Leveraging Temporal Information to Improve Machine Learning-Based Calibration Techniques for Low-Cost Air Quality Sensors
Sharafat Ali, Fakhrul Alam, Johan Potgieter, Khalid Mahmood Arif

TL;DR
This paper shows that using time-based data improves the accuracy of low-cost air quality sensors when calibrated with machine learning.
Contribution
The novel use of temporal information, like deployment duration and time of day, in calibrating low-cost air quality sensors.
Findings
Temporal data as a co-variate significantly improves calibration accuracy for low-cost sensors.
Machine learning models like Random Forest and LSTM benefit from incorporating time-based features.
Results are validated using three global datasets of CO and NO2 sensor readings.
Abstract
Low-cost ambient sensors have been identified as a promising technology for monitoring air pollution at a high spatio-temporal resolution. However, the pollutant data captured by these cost-effective sensors are less accurate than their conventional counterparts and require careful calibration to improve their accuracy and reliability. In this paper, we propose to leverage temporal information, such as the duration of time a sensor has been deployed and the time of day the reading was taken, in order to improve the calibration of low-cost sensors. This information is readily available and has so far not been utilized in the reported literature for the calibration of cost-effective ambient gas pollutant sensors. We make use of three data sets collected by research groups around the world, who gathered the data from field-deployed low-cost CO and NO2 sensors co-located with accurate…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
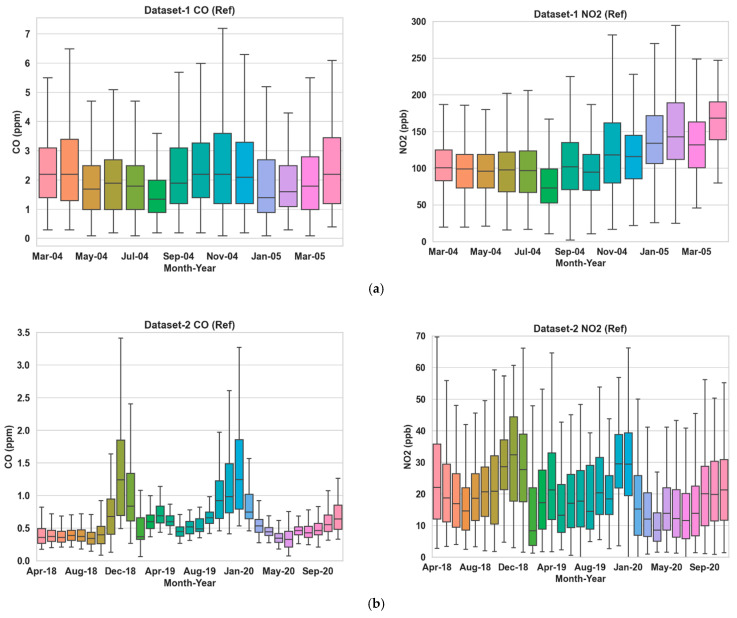 Figure 1
Figure 1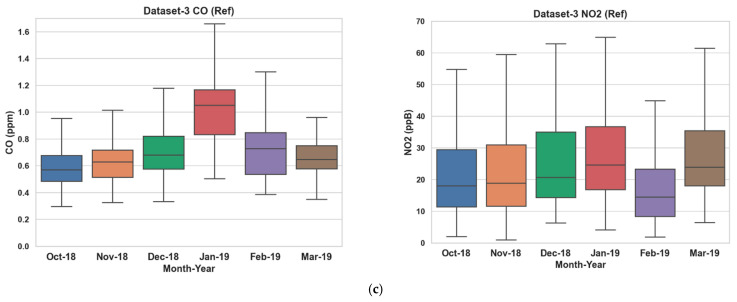 Figure 2
Figure 2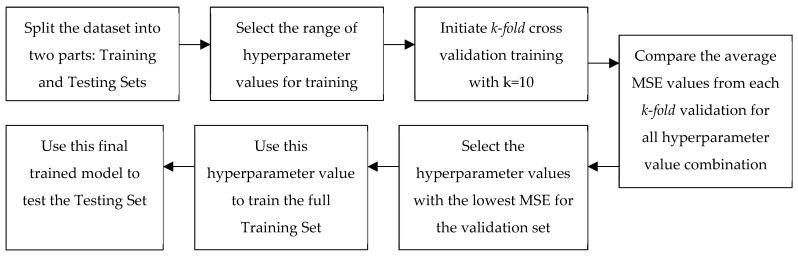 Figure 3
Figure 3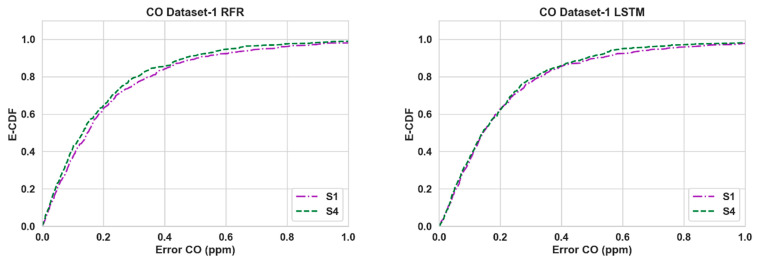 Figure 4
Figure 4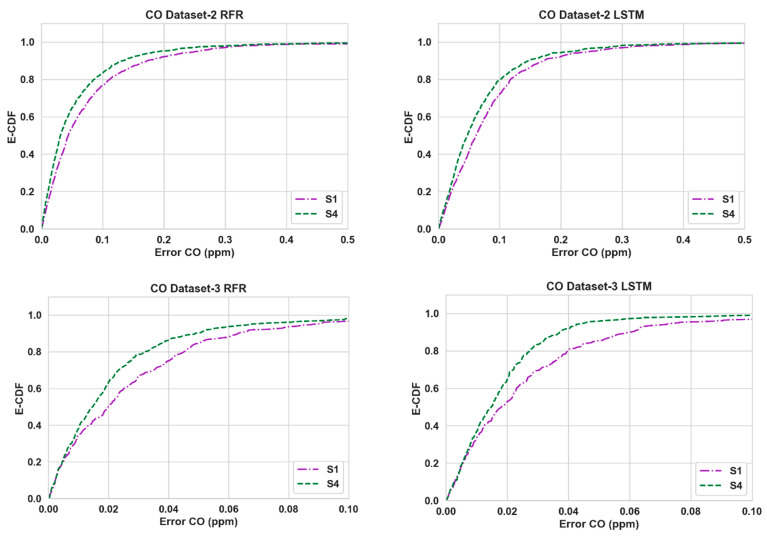 Figure 5
Figure 5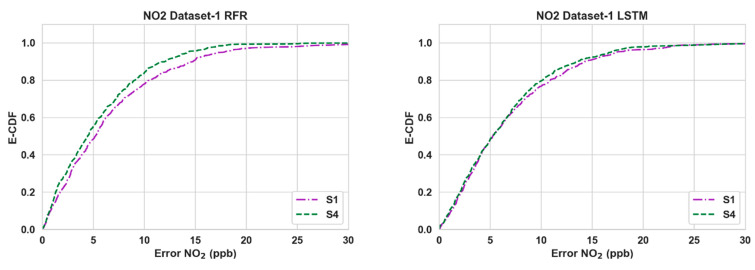 Figure 6
Figure 6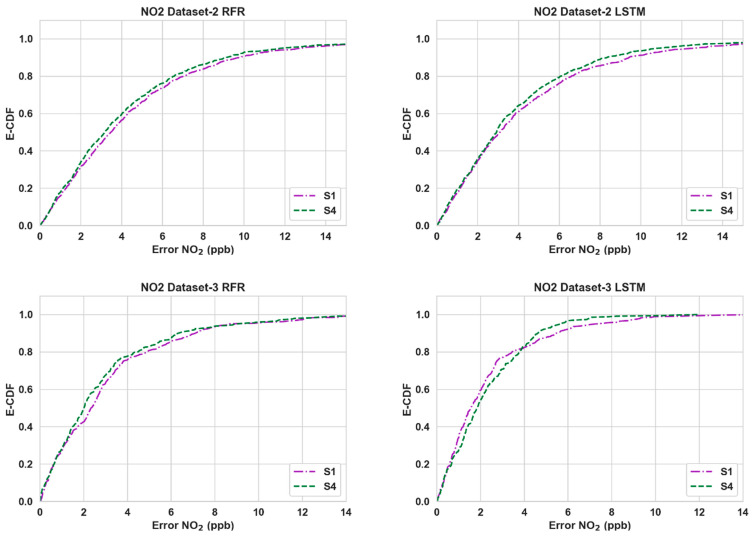 Figure 7
Figure 7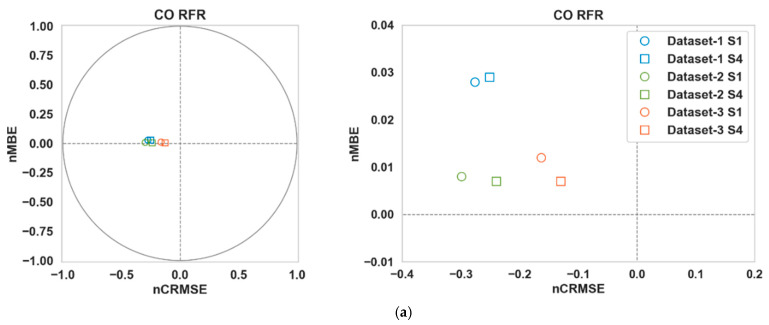 Figure 8
Figure 8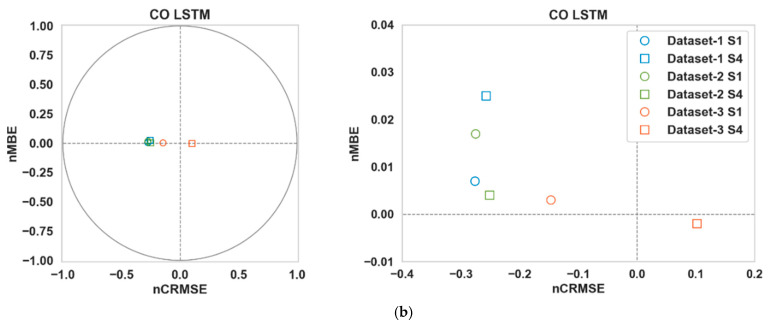 Figure 9
Figure 9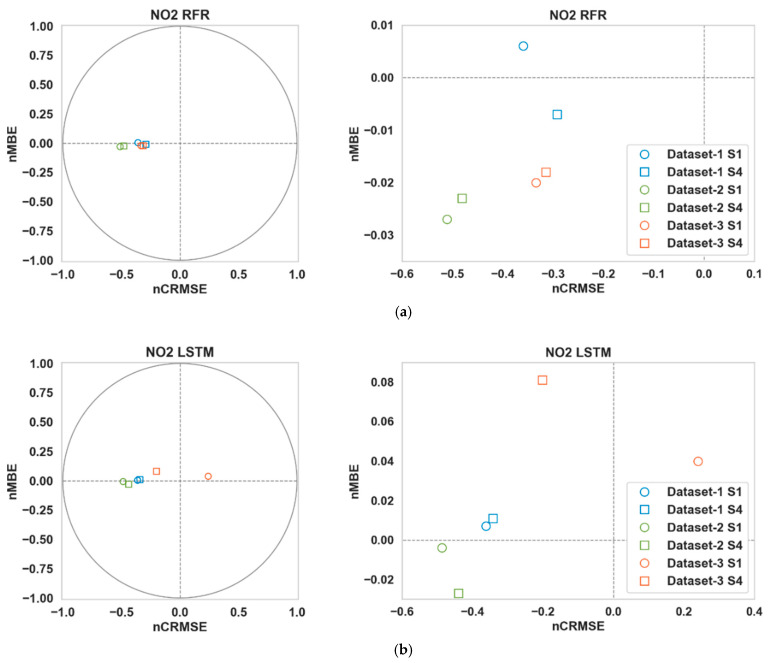 Figure 10
Figure 10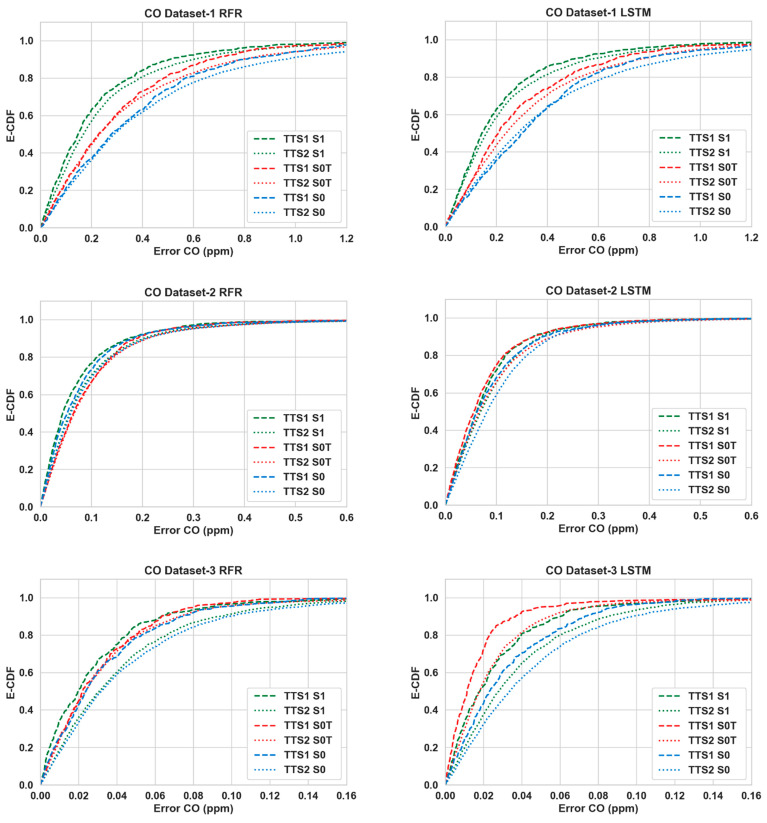 Figure 11
Figure 11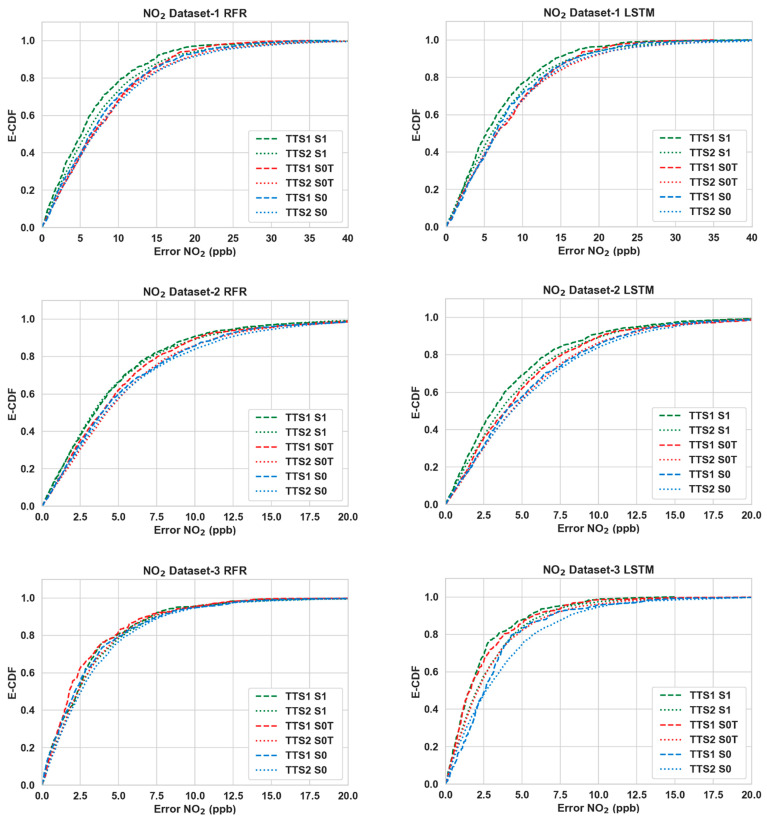 Figure 12
Figure 12| Pollutant | Algorithm | Dataset | Parameter | Scenario | |||
|---|---|---|---|---|---|---|---|
| S1 | S2 | S3 | S4 | ||||
| CO | RFR | 1 | RMSE | 0.346 | 0.332 | 0.326 | 0.314 |
| Improvement | 0 | 4.094 | 5.606 | 9.182 | |||
| 2 | RMSE | 0.129 | 0.110 | 0.125 | 0.104 | ||
| Improvement | 0 | 15.037 | 3.753 | 19.772 | |||
| 3 | RMSE | 0.043 | 0.034 | 0.042 | 0.034 | ||
| Improvement | 0 | 19.581 | 1.137 | 20.337 | |||
| LSTM | 1 | RMSE | 0.344 | 0.335 | 0.326 | 0.322 | |
| Improvement | 0 | 2.63 | 5.17 | 6.44 | |||
| 2 | RMSE | 0.119 | 0.110 | 0.117 | 0.109 | ||
| Improvement | 0 | 7.54 | 1.58 | 8.66 | |||
| 3 | RMSE | 0.039 | 0.029 | 0.038 | 0.027 | ||
| Improvement | 0 | 24.91 | 2.97 | 30.89 | |||
| NO2 | RFR | 1 | RMSE | 8.886 | 7.497 | 8.456 | 7.236 |
| Improvement | 0 | 15.64 | 4.84 | 18.58 | |||
| 2 | RMSE | 6.193 | 5.930 | 6.088 | 5.836 | ||
| Improvement | 0 | 4.25 | 1.70 | 5.77 | |||
| 3 | RMSE | 4.549 | 4.305 | 4.474 | 4.277 | ||
| Improvement | 0 | 5.36 | 1.65 | 5.98 | |||
| LSTM | 1 | RMSE | 8.968 | 8.560 | 8.836 | 8.476 | |
| Improvement | 0 | 4.55 | 1.47 | 5.49 | |||
| 2 | RMSE | 5.896 | 5.603 | 5.736 | 5.342 | ||
| Improvement | 0 | 4.97 | 2.71 | 9.39 | |||
| 3 | RMSE | 8.886 | 7.497 | 8.456 | 7.236 | ||
| Improvement | 0 | 15.64 | 4.84 | 18.58 | |||
- —NZ Product Accelerator
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsChalcogenide Semiconductor Thin Films · Quantum Dots Synthesis And Properties · Semiconductor materials and interfaces
1. Introduction
Air pollution adversely affects public health and quality of life [1]. Therefore, researchers from a diverse range of disciplines are working on mitigating the impact of air pollution [2,3]. Monitoring outdoor air pollution is one of the means to ensure public health and safety, raise public awareness and build a sustainable urban environment [4]. The conventional sensors used for monitoring air pollutants are typically expensive and large [5]. As a result, deploying a large number of monitoring stations is not affordable, leading to a poor spatial resolution of urban pollution data. Low-Cost Sensor (LCS) technologies aim to address this challenge and make air quality monitoring with high spatio-temporal resolution feasible [6]. Many cities are adopting this approach to improve their pollutant measurement capacity [7,8,9,10].
The pollutant data captured by the LCSs are less accurate than their conventional (and expensive) counterparts [11,12]. Many innovative methods have been proposed to improve the accuracy and the operability of the LCSs [12,13]. It should be noted that the detection limits of the LCSs depend on the sensors’ hardware and how the sensors were assembled rather than the calibration techniques working on a sensor’s output. Therefore, while the accuracy of LCSs can be improved with calibration, the detection limits of such sensors cannot be increased.
A popular method for calibration is to co-locate an LCS with a high-quality sensor (reference sensor) and use the data from the reference sensor as the ground truth to derive a calibration model [7,8,9,10] for the LCS to improve its accuracy. Many regression-based calibration methods have been proposed to improve the accuracy and reliability of LCSs [13,14]. Multiple Linear Regression (MLR) [7,8,9,15,16,17,18,19], Support Vector Regression (SVR) [20,21,22,23,24,25], Random Forest Regression (RFR) [20,22,26,27,28,29,30], Neural Networks (NN) (like Multilayer Perceptron (MLP)) [8,9,10,23,24,25,29] and Recurrent Neural Networks (RNN) [23,24,25,31] are among the most common techniques reported in the literature. In this study, we selected Random Forest Regression (RFR) from the ensemble Machine Learning (ML) techniques and Long Short-Term Memory (LSTM) from the RNN-based technique as representative examples from the two most popular ML-based calibration techniques. We show how readily available and previously unexploited co-variate data can significantly improve calibration accuracy.
Random Forest Regression constructs a set of decision trees from the training dataset to infer predictions. Each level of the decision tree splits the training data into smaller subsets to predict the target value (reference reading for gas sensor calibration). This splitting process ends when the model performance does not improve further or a terminal node is reached [26]. RFR-based calibration techniques have performed well for LCSs measuring ambient gas pollutants. Examples of RFR improving the calibration of field-deployed LCSs measuring ambient gas pollutants can be found in the works of Borrego et al. [30] (CO, NO_2_, O_3_ and SO_2_), Cordero et al. [20] (NO_2_), Bigi et al. [22] (NO and NO_2_), Malings et al. [29] (CO, NO, NO_2_ and O_3_) and Zimmerman et al. [26] (CO, CO_2_, NO_2_, O_3_). One of the main reasons for RFR being utilized by many reported works is its ability to account for cross-sensitivity [26], the influence of gases other than the target pollutant on the LCS.
Many researchers have used Neural Networks to calibrate LCS data [24,32]. Unlike other NNs that mostly use current data, RNNs model the historical time series behavior present in the dataset. They have been used by Sheik et al. [33], Wang et al. [34] and Fonollosa et al. [31] for calibrating LCSs under laboratory conditions. Esposito et al. [24,25] studied multiple calibration techniques, including RNN, on different LCSs and compared their performances. It should be noted that RNN models face two issues during calibration: Firstly, the determination of time lag must be made in advance, which requires a considerable number of experiments to identify. Secondly, these RNNs fail to capture long-time dependencies in the training dataset. Therefore, Long Short-Term Memory network (LSTM), a variant of RNNs, was introduced [35]. LSTM has been used for calibrating low-cost ambient gas sensors by different research groups. Examples of such applications can be found in the works of Han et al. (CO, NO_2_, O_3_ and SO_2_) [35] and Peng et al. (NO_2_) [36], among others.
The response of the LCSs are highly susceptible to cross-sensitivity from other ambient gases [7,24] and temperature and relative humidity [7,8]. Therefore, temperature, relative humidity and cross pollutant data are traditionally used as the regressor co-variates to correct the sensor output and make the pollutant readings more accurate [7,8,9,37]. These data are usually available, as LCSs are often deployed as an array or a suite with multiple pollutant sensors along with temperature and humidity sensors.
It is well known that LCS performance drifts and degrades over time. We hypothesize that using the number of days an LCS has been deployed in operation can be used as a co-variate to enable the ML algorithms to model and address the gradual degradation. Many gas pollutants come from anthropogenic sources and are direct results of human activities (e.g., CO, NO_X_ resulting from automobile emissions) [23,38]. Therefore, it is reasonable to assume that the time of the day that influences relevant human activities will also impact the pollutant concentration and can potentially be used as a co-variate. However, the literature does not show any evidence of utilizing these parameters, which are readily available without any additional cost, for multi-variate calibration of LCSs. In this article, we demonstrate that including these parameters as input features can significantly improve the accuracy of the LCSs.
2. Dataset Description
We have focused on the calibration of an LCS measuring two gas pollutants, CO and NO_2_, for this work. Both pollutants are components of the Air Quality Index (AQI) [39]. We have utilized three datasets collected by researchers using LCSs deployed in different parts of the world. Figure 1 shows the box plot of the target pollutant (CO and NO_2_) concentrations recorded by the reference sensors for all three datasets.
The raw pollutant readings from the LCSs (unchanged electrode data) and ground truth from co-located accurate reference-grade sensors are available for all three deployments. These datasets also include other pollutant data that have allowed us to address cross-sensitivity. Temperature and relative humidity data from sensors onboard the LCSs, available for all three setups, help mitigate their respective effects. Table 1 provides a summary of the three datasets. For more details of the datasets, sensors, deployment setup, and other relevant information, please refer to the works reported in [7,10,23], as well as our previous work [40].
3. Methodology
3.1. Calibration Models
The calibration models are regressors so that,
Here is the calibrated CO or NO_2_ reading computed from the raw readings ( of the LCS ( or , working electrode data and/or auxiliary electrode data), as well as , which comprises co-variates. Additionally, is the regression model, the parameters of which are derived from the training data in order to minimize the Mean Square Error (MSE) between the calibrated output and the ground truth received from the reference sensor. Four different scenarios have been considered for each of the ML algorithms.
3.1.1. Scenario 1 (S1)
Here the co-variates are temperature, relative humidity and other pollutant readings from the LCS sensor array so that,
The regressor, , is derived based on P_raw_, the raw pollutant sensor input (working electrode data and/or auxiliary electrode data), along with temperature (T) and relative humidity (RH) readings and other pollutant readings ( ), to minimize the MSE between and the ground truth.
3.1.2. Scenario 2 (S2)
For the second scenario, , the number of days the LCS has been deployed in the field is used as an additional co-variate for estimating the regressor model . The calibrated output is
3.1.3. Scenario 3 (S3)
In Scenario 3, is replaced with , the time of the day the readings were taken at for estimating the regressor, . The calibrated output can be expressed as
3.1.4. Scenario 4 (S4)
Both and are now included as co-variates along with the raw target pollutant readings (either CO or NO_2_), the temperature and relative humidity readings and other pollutant readings from the LCS to estimate the regressor . Therefore, the calibrated output can be written as
3.2. Algorithm Training and Validation
As mentioned previously, we have used two machine learning algorithms, RFR and LSTM, to investigate the effects of the temporal co-variates, and . A rigorous training, validation and testing method has been followed during this work. The hyperparameters have been tuned on the relevant training datasets and tested on the corresponding testing sets for the regressors. The list of the tuned hyperparameters is given in Table 2.
A portion of each dataset (training data) is used to determine the parameter of the calibration model by training and validating the regressor model. The performance of the trained model is then evaluated on the remainder of the data (testing data) not used for training. There are two common usage situations for an LCS. In one situation, a co-located low-cost sensor can be used as a backup in case the reference grade monitor is out of commission for a short period. To emulate this situation, we split each data set so that 90% of the data were used for training/validation and 10% of the data were used for evaluating the accuracy of the trained models. We term this as Train-Test Split 1 or TTS1. The second usage situation is using the LCS after calibrating the sensors through a relatively short co-location with a reference sensor. This is emulated by using 20% of the data for training/validation and the remaining 80% for evaluating the accuracy of the trained models. We term this as Train-Test Split 2 or TTS2. The train/validation/test process has been illustrated as a diagram in Figure 2.
For the LSTM models, an early stopping method has been used during the train/validation stage. The validation sets’ MSEs are observed for each epoch. The training terminates when the MSE does not decrease by a certain tolerance threshold for a set number of epochs (patience). The weights which provide the minimum MSE within that patience are chosen as the model’s final weight.
3.3. Performance Metrics
Several standard performance metrics have been used in this study to evaluate the calibration models. These metrics in various ways measure the residuals or errors, i.e., difference between the calibrated output of the LCS ( ) and the ground truth reading ( ) for the “un-seen” test data.
Root Mean Square Error (RMSE), which is commonly used as a performance metric for sensor calibration [7,41,42,43,44], was utilized as a metric. RMSE is the standard deviation of the residuals and can be expressed as:
Here, N is the number of samples in the relevant test dataset.
For a more detailed investigation, we have also plotted the Cumulative Distribution Function (CDF) of absolute errors, .
Target diagrams [26,45] were constructed for visualizing the performance of the calibration models. The y axis in a target diagram represents the Mean Bias Error (MBE) normalized by the standard deviation of the ground truth so that:
Here, is the standard deviation of the ground truth for the relevant test dataset. The x axis of the Target Diagram represents the normalized unbiased estimate of the RMSE, the Centered RMSE (CRMSE), where:
Please note that the normalized CRMSE is multiplied by to produce the target diagrams, with being the standard deviation of the calibrated data for the relevant test dataset.
4. Results and Discussion
4.1. Model Evaluation for Different Scenarios
Table 3 shows the performance of the calibration algorithms (RFR and LSTM) in different scenarios. We can make the following observations:
- Overall, the use of and has improved the calibration accuracy noticeably for both pollutants throughout all three datasets. The lowest RMSE (Table 3) is achieved for S4 in all cases.
- For CO, the gain is quite noticeable in S2 and S4 compared to S3 for both algorithms in Datasets 2 and 3. Dataset 3 in particular showed a large improvement (around 20% or more) when was introduced as an input. For both algorithms with CO as the target pollutant, RMSE improved slightly in S3 from that of S2 in Dataset 1, while they were significantly lower (around 3% or less) in Datasets 2 and 3.
- Overall, the improvements for NO_2_ are more modest compared to the RMSE improvements in CO. For NO_2_, these improvements were mostly below 10% in all scenarios, with the exception being RFR in S2 and S4 (more than 15%) for Dataset 1.
- In all cases, both S2 and S4 have outperformed S3 noticeably (the only exception being CO in Dataset 1). Thus, the impact of as an input co-variate seems to be more prominent than adding . However, the opposite can be seen for CO in Dataset 1.
- The empirical CDF plots of calibration error in Figure 3 and Figure 4 show a clear improvement in S4 from S1, further demonstrating the importance of using both and data as input features.
- The target diagrams for the calibration are presented in Figure 5 and Figure 6. All the points lie inside the unit circle, i.e., radius = 1, and therefore the variance of the residuals is smaller than that of the reference measurements. Thus, the variability of the calibrated output (dependent variable) is explained by the reference data (independent variable) and not the residues. The distance of these points from the origin represents the normalized RMSE (RMSE/ ), which shows that calibrations achieved are more accurate than the same for S1. This once again underlines the importance of adding temporal data as input features. It is also observed that the standard deviation of the calibrated data is mostly smaller than the standard deviation of the ground truth, as the majority of the points lie on the left plane.
In summary, using temporal parameters as co-variates for the regressors improved the calibration accuracy for both pollutants for all three datasets. The performance gain for NO_2_ is more modest compared to those achieved for CO. In general, the impact of the duration of time a sensor has been deployed is more pronounced than the time of day the reading was taken. Using both temporal co-variates (along with cross-pollutant data and temperature and relative humidity) provides the most accurate calibration for both target pollutants for all three datasets.
4.2. Impact of Train-Test Split
Table 4 shows the improvement in RMSE while using the temporal co-variates for a 20/80 train/test split (TTS2). This represents the use case where the LCS is co-located with a reference sensor for a set period for calibration and then afterwards deployed in the field for monitoring pollutants at locations where no AQM station is available. We can again observe noticeable improvements in S4 for both pollutants. However, the level of improvement is more modest than its 90:10 counterparts.
4.3. Significance of Temporal Information
Traditionally, LCS are calibrated by utilizing cross-pollutant data as co-variates alongside temperature and relative humidity data received from the LCS. However, cross-pollutant data are only available if the LCS is constructed as an array consisting of a suite of multiple pollutant sensors. Based on the efficacy of the temporal co-variates shown in this study, we believe that utilizing the number of days deployed ( ) and time of day data as input for the calibration algorithms may let us achieve a reasonably accurate calibration model even when the cross-pollutant data are not available.
Let us consider a scenario (termed S0) where the LCS provides only the target gas sensor data along with T and RH. We now include the two readily available co-variates (scenario S0T). We will use a similar methodology to that outlined in Section 3.2 to train and validate the algorithms for these two scenarios. RMSE improvement results for the 90:10 training and testing ratio for RFR and LSTM have been illustrated in Table 5. All the results show a noticeable improvement in RMSE. It is obvious that the accuracy of the calibration can be significantly improved even without deploying a sensor array of multiple pollutants, and therefore without increasing the cost.
The improvement of RMSE scores in S1 and S0T from S0 for the 90:10 training and testing ratio are shown in Table 6 and Table 7. This helps us compare the impact of temporal co-variates against that of cross-pollutant data. Table 8 and Table 9 show the comparative results for 20:80 training and testing ratio. Overall, the improvements that can be achieved with the temporal co-variates exclusively are substantial and not far behind the improvements observed when cross-pollutant data were available (and temporal co-variates were not used). The empirical CDF plots for S1 and S0T presented in Figure 7 and Figure 8 show similar encouraging patterns.
5. Conclusions and Future Work
In this article, we proposed to utilize temporal co-variates, namely the duration of time a sensor has been deployed and the time of day the reading was taken, to improve the calibration of low-cost sensors. For our study, we selected two common machine learning-based algorithms, Random Forest, and LSTM, and three datasets of ambient gas pollutant collected by researchers. The target pollutants of the study were CO and NO_2_. Based on our investigation, it can be concluded that the temporal co-variates can improve the calibration accuracy significantly. This is a significant outcome, as this can be achieved with readily available information.
Continual progress in deep learning presents the opportunity to use new and advanced ML algorithms. Our preliminary investigation shows that the temporal co-variates improve the accuracy of a wide range of ML methods, e.g., Gradient Boost, One Dimensional Convolutional Neural Network, Multilayer Perceptron or Artificial Neural Network, etc. However, further investigation is necessary; therefore, future research can investigate the impact of the temporal co-variates on other machine learning-based calibration algorithms. Our work shows the efficacy of various co-variates. The extent of the impact varies, potentially due to both the hardware used and the ambient conditions. We believe that the gradual degradation of the sensor’s performance, in large part, depends on the hardware. Therefore, the co-variates used in this study should improve the performance of LCSs in general. However, the degree of the efficacy would be dependent on the hardware, among other factors. A future study can investigate this issue with data collected from a diverse group of LCS hardware.
Our investigation showed that the time of deployment and time of the day have a significant impact when used as input. However, there are other available temporal parameters, such as month of the year, whether the day is a weekday or weekend, etc. While these parameters were found to have no noticeable impact for the three datasets in this work, a future study with other datasets may show them to be useful co-variates. It is also not clear how the ML models behave if the trained model from one LCS is used to calibrate another LCS with similar hardware and a similar configuration. It will be worthwhile to investigate how a transfer calibration approach can be used in such a scenario.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1World Health Organization WHO Global Air Quality Guidelines: Particulate Matter (PM 2.5 and PM 10), Ozone, Nitrogen Dioxide, Sulfur Dioxide and Carbon Monoxide World Health Organization Geneva, Switzerland 202134662007 · pubmed ↗
- 2Cohen A.J. Brauer M. Burnett R. Anderson H.R. Frostad J. Estep K. Balakrishnan K. Brunekreef B. Dandona L. Dandona R. Estimates and 25-year trends of the global burden of disease attributable to ambient air pollution: An analysis of data from the Global Burden of Diseases Study 2015 Lancet 20173891907191810.1016/S 0140-6736(17)30505-628408086 PMC 5439030 · doi ↗ · pubmed ↗
- 3Kampa M. Castanas E. Human health effects of air pollution Environ. Pollut.200815136236710.1016/j.envpol.2007.06.01217646040 · doi ↗ · pubmed ↗
- 4Alshamsi A. Anwar Y. Almulla M. Aldohoori M. Hamad N. Awad M. Monitoring pollution: Applying Io T to create a smart environment Proceedings of the 2017 International Conference on Electrical and Computing Technologies and Applications (ICECTA)Ras Al Khaimah, United Arab Emirates 21–23 November 201714
- 5Tsujita W. Yoshino A. Ishida H. Moriizumi T. Gas sensor network for air-pollution monitoring Sens. Actuators B Chem.200511030431110.1016/j.snb.2005.02.008 · doi ↗
- 6Ali S. Glass T. Parr B. Potgieter J. Alam F. Low Cost Sensor with Io T Lo Ra WAN Connectivity and Machine Learning-Based Calibration for Air Pollution Monitoring IEEE Trans. Instrum. Meas.20207011110.1109/TIM.2020.3034109 · doi ↗
- 7Liang Y. Wu C. Jiang S. Li Y.J. Wu D. Li M. Cheng P. Yang W. Cheng C. Li L. Field comparison of electrochemical gas sensor data correction algorithms for ambient air measurements Sens. Actuators B Chem.202132712889710.1016/j.snb.2020.128897 · doi ↗
- 8TopalovićD.B. DavidovićM.D. JovanovićM. Bartonova A. Ristovski Z. Jovašević-StojanovićM. In search of an optimal in-field calibration method of low-cost gas sensors for ambient air pollutants: Comparison of linear, multilinear and artificial neural network approaches Atmos. Environ.201921364065810.1016/j.atmosenv.2019.06.028 · doi ↗