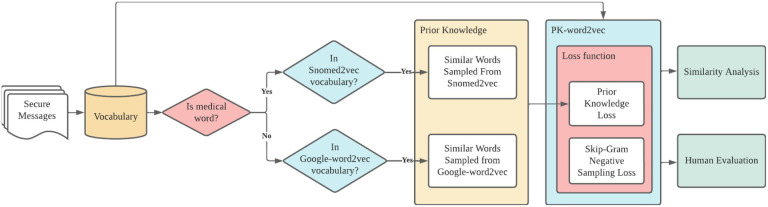 Figure 1
Figure 1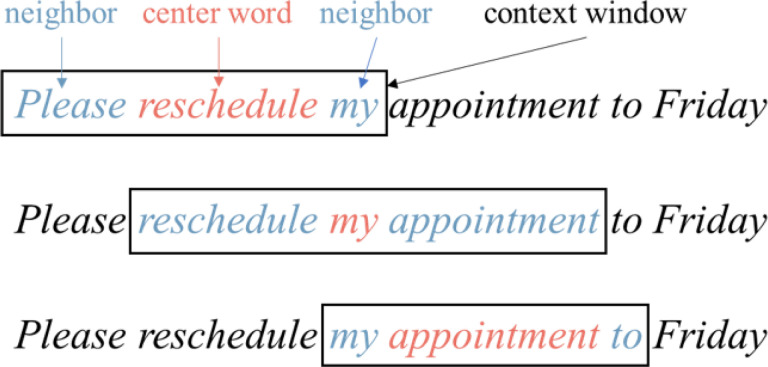 Figure 2
Figure 2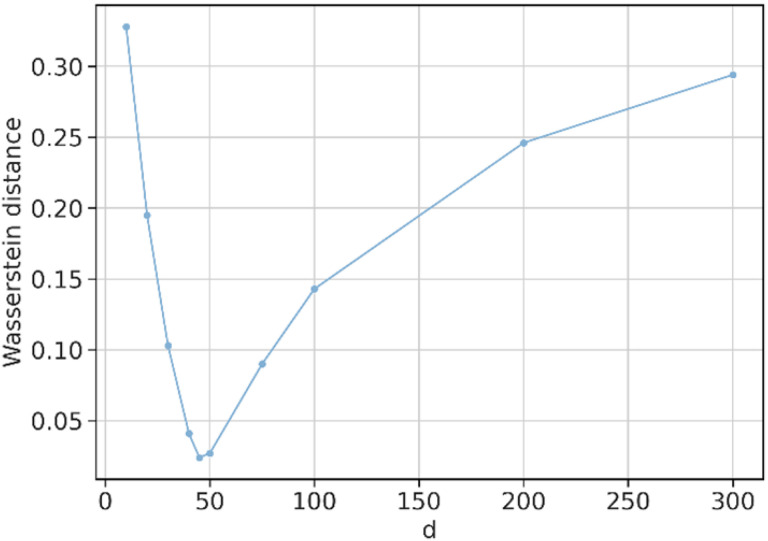 Figure 3
Figure 3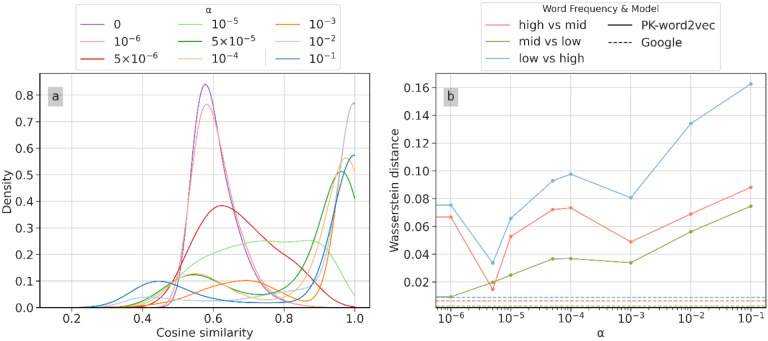 Figure 4
Figure 4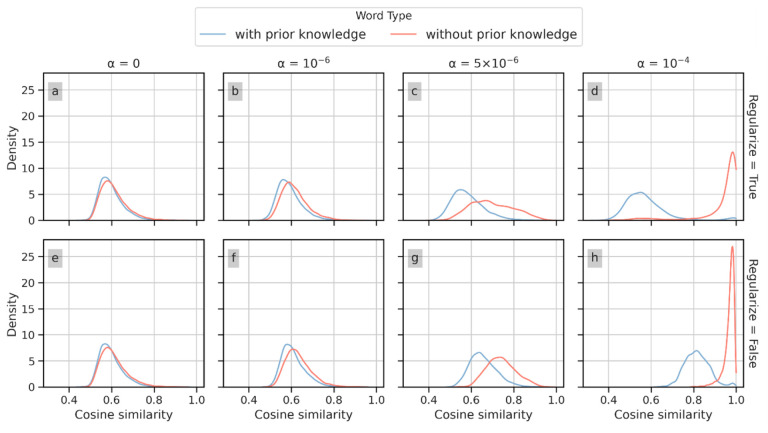 Figure 5
Figure 5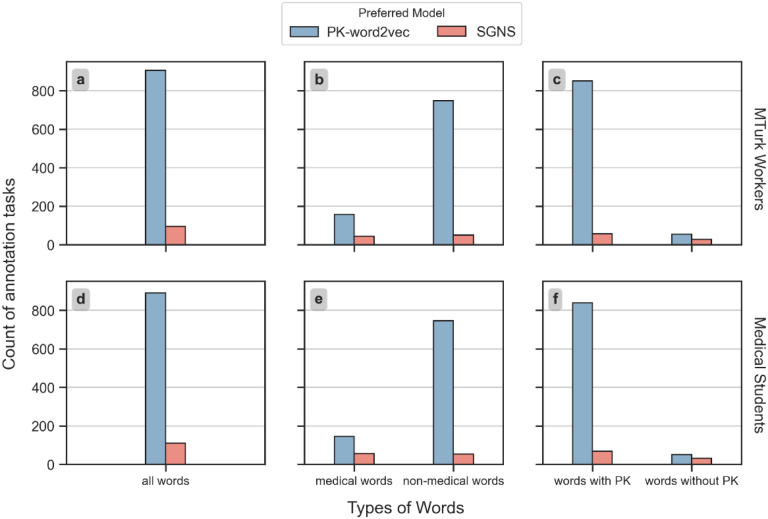 Figure 6
Figure 6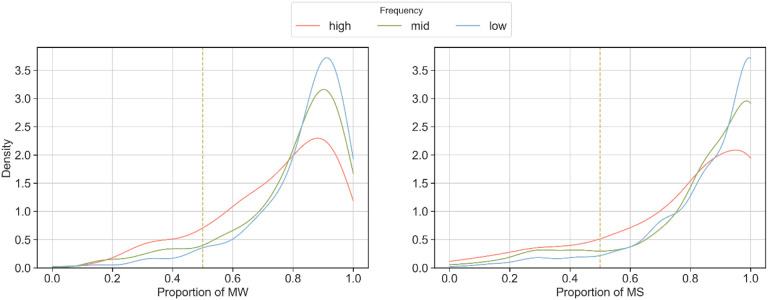 Figure 7
Figure 7Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsTopic Modeling · Natural Language Processing Techniques · Recommender Systems and Techniques
Introduction
Patient portals have become standard components of modern electronic health record (EHR) systems.^1^ They enable patients to access health information, manage clinical appointments, and communicate securely with care providers in an asynchronous manner.^2,3^ The messaging functionality of patient portals has gained in popularity over time^4,5^ due to various benefits, such as the ability to increase patient involvement in medical decision-making^6^. At the same time, the information conveyed in patient portal messages can serve as a foundation for clinical research, such as studies of initiation and discontinuation of cancer therapies^7,8^, assessing readmission risk^9,10^, and creating taxonomies of patient engagement^11^.
However, maximizing the utility of patient portal messages requires a means to extract meaningful signals from unstructured text.^12^ Rule-based methods, which rely on manually pre-defined rules to perform a task, are ineffective as the volume of data or complexity of the task increases ^12^. While specific computational methods, such as topic modeling, can be applied in this regard, these approaches typically rely on word frequency to determine the most representative words for each topic. By contrast, word embedding models, such as word2vec^13^, have been widely adopted by natural language processing (NLP) applications. These models can learn vector representations, typically from millions of documents, to capture each word’s semantic and linguistic meaning. However, it is challenging to procure a cohort that is sufficiently large to train a specific word embedding model. As an illustration, in this paper, we focus on breast cancer as it serves as an exemplar of a complex care coordination setting between various specialists who often communicate with patients via the patient portal^14^.
The current approaches for generating word embeddings on relatively small corpora may learn semantic meaning inaccurately due to lack of sufficient occurrences of word usage. A natural solution to this problem is to fine-tune a word embedding model that is pre-trained on a larger data corpus. This is because the fitted parameters of a pre-trained model can serve as a better starting point for training than random initialization. Yet this strategy presents certain limitations as well. In particular, pre-trained models are incapable of handling words that are absent from the pre-trained model’s vocabulary. Moreover, inconsistencies arise due to the incompatible linguistic contexts between the data used to fit the pre-trained model and the data for a specific domain of interest.^15^
In this study, we introduce a novel approach, PK-word2vec, to train word2vec models on a patient portal message corpora of relatively small sample size. Our model leverages prior information, as defined by the most similar words sampled from pre-trained embedding models, to regularize the model training. We demonstrate the utility of this approach using a dataset of approximately 137,000 patient portal messages from 1,389 patients diagnosed with breast cancer at a large academic medical center. ^1416^Our experiments show that the regularization process of PK-word2vec can guide and constrain the model training to learn word semantic meanings more effectively than standard word2vec models.
Methods
Figure 1 depicts the workflow for this study: 1) data extraction and cleaning; 2) prior knowledge extraction from two pre-trained models, Snomed2vec^16^ and the Google pre-trained word2vec (Google-word2vec)^13^ for medical and non-medical words, respectively; 3) model training regularized by prior knowledge (PK-word2vec); and 4) similarity analysis and human evaluation of the model performance. This study was deemed exempt from human subjects research by the Vanderbilt University Institutional Review Board.
Data Collection and Preprocessing
2.1.
We collected the patient portal messages from the EHR system of Vanderbilt University Medical Center (VUMC), a large, private, non-profit, academic medical center in Nashville, Tennessee. VUMC launched its patient portal, My Health at Vanderbilt (MHAV), in 2004, which was migrated to Epic’s MyChart platform in 2017. MHAV supports secure messaging between healthcare providers and patients, appointment scheduling, billing management, and access to laboratory results or other EHR data.^5^
In this study, we focused on the patient portal messages for patients with breast cancer who were prescribed the most common hormonal therapy medications: anastrozole, exemestane, letrozole, raloxifene, and/or tamoxifen. We masked URLs, email addresses, phone numbers, timestamps, and numerals by using the ekphrasis (v0.5.1)^17^. Afterwards, all personal names and usernames were manually masked, and misspelled words were corrected with the guidance of two domain experts (STR, JLW) by referring to the contexts from randomly selected messages that contain these misspelled words. We applied the CLAMP software package (v1.6.4) to detect medical words pertaining to diseases, laboratory tests, and medications from messages^18^.
Skip-Gram Model with Negative Sampling
2.2.
PK-word2vec is built on a skip-gram model with negative sampling (SGNS)^13^, a standard word2vec. In SGNS, each word has two vector representations: 1) a center vector when it is processed as a center word, and 2) a context vector when it serves as a neighbor of a center word. Figure 2 illustrates the center word and neighbor word within a context window size of 1 in the sentence “Please reschedule my appointment to Friday”. In this example, reschedule is one of the neighbors of the center word appointment. Formally, SGNS structures the model training as a binary classification problem, where the objective is to predict whether a certain pair of words are neighbors. Formally, given a sequence of words W1, W2, …, WT and a context window of size m, the SGNS objective function is defined as:
where ut and vt represent the context and center vector of wt, which are the parameters optimized in the loss function; w′k represents a random word that does not appear in the neighboring context of wt. w′k is sampled from P (wt), a unigram distribution defined by the frequency of occurrence of each word^19^; K is a hyperparameter that specifies the number of negative words sampled for wt; and σ is the sigmoid function. The first term in Eq. (1) aims to maximize the probability of occurrence for words that are in the context window. By contrast, the second term in Eq. (1) aims to minimize the probability of occurrence for words that are not in the context window.
Prior Knowledge Word2vec Model
2.3.
The challenge of training a word2vec model on a small dataset arises from the insufficient context that such datasets provide. To address this issue, we define the prior knowledge of a word as its most similar words identified from other pre-trained models. Subsequently, the prior knowledge is applied to regularize the PK-word2vec model training. More formally, if a word in the patient portal messages wt also appears in a pre-trained embedding vocabulary, the prior knowledge of wt is defined by another word wj that is sampled with probability ptj from the patient portal message vocabulary. In this respect, the more similar wj is to wt in the pre-trained embedding model, the greater the likelihood that Wj will be sampled.
We introduce a prior knowledge loss function for the entire dataset, which is defined as follows:
where γ(wt) = τ/freq(wt) discounts the words proportionally to their frequency, τ is a hyperparameter, and Ψ (·) is a regularization factor to be defined in Eq. (4) below. Note that if a word does not exist in the pre-trained model, then it has no prior knowledge and its corresponding term in is set to zero.
In this work, we calculate word similarity as the cosine similarity of two vectors u and v, cos (u, v) = u • v/(|u|·• |υ|). We require that each sampled wj have a similarity score with wt above a pre-defined threshold θ. As such, ptj is defined as:
In our experiments, for each pre-trained model, we set θ to the average of the top 10 similarity scores for words with prior knowledge in patient portal messages. In practice, each time wt is processed in model training using gradient descent optimization, a word wj is sampled and its cosine similarity with wt in both context and center vectors is calculated as its prior knowledge. Then, the corresponding item for wt that needs to be minimized in the PK-word2vec loss function in Eq. (2) is:
There are several reasons for incorporating context vector similarity into Eq. (4). First, a key characteristic of high-quality word embeddings is that the distance between the context vectors for similar words is relatively small ^20^. Second, since the context vectors are applied to estimate the center vectors of neighboring words, the regularization of the context vectors can propagate to the center vectors of neighboring words without prior knowledge. Finally, the overall objective function for PK-word2vec can be defined as:
where α is a hyperparameter that determines the degree to which the training of PK-word2vec relies on prior knowledge. A higher α indicates a stronger dependency on prior knowledge. To evaluate the impact of α, we compared our approach to a baseline model where α = 0, a condition corresponding to SGNS. We generate prior knowledge for non-medical and medical words using two different models. Specifically, we applied Google-word2vec, which was trained on the Google News dataset (about 100 billion words), to build prior knowledge for non-medical words. We turned to a Snomed2vec model, which was trained on the SNOMED-CT knowledge graph^16^ to obtain prior knowledge for medical words.
Hyperparameter Selection
2.4.
Hyperparameter tuning for word2vec models is challenging because it is difficult to define similarity. Since Google-word2vec was trained on a vast corpus, we selected hyperparameters, the dimension of word embedding d and the prior knowledge weight α, such that PK-word2vec is similar to Google-word2vec in terms of the distribution of the similarity scores between a given word and its 10 most similar words. In this paper we name this distribution as similarity distribution for simplicity. We did not use Snomed2vec as a reference because it is inherently a node2vec^21^ trained on a semantic network in the Unified Medical Language System^22^ rather than text data.
We set the embedding size d with a value that corresponds to the smallest Wasserstein distance^23^ in the similarity distributions between the two models. To select α, we first categorized words into high-, mid-, and low-frequency ranges based on their tertiles. Then, we set α with a value that corresponds to the smallest Wasserstein distance in the similarity distribution between three distinct word frequency ranges. This resulted in a comparison in an unbiased manner, since high-frequency words tended to receive better representations. When training PK-word2vec, the θ threshold was set to the average word similarity between all the words and their 10 most similar words in the pre-trained models. We set the threshold τ in Eq. (2) to 0.00001, batch size to 10000, and trained the model for 10 epochs.
Human Evaluation
2.5.
To compare PK-word2vec with SGNS, we randomly sampled 1,000 words from the patient portal message vocabulary, with the same proportion of medical to non-medical words. For each term of interest, we created one group of the five most similar words generated from PK-word2vec and SGNS, respectively. To evaluate the system, we asked each reviewer to indicate which word group was more related to the word of interest. We randomized the order of the two groups in each task to avoid framing biases.
We recruited two groups of reviewers for the model evaluation. The first group consisted of 330 Amazon Mechanical Turk (MTurk) workers^24^, recognized as “masters” due to their consistently submission of high-quality results in their history annotations. Each MTurk worker completed 100 out of the 1000 tasks and each task was answered by 33 different MTurk workers. The second group consisted of 7 medical students recruited through the Vanderbilt Institute for Clinical and Translational Research. Each medical student completed all 1,000 tasks. We set a 30-second time limit for each task; task not completed within this time limit were reassigned to a new worker.
To analyze the human evaluation data, we first calculated the support rate, defined as the proportion of the 1,000 tasks for which MTurk workers or medical students preferred PK-word2vec by a majority vote. Next, we employed sample skewness^25^ to examine the distribution of the proportion of reviewers who favored PK-word2vec in each task. This provided insights into the extent to which PK-word2vec was favored over SGNS. A larger value for left sample skew indicates a preference of PK-word2vec over SGNS. Finally, to account for the heterogeneity, we fitted a mixed-effects logistic regression model to assess which word embedding model was preferred by MTurk workers. The type of model (PK-word2vec or SGNS) and the category of the term of interest (medical or non-medical words) were variables with fixed effects. We assigned a value of 1 to the PK-word2vec model and medical words and a value of 0 to the SGNS and non-medical words in the corresponding variables.
Results
Data Summary
3.1.
The dataset was composed of 137,554 messages sent by 1,389 patients with breast cancer. After preprocessing, there was a total of 10,683 unique words in the vocabulary, of which 8,878 (80%) and 1,895 (20%) were non-medical and medical words, respectively. Prior knowledge was available for 7,981 (90%) non-medical and 1,116 (59%) medical words.
Hyperparameter Selection
3.2.
Embedding size (d).
The word embedding size was selected from a range of 10 to 300. Figure 3 depicts the Wasserstein distance between SGNS and the Google-word2vec as a function of the word embedding size. In the following experiments, we present results with an embedding size of 45 for SGNS and PK-word2vec because it corresponds to the smallest distance among all the candidate vector sizes.
Prior knowledge weight (α).
Figure 4a shows the similarity distribution for PK-word2vec as a function of α When α = 0, this model corresponds to SGNS and most of the density concentrates around 0.6. As α increases, the prior knowledge becomes dominant, and the density gradually shifts toward two directions, forming two peaks. Figure 4b shows the Wasserstein distance in the similarity distribution between Google-Word2vec (three dashed lines at the bottom of the figure) and PK-word2vec (three solid lines at the top of the figure) in different word frequency ranges. The distributions for Google-word2vec were nearly flat and maintained relatively small values. Based on this observation, we set α to 5 × 10^−6^ for the following experiments because it corresponds to the smallest Wasserstein distances as well as smallest variance across three pairs of comparisons.
Word Similarity
3.3.
Context vector regularization.
Figure 5 depicts the similarity distribution for the models with (panels a–d) and without (panels e–g) context vector regularization. The blue and orange lines in each graph correspond to words with and without prior knowledge, respectively. The comparisons between two similarity distributions are illustrated in settings with different pre-selected α values. As extreme examples, Figs. 5d and 5g show that when α = 10^−24^, context vector regularization mitigates the skew of the similarity distribution for the words with prior knowledge. While a large α value shifts the mode of the similarity distribution for words without prior knowledge in the model without context vector regularization to the right, the variance of similarity distribution is not significantly altered. Figures 5c and 5f depict the scenario where α is set to its optimal value of 5 × 10^−6^, where the difference between the two distributions is in an intermediate state compared with other α values. These results show that context vector regularization mitigates the impact of prior knowledge on the similarity distribution between words with and without prior knowledge.
Human Evaluation
3.4.
Figure 6 displays the human evaluation results based on a majority vote from the MTurk workers and medical students. In addition to an overall comparison, the results were stratified by the word type, and the existence of prior knowledge. The difference was negligible for all comparisons between the two groups of reviewers (p = 0.774 under a paired t-test). In over 90% of the tasks, both groups of reviewers indicated that PK-word2vec generates more similar words than SGNS. For medical words, the support rate for PK-word2vec was 78.8% for MTurk workers and 71.8% for medical students. For non-medical words, the support rate for PK-word2vec was 93.6% for MTurk workers and 93.4% for medical students. For words lacking prior knowledge, the support rate for PK-word2vec was 66.7% from MTurk workers and 61.4% from medical students.
Figure 7 shows the distribution of the proportion of reviewers that favor PK-word2vec in each task. The three curves represent the proportion distribution for the low-, mid-, and high-frequency words, respectively. All distributions are strongly left-skewed and most of the density falls between 0.8 and 1.0, indicating reviewers consistently favored PK-word2vec. Notably, in the responses from MTurk workers, the sample skew was 1.19, 1.65, and 1.92 for the high-, mid-, and low-frequency words, respectively. In the responses from the medical students, the sample skew was 0.88, 1.46, and 1.84 for the high, mid-, and low-frequency words, respectively. In other words, the degree to which the distribution was left-skewed was inversely proportional to the word frequency.
The results of the mixed-effect model showed that PK-word2vec was significantly more favored than SGNS (β = 2.702, p-value = 0.01). By contrast, no difference was found between medical word and non-medical word (β = 0, p-value = 1).
Discussion
This study has several findings that are worth highlighting. First, relying on external word pairs to tune hyperparameters, as has been done in many prior studies^13,26,27^, is suboptimal for smaller datasets. This limitation arises from the fact that many word pairs in external datasets may not be included in the target datasets. To address this issue, we selected hyperparameters by minimizing the distance in the similarity distribution between Google-word2vec and PK-word2vec. Our experiments showed that the prior knowledge weight α changed the word similarity distribution from a unimodal to a bimodal form, suggesting that introducing too much prior knowledge might degrade the quality of word embedding models. However, when comparing the similarity distribution between words across different frequency ranges, we observed that when the prior knowledge weight was very small or very large, it caused the similarity distribution to become dissimilar amongst these word frequency ranges. This finding highlights the necessity of carefully balancing the weight of prior knowledge within the model training.
Second, including context vector regularization into the PK-word2vec training helped reduce the difference in the similarity distribution between words with and without prior knowledge. Specifically, in the model with context vector regularization, the distribution of words with prior knowledge exhibited a longer tail as the value of α increased. By contrast, without context vector regularization, the similarity distribution for words without prior knowledge was right shifted without significant changes to its shape. To investigate the root cause, we inspected the most similar words for those without prior knowledge and located in the tail of the similarity distribution around cosine similarity of 0.9. For example, consider the word miscarriage. In the model with context vector regularization, its most similar words were trimester, gestational, gestation, fetal, and fetus, all of which are directly related to pregnancy. Conversely, without context vector regularization, the most similar words were tube, defects, defect, homocysteine, and suction. While these terms are associated with miscarriage, they revealed a different pattern of similarity compared to the model with context vector regularization. This effect suggests the importance of context vector regularization in enhancing the model’s compatibility with a small sample size of data.
Third, despite using a relatively small dataset, our human reviewers preferred the word groups produced by PK-word2vec over those produced by SGNS, and had a higher support rate for PK-word2vec for non-medical words than medical words. There are several possible explanations for this result. First, the medical words are inherently complex and more difficult for the reviewers to evaluate. Second, the number of medical words was relatively small, such that some medical words are associated with fewer than five other words with high similarity scores. In addition, the new PK-word2vec helped improve the vector representation, especially for low-frequency words (see Fig. 6). While medical students likely had more medical training than MTurk workers on average, our analysis suggested that the two types of reviewers were similar regarding their preferences for non-medical and medical words. This implies that for simple medical surveys, engaging a large number of participants pool can obtain accurate results, mitigating the need for, and potential higher costs associated with, specialized professionals.
In the context of customizing word representation models, our PK-word2vec method offers a distinct approach compared to previous studies. Several earlier studies have adapted SGNS to enhance word representation, primary focusing on aligning the vector space of a general, pre-trained embedding model to a specific problem domain^28,29^. Other refined strategies included improving the embedding quality by retrofitting the pre-trained word vectors using lexical relational resources ^30^, and augmenting SGNS with additional knowledge-based graph models and ‘anchor context models ^31^. Different from these approaches, our PK-word2vec method does not require a large number of training samples to fine-tune the word embedding model. This significant advantage could substantially facilitate research within the field of biomedical informatics, mainly when working with small study cohorts.
Despite the encouraging findings, this study has several limitations that can serve as a basis for future research. First, PK-word2vec was examined solely on patients with breast cancer. It has yet to be determined whether the method generalizes to clinical communications or notes for other types of patients. Second, we generated prior knowledge from two pre-trained models only. It is unknown if incorporating additional pre-trained models can enhance the generalizability of PK-word2vec. Third, complex medical concepts are often represented by long phrases rather than words, which begs the question of how to include more complex concepts in human evaluations. Finally, the model should be tested in downstream NLP tasks by jointly tuning the prior knowledge weight and other hyperparameters.
Conclusions
This paper introduces PK-word2vec, an adapted word embedding model trained on a relatively small number of patient portal messages. This was achieved by incorporating prior knowledge from two pretrained embedding models into the model training. Our evaluation with MTurk workers and medical students demonstrated that PK-word2vec outperformed the standard word2vec model in generating more similar words from small-size patient portal messages. While this study focused on extracting prior knowledge from Google-word2ec and Snomed2vec for patient portal messages, the proposed PK-word2vec can leverage prior knowledge from any pre-trained models, irrespective of the vector size or representation space, to build vector representations for other clinical text data.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Dendere R, Slade C, Burton-Jones A, Sullivan C, Staib A, Janda M. Patient Portals Facilitating Engagement With Inpatient Electronic Medical Records: A Systematic Review. J Med Internet Res. 2019;21(4):e 12779. doi:10.2196/1277930973347 PMC 6482406 · doi ↗ · pubmed ↗
- 2Goel MS, Brown TL, Williams A, Cooper AJ, Hasnain-Wynia R, Baker DW. Patient reported barriers to enrolling in a patient portal. Journal of the American Medical Informatics Association. 2011;18(Supplement_1):i 8–i 12.22071530 10.1136/amiajnl-2011-000473 PMC 3241181 · doi ↗ · pubmed ↗
- 3Kruse CS, Bolton K, Freriks G. The effect of patient portals on quality outcomes and its implications to meaningful use: a systematic review. J Med Internet Res. 2015;17(2):e 44.25669240 10.2196/jmir.3171 PMC 4342639 · doi ↗ · pubmed ↗
- 4Ralston JD, Carrell D, Reid R, Anderson M, Moran M, Hereford J. Patient web services integrated with a shared medical record: patient use and satisfaction. Journal of the American Medical Informatics Association. 2007;14(6):798–806.17712090 10.1197/jamia.M 2302 PMC 2213480 · doi ↗ · pubmed ↗
- 5Osborn CY, Rosenbloom ST, Stenner SP, My Health At Vanderbilt: policies and procedures governing patient portal functionality. Journal of the American Medical Informatics Association. 2011;18(Supplement_1):i 18–i 23.21807648 10.1136/amiajnl-2011-000184 PMC 3241162 · doi ↗ · pubmed ↗
- 6Griffin A, Skinner A, Thornhill J, Weinberger M. Patient portals. Appl Clin Inform. 2016;7(02):489–501.27437056 10.4338/ACI-2016-01-RA-0003 PMC 4941855 · doi ↗ · pubmed ↗
- 7Yin Z, Warner JL, Chen Q, Malin BA. Patient Messaging Content Associated with Initiating Hormonal Therapy after a Breast Cancer Diagnosis. In: AMIA Annual Symposium Proceedings. Vol 2019.; 2019:962.PMC 715309332308893 · pubmed ↗
- 8Yin Z, Harrell M, Warner JL, Chen Q, Fabbri D, Malin BA. The therapy is making me sick: how online portal communications between breast cancer patients and physicians indicate medication discontinuation. Journal of the American Medical Informatics Association. 2018;25(11):1444–1451. doi:10.1093/jamia/ocy 11830380083 PMC 7646923 · doi ↗ · pubmed ↗